・はじめに
はじめまして。
私はアイデミーのデータ分析コースを受講したpython初心者です。
今回はアイデミーで3か月間勉強した復習もかねて、2021年の台風発生数を時系列分析で予測することにしました。
・台風発生数を予測しようとしたきっかけ
主に2つあります。
一つめは、ここ数年台風による自然災害が多く発生している気がしていて、
1年間あたりの台風の発生数は過去に比べて増えているのかなど、
基本的な事を知りたいと思ったからです。
二つめは、アイデミーを受講していて、一番時系列分析が理解できなかったからです(笑)
このブログのテーマも自分の中で比較的理解が進んだ機械学習(判別)にしようとも思いましたが、ここで苦手を克服しようと思い時系列分析が使えそうな「日本における台風発生数の予測」を選びました。
・時系列分析とは
一言で言うと、「時間の経過と密接に関わりのあるデータ」を分析する方法のひとつです。
では「時間の経過と密接に関わりのあるデータ」とはどのようなものでしょうか。
具体的には以下のようなデータが該当します。
・気温:昼間は暖かくて夕方から朝方にかけてひんやりしていく。
・日照時間(日本だと):夏は長くてから冬は短い。
両方とも時間(X軸)の変化ともに値(Y軸)が変化していきます。
時系列分析はこのようなデータに対して分析を行う際には有効は方法となります。
・台風発生数予測の概要
- 予測すること
- 2021年の台風発生数を予測する。
- 実行環境
- Microsoft Windows 10 Home
- Google colab
- Python 3.7.11
- 分析手法
- SARIMA(台風発生数は季節性があることからこの手法を選択しました)
- 使用データ
- 分析の流れ
- 1.データの読み込み
- 2.データの整理
- 3.データの可視化
- 4.データの周期の把握 (パラメーターsの決定)
- 5.他パラメーターの決定
- 6.モデルの構築および予測とその可視化
- 7.精度評価
- 8.2021年の台風発生数を予測
・台風発生数予測の開始!
1.データの読み込み
まずは今回の台風発生数予測で使用するライブラリの読み込みと、
気象庁から取得した台風発生数のcsvをデータフレーム化します。
import calendar
import itertools
import matplotlib.pyplot as plt
import numpy as np
from pandas import datetime
import pandas as pd
import statsmodels.api as sm
# ----------------------------
# 1.データの読み込み
# ----------------------------
typhoon_1 = pd.read_csv("/content/drive/MyDrive/20210717_TAIFU/generation.csv",encoding='shift-jis')
2.データの整理
ここでは、やりたいことは主に2つです。
まずはデータレイアウトの変更。
気象庁のcsvは台風発生数が横持ちとなっています。
これだと時系列分析がしにくいので縦持ちに変更します。
具体的には以下です。
もうひとつは時系列分析しやすいようにデータ加工を行うことです。
縦持ちしたデータに対して以下の加工を行っていきます。
・ゼロ埋め
・index付与
以下、ソースです。
# ----------------------------
# 2.データの整理
# ----------------------------
keep_cols = ['dt','typhoon_num']
typhoon_2 = pd.DataFrame(index=[],columns=keep_cols,dtype=int)
