一行まとめ
先頭行をそのままヘッダー(列名)として扱えない CSV データの前処理をした。
背景
Python でデータ分析をする練習用のデータとして、独立行政法人統計センターが提供している SSDSE(教育用標準データセット)を利用したい。
しかし、SSDSE-市区町村(SSDSE-A)をダウンロードしたところ、そのままでは扱いづらいデータであることがわかった。
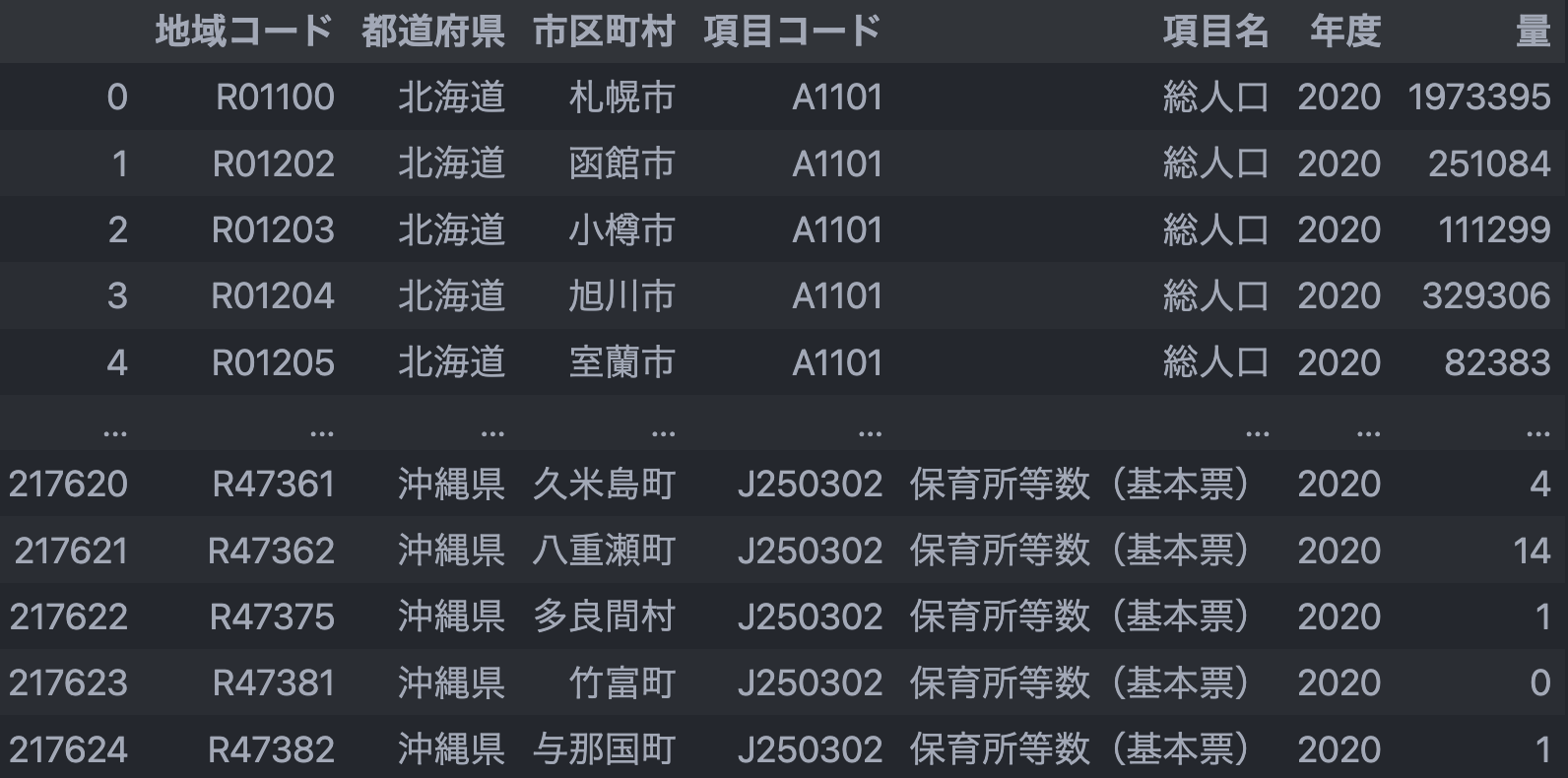
(CSV データなんだけど、若干のエクセル味を感じる…!)
