はじめに
SageMakerは機械学習のワークロード一式を提供するサービスです。S3などに格納されたデータを使用して、Jupyter notebookによるモデルの開発、Gitリポジトリによるコードの管理、トレーニングジョブの作成、推論エンドポイントのホストといった機械学習プロジェクトに必要な機能が一通り提供されています。
Amazon Web Services ブログの「TorchServe を使用した大規模な推論のための PyTorch モデルをデプロイする」を読んでAmazon SageMakerを使用してモデルをホストしてみました。以下では手順とその周辺の話を紹介します。
モデルの変換部分についてはこちらの記事にも書きましので御覧ください。
手順
S3バケットの作成
まず、S3でバケットを作成します。今回はtorchserve-modelという名前のバケットを作成しました。リージョンは「アジアパシフィック(東京)」で、名前以外は全てデフォルトです。
ノートブックインスタンス作成
Amazon SageMakerのコンソールを開くと左のペインにメニューがあることがわかります。
ノートブックメニューから[ノートブックインスタンス]を選択し、[ノートブックインスタンスの作成]をクリックします。インスタンスの設定は下記項目を設定し、その他はデフォルトとします。
- ノートブックインスタンス設定
- ノートブックインスタンス名: sagemaker-sample
- アクセス許可と暗号化
- IAM ロール: 新しいロールの作成
IAM ロール作成画面では、先程作成したS3バケットを指定します。

設定を入力したら[ノートブックインスタンスの作成]をクリックします。ノートブックインスタンス画面に戻るので、作成したインスタンスの名前をクリックすると、詳細画面に入れます。IAM ロール ARNのリンクから、IAM画面を開き、「ポリシーをアタッチします」をクリック、「AmazonEC2ContainerRegistryFullAccess」ポリシーをアタッチします。これは後ほど、ECRを操作するために必要なポリシーです。
ステータスがIn serviceになったら「JupyterLab を開く」でJupyterLabを立ち上げます。
まず、LaucherのOtherからTerminalを起動します。
sh-4.2$ ls
anaconda3 Nvidia_Cloud_EULA.pdf sample-notebooks tools
examples README sample-notebooks-1594876987 tutorials
LICENSE SageMaker src
sh-4.2$ ls SageMaker/
lost+found
画面左のエクスプローラはSageMaker/以下のファイルを表示しています。

gitもインストールされています。
sh-4.2$ git --version
git version 2.14.5
以下ではノートブックを作成し、モデルをホストしていきますが、同様のことをチュートリアルノートブックでも実行できます。SageMaker/でサンプルコードをクローンすればよいです。
sh-4.2$ cd SageMaker
sh-4.2$ git clone https://github.com/shashankprasanna/torchserve-examples.git
deploy_torchserve.ipynbに手順が全て記載してあります。ノートブックを開く際は、使用するPythonのカーネルを聞かれるので、conda_pytorch_p36を選択します。
モデルのホスト
まず、左のペインのフォルダのボタンからフォルダを新規作成し、ダブルクリックして作成したフォルダに入ります。
次にノートブックを作成します。

conda_pytorch_p36のノートブックを選択します。ノートブック名をdeploy_torchserve.ipynbにリネームしておきます。
セルでPytorchモデルをデプロイ用に変換するライブラリのインストールを実行します。
!git clone https://github.com/pytorch/serve.git
!pip install serve/model-archiver/
今回はdensenet161モデルをホストします。学習済みの重みファイルをダウンロードします。また、先ほどクローンしたライブラリにサンプルモデルクラスが入っているので、重みファイルとクラスを使用して、ホストする形式に変換します。
!wget -q https://download.pytorch.org/models/densenet161-8d451a50.pth
model_file_name = 'densenet161'
!torch-model-archiver --model-name {model_file_name} \
--version 1.0 --model-file serve/examples/image_classifier/densenet_161/model.py \
--serialized-file densenet161-8d451a50.pth \
--extra-files serve/examples/image_classifier/index_to_name.json \
--handler image_classifier
実行すると、カレントディレクトリにdensenet161.marが出力されます。
作成したファイルをS3に格納します。
# boto3 セッションを作成し、リージョンとアカウント情報を取得します
import boto3, time, json
sess = boto3.Session()
sm = sess.client('sagemaker')
region = sess.region_name
account = boto3.client('sts').get_caller_identity().get('Account')
import sagemaker
role = sagemaker.get_execution_role()
sagemaker_session = sagemaker.Session(boto_session=sess)
# ちなみに中身は次のような感じになっています。
# print(region, account, role)
# ap-northeast-1
# xxxxxxxxxxxx
# arn:aws:iam::xxxxxxxxxxxx:role/service-role/AmazonSageMaker-ExecutionRole-20200716T140377
# Amazon SageMaker S3 バケット名を指定します
bucket_name = 'torchserve-model'
prefix = 'torchserve'
# print(bucket_name, prefix)
# sagemaker-ap-northeast-1-xxxxxxxxxxxx torchserve
# Amazon SageMaker はモデルが tar.gz ファイルにあると想定しているため、densenet161.mar ファイルから圧縮 tar.gz ファイルを作成します。
!tar cvfz {model_file_name}.tar.gz densenet161.mar
# モデルのディレクトリの下の S3 バケットにモデルをアップロードします。
!aws s3 cp {model_file_name}.tar.gz s3://{bucket_name}/{prefix}/models/
次に、ECRでコンテナレジストリを作成します。