# index
index_cols = ['year', 'month','day','hour','minute']
for index , row in typhoon_1.iterrows():
# データフレームとして転置する
tmp_2 =typhoon_1.loc[[index]].T
# 行列変換後の列名を変更する
tmp_2 = tmp_2.rename(columns={index:'typhoon_num'})
# indexをカラム'month'に変換
tmp_2["month"] = tmp_2.index
tmp_2["month"] = tmp_2['month'].str.replace('月', '')
# 年を作成
tmp_2['year'] = tmp_2['typhoon_num'][0]
# 不要な行を削除
drop_vars = ['年','年間']
tmp_2 = tmp_2.drop(drop_vars, axis=0)
# 欠損補完
tmp_2['typhoon_num'] = tmp_2['typhoon_num'].fillna(0)
# 型式変換
tmp_2['year'] = tmp_2['year'].astype('float').astype('int')
tmp_2['month'] = tmp_2['month'].astype('float').astype('int')
tmp_2['typhoon_num'] = tmp_2['typhoon_num'].astype('float').astype('int')
# index用変数作成
tmp_2['day'] = tmp_2.apply(lambda x: calendar.monthrange(x['year'],x['month'])[1], axis=1)
tmp_2['hour'] = 0
tmp_2['minute'] = 0
tmp_2['dt'] = pd.to_datetime(tmp_2[index_cols])
# 不要な列を削除
tmp_2 = tmp_2.drop(index_cols, axis=1)
# 縦結合
typhoon_2 = typhoon_2.append(tmp_2, ignore_index=True)
# indexを作成
typhoon_2 = typhoon_2.set_index('dt')
typhoon_2
3.データの可視化
前処理が終わった段階で、日本における台風発生状況を可視化していきます。
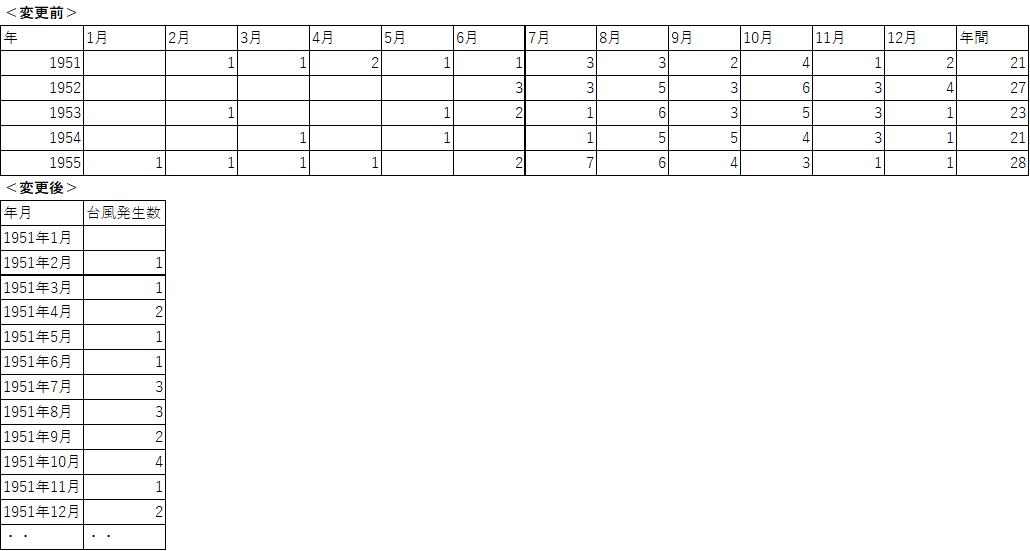
まずは、月毎の台風発生数の平均です。
夏から秋にかけて多く発生していることがわかります。
台風の発生は季節性があるといえそうですね。
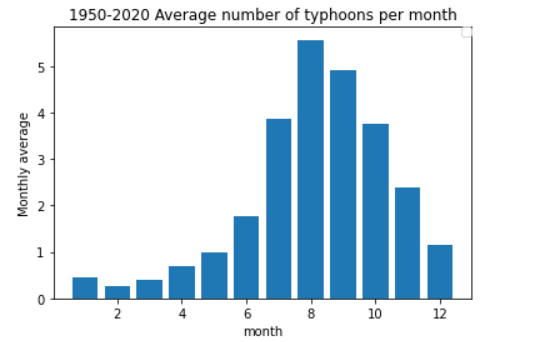
次に年毎の台風発生数です。
2010年以降は増えていますが、1950年からでみると減っていますね。
台風の定義が変わったのでしょうか。それとも気象観測の技術が向上したからでしょうか。
いずれにしても興味深い結果です。
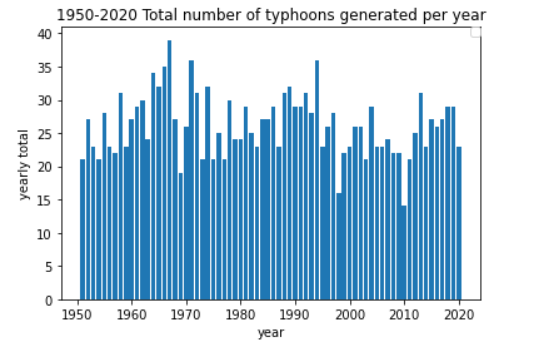
最後にpythonのStatsModelsライブラリにあるseasonal_decompose()関数を使い、台風データを現系列(Observed)、傾向変動(Trend)、季節変動(Seasonal)、不規則変動(Residual)の4つの観点から観察してみます。
やはり長い時間軸では台風は減少傾向にあり、季節変動を持っていることがわかります。
なお、可視化のソースはいかになります。
# ----------------------------
# 3.データの可視化
# ----------------------------
# 月ごとの平均台風発生回数
tmp_3 = typhoon_2.set_index([typhoon_2.index.month,typhoon_2.index])
