はじめに
「推薦システム実践入門」を読んだ。サンプルコードを実行したが、いくつか疑問に思う点があったので、検証を実施する
- 問い1: ユーザー間型協調フィルタリング(UMCF)が人気順を上回るのはどのような状況においてか
- 背景: 提供されたサンプルコードにおける結果では、 人気順の精度がUMCFを上回っていた。これはデータがスパースであること/UMCFのパラメータが主な要因と考えられるが、実際にどのようなデータ/UMCFのパラメータ設定なら、UMCFが人気順を上回るのかを検証したい
- 問い2: Matrix Factorization(MF)→ Factorization Machines(FM)にすることによる精度向上は、データによってどう変わるか
- 背景: サンプルコードでは、MFとFMの性能が大差なかった(自分の実行環境におけるものなので参考)が、どんなデータであればよりFMが活躍するのかを明らかにする
データ
train/test 分割
各ユーザーの評価を時系列でソートし、直近20件をtestセット、それ以前をtrainセットとした。testセットのうち評価値が4.0以上の映画を「正解アイテム」として扱う
ユーザーサンプリング(2パターン)
仮説1の検証には、行動ログ量の影響を比較するため2パターン(ランダム300人,アクティブ300人)のユーザー集合を用意した。
仮説2については、アクティブ300人のユーザー集合を用いて検証する。
| パターン | 抽出方法 | 目的 |
|---|---|---|
| ランダム300人 | 全ユーザーからランダムサンプリング(random_state=42) |
行動ログが少ないユーザーを含むベースライン |
| アクティブ300人 | 評価数で降順ソートし上位300人 | 行動ログが十分なユーザーのみ |
評価指標
$\mathrm{MAP@K}(\mathrm{K}=10)$ を用いる。
ユーザー $u$ に対する Average Precision は次式で定義される。
$$\mathrm{AP@K}(u) = \frac{1}{\min(|R_u|, K)} \sum_{k=1}^{K} P@k(u) \cdot \mathbb{1}[\text{item}_k \in R_u]$$
ここで $R_u$ はユーザー $u$ の正解アイテム集合、$P@k(u)$ は上位 $k$ 件におけるPrecision(適合率)、$\mathbb{1}[\cdot]$ は指示関数である。
全ユーザーの平均を取ったものが MAP@K である。
$$\mathrm{MAP@K} = \frac{1}{|U|} \sum_{u \in U} \mathrm{AP@K}(u)$$
MAP@K は順序を考慮した指標であり、正解アイテムが上位に来るほど高い値を示す。(サンプルコードではPrecision@K, Recall@Kを算出しており、これらは順序を考慮しない指標であった)
手法
人気順(ベースライン)
- trainセットにおける平均評価が高い映画を、各ユーザーが未評価のものから順に推薦する
ユーザー間型協調フィルタリング(UMCF)
対象ユーザー $u$ と類似した他ユーザー $v$ の評価をもとに、未評価映画の評価値を予測する。
類似度にはピアソン相関係数を用いる。
$$\rho_{uv} = \frac{\sum_{i \in I_{uv}} (r_{ui} - \bar{r}u)(r{vi} - \bar{r}v)}{\sqrt{\sum{i \in I_{uv}} (r_{ui} - \bar{r}u)^2} \cdot \sqrt{\sum{i \in I_{uv}} (r_{vi} - \bar{r}_v)^2}}$$
$I_{uv}$ はユーザー $u$ と $v$ が共通して評価したアイテム集合、$\bar{r}_u$ はユーザー $u$ の平均評価値である。
評価値の予測は、類似ユーザーの評価値の加重平均で行う。
$$\hat{r}{ui} = \bar{r}u + \frac{\sum{v \in N(u)} \rho{uv} (r_{vi} - \bar{r}v)}{\sum{v \in N(u)} |\rho_{uv}|}$$
実装には Surprise ライブラリの KNNWithMeans($k=30$)を使用した。
Matrix Factorization(MF)
ユーザー×映画の評価値行列 $R \in \mathbb{R}^{|U| \times |I|}$ を、潜在因子行列の積に分解する。
$$R \approx P Q^\top, \quad P \in \mathbb{R}^{|U| \times d}, \quad Q \in \mathbb{R}^{|I| \times d}$$
