Dataiku Academyのユースケースを実施してみた。(Network Optimization編)
はじめに
Dataiku社から、データ分析の学習のためのコンテンツとして提供されている、Dataiku Academyで学習してみました。
英語ですが、ビジネスサンプルをベースにどのようにデータを分析し、業務に活かしていくのかを理解できるので、試しに実施してみたことを書いてみました。
ここでは、Network Optimizationという、レンタカー会社がレンタカーの需要を拡大するため、パートナーシップを組んでいる保険会社の情報を活用して、パートナーを組むガレージをどこにするかといったユースケースを実施した内容を掲載しています。
詳細は、こちらを参照してください。
ビジネスの背景
レンタカー会社が、保険会社とのパートナーシップをもとに新たな需要を満たすため、同社の代理店ネットワークを拡大していきたいと考えています。具体的には、次のようなことを目的にしています。
- 現在の代理店ネットワークが、実際の需要と予想需要を踏まえて、適切であるかを理解する。
- 各代理店の所在地での需要を予測することでレンタカーのローテーションのスケジュールを最適にする。
- 代理店ネットワークを効率的に広げていくため、パートナーシップやその場所を評価する
データ
ここでは、次のデータを使用します。
-
Demand
- 保険会社から提供されたデータ。4年間分の交通事故の記録。約25万件のレコード。
-
Network
- 約350件のレンタカー代理店の所在地情報。
-
Parners
- パートナー(ガレージ)候補の情報。HTML形式。
手順
大きくは次の手順になります。
- データをアップロードします。
- 日時情報をクレンジングしたり、緯度経度を算出したりします。
- 事故発生場所からステーション(代理店やパートナー候補のガレージ)までの地理的な近さをもとにデータを結合します。
- 地域毎、またはステーション毎にデータを集計して分析します。
前準備
Dataiku DSSをインストールする方法はこちらを参照してください。
Dataiku DSSをインストールした後、次のDataikuプラグインをインストールします。Dataikuプラグインのインストールの仕方はこちらを参照してください。
あと、Geocoder pluginを用いる場合は、Map QuestかBing Maps API keyが必要になります。
MapQuest API Keyを取得する場合は、次のサイドでアカウントを作成して、API keyを作成します。
https://developer.mapquest.com/
(Bing Mapsの方はセットアップの仕方がまずかったのか、エラーとなって正常に動作しませんでした。)
プロジェクトの作成
Dataikuのトップページで[+ NEW PROJECT]をクリックして、[Blank Project]を作成します。
データ準備
ここでは、3種類のデータを結合して1つのデータにします。
Demand データ
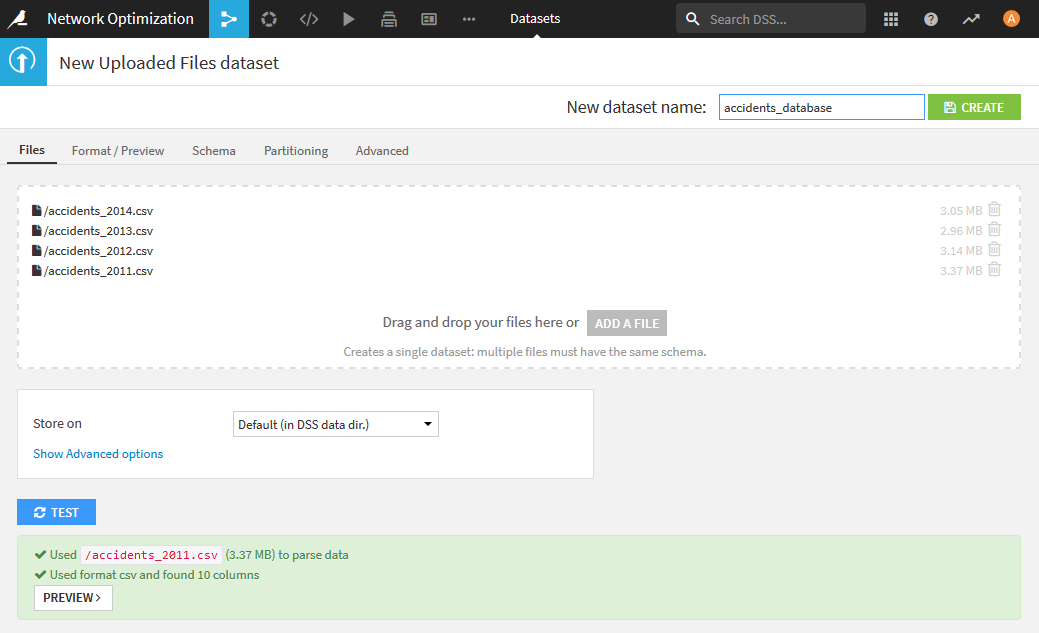
