記事のゴール
本記事では、傾向スコアを用いた因果推論の実践的な手順を、Lalondeデータセットを題材に解説する。以下の2点を目標とする。多くは「効果検証入門:正しい比較のための因果推論/計量経済学の基礎」を参考にしたものだが、データの母集団が異なっており数値としては異なる結果になっている。
- 実務で傾向スコアを用いた分析を実施する際の注意点を理解する
- 傾向スコアを使うのに適した場面を理解する
データ
Lalondeデータセットとは
Lalondeデータセットは、1986年にRobert LaLondeが発表した論文で使用されたデータである。National Supported Work(NSW)プログラムという職業訓練プログラムの効果を検証するために収集された。
このデータの特徴は、ランダム化比較試験(RCT)による実験データと、観察データの両方が含まれている点である。RCTの結果をベンチマークとして、観察データに対する各種因果推論手法の妥当性を検証できる。
分析に使用するデータ
本分析では、以下の2つのグループを使用する。
- NSW処置群(sample=1, treated=1): 職業訓練プログラムに参加した179名
- CPS比較群(sample=2): Current Population Survey(米国の雇用統計調査)から抽出された2,930名
RCTの対照群のデータは「手に入っていない」想定で分析を進める。つまり、観察データのみから因果効果を推定するという、実務で直面しやすい状況を再現している。
なお、re75(1975年の所得)の分布が処置群とCPS比較群で大きくことなり、傾向スコアによる調整が困難であったため、re75 < 2000 に限定した。
変数の定義
| 変数 | 説明 |
|---|---|
| treated | 処置変数(1 = プログラム参加、0 = 非参加) |
| age | 年齢(歳) |
| educ | 教育年数(年) |
| black | 人種ダミー(1 = 黒人) |
| hisp | ヒスパニック系ダミー |
| married | 結婚状況(1 = 既婚) |
| nodegree | 学位なしダミー(1 = 高卒資格なし) |
| re74 | 1974年の実質所得(ドル) |
| re75 | 1975年の実質所得(ドル) |
| re78 | 1978年の実質所得(ドル)― アウトカム変数 |
手法
傾向スコアとは
傾向スコアとは、各サンプルが「介入(処置)を受ける確率」を共変量から予測した値である。本分析では、ロジスティック回帰モデルを用いて推定した。
傾向スコアの利点は、多次元の共変量情報を1次元のスカラー値に集約できる点にある。これにより、処置群と対照群の比較可能性を直感的に評価・調整できる。
