背景
前回の続き
参考書の最後の章にあるDQNをやってみる
いよいよkerasを使って深層強化学習なので期待が高まっている
前提
前回と同じ
これが達成できればいつまでも上昇気流に乗っていられるはず
Deep Q Network
環境
予想通り環境を作るのに苦労した、、
- クラウド上に構築するのがよいのか?
- どのくらい時間がかかるかわからないし、そもそも成功するかわからないし、、
- 手元である程度目途つけたい
- できればGPU使える環境を試したい
せっかく持っているのだから自前のGPUを使おうなどと思わなければもっと容易に環境を作れたのかもしれない。
最終的に動いた環境は以下
- Ubunto20.4
- Cuda11.3
- driver 165.19.01
- cuDNN 8?
- docker tensorflow/tensorflow:latest-gpu-jupyter
果たしてこの組み合わせで動いているのか確証が持てないものの、nvidia-smiで確認すると動いている形跡があるので良しとして先に進める
サンプル収集、学習
以下の形でデータをため込んでゆく。数を打って最後のゴールまでだどりつくケースを多く集める
(空域の配列(9X9), 上昇帯の配列(9X9), パイロットの進行方向(9X9), 次の進行方向, 価値)
サンプルを集めるに従ってゴールする確率やゴールするまでの手数が少なくなると思っていたもののそうでもなく、やたらゴールするイテレーションが続いた後まったくゴールしなくなる、という波がある。開始位置や進行方向が異なると未学習部分が多く出てくるからか?
ネットワーク
参考書をまねて作成したネットワークの模式図が以下。
それぞれの値が適切なのか?適切な値ってどうやって決めるのか?など疑問はあるもののまずは最後まで走りきる所を目指す
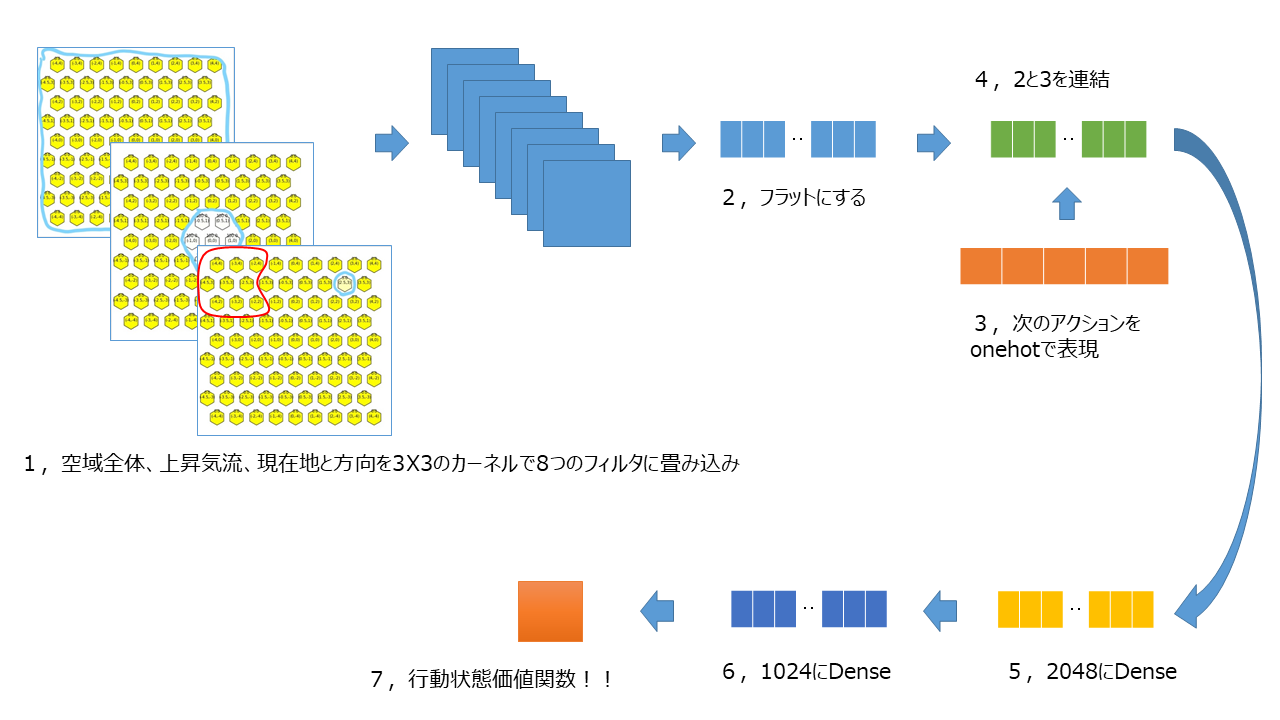
Model: "model"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, 3, 9, 9)] 0
__________________________________________________________________________________________________
conv2d (Conv2D) (None, 3, 9, 8) 656 input_1[0][0]
__________________________________________________________________________________________________
flatten (Flatten) (None, 216) 0 conv2d[0][0]
__________________________________________________________________________________________________
input_2 (InputLayer) [(None, 6)] 0
__________________________________________________________________________________________________
concatenate (Concatenate) (None, 222) 0 flatten[0][0]
input_2[0][0]
__________________________________________________________________________________________________
dense (Dense) (None, 2048) 456704 concatenate[0][0]
