はじめに
近年、オブジェクト検出の分野において、Real-time処理が求められるアプリケーションが増えてきました。自動車の自動運転、ドローンの空中ナビゲーション、高速なビデオ解析など、速度と精度が両立するオブジェクト検出技術のニーズが高まっています。この背景から、YOLO(You Only Look Once)というオブジェクト検出のアプローチは非常に注目を浴びてきました。そして、YOLOの進化版とも言える「YOLOX」は、その最先端を担っています。
YOLOXは、従来のYOLOシリーズとは異なるいくつかの革新的なアイディアを組み込んでおり、それにより、さらなる精度の向上と計算効率の最適化を実現しています。
YOLOXの特徴は以下の通りです。
- ネットワークアーキテクチャの改良: YOLOv5を参考にネットワークアーキテクチャを改良しています。backboneにはDarknet53を改良したCSPDarknet53を使用します。
- Decoupled Head: ネットワークのヘッド部分を複数のサブヘッドに分離することで、学習と推論の効率を向上させています。
- Strong data augmentation: Mosaic と MixUp augmentation を採用しています。Strong data augmentationを使用する場合はbackboneを事前学習しても精度が上がらないので、モデルはスクラッチで学習しています。
-
アンカーフリー検出器: 従来のYOLOモデルがアンカーベースだったのに対し、YOLOXはアンカーフリーを採用しています。
- multi positives: ポジティブアンカーを正解ボックスの中心にある一つのみでなく、周辺のアンカーもポジティブとします。
- SimOTA: 正解ボックスに割り当てるアンカーの絞り込み戦略に最適輸送の考え方を導入した、効率的かつ効果的な方法でラベルを割り当てるための新しい手法です。
本稿では、YOLOXのアーキテクチャに焦点を当て、その特徴や利点、そして他のオブジェクト検出手法との違いについて詳細に解説していきます。解説にはYOLOXのテクニカルレポートと本家の実装を使用します。また、本稿は以前の記事をベースに、他の手法と比較しながら解説します。
環境
本家のソースコードMegvii-BaseDetection/YOLOX (commit ac58e0a)を参考に解説します。
ソースコードはApache License 2.0(Copyright (c) 2021-2022 Megvii Inc. All rights reserved.)です。