- accidents.zipを[Upload your files]でアップロードしてデータセットを作成します。これらのファイルはすべて項目が同じなので、複数ファイルをアップロードすることで自動的に1つのデータセットに統合されます。
- データ分析できるようにPrepareレシピを利用してデータを加工します。
- 日付と時刻の変換
-
yearを、Formulaを用いて西暦下2桁から4桁表示に変更します。下記コードを記載します。"20"+year -
hrmnを、Formulaを用いて24時間形式に変更します。下記コードを書きます。if(length(hrmn) == 3,"0"+hrmn, if(length(hrmn) == 2,"00"+hrmn, if(length(hrmn) == 1,"000"+hrmn,hrmn)))
-
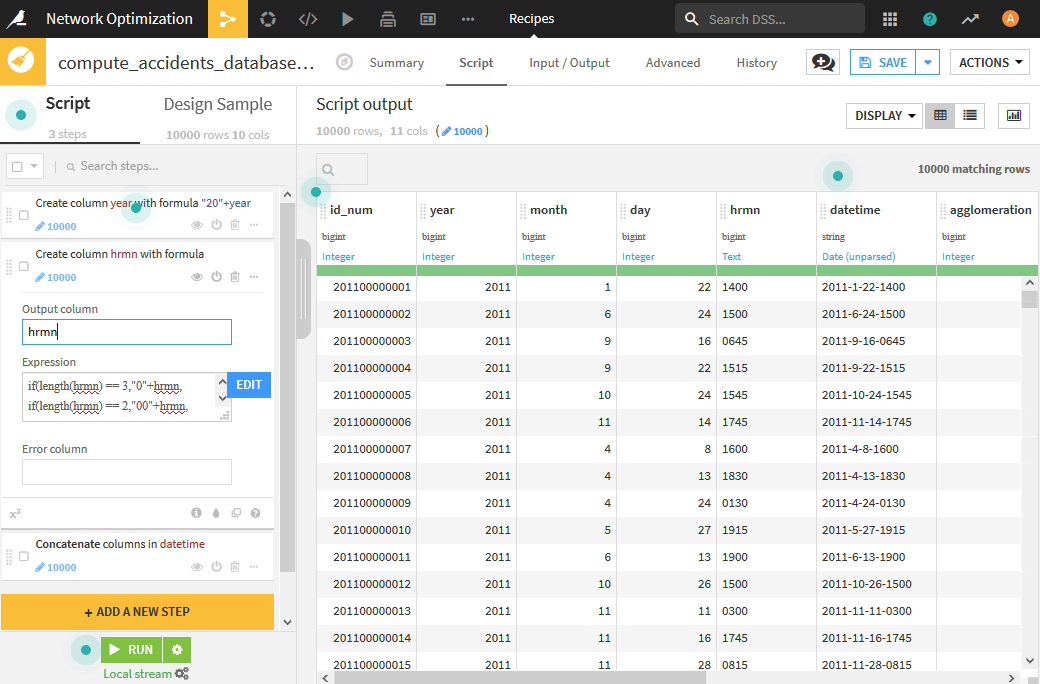
- Concatenate columnsを用いて、year,month,day,hrmnを-「ハイフン」で連結した値をもつdatetimeを作ります。
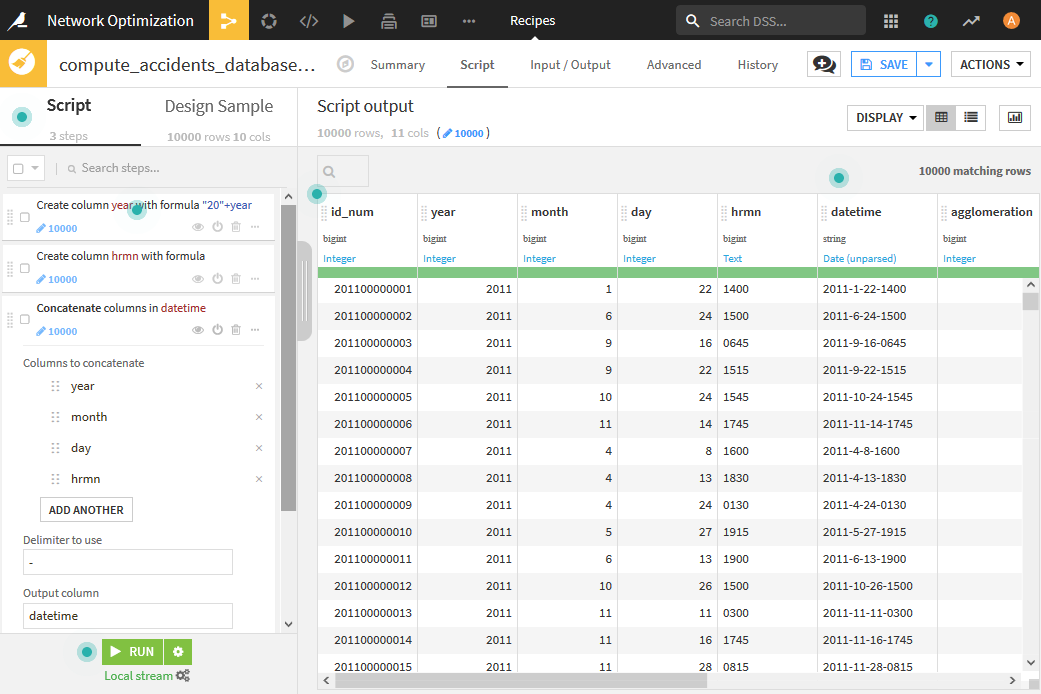
- Parse dateを用いて、datetimeをdate型に変換します。表示される画面で「yyyy-MM-ddZ」を選択して、[OK]ボタンをクリックします。
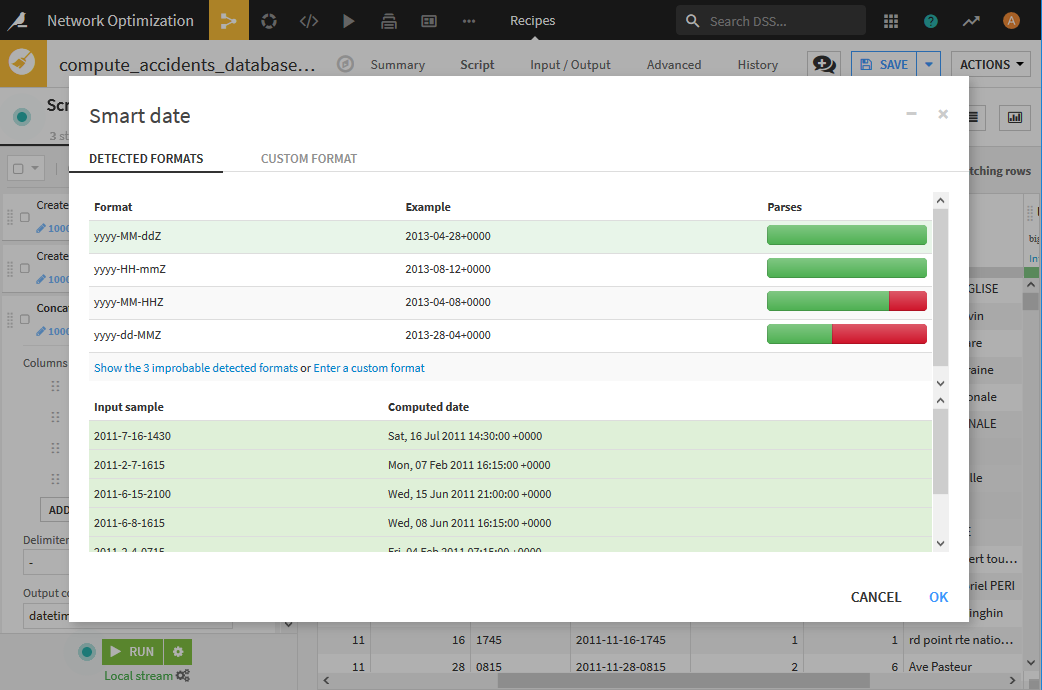
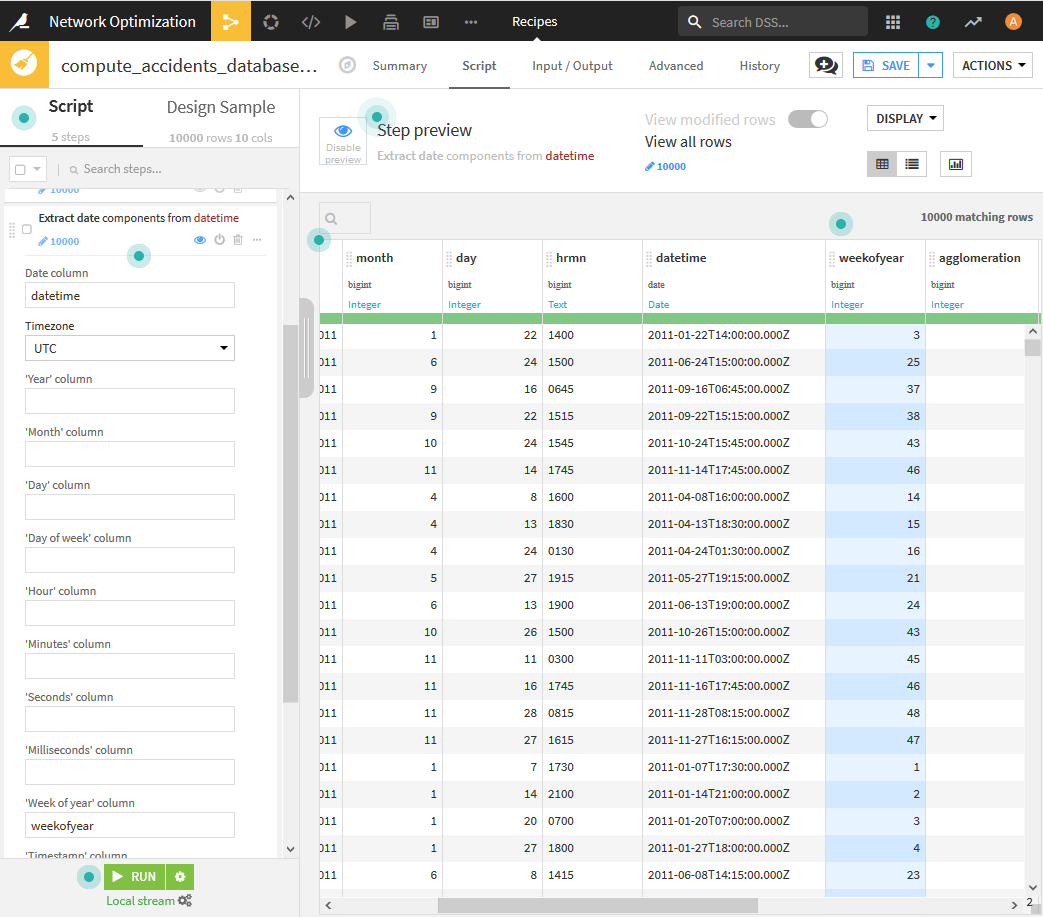
- Extract date componentsを用いて、datetimeからをdate型に変換します。表示される画面で「yyyy-MM-ddZ」を選択し、週番号であるweek of yearの項目を作成します。
-
地理情報の変換
-
latitude,longitudeの項目をWGS84座標系に変換します。そのために、まず、これらの項目の値を100,000で割って、その後、データ型をbigintからdoubleに変更します。 - Create GeoPoint from lat/lonを用いて
geopointを作成します。 - Remove rows where cell is emptyを用いて、
geopointが空の行を削除します。 - Filter rows/cells on valueを用いて、
geopointがPOINT(0 0)の行を削除します。
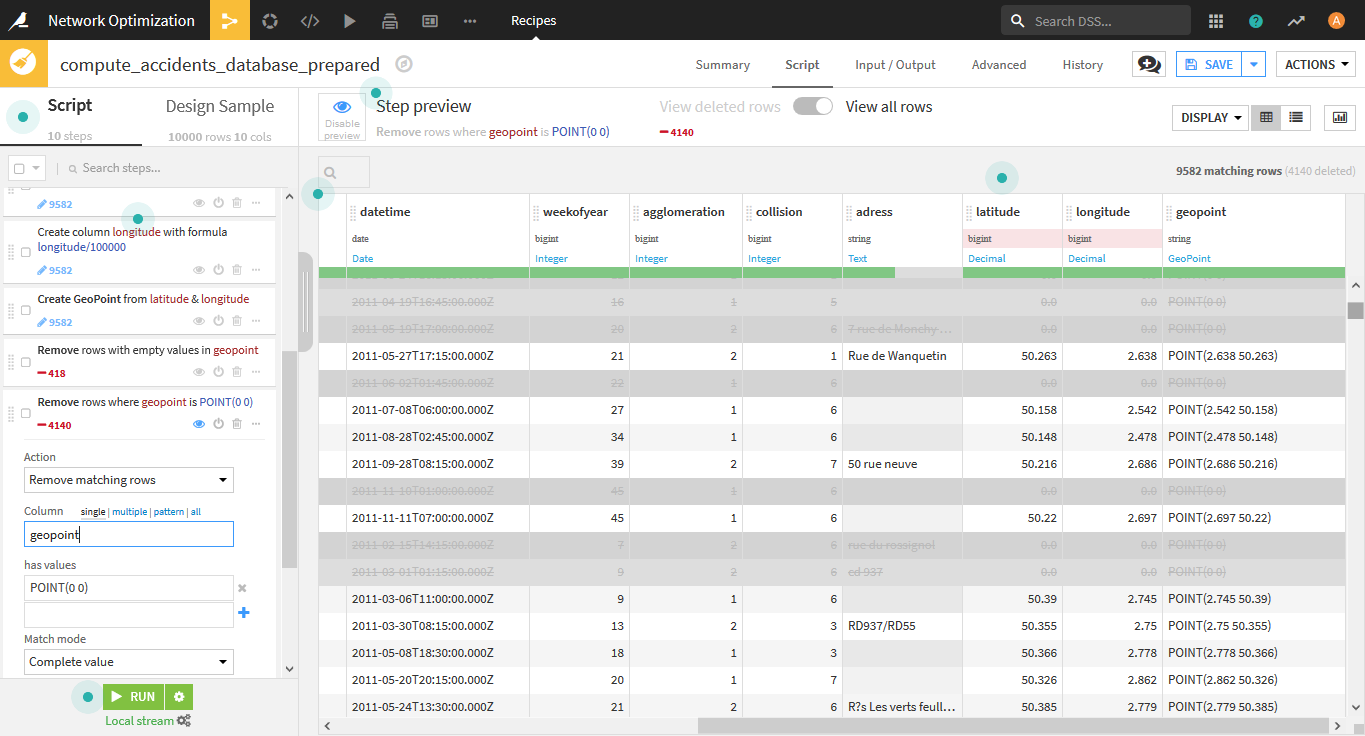
- Reverse-geocodeを用いて、
geopointから、city(level8), department(level6), region(level4), country(level2)を作成します。その時、「_enName」のサフィックスがついている列ができるので、削除します。
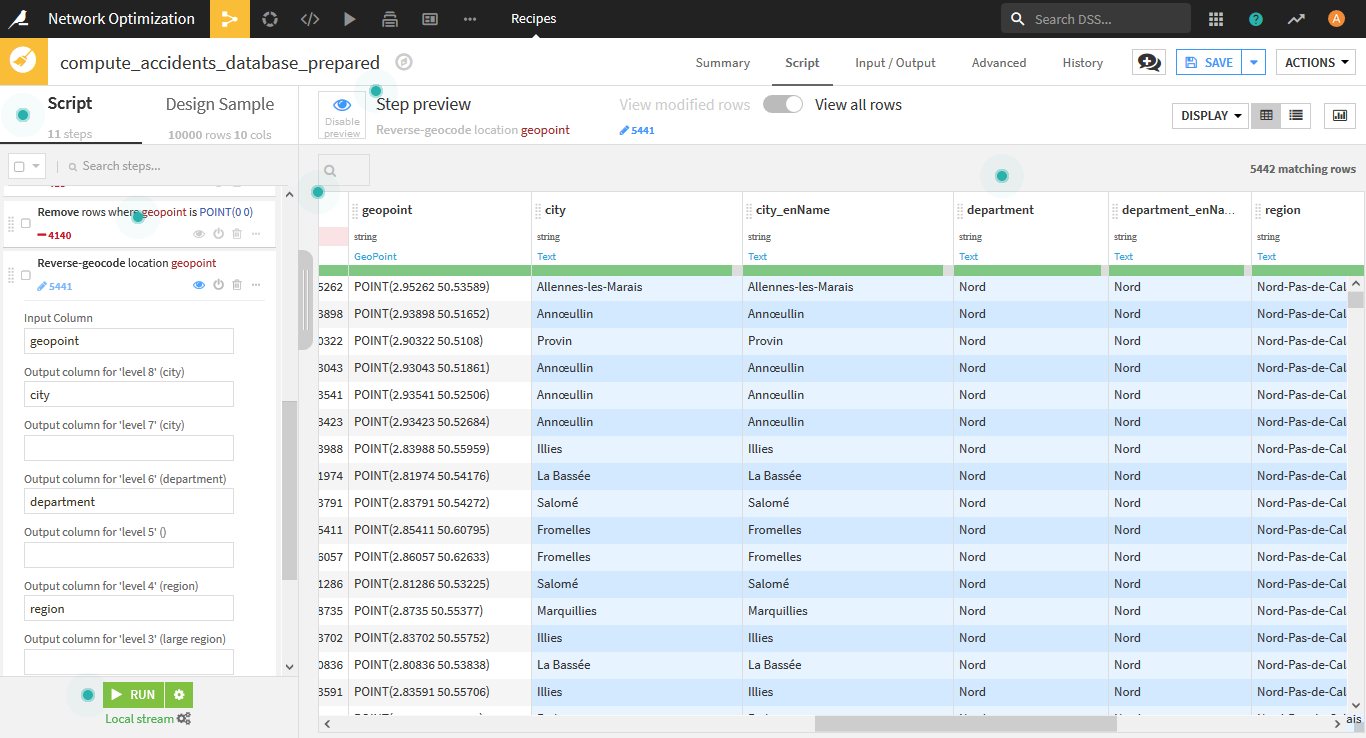
