先日HackDay2019というイベントに参加しました.
これはYahoo主催のハッカソンで,"24時間で何か面白いプロダクトを作ろう"というイベントなのですが,約80チームが参加した中で私たちのチームはO2O賞とHappy Hacking賞(観客投票賞)という2つの賞を獲ることができました.
昨日と今日開催のYahoo Hackday 2019で、僕らの作品「都会のオアスシ」がO2O賞とHappy Hacking賞をダブル受賞しました!!
— たかはま (@grouse324st) December 15, 2019
フィールド上を寿司が自在に動き回り、注文されると駆けつける次世代の寿司体験を楽しめます!
(バズり賞のためにいいねRT希望)
Hack ID:20#HackDay2019 #つくるってたのしいね pic.twitter.com/sJVhQgI4ih
何を作ったかというと,一言で言えば「フィールド上で寿司が自走し,注文すると最速で駆けつける」プロダクトです.

写真のインパクトが強すぎて何を言っているかわからないと思うので,詳しく知りたい人は僕のチームメイトが書いたこちらの記事を見てください.面白かったらぜひいいねもしてあげてください.
【報告】
— shio⑅ᵕ_ᵕ̩̩ƪ (@music_shio) December 19, 2019
Hack Day 2019で、機械学習しながら魚偏の漢字の上を走り回る寿司を作ってO2O賞とHappy Hacking賞をダブル受賞しました。
何言ってるかよくわからないと思うのですが、全貌をnoteにまとめたのでぜひ読んでください。https://t.co/pu5MK1Aq9m
HackID:20#つくるってたのしいね#HackDay2019
この寿司,実は様々なテクノロジーを駆使して作られているのですが,その中で私が担当したのが「魚へんの漢字の画像パターンマッチング」です.
寿司たちは魚へんの漢字が多数描かれたフィールド上をぐるぐると自走しています.その際,寿司が自分の現在位置を知るために,カメラでフィールドの一部(つまり漢字)を撮影し,それがフィールド上のどこなのかをマッチングをして調べているのです.
