1. はじめに
Octillery というGo言語用のデーターベースシャーディングライブラリを開発したので紹介します。
すでにいくつかあるライブラリ ( evalphobia/wizard や go-pg/sharding )と異なる点は
-
database/sqlパッケージのインターフェースを実装するすべてのORMライブラリで利用できる -
database/sqlの機能を直接使っていても利用できる - 特定のデータベース実装に依存せずに利用できる設計になっている
- シャーディングアルゴリズムがプラガブルになっている
あたりです。ライブラリの利用環境をなるべく限定したくないという思いから、特定の実装に依存しないような作りを目指して設計しました。
ライブラリの実装自体は昨年のうちに終わっていましたが、運用実績を作るために温めてきました。
ライブラリはすでに本番環境で半年ほど運用されており、今も継続的に利用・開発しています。
本稿ではデータベースシャーディングライブラリが提供すべき機能要件を実装視点から解説し、Octillery がそれらをどう解決したかという実装・設計の話、最後に使い方について触れたいと思います。
2. データベースシャーディングとは
この記事を読んでいる方にいまさらデータベースシャーディングについて解説する必要はないと思うので、シャーディングの仕方によってどうアプリケーションの設計が変わってくるかに重きをおいて解説してみたいと思います。
例えば以下のようなスキーマの posts テーブルがあったとします。
CREATE TABLE `posts` (
`id` bigint unsigned NOT NULL AUTO_INCREMENT,
`user_id` bigint unsigned NOT NULL,
`created_at` datetime NOT NULL,
`updated_at` datetime NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `uq_posts_01` (`user_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
いま、このテーブルに対する書き込みクエリが尋常じゃないほどありそうなので、負荷分散したいという要求が生まれたとします。
このとき、数ある解決策の中でデータベースシャーディングによって負荷分散する方法を選択したときにとる構成を何パターンか紹介したいと思います。
2.1. シーケンサー(採番器)を使って id カラムの値をすべてのDBの間でユニークにする場合

データベースシャーディングを行うためには、分割されたテーブル間でユニークとなる値(カラム)が必要です。
そのため、例えば上記のようにアプリケーションサーバとデータベースの間に sequencer と呼ばれる id 採番用のDBを構築して、 id 値を各データベース上に配置されているテーブル間でユニークにする方法があると思います。
上の図では、posts テーブルに対してレコードを挿入するような場合に、以下に示す手順でデータの挿入先を決定する様子を表しています。
( posts テーブルはシャーディングによって4テーブルに水平分割されており、それぞれ posts_shard1 ~ posts_shard4 までの異なるデータベース上に格納されているとします )
- アプリケーションサーバからシーケンサに対して、次に
INSERTするときに使うidカラムの値を問い合わせる - シーケンサーで
idを採番する -
id値をアプリケーションサーバに伝える -
INSERT INTO posts (id, user_id, ...) values (null, 1, ...)のようなクエリの中のnullの部分をシーケンサーからもらった値で上書きする -
idの値をシャーディングアルゴリズム(moduloなど )を通すことによって挿入先を知り、クエリを流す
いくつかのレコードを挿入したあと、各データベースの状態は以下のようになります。
| posts_shard_1 | posts_shard_2 | posts_shard_3 | posts_shard_4 | ||||
