はじめに
はじめまして!
この記事は初心者が初めてRAGに挑戦した記録です。
せっかくなので初めて投稿してみました!
温かい目で読んでいただけますと幸いです。
「RAG?」から始まった、AWSで作るRAG PoCの話
この記事では、
RAGをこれから試してみたい方向けに、
AWSでPoCを実施する際の検討ポイントや調査した内容を紹介します。
…ある日、こんなお話がありました。
💬 発端となったお話(要約)
「例えば書籍の電子データとかWebサイトの情報のみを元に、質問したらAIが回答を生成するようなシステムって作れるの?」
「どの情報を参照してAIが答えたのかもわかると嬉しいね」
なるほどつまり…
- 特定の内容を知識として使いたい
- 質問に対してAIが自然文で回答してほしい
- 参照元(根拠)を確認できるようにしたい
ということか。
💡「これ…RAGってやつか?」
調べてみるうちに
「これってRetrieval-Augmented Generation(RAG)なんじゃない?」
ってなりました。(恥ずかしながら本件で初めて知りました)
生成AIにいきなり答えさせるのではなく、
事前に用意した情報を検索してから、その内容をもとに回答を作る仕組み。
しかも
「どの文書を参照したかを見せたい」という要件、
RAGの王道ユースケースみたいですね。
ということで…
🚀 PoCとして作ってみることにした
まずは本格導入ではなく、 PoCとして、小さくRAGを作ってみることにしました。
- データはまず手元のドキュメント
- クラウド上に構築してみる(慣れているAWSを使う)
- 目的は「仕組みがちゃんと成立するか」を確認すること
調べながら、「検索どうする?」「生成AIはどれ?」という技術選定フェーズに入ります。
今回のPoCでは、以下を重視して選定しました。
- 参照元を提示できること
- 検索精度
- 早く試せること(実装コストの低さ)
🧠 RAGとは?(おさらい)
RAGとは、
「検索」+「生成AI」
を組み合わせた仕組みです。
ざっくりな流れは
- ユーザーが質問する
- 検索エンジンで「用意しているドキュメント群」の中からヒットする情報を探す
- 見つけた文書を生成AIに渡す
- 生成AIが内容を踏まえて文章を生成
- 根拠付きの回答を返す
この仕組みのおかげで、
- 書籍や社内資料など、AIが元々知らない情報も扱える
- 情報補完できるため、ハルシネーションを抑制できる
- 「どの文書を参照したか」を表示できる
というメリットがあります。
🔍 技術選定_検索エンジンについて
まず悩んだのが 検索エンジン問題。
AWSでRAGをやるなら、主にこの3つが候補になりました。
候補1:Amazon Kendra
一言で表すと、「検索が強い」
✅ メリット
- 自然言語検索の精度が高い
- S3上のPDFやWebサイトをそのまま検索できる
- 原本(参照元)を返しやすい
❌ デメリット
- コストが高め
- ベクトル検索の自由度が低い
「参照元を見せたい」という要件にはかなり相性が良さそう
候補2:Amazon Bedrock Knowledge Bases
一言で表すと、「RAGを最短で作れる」
✅ メリット
- チャンク化・Embedding・検索を自動でやってくれる
- Bedrockとの連携が楽
❌ デメリット
- 検索の中身を細かく制御できない
- 検索単体用途には向かない
うーん、検索能力を重視したい…
候補3:Amazon OpenSearch Service
一言で表すと、「自由度が高い」
✅ メリット
- ベクトル検索+キーワード検索が可能
- スコアリングや検索条件を自由に設計できる
- 拡張性が高い
❌ デメリット
- 実装・運用コストが高い
- まずは動かしたい場合には不向き
PoCには向いていなさそう…
選択
ということで、今回はAmazon Kendraを選びました。
選定理由
- 様々なデータソースを扱える(S3、Webサイトなど)
- 検索精度を重視したかった
- コスト面は無料枠でカバー
🤖 技術選定_生成AIについて
選択
調べた限りだとAmazon Bedrockの使用が一般的(一択?)だと思います。
Amazon Bedrockは、AWS上で複数の生成AIモデルを簡単に利用できるサービスです。
その中でモデルは豊富な選択肢があります。
今回はAmazon Nova 2 Liteを選びました。
選定理由
- Bedrockからすぐ使える
- PoCとしては十分な性能とコスト感
✅ 結論:今回の構成
最終的に、今回のPoCでは
Amazon Kendra + Amazon Bedrock(Nova 2 Lite) にしました。
☁️ サーバレスなシステムにしてみた
今回のPoCでは、
できるだけマネージドサービスを使って、サーバレスなシステムにすることを
意識しました。
理由はシンプルで、
- インフラ運用を極力したくない
- PoCなので、まずは早く動くものを作りたい
- サーバレスっていいよね
という感じです。
📦 データソースは S3 に全部突っ込む
まず、AIに参照させたいドキュメントは Amazon S3 にまとめて配置しました。
- Kendra のデータソースとして簡単に連携できる
- あとからファイルを追加・差し替えしやすい
「とりあえずS3に置く」は、PoC用途との相性も良かったです。
✏️ ロジックは Lambda で実装
アプリケーション側のロジックは AWS Lambdaで実装しました。
Lambda に任せた役割はこんな感じです。
- ユーザーからの質問を受け取る
- Kendraに検索クエリを投げる
- 検索結果を整形する
- Bedrockに渡して回答を生成する
- 回答と参照元をまとめて返す
🌐 エントリーポイントは API Gateway
外部から呼び出すための入り口として Amazon API Gatewayを使用しました。
- HTTP API としてシンプルに公開できる
- Lambda とそのまま連携できる
- 認証や制限も後から追加しやすい
結果として、
API Gateway → Lambda → Kendra(+S3) / Bedrock → Lambda → API Gateway
という、サーバレスな構成になりました!