- Filter rows/cells on valueを用いて、countryが「France」以外の国の行は削除します。
ここまでの操作が完了したら、[RUN]ボタンを押下します。これで、フランスの自動車事故の日付と時刻、地理情報のクレンジングが完了しました。
-
Networkデータ
rental_agencies.csv.zipをアップロードします。データセットの名前は、rental_agenciesとします。
ここでは、行ごとに住所と郵便番号に対応する緯度経度を作成します。
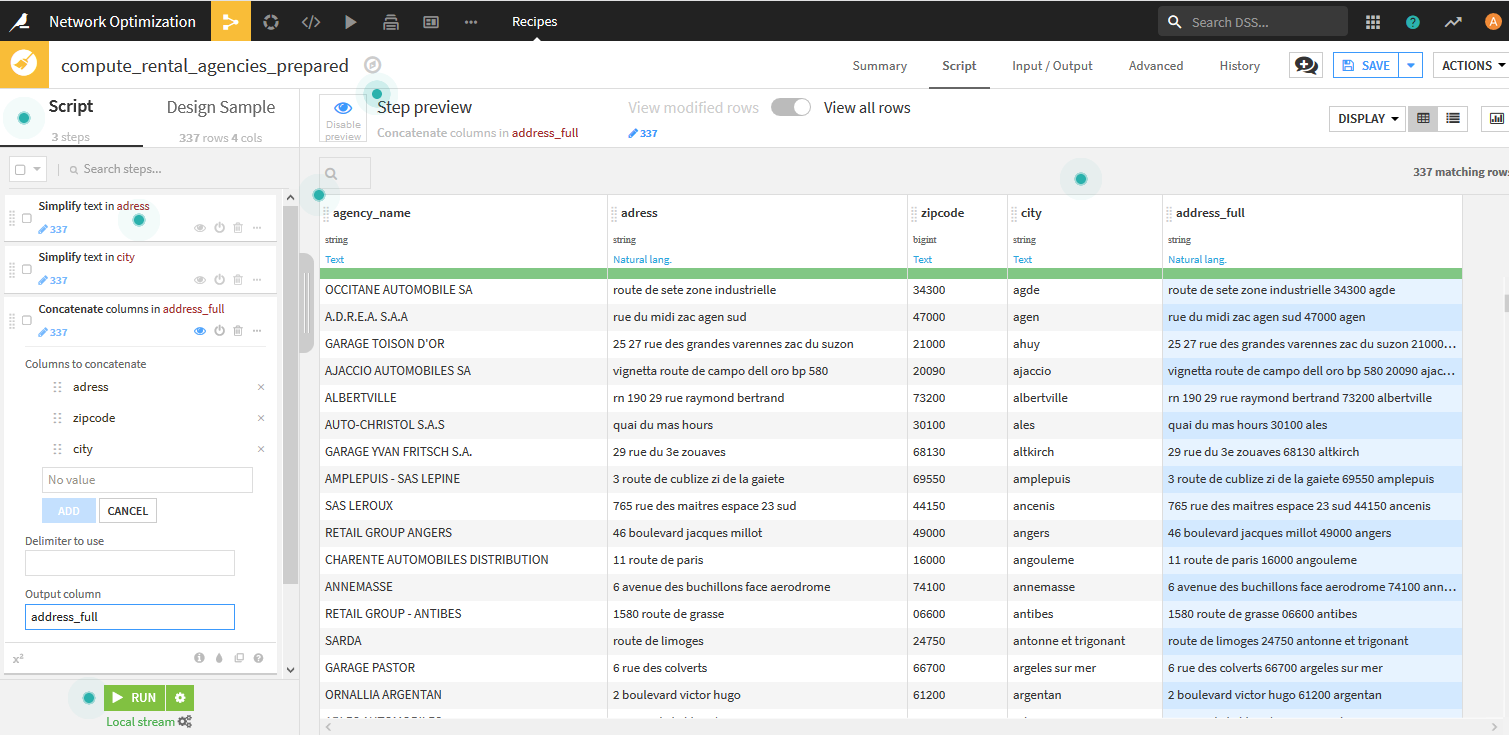
- Simpify textを用いて、
address、cityを正規化(Normalize text)します。 - Concatenate columnsを用いて、
address、zipcode、cityを半角スペースで連結してaddress_fullを作成します。
- Geocodeを利用して、各レンタル代理店の緯度経度を作成します。ここでは、Map Quest Open APIを指定して緯度経度の情報を取得しています。
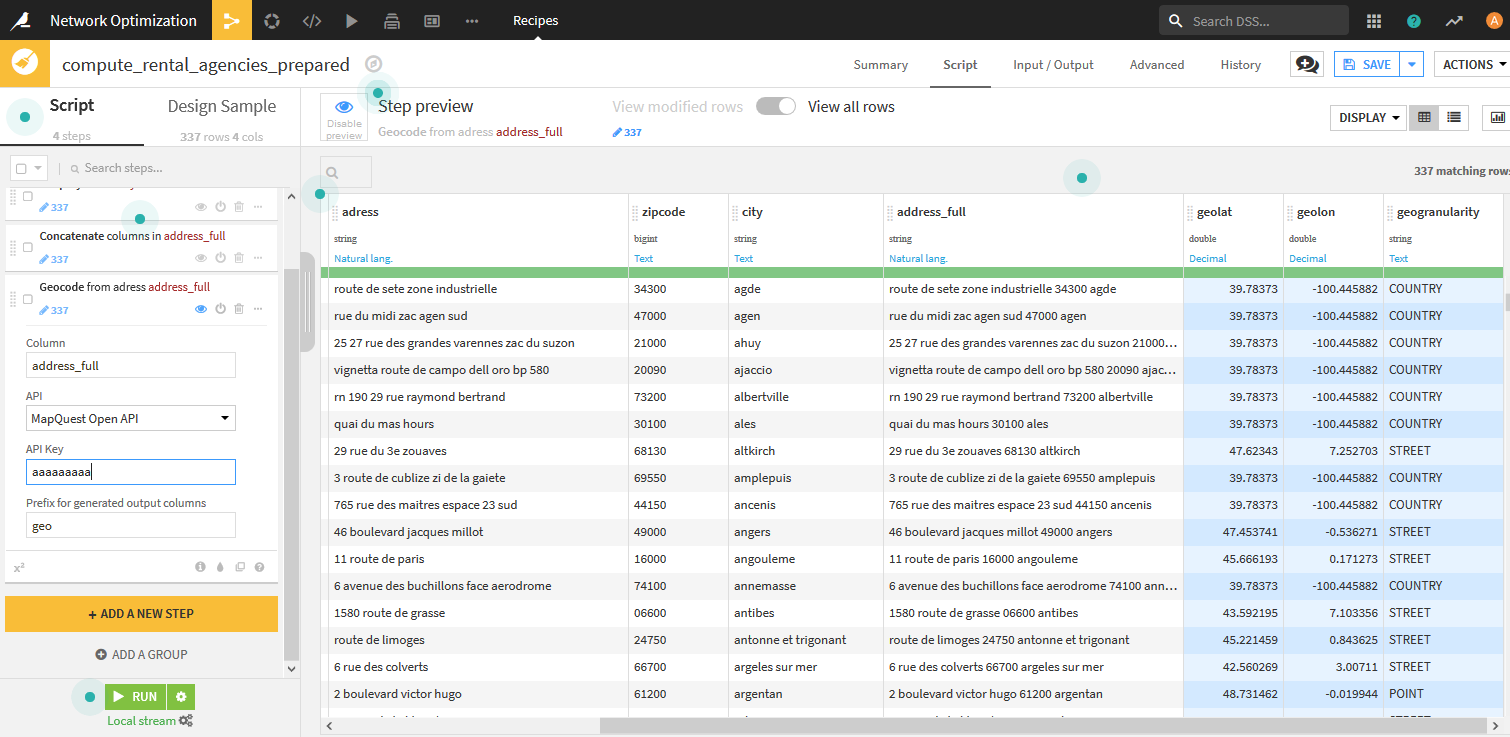
注意 Geocoder pluginはプロキシには対応していないようです。。。プロキシのないネットワーク環境で実施してみてください。
ここまでの操作が完了したら、[RUN]ボタンを押下します。これで、代理店の地理情報のクレンジングが完了です。
Garageデータ
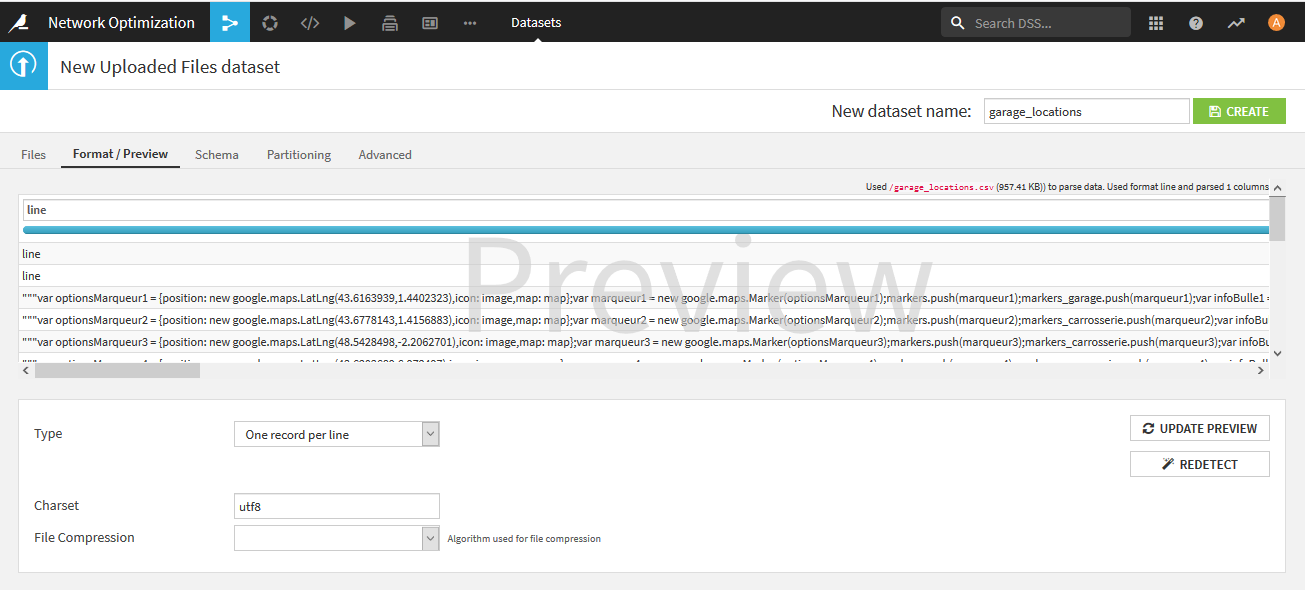
- garage_locations.csv.zipを[Upload your files]でアップロードします。
アップロードすると、ファイルフォーマットが認識できないというエラーが表示されるので、[FORMAT SETTINGS>]ボタンをクリックした後、[Type]で「One record per line」を選択します。データセットの名前は、garage_locationsにします。
- Prepareレシピを利用してデータを加工します。
- まず、ガレージ名を抽出します。
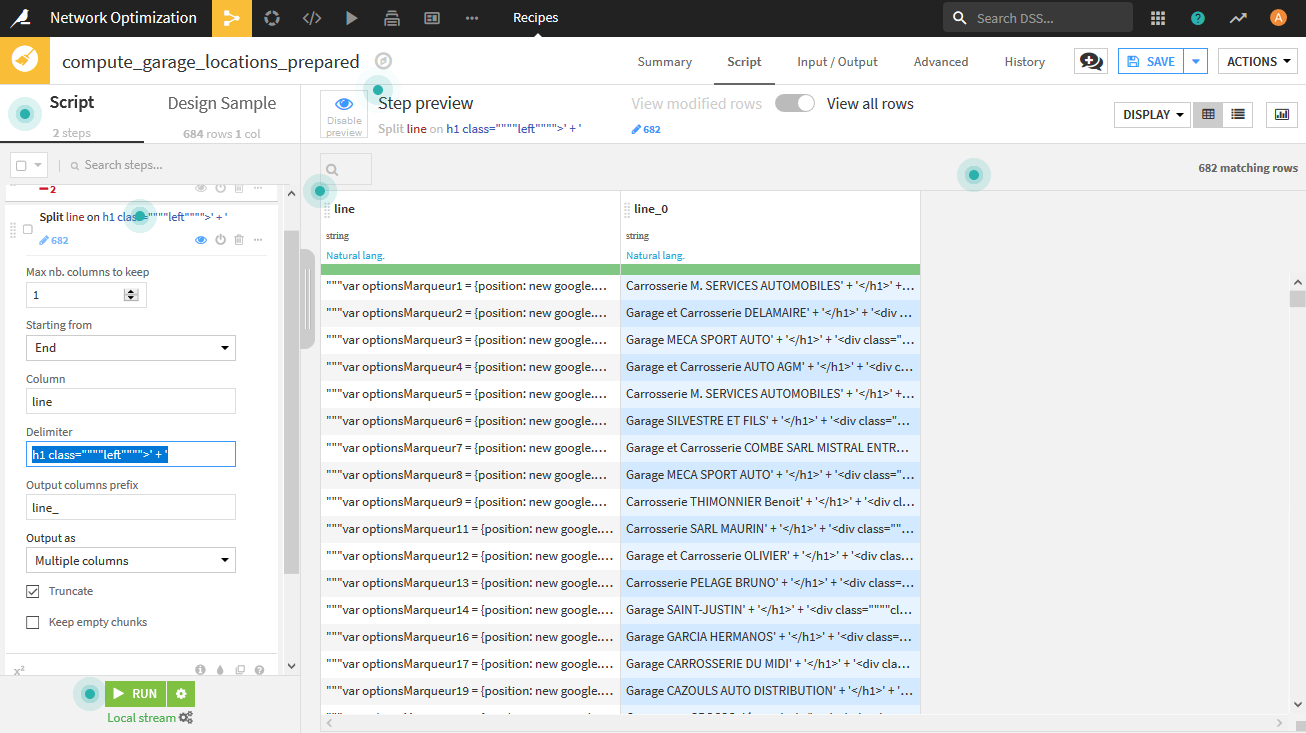
Filter rows/cells on valueを用いて「line」という行を削除します。 - 最初のセルを右クリックして[Show complete value]をクリックすると、値全体を見れます。ここでガレージ名を抽出するために、Split columnを用いて、次を指定します。
- delimiterに
h1 class=""""left"""">' + ' - Trancateをチェック
- Starting fromを「End」を指定
- delimiterに
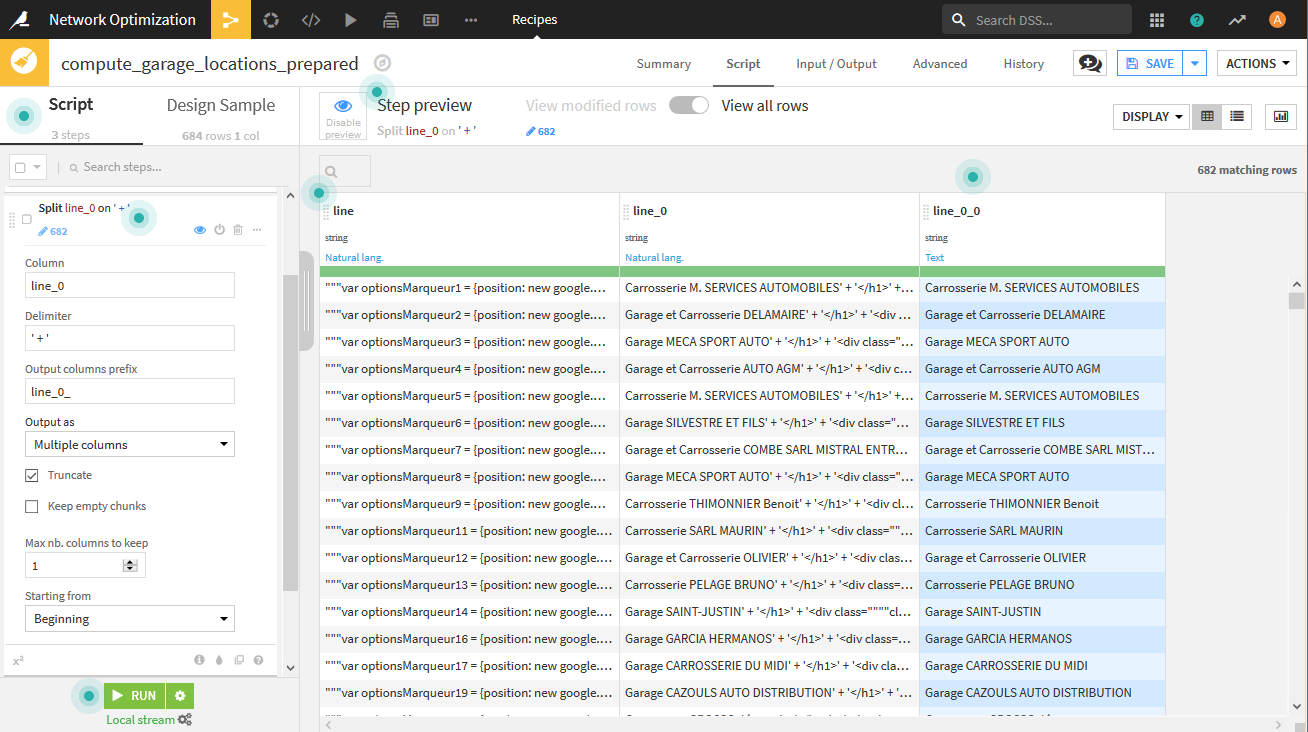
- 次にline_0に対して、Split columnを用います。次を指定します。
- delimiterに
' + ' - Trancateをチェック
- delimiterに
