この記事はSRE Advent Calendar 2023 9日目の記事です。@gogogonkunです。よろしくお願いいたします。
はじめに
オートスケールと聞くと、何でも自動的に調整してくれる感じがして、めちゃめちゃ聞こえが良いですよね。
でも、実際には綺麗にオートスケールさせるにはチューニングが必要になりますし、色々と地雷ポイントがあると思います。
ここ最近、Kubernetes上で動いているdeploymentのオートスケールの調整をすることが多かったので、私自身の振り返りを兼ねて、その時に考えていたことをつらつらと書き記します。
想定する読者
- これからオートスケールの設定をしようと考えている人
- オートスケールって何でも良い感じで調整してくれるんでしょ? という感覚の方
案外、色々と考えることが多いのだなという雰囲気だけでも伝われば嬉しいです。
ちょっとやってみようかな... と思ってもらえるともっと嬉しいです。
Horizontal Pod Autoscaler (HPA)とは
HPAは、リソース使用率に基づいてPodの数を動的に調整する機能です。
CPU使用率やメモリ使用率などのメトリクスを監視し、設定されたターゲット値に基づいてPodの数をスケーリングします。
HPAを設定し、組み込む上で気をつけねばならないこと
思いついたことをつらつらと書いていきます。
オートスケール対象のPodはGracefulにShutdown出来るようしておく
オートスケールの仕組みが動くということは、Podの生成、削除が頻繁に動くことになります。
特にPodを削除される際の挙動には注意しておかなければなりません。
ユーザからのリクエストを処理している途中で、Podが死んでしまったら、そのリクエストをユーザに返却することも出来ずにエラーに落ちてしまいます。
なるべく、リクエストを処理しきってから、Podが削除されるよう、調整しましょう。Podのライフサイクル管理、大事です。
個人的には、ライフサイクル管理のイメージを湧かせる上で、以下の記事がとても参考になりました。
HPAだけだと突発的なスパイク負荷には適応出来ない
HPAはCPUやMemoryのようなメトリクスベースでのオートスケールを行います。
スケールアウトが始まってから、新たに起動したPodがリクエストを受け付けられるようになるまでの間にはラグがあります。
このラグはアプリケーションがどの程度の時間で上がってくるかにも左右されます。
つまり、急激に負荷が増えた場合でも、Podはすぐにリクエストを受け付けられるようにはならない。
その間に受けたリクエストを処理しきれずに既存のPodのリクエストが詰まってしまう。
結果的に、スパイク負荷だとオートスケールが間に合っていない というケースがあります。
HPAが万能ではないというのは当たり前ですが、大事ですね。
HPA対象となるdeploymentが過負荷状態となるのは避ける
上で挙げた「突発的なスパイク負荷には対応出来ない」という話に関連します。
HPAはメトリクスベースのオートスケールの仕組みである以上、Podからサンプリングしているメトリクスが正しいという前提で成り立っています。
リクエストが詰まり始めると、この前提が揺らぐこともあります。
Podが過負荷の状態に陥っている際に、そのPodのメトリクスが必ずしも負荷の状況を適切に表していると言えないこともあります。
例えばですが、特定のPodでは、Webサーバがリクエストを捌ききれずに詰まってしまい、リクエストを全く受け付けられていない状況である。でも、リクエストを処理しているわけではないので見かけ上のCPU使用率は低い状態になってしまっている。ということも考えられます。
この場合、過負荷の状況であってもHPAでのスケールアウトが発生しない。ということも考えられます。
また、過負荷になってdeployment配下のPodが死んで、生成されて、というサイクルを繰り返してスケールアウトを走っているものの、healthyなPodの数が一向に増えない。ということも考えられます。
言いたいのは、過負荷な状況下においては、HPAでのオートスケールは期待通りに動かないこともある(そういうことが多い)。というのを頭の片隅にでも残しておきましょう。ということです。
スケールアウトのしきい値はスパイク負荷の許容量と関係する。ゆとりも大事
スケールアウトのしきい値はスパイク負荷の許容量となることを気をつけます。
例えば、CPUベースでオートスケールさせるとなった場合、CPUの目標値(averageUtilization)を定めると思います。
この数値がスパイクの許容率と捉えていいです。あくまで経験則上の話ですが...
