はじめに
よく理解せずPyTorchのdetach()とclone()を使っていませんか?この記事ではdetach()とclone()の挙動から一体何が起きているのか、何に気をつけなければならないのか、具体的なコードを交えて解説します。
環境
- google colab
- Python 3.7.11
- torch==1.9.0+cu102
- perfplot==0.8.0
detach
.detach() は同一デバイス上に新しいテンソルを作成する。計算グラフからは切り離され、requires_grad=Falseになる。
まず、基本となる次の計算を考える。
DEVICE = torch.device("cuda")
x = torch.tensor([2.0], device=DEVICE, requires_grad=False)
w = torch.tensor([1.0], device=DEVICE, requires_grad=True)
b = torch.tensor([3.0], device=DEVICE, requires_grad=True)
y = x*w + b
y.backward()
print(x)
print(w)
print(b)
print(y)
# tensor([2.], device='cuda:0')
# tensor([1.], device='cuda:0', requires_grad=True)
# tensor([3.], device='cuda:0', requires_grad=True)
# tensor([5.], device='cuda:0', grad_fn=<AddBackward0>)
print(x.grad)
print(w.grad)
print(b.grad)
print(y.grad)
# None
# tensor([2.], device='cuda:0')
# tensor([1.], device='cuda:0')
# None
print(x.requires_grad)
print(w.requires_grad)
print(b.requires_grad)
print(y.requires_grad)
# False
# True
# True
# True
print(x.is_leaf)
print(w.is_leaf)
print(b.is_leaf)
print(y.is_leaf)
# True
# True
# True
# False
計算グラフは次のようになる。
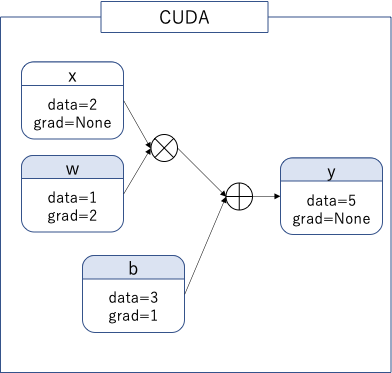
次に.detach()がどのようになるか確認しよう。
z = w.detach()
print(z)
print(z.grad)
print(z is y)
print(z.is_leaf)
# tensor(1., device='cuda:0')
# None
# False
# True
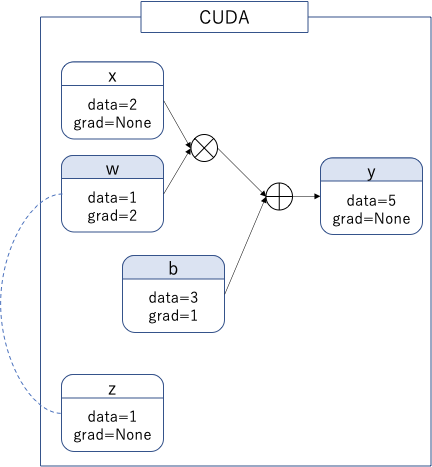
テンソルの値を共有していることに注意。
print(w)
print(z)
z[0] = 2
print(w)
print(z)
# tensor([1.], device='cuda:0', requires_grad=True)
# tensor([1.], device='cuda:0')
# tensor([2.], device='cuda:0', requires_grad=True)
# tensor([2.], device='cuda:0')
clone
.clone() は同一デバイス上に新しいテンソルを作成するが、clone元のテンソルに微分が流れ込む。
x = torch.tensor([2.0], device=DEVICE, requires_grad=False)
w = torch.tensor([1.0], device=DEVICE, requires_grad=True)
b = torch.tensor([3.0], device=DEVICE, requires_grad=True)
v = w.clone()
y = x*v + b
y.backward()
print(x)
print(w)
print(v)
print(b)
print(y)
# tensor([2.], device='cuda:0')
# tensor([1.], device='cuda:0', requires_grad=True)
# tensor([1.], device='cuda:0', grad_fn=<CloneBackward>)
# tensor([3.], device='cuda:0', requires_grad=True)
# tensor([5.], device='cuda:0', grad_fn=<AddBackward0>)
print(x.grad)
print(w.grad)
print(v.grad)
print(b.grad)
print(y.grad)