registry_name = 'torchserve'
!aws ecr create-repository --repository-name torchserve
# {
# "repository": {
# "repositoryArn": "arn:aws:ecr:ap-northeast-1:xxxxxxxxxxxx:repository/torchserve",
# "registryId": "xxxxxxxxxxxx:repository",
# "repositoryName": "torchserve",
# "repositoryUri": "xxxxxxxxxxxx:repository.dkr.ecr.ap-northeast-1.amazonaws.com/torchserve",
# "createdAt": 1594893256.0,
# "imageTagMutability": "MUTABLE",
# "imageScanningConfiguration": {
# "scanOnPush": false
# }
# }
# }
一旦ノートブックから離れ、左のペインの「+」ボタンをクリック、Launcherから「Text File」を選択し、Dockerfileを作成します。
FROM ubuntu:18.04
ENV PYTHONUNBUFFERED TRUE
RUN apt-get update && \
DEBIAN_FRONTEND=noninteractive apt-get install --no-install-recommends -y \
fakeroot \
ca-certificates \
dpkg-dev \
g++ \
python3-dev \
openjdk-11-jdk \
curl \
vim \
&& rm -rf /var/lib/apt/lists/* \
&& cd /tmp \
&& curl -O https://bootstrap.pypa.io/get-pip.py \
&& python3 get-pip.py
RUN update-alternatives --install /usr/bin/python python /usr/bin/python3 1
RUN update-alternatives --install /usr/local/bin/pip pip /usr/local/bin/pip3 1
RUN pip install --no-cache-dir psutil \
--no-cache-dir torch \
--no-cache-dir torchvision
ADD serve serve
RUN pip install ../serve/
COPY dockerd-entrypoint.sh /usr/local/bin/dockerd-entrypoint.sh
RUN chmod +x /usr/local/bin/dockerd-entrypoint.sh
RUN mkdir -p /home/model-server/ && mkdir -p /home/model-server/tmp
COPY config.properties /home/model-server/config.properties
WORKDIR /home/model-server
ENV TEMP=/home/model-server/tmp
ENTRYPOINT ["/usr/local/bin/dockerd-entrypoint.sh"]
CMD ["serve"]
Dockerfikeの中身については下記のような設定がされています。
-
PYTHONUNBUFFERED TRUEはstdoutとstderrがバッファリングをしないようにしています。 -
DEBIAN_FRONTEND=noninteractiveとするとインタラクティブな設定をしなくなります。 -
--no-install-recommendsは必須でない、推奨パッケージのインストールをしないようにします。 -
update-alternativesは使用するPythonとpipの優先度を変更しています。
同様にdockerd-entrypoint.shとconfig.propertiesも作成します。
# !/bin/bash
set -e
if [[ "$1" = "serve" ]]; then
shift 1
printenv
ls /opt
torchserve --start --ts-config /home/model-server/config.properties
else
eval "$@"
fi
# prevent docker exit
tail -f /dev/null
シェルスクリプトについては下記のようなコードが書かれています。
-
set -e: エラーがあったらシェルスクリプトをそこで打ち止めにしてくれます。 -
$1: 1つ目の引数です。 -
shift 1: 引数の順番をずらします。こうすると次のコマンドにあたかも最初から与えられたかのように引数を渡せます。 -
printenv: 環境変数の内容を表示します。 ※後に紹介するCloudWatch logsに出力されます。 -
eval "$@": 引数をコマンドとして展開し、そのコマンドを実行します。serve以外のコマンドを実行するときに使用します。 -
tail -f /dev/null: コンテナを起動したままにするための、ダミー的なコマンドです。
inference_address=http://0.0.0.0:8080
management_address=http://0.0.0.0:8081
number_of_netty_threads=32
job_queue_size=1000
model_store=/opt/ml/model
load_models=all
設定について補足です。詳細はこちらを参照してください。
-
number_of_netty_threads: フロントエンドの全体スレッド数で、デフォルトはJVMで利用可能な論理プロセッサの数。 -
job_queue_size: バックエンドがサービスを提供する前にフロントエンドがキューに入れる推論ジョブの数、デフォルトは100。 -
model_store: モデルの格納場所。 ※SageMakerを使用する場合は/opt/ml/model/にS3からモデルが格納されます。 -
load_models: 起動時の–modelsと同じ効果。デプロイするモデルを指定する。allのときはmodel_storeに格納されているモデルを全てデプロイする。
コンテナイメージを作成し、レジストリに格納します。v1はイメージのタグ、imageはタグまで含めたイメージ名です。ECRを利用する場合、<レジストリ名>/<イメージ名>:<タグ>の規則でイメージ名を付けます。<レジストリ名>はレジストリを作成したときの戻り値のrepositoryUriに一致します。
ビルドには15分くらいかかりました。
image_label = 'v1'
image = f'{account}.dkr.ecr.{region}.amazonaws.com/{registry_name}:{image_label}'
# print(image_label, image)
# v1 xxxxxxxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com/torchserve:v1
!docker build -t {registry_name}:{image_label} .