type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50 // オートスケールのしきい値はスパイク負荷の許容量
このaverageUtlizationが50%ならば、それは2倍のスパイク負荷を許容出来るような遊びを持たせている状態と言えます。
40%ならば2.5倍のスパイク負荷を許容出来るような遊びを持たせている状態です。
CPU使用率が100%を超えた場合、リクエストが詰まり始めて、アプリケーション全体に影響を及ぼす。と仮定しているので、このような考え方をしております。
なぜ、CPU使用率50%でスケールアウトさせるの?、80%とかぎりぎり攻めてもいいのでは? と思う場合には、スパイク負荷に対してどの程度の許容をするのか考えると、答えが出てくると思います。
現行のシステムであれば、時間帯別のリクエスト量から、どの程度スパイクが発生しうるのか見積もって、この辺の数値を定めていくと精緻な値が出せると思います。
CPUを100%使用している状態こそ、リソースをフル活用出来ているというGood。という話もあるので、この辺の考え方は宗派があると思います。
一つの考え方として、スパイク負荷を許容するためのしきい値であるということは念頭において、数値を定めましょう。
スケールアウト時の感度をチューニングする
スケールアウト時の感度をチューニングするのは大事です。
アプリケーションに対して、どの程度の速度、増加量で、どの程度の負荷が見込まれるのか次第で、それに合わせた感度調整が必要です。
Podの増加量
スケールアウト時にはscaleUpの数値を変更することになると思います。
HPAにおけるPod数の計算方法
デフォルト設定の場合、一度に増加するPodの最大数は 4 or 現在のPodの数の2倍 のどちらかの大きい数が選択されます。
behavior:
scaleUp:
stabilizationWindowSeconds: 0
policies:
- type: Percent
value: 100
periodSeconds: 15
- type: Pods
value: 4
periodSeconds: 15
selectPolicy: Max
selectPolicyがMinの場合には、2択のうち、Podの増加数が少ない方が選択されます。
The policy selection can be changed by specifying the selectPolicy field for a scaling direction. By setting the value to Min which would select the policy which allows the smallest change in the replica count.