|---|---|---|---|---|---|---|---|
| id | user_id | id | user_id | id | user_id | id | user_id |
| 1 | 1 | 2 | 2 | 3 | 3 | 4 | 4 |
| 5 | 5 | 6 | 6 | 7 | 7 | 8 | 8 |
ここでのポイントは、 id カラムの値が全データベースの間でユニークになっていることです。同じ値はどこにも存在しません。
2.2. シャードキーを利用してシャーディングする場合 ( id 値は重複しても構わない場合)
2.1 では id カラムをシャーディングに用いましたが、必ずしもその必要はありません。 例に挙げた posts テーブルでは、 user_id が仕様上ユニークになる値として定義されているため、このカラムを利用してシャーディングを行うことができます。また、この場合はシーケンサーを利用する必要はありません。このとき、アプリケーションサーバとデータベースの関係は以下の図のようになると思います。
(今回のように、シャーディングに使うカラムを便宜上 シャードキー と呼ばせていただきます)
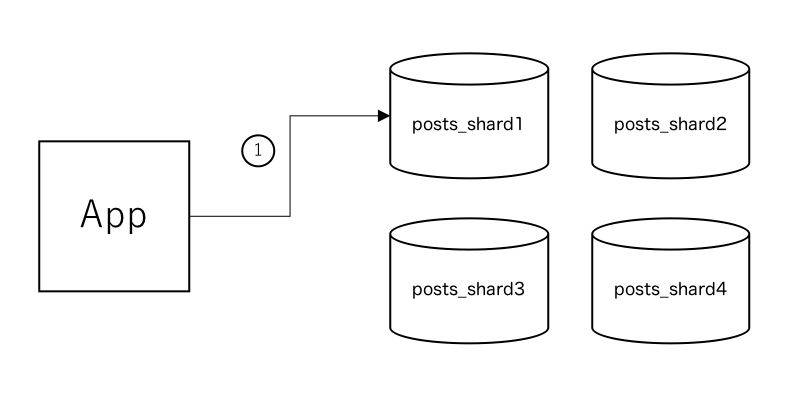
必要な手順は以下の1つだけです。
-
user_idの値をシャーディングアルゴリズム(moduloなど )を通すことによって挿入先のデータベースを知り、クエリを流す
このときにいくつかレコードを挿入すると、各データベースの状態は以下のようになります。
| posts_shard_1 | posts_shard_2 | posts_shard_3 | posts_shard_4 | ||||
|---|---|---|---|---|---|---|---|
| id | user_id | id | user_id | id | user_id | id | user_id |
| 1 | 1 | 1 | 2 | 1 | 3 | 1 | 4 |
| 2 | 5 | 2 | 6 | 2 | 7 | 2 | 8 |
posts テーブルの id 値は AUTO_INCREMENT になっているので、id 値は 1 => 2 と採番されていきます。
2.3. シーケンサーを利用するメリット・デメリット
2.1 , 2.2 で示した2つのアプローチの違いは、つまるところシーケンサーがあるかないかですが、その違いによってどういったメリット・デメリットがあるでしょうか
2.3.1. シーケンサーを利用するメリット
まず、今回の posts テーブルのスキーマにはユニークな値を格納できるカラムが2種類ありました。1つは id カラムで、もうひとつは user_id カラムです。このうち、id の値は本来クエリ上にのる値ではなく、AUTO_INCREMENT によって決定されるものでしたが、user_id は 別の仕組みで作った値を最初からクエリにのせる点が異なります。
もし、posts テーブルにユニークな値を格納するカラムが存在しない場合 ( user_id のようなカラムがない場合)、 PRIMARY KEY である id 値でシャーディングする選択しか取ることができなくなります。この場合、シーケンサーを導入しなければ各データベース上での値がかぶってしまうため、シーケンサーを導入する選択しかとることはできません。
では user_id のようなカラムがある場合はどうでしょうか。この場合はシーケンサーを導入するかどうかを選択することができます。
このとき、あえてシーケンサーを導入するメリットは 分割されたデータベースをまとめるとき にあると考えます。
サービスを運用していく中で、残念ながら予想に反して負荷が少なかった場合、コスト削減のために当初分割していたデーターベース数を減らしたいという要件が出てくると思います。
このとき、シーケンサーを導入していないとどうなるでしょうか。id 値が各データベース側で採番されているために同じ値が存在し、単純に dump => restore しても重複レコードエラーになってしまいます。
シーケンサーがあればエラーなくまとめられるため、オペレーションがかなり楽になります。
2.3.2 シーケンサーを利用するデメリット