!$(aws ecr get-login --no-include-email --region {region})
!docker tag {registry_name}:{image_label} {image}
!docker push {image}
# Sending build context to Docker daemon 399.7MB
# Step 1/16 : FROM ubuntu:18.04
# 18.04: Pulling from library/ubuntu
# 5296b23d: Pulling fs layer
# 2a4a0f38: Pulling fs layer
# ...
# 9d6bc5ec: Preparing
# 0faa4f76: Pushed 1.503GB/1.499GBv1: digest:
# sha256:bb75ec50d8b0eaeea67f24ce072bce8b70262b99a826e808c35882619d093b4e size: 3247
いよいよ推論エンドポイントをホストします。次のコードでデプロイするモデルを作成します。
import sagemaker
from sagemaker.model import Model
from sagemaker.predictor import RealTimePredictor
role = sagemaker.get_execution_role()
model_data = f's3://{bucket_name}/{prefix}/models/{model_file_name}.tar.gz'
sm_model_name = 'torchserve-densenet161'
torchserve_model = Model(model_data = model_data,
image = image,
role = role,
predictor_cls=RealTimePredictor,
name = sm_model_name)
次のコードでエンドポイントをデプロイします。デプロイには5分ほどかかりました。
endpoint_name = 'torchserve-endpoint-' + time.strftime("%Y-%m-%d-%H-%M-%S", time.gmtime())
predictor = torchserve_model.deploy(instance_type='ml.m4.xlarge',
initial_instance_count=1,
endpoint_name = endpoint_name)
デプロイの経過はCloud Watch logsで見ることが出来ます。Cloud Watchのコンソールを開いて、左ペインの[ロググループ]をクリックし、検索バーに/aws/sagemaker/Endpointsと入力するとエンドポイントの一覧を表示できます。
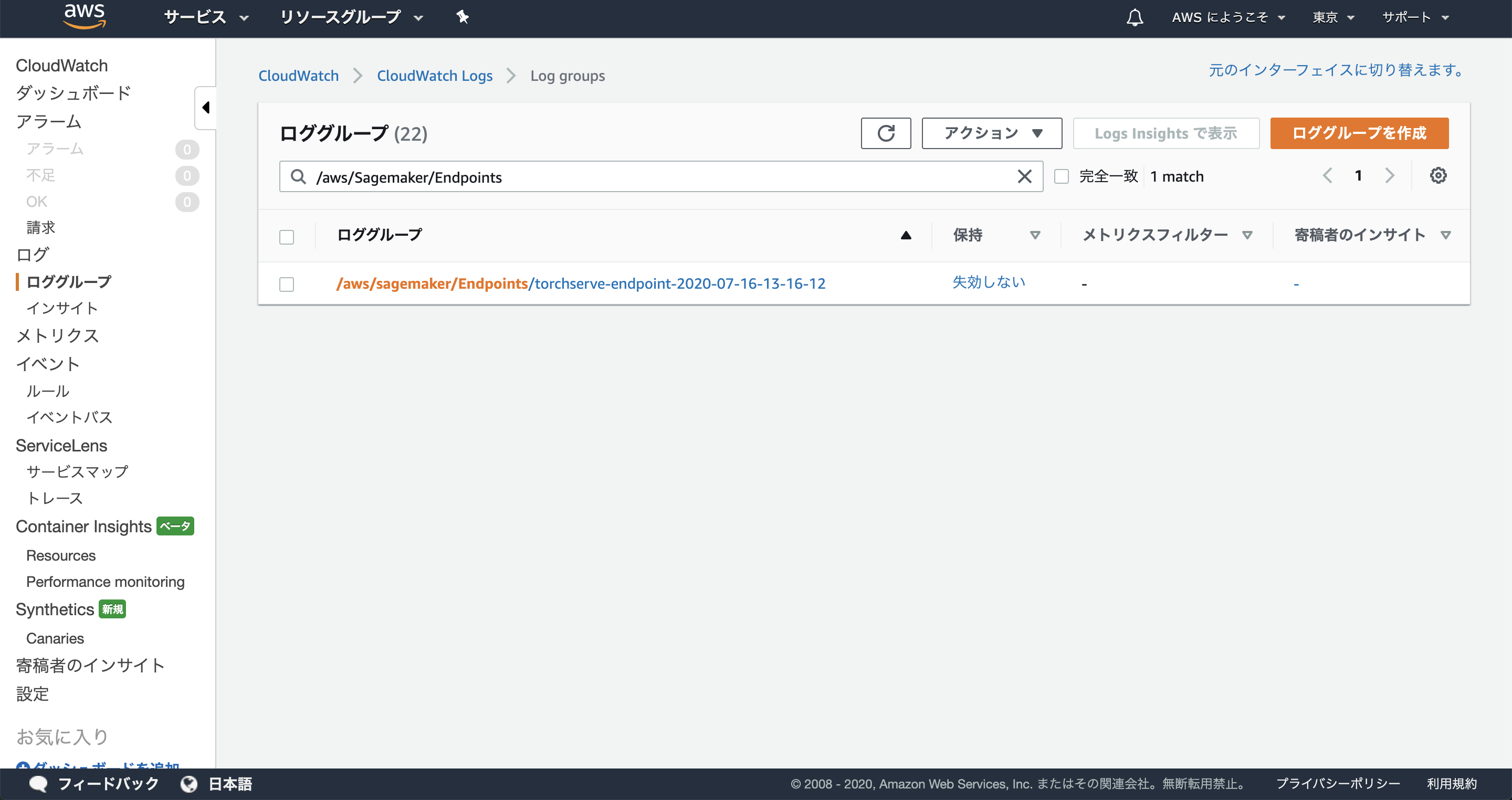
クリックして詳細画面を開き、[ログストリーム]内のログを確認すると、デプロイのログを確認できます。

デプロイがうまく行っていないときはErrorを出力していると思います。ちなみにエラーが発生すると再デプロイしようと1時間くらいリトライし続けるので、おかしいと思ったら早めにログを確認したほうがいいです。
※筆者はデプロイ長いなーって放置し続けて時間を無駄にしました。

リクエストを投げて、正常に動作しているか確認します。
!wget -q https://s3.amazonaws.com/model-server/inputs/kitten.jpg