- line_0を削除して、line_0_0の列名をnameに変更します。
- ガレージ名を抽出するための処理をひとまとめにします。最後から4つのステップをチェックして、右クリックして表示される[Group]をクリックします。グループ名を「Parse garage name」とします。
- 緯度経度の抽出も同じ要領で抽出します。
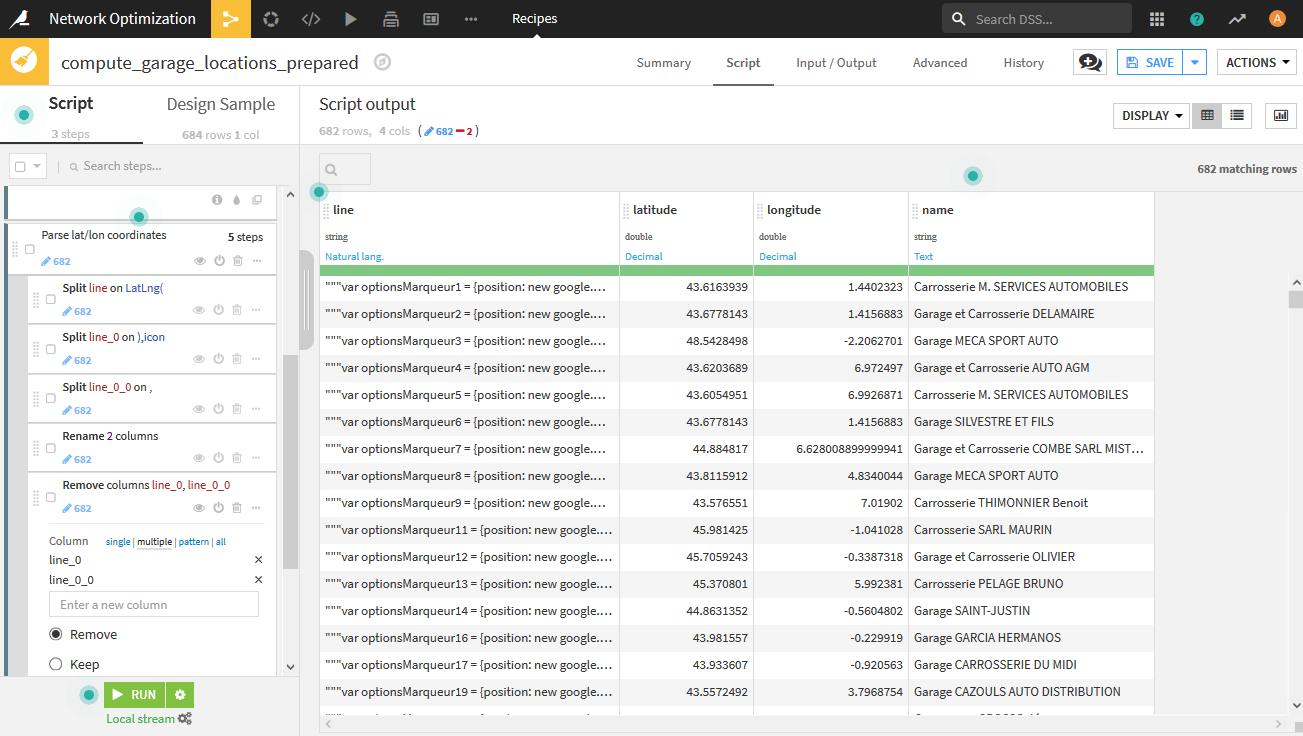
- Create GeoPoint from lat/lonを用いて
latitude,longitudeからgeopointを作成します。 - Reverse-geocodeを用いて、地理情報を取得します。ここでは、city(level8), department(level6), region(level4), country(level2)を取得します。「_enName」を含む列やlineを削除して必要な列のみ残します。
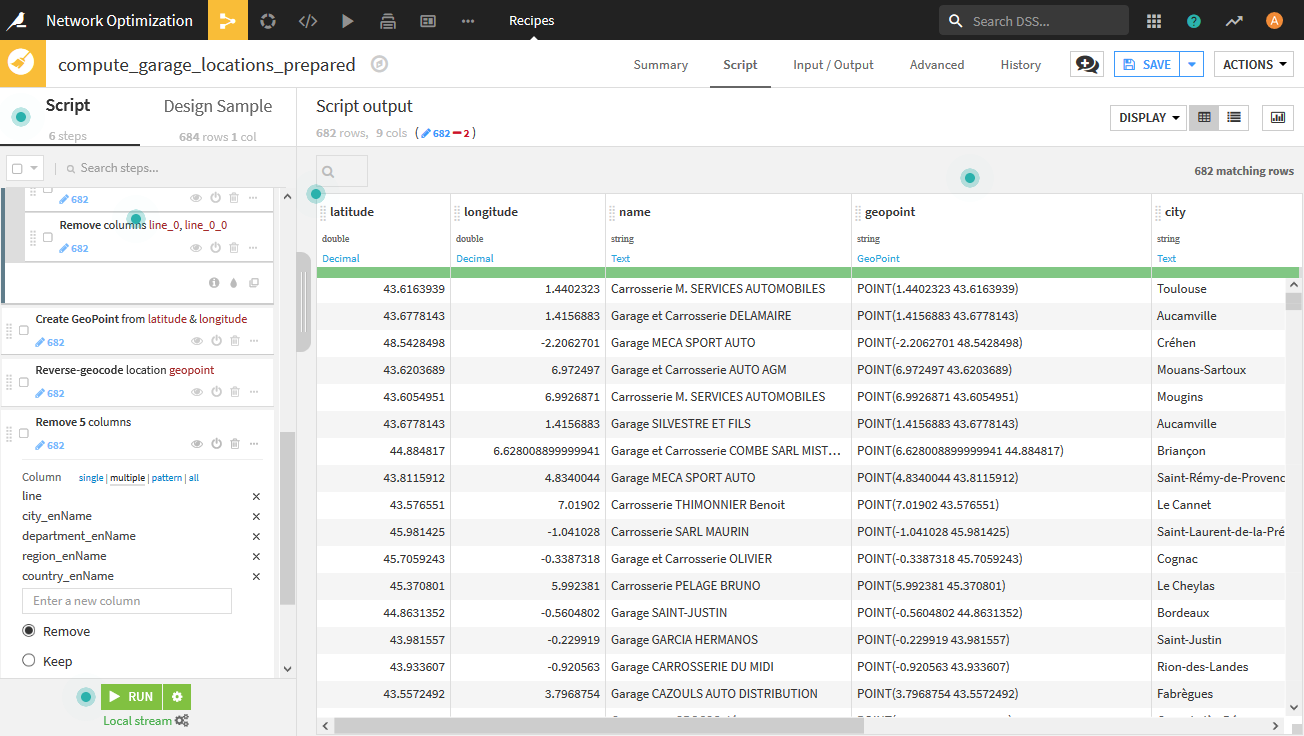
ここまでの操作が完了したら、[RUN]ボタンを押下します。これで、パートナー(ガレージ)の地理情報のクレンジングが完了です。
地理情報によるデータの結合
ここでは、自動車事故が発生した箇所から最寄りの代理店や提携可能性のあるパートナー(ガレージ)をもとに、ステーション(代理店とパートナー候補のガレージ)毎に必要とするレンタカー台数と、地域毎に必要とするレンタカー台数を見積もります。
これを行うために、3つのデータを統合します。
統合する際、事故の発生個所から最寄りの代理店、およびパートナー(ガレージ)候補を結びつけます。
- PrepareレシピのGeo-joinプロセッサを用いて、データセットaccidents_database_preparedとrental_agencies_preparedを統合し、accidents_joinedを作成します。
- 同様に、Geo-joinプロセッサを用いて、accidents_database_preparedとgarage_locations_preparedを統合します。
ここまでの操作が完了したら、[RUN]ボタンを押下します。データが統合されます。
分析とビジュアライゼーション
チャート
作成するチャートとして次があります。
| チャート | 内容 | 種類 |
|---|---|---|
| Distribution of accidents by hour of the day | 日時毎の事故発生の分布 | histogram |
| Distribution of accidents by day of week and year | 曜日毎の事故発生の分布 | histogram |
| Weekly comparison of accidents count on the past 4 years | 過去4年間の事故発生数の週数毎の比較 | line chart |
