はじめに
今までなぁなぁにしてきたRedisをいまさらながらに勉強してまとめました。
Redisって聞いたことあるけど中身はよく知らないとか、プロジェクトでなんとなく使っているけど実はよく分かっていないなどの人向けのページです。

NoSQL
Redisの前にまずはNoSQLから。
背景
ビッグデータの登場により、従来のRDBだけでは充分な処理ができなくなってきたことがNoSQL登場の背景にある。
ビッグデータの定義は色々ありますが、ここでは3V(Volume/Velocity/Variety)を満たすものをビッグデータと呼びます。
VolumeとVelocityの問題を解決するためにNoSQLが必要
Volume(大量データ)とVelocity(秒単位で大量データ)に関する問題を対処する場合、スケールアップ(メモリ増加、コア数増加、SSD化)とスケールアウトの2通りの方法がある。
しかしながら、スケールアップは物理的な限界があるし、RDBのスケールアウトは一般的に難しい。
NoSQLは一般的にRDBよりもスケールアウトが容易に行える。
Varietyの問題を解決するためにNoSQLが必要
Variety(非リレーショナルな多様なデータ)をRDBで扱うのはそもそも辛い。
特徴
- 4つの種類と代表的なOSS
- KVS(キーバリューストア): キーとバリューの組み合わせ
- Redis
- memcached
- カラム指向データベース: 列方向のデータのまとまりをファイルシステム上の連続した位置に格納し効率的にアクセスする
- cassandra
- HBASE
- ドキュメント指向データベース: キーに対してJSONあるいはXMLを格納する
- mongoDB
- couchDB
- グラフ指向データベース: グラフ理論に基づいて関連性を持たせる
- neo4j
- TITAN
- KVS(キーバリューストア): キーとバリューの組み合わせ
- 高速
- インメモリで動作
- トランザクション処理ができない
- ACID特性でない
- スケールしやすい
- ただしAWSのAuroraのようにスケールが容易なRDBもでてきているためこの特徴は薄れてきている
NoSQLとRDBの使い分け
- 使い分け
- 基本的にはRDBを採用し、NoSQLがどうしても必要な以下のユースケースのみ導入する。
- ユースケース
- リレーショナルに保存する必要のないデータを保存するケース
- 超低レイテンシーが求められるケース
- 超大容量のデータを保存するケース
Redis
いよいよRedisについてです。
特徴
- Remote Dictionary Serverの略
- OSS(BSDライセンス)
- KVS
- 豊富なデータ型
- String/List/Set/Sorted Set/Hash
- 高速
- インメモリDBだから
- 永続化設定可能
- シングルスレッド
- 自動的に排他的となる
- Redis3.0以降ならスケールアウト可能(2018/11時点ではRedis5.0.0が最新)
豊富なデータ型
- String
- 一番基本的な型
- いわゆるkey/value
- List
- key(list名)/value(listに格納する値)
- listなので同じkeyに複数の値を格納できる
- Set
- key(set名)/value(setに格納する値)
- setなので同じkeyに複数の値を格納できる
- set内
- 重複を許さない
- 順不同
- Sorted Set(ZSet)
- key(set名)/value(setに格納する値とそのscore)
- set内
- 重複を許さない
- 順番はscoreで保持する(setへの保存時にscoreを指定する)
- Hash
- key(hash名)/value(hash)
- key-valueの入れ子構造になる
図でいうとこちらの記事がイメージしやすかった。
レプリケーション
マスターのデータをスレーブにコピーすることで読み取り処理の負荷分散と耐障害性を高める方法。
マスターは読み書き両方ができるが、スレーブは読み込み専用。
マスターはスレーブは複数もつことができる。
レプリケーションは非同期に行われる。
設定方法はこちらの記事が参考になりそう。
後述するAWSのElastiCacheサービスでは、マスターのことを"プライマリノード"、スレーブのことを"リードレプリカ"と呼ぶ。
データの永続化(バックアップ)
RDBとAOFの2種類の方式が存在する。
後述するAWSのElastiCacheではAOFが利用可能だが、そもそもバックアップ機能を利用せずにMulti-AZのレプリカ構成が推奨されている。
RDB(スナップショット)
デフォルトで有効になっている方式。
定期的にデータベースの内容をディスク(dump.rdbというバイナリファイル)に保存する。
再起動時にはdump.rdbを元にデータが復元される。
故障時は最後に取ったバックアップからの差分のデータは消失してしまう。
# save "" # RDBに保存しない
save 900 1 # 900秒以内に1回以上の更新があったらRDBに保存する
save 300 10 # 300秒以内に10回以上の更新があったらRDBに保存する
save 60 10000 # 60秒以内に10000回以上の更新があったらRDBに保存する
AOF(Append Only File)
更新処理ごとにその処理内容を保存し続ける。
消失する心配は減るが、更新系の処理のパフォーマンスが下がる。
appendonly yes
(省略)
# appendfsync always # AOFへ常に同期的に書き込む
appendfsync everysec # AOFへ1秒毎に同期的に書き込む
# appendfsync no
(省略)
Redisの使い所
- 有効期限のあるデータを扱う場合
- セッション、ワンタイムトークンなど
- データ保存時にexpire指定できる
- ランキングデータを扱う場合
- Sorted Set(ユーザID/スコアなど)を利用する
- RDBのorder byより速い
- IoTデータの一時保存先として使う場合
- Pub/Subを使う場合
Redisとmemcachedの使い分け
とりあえずRedisの方が多機能だと思っていれば初心者はよさそう。
Redisを選択すべきケース
- 複雑なデータ型が必要な場合
- 永続化が必要な場合
- フェイルオーバーが必要な場合
- pub/subが必要な場合
memcachedを選択すべきケース
- シンプルなデータ型だけで充分な場合
- マルチスレッドが必要な場合
Redisをローカルで触ってみる
install(MacOSの場合)
$ brew install Redis
起動
サーバー起動
$ redis-server
クライアント起動
$ redis-cli
CLI
起動したクラアイント側でCLI操作する。
ここでは基本的な操作方法のみ記載します。
さらに細かい操作方法はこちらの記事が参考になります。
各実行例にあるflushallはDB内の全てのキーを削除するコマンドです。
String型
setでvalueを登録する。
getでvalueを取得する。
127.0.0.1:6379> set str1 hello
OK
127.0.0.1:6379> get str1
"hello"
127.0.0.1:6379> flushall
OK
setexで有効期限付きで登録する。
ttlで有効期限の確認する。
127.0.0.1:6379> setex str1 10 world
OK
127.0.0.1:6379> ttl str1
(integer) 7
127.0.0.1:6379> ttl str1
(integer) -2
127.0.0.1:6379> get str1
(nil)
127.0.0.1:6379> flushall
OK
msetで複数の登録をまとめてする。
mgetで複数の取得をまとめてする。
127.0.0.1:6379> mset str1 hello str2 world
OK
127.0.0.1:6379> mget str1 str2
1) "hello"
2) "world"