図で見た方がわかりやすいですね.要するにこれです(発表スライドより).
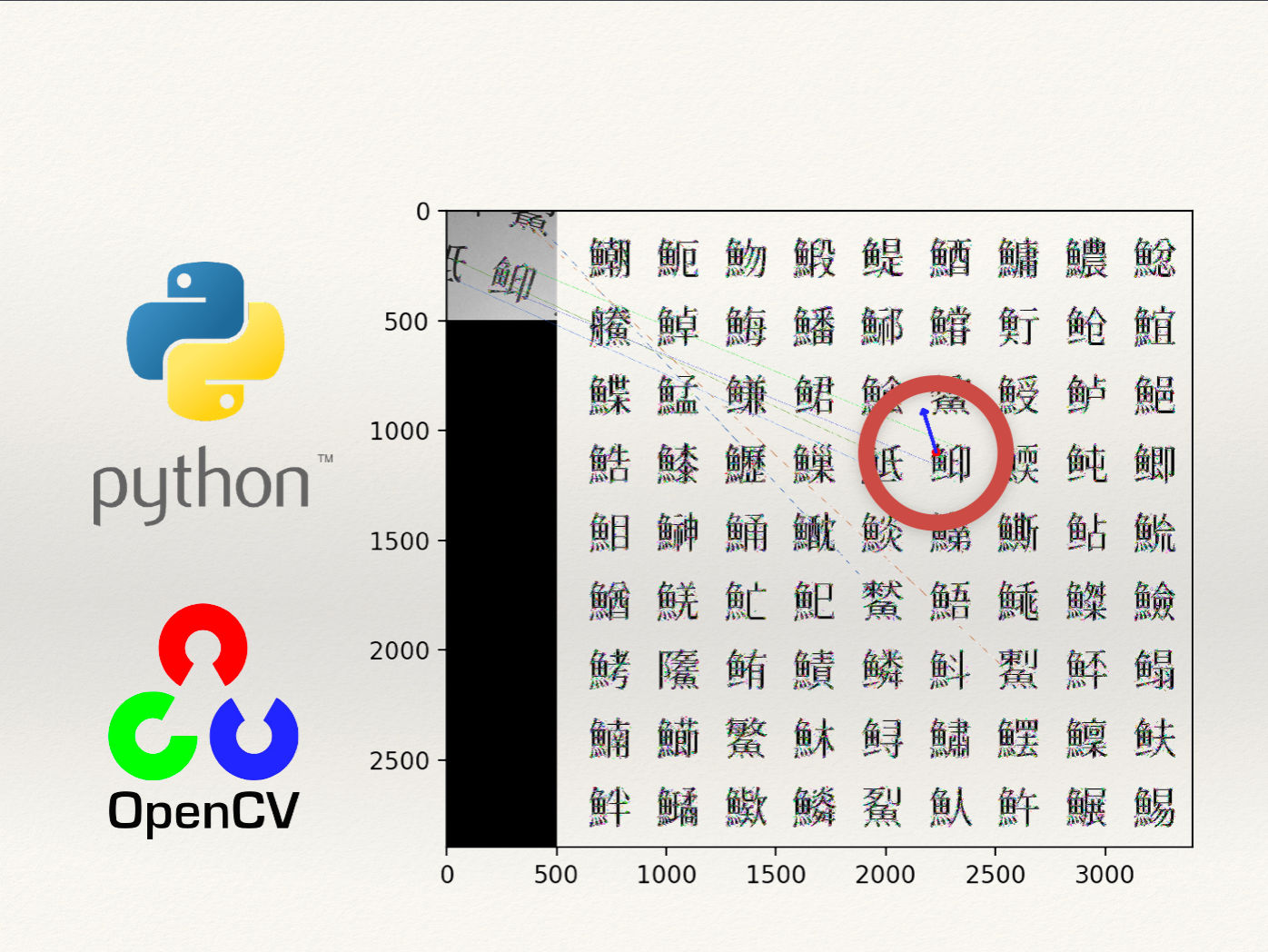
左がカメラ画像,右がフィールド全体です.魚へんの漢字が書かれたマップの中から,カメラ画像の位置と向いている方向(角度)を特定しています.カメラ画像の中心,「鮣(こばんざめ)」という漢字の左上あたりをぴったりと検出できていますね.
これはOpenCVのAKAZEを使った特徴量マッチングによって実現されています.
とはいえ,「魚へんの漢字をマッチングしたい」と思っている人はおそらく世界に私たちしかおらず,この記事を読んでいる方はタイトルを見て純粋に「誰よりも頑強な特徴量マッチングを教えてくれ」と焦ってらっしゃる方だと思いますので,これ以降は手法の説明に専念したいと思います.
ソースコードと今回使った漢字マップ,カメラ画像のサンプルは全てこちらのフォルダにありますので興味がある方はぜひ試してみてください!
https://github.com/shutakahama/OpenCV_feature_matching
状況,求められること
- マップ画像
魚へんの漢字が多数書かれています.中には同じ意味の漢字の旧字体なども含まれていたりします.魚へんが同じなのでとにかく似ています.
なお,フィールド上には漢字が3232個並んでいますが,もはや細かすぎて見えないので今回は1010個程度の範囲で探索します.(ハッカソンの際も直前にいた位置を元にマップ全体の一部を切り取ってマッチングしていました.)

- カメラ画像
フィールドを紙に印刷し,それをカメラで撮影した画像です.
漢字が1つは含まれるくらいの画角サイズとします.撮影の向きは正面とは限らないので,文字は回転しているかもしれません.字のサイズはだいたい一定だとしますが,マップ画像と同じではありません.また写真なので影が映ったりピンボケしたりすることがあります.

- 出力
撮影したカメラ画像のマップ上での位置と向きを特定します.こんな感じで所要時間(time)と座標(x, y)と向き(drc)が出てきます.

なぜ特徴量マッチング?