シーケンサーを利用することによって起こる課題はおわかりだと思いますが、アーキテクチャが複雑になることです。採番用に別のテーブル(やデータベース)を用意する必要がありますし、アプリケーション側で採番後の値でクエリを置き換えたりするなど処理が複雑になります。
また、負荷分散のためにデータベースシャーディングをおこなったわけですが、シーケンサーでシンプルに LAST_INSERT_ID を利用して採番する場合、シーケンサー自体の負荷を分散させることができないので、やり方を間違えると本末転倒になる恐れがあります。さらに言えば、シーケンサー用に確保しているデータベースが障害で落ちると、復帰するまでの間該当テーブルに関する INSERT はいっさいできなくなってしまいます。
シーケンサーを利用していない場合では、分散先のデータベースのどれかひとつが落ちたとしても、そのデータベースを利用しないクエリは正常に動作するため、シーケンサーを利用する場合に比べて障害耐性が高いことが想像できるかと思います。
2.4 シャーディング対象のテーブルが複数ある場合を考える
2.3 までは posts テーブルの負荷分散だけ考えていましたが、ここでもうひとつ対象テーブルを増やして複数のテーブルに対するシャーディングのアプローチについても考えてみたいと思います。
例えば以下のような points テーブルを用意し、
サービスに対して何かしらの投稿をおこなって、それによってポイントを付与するようなケースを想定して posts テーブルと points テーブルを同一トランザクション内で処理するという場合について考えてみたいと思います。
CREATE TABLE `points` (
`id` bigint unsigned NOT NULL AUTO_INCREMENT,
`user_id` bigint unsigned NOT NULL,
`point` int unsigned NOT NULL,
`created_at` datetime NOT NULL,
`updated_at` datetime NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `uq_points_01` (`user_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
同じトランザクション内で
-
INSERT INTO posts (id, user_id, ...) VALUES (null, 1, ...)
-
INSERT INTO points (id, user_id, point, ...) VALUES (null, 1, 10, ...)
といった2つのクエリを発行したいとします。このとき、データベースの構成によってとりうるアプローチが大きく変わってきます。
2.4.1 posts テーブルと points テーブルを異なるデータベース上に配置する場合
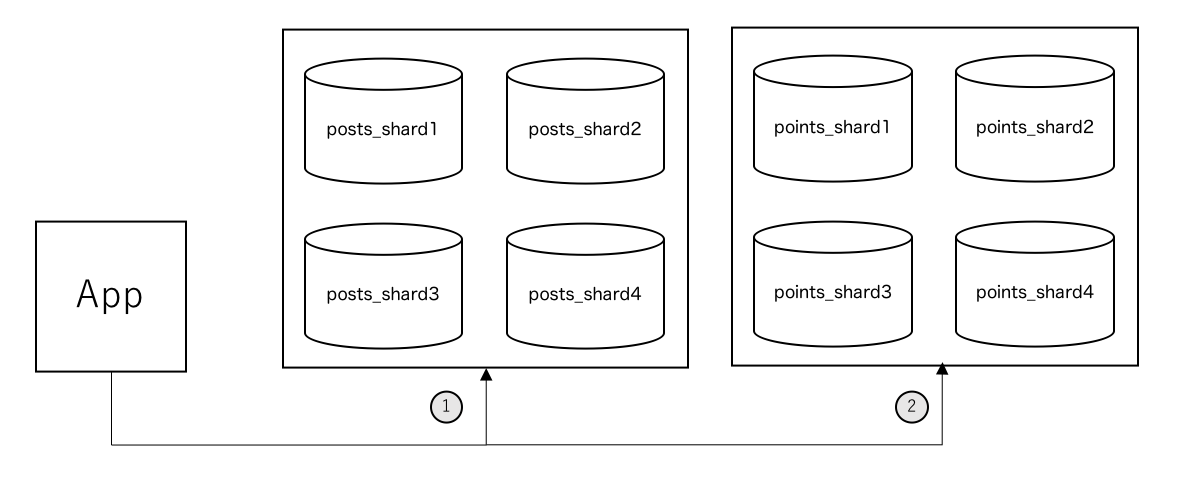
上の図では points テーブルをシャーディングしていますが、テーブルはシャーディングしていてもいなくても構いません。重要なのは posts テーブルのデータが格納されているデータベースとは異なるデータベースに points テーブルのデータが格納されているという状況です。
※ 図中の 1 , 2 は先に挙げた INSERT クエリを発行することを表しています
この方式の利点は、データベースを分けることによってテーブルごとの負荷が見積もりやすくなることが挙げられると思います。
もし posts テーブルと points テーブルが同じデータベースに格納されていた場合、データベースの負荷がどちらのテーブルに起因するものなのか予測しづらくなりますが、あるデータベースに格納されているテーブルが1種類しかない場合は自明です。この特徴から、この方式ではモニタリングのしやすさ・負荷対策のしやすさの点で優れていると考えています。