| Geographic distribution of accidents, filtering out for low collision scores | 地図上での事故発生分布 | scatter map |
| Choropleth of number of accidents | 事故発生数のコロプレスマップ | administrative map |
| Choropleth of average distance between accidents and agencies | 事故発生場所と代理店の間の距離の平均値のコロプレスマップ | administrative map |
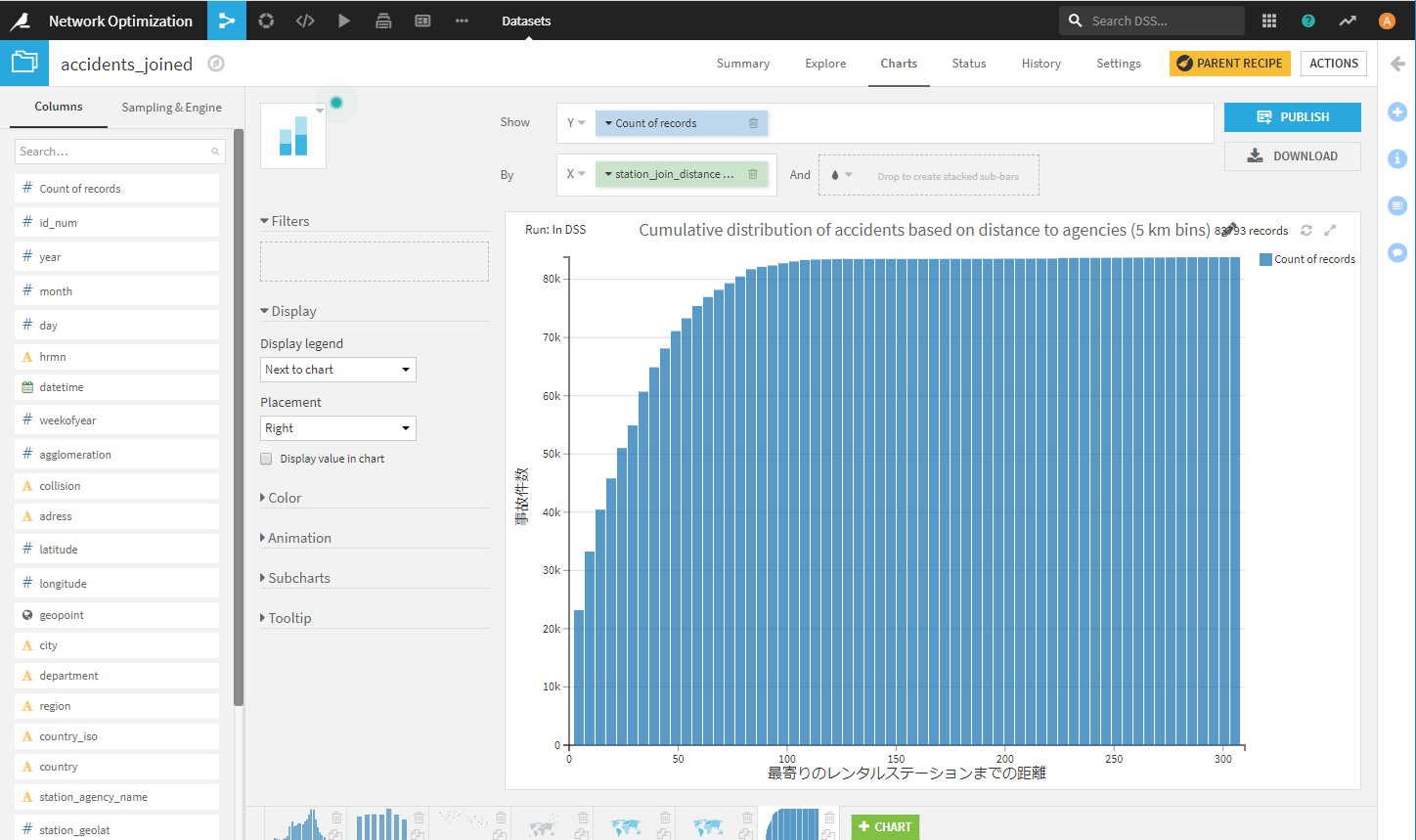
| Cumulative distribution of accidents based on distance to agencies (5 km bins) | 代理店までの距離に基づく事故の累積分布 | stacked bar chart |
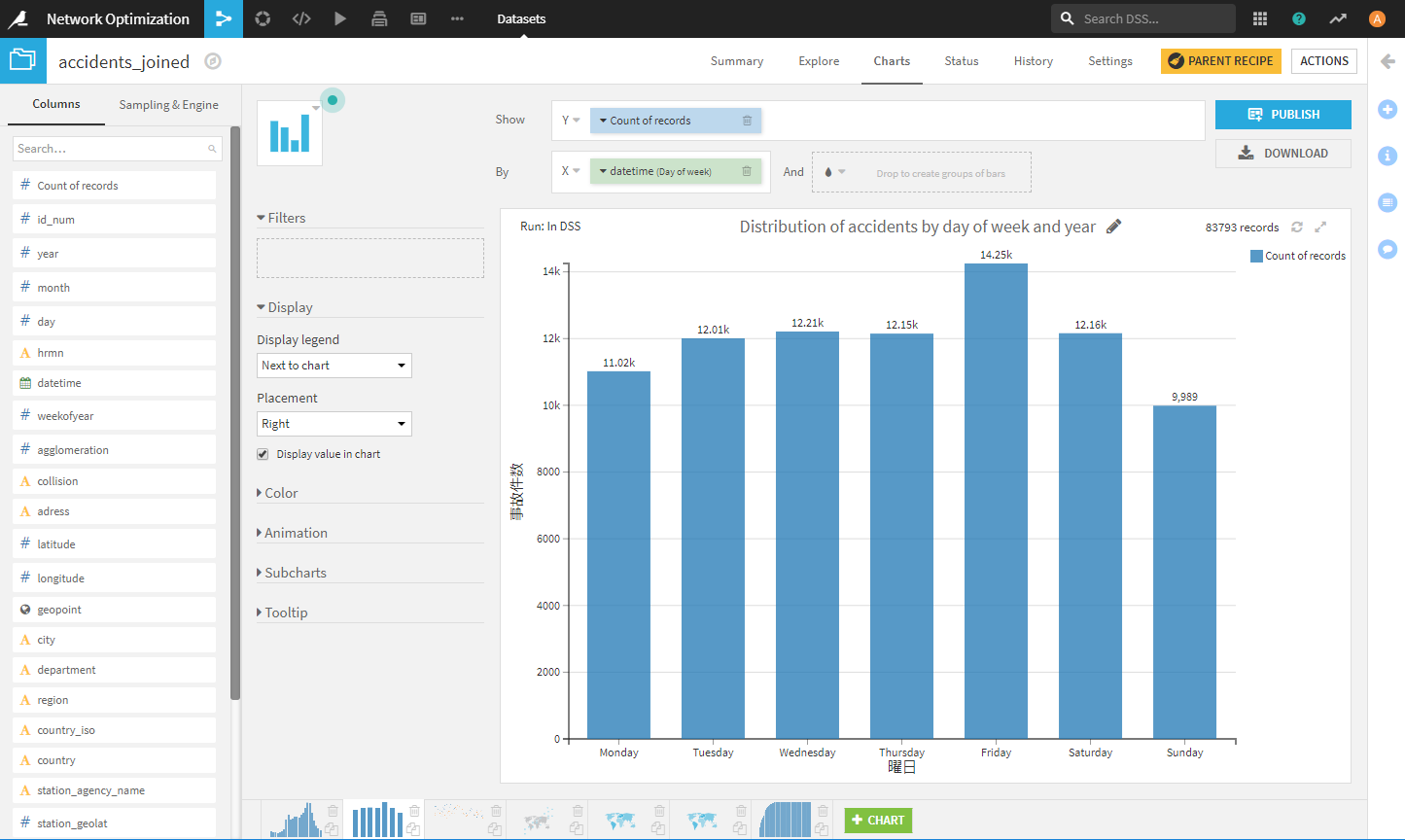
例えば、曜日毎の事故発生の分布のグラフは次のようになります。
代理店までの距離に基づく事故の累積分布のグラフを見ると、代理店から15km以上離れた場所で多くの事故が発生していることがわかります。
次に、パートナー(ガレージ)と組んだ場合にどのような効果が得られるか確認します。
具体的には、事故発生個所から最も近いのがパートナー(ガレージ)候補である場合、そことパートナーを組んだと仮定して、事故発生場所から、どれぐらい近い距離で対応できるかを見ます。
上記を進めるのに、accidents_joinedデータセットを選択して、画面右側の[LAB]ボタンをクリックして、分析をします。
Formulaを使って、次の2つの項目を作成します。
-
effective_network
事故発生場所から最も近いのが代理店かパートナー(ガレージ)かを示すフラグ
if(station_join_distance > 15 && garage_join_distance < station_join_distance,
"garage","station")
-
effective_distance
最も近い代理店/パートナーから事故発生場所までの距離
if(effective_network=="garage",garage_join_distance,station_join_distance)
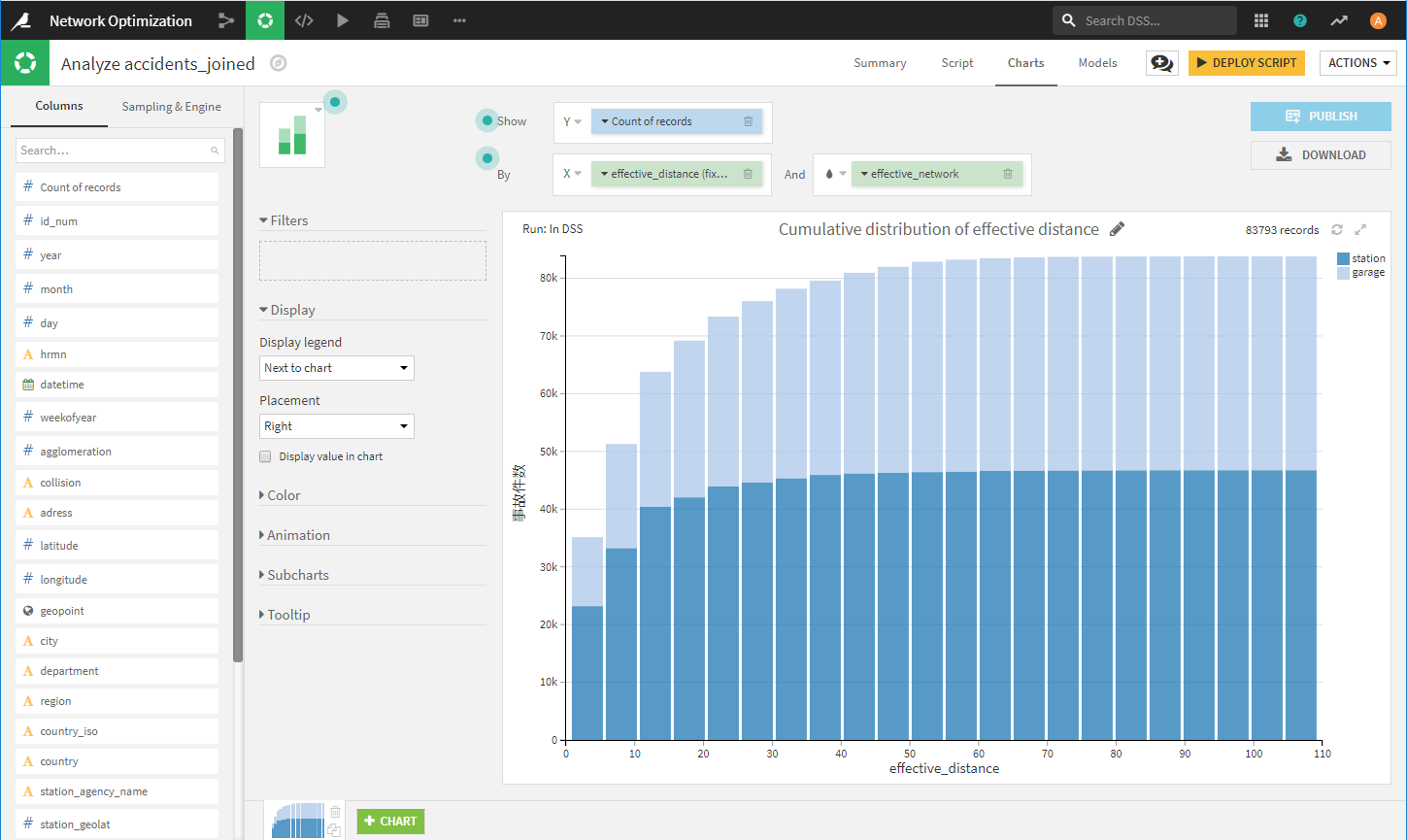
最も近い代理店/パートナーから事故発生場所までの距離をもとに、事故の累積分布のグラフを作成します。
パートナーを組むことで、事故発生場所からより近い位置から対応できるようになるのが分かります。例えば、15km以内で、パートナーを組まない場合は約40%のカバー率であるのに対し、パートナーを組むことによって約64%の事故をカバーできるようになることが分かります。
画面右上の[DEPLOY SCRIPT]ボタンをクリックすると、このデータ加工したデータがフローに登録されます。
Webapp