構成図も作ってみました↓
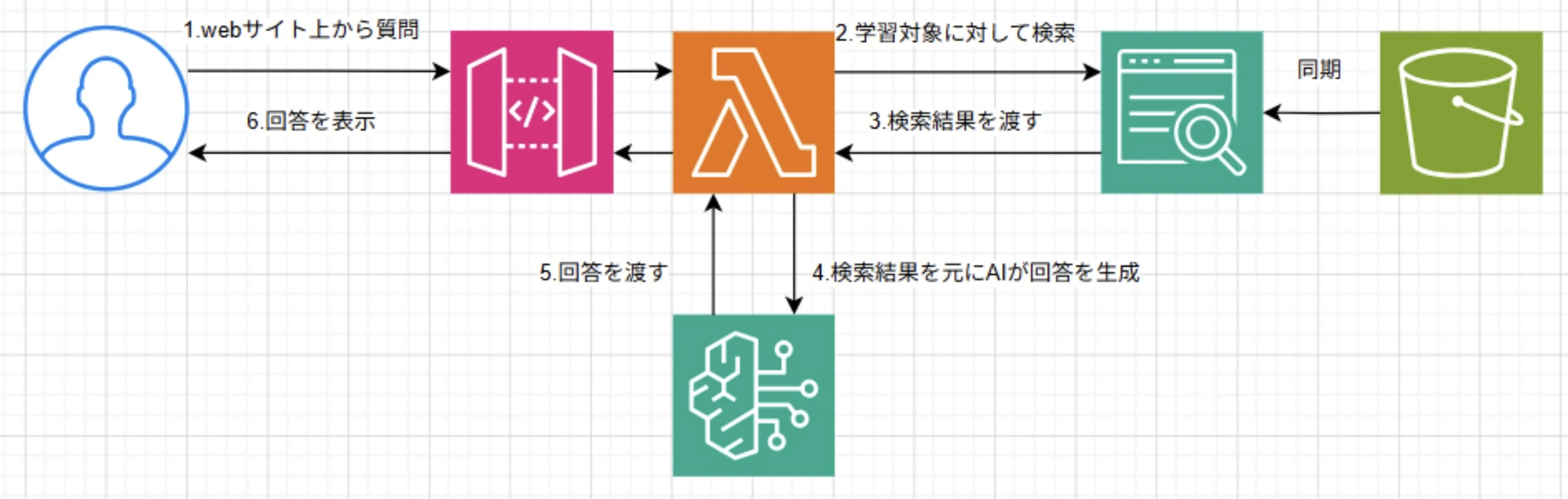
✅ この構成にしてよかった点
今回の構成を振り返ってみると、
- サーバ管理が一切不要
- 部品ごとに役割がはっきりしている
- PoCから本番への拡張もイメージしやすい
というメリットを感じました。
RAGの中身(検索や生成)に集中できて、インフラで悩む時間がほぼ無かったのは大きいです。
📝 まとめ
- 要件を整理すると、RAGはかなり自然な選択肢だった
- AWSにはRAG向けのサービスが複数ある
- 今回は PoC重視で Kendra + Bedrock を採用
📍その後(おまけ)
ローカル上で動作するシステムにてお客様向けにデモを実施したところ、とても興味を持ってもらえました!
初めてプリセールス的なことまで担当させてもらいましたが、とても楽しかったです。
良い経験が出来ました!
今後の展望としては
- Webサイトから情報を取得してみる
- CognitoやCloudFront等のサービスを採用して認証やセキュリティを強化
- 上位モデルを試して性能比較
あたりにチャレンジですかね。まだまだ改良の余地ありですね!
ここまで、読んでいただきありがとうございました!