ネットワークアーキテクチャの改良
YOLOXのアーキテクチャを下図に示します。
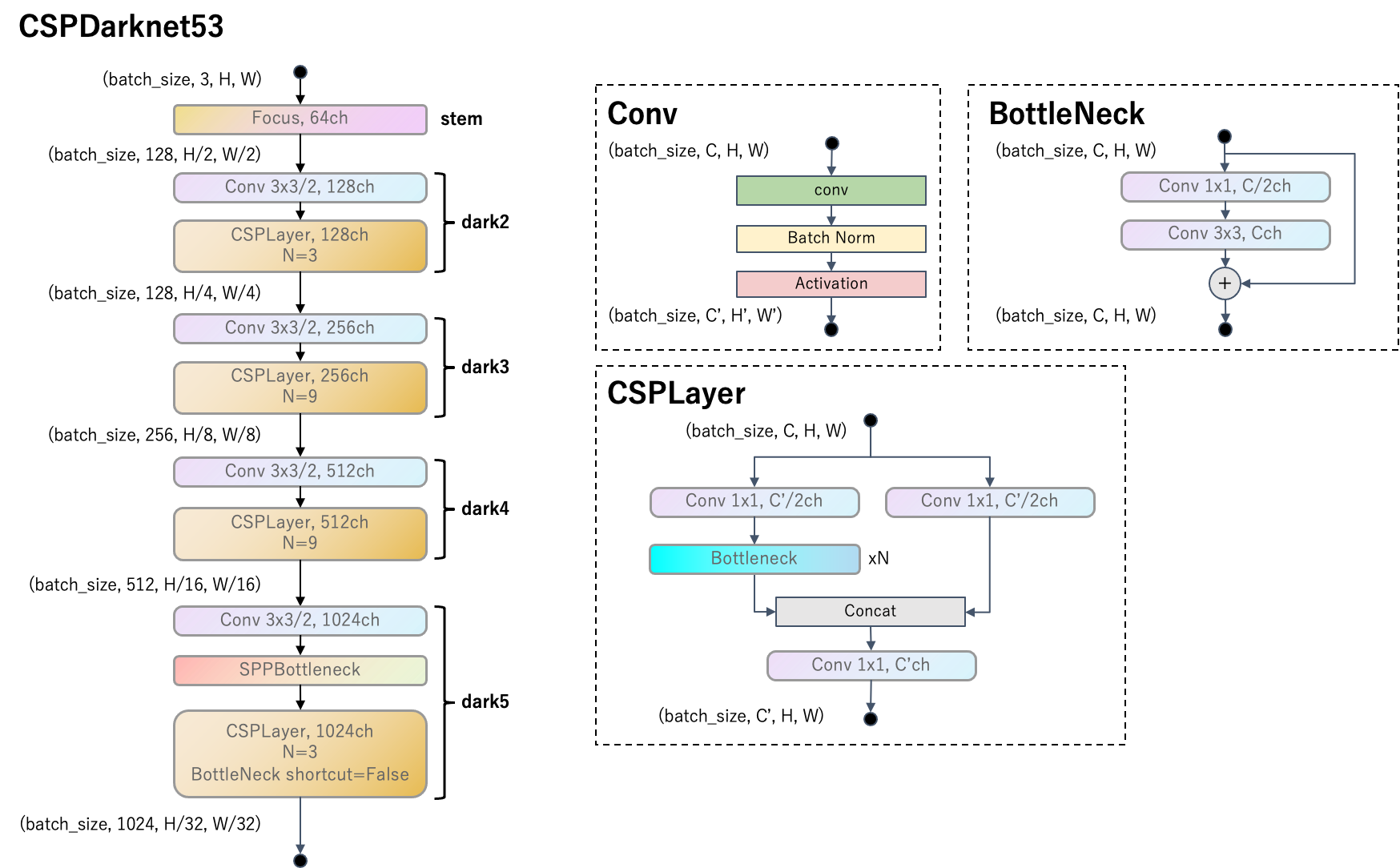
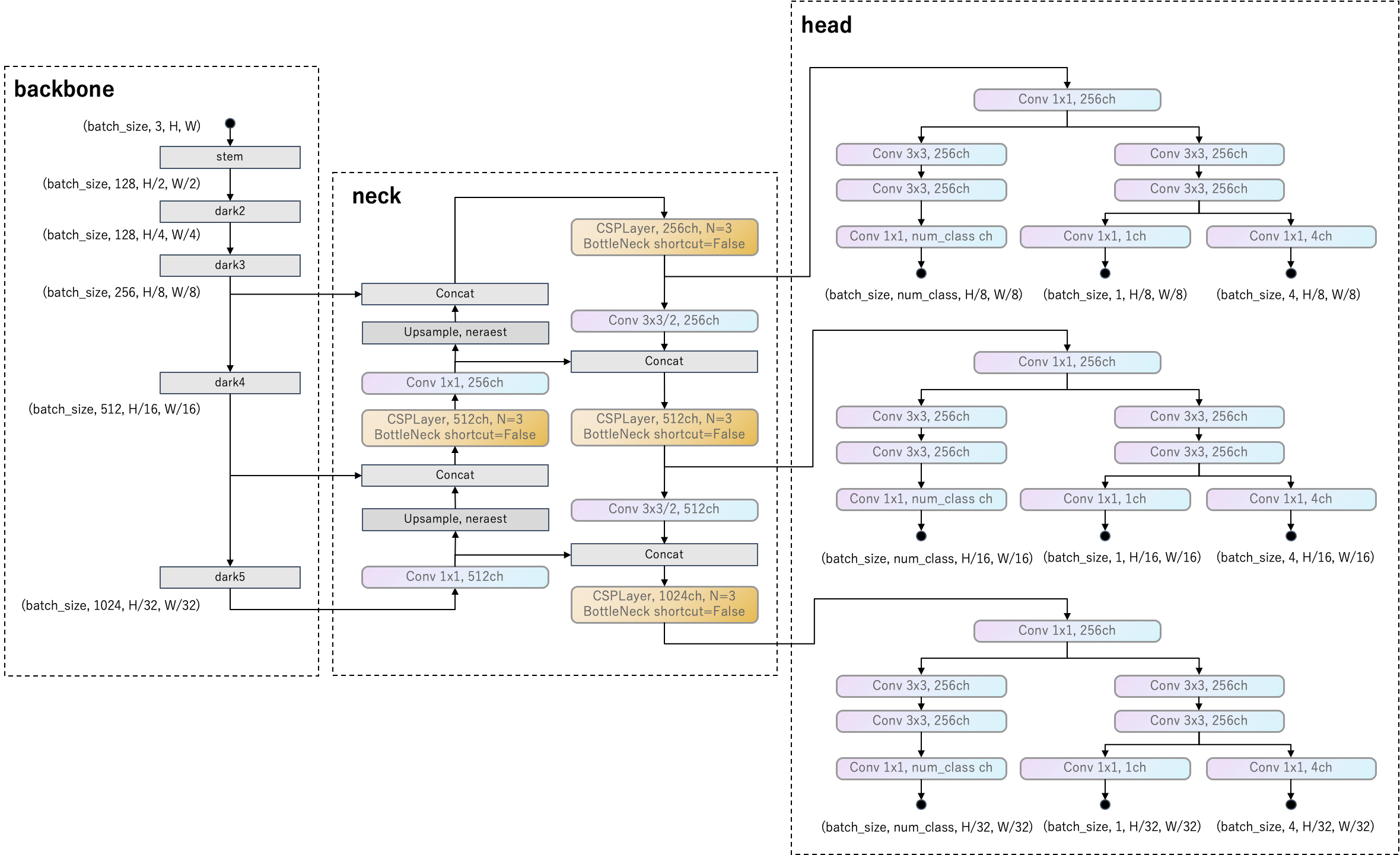
backboneは、Darknet53をベースにCSPLayerを追加して、CSPDarknet53に改良しています。
neckは、PAFPNをベースにCSPLayerを追加して、YOLOPAFPNに改良しています。
headは各タスクの予測を出力します。タスクはクラス分類、バウンディングボックス位置回帰と"IOU"があります。
バウンディングボックス位置回帰では、バウンディングボックスの中心座標と幅、高さのオフセットを予測します。オフセットは$(dx,dy,dw,dh)$形式で表します。
\begin{align}
dx^\ast &= \frac{cx^\ast}{w_a}-cx_a \\
dy^\ast &= \frac{cy^\ast}{h_a}-cy_a \\
dw^\ast &= \log\left(\frac{w^\ast}{w_a}\right) \\
dh^\ast &= \log\left(\frac{h^\ast}{h_a}\right)
\end{align}
ここで、$cx,cy,w,h$はボックスの中心座標と幅と高さを表します。添字$a$はアンカーボックスを表します。添字$*$は正解バウンディングボックスを表します。ただし、$(cx_a, cy_a)$は特徴マップのサイズを基準にしたアンカーの中心座標です。バウンディングボックス位置回帰では正解ボックスとIoUを計算し、それをlossとします。
"IOU"はアンカーがポジティブであるか、すなわちアンカーがバウンディングボックスの中心付近にあるかを0-1で予測するタスクです。正解データは、アンカーがポジティブかどうかを表すマスクであるfg_maskです。
def get_losses(
self,
imgs,
x_shifts,
y_shifts,
expanded_strides,
labels,
outputs,
origin_preds,
dtype,
):
...
obj_target = fg_mask.unsqueeze(-1)
...
これはFCOSのcenternessや、Faster R-CNNのObjectnessに相当するものです。
また、headは各YOLOPAFPNのレベルごとに独立しており、FCOSのように重み共有していません。
テスト時はNMSを使用します。
Decoupled Head