事故発生場所と代理店、またはガレージの間の距離を表示するデモをWebappで作成します。
Dataikuでは、デモアプリのための環境を準備しなくても、簡単にデモアプリを作成することができます。
- 上部のバーから[>]をクリックして、新しいWebアプリを作成します。
- Code Webapp
- Starter code for creating map visualizations
- [Settings]タブでpreparedがつくデータセットに「Read data」権限をつける
- HTMLタブで、次のコードを記載します。
<!-- Body of your app -->
<div class="container">
<div class="row">
<div class="col-md-9" id="map"></div>
<div class="col-md-3"> <strong>Description</strong>
<p>
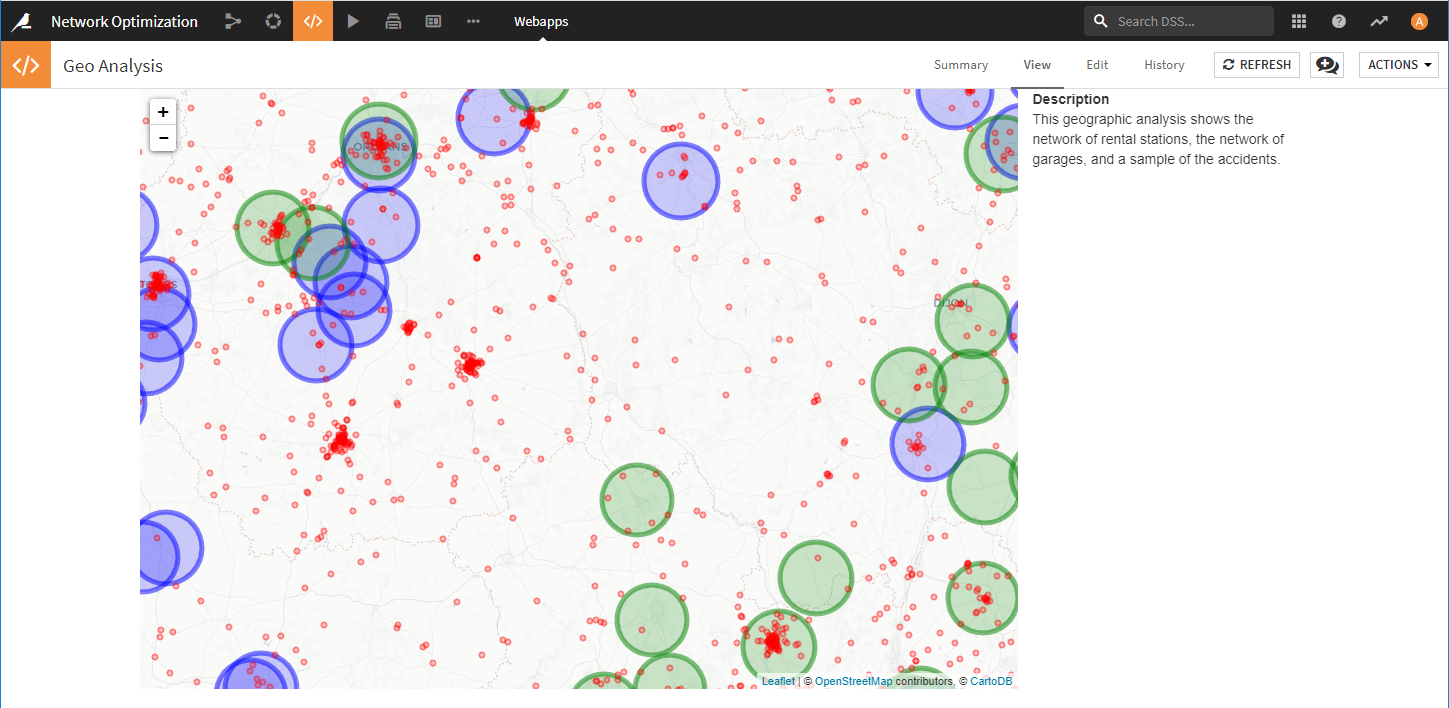
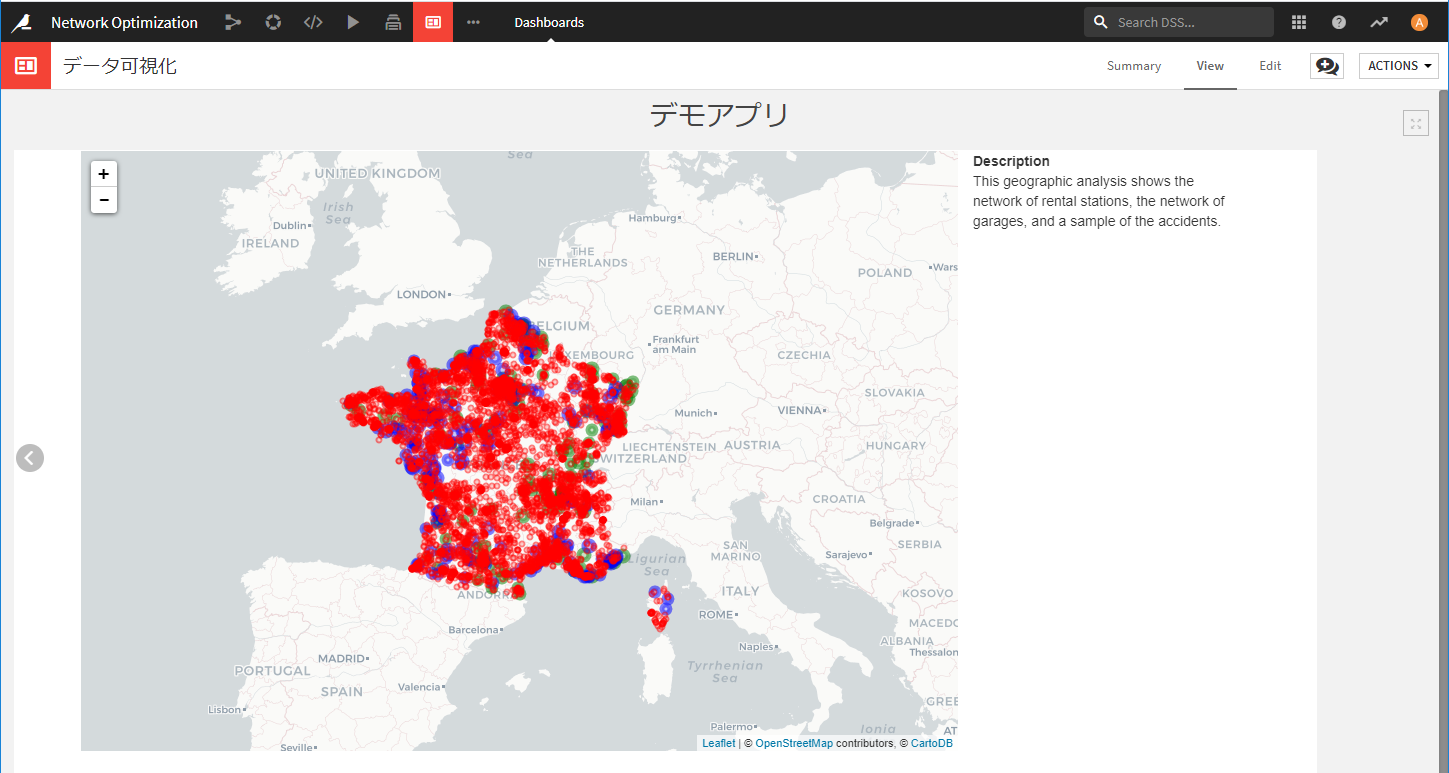
This geographic analysis shows the network of rental stations, the network of garages, and a sample of the accidents.
</p>
</div>
</div>
</div>
- JSタブで次のコードを記載します。もともと記載されている
dataiku.fetchは削除してから、下記のコードを記載します。- 代理店を緑丸(半径15km)で表示します。
dataiku.fetch('rental_agencies_prepared', {
sampling : "head",
limit : 20000
}, function (df) {
// Add a map marker for each row on the dataset
// Each marker is a circle. The size of the circle varies with the 'size' column values
var nbRows = df.getNbRows();
for (var i = 0; i < nbRows; i++) {
var record = df.getRecord(i);
// Replace by your own column names here
var lat = parseFloat(record["geolat"]);
var lon = parseFloat(record["geolon"]);
var name = record["agency_name"];
var city = record["city"];
if(isNaN(lat) || isNaN(lon)) continue;
// Radius of the marker is in meters
var radius = 15000;