# None
# tensor([2.], device='cuda:0')
# None
# tensor([1.], device='cuda:0')
# None
print(v is w)
print(v.is_leaf)
print(v.requires_grad)
# False
# False
# True
気持ちとしては次の計算グラフになる。変数$1$はグラフ作成上のダミー変数。
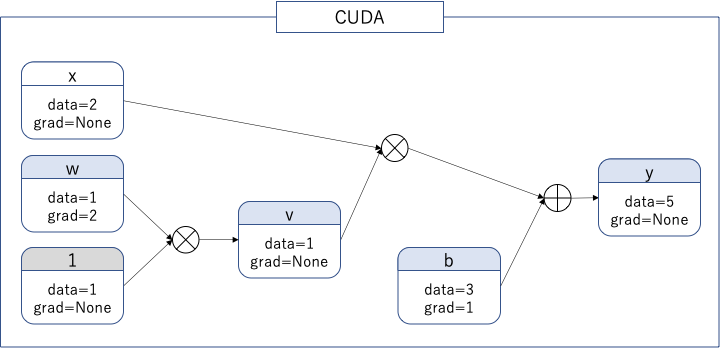
.detach()とは異なり、テンソルの値は共有していない。
print(w)
print(v)
v[0] = 7.0
print(w)
print(v)
# tensor([1.], device='cuda:0', requires_grad=True)
# tensor([1.], device='cuda:0', grad_fn=<CloneBackward>)
# tensor([1.], device='cuda:0', requires_grad=True)
# tensor([7.], device='cuda:0', grad_fn=<CopySlices>)
clone先の変数はleaf変数ではないので、.gradで微分を取得できない。ただし、retain_grad()で微分を取得可能になる。次の計算を考えてみる。
x = torch.tensor([2.0], device=DEVICE, requires_grad=False)
w = torch.tensor([1.0], device=DEVICE, requires_grad=True)
v = w.clone()
v.retain_grad()
y = x*w + v
y.backward()
print(x)
print(w)
print(v)
print(y)
# tensor([2.], device='cuda:0')
# tensor([1.], device='cuda:0', requires_grad=True)
# tensor([1.], device='cuda:0', grad_fn=<CloneBackward>)
# tensor([3.], device='cuda:0', grad_fn=<AddBackward0>)
print(x.grad)
print(w.grad)
print(v.grad)
print(y.grad)
# None
# tensor([3.], device='cuda:0')
# tensor([1.], device='cuda:0')
# None
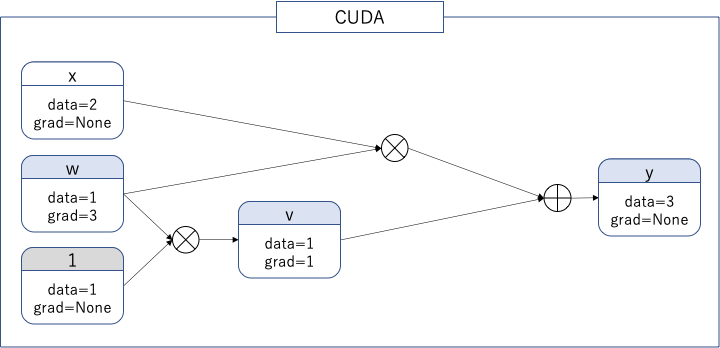
$w$には$v$からの流れも加わるため、微分は$2+1=3$になる。
cpu
.cpu() はcpu上に新しいテンソルを作成するが、元のテンソルに微分が流れ込む。同一デバイス上にないテンソルは、テンソル演算が出来ないが、逆伝播は出来ることに注意。
x = torch.tensor([2.0], device=DEVICE, requires_grad=False)
w = torch.tensor([1.0], device=DEVICE, requires_grad=True)
b = torch.tensor([3.0], device=DEVICE, requires_grad=True)
y = x*w + b
y.retain_grad()
z = y.cpu()
z.retain_grad()
v = torch.tensor([7.0], device="cpu", requires_grad=True)
c = torch.tensor([4.0], device="cpu", requires_grad=True)
f = v*z + c
f.backward()
print(x)
print(w)
print(b)
print(y)
print(z)
print(v)
print(c)
print(f)
# tensor([2.], device='cuda:0')
# tensor([1.], device='cuda:0', requires_grad=True)
# tensor([3.], device='cuda:0', requires_grad=True)
# tensor([5.], device='cuda:0', grad_fn=<AddBackward0>)
# tensor([5.], grad_fn=<CopyBackwards>)
# tensor([7.], requires_grad=True)
# tensor([4.], requires_grad=True)
# tensor([39.], grad_fn=<AddBackward0>)
print(x.grad)
print(w.grad)
print(b.grad)
print(y.grad)
print(z.grad)
print(v.grad)
print(c.grad)
print(f.grad)