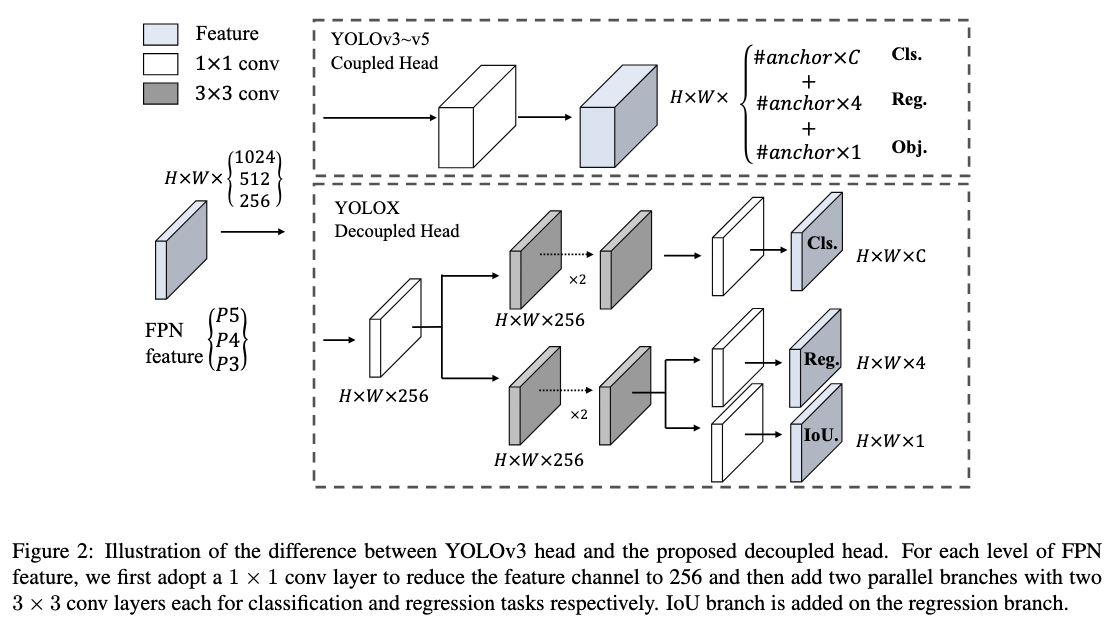
分類タスクとバウンディングボックス位置の回帰タスクでは、それぞれに適しているヘッドのアーキテクチャが異なることが知られています(参考文献)。
このコンフリクトを解消するために、多くの一段階および二段階の検出器で、分類と位置特定のための分離されたヘッドが使用されています。しかし、YOLOシリーズでは、バックボーンや特徴ピラミッドが進化しているにもかかわらず、ヘッドは結合されたままでした。
YOLOXではDecoupled Headを採用することで、収束速度が大幅に向上しました。特に、YOLOXにPSS headを追加し、NMS freeに向けて学習させる場合にはDecoupled Headが重要で、これがないと大幅に精度低下します。
Strong data augmentation
YOLOXではMosaic と MixUp augmentation を採用しています。Strong data augmentation は訓練の最終15エポックでは使用しないようにします。
また、Strong data augmentationの前に、RandomHorizontalFlip、 ColorJitter 、 multi-scale augmentationを行っています。
訓練戦略はYOLOv3をベースに少し改変されています。
- 学習データのサイズは640x640
- multi-scale augmentationは448〜832で32刻みで実施
- モデルの重みはExponential Moving Averageで更新
- スケジューラにCosine lr schedule を使用
- クラス分類とobjectnessにはBinary Cross Entropyを使用し、回帰にはIoU lossを使用
- 最終15エポックで、損失に回帰のL1 lossを追加
YOLOXのレポートでは、Strong data augmentationを使用した場合はbackboneを事前学習しても精度が上がらなかったようです。したがって、レポート中のモデルはスクラッチで学習しています。
アンカーフリー検出器
YOLOXはアンカーフリー検出器です。アンカーフリー検出器についてはFCOSの記事で解説しました。
以下では、YOLOXのアンカー割当戦略について解説します。割当はheadで行われます。ファイルはYOLOX/yolox/models/yolo_head.pyです。主にget_assignmentsメソッドの中身の解説になります。
multi positives