2つの画像の一致を調べる手法でベーシックなものとしてはテンプレートマッチングや特徴量マッチングがあります.しかしテンプレートマッチングは回転や拡大縮小に弱く,今回の状況では角度や大きさを少しずつずらしていちいちマッチングする必要があります.時間がかかりすぎる方法は現実的ではありません.
一方特徴量マッチングは回転やスケーリングにある程度強いのが特徴です.特にAKAZE特徴量によるマッチングは扱いやすくかなり強力で,関連する記事も多いので試すにはもってこいです.
特徴量マッチングの説明や試してみた記事は少し検索するだけでもこのくらいあります.私も参考にさせていただきました.特に上2つは状況が似ていたので大変助かりました.
Python OpenCV AKAZEで文字検出したい話
OpenCVを使ったパターンマッチングで画像中の物体抽出 with Python
OpenCV 3とPython 3で特徴量マッチング(A-KAZE, KNN)
【Python】OpenCVで特徴量マッチング – ORB, SIFT, FLANN
[OpenCV] いまさら局所特徴量で物体検出!?
しかし!今回は今までのどの記事よりも頑強なマッチングを実現します!なぜならどの記事よりも状況がシビアだから!
なお,より高度な画像認識として深層モデル(ディープラーニング)を用いたものを使う選択肢もありましたが,計算資源が乏しくデータ準備も大変そうだったため今回は使っていません.
カメラ画像の前処理
画像認識の基本は上手な前処理です.実世界での応用は前処理こそが命と言っても過言ではありません.
例えばこのような画像が入力されると比較的マッチングがうまくいきます.文字と背景の色がはっきり分かれているからです.

しかしこのような画像ではうまく行かないことがあります.背景が陰っていて文字と同じくらい色が黒いからです.

例えばこれに2値化処理を施してもあまりうまくいきません.うまく文字と影を分離できず一部分が黒くなってしまうからです.大津の2値化では限界がありますし,パラメータ職人が天才的な閾値を見つけたとしても別の環境に行けばそれは通用しない可能性が高いです.

また2値化を行うと輪郭の形が少し変わってしまうことがあるのですが,形状が重要な特徴点マッチングでは輪郭の変化は命取りです.上の画像でも文字が太くなったり細くなったりしている箇所がありますがこれでは性能が上がりません.
そこで私は画像にガンマ補正をかけることにしました.ガンマ補正とは画像の輝度を調整するもので,
- gamma > 1 --> 元の画像より全体的に暗くなる
- gamma = 1 --> 元の画像と同じ
- gamma < 1 --> 元の画像より全体的に暗くなる
となります.gamma補正については例えばこの記事が詳しそうです.
(99) OpenCV #4 : ガンマ補正で画像を見やすく調整
コードではこの部分です.
gamma = 1.8 # この値で明るさが変わる
gamma_cvt = np.zeros((256,1),dtype = 'uint8')
for i in range(256):
gamma_cvt[i][0] = 255 * (float(i)/255) ** (1.0/gamma)
query_img = cv2.imread('./img/query/img_camera1.png', 0)
query_img = cv2.LUT(query_img, gamma_cvt) # 変換部分
gamma=1.8で変換してみたところ,暗かった画像がこのようになりました.明らかに文字がはっきりしました.これでマッチングがうまくいきそうですね!

特徴点をとる
次は得られたカメラ画像とマップ画像で特徴点マッチングを行い,特徴点のペアを取り出します.
# AKAZE作成
akaze = cv2.AKAZE_create()
# 画像の拡大,縮小の割合
expand_query = 0.5
expand_map = 2
# クエリ画像を読み込んで特徴量計算
query_img = cv2.imread('./img/query/img_camera1.png', 0)
query_img = cv2.LUT(query_img, gamma_cvt) # gamma補正
query_img = cv2.resize(query_img, (int(query_img.shape[1] * expand_query),
int(query_img.shape[0] * expand_query)))
kp_query, des_query = akaze.detectAndCompute(query_img, None)
# マップ画像を読み込んで特徴量計算
map_img = cv2.imread('./img/map/field.png', 0)
map_img = cv2.resize(map_img, (int(map_img.shape[1] * expand_map),
int(map_img.shape[0] * expand_map)))
kp_map, des_map = akaze.detectAndCompute(map_img, None)
# 特徴量マッチング実行,k近傍法
bf = cv2.BFMatcher()
matches = bf.knnMatch(des_query, des_map, k=2)
取れる特徴点の数は画像の解像度に大きく依存するので,あらかじめ画像をリサイズしておきます.この時2枚の画像で漢字のサイズ感が合っている方がマッチングしやすいと思います(経験則).サイズを大きくすると特徴点は増えて嬉しい反面計算時間が増えるため,精度と時間のトレードオフになります.