しかし、posts テーブルのデータと points テーブルのデータが物理的に異なる場所に格納されているため、 JOIN は利用できなくなります。加えて、今回のようにひとつのトランザクション中に posts と points を両方処理したい場合は、分散トランザクションマネージャを用意してそれぞれのテーブルに対応するデータベースのトランザクションを管理し、同時に Commit / Rollback するような仕組みが必要です。 また、片方だけ Commit に成功してもう片方が失敗してしまうとデータ不整合になってしまうため、不整合状態をリカバリする仕組みも必要になります。
2.4.2 posts テーブルと points テーブルを同じデータベース上に配置する場合

上図のように、DB1 ~ DB4 にそれぞれ posts テーブルと points テーブルが配置されます。
ここでのポイントはシャード先を決定する値に user_id を利用することによって、同じ user_id であれば posts , points テーブルに関係なく必ず同じデータベースに格納されるということです。
※ 図中の 1 , 2 は先に挙げた INSERT クエリを発行することを表しています
この方式のメリット・デメリットは先に挙げた方式の逆になります。
同じシャードキーをもとに同じアルゴリズムでシャード対象を決めさえすれば、同じデータベース上に必要なデータ集まるため、 JOIN クエリも利用できるし、トランザクションも同じものを利用できます。分散トランザクション管理から開放されるのは大きなメリットでしょう。
しかし、複数のテーブルが同じデータベースに集まることによって負荷予測がしにくくなり、シャード数を増減するときにはすべてのテーブルのデータを一緒に移動させなければなりません。
2.1 ~ 2.4 でいくつかシャーディングのパターンを紹介してきましたが、弊社では 2.2 であげた シーケンサーなしのパターンで 2.4.1 であげた別データベース上にそれぞれのテーブルのデータを格納する方針でシャーディングを行っています。細かな説明は省きますが、アプリケーションサーバで分散トランザクションマネージャを構築し、障害時に運悪く Commit できなかったクエリだけ、同一ユーザーからアクセスがあったときに自動的に Commit してリカバリするようなことをしています。このあたりの話に興味がある方がいれば、あとで記事にしてみようと思います。
2.5 シャーディングアルゴリズム
2.1 ~ 2.4 では、どういったアーキテクチャでデータベースシャーディングを実現するかによって、考慮しなければいけない課題が変わることを説明しました。
ここでは、シーケンサーから払い出された id 値やシャードキーとして利用しているカラムの値を入力として、シャード対象を決定するためのアルゴリズムについて少し触れたいと思います。
2.5.1 modulo アルゴリズム
シンプルですが、たぶん本番環境でこのアルゴリズムを利用することはないだろうというものが modulo になります。アルゴリズムは非常に単純で
シャード対象 = シャードキーの値 % シャード対象の総数
とするだけです。 ただしこのアルゴリズムには問題があります
シャード対象の総数 というところが問題で、この数が変わるとシャード対象が変わってしまいます。
つまり、負荷によってシャード数を増減させると同じシャードキーであっても格納先が変わってしまいます。
例えば 4 => 8 にシャード対象を増やすと、今まで シャードキーの値が 4 だったものは 0 番目のシャード先を割り当てられていましたが、増えたあとは 4 番目になります。 問題はこの割り振り先が連続した値に対してバラバラになってしまうところで、データベースを増減させたときのデータ移行オペレーションを大変なものにしてしまいます。
2.5.2 ハッシュ値を使ったレンジ指定アルゴリズム
おそらく実際に利用するのはこちらの方法ではないかと思います。
まず最初に実際に用意するシャード数よりもかなり大きな数を設定します。
どんなにサービスが成長してもこの数よりはシャード先を増やすことはないだろうというような数を設定します (例では 1023 )。
シャードキーの値をうまく分散できるようにハッシュ値に変換してから、先程決めた値で mod をとります。
ハッシュ値 = hash(シャードキーの値)
仮想的なシャード対象 = ハッシュ値 % 1023