まず、各正解ボックスに対して割り当てるポジティブアンカーを決定します(get_geometry_constraintメソッドの処理)。
- 正解ボックスの中心座標を求めます。
- 「正解ボックスの中心座標」を中心座標とするようなボックスの位置を求めます(下図赤点線)。このボックスの幅と高さはアンカーサイズの
center_radius倍とします。center_radiusはレポートでは$1.5$、すなわちアンカー3x3分の範囲の大きさでしたが、YOLOXリポジトリの実装では$2.5$、すなわちアンカー5x5分の範囲の大きさになっています(最新のmainブランチだとひっそり$1.5$になってたりします)。 - 求めたボックス内に、含まれるアンカーをポジティブにラベルします。ここで、含まれるとは、アンカーの中心座標が求めたボックス内に含まれることを指します。これで正解ボックスに対して複数のアンカーが紐づきます。これがmulti positivesという手法です。

赤線は正解ボックスです。赤丸は正解ボックスの中心です。赤点線は「正解ボックスの中心」を中心とするアンカーの1.5倍の大きさのボックスです。黄色丸は赤点線に含まれるアンカーの中心座標です。
SimOTA
次に、正解ボックスと予測ボックスを紐付けます。get_assignmentsメソッドの続きです。
SimOTAを実行し、正解ボックスと予測ボックスを紐づけます。SimOTAは、物体検出の高度なラベル割り当て戦略として、OTAの考え方を元にして効率的かつ効果的な方法でラベルを割り当てるための新しい手法です。
レポートの著者が気づいた、ラベル割り当ての重要な洞察4点は以下の通りです。
- loss/quality aware
- センターを優先 (center prior)
- 各正解ラベル(ground-truth)に対する動的な正アンカーの数 (dynamic top-k)
- グローバルな視点 (global view)
上記の4つのルールすべてを満たすOptimal Transport Assignment(OTA)をラベル割り当て手法を候補にしましたが、OT問題をSinkhorn-Knoppアルゴリズムで解決するとトレーニング時間が25%も増加してしまいます。そこで、OTAを単純化してSimOTAという戦略を提案しています。
SimOTAの手順を見ていきます。
-
まず、予測ボックスの全体から、ポジティブアンカー由来のもののみ残すようにフィルターします。
-