ここまでで、なるほど... しきい値を超えたら、Podの数は4つ一気に増える or 現状の2倍の数になるのか... と思ってはなりません。
Podの数を算出する計算式を確認しましょう。
現状のCPU使用率によって、Podの数が変動するように見えます。
desiredReplicas = ceil[currentReplicas * ( currentMetricValue / desiredMetricValue )]
実際の数値を当てはめてみないとイメージしにくいですね。
イメージを具体的に湧かせるために、Podの数(currentReplicas)= 10, CPU使用率の目標値(desiredMetricValue) = 50%として、スケールアウト後のPodの数を計算してみましょう。
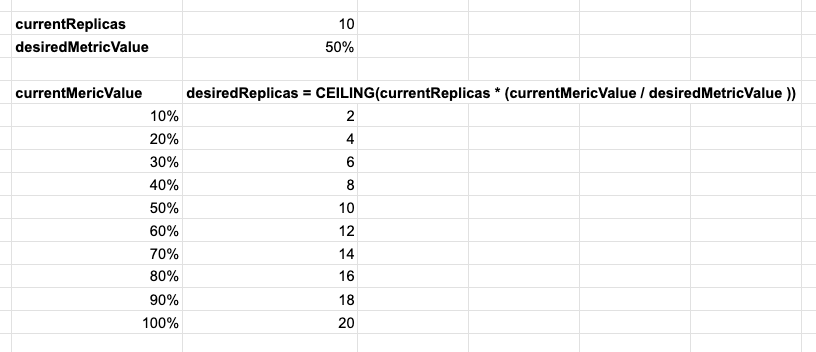
CPU使用率の目標値が50%の場合、CPU使用率が100%になってようやく、Pod数が2倍になる可能性があるわけですね。
behavior:
scaleUp:
stabilizationWindowSeconds: 0
policies:
- type: Percent
value: 100
periodSeconds: 15
- type: Pods
value: 4
periodSeconds: 15
selectPolicy: Max
上の例で記載している、4や2倍は、あくまで「最大」でいくつ増えるのか。という数値なわけです。
実際には、現状のPodのCPU使用率と目標値を比較して、Podの増加量が定まるようです。
現状のCPU使用率と目標値に2倍の乖離があれば、Podの増加量も2倍となります。
スケールアウトの基準値をCPU使用率40%とする場合
更にもう一つ踏み込んで考えてみましょう。
スケールアウトの基準値をCPU使用率40%としてみましょう。
この場合、理論上は2.5倍までのスパイク負荷であれば捌ける想定となります。
type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 40
先程と同様にCPU使用率に対するPod数の理論値を計算してみます。
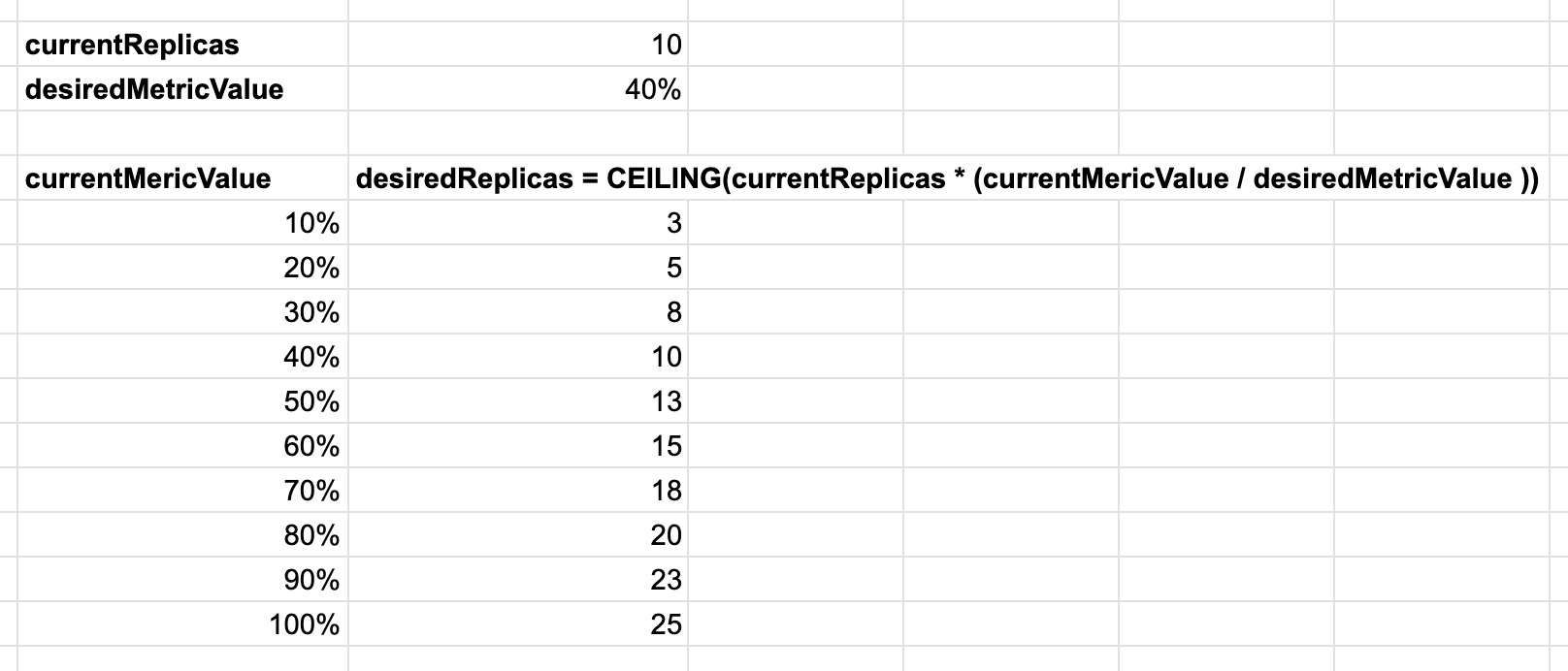
CPU使用率が80%になった場合、Podの数は現在と比較して倍になります。
ここでもう一つ、チューニングするポイントがあります。
CPU使用率が100%になった場合どうなるでしょう?
