この記事は、「弁護士ドットコム Advent Calendar 2019 - Qiita」の9日目の記事です。
最近やったタスクのGCPを使ってAPIで取得したデータの差分を定期的に BigQuery にインポートするについて書きたいと思います。
途中goのサンプルコードがありますが、あくまでサンプルなのであしからず…
前提
とある日、外部サービスの様々なオブジェクト(ユーザー情報など)のデータをBIツールでみたいという依頼がきました。BIツール上で、この外部サービスのデータが連携できる状態になっておらず、BigQueryにデータを入れる必要がありました。
外部サービスのデータは、APIで取得可能になっており、各オブジェクトを指定して取得できるもので、レコードの更新日時などで絞り込んで検索できるようなものでした。レコードは件数が多く、挿入、更新が随時行われるようなものでした。レコードにはIDと、更新日時が存在します。
独立した環境がよく、運用を楽にしたかったので、GCPのサービスを使って作りました。
BigQueryでは、各オブジェクトあたり1つのテーブルを使ったほうが検索しやすいかなと思ったのと、外部サービスのデータが大容量になったときに仕組みの作り直しが起きないように、テーブルを差分更新する方法を採用しました。
方法
インフラ図
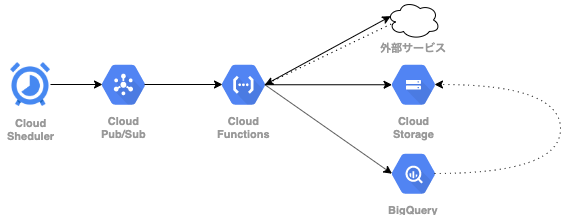
解説
定期的に実行する部分
Cloud Schedulerで1日1回Cloud Pub/Sub にメッセージを送信するジョブを設定しました。
Cloud Pub/SubはCloud Functions のフックのためだけに使うので、送られるメッセージは任意のメッセージにしました。
※ 今はCloud Functionsで直接スケジューリングすることができないので、Cloud Schedulerを経由しました。
差分更新しながらBigQueryにインポートする部分
Cloud Functionsで以下一連の処理を行います。
BigQueryのテーブルは事前に作っておく必要があります(一時テーブルと、以下では既存テーブルと呼んでいる差分更新をしていくテーブル)。
外部サービスのAPIを叩き、結果をCSVにして、Cloud Storageにアップロード
前日との差分を取得するために、APIでオブジェクトを指定し、処理実行日で絞り込みをしてリクエストを行い、レスポンスからCSVを作成します。
CSVのヘッダーはBigQueryに入れ込むときに使うので、列が対応するようになんとかして作っておきます。
上記で取得したCSVを /{処理実行日}/{オブジェクト名}.csv のようなパスでCloudStorageに保存します。
以下がサンプルコード。
package hoge
import (
"context"
"fmt"
"time"
"cloud.google.com/go/storage"
)
// UploadCSVToStorage はCSVをCloudStorageにアップロードする
// `/{実行日}/{オブジェクト名}.csv`のようなパスでCloudStorageに保存される
func UploadCSVToStorage() error {
ctx := context.Background()
execTime := time.Now().Format("2006-01-02")
objectName := "user"
bucket := "example-bucket"
client, err := storage.NewClient(ctx)
if err != nil {
return err
}
defer client.Close()
path := fmt.Sprintf("%s/%s.csv", execTime, objectName)
w := client.Bucket(bucket).Object(path).NewWriter(ctx)
defer w.Close()
// CSVにAPIから取ってきた情報を書き込む
// c := csv.NewWriter(w)
// defer c.Flush()
// ...