# None
# tensor([14.], device='cuda:0')
# tensor([7.], device='cuda:0')
# tensor([7.], device='cuda:0')
# tensor([7.])
# tensor([5.])
# tensor([1.])
# None
print(z is y)
print(z.is_leaf)
print(v.is_leaf)
print(c.is_leaf)
print(f.is_leaf)
print(z.requires_grad)
print(v.requires_grad)
print(c.requires_grad)
print(f.requires_grad)
# False
# False
# True
# True
# False
# True
# True
# True
# True
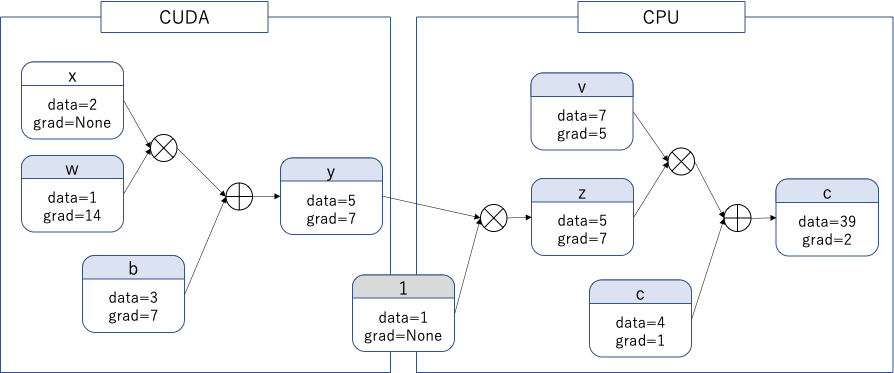
.cpu()はテンソルの値を共有しない。
w = torch.tensor([1.0], device=DEVICE, requires_grad=True)
v = w.cpu()
print(w)
print(v)
v[0] = 7.0
print(w)
print(v)
# tensor([1.], device='cuda:0', requires_grad=True)
# tensor([1.], grad_fn=<CopyBackwards>)
# tensor([1.], device='cuda:0', requires_grad=True)
# tensor([7.], grad_fn=<CopySlices>)
numpy
.numpy() はテンソルがGPU上にあるときはエラーになる。
TypeError: can't convert cuda:0 device type tensor to numpy. Use Tensor.cpu() to copy the tensor to host memory first.
.numpy() はテンソルが変数(requires_grad=True)のときはエラーになる。
RuntimeError: Can't call numpy() on Tensor that requires grad. Use tensor.detach().numpy() instead.
ndarrayとtensorが値を共有することに注意。
x = torch.tensor([2.0], device="cpu", requires_grad=False)
w = torch.tensor([1.0], device="cpu", requires_grad=True)
b = torch.tensor([3.0], device="cpu", requires_grad=True)
y = x*w + b
y.backward()
z = x.numpy()
print(x)
print(z)
z[0] = 7.0
print(x)
print(z)
