業務でAzureをよく使う関係で,Microsoft Azure アダプターを導入しています。リレーショナルにしづらいデータを格納したり,Azure Searchの検索対象にしたりするのに便利です。しかしながら,ASTERIA WARPでの実例があまり見当たらないのでここに書いてみることにしました。
CosmosDB コンテナー作成
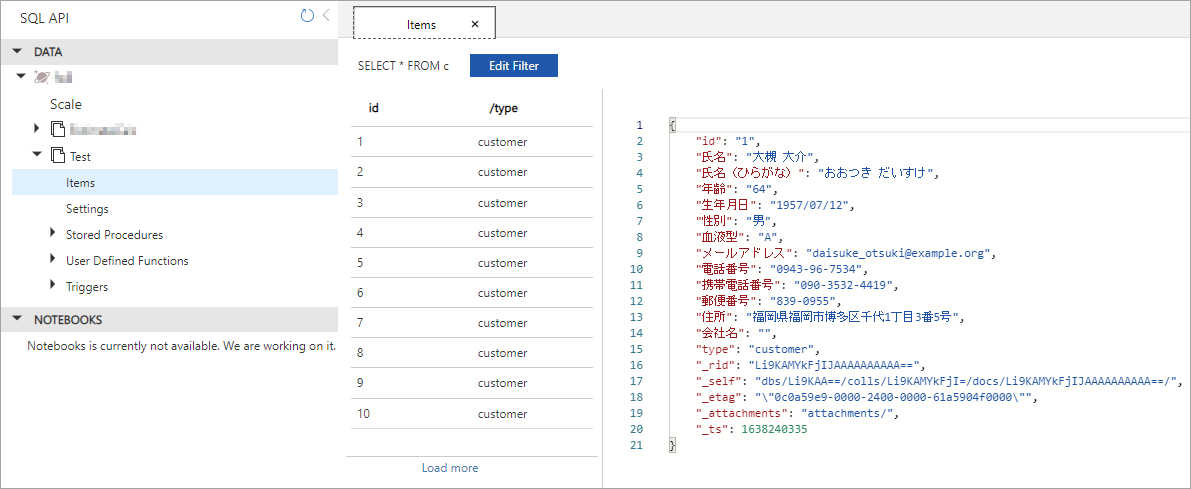
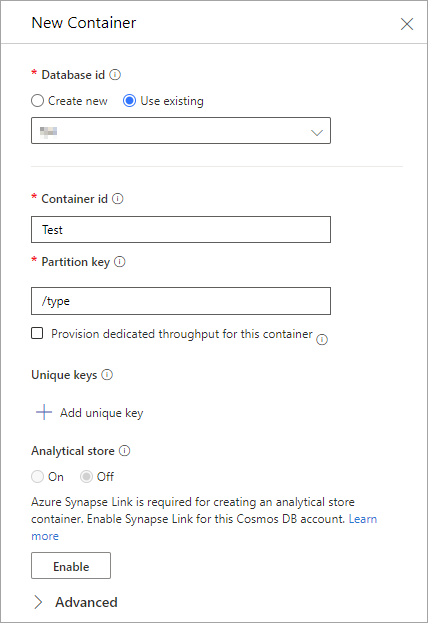
テスト用にコンテナーを作成します。
- Container id:Test
- Partition key:/type(テストなので何でもよいのですが,今回は type をパーティションキーにします)
フロー作成
今回の記事に使うフローを作成します。
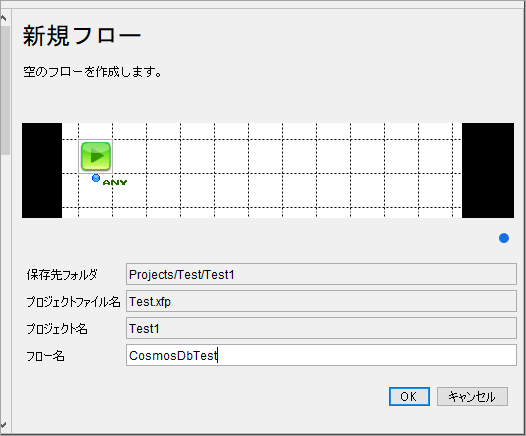
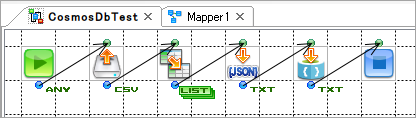
CSVから顧客データ(架空)を読取り,CosmosDBにアップロードするだけのシンプルなフローです。
CSVの準備
CSVは個人情報テストデータジェネレーターで作成しました。
idとして使うため,「コード」列は自分で追加します。
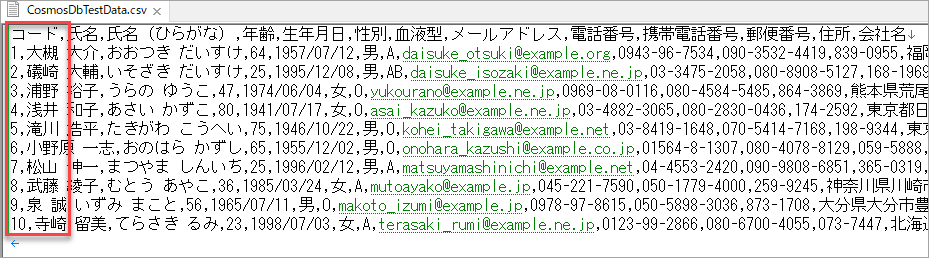
CSVを読み取るためのFileGetは以下のように設定します。
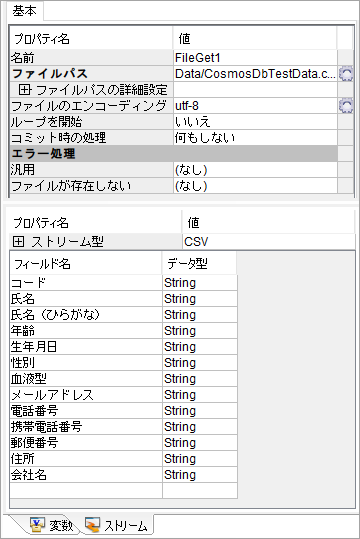
ParameterListに変換
マッパーを追加して,以下のように設定します。
- ループを開始:はい(今回は1行ずつアップロードします)
- ストリーム型:ParameterList(RecordやCSVのままだとJSONに変換した時に配列になり,エラーが発生します)