正解ボックスの全体と、予測ボックス全体とのIoUを計算し、回帰のlossを計算します。同様にクラス分類のlossと"IOU"のlossも計算します。これらのlossを組み合わせてコストを計算します。Negative penaltyは正解ボックスと予測ボックスの由来アンカーが紐づいていない場合に$10^6$のペナルティを加えます。
\text{cost} = \sqrt{(\text{Cls loss})\times \text{("IOU" loss)}} + 3 \times \text{(Reg loss)} + \text{(Negative penalty)}
計算した$\text{cost}$を元に、正解ボックスと予測ボックスを紐付けます。具体的にはsimota_matchingメソッドの内容になります。
def simota_matching(self, cost, pair_wise_ious, gt_classes, num_gt, fg_mask):
matching_matrix = torch.zeros_like(cost, dtype=torch.uint8)
n_candidate_k = min(10, pair_wise_ious.size(1))
topk_ious, _ = torch.topk(pair_wise_ious, n_candidate_k, dim=1)
dynamic_ks = torch.clamp(topk_ious.sum(1).int(), min=1)
for gt_idx in range(num_gt):
_, pos_idx = torch.topk(
cost[gt_idx], k=dynamic_ks[gt_idx], largest=False
)
matching_matrix[gt_idx][pos_idx] = 1
del topk_ious, dynamic_ks, pos_idx
anchor_matching_gt = matching_matrix.sum(0)
# deal with the case that one anchor matches multiple ground-truths
if anchor_matching_gt.max() > 1:
multiple_match_mask = anchor_matching_gt > 1
_, cost_argmin = torch.min(cost[:, multiple_match_mask], dim=0)
matching_matrix[:, multiple_match_mask] *= 0
matching_matrix[cost_argmin, multiple_match_mask] = 1
