背景
前回の続き。
参考書の流れにあわさせてQlearningをやってみる。
強化学習でよく聞くモデルなのでちょっとテンションが上がっている
前提
前回からちょっと変えて連続してサーマル(上昇気流)に乗っていることをゴールに変更
学習時の条件をパラグライダーで実際に達成したい条件に近づけた。
- 一つのセルは六角形、セルの組み合わせで空域を構成
- 設定した空域の真ん中付近にサーマルエリア(上昇気流帯)
- 進行方向に向かって正面、右斜め前、左斜め前にしか進めない
- 出発位置はランダムに決定
- 次の進行方向は空域の外に出ないようにランダムに決定
- サーマルに連続して4回留まればゴール
Qlearning
ここまで順番にやってきていると、実装内容はそれほど変わるものではなかった。
全体の流れは以下。
- 必要なライブラリのインポート
- 空域の広さ、サーマル(上昇気流)の場所、今の進行方向に対して取り得る次の進行方向などを定義
- パイロットの初期化、動き方を定義したメソッド、動いた結果による報酬の計算を定義(表示をヘックスにしたいので余分な計算も入っている)
- 表示関連の処理を定義
- エピソードの定義(train,predict双方で使うので中で処理を分岐。predictの時は学習せずに結果だけ使って(結果で得たpolicyだけ使って)エピソードを進めてゆく)
- policyの更新処理を定義
- trainの処理を定義(取得するepsode数やepsilonの値は引数で与える)
- 実行して結果を表示!
空域のイメージ
大戦略とかシミュレーションゲームで見るような6角形のセルで平面を表現
今まで通り9x9、上昇気流は中央付近の7セル(赤線内)

状態、行動、ポリシー、行動―状態価値関数、報酬
-
状態は現在地と現時点での進行方向を表現
(x,y,進行方向) -
行動はセルの辺の方向に向かって動く(6方向)
[0, 1, 2, 3, 4, 5] -
今の進行方向に対して、次に選択できる行動正面、左斜め前、右斜め前に限定される
actions = {0:[5,0,1],1:[0,1,2],2:[1,2,3],3:[2,3,4],4:[3,4,5],5:[4,5,0]} -
ポリシーは状態をキーにして設定
{(x,y,進行方向):ポリシー} -
行動―状態価値関数は状態、次の行動をキーに設定
{(x,y,進行方向),次の進行方向):行動―状態価値関数}
行動―状態価値関数を初期化する際に、進行方向に対して取り得ない次の進行方向についてはすごく小さな値を設定しておく。取り得る次の進行方向については0で初期化することで見学習のルートの学習を促す。
- 上昇気流に入った場合の報酬は1、
- 上昇気流に関係ない移動の報酬は -1(移動先が空域外に出る場合はその場にとどまり、ポリシーを更新)
get_episode
trainの場合はepisodeの終了を待たず、逐次的に行動―状態価値関数が計算されてpolicyを更新するため、学習処理がget_episode内に取り込まれコードがスリムになってように思える。
def get_episode(pilot,epsilon,train,s_p=(2,2,2),a_p=2):
# trainの場合はスタート地点をランダムに決定して学習を進める
# trainでない場合は渡された位置から既存のポリシーに従って進める(epsilo=0で学習結果の確認)
episode = []
# 最初の状態をランダムに決定
# statusの形で初期のstateを決定
x = np.random.randint(-4,5)
y = np.random.randint(-4,5)
direc = np.random.randint(0,6)
s = (int(x),int(y),int(direc))
# 初期状態フラグ
initial = True
while True:
# 初期状態の場合
if initial:
if train:
cand_direc = actions[s[2]]
a = npp.random.choice(cand_direc)
initial = False
else:
s=s_p
a=a_p
initial = False
else:
# epsilon-greedy
if np.random.random() < epsilon:
cand_direc = actions[s[2]]
a = npp.random.choice(cand_direc)
else:
a = pilot.policy[s]
r, s_new = pilot.fly(s,int(a))
episode.append((s,a,r))
# トレーニング状態を判別することで、学習時と予測時を切り分ける
if train:
pilot.q[(s,a)] += 0.2 * (r + pilot.q[(s_new,pilot.policy[s_new])] - pilot.q[(s,a)])
policy_update(pilot,s)
# 連続して4回上昇気流に入っていたらブレーク
if pilot.stay_cnt>=4:
break
s=s_new
return episode
結果
出た!前回同様アクションごとの出力を見てみる

ところどころ直観的に?という部分もあるものの(赤枠)、取り得ない方向を選択してはいないので経路として通っていないことが原因かもしれない。(取りうる方向は0で初期化、それ以外はすごく小さい値で初期化したので前回のように取り得ない方向がポリシーと採用されることはなくなった)
上手く動いてそうなので、学習回数を変えながら状態(3,1,0)、次の行動が0方向を起点にしたルートの予測結果を比較してみる
100回(Wall time: 1.27 s)
端っこに行ってスタックしてしまった、、