matchesには特徴点のペアが入っているので,この中から有効なペアを選んで取り出します.
# 近傍点の第一候補と第二候補の差がある程度大きいものをgoodに追加
ratio = 0.8
good = []
for m, n in matches:
if m.distance < ratio * n.distance:
good.append([m])
# 対応点が1個以下なら相対関係を求められないのでNoneを返す
if len(good) <= 1:
print("[error] can't detect matching feature point")
return None, None, None
# 精度が高かったもののうちスコアが高いものから指定個取り出す
good = sorted(good, key=lambda x: x[0].distance)
print("valid point number: ", len(good))
# 上位何個の点をマッチングに使うか
point_num = 20
if len(good) < point_num:
point_num = len(good) # もし20個なかったら全て使う
# マッチング結果の描画
result_img = cv2.drawMatchesKnn(query_img, kp_query, map_img, kp_map, good[:point_num], None, flags=0)
img_matching = cv2.cvtColor(result_img, cv2.COLOR_BGR2RGB)
plt.imshow(img_matching)
plt.show()
マッチングではk近傍法(k=2)によって,候補点が2つずつ得られます.このうちまず最上位の候補と次の候補との差が小さいものは確信度が低いとして除きます.次に残った点のうち,第一候補の確信度が高いものを上から指定個(ここでは最大20個)選びます.これ以降は選んだ20個の点を使って計算していきます.
plotした結果は下のようになります.いくつかの線は正しい場所にマッチングされているのがわかります.ここは単純にAKAZEの実力.AKAZEってすごいんですね.
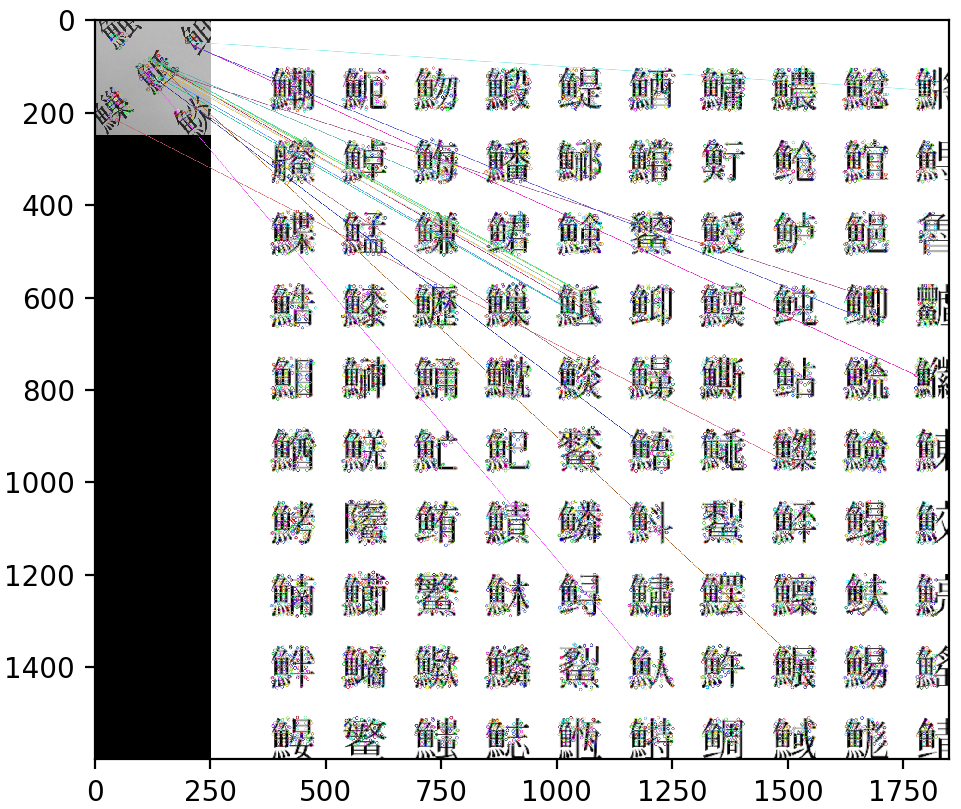
マッチングした点を選別する
マッチングできて終わりではありません.得られた特徴点のペアから位置と方向を特定します.この部分が本記事の頑強なマッチングの肝です.