127.0.0.1:6379> flushall
OK
incrで数字をインクリメントする。
decrで数字をデクリメントする。
127.0.0.1:6379> set str1 0
OK
127.0.0.1:6379> incr str1
(integer) 1
127.0.0.1:6379> get str1
"1"
127.0.0.1:6379> decr str1
(integer) 0
127.0.0.1:6379> get str1
"0"
127.0.0.1:6379> flushall
OK
List型
lpushで先頭にvalueを登録する。
lrangeで先頭要素と末尾要素を指定して取得する。0と-1を指定した場合は全て。
lpopで先頭の値を取得する。
127.0.0.1:6379> lpush list1 abc
(integer) 1
127.0.0.1:6379> lpush list1 def
(integer) 2
127.0.0.1:6379> lrange list1 0 -1
1) "def"
2) "abc"
127.0.0.1:6379> lpop list1
"def"
127.0.0.1:6379> lrange list1 0 -1
1) "abc"
127.0.0.1:6379> flushall
OK
rpushで末尾にvalueを登録する。
rpopで末尾の値を取得する。
127.0.0.1:6379> rpush list2 abc
(integer) 1
127.0.0.1:6379> rpush list2 def
(integer) 2
127.0.0.1:6379> lrange list2 0 -1
1) "abc"
2) "def"
127.0.0.1:6379> rpop list2
"def"
127.0.0.1:6379> lrange list2 0 -1
1) "abc"
127.0.0.1:6379> flushall
OK
lremで削除する。削除する個数は指定できる。0の場合は全て。
127.0.0.1:6379> lrange list1 0 -1
1) "abc"
2) "def"
3) "abc"
127.0.0.1:6379> lrem list1 0 abc
(integer) 2
127.0.0.1:6379> lrange list1 0 -1
1) "def"
127.0.0.1:6379> flushall
OK
Set型
saddで登録する。
smembersで値を全て取得する。
sremで値を削除する。
127.0.0.1:6379> sadd set1 abc
(integer) 1
127.0.0.1:6379> sadd set1 def
(integer) 1
127.0.0.1:6379> smembers set1
1) "def"
2) "abc"
127.0.0.1:6379> srem set1 abc
(integer) 1
127.0.0.1:6379> smembers set1
1) "def"
127.0.0.1:6379> flushall
OK
setなので同じ値を登録しようとしても、登録できない。
127.0.0.1:6379> sadd set1 abc
(integer) 1
127.0.0.1:6379> sadd set1 abc
(integer) 0
127.0.0.1:6379> flushall
OK
Sorted Set型
zaddでscoreと併せて登録する。scoreの値はマイナスでも構わない。
zrangeで先頭要素と末尾要素を指定して取得する。0と-1を指定した場合は全て。
zremで削除する。
127.0.0.1:6379> zadd zset1 5 abc
(integer) 1
127.0.0.1:6379> zadd zset1 -10 def
(integer) 1
127.0.0.1:6379> zrange zset1 0 -1 withscores
1) "def"
2) "-10"
3) "abc"
4) "5"
127.0.0.1:6379> zrem zset1 abc
(integer) 1
127.0.0.1:6379> zrange zset1 0 -1 withscores
1) "def"
2) "-10"
127.0.0.1:6379> flushall
OK
Hash型
hsetで登録する。
hgetでvalueを取得する。
hgetallでまとめてhashを取得する。
hdelでhashを削除する。
127.0.0.1:6379> hset hash1 field1 abc
(integer) 1
127.0.0.1:6379> hget hash1 field1
"abc"
127.0.0.1:6379> hset hash1 field2 def
(integer) 1
127.0.0.1:6379> hgetall hash1
1) "field1"
2) "abc"
3) "field2"
4) "def"
127.0.0.1:6379> hdel hash1 field1
(integer) 1
127.0.0.1:6379> hget hash1 field1
(nil)
127.0.0.1:6379> flushall
OK
Python(redis-py)
有名な言語であればライブラリが用意されているが、ここではPythonを例にまとめる。
install
$ sudo pip install redis
接続
コネクションプールを使う方法と使わない方法の2パターンがある。
コネクションプールを使う方が速いらしい。
import redis
pool = redis.ConnectionPool(host='localhost', port=6379, db=0)
r = redis.StrictRedis(connection_pool=pool)
import redis
r = redis.StrictRedis(host='localhost', port=6379, db=0)
操作
ここではString型の簡単な例だけ記載する。
他の型やもう少し詳しい使い方はこちらの記事を参考にするとよさそう。
r.set("key1", "hello")
print(r.get("key1"))
b'hello'
pub/sub
概要
publishとsubscribeの略。
あるクライアントがpublish(チャンネルにメッセージを送信)すると、subscribe(チャンネルを購読)しているクライアントがそのメッセージを受け取れる機能。
RedisはKVS的使い方以外にも、pub/sub機能を有している。
使い方
サーバー起動する。
$ redis-server
クライアントAを起動し、チャンネルをsubscribeする。
$ redis-cli
127.0.0.1:6379> SUBSCRIBE sample_channel
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "sample_channel"
3) (integer) 1
クライアントBを起動し、チャンネルにPUBLISHする。
$ redis-cli
127.0.0.1:6379> PUBLISH sample_channel "Hello! World!"
(integer) 1
クライアントA側でクライアントB側でPUBLISHされたメッセージが確認できる。(★マーク)
$ redis-cli
127.0.0.1:6379> SUBSCRIBE sample_channel
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "sample_channel"
3) (integer) 1
1) "message" ★
2) "sample_channel" ★
3) "Hello! World!" ★
ElastiCache
ElastiCacheはAWSのインメモリキャッシュに関するマネージドサービスです。
キャッシュエンジンはRedisとmemcachedが選択可能。
ノード、シャード、クラスタの単位が存在する。