var marker = new L.circle([lat, lon], radius, {
color: 'green',
fillColor: 'green',
fillOpacity: 0.2
}).bindPopup("Name: <strong>" + name + "</strong>");
marker.addTo(map);
};
});
- ガレージを青丸(半径15km)で表示します。
dataiku.fetch('garage_locations_prepared', {
sampling : "random",
limit : 200
}, function (df) {
// Add a map marker for each row on the dataset
// Each marker is a circle. The size of the circle varies with the 'size' column values
var nbRows = df.getNbRows();
for (var i = 0; i < nbRows; i++) {
var record = df.getRecord(i);
// Replace by your own column names here
var lat = parseFloat(record["latitude"]);
var lon = parseFloat(record["longitude"]);
var name = record["name"];
// Radius of the marker is in meters
var radius = 15000;
var marker = new L.circle([lat, lon], radius, {
color: 'blue',
fillColor: 'blue',
fillOpacity: 0.2
}).bindPopup("Name: <strong>" + name + "</strong>");
marker.addTo(map);
};
});
- 事故発生場所を赤丸で表示します。
dataiku.fetch('accidents_database_prepared', {
sampling : "random",
limit : 10000
}, function (df) {
// Add a map marker for each row on the dataset
// Each marker is a circle. The size of the circle varies with the 'size' column values
var nbRows = df.getNbRows();
for (var i = 0; i < nbRows; i++) {
var record = df.getRecord(i);
// Replace by your own column names here
var lat = parseFloat(record["latitude"]);