// c.Write(row)
return nil
}
BigQueryに差分更新用の一時テーブルを作成する
BigQueryにはCloud StorageにあるCSVを読み込んでテーブルを作成するといった機能が存在します[参考]。
BigQueryで、上記で作ったCloudStorageのファイルを /{処理実行日}/user_*.csv のような条件で読み込ませ、一時テーブルを作成します。
CSVのヘッダーをもとに、BigQueryのカラムに対応するレコードが自動的にはいるようになっています。
以下がサンプルコード。
package hoge
import (
"context"
"fmt"
"time"
"cloud.google.com/go/bigquery"
)
// UpdateTemporaryTable はCloudStorageにある各ファイルからBigQueryの差分更新用のテンポラリテーブルを更新する
func UpdateTemporaryTable() error {
ctx := context.Background()
pID := "example-project-id"
bucket := "example-bucket"
datasetID := "example-dataset-id"
execTime := time.Now().Format("2006-01-02")
objectName := "user"
tmpTableName := "tmp_user"
client, err := bigquery.NewClient(ctx, pID)
if err != nil {
return err
}
gcsPath := fmt.Sprintf("gs://%s/%s/%s_*.csv", bucket, execTime, objectName)
gcsRef := bigquery.NewGCSReference(gcsPath)
gcsRef.AllowJaggedRows = true
gcsRef.AllowQuotedNewlines = true
gcsRef.FieldDelimiter = "\t"
gcsRef.SourceFormat = bigquery.CSV
loader := client.Dataset(datasetID).Table(tmpTableName).LoaderFrom(gcsRef)
loader.WriteDisposition = bigquery.WriteTruncate
job, err := loader.Run(ctx)
if err != nil {
return err
}
status, err := job.Wait(ctx)
if err != nil {
return err
}
if err := status.Err(); err != nil {
return err
}
return nil
}
一時テーブルを使って、既存のテーブルの差分更新を行う
BigQueryにはクエリの結果をテーブルに書き込むといった機能があります[参考]。これをつかって既存のテーブルをクエリの結果で更新することもできます。1
クエリの内容としては、既存のテーブルと差分更新用のテーブルをマージし、レコードのIDごとで、更新日時降順に並べて、一番新しいレコードで絞り込むといったものになります。
これらを使って差分更新を実現しています。
以下がサンプルコードとなります。サンプルとして、テーブルのスキーマには、idと更新日時(updated_at) があるものとします。
package hoge
import (
"context"
"fmt"
"cloud.google.com/go/bigquery"
)
// 一時テーブルと既存のテーブルをマージしてセレクトするクエリ
// このクエリの結果を使って既存のテーブルを更新する
// 各テーブル部分が変数になっている
// ROW_NUMBER() OVER (PARTITION BY id ORDER BY updated_at DESC) AS rowNumber でidごとでupdated_at降順に並べて行番号を振っている
// その後 WHERE rowNumber = 1 をして、updated_atが一番新しいもののみを取得するようにしている
const mergeQuery = `
SELECT
* EXCEPT(rowNumber)
FROM (
SELECT
*,
ROW_NUMBER() OVER (PARTITION BY id ORDER BY updated_at DESC) AS rowNumber
FROM (
SELECT
*
FROM
%s
UNION ALL
SELECT
*
FROM
%s
)
) WHERE rowNumber = 1;
`
// UpdateMainTable は一時テーブルを使って既存のテーブルを更新します
func UpdateMainTable(ctx context.Context) error {
pID := "example-project-id"
datasetID := "example-dataset-id"
objectName := "user"
mainTable := "example-data-set-id.user"
tmpTable := "example-data-set-id.tmp_user"
client, err := bigquery.NewClient(ctx, pID)
if err != nil {
return err
}
q := client.Query(fmt.Sprintf(mergeQuery, mainTable, tmpTable))
q.QueryConfig.Dst = client.Dataset(datasetID).Table(objectName)
q.WriteDisposition = bigquery.WriteTruncate
job, err := q.Run(ctx)
if err != nil {
return err
}
status, err := job.Wait(ctx)
if err != nil {
return err
}
if err := status.Err(); err != nil {
return err
}
return nil
}
これで完了!
さいごに
https://tech.mercari.com/entry/2018/06/28/100000
BigQuery差分更新の方法に関して、こちらの記事を大変参考にさせていただきました。ありがとうございました。
-
クエリ結果の書き込み時のオプションでWriteTruncateてのがあるので、実際は空っぽにして書き込みしてる? ↩