1,000回(Wall time: 6.21 s)
おぉ、それっぽく到達してサーマルを回り始めている

10,000回(Wall time: 55.7 s)
なぜ大回りしたし、、、
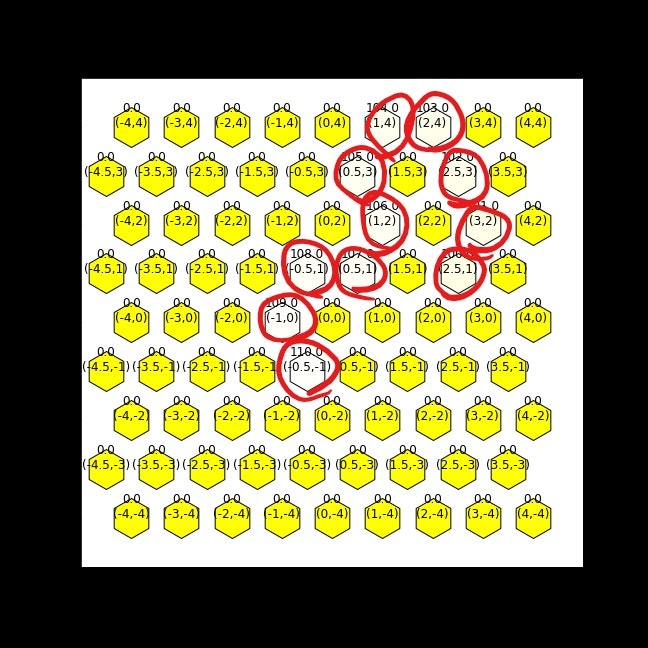
100,000回(9min 21s)
それっぽいルートになった。結果としては1,000回の時と一緒
ここまでやってみると1,000回の結果は偶々だったのか?と思ってしまう。
この設定だとおそらく今のがベストであろうと見た目でわかるが、もっと複雑な状態だと「これで十分!」と確信するには学習回数を増やしても結果が変わらなくなるまで学習し続けるしかないのか?そこで、200,000回実行して結果を確認したところ、100,000回と同じルートになった。
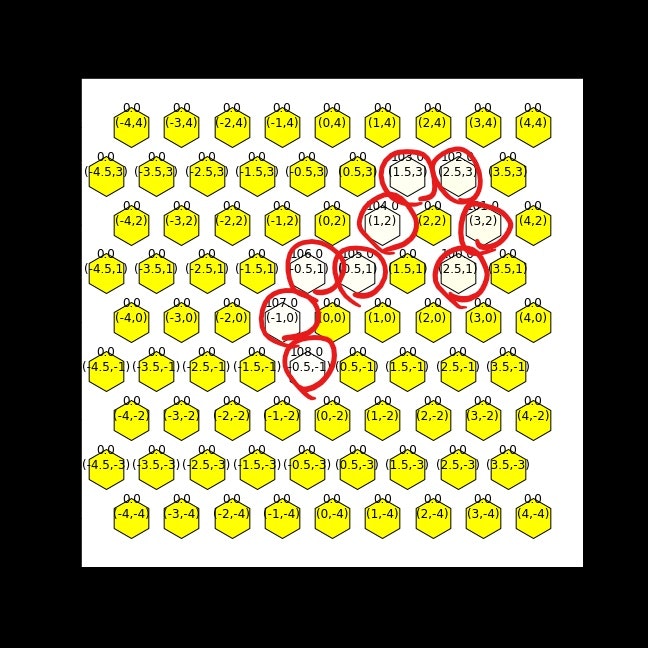
このあと
だんだんイメージしていた強化学習っぽくなってきて、起点を変えながら嬉々として遊んでいる。
今は200,000回試行しても20分程度で済んでいるものの、空域を広げたりすると計算資源は相応に必要になってくるので、応用してゆく際にはパフォーマンス面をもう少し見たほうが良いかも。どうあっても1回は成功するルートを探し出さないと計算が有効に進むことはないという点が教師ありとか教師なしとかでも感じた力業感に似ている
なぜこうなったのかもう少し考える、、(新)進行方向を考慮した表現もなんとかしたい(新)できればベストの方向を表示させたい- もっと強化学習っぽいアルゴリズムを試してみる
サーマルエリアに4回以上滞空出来たらゴールとしたい(サーマルエリアを突っ切って出てしまわないように- いつの日か実際の距離感に合わせてみたい
- そしてさらにいつの日か携帯デバイスとして飛びながらベストな方向を教えてくれるようにしたい
参考
参考書の流れに従って次はニューラルネットワークする予定
ITエンジニアのための強化学習理論入門
環境やライブラリは執筆時点とコ異なっているので、gpu,tensorflowあたりを乗り越えられるかが最初の関門の気がしている。