# tensor([2.])
# [2.]
# tensor([7.])
# [7.]
detach().clone()
.detach()することで得られるテンソルは定数テンソルであり、さらに.clone()することで値の共有もされなくなる。定数テンソルのcloneなので、逆伝播はしない。したがって.detach().clone()で得られるテンソルは他のテンソルと独立したテンソルになる。
x = torch.tensor([2.0], device=DEVICE, requires_grad=False)
w = torch.tensor([1.0], device=DEVICE, requires_grad=True)
b = torch.tensor([3.0], device=DEVICE, requires_grad=True)
y = x*w + b
y.backward()
z = w.detach()
s = z.clone()
print(z)
print(z.grad)
print(z is w)
print(z.is_leaf)
# tensor([1.], device='cuda:0')
# None
# False
# True
print(s)
print(s.grad)
print(s is z)
print(s.is_leaf)
# tensor([1.], device='cuda:0')
# None
# False
# True
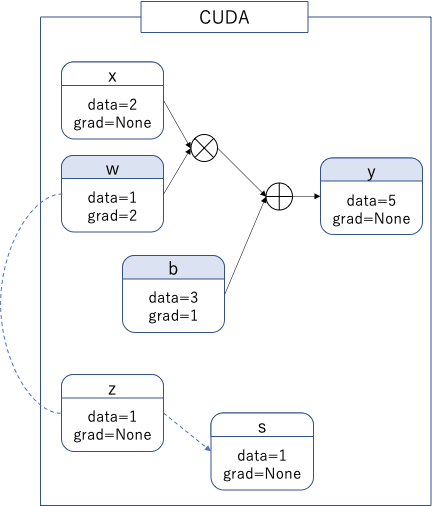
$s$と$w$は値の共有もしていないし、逆伝播もしない。
clone().detach()
.clone()することで得られるテンソルは値の共有はしない。さらに.detach()することで逆伝播も行われなくなり、.clone().detach()で得られるテンソルは他のテンソルと独立したテンソルになる。
x = torch.tensor([2.0], device=DEVICE, requires_grad=False)
w = torch.tensor([4.0], device=DEVICE, requires_grad=True)
b = torch.tensor([3.0], device=DEVICE, requires_grad=True)
v = w.clone()
z = v.detach()
y = x*v + b
y.backward()
t = torch.tensor([7.0], device=DEVICE, requires_grad=True)
c = torch.tensor([9.0], device=DEVICE, requires_grad=True)
u = z*t + c
u.backward()
print(x)
print(w)
print(b)
print(y)
print(v)
print(z)
print(t)
print(c)
print(u)
# tensor([2.], device='cuda:0')
# tensor([4.], device='cuda:0', requires_grad=True)
# tensor([3.], device='cuda:0', requires_grad=True)
# tensor([11.], device='cuda:0', grad_fn=<AddBackward0>)
# tensor([4.], device='cuda:0', grad_fn=<CloneBackward>)
# tensor([4.], device='cuda:0')
# tensor([7.], device='cuda:0', requires_grad=True)
# tensor([9.], device='cuda:0', requires_grad=True)
# tensor([37.], device='cuda:0', grad_fn=<AddBackward0>)
print(x.grad)
print(w.grad)