上の画像を見ればわかるのですが,「鯳(すけとうだら)」という漢字に正しくマッチングされている線もある一方,間違えたマッチングをしている線もあります.なぜか.**だいたい全部魚へんが一緒だから.**どこもかしこも同じような漢字ばっかりです. 漢字の意味が分かればまだマシですが半分も読めません.すけとうだらって漢字があることも初めて知りました.こんなマップをマッチングさせること自体が鬼畜.
このような状況ではどれが正しいマッチングペアなのかを見極めることが必要になります.もし正しいペアを2組取り出すことができたなら,下の図のようにそれぞれの画像で2点の長さと角度を求め,そこから2つの画像のサイズ比と相対角度を算出することができます.
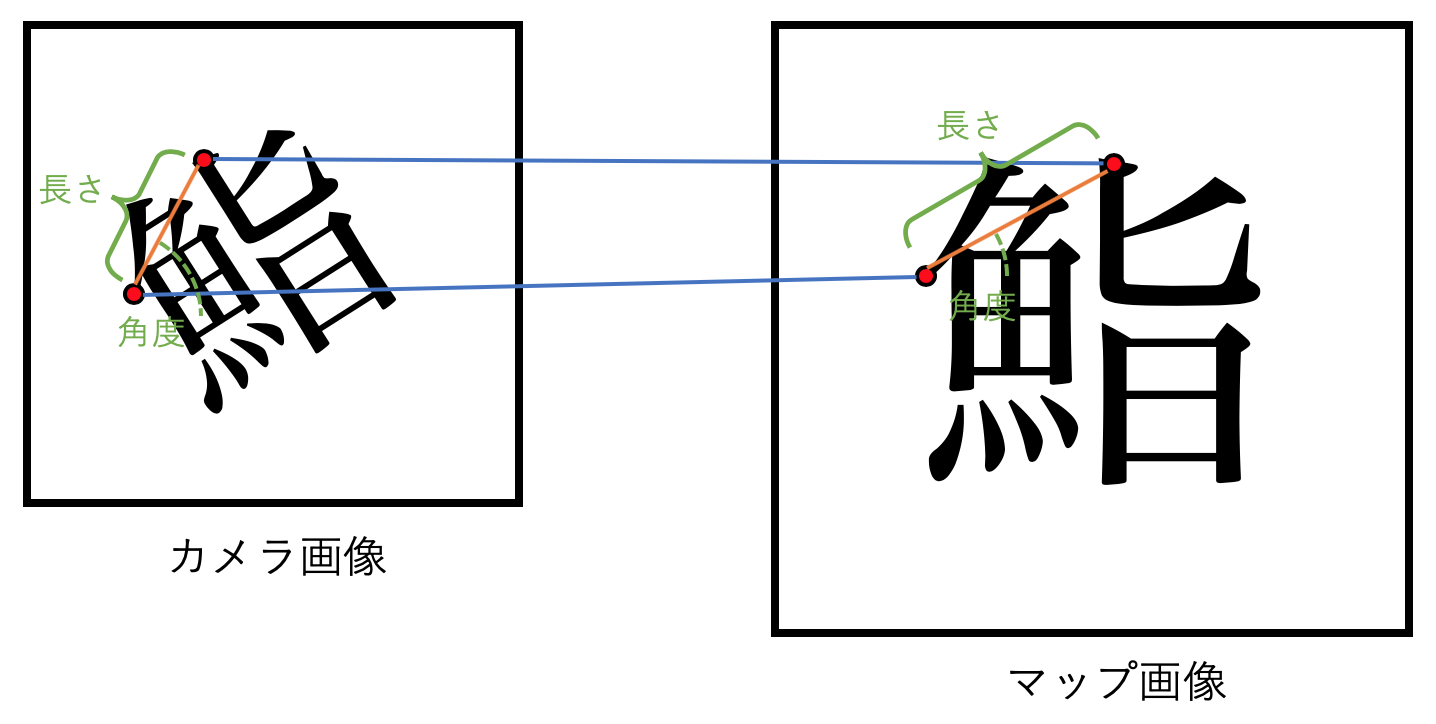
よってここでは各マッチング点のペアの組,全てについてサイズ比,相対角度を算出し,それの多数決を取ることにしました.最も多かったサイズ比,相対角度が正しい値だと推定するわけです.