file_name = 'kitten.jpg'
with open(file_name, 'rb') as f:
payload = f.read()
payload = payload
response = predictor.predict(data=payload)
print(*json.loads(response), sep = '\n')
# {'tiger_cat': 0.4693359136581421}
# {'tabby': 0.4633873701095581}
# {'Egyptian_cat': 0.06456154584884644}
# {'lynx': 0.001282821292988956}
# {'plastic_bag': 0.00023323031200561672}
predictorインスタンスが取得できている場合は上記の方法でリクエストが可能ですが、外部からリクエストをする場合はSDKが必要です。外部のPCでPythonの対話シェルを開き、boto3を使用してリクエストをしてみます。
$ !wget -q https://s3.amazonaws.com/model-server/inputs/kitten.jpg
$ python
>>> import json
>>> import boto3
>>> endpoint_name = 'torchserve-endpoint-2020-07-16-13-16-12'
>>> file_name = 'kitten.jpg'
>>> with open(file_name, 'rb') as f:
... payload = f.read()
... payload = payload
>>> client = boto3.client('runtime.sagemaker',
aws_access_key_id='XXXXXXXXXXXXXXXXXXXX',
aws_secret_access_key='XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX',
region_name='ap-northeast-1')
>>> response = client.invoke_endpoint(EndpointName=endpoint_name,
... ContentType='application/x-image',
... Body=payload)
>>> print(*json.loads(response['Body'].read()), sep = '\n')
{'tiger_cat': 0.4693359136581421}
{'tabby': 0.4633873701095581}
{'Egyptian_cat': 0.06456154584884644}
{'lynx': 0.001282821292988956}
{'plastic_bag': 0.00023323031200561672}
正しくレスポンスが返ってくることを確認できました。
デプロイされたモデル、デプロイの設定、エンドポイントの情報はコンソールからも確認できます。



おわりに
いかがでしたでしょうか(笑)。SageMakerとても便利です。バックエンドで推論をちょっとホスティングする場合はとても楽なのではないでしょうか。
インターフェースをカスタマイズしたい場合、より柔軟なカスタマイズも可能なようですが、TorchServeはSageMaker以外でもserveできるので(前回記事)、TorchServeの形式に従って開発したほうがAWSで使い回すには良さそうです。