解決したい問題
- 先頭行が正しい項目名になっていない
- 年度が一つの行になっており、そのままでは集計できない
対応(2023-12-23 更新)
いただいたコメントを参考にしてコードをコンパクトにできたので更新分を載せます。
import pandas as pd
id_cols = ['地域コード', '都道府県', '市区町村']
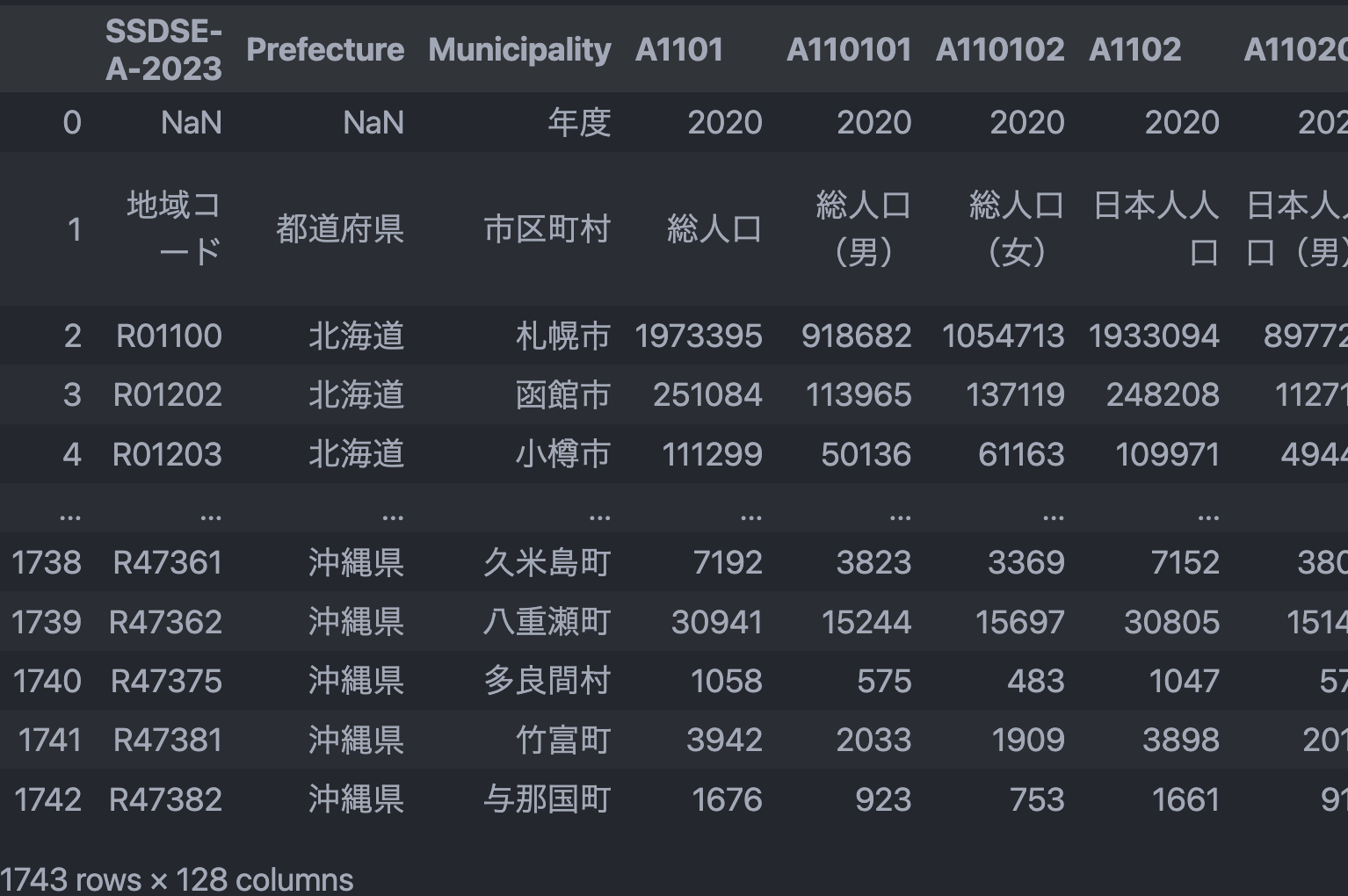
df = pd.read_csv('SSDSE-A-2023.csv', encoding='cp932', header=[1,2])
df = pd.melt(
df, id_vars=list(df.columns[:3]),
var_name=['年度', '項目'], value_name='値')
df.columns = [*id_cols, *df.columns[3:]]
header をリストで指定することで列を MultiIndex にしています。
MultiIndex はそのままだとちょっと扱いづらいので、id_varsなどは少しまどろこっしい書き方になってます。
感想
だいぶスッキリしました。
マルチカラムの扱いは相変わらず自信ないですが。
以下、アーカイブとして.