ノード(Node)
キャッシュサーバ。
ElastiCacheの最小単位。
選択したノードタイプによって性能(メモリやCPUなど)が異なる。
シャード(Shard)
ノードをまとめるグループ。
1つのシャードにプライマリノード(読み書き可)1個と、リードレプリカ(読み込み専用)0〜5個を持つ。
クラスタ(Cluster)
シャードをまとめるグループ。
クラスタ毎にキャッシュエンジンを選択可能。
クラスタモードは有効と無効を選択可能。
クラスタモード無効
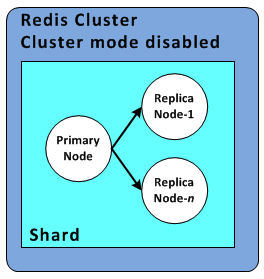
上図はレプリケーションも有効のものです。
- クラスタ1つにシャード1個を持つ
クラスタモード有効
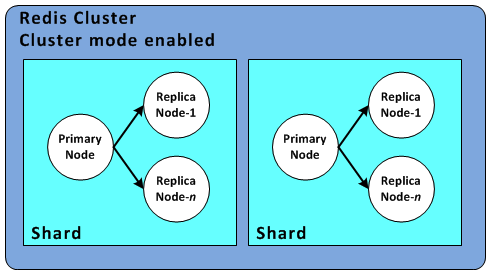
上図はレプリケーションも有効のものです。
- クラスタ1つにシャード1〜15個を持つ
- スケールアウト/スケールイン可能
- シャード数の増減により変更
スケールアップ/スケールダウン
- スケールアップ可能
- ノードタイプをAPIを利用して変更
- スケールダウン不可
Multi-AZ
t2以外のノードタイプであればMulti-AZが選択可能。ノードをMulti-AZに配置することができる。
昔はmemcachedはMulti-AZが不可だったが、最近はmemcachedも対応したため、Redisにとってそこでの優位性は失われた。
障害発生時
障害発生時には自動フェイルオーバー(故障ノードから新しいノードへの切り替え)する機能が用意されている。
プライマリノードが故障した場合
- リードレプリカの1つ(複数ある場合は最も最新のデータが記録されているものが自動選択される)がプライマリノードに昇格する
- フェイルオーバー中はプライマリノードへの書き込みは不可
- 昇格して減った分のリードレプリカは新しく補填される
リードレプリカが故障した場合
- 新しいリードレプリカノードを自動生成し、故障したノードから切り替える
- フェイルオーバー中の読み込み処理は他のノードに負荷が集中する
クラスタ全体が故障した場合
- シャードもノードも自動で再作成
- 永続化していない場合データは失われる
- 永続化は非推奨なのでどうしても永続化したいデータは定期的にRDBに格納すべし
使ってみた
クラスタモード無効