ユーザー $u$ の映画 $i$ に対する予測評価値は次式で計算される。
$$\hat{r}_{ui} = \mathbf{p}_u^\top \mathbf{q}_i$$
Surprise ライブラリの SVD(名前は SVD だが実体は MF)を使用し、因子数 $d=5$、学習率 $0.005$、50エポックで学習する。評価数が100件未満の映画はフィルタリングする。
Factorization Machines(FM)
FM は特徴量ベクトル $\mathbf{x} \in \mathbb{R}^n$ を入力として、次式で予測値を計算する。
$$\hat{y}(\mathbf{x}) = w_0 + \sum_{j=1}^{n} w_j x_j + \sum_{j=1}^{n} \sum_{j'=j+1}^{n} \langle \mathbf{v}j, \mathbf{v}{j'} \rangle x_j x_{j'}$$
$w_0$ は全体バイアス、$w_j$ は各特徴量の重み、$\mathbf{v}j \in \mathbb{R}^k$ は各特徴量の潜在ベクトルである。交互作用項 $\langle \mathbf{v}j, \mathbf{v}{j'} \rangle x_j x{j'}$ を効率的に計算できるため、スパースな特徴量に対して有効に機能する。
ユーザーIDと映画ID以外の補助情報を特徴量に加えられる点もメリットだが、今回は交互作用の有無のみに着目する。
本実験ではこれをNumPyでスクラッチ実装した。
結果・考察
問い1: 協調フィルタリング vs 人気順
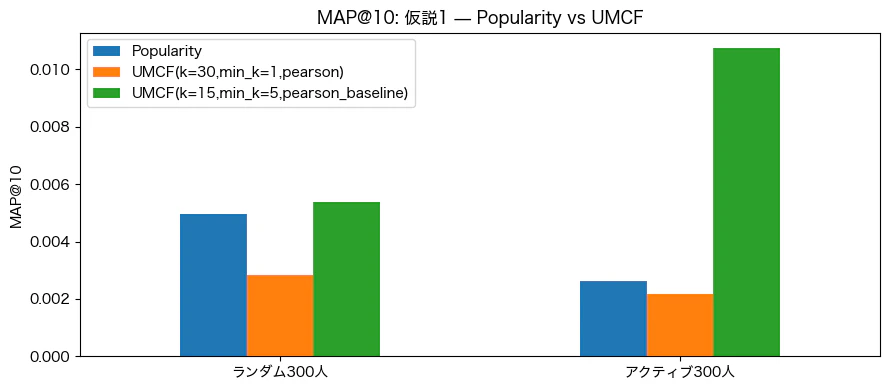
- UMCFのデフォルトパラメータ(オレンジ)では、ランダムなユーザー抽出でもアクティブに絞ったユーザー抽出でも、どちらも人気順(青)を下回る結果となった
- UMCFのパラメータに改善余地があると考え、以下の変更を実施した
-
k: 評価値の推定に使うユーザーの人数- 30→15
- 相関が低いユーザーはノイズになる可能性があるため、類似ユーザーの数を減らしてみた
-
min_k: 評価値の推定に使うユーザーの最低人数- 1→5
- 類似ユーザーが少ない場合の予測は不安定になる可能性があるため、最低人数を増やしてみた
-
sim_options.name: ピアソン相関係数の算出方法-
pearson: ユーザーごとの平均評価値を引いてから相関係数を計算する方法 - →
pearson_baseline: ユーザーとアイテムのバイアスを考慮してから相関係数を計算する方法
-
-
- 結果として、ランダムでは人気順と同程度の精度、アクティブでは人気順を大きく上回る精度となった
- 協調フィルタリングは、スパースなデータでは工夫しても難しいが、ある程度値が埋まっている評価値行列では、パラメータの調整しだいで単純なルールベースを大きく上回ることが可能
問い2: MF vs FM(ランダム300人・アクティブ300人)
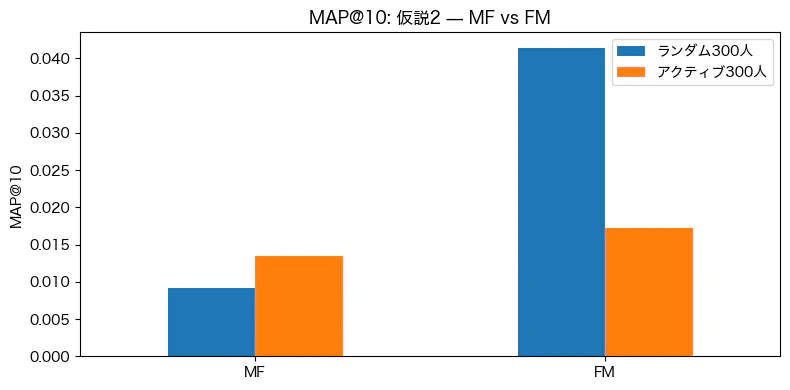
- ランダム300人では、MF→FMにすることによる精度の増加が大きかったが、アクティブ300人では小さかった
- 仮説として、アクティブユーザーは各ユーザーが積極的に評価をしている分各ユーザーの好みがはっきりしており、評価の分布が偏っている(高評価に集中するなど)可能性があり、モデルが汎化しにくかった可能性がある
まとめ
本稿では MovieLens-10M を用いて、推薦アルゴリズムの精度比較を行った。
-
仮説1: デフォルトパラメータの UMCF はランダム・アクティブのいずれのユーザー集合でも人気順を下回った。パラメータを
k=15, min_k=5, pearson_baselineに変更したところ、アクティブ300人において UMCFが人気順を大きく上回り、行動ログが十分なユーザーに絞ることで協調フィルタリングが有効に機能することが確認された。 - 仮説2: ランダム300人では MF→FMで大きな改善幅があった。一方でアクティブ300人において、MF(0.0130)→FM(0.0156)と改善幅が小さかった。よりスパースなデータで、交互作用項を考慮するFMの優位性が高いことが示唆された。ただ、よりFMの精度をランダムとアクティブで比べた際に、ランダムの方が高い理由は定かではない。
参考文献
- 風間正弘、飯塚洸二郎、松村優也. 2022. 推薦システム実践入門―仕事で使える導入ガイド. O'Reilly Japan.