分析の前提条件
傾向スコアを用いた分析では、以下の2つの前提条件を確認する必要がある。
バランシングの確認
傾向スコアによる調整後に、共変量の分布が処置群と対照群で均衡しているかを確認する。指標としては標準化平均差(SMD) を用いる。
$$
SMD = \frac{\bar{X}{treat} - \bar{X}{control}}{\sqrt{(s^2_{treat} + s^2_{control})/2}}
$$
|SMD| < 0.1 であればバランスが良好とされることが多い。
共通サポート仮定(正値性)
すべてのサンプルについて、介入を受ける確率が 0 < e(x) < 1 であることが求められる。傾向スコアの分布を可視化し、処置群と対照群の両方にサンプルが存在する領域(共通サポート領域)を確認する。
3つの推定手法
傾向スコアをもとにした代表的な集計方法として、以下の3つを実施した。
1. マッチング
介入群の各個体に対して、傾向スコアが最も近い対照群の個体をペアとして割り当てる(1対1、復元なし)。ペアごとのアウトカムの差分の平均を効果とする。
介入群に対してマッチングを行うため、推定される効果量はATT(Average Treatment Effect on the Treated)、すなわち処置群における平均的な因果効果である。
2. 層別解析
傾向スコアを一定の区間(本分析では四分位)で層に分割し、各層内で処置群と対照群のアウトカムの平均差を算出する。各層の効果をサンプルサイズで加重平均することで、全体の効果を推定する。
推定される効果量はATE(Average Treatment Effect) である。
3. IPW(逆確率重み付け)
各サンプルに逆確率重みを付与し、処置群と対照群それぞれの重みつき平均の差を効果とする。
- 処置群の重み: $1 / e(x)$
- 対照群の重み: $1 / (1 - e(x))$
推定される効果量はATEである。
IPWの注意点として、傾向スコアが非常に小さい(0に近い)サンプルが存在する場合、そのサンプルの重みが極端に大きくなり、推定が不安定になるという問題がある。
結果
ベンチマーク: RCTによる真の効果
NSW実験データ(sample=1)の処置群と対照群の差分から、RCTによるATTを算出した。
ATT (RCT) = $1,535.53
これを真の因果効果のベンチマークとして使用する。
共変量のバランス(調整前)
調整前の標準化平均差を確認すると、多くの共変量でバランスが取れていないことがわかった。
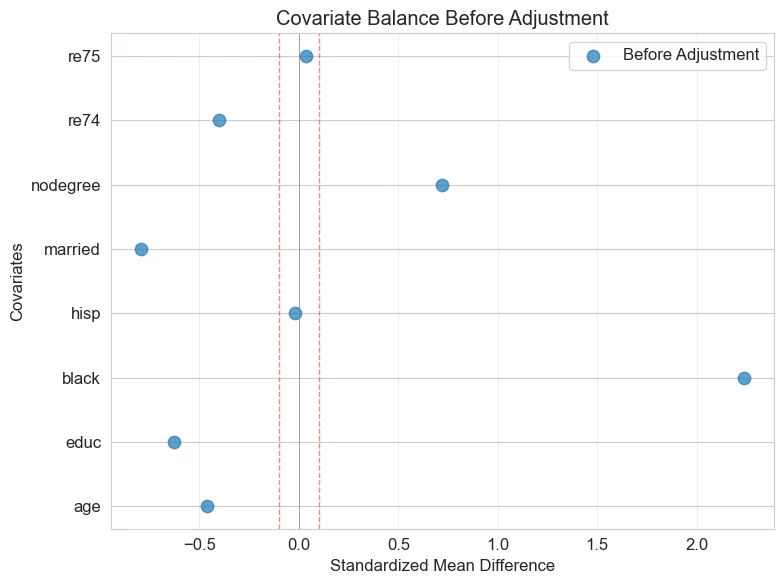