tmp_3.index.names = ['month','date']
typhoon_3 = tmp_3.mean(level='month')
plt.title('1950-2020 Average number of typhoons per month')
x_data = typhoon_3.index
y_data = typhoon_3['typhoon_num']
plt.bar(x_data, y_data)
plt.xlabel("month")
plt.ylabel("Monthly average")
plt.legend(bbox_to_anchor=(1, 1), loc='upper right', borderaxespad=0, fontsize=10)
plt.show()
# 年ごとの合計台風発生回数
tmp_3 = typhoon_2.set_index([typhoon_2.index.year,typhoon_2.index])
tmp_3.index.names = ['year','date']
typhoon_3 = tmp_3.sum(level='year')
plt.title('1950-2020 Total number of typhoons generated per year')
x_data = typhoon_3.index
y_data = typhoon_3['typhoon_num']
plt.bar(x_data, y_data)
plt.xlabel("year")
plt.ylabel("yearly total")
plt.legend(bbox_to_anchor=(1, 1), loc='upper right', borderaxespad=0, fontsize=10)
plt.show()
# 季節調整を行い原系列をトレンド、季節変動、残差に分けて出力
fig = sm.tsa.seasonal_decompose(typhoon_2 , freq=24).plot()
plt.show()
4.データの周期の把握 (パラメーターsの決定)
前述の可視化までで、台風には周期性があることがわかりました。
ここでは、SARIMAモデルで必要となるパラメータ(周期性)について台風データの自己相関(上図)と偏自己相関(下図)から検討していきます。
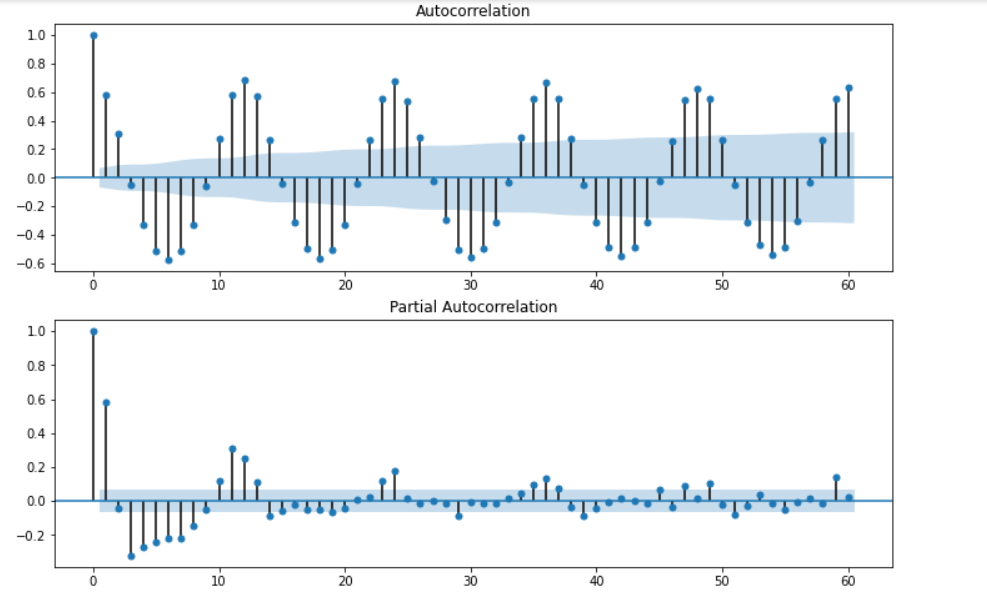
青色で塗りつぶされている領域は95%信頼区間となります。
この中に納まっている場合は偶然の結果であるといえるのでその範囲外の値が有望です。
詳しく見てみると自己相関(上図)と偏自己相関(下図)ともに
12ヵ月・24か月といった12ヵ月周期に該当する値が青色の外に飛び出ています。
SARIMAモデルで必要となるパラメータ(周期性)は12ヵ月でよさそうです。
以下ソース。
# ----------------------------
# 4.データの周期の把握 (パラメーターsの決定)
# ----------------------------
# 自己相関・偏自己相関の可視化
fig=plt.figure(figsize=(12, 8))
# 自己相関係数のグラフを出力します
ax1 = fig.add_subplot(211)
fig = sm.graphics.tsa.plot_acf(typhoon_2, lags=60, ax=ax1)
# 偏自己相関係数のグラフを出力します
ax2 = fig.add_subplot(212)
fig = sm.graphics.tsa.plot_pacf(typhoon_2, lags=60, ax=ax2)
plt.show()
5.他パラメーターの決定
SARIMAモデルではデータの周期以外にもパラメータを決める必要があります。