サンプルコード
MAP@K
def average_precision_at_k(true_items, pred_items, k):
if not true_items:
return 0.0
true_set = set(true_items)
hits, score = 0, 0.0
for i, item in enumerate(pred_items[:k], 1):
if item in true_set:
hits += 1
score += hits / i
return score / min(len(true_items), k)
def map_at_k(true_user2items, pred_user2items, k=10):
scores = [average_precision_at_k(true_user2items.get(u, []), pred_user2items.get(u, []), k)
for u in true_user2items]
return float(np.mean(scores))
UMCF
from surprise import KNNWithMeans, Reader
from surprise import Dataset as SurpriseDataset
class UMCFRecommender(BaseRecommender):
def recommend(self, dataset, **kwargs):
reader = Reader(rating_scale=(0.5, 5))
data_train = SurpriseDataset.load_from_df(
dataset.train[["user_id", "movie_id", "rating"]], reader
).build_full_trainset()
sim_options = {
"name": kwargs.get("sim_name", "pearson"),
"user_based": True,
"shrinkage": kwargs.get("shrinkage", 100),
}
knn = KNNWithMeans(k=kwargs.get("k", 30), min_k=kwargs.get("min_k", 1),
sim_options=sim_options)
knn.fit(data_train)
predictions = knn.test(data_train.build_anti_testset(None))
top_n = defaultdict(list)
for uid, iid, _, est, _ in predictions:
top_n[uid].append((iid, est))
pred_user2items = {
uid: [iid for iid, _ in sorted(items, key=lambda x: -x[1])[:10]]
for uid, items in top_n.items()
}
return RecommendResult(pred_user2items=pred_user2items)
FM(notebooks/fm.py)
import numpy as np
from scipy.sparse import csr_matrix
from sklearn.feature_extraction import DictVectorizer
class _FMModel:
def __init__(self, k=10, lr=0.01, reg=0.01, n_epochs=20, batch_size=512):
self.k, self.lr, self.reg = k, lr, reg
self.n_epochs, self.batch_size = n_epochs, batch_size
def fit(self, X, y):
n, p = X.shape
self.w0 = 0.0
self.w = np.zeros(p)
self.V = np.random.normal(0, 0.01, (p, self.k))
for epoch in range(self.n_epochs):
perm = np.random.permutation(n)
total_loss = 0.0
for start in range(0, n, self.batch_size):
idx = perm[start:start + self.batch_size]
Xb, yb = X[idx].toarray(), y[idx]
xv = Xb @ self.V
xv2 = (Xb ** 2) @ (self.V ** 2)
y_hat = self.w0 + Xb @ self.w + 0.5 * np.sum(xv ** 2 - xv2, axis=1)
err = y_hat - yb
total_loss += np.sum(err ** 2)
b = len(idx)
self.w0 -= self.lr * err.mean()
self.w -= self.lr * (Xb.T @ err / b + self.reg * self.w)
Xe2_err = ((Xb ** 2) * err[:, None]).sum(axis=0)
grad_V = (Xb.T @ (err[:, None] * xv) - Xe2_err[:, None] * self.V) / b
self.V -= self.lr * (grad_V + self.reg * self.V)
def predict_sparse(self, X):
XV = X.dot(self.V)
X2V2 = X.power(2).dot(self.V ** 2)
return self.w0 + X.dot(self.w) + 0.5 * np.sum(XV ** 2 - X2V2, axis=1)
class FMRecommender(BaseRecommender):
def recommend(self, dataset, **kwargs):
use_side = kwargs.get("use_side_information", False)
min_rating = kwargs.get("minimum_num_rating", 200)
movie_counts = dataset.train.groupby("movie_id").size()
filtered = dataset.train[dataset.train.movie_id.isin(
movie_counts[movie_counts >= min_rating].index)]
user_avg = filtered.groupby("user_id")["rating"].mean().to_dict()
user_evaluated = filtered.groupby("user_id")["movie_id"].apply(list).to_dict()
tags = filtered["tag"].tolist() if "tag" in filtered.columns else [None] * len(filtered)