fg_mask_inboxes = anchor_matching_gt > 0
num_fg = fg_mask_inboxes.sum().item()
fg_mask[fg_mask.clone()] = fg_mask_inboxes
matched_gt_inds = matching_matrix[:, fg_mask_inboxes].argmax(0)
gt_matched_classes = gt_classes[matched_gt_inds]
pred_ious_this_matching = (matching_matrix * pair_wise_ious).sum(0)[
fg_mask_inboxes
]
return num_fg, gt_matched_classes, pred_ious_this_matching, matched_gt_inds
matching_matrixは行方向に正解ボックスのインデックス、列方向に予測ボックスのインデックスを持つ行列です。この行列の要素は、正解ボックスと予測ボックスが紐づいた場合は$1$、そうでない場合は$0$となります。
各正解ボックスに対して紐づく予測ボックスを決定していきます。紐付ける予測ボックス数の最大値がn_candidate_kです。n_candidate_kは最大10とします。
topk_iousは行方向に正解ボックスのインデックス、列方向はn_candidate_kの大きさを持つ行列です。各行は、各正解ボックスとアンカーのIoUで、トップn_candidate_k個のIoUを保持しています。
dynamic_ksはtopk_iousを列方向に和をとります。したがって、dynamic_ksは各正解ボックスと紐づくアンカーのIoUの和をとり、整数にしたものになります。これを各正解ボックスそれぞれに紐付ける予測ボックスの数にします。つまり、予測精度が高い予測ボックスが多いほど、それらに対してバックプロパゲーションするための、正解ボックスごとに動的にパラメータを決定する仕組みになっています。
その後のforループでは、各正解ボックスに対してdynamic_ks個だけ、costが低い順で予測ボックスのインデックスを取得し、matching_matrixを完成させます。costを使うところが、loss awareです。
次に、予測ボックス1つに対し複数の正解ボックスが紐づいている場合の対処を行います。anchor_matching_gtは予測ボックス数(=アンカー数)の要素を持つベクトルで、各予測ボックスに紐づいた正解ボックスの数を要素に持ちます。anchor_matching_gtで1より大きい値をもつ予測ボックスに対し、costが最小になる正解ボックスを1つ選び、matching_matrixを修正します。