計算式上は、Podの数は2.5倍になる想定です。
しかしながら、デフォルトの設定の場合、type: Percentのvalueが100なので、Podの数はMaxでも100%(2倍)までしか増えないように設定されています。
behavior:
scaleUp:
stabilizationWindowSeconds: 0
policies:
- type: Percent
value: 100
periodSeconds: 15
- type: Pods
value: 4
periodSeconds: 15
selectPolicy: Max
いやいや、CPU使用率が100%を超えた場合には、Podの数も2.5倍にしたい。という話であれば、特定期間においてスケールアウトするPodの数の上限を増やしておく必要があります。
この辺を踏まえつつ、Podの増加量の感度をチューニングします。
アプリケーションの負荷特性によって、感度を鈍くするのか、高くするのかは変わります。
感度が高いほうがコスパが悪くなると言えますが、その分、比較的短い期間の負荷の増大には強くなります。
Podの増加頻度
periodSecondsを使って、Podが増加する頻度をチューニング出来ます。
behavior:
scaleUp:
stabilizationWindowSeconds: 0
policies:
- type: Percent
value: 100
periodSeconds: 15
- type: Pods
value: 4
periodSeconds: 15
selectPolicy: Max
デフォルトでは、periodSecondsが15となっています。
つまり、type:Podsのスケールアウトの条件に合致している状態の場合、15秒毎にPodを4つまで増やすことが出来ます。
もちろん、periodSecondsの間隔が短くなればなるほど、短い期間で多くのPodを増やす事が出来ます。
ここで気にしなければならないのは、スケールアウトが始まってPodが起動してから、そのPodがリクエストを受け付けられるようになるまでのタイムラグです。
長い場合には、数分間かかるかもしれません。その間、deployment配下のPodのCPU使用率は下がることは無いでしょう。
その場合は、periodSecondsの間隔が短いが故に、Podが過剰に増えすぎてしまうケースも起きうることが想像出来ます。
このあたりのバランス調整が大事になってくるわけです。
これもアプリケーションの負荷特性を考慮して、コストとスケーラビリティのバランスを取ることが必要となります。
スケールイン時に感度をチューニングする
考え方としては、スケールアウトの場合と同じです。
Podを減らす速度が早すぎる場合には、アプリケーションが受ける負荷が収まっていないにも関わらず、deploymentが縮退してしまい、結果的に過負荷な状態が発生してしまう。
という可能性も考えられます。
ただし、Podを減らす速度が遅すぎる場合には、負荷が落ち着いたにも関わらずPodの数は多いまま。というコスト的に無駄な状態が発生してしまいます。
ここも、結局はコストとスケーラビリティのバランスをどのように取るのか。という話になります。
スケールインの開始をどの程度のウィンドウとするのかは、stabilizationWindowSecondsを調整します。
behavior:
scaleDown:
stabilizationWindowSeconds: 300
policies:
- type: Percent
value: 100
periodSeconds: 15
selectPolicy: Max
Podの減らす速度は、scaleDownの中で定義します。
個人的な意見にはなりますが、スケールインはゆっくり実施しても罰は当たらないという感覚があります。
1分間に1~3個のPodを減らす程度、ゆっくりと減らしてみるのが吉だと思います。
最初はゆるーくしておいて、システムを運用する中で、チューニングしていくのかいいかもしれません。
後は実践しつつチューニングするのみ
ここまでで、考えたほうが良さそうなことを列挙してきました。
これらの話を机上で計算しきるのは、正直しんどいと思います。
実際にProduction環境でオートスケールを動かしてみたら、想定外のスパイク負荷にぶち当たってしまう。ということも十分にありえます。
となると、後は実践しながらチューニングしていくしかないかなと思います。
最低限、影響が起きないであろう設定(高感度、CPUのしきい値をゆるく設定する等)から始めて、Productionの負荷状況をふまえつつ徐々にチューニングしていくのが確実だと思います。
Podの数を減らす時にはくれぐれも慎重に...