var lon = parseFloat(record["longitude"]);
var collision = record["collision"];
// Radius of the marker is in meters
var radius = 1;
var marker = new L.circle([lat, lon], radius, {
color: 'red',
fillColor: 'red',
fillOpacity: 0.2
}).bindPopup("Number of collisions: <strong>" + collision + "</strong>");
marker.addTo(map);
};
});
そうすると、代理店・ガレージの場所、および事故発生場所がマッピングされ、どの代理店・ガレージが15km以内でどの程度の事故をカバーできるか確認できます。
キャパシティプランニング
地域レベルでの分析
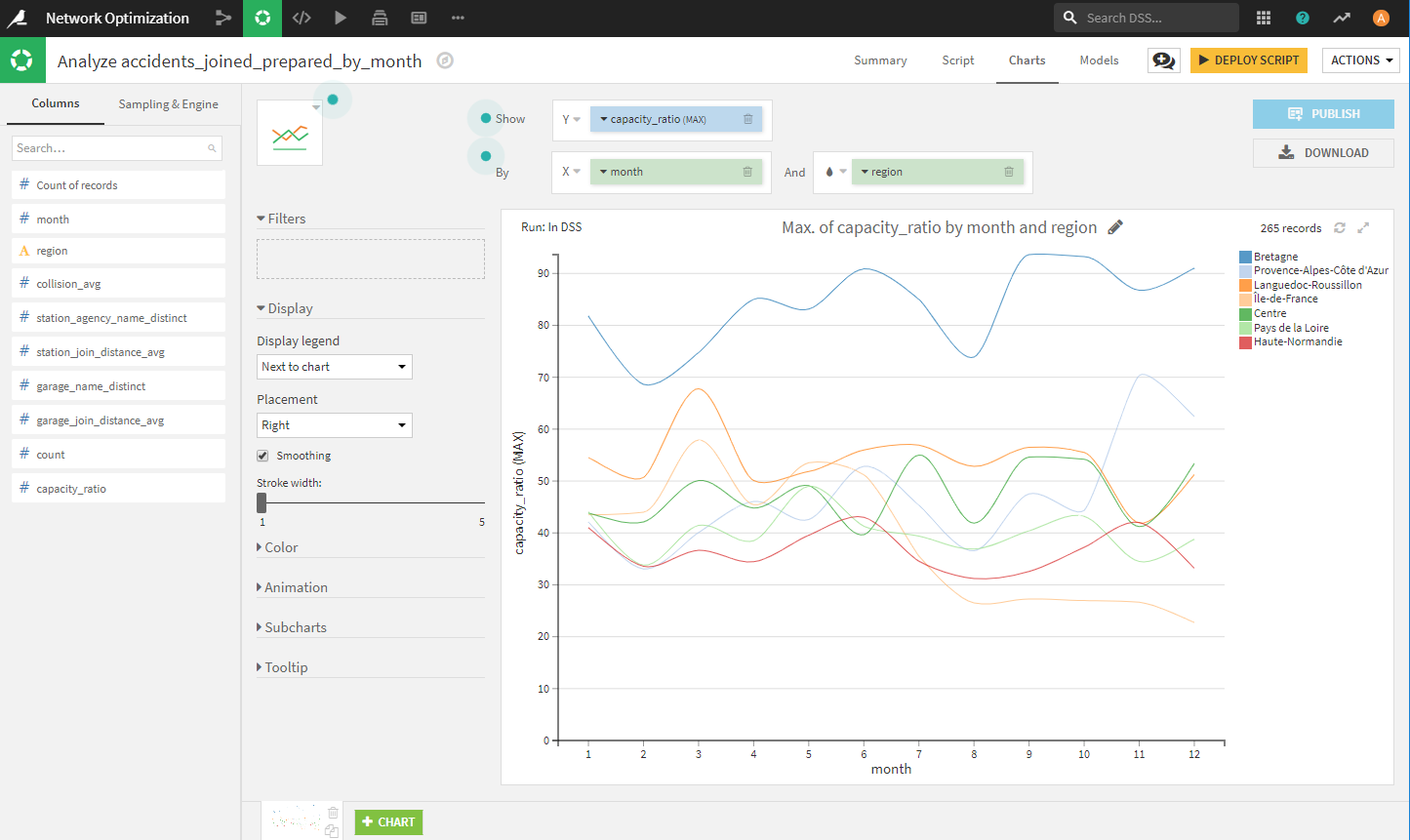
2012年より後のデータを用いて、月毎地域毎に代理店、またはガレージから事故発生場所までの距離がどのようになっているのか分析します。
[LAB]を使ってmonth、regionをキーとして、代理店、ガレージから事故発生場所までの距離の平均値を算出し、可視化します。
これにより、「Bretagne」など1店舗当たりに網羅する事故数(capacity_ratio)が多い、上位7地域を確認することができます。これらの地域で積極的にパートナーを組んでいく必要があることが分かります。
[DEPLOY SCRIPT]ボタンをクリックして、この分析結果をフローに登録します。
ステーションレベルの分析
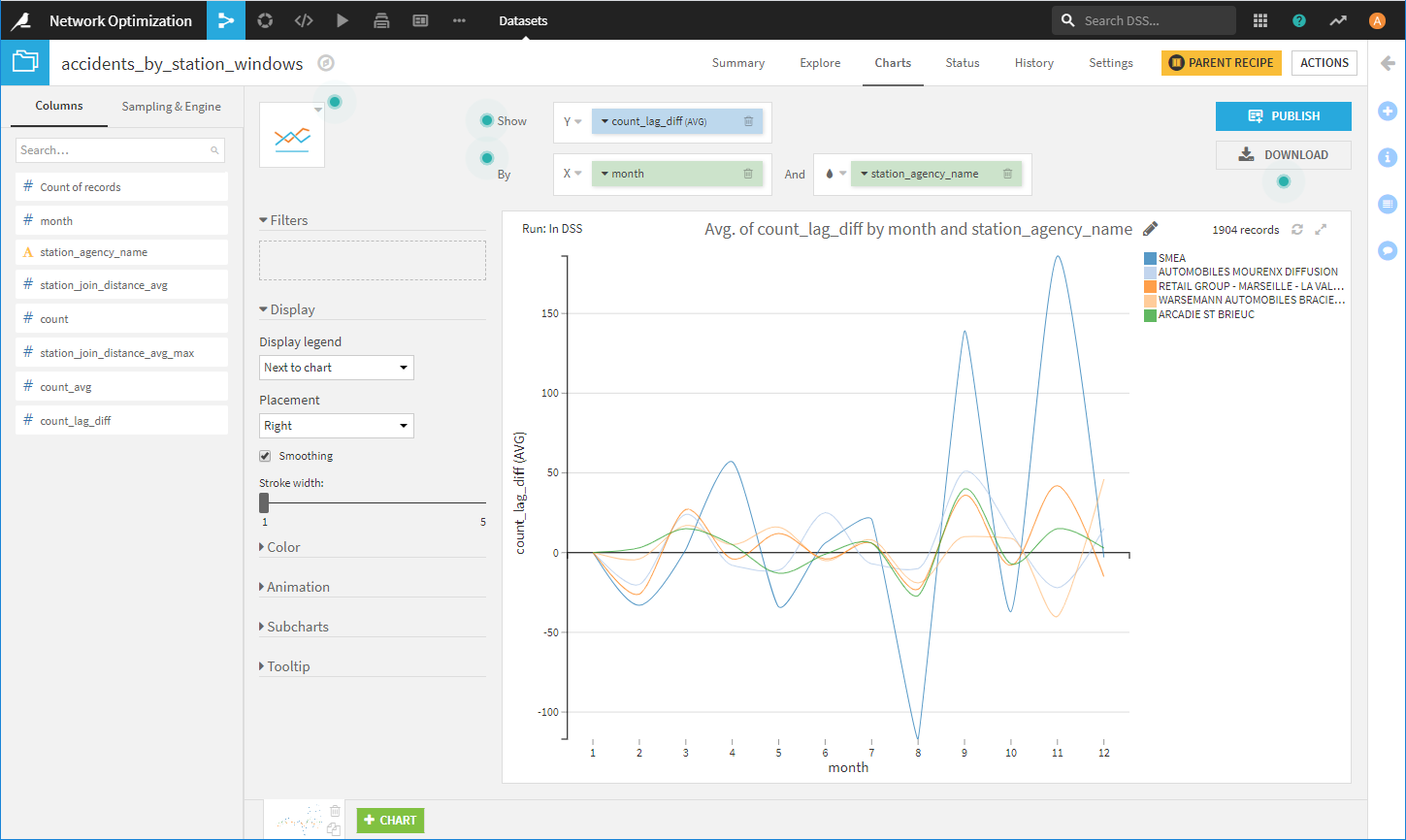
需要が多く負荷の高い代理店を見つけます。
具体的には、[LAB]を使ってmonth、station_agency_nameをキーとして、代理店、ガレージの月毎の負荷値と、その負荷値の3か月の移動平均を算出して確認します。
ダッシュボード
先ほど作成したグラフをダッシュボードに貼り付けて、他の人と分析結果を共有するためのダッシュボードを作成します。
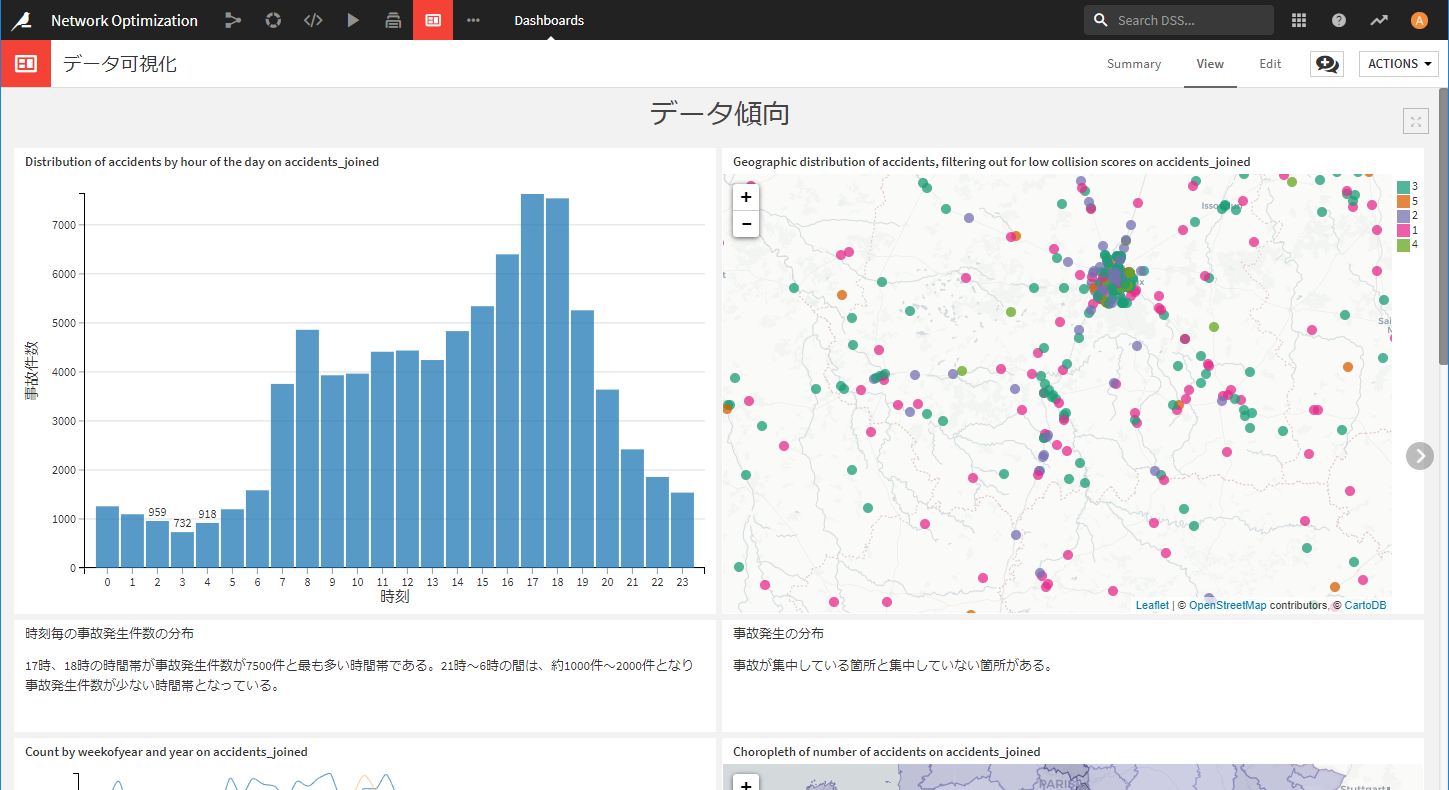
また、Webappもダッシュボードに貼り付けて見せることができます。
さいごに
Dataikuを使って次のことをして、レンタカー会社がパートナーとするガレージを選定する際の材料となる情報を分析しました。
- パートナーを組むことで、どの程度の効果があるか把握できるグラフを作成
- どこの地域や代理店のレンタカー需要が多いか把握するためのダッシュボードやデモを作成
地理情報を活用して、事故発生場所から最も近い代理店やガレージを紐づけるなどのデータ加工や項目追加、データの統合が簡単にできるところ、またグラフやダッシュボード、デモアプリを簡単に作成できるところはDataikuのよさだと感じました。
よかったら、みなさんもDataikuを利用してみてください。