- クラスターエンジン
- Redisを選択
- クラスターモードを有効のボタン
- チェックつけない

- ポート番号
- デフォルトの6379
- パラメータグループ
- cluster.onが付いていないもの
- ノードタイプ
- 検証用のため最も安いもの(t2.micro)を選択
- レプリケーション数
- リードレプリカの数のこと
- 2を選んだ場合はクラスタの中にプライマリが1台とリードレプリカが2台生成され、合計3台になる

- Multi-AZ
- ノードタイプがt2なので選択不可

- セキュリティグループ
- 同一VPC内のEC2インスタンスからの6379を受け入れるセキュリティグループを作成して選択する
- 同一VPC内のEC2インスタンス以外からも接続はできるがVPNの設定とかめんどい
- 同一VPC内のEC2インスタンスからの6379を受け入れるセキュリティグループを作成して選択する
- 保管時の暗号化
- 保管したデータを暗号化するかどうか
- 送信中の暗号化
- EC2インスタンスやノード間の通信を暗号化するかどうか

- バックアップ
- ノードタイプがt2なのでバックアップは選択不可

- メンテナンス
- ElastiCacheのパッチ適用が発生した場合に、パッチを適用する時間を指定できる。
- 運用サービスのメンテナンス時間やリクエストが少ない時間帯に設定するのが良さそう。
- 通知方法も指定できる。
- 今回は検証用なので設定しない。

- 最終的にこんな感じ
クラスタモード有効
上のクラスターモード無効の例との違いがある部分だけ説明します。

- クラスターモードを有効のボタン
- チェックする

- パラメータグループ
- cluster.onが付いているもの
- ノードタイプ
- m3.medium(検証用にMulti-AZやバックアップ機能を確認するために選択)

- Multi-AZ
- チェックつけて有効化
- スロットおよびキースペース
- シャードの負荷分散方法を選択する
- デフォルトの均等分散を選択
- アベイラビリティゾーン
- ノード単位でアベイラビリティゾーンを指定可能
- 今回は指定なし

- バックアップ
- 自動バックアップを有効化
- AOF
- 自動バックアップを有効化
作成後の変更できることできないこと

- キャッシュエンジンのバージョン変更
- アップグレード可能
- ダウングレード不可
- パラメータグループ変更可能
- バックアップ設定変更可能
- 通知方法変更可能
- シャード数の増減可能
- レプリカ数の増減可能
感想
- ローカルにインストールするにしてもElastiCacheを利用するにしても簡単にRedisを使い始めることができる
- 単純なデータしか扱えない分、覚えることが少ないので学習コストは低い
- とりあえずRedisが使えるようになっておけばmemcachedもいけそう