そうすると、 仮想的なシャード対象 が求まります。ポイントは、シャード数を増減させたとしても同じシャードキーの値であればこの 仮想的なシャード対象 は常に同じものを示すということです。
このあと、この値を範囲指定で実際のシャード対象にマッピングします。
例えば 2 つのデータベースがある場合は、range を
- [1]
0 ~ 511 - [2]
512 ~ 1023
のように指定します。
4 つにする場合は
- [A]
0 ~ 255 - [B]
256 ~ 511 - [C]
512 ~ 767 - [D]
768 ~ 1023
のように指定します。
つまり、仮想的なシャード対象が 100 であれば [1] , [A] がシャード対象で、 300 であれば [1] , [B] が対象です。ここでのポイントは、レンジ指定でシャード先をマッピングしているため、仮想的なシャード対象と実際のシャード対象の関係が自明なことです。
データベースの移行オペレーションは、データベースを倍にしたあとにもとにしたデータベースから値をコピーすればいいだけになります。( [1] => [A],[B] , [2] => [C],[D] )
3. シャーディングライブラリに求められること
データベースシャーディング機能をライブラリとして提供するものに求められるのは、シャード処理の隠蔽に尽きると思います。
2 であげたいろいろなパターンをいかにアプリケーション側に意識させずに実現するか。そのためにライブラリがやらなければいけないことは次のようなものだと考えています。
- テーブル単位でシャードするかどうか・分散先はどこか・アルゴリズムはなにか・シーケンサーを使うかなどが設定できること
- データベースにクエリが飛ぶ前に途中でキャプチャできること
- キャプチャしたクエリをパースして、シャードキーを入手できること
- シーケンサーを使う場合は、クエリ中の値を置き換えできること
- シャーディングアルゴリズムを使って、シャードキーからシャード先を決定できること
これらを実現するために、 Octillery でどのように設計・実装したかについて説明したいと思います。
3.1 テーブル単位でシャーディング情報を設定できること
こちらはシンプルに、みなさん大好きな YAML で設定できるようにしました。例えば以下のように記述します。
default: &default
adapter: mysql
encoding: utf8mb4
username: root
master:
- localhost:3306
tables:
posts:
shard: true
shard_key: user_id
shards:
- post_shard_1:
<<: *default
database: posts_shard_1
- post_shard_2:
<<: *default
database: posts_shard_2
tables キー配下に、 テーブル名 : 設定値 のような形で設定を書いていきます。
-
shard: シャードするかどうか -
shard_key: シャーディングに使うカラム名 -
shards: シャード先の定義を書きます -
shards[].database: シャード先のデータベース名
Octillery はこの YAML をはじめに読み込んで、テーブル名に対応する情報を得ます。
3.2 データベースにクエリが飛ぶ前に途中でキャプチャできること
おそらく Go をふだん書いている方は、この実装をどうしているか気になると思います。
Go にはシンボルテーブルを実行中に操作する方法などはないため、すべてのORMで利用できるようにするにはライブラリ側のソースコードを書き換える以外に方法がありません。ですが、書き換えようにもライブラリ毎に異なる実装を変更するにはどうすればいいでしょうか。
わたしがとったのは import 文を書き換えるアプローチです。
Octillery に CLI ツールを用意して、 octillery transpose . とすると、指定したディレクトリ配下の .go ファイルを AST にして import 文を解析し、 database/sql を見つけたらそれを go.knocknote.io/octillery/database/sql に置き換えて上書きします。