fg_mask_inboxesは、正解ボックスが紐づいている予測ボックス(すなわちポジティブアンカーのインデックス)をTrueにするマスクです。これはつまり、SimOTAで紐づけを決定した後のポジティブアンカーを表すマスクになっています。
matched_gt_indsは正解ボックスと紐づきを持つ予測ボックス数の要素を持つベクトルで、各予測ボックスと紐づく正解ボックスのインデックスを保持しています。
gt_matched_classesは正解ボックスと紐づきを持つ予測ボックスのクラスラベルです。pred_ious_this_matchingは正解ボックスと紐づきを持つ予測ボックスの、正解ボックスとのIoUを要素に持つベクトルです。
以上でsimota_matchingメソッドの処理が終わり、さらにget_assignmentsの処理も終わりです。これを正解データとして損失関数を計算し、バックプロパゲーションします。"IOU"は全てのアンカーに対して計算します。"IOU"以外の損失は正解ボックスと紐づきを持つ予測ボックス(を出力したアンカー)に対してのみ計算します。
結局、SimOTAはcostが小さくなるペアで正解ボックスと予測ボックスを紐付ける処理をしています。正解ボックスから見ると正解ボックス1つに対し複数の予測ボックスがひも付き、予測ボックスから見ると予測ボックス1つに対し1つの正解ボックスがひも付きます。
この方法は全ての正解ボックスに対し予測ボックスが紐づくとは限らないことに注意です。
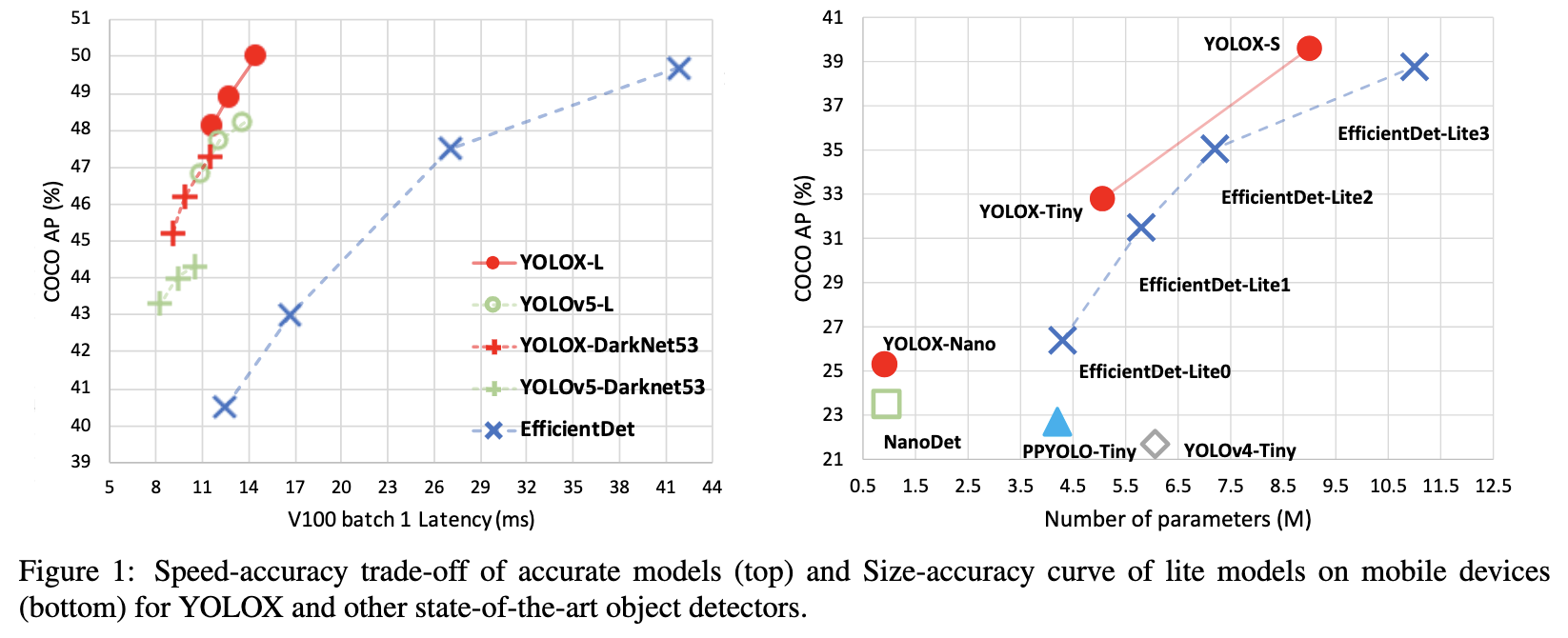
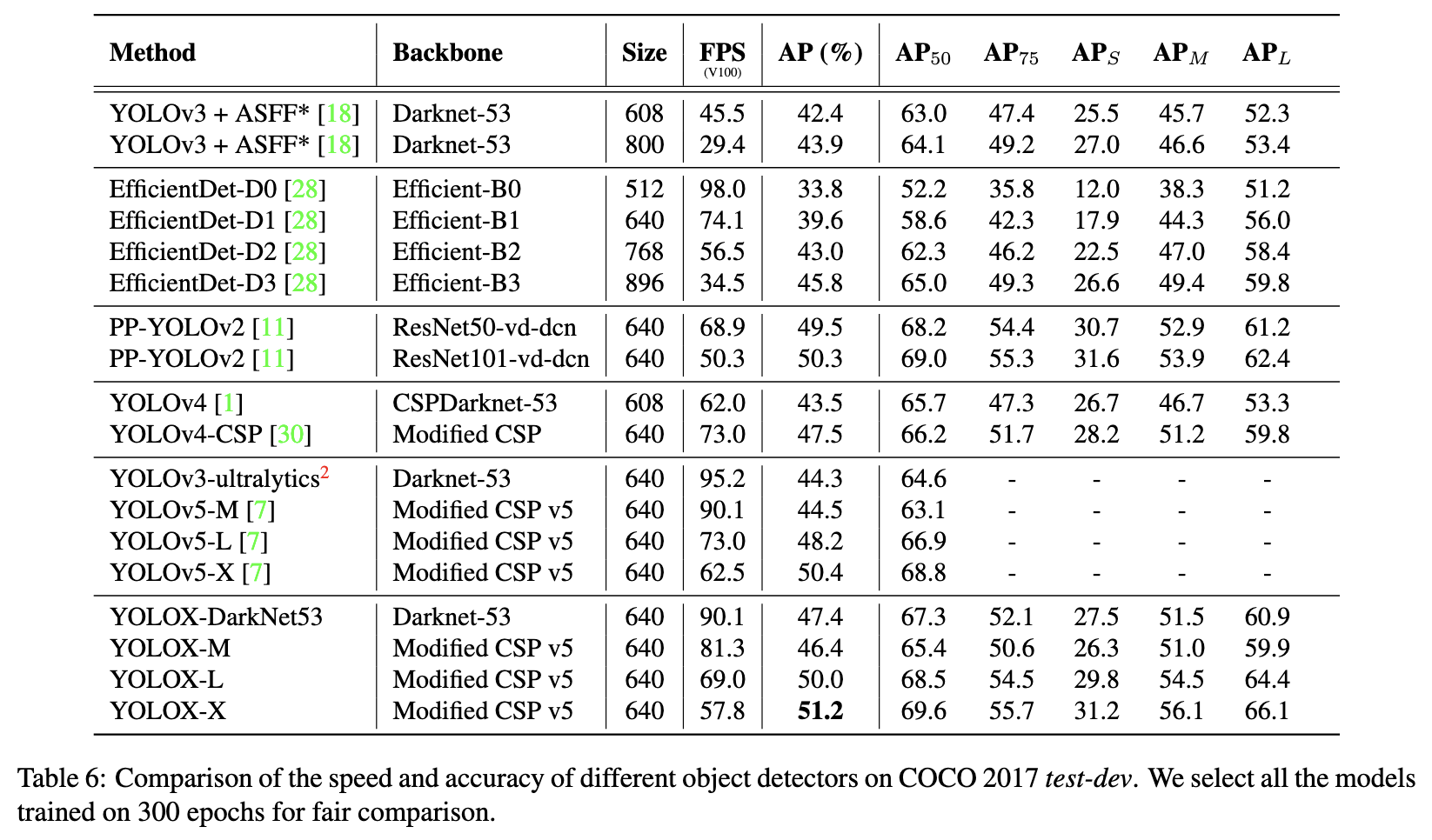
下図は各改良手法の貢献度合いです。
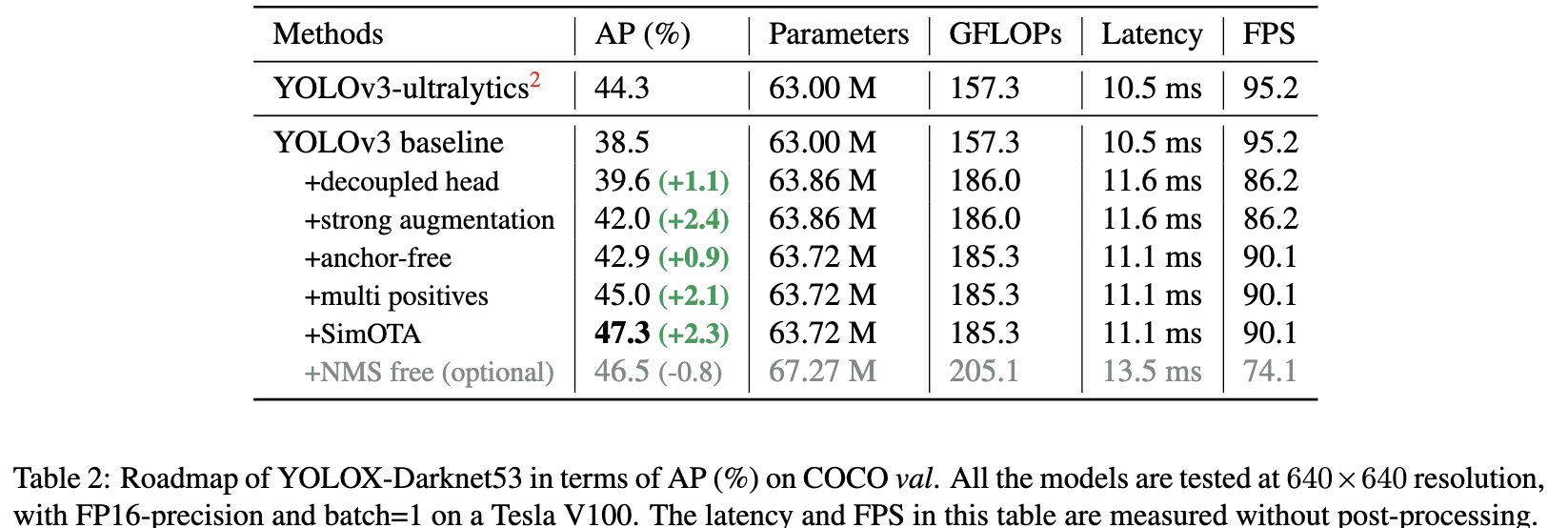
精度比較
すべてのYOLOシリーズに対して同じハードウェアとコードベースを使用して比較しています。
まとめ・感想
- アンカーモデルが最大の性能を出すためにはハイパーパラメータチューニングが必要であるのに対し、YOLOXはアンカーフリーでハイパーパラメータチューニングがほぼ不要
- YOLOv5と同等の精度を持ち、Apache-2.0 licenseで提供される実用的な物体検出器
- COCOによる検証だけでなく、Streaming Perception Challenge (Workshop on Autonomous Driving at CVPR 2021)で1位になった実績あり
