今回はIBM i での複数ジョブ(タスク、スレッド)によるCPU共有のお話です。
コンピューターは物理的に1つのCPUを複数の処理(タスク、スレッド、ジョブなどと呼ばれます)で共有させるためにディスパッチと呼ばれる処理を実行しています。
IBM i では活動レベルという設定があります。活動レベルは前回ご紹介した、プール(実行プログラムの特性毎に分割したメインメモリのエリア)毎に設定されています。システム値QPFRADJが1~3ではOSがシステムの負荷状況を調べて適時最適な値に活動レベル(画面の 最大活動 )値を自動調整します。

上図では、プール2(*BASE : OS本体やバッチジョブ等のプログラムが動作する)の最大活動=活動レベルは147です。皆さまの手元の環境はいくつになっているでしょう?
さて、上記のシステムの例だとプール2に最大147のジョブが活動状態で存在できますが、物理的なCPU演算回路は非常に限られています。(次章 CPUのマルチスレッドをご参照ください)
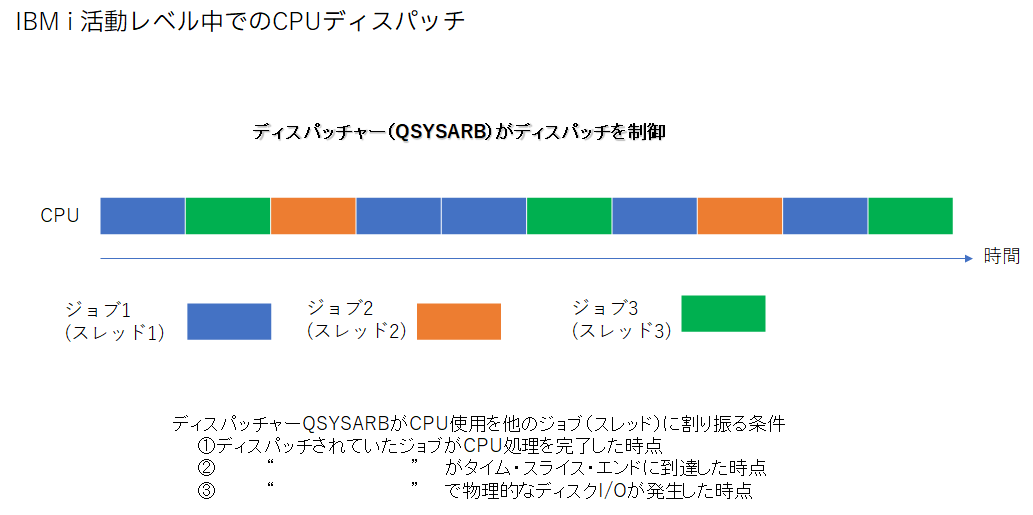
・一時点でCPUを使用できるジョブは1つだけです。どのジョブがCPUを使用できるかはQSYSARB(QSYSアービター)というシステム・ジョブが決定します。(下図)

・QSYSARBがディスパッチするジョブを選択する基準は、各ジョブに指定されている実行優先順位に依存します。実行優先順位はクラス CLS で指定されます。

上記のCLS QBATCHはバッチ用の定義なので、実行優先順位が50と比較的低くなっています。対して*CLS QINTERは30です。

バッチジョブと対話型ジョブが同一条件でCPUにディスパッチされるのを待っていたとすると、優先順位としては対話型ジョブが優先されることになります。
ディスパッチされ実行中のジョブがCPUを使用する権利を失い、他のジョブにディスパッチが移る契機は以下の3つです。
- ディスパッチされていたジョブがCPU処理を終了
バッチジョブの場合はジョブの終了、対話型ジョブの場合はロング・ウェイトに入った状態です。 - タイム・スライス・エンド
ディスパッチされているジョブが使用したCPU処理時間が、そのジョブの*CLS クラスのタイムスライス値に達した場合
3. 物理的ディスク装置I/Oの発生
ディスパッチされたジョブがメインメモリに無いプログラム・コードやデータ・レコードをアクセスしようとして物理的I/Oが発生した場合にも、ジョブはディスパッチを他のジョブに渡します。ただし、アクセスしようとしたプログラムコードやデータ・レコードがメイン・メモリ上にあった場合はそのままディスパッチされたジョブは継続して処理を続けることができます。
■CPUのマルチスレッド
※近年のCPUは1つのCPUコアの中に、並列に動作する複数の演算回路を搭載しています(ハイパースレッド(Intel系)やSMT(POWER))。上図では単純化のためにハイパースレッドやSMTの表記は省略しています。
模式的にはこのようなイメージになります。

POWER10の場合、1つのCPUコアの中に8つの独立した回路がありSMT8モードでは8並列で動作します。前章の図では横軸のラインが1つですが、これが1コアで8本あるイメージになります。
※また、1つの物理的なCPUチップ(1ソケット、と表現される=自作PC作った方なら周知のとおりですが買ってきたマザーボードにCPUを刺すソケットのことです)の中に複数のコアが搭載されていることが最近は多いと思います。POWER10の最小モデルであるPOWER S1014の最小モデルでも1ソケットで4コアを搭載しています。
POWER S1014の最小モデルで4コアをフルアクティベーションした場合、同時並行処理できる演算回路の数=スレッド数は、8スレッド・1コア X 4コア・1ソケット = 32スレッドとなります。
前章の例ですと、プール2だけだと仮定すると、最大147ジョブがOSレイヤーでは稼働でき、それを32スレッドに割振りして(並列処理して)いる、という事になります。(実際はプール1~4の合計の最大活動数になります。)