今回はアイデミーにてBIC(ベイズ情報量基準) による最適なパラメーター探索を行うPGMが提供されていたのでそれを利用して決定しました。
以下、今回のSARIMAモデルに与えるパラメータです。
・ 自己相関度=0
・ 誘導=0
・ 移動平均=0
・ 季節性自己相関=0
・ 季節性導出=1
・ 季節性移動平均=1
・ データの周期=12(自己相関と偏自己相関の結果から決定)
# ----------------------------
# 5.s以外のパラメーターの決定
# ----------------------------
# 関数の定義
def selectparameter(DATA,s):
p = d = q = range(0, 2)
pdq = list(itertools.product(p, d, q))
seasonal_pdq = [(x[0], x[1], x[2], s) for x in list(itertools.product(p, d, q))]
parameters = []
BICs = np.array([])
for param in pdq:
for param_seasonal in seasonal_pdq:
try:
mod = sm.tsa.statespace.SARIMAX(DATA,
order=param,
seasonal_order=param_seasonal)
results = mod.fit()
parameters.append([param, param_seasonal, results.bic])
BICs = np.append(BICs,results.bic)
except:
continue
return parameters[np.argmin(BICs)]
# 周期を埋めて最適なパラメーター探索
selectparameter(typhoon_2,12)
6.モデルの構築および予測とその可視化
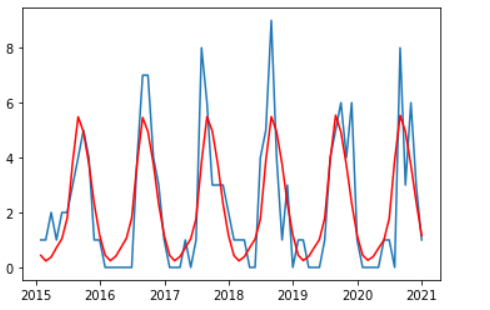
前述で決めたパラメータをSARIMAモデルに設定し、実行します。
モデル構築が完了したら台風発生数の実績値と予測値を可視化してみます。
期間は2015年から2020年までです。
周期性はうまく表現できていますが台風ピーク時の予測は低そうです。
# ----------------------------
# 6.モデルの構築
# ----------------------------
# モデルの当てはめ
typhoon_6_1 = sm.tsa.statespace.SARIMAX(typhoon_2,order=(0, 0, 0),seasonal_order=(0, 1, 1, 12)).fit()
# 構築したSARIMAモデルのBICを出力します
print(typhoon_6_1.bic)
# predに予測データを代入する
pred = typhoon_6_1.predict("2015-1-31", "2020-12-31")
typhoon_6_2 = typhoon_2["2015":"2020"]
plt.plot(typhoon_6_2)
plt.plot(pred, color="r")
plt.show()
7.精度評価
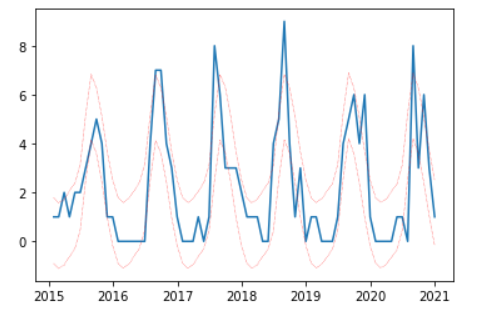
精度はどうでしょうか。
[RMSE = 1.3408]という結果になりました。
RMSEは標準偏差とほぼ同じ意味です。
ですので、各月の台風発生数の予測値は「予測値±1.3408回(1σ)の範囲」に約68%の確率で収まります。
具体的には下図の赤線の範囲です。
台風ピーク時は赤線の範囲を超えていますね。
予測の成功を実測値が「予測値±1.3408回(1σ)の範囲」であるとした場合、
正解率は、**約80%**となりました!