# 点i, jの相対角度と相対長さを格納する配列
deg_cand = np.zeros((point_num, point_num))
len_cand = np.zeros((point_num, point_num))
# 全ての点のサイズ比,相対角度を求める
for i in range(point_num):
for j in range(i+1, point_num):
# クエリ画像から特徴点間の角度と距離を計算
q_x1, q_y1 = query_kp[i].pt
q_x2, q_y2 = query_kp[j].pt
q_deg = math.atan2(q_y2 - q_y1, q_x2 - q_x1) * 180 / math.pi
q_len = math.sqrt((q_x2 - q_x1) ** 2 + (q_y2 - q_y1) ** 2)
# マップ画像から特徴点間の角度と距離を計算
m_x1, m_y1 = map_kp[i].pt
m_x2, m_y2 = map_kp[j].pt
m_deg = math.atan2(m_y2 - m_y1, m_x2 - m_x1) * 180 / math.pi
m_len = math.sqrt((m_x2 - m_x1) ** 2 + (m_y2 - m_y1) ** 2)
# 2つの画像の相対角度と距離
deg_value = q_deg - m_deg
if deg_value < 0:
deg_value += 360
if m_len <= 0:
continue
size_rate = q_len/m_len
deg_cand[i][j] = deg_value
deg_cand[j][i] = deg_value
len_cand[i][j] = size_rate
len_cand[j][i] = size_rate
# 多数決を取る
# ある点iについて,j, kとの相対関係が一致するかを各jについて調べる
cand_count = np.zeros((point_num, point_num))
size_range_min = 0.3 # 明らかに違う比率の結果を弾く重要パラメータ
size_range_max = 3 # 明らかに違う比率の結果を弾く重要パラメータ
dif_range = 0.05 # 重要パラメータ
for i in range(len(deg_cand)):
for j in range(len(deg_cand)):
# 明らかに違う比率の結果を弾く
if len_cand[i][j] < size_range_min or len_cand[i][j] > size_range_max:
continue
for k in range(len(deg_cand)):
# 明らかに違う比率の結果を弾く
if len_cand[i][k] < size_range_min or len_cand[i][k] > size_range_max:
continue
# 誤差がある範囲以下の値なら同じ値とみなす
deg_dif = np.abs(deg_cand[i][k] - deg_cand[i][j])
size_dif = np.abs(len_cand[i][k] - len_cand[i][j])
if deg_dif <= deg_cand[i][j]*dif_range and size_dif <= len_cand[i][j]*dif_range:
cand_count[i][j] += 1
# print(cand_count)
# どの2点も同じ相対関係になかった場合
if np.max(cand_count) <= 1:
print("[error] no matching point pair")
return None, None, None
# もっとも多く相対関係が一致する2点を取ってくる
maxidx = np.unravel_index(np.argmax(cand_count), cand_count.shape)
deg_value = deg_cand[maxidx]
size_rate = len_cand[maxidx]
return deg_value, size_rate, maxidx[0], maxidx[1]
まずはじめに各マッチングペア $i, j$ から計算されるサイズ比,相対角度を全て格納します.