功を急いで一度に多くのPodを減らすのは避けましょう。
(Production環境での負荷特性を完全に見切っているのであれば止めませんが...)
アプリケーションには負荷の周期があると思います。
大抵は、1日や1週間の周期と、1ヶ月、四半期、1年というような大きな周期があるでしょう。
この周期に合わせて、少しずつチューニングしていくのをおすすめします。
大抵の場合は、1日ずつ、1週間ずつといった頻度でチューニングすることになると思います。
そうすることで、その周期の中で発生する負荷の増加やスパイクの発生に適応出来ることを検証しつつ、チューニングを進められるようになります。
功は急がず、慎重に。
KEDA | Kubernetes Event-driven Autoscaling
ここまで記事の話の流れで、HPAはスパイク負荷に対応するのが苦手である というのを薄々感じ取れたのではないでしょうか?
HPAを設定していると、スパイク負荷に対応するための方法を知りたくなります。
そこで1つおすすめ出来るのがKEDAです。
その名の通り、メトリクスドリブンだけではなく、イベントドリブンなオートスケール操作を可能にするのがKEDAです。
活用方法は幅広く、対応する数多くのイベントソースを元にオートスケールをトリガーさせることが出来るようになります。
例えばですが、特定の時間帯に必ずスパイク負荷が発生するような負荷特性を持つサービスがあったとします。
このスパイク負荷が、1分間で2,3,4倍になるようなものである場合、HPAでのメトリクスベースのオートスケールだと、どうあがいてもオートスケールが間に合いません。
ここでKEDAを活用すると、スケジュールを指定して、特定の日時にスケールアウトさせることが出来ます。
この場合だと、スパイク負荷が始まる前にPodの数を増やしておき、来たる負荷を迎え撃つ事が出来ます。
一例ですが、Cronを用いてスケールアウトをスケジュール化することが出来ます。
triggers:
- type: cron
metadata:
# Required
timezone: Asia/Kolkata # The acceptable values would be a value from the IANA Time Zone Database.
start: 30 * * * * # Every hour on the 30th minute
end: 45 * * * * # Every hour on the 45th minute
desiredReplicas: "10"
HPAでは対応出来ない負荷については、KEDAを用いて対処するのも一案です。
おわりに
自分の中の経験上の前提を元に、今回の記事は記載している部分もあります。
おそらく、前提が異なれば、チューニングの考え方や気をつけるポイントは変わってくると思います。
今回は、自分の頭の中の前提条件を明記せずにつらつらと書いていますが、「こういう考えもあるんだな」という気持ちで見てもらえれば嬉しいです。
(記載に間違いがあれば、その旨お知らせいただけると嬉しいです)
HPAの設定、KEDAの活用は、色々調査してもっと書きたいところですが、本記事が公開されるまでもう後わずかの時間となってしまいました。
皆さんも、HPAやKEDAを設定して、コストとスケーラビリティのバランスを取ってみませんか?
2023年の今年も残り少ないですが、楽しんでいきましょう!!