対応(過去分)
解決したい問題
- 先頭行が正しい項目名になっていない
- 年度が一つの行になっており、そのままでは集計できない
戦略
-
列の階層構造を分解して縦持ちデータ(地域-項目-年度ごとに一行)にすることを目指す
-
必要な情報を一旦文字列で結合して、あとで分解する
対応(2023-12-23 更新)
いただいたコメントを参考にしてコードをコンパクトにできたので更新分を載せます。
単純にデータを読み込んだ場合の結果
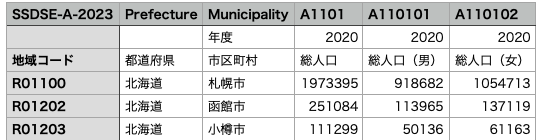
データの前処理をした結果
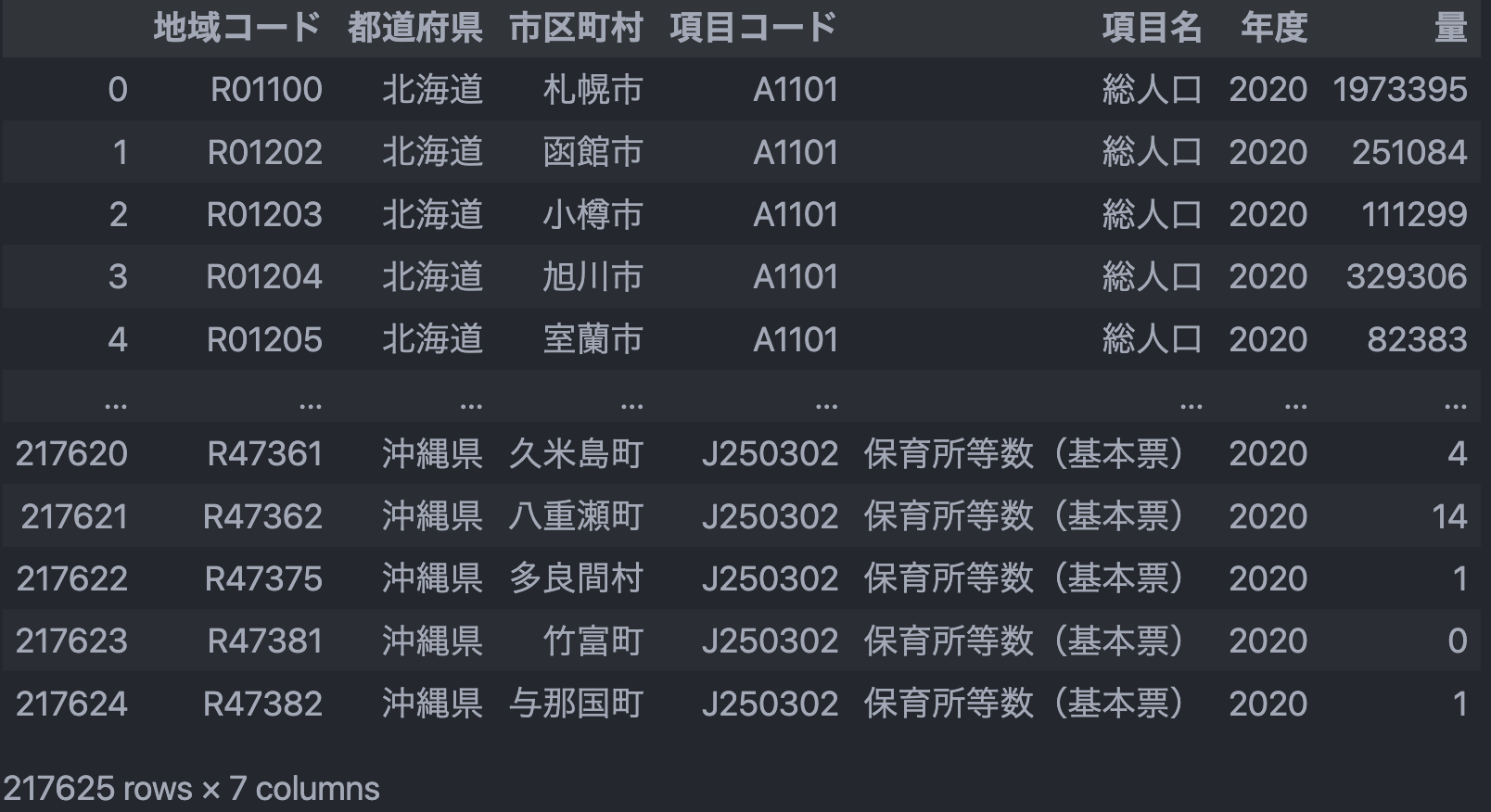
実行した Python のコード
import pandas as pd
FILE_PATH = 'あなたの/ファイルパス/を入れてください'
LOCAL_CODE = '地域コード'
PREFECTURE = '都道府県'
MUNICIPALITY = '市区町村'
ITEM_YEAR = '項目名(年度)'
ITEM_CODE = '項目コード'
ITEM_NAME = '項目名'
YEAR = '年度'
AMOUNT = '量'