精度についてまとめると、
台風ピーク時こそ予測値と大きくずれてしまうことがあるものの、
各月の台風発生数を±1.3回程度の誤差で約80%の確率で予測できるのであれば悪くない精度だと思いました。
# ----------------------------
# 7.精度評価
# ----------------------------
# RMSE算出
rmse = np.sqrt(((pred - typhoon_3_1['typhoon_num']) ** 2).mean())
print('RMSE = {}'.format(round(rmse, 4)))
# RMSEを1σとみなした予測値を算出
typhoon_7 = pd.DataFrame(pred)
typhoon_7.index.name = 'dt'
pred =typhoon_7.rename(columns={0:'pred'})
typhoon_7 = pd.merge(typhoon_6_2, pred, on='dt')
print(typhoon_7.info())
typhoon_7['pred_minus'] = typhoon_7['pred'] - 1.3408
typhoon_7['pred_plus'] = typhoon_7['pred'] + 1.3408
# 実測値と予測値1σを可視化する
plt.plot(typhoon_3_1, label = "Pred")
plt.plot(typhoon_7['pred_plus'], color="r", linestyle = "dotted", linewidth = 0.5,label = "Plus:1.3408")
plt.plot(typhoon_7['pred_minus'], color="r", linestyle = "dotted", linewidth = 0.5, label = "pred_minus:1.3408")
plt.show()
# 予測値1を予測成功とした場合の予測結果を算出する。
typhoon_7['pred_success_failure'] = np.where((typhoon_7['typhoon_num'] >= typhoon_7['pred_minus']) & (typhoon_7['typhoon_num'] <= typhoon_7['pred_plus']) , "予測成功", "予測失敗")
typhoon_7.groupby('pred_success_failure')['typhoon_num'].count()
8.2021年の台風発生数を予測
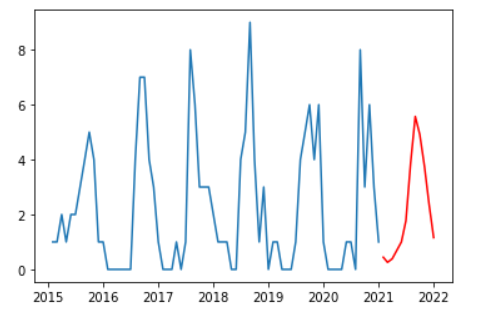
やっとここまでたどり着きました。
最後に2021年の台風発生数を予測します。
予測の結果、2021年の台風発生数は26.2回となりました。
2021年7月19日時点では6回台風が発生していますので、これから20回くらい発生しそうですね。
ちなみに可視化結果はこんな感じです。
# ----------------------------
# 8.2021年の台風発生数は?
# ----------------------------
# predに予測データを代入する
pred = typhoon_6.predict("2015-1-31", "2021-12-31")
typhoon_8_1 = typhoon_2["2015":"2020"]
plt.plot(typhoon_8_1)
plt.plot(pred, color="r")
plt.show()
# 2021年の台風発生数
print('2021年の台風発生数 = {}'.format(round(pred.sum(), 4)))
・終わりに
最初は1日あれば終わるかなと思ったのですが、余裕で3日くらいかかりました。
いちから自分ですべてコーディングするとなると中々思ったように進まないですね。
時間がかかった要因としては、
・pyhonに慣れていなくて思ったようにデータハンドリングできなかった。
・時系列分析もヒヨコレベルなので分析手法の理解に時間がかかった。
があげられます。
一方で思ったように進まなかったからこそ**「没頭」**できました。
これが個人的にはなにより嬉しいことでした。
時間を忘れて苦しくも楽しみながら最後までやり遂げられたのはなによりも代えがたい経験になったと思います。
これからはアイデミーで学んだスキルを一層高めるとともに本業にも活かしていきたいと思います!
最後まで読んでいただきありがとうございました!