特に black(SMD = 2.24)や married(SMD = -0.79)で大きな不均衡が確認された。
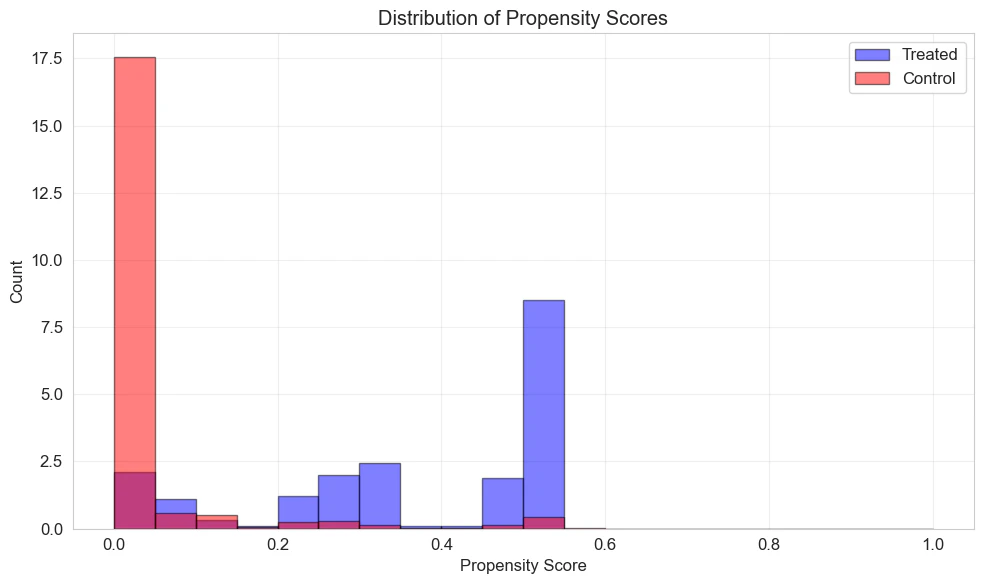
傾向スコアの推定結果
ロジスティック回帰モデルにより傾向スコアを推定した結果、処置群の傾向スコアの平均は0.358、対照群は0.039であった。
共通サポートの確認では、bin=0.05で分布を描いたところ、12区間中11区間で両群のサンプルが存在しており、概ね共通サポート仮定は問題ないと考える。(ただ、分布は大きくことなっている点は注意が必要)
バランシングの確認(IPW調整後)
IPW調整後のSMDを確認すると、一部の共変量ではバランスが改善されたが、age、nodegree、re74、re75 では依然として|SMD| > 0.1 であった。
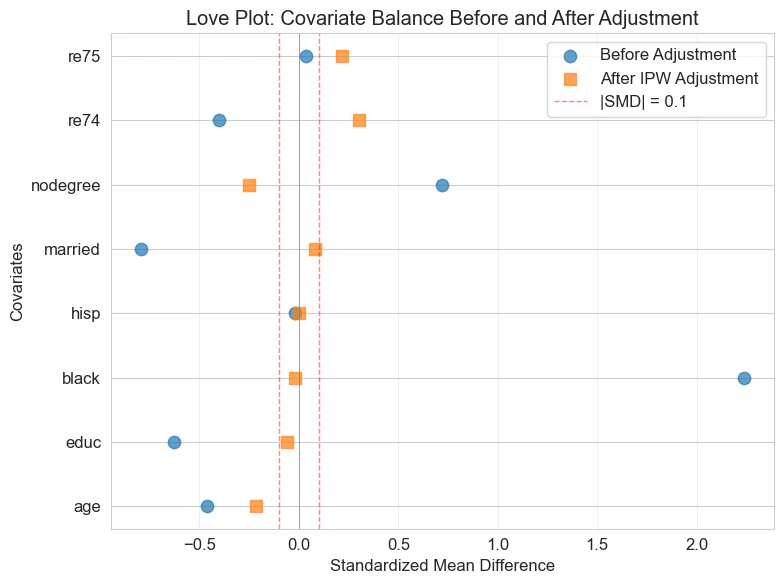
バランシングが十分でない共変量が残っている点には留意が必要である。
効果の推定結果
| 手法 | 推定対象 | 効果推定値 | RCTとの差 |
|---|---|---|---|
| RCT(ベンチマーク) | ATT | $1,535.53 | - |
| マッチング | ATT | $1,613.00 | +$77.46 |
| 層別解析 | ATE | $1,338.11 | -$197.42 |
| IPW | ATE | $289.42 | -$1,246.11 |
マッチングによるATTの推定値($1,613.00)は、RCTベンチマーク($1,535.53)に近い値を示した。層別解析も比較的近い推定値を得られた。
一方、IPWによるATEの推定値($289.42)はRCTから大きく乖離した。これは、IPWでは傾向スコアが小さいサンプルの重みが極端に大きくなる問題が影響していると考えられる。実際に、処置群のIPW重みの最大値は923.6に達しており、一部のサンプルの影響が過大になっていた。
感想
- 傾向スコアを用いた手法では、標準化平均差や共通サポートの確認など、直感的に「適切な効果検証になっているか」の判断がしやすい。回帰分析でも感度分析によって欠落変数バイアスの評価をする方法はあるが、傾向スコアの方が直感的に納得しやすいと感じた
- 傾向スコアを用いた手法の中でも、処置群における効果を知りたいか(ATT)、対照群における効果を知りたいか(ATC)、全体の効果を知りたいか(ATE)によって、適切な手法を選択すべきである
- ATEを求める場合には層別解析やIPWが考えられるが、IPWは傾向スコアが非常に小さくなるサンプルがある場合に推定が不安定になる点に留意が必要である