df = pd.read_csv(FILE_PATH, encoding='shift-jis', header=None)
df.iloc[0:2,:3] = '' # 表の左上ゾーンの NaN が邪魔なので '' で埋めておく
# ヘッダーとしてまとめたい情報を抜き出す
item_code_row = df.iloc[0,:]
year_row = df.iloc[1,:]
item_name_row = df.iloc[2,:]
# 一旦文字列として結合してあとで分解する
_header = item_code_row + ',' + item_name_row + ',' + year_row
_header = _header.str.strip(',') # 地域コードなどは分割しないので , を削っておく
df.columns = _header
# ヘッダーの素材になった行を削除しておく
df = df.iloc[3:,]
# [地域-項目名-年度] が一行ずつになるようにデータを変換する
id_cols = [LOCAL_CODE, PREFECTURE, MUNICIPALITY]
_var_col = 'variable' # データ加工のための作業列
df = pd.melt(df, id_vars=id_cols, var_name=_var_col, value_name=AMOUNT)
df[ITEM_CODE] = df[_var_col].apply(lambda x: x.split(',')[0])
df[ITEM_NAME] = df[_var_col].apply(lambda x: x.split(',')[1])
df[YEAR] = df[_var_col].apply(lambda x: x.split(',')[2])
df = df[[*id_cols, ITEM_CODE, ITEM_NAME, YEAR, AMOUNT]] # 列の並び替え
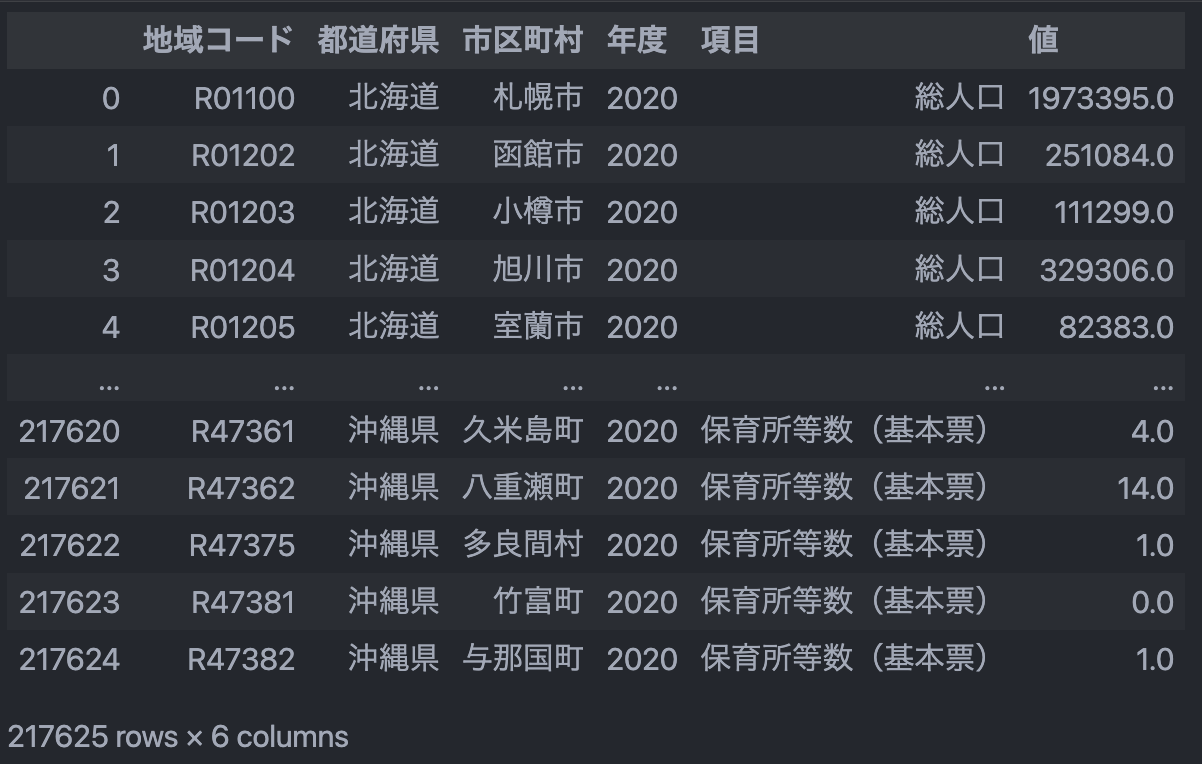
df
感想
単純な問題のようで、実際には前処理にかなり手こずった。
とはいえ、利用可能なデータが公的に供給されていることはありがたい。
先頭行をそのままヘッダーに使えないデータは今後もしばしば出くわしそうなので、
今後こういうケースがあったら今回の知見を活かしたい。
(もうちょとスマートな解決方法もありそうだけど、まあ前処理は多少泥臭くてもやるものなので…)
Appendix
データの変形過程
実行環境は VSCode の Interactive Window.