print(b.grad)
print(y.grad)
print(v.grad)
print(z.grad)
print(t.grad)
print(c.grad)
print(u.grad)
# None
# tensor([2.], device='cuda:0')
# tensor([1.], device='cuda:0')
# None
# None
# None
# tensor([4.], device='cuda:0')
# tensor([1.], device='cuda:0')
# None
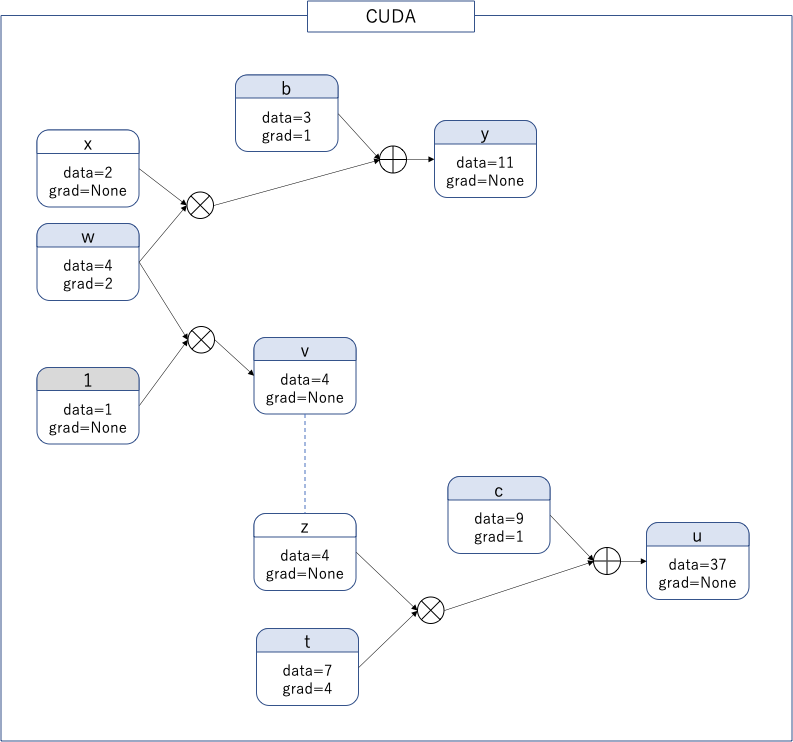
$w$と$z$は値の共有もしていないし、逆伝播することもない。
TIPS1 -- Tensorからndarrayへの変換
.detach().numpy()だと元のテンソルとndarrayが値を共有してしまう。独立なndarrayを得たい場合は.detach().numpy().copy()を使用するか、.detach().clone().numpy()もしくは.clone().detach().numpy()を使用する必要がある。.clone().numpy()だと元のテンソルがrequires_grad =Trueの時にエラーになる。
下記コードで、それぞれの方法にかかる時間を計測する。
pip install perfplot==0.8.0
import torch
import perfplot
perfplot.show(
setup=lambda n: torch.randn(n),
kernels=[
lambda a: a.detach().numpy().copy(),
lambda a: a.clone().detach().numpy(),
lambda a: a.detach().clone().numpy(),
],
labels=["detach.numpy().copy()", "clone().detach().numpy()", "detach().clone().numpy()"],
n_range=[2 ** k for k in range(15)],
xlabel="len(a)",
logx=False,
logy=False,
title='Timing comparison for copying a pytorch tensor',
)
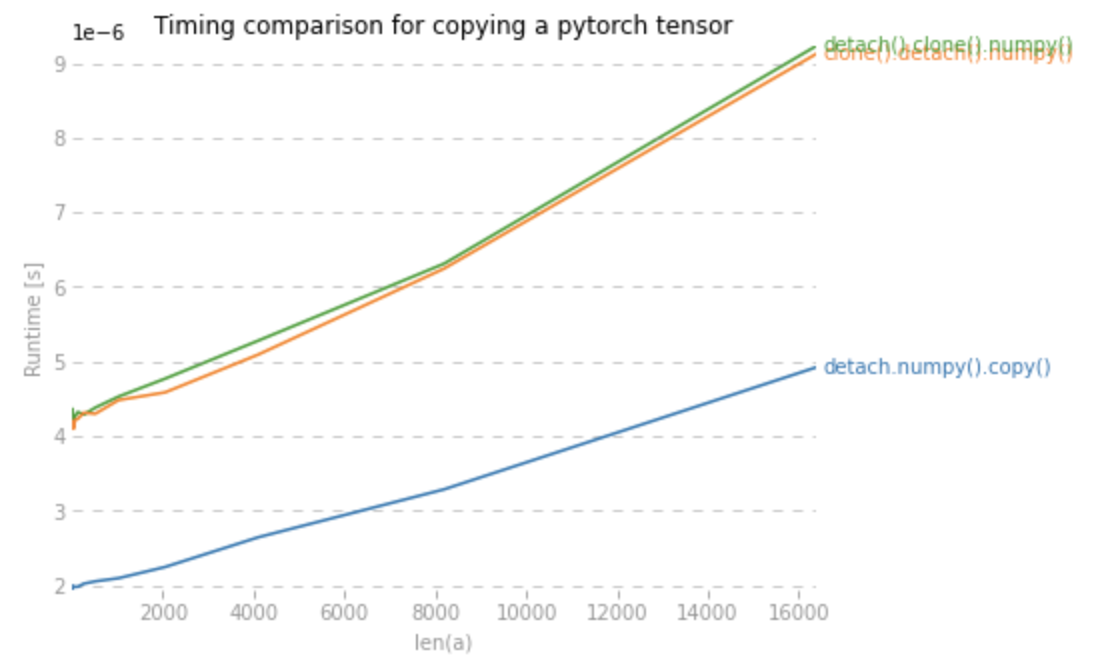
CPUとGPUの速度を比較しているので一概には言えないが、一つの参考になるだろう。
TIPS2 -- テンソルをコピーするベストプラクティス
テンソルをコピーするには何を使うのが良いのか。こちらの質問回答で、5つの方法を比較している。
y = tensor.new_tensor(x) # method a
y = x.clone().detach() # method b
y = torch.empty_like(x).copy_(x) # method c
y = torch.tensor(x) # method d
y = x.detach().clone() # method e
new_tensorの説明は公式ドキュメントに記載がある。
When data is a tensor x, new_tensor() reads out ‘the data’ from whatever it is passed, and constructs a leaf variable. Therefore tensor.new_tensor(x) is equivalent to x.clone().detach() and tensor.new_tensor(x, requires_grad=True) is equivalent to x.clone().detach().requires_grad_(True). The equivalents using clone() and detach() are recommended.
