本記事はCodeRabbitの提供するポッドキャストTHE MERGEより、Anthropic's "Mythos" Fable 5 vs Claude Opus 4.8: Genius Coding or Waste of Tokens?の日本語解説です。
TL;DR
Fable 5はコードレビュータスクにおいて高品質なコメントを生成する一方で、処理速度が遅くコストも高い点が課題です。Opus 4.8は価格と速度のバランスに優れ、短時間でのタスク実行に適しています。
また、長時間タスクにおいてFable 5は環境理解に時間をかけるため、詳細なコード解析が可能ですが、利用者にとってはコメント過多で負担になる可能性があります。ゲーム設計タスクではFable 5がバランスの取れた出力を示すなど、生成品質の向上が見られます。
コードレビュー性能とコスト
Fable 5は従来モデルに比べてコメント量が15〜20%増加し、コードレビューの精度が向上しています。しかし、処理時間が長く、単一レビューあたりのコストがOpus 4.8の2倍になるため、コスト効率を重視する場合は注意が必要です。コメントの精度は高いものの、ユーザーにとっては情報過多になり得ます。

モデルは環境理解を優先する設計であり、コードベース全体のファイル関係を把握してからレビューに入るため、徹底的な解析が可能です。一方で、多すぎるコメントはユーザーが無視するリスクを伴い、信頼性にも影響します。
長時間タスクにおける性能(06:30〜)
Deep Suiteベンチマークにおいて、Fable 5は長時間タスクで90分以上を要し、Opus 4.8やCodeexの12〜34分に比べ圧倒的に遅いことが確認されました。これは、モデルが環境理解とファイル探索に時間をかけるためです。

タスク成功率は約60%で、失敗は40%でした。Fable 5は長時間タスク向けの設計として、結果の正確性よりも徹底した解析を優先しており、スピードよりも詳細さを重視するユースケースに適しています。
ゲーム設計タスクでの評価(10:25〜)
Fable 5はゲーム設計タスク(Elder Ringレプリカ、BattleSnake)において、バランスの取れた出力を示しました。モデルは明示的に指示しなくても、勝者が偏らないよう戦略を自動調整します。