その後各 $i, j$ の値について,それと一致する値をもつ別の組が何個あるかを数えます.
一致する個数が一番多かったペアが多数決で一番もっともらしい相対関係だと言えるので,それをmaxidxとして取り出し,deg_value(相対角度),size_rate(サイズ比)を返します.
なお事前に大まかなサイズ比がわかっているなら,size_range_min,size_range_maxで明らかに違う値を除くことができます(サイズ比だけでなく角度も同様に除くことはできますが,今回は角度は360度あらゆる値を取り得たので,制約はつけていません.)
またサイズ比や相対角度はそれぞれの組で完全一致することはほとんどなく,同じ位置関係でも僅かに違う値が出てくることがほとんどです.なのでここでは誤差がdif_rangeで定めた範囲以下なら一致しているとカウントしました.
この方法を使うと,間違ったマッチングをしている点が多くあったとしても,正しくマッチングされている点がいくつかあれば正しくサイズ比と相対角度を得ることができます.間違った点同士はそれぞれの相対位置関係が一致することがほとんどないからです.
なお,for文の3重ループを使っているので実装がスマートじゃないと怒られそうですが,たかだか20個ほどの要素のループなので時間ロスはほとんどありません.
位置と方向を特定する
ここまでで
- 2つの画像のサイズ比
- 2つの画像の相対角度
- 正しくマッチしている点のペア
が得られました.ここからカメラ画像の位置と方向を求めます.
# クエリ画像の1点目とクエリ画像の中心の相対的な関係
q_x1, q_y1 = query_kp[m1].pt
m_x1, m_y1 = map_kp[m2].pt
q_xcenter = int(width_query/2)
q_ycenter = int(height_query/2)
q_center_deg = math.atan2(q_ycenter - q_y1, q_xcenter - q_x1) * 180 / math.pi
q_center_len = math.sqrt((q_xcenter - q_x1) ** 2 + (q_ycenter - q_y1) ** 2)
# 上の関係をマップ画像上のパラメータに変換
m_center_deg = q_center_deg - deg_value
m_center_len = q_center_len/size_rate
# 中心点のマップ画像上での位置
m_center_rad = m_center_deg * math.pi / 180
m_xcenter = m_x1 + m_center_len * math.cos(m_center_rad)
m_ycenter = m_y1 + m_center_len * math.sin(m_center_rad)
# 算出された値が正しい座標範囲に入っているかどうか
if (m_xcenter < 0) or (m_xcenter > width_map):
print("[error] invalid x value")
return None, None, None
if (m_ycenter < 0) or (m_ycenter > height_map):
print("[error] invalid y value")
return None, None, None
if (deg_value < 0) or (deg_value > 360):
print("[error] invalid deg value")
return None, None, None
x_current = int(m_xcenter/expand_map)
y_current = int(m_ycenter/expand_map)
drc_current = deg_value
# 最終結果
print('*****detection scceeded!*****')
print("final output score-> x: {}, y: {}, drc: {}".format(x_current, y_current, drc_current))
前半では,正しくマッチングされた点の情報を元に,カメラ画像の中心座標がマップ画像でどこにあたるかを計算しています.単純に並行移動している感じです.
そして計算された座標がmapのサイズに収まっていることを確認し,最後に拡大した倍率で割って最終的な出力を出します.
最終的な描画は冒頭にも載せましたがこのようになりました.赤い丸が中心,矢印が向きです.間違ったマッチング線があってもぴったり検出できています.また全体が暗い画像やピンボケした画像に対してもかなり頑強にマッチングすることができます.

まとめ
魚へんの漢字が多数描かれたマップから,カメラ画像の場所を特定する方法を解説してきました.似たような漢字が多数出てくるマップにおいても正確に場所と向きを検出できたので,タイトルに恥じない内容になったのではないかと思います.
他のカメラ画像で試したい場合はこちらに画像が置いてありますので,実際にコードを動かして性能を確認してみてください!