def make_dict(uid, mid, tag=None):
d = {"user_id": str(uid), "movie_id": str(mid)}
if use_side:
d["tag"] = " ".join(str(t) for t in tag) if isinstance(tag, list) else ""
d["user_rating_avg"] = str(round(user_avg.get(uid, 3.0), 1))
return d
train_dicts = [make_dict(u, m, t) for u, m, t in
zip(filtered["user_id"], filtered["movie_id"], tags)]
vectorizer = DictVectorizer()
X_train = vectorizer.fit_transform(train_dicts)
fm = _FMModel(k=kwargs.get("factors", 10), lr=kwargs.get("lr", 0.01),
n_epochs=kwargs.get("n_epochs", 20), batch_size=kwargs.get("batch_size", 512))
fm.fit(X_train, filtered["rating"].to_numpy())
unique_users = sorted(filtered.user_id.unique())
unique_movies = sorted(filtered.movie_id.unique())
mid_strs = [str(m) for m in unique_movies]
content_map = (dataset.item_content.set_index("movie_id")["tag"].to_dict()
if use_side else {})
pred_user2items = defaultdict(list)
for user_id in unique_users:
uid_str = str(user_id)
if use_side:
avg_str = str(round(user_avg.get(user_id, 3.0), 1))
row_dicts = [{"user_id": uid_str, "movie_id": ms,
"tag": " ".join(str(t) for t in content_map.get(int(ms), [])),
"user_rating_avg": avg_str} for ms in mid_strs]
else:
row_dicts = [{"user_id": uid_str, "movie_id": ms} for ms in mid_strs]
scores = fm.predict_sparse(vectorizer.transform(row_dicts))
evaluated = set(user_evaluated.get(user_id, []))
for mi in np.argsort(-scores):
if unique_movies[mi] not in evaluated:
pred_user2items[user_id].append(unique_movies[mi])
if len(pred_user2items[user_id]) == 10:
break
return RecommendResult(pred_user2items=pred_user2items)
実験ノートブック
from notebooks.data_loader import DataLoader
from src.popularity import PopularityRecommender
from src.umcf import UMCFRecommender
from src.mf import MFRecommender
from notebooks.fm import FMRecommender
DATA_PATH = "../chapter5/data/ml-10M100K/"
CACHE_PATH = "../data/cache/"
ds_random = DataLoader(num_users=300, num_test_items=20, data_path=DATA_PATH,
cache_path=CACHE_PATH, random_state=42, sampling="random").load()
ds_active = DataLoader(num_users=300, num_test_items=20, data_path=DATA_PATH,
cache_path=CACHE_PATH, sampling="active").load()
# 仮説1: Popularity vs UMCF
sim_pb = {"name": "pearson_baseline", "user_based": True, "shrinkage": 100}
df1 = pd.DataFrame({
"Popularity": [map_at_k(ds.test_user2items, PopularityRecommender().recommend(ds, minimum_num_rating=10).user2items) for ds in [ds_random, ds_active]],
"UMCF(k=30,min_k=1,pearson)": [map_at_k(ds.test_user2items, UMCFRecommender().recommend(ds).user2items) for ds in [ds_random, ds_active]],
"UMCF(k=15,min_k=5,pearson_baseline)": [map_at_k(ds.test_user2items, UMCFRecommender().recommend(ds, k=15, min_k=5, sim_options=sim_pb).user2items) for ds in [ds_random, ds_active]],
}, index=["ランダム300人", "アクティブ300人"])
# 仮説2: MF vs FM
df2 = pd.DataFrame({
ds_label: [map_at_k(ds.test_user2items, rec.recommend(ds, minimum_num_rating=10).user2items)
for rec in [MFRecommender(),
FMRecommender(), # use_side_information=False
FMRecommender()]] # use_side_information=True (別途呼び出し)
for ds_label, ds in [("ランダム300人", ds_random), ("アクティブ300人", ds_active)]
}, index=["MF", "FM", "FM+side"])