- mmdetectionにも実装があり、使いやすい
- 改良点が盛り沢山なので、他の手法との差分比較はしにくい
気になる点
YOLOPAFPN
PAFPNのボトムアップはbackboneの浅い層を深いFPNレベルと繋げやすくする手法だったはずですが、CSPLayerを追加したため、backboneを経由するのと大差なくなっています。PAFPNの本来の主旨とは異なる手法になってしまっていますが、なぜ精度が向上するのでしょうか。パラメータ数の方が重要だったということでしょうか。
pre-define a scale range
YOLOXのレポート中では、FCOSと同じように、正解ボックスのスケール範囲に基づくアンカーの紐づけをすると書いてあります。しかし、該当する実装がありません。したがって、PAFPNの任意のレベルのアンカーが、任意のサイズの正解ボックスを予測してもよいことになっています。
YOLOXには難しい予測を排除する機構がないため、一見モデルに悪影響を与えそうです。しかし、YOLOXはYOLOv5と同等の精度と、かなり精度が良いです。
SimOTAが訓練時の実績ベースで難しい予測をしているアンカーを排除しているとみなせるので、難しい予測を排除する機構として働いていると考えられますが、完全に不安定な予測を排除できるかはよく分かりません。
Focal loss
RetinaNetで使用されていたFocal lossはなぜ使用されないのでしょうか。
Focus
追記予定
参考文献
-
Zheng Ge, Songtao Liu, Feng Wang, Zeming Li, Jian Sun, "YOLOX: Exceeding YOLO Series in 2021," https://arxiv.org/abs/2107.08430
-
Gabriel Mongaras, "YOLOX Explanation — How Does YOLOX Work?," https://medium.com/mlearning-ai/yolox-explanation-how-does-yolox-work-3e5c89f2bf78
-
Chul Hyun (Chadrick) Kwag, "paper review: “Path Aggregation Network for Instance Segmentation”," https://chadrick-kwag.net/paper-review-path-aggregation-network-for-instance-segmentation/