df = pd.read_csv(FILE_PATH, encoding='shift-jis', header=None)
df.iloc[0:2,:3] = '' # 表左上ゾーンの NaN が邪魔なので '' で埋めておく
df
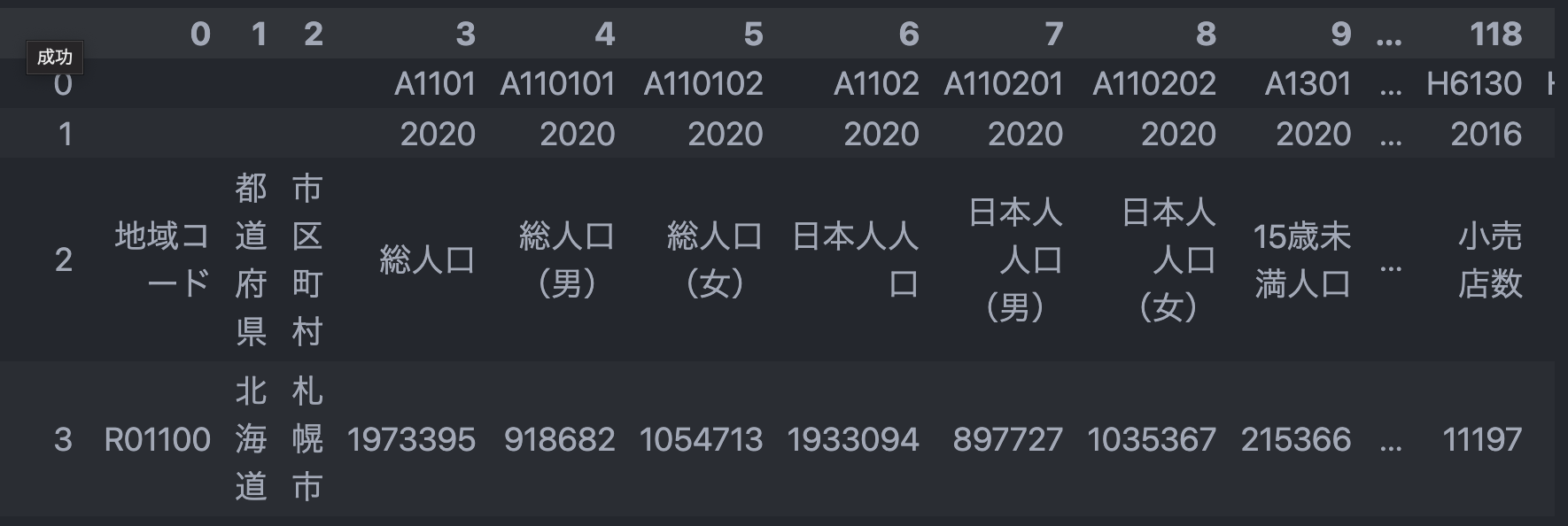
# ヘッダーとしてまとめたい情報を抜き出す
item_code_row = df.iloc[0,:]
year_row = df.iloc[1,:]
item_name_row = df.iloc[2,:]