__________________________________________________________________________________________________
dense_1 (Dense) (None, 1024) 2098176 dense[0][0]
__________________________________________________________________________________________________
dense_2 (Dense) (None, 1) 1025 dense_1[0][0]
==================================================================================================
Total params: 2,556,561
Trainable params: 2,556,561
Non-trainable params: 0
これでエピソードをためて学習をすれば上昇気流を目指し、乗り続けるモデルができるはず
結果
期待したような爽快感のある結果が出ない
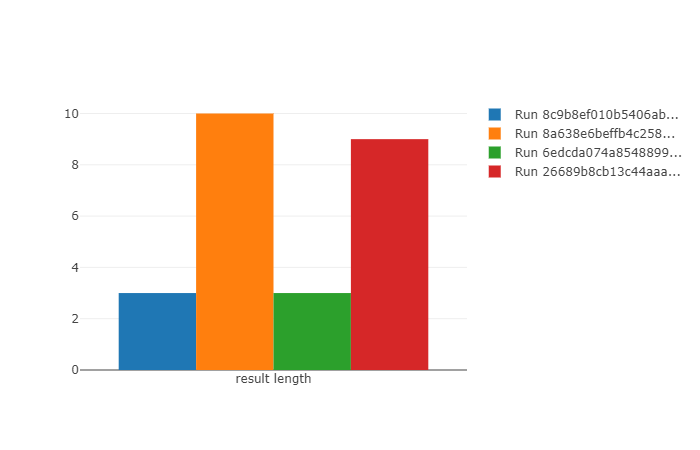
同じ条件で再実行しても同じ結果にならない。オレンジと赤は上昇気流に乗れたものの道筋が異なる。青と緑の2件は上昇気流に乗れなかった。
GPUを使うと計算順序が固定できないから再現はできない、などの記事を見たりして辿り着いたのがこのコードで、公式に乗っているこの方法で安定しないようであれば次の手は考えつかない、、
tf.random.set_seed(seed)
np.random.seed(seed)
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
必要と思われる乱数シードを設定したうえで同じ条件の学習を行う
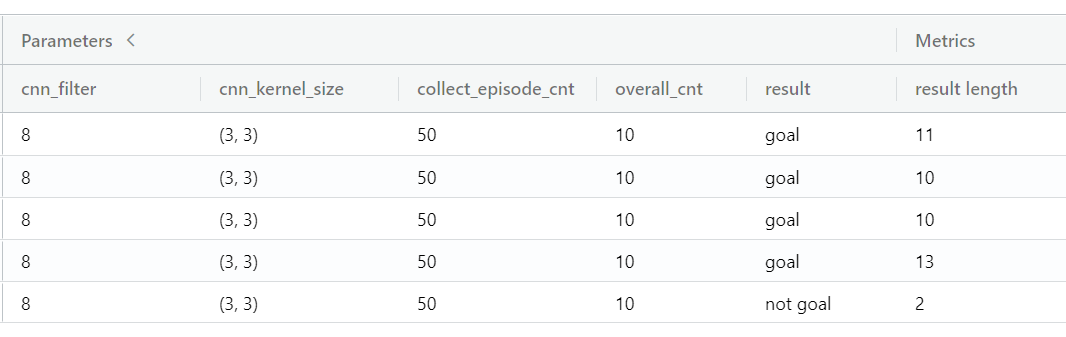
再現しない、、、同じ条件なのに2手で失敗して終わったり13手で成功して終わったりする。
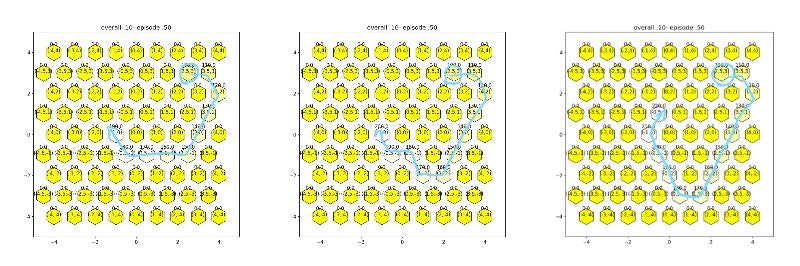
すべて成功しているが、一番左の10手で成功しているもの以外は直観的に最適ではない。
エピソードをため込むところで差が出ているのか?、学習しているところで差が出ているのか?、そもそもCPUだけで計算したら発生しないのか?など確認すべき点はあると思うもののとりあえずの結果はここに至るまでで出ているのでここまでにする
このあと
冴えない感じではあるものの、一通りは体感できたので良しとする。(最初にゴールまでのルートをある程度用意してから学習させればよいのでは?など考えたものの、この大きさの空域だと、そのデータが用意できた時点で学習の必要がなくなってしまう、、)
強化学習のフレームワークがもっとよくなり、カスタムメイドの環境、状態、行動を容易に設定できるようになるともっといろいろ試せるようになるのに、、
[前回]
(https://qiita.com/goichiya/items/3c7742621ace038b284c#%E3%81%93%E3%81%AE%E3%81%82%E3%81%A8)の続き
PC上でできることは一通りできた。
実際に飛ぶときの状態に合わせて作成したモデルをどのように持ち出して利用するか考えてゆく
なぜこうなったのかもう少し考える、、(新)進行方向を考慮した表現もなんとかしたい(新)できればベストの方向を表示させたいもっと強化学習っぽいアルゴリズムを試してみるサーマルエリアに4回以上滞空出来たらゴールとしたい(サーマルエリアを突っ切って出てしまわないように- いつの日か実際の距離感に合わせてみたい
- そしてさらにいつの日か携帯デバイスとして飛びながらベストな方向を教えてくれるようにしたい
参考
この本を参考にここまで来ました
ITエンジニアのための強化学習理論入門
乱数の設定で参考にしたサイト