短いプロンプトでも直感的にユーザーの意図を理解し、インターフェースデザインや攻撃アニメーションなどの細部まで適切に生成します。従来モデルでは長いプロンプトが必要でしたが、Fable 5では効率的に対応可能です。
論理パズルと推論能力(15:20〜)
Fable 5とOpus 4.8を用いた論理パズルテストでは、両モデルとも以前より改善しているものの、完全ではありません。たとえば橋を渡る問題では、Fable 5は50%長い時間をかけて回答し、正解に至りませんでした。
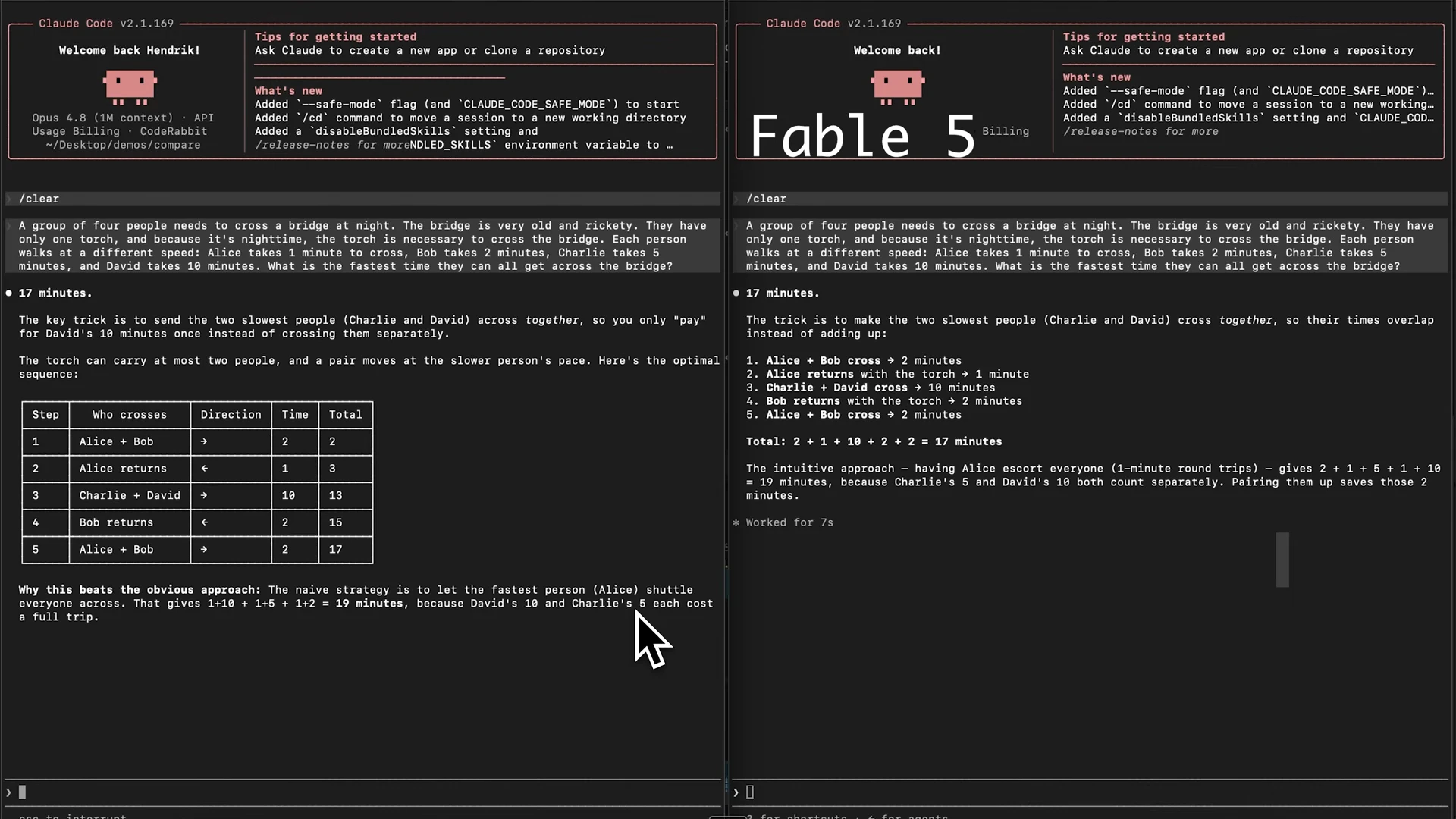
また、帽子問題や単語のトークン化問題でも、Fable 5は状況理解に時間を要し、必ずしも正答に至らない場合がありました。これは長時間タスクと同様、環境把握に重きを置くためです。
モデルファミリーの初期世代としての特性(21:35)
Fable 5は新しいモデルファミリーの初期リリースであり、全体的に性能は向上しているものの、まだ荒削りな部分があります。今後の世代で改良が加わることで、速度・コスト・精度のバランスがさらに改善されると考えられます。

初期世代モデルでは、長時間タスクや詳細なコード解析において優れた精度を示す一方で、利用者が負担に感じる点も残っています。今後のモデルでは、これらの課題に対処した改善が期待されます。
まとめ
Fable 5は、コードレビューやゲーム設計のようなタスクで、詳細かつ文脈を踏まえた出力を生成できるモデルです。特にコードベース全体の構造を理解しようとする能力や、明示されていない意図を補完する能力には強みがあります。一方で、コメント量が増えやすく、ユーザーにとってはノイズや負担になる可能性もあります。
現時点では、Fable 5は速度とコストの面でOpus 4.8より扱いづらい場面があります。長時間タスクや精度重視の用途では有力な選択肢になり得ますが、日常的なコードレビューで使う場合は、コスト、処理時間、コメントの有用性を慎重に見極める必要があります。初期世代のモデルとして荒削りな部分は残っていますが、今後の改善によって実用性が高まる余地があります。
今後もCodeRabbitでは、AIに関する最新トピックを扱う動画を公開していきます。ぜひチャンネル登録、高評価をお願いします!