# 一旦文字列として結合して、あとで分解する戦略を取る.
_header = item_code_row + ',' + item_name_row + ',' + year_row
_header = _header.str.strip(',') # 地域コードなどは分割しないので , を削っておく
df.columns = _header
df
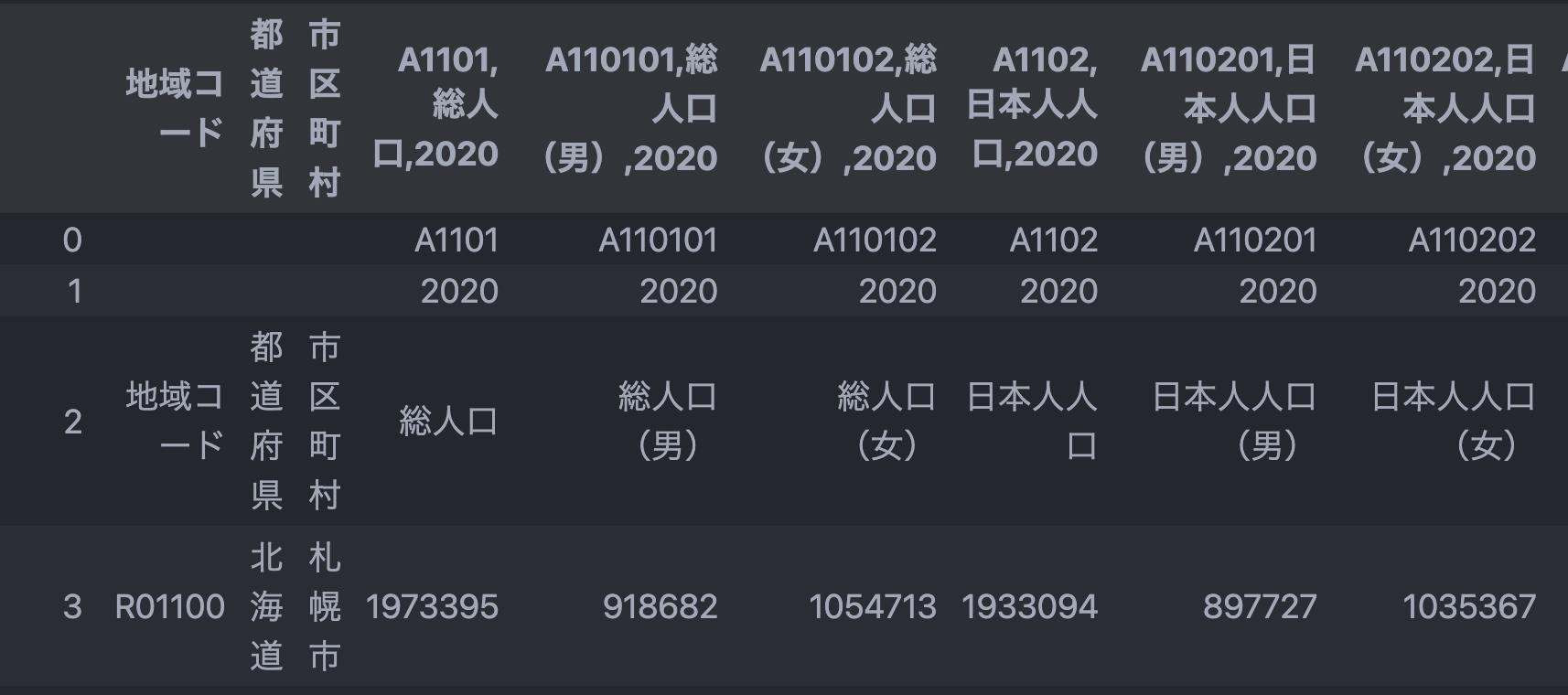
# header の素材になった行を削除しておく
df = df.iloc[3:,]
# [地域 - 項目名 - 年度] が一行ずつになるようにデータを変換する
id_cols = [LOCAL_CODE, PREFECTURE, MUNICIPALITY]
_var_col = 'variable'