下記コードで、それぞれの方法にかかる時間を計測する。
pip install perfplot==0.8.0
import torch
import perfplot
perfplot.show(
setup=lambda n: torch.randn(n),
kernels=[
lambda a: a.new_tensor(a),
lambda a: a.clone().detach(),
lambda a: torch.empty_like(a).copy_(a),
lambda a: torch.tensor(a),
lambda a: a.detach().clone(),
],
labels=["new_tensor()", "clone().detach()", "empty_like().copy()", "tensor()", "detach().clone()"],
n_range=[2 ** k for k in range(15)],
xlabel="len(a)",
logx=False,
logy=False,
title='Timing comparison for copying a pytorch tensor',
)

下三つの方法はほとんど差がないので、どれを使用してもよい。明らかに上二つよりは速い。
TIPS3 -- detachの値共有の使い方
clone().detach()の例から、cloneをなくしてみると次のようになる。
x = torch.tensor([2.0], device=DEVICE, requires_grad=False)
w = torch.tensor([4.0], device=DEVICE, requires_grad=True)
b = torch.tensor([3.0], device=DEVICE, requires_grad=True)
z = w.detach()
y = x*w + b
y.backward()
t = torch.tensor([7.0], device=DEVICE, requires_grad=True)
c = torch.tensor([9.0], device=DEVICE, requires_grad=True)
u = z*t + c
u.backward()
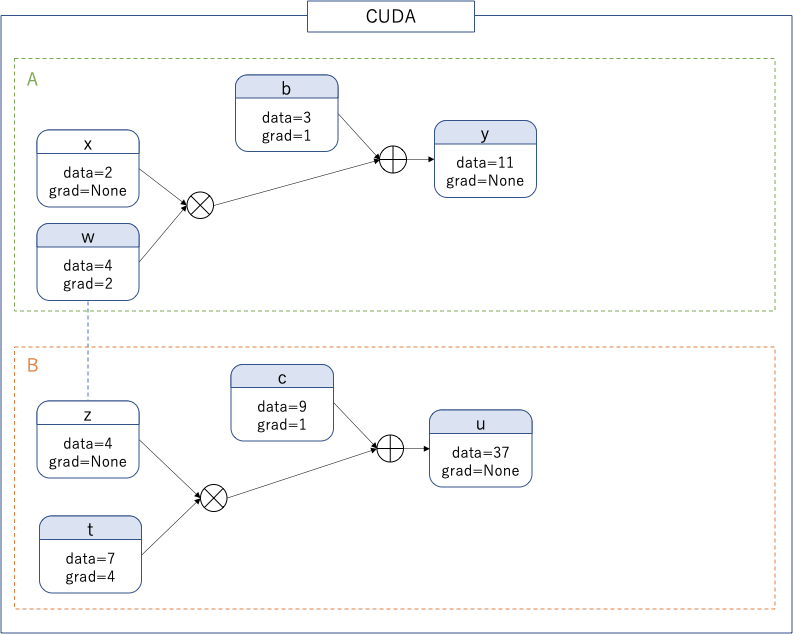
この場合はネットワークAを学習して$w$を更新後、$z$が値を共有しているので新たな値でネットワークBを学習、ただし$z$は定数なのでネットワークBの学習では更新されない。このように二つのネットワークを使用する際、片方のネットワークでは重みを更新し、片方のネットワークでは固定したいといった場合にdetach()が使える。
おわりに
detach()とclone()、ついでにcpu()とnumpy()の挙動も確認しました。cpu()はto()の挙動と同じようになるはずです。
気になる点
-
detach()もclone()も新たにメモリを確保するので、x.detach().clone().numpy()はGPUを余計に消費してしまうのではないか? たくさんの変数をnumpyに変換する際は気をつけなければならないかもしれない。