- フィールド名:id(CosmosDBのid)
- フィールド名:type(CosmosDBのパーティションキー)
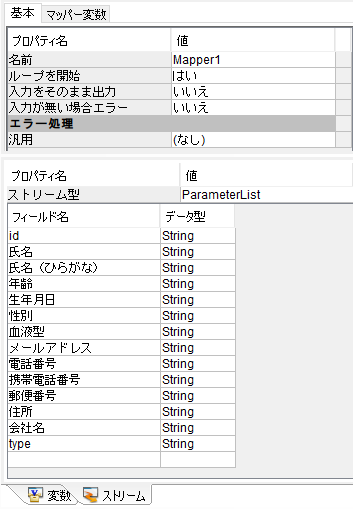
以下のように連結します。
- id:コード(コードをCosmosDBのidとして使います)
- type:customer(今回は固定の文字列を使います)
JSONに変換
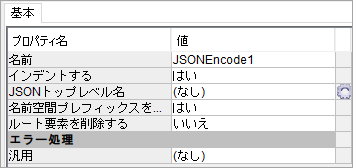
JSONEncodeを追加し,以下のように設定します。
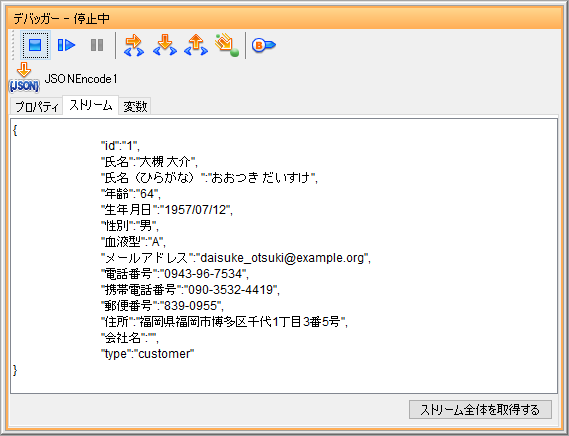
以下のようなJSONテキストになります。
CosmosDBにアップロード
AzureDocumentDBPutを追加し,以下のように設定します。
- コネクション情報,データベース名(自分の環境を使用)
- コレクション名:Test
- 実行する処理:Create
- パーティションキー:["customer"](typeと同じ値。行によって変えたい場合は変数やマッパーを使用)
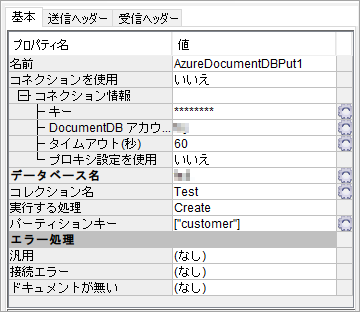
パーティションキー
ポイントはパーティションキーで,大括弧と引用符で囲む必要があります。これを設定しないと以下のようなエラーが発生します。
空白の場合
The partition key supplied in x-ms-partitionkey header has fewer components than defined in the the collection
customerだけの場合
Partition key customer is invalid
実行結果
10件のデータをアップロードすることができました。