df = pd.melt(df, id_vars=id_cols, var_name=_var_col, value_name=AMOUNT)
df
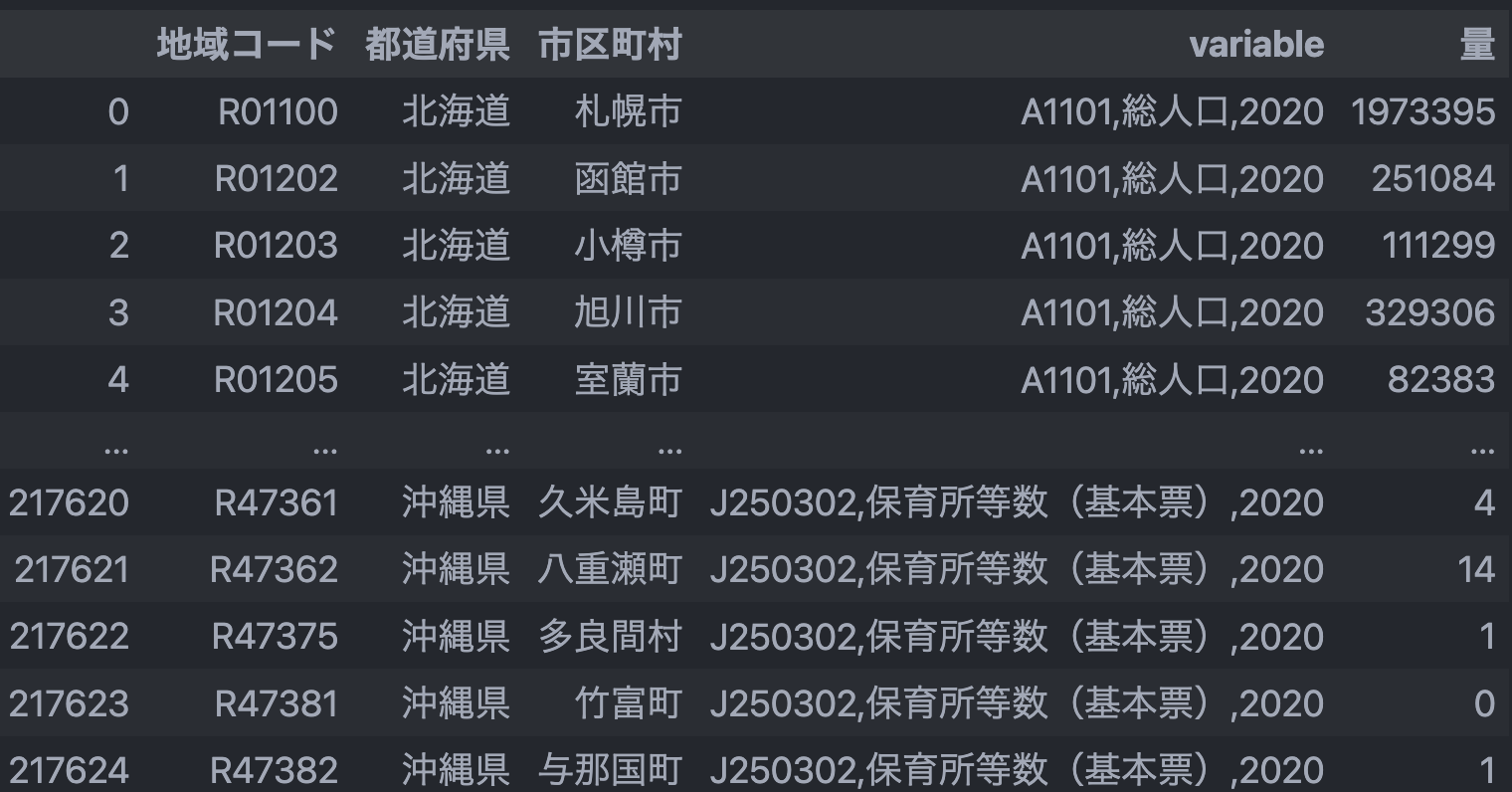
# 文字列で結合された列を分解してごにょごにょする
df[ITEM_CODE] = df[_var_col].apply(lambda x: x.split(',')[0])
df[ITEM_NAME] = df[_var_col].apply(lambda x: x.split(',')[1])
df[YEAR] = df[_var_col].apply(lambda x: x.split(',')[2])
df = df[[*id_cols, ITEM_CODE, ITEM_NAME, YEAR, AMOUNT]] # 列の並び替え
df