go.knocknote.io/octillery/database/sql 配下には database/sql とコンパチのインターフェースを用意しておき、 Octillery 側の実装に切り替わるようにしました。
3.3 キャプチャしたクエリをパースして、シャードキーを入手できること
SQLのパースには knocknote/vitess-sqlparser を利用しています。
これは同じくシャーディング機能をスタンドアローンのプロセスとして提供する vitess から SQL パースの部分だけを抜き出し、それだけだと DDL まわりの解析が弱かったので TiDB から DDL パースの機能を抜き出してきたライブラリです。やったことは両者から必要最小限のソースコードをもらってきて、 DDL 解析の結果を TiDB から vitess で用意しているインターフェースに変換して返すということだけです。
それぞれ信頼できるプロジェクトなので、SQLパースも安心して任せることができています。
本番運用している中でもパーサーまわりで問題になったことはありませんでした。
3.4 シーケンサーを使う場合は、クエリ中の値を置き換えできること
シーケンサーは採番テーブルを利用する方法をとっており、シーケンサーに使うデータベースのDSNを設定すると、ライブラリ側で自動的に採番用のテーブルを構築するようになっています。
クエリ中の値を置き換えるのは 3.3 でパースできているので難しくはありません。
3.5 シャーディングアルゴリズムを使って、シャードキーからシャード先を決定できること
Octillery がデフォルトでサポートしているのは 2.5 で挙げた2種類のアルゴリズムになります。
それぞれ modulo , hashmap と YAML ファイル中の algorithm キーに対して指定していただければ動作するようになっています。
また、アルゴリズムはプラガブルな作りになっており、自作することも可能です。必要なインターフェースを実装したファイルを作成し、 go.knocknote.io/octillery/algorithm ディレクトリに配置すると自動で読み込まれ、利用できるようになります。
データベースアダプタもプラガブルになっており、デフォルトでは mysql , sqlite3 (テスト用) をサポートしています。利用しないプラグインに依存するライブラリ(driverライブラリなど)を入れないようにするため、 これらのプラグインは普段は go.knocknote.io/octillery/connection/adapter/plugin 配下に置いてあり (このディレクトリはコンパイル対象にならない)
octillery install --mysql
のように指定すると、内部では vendor 配下に octillery があればそちらを対象に、なければ $GOPATH 配下を対象に connection/adapter/plugin から plugin に .go ファイルを移動する操作が走ります。
(例えば $GOPATH 配下にあるときの挙動)
cp $GOPATH/src/go.knocknote.io/octillery/connection/adapter/plugin/mysql.go $GOPATH/src/go.knocknote.io/octillery/plugin/mysql.go
が走ります。 go.knocknote.io/octillery/plugin ディレクトリはライブラリのロードパスに入っているため、この配下においたファイルは自動的に読み込まれ利用することができます。
例えば、 postgres.go のようなファイルを作って、 go.knocknote.io/octillery/plugin 配下におけば PostgreSQL の機能を利用することも可能です。
このあたりのプラグインまわりの挙動は、プラグインを自分で配置する操作を行わなくて済むように改善する予定でいます
4. Octillery の使い方
4.1 CLIツールをインストールする
import文置き換えに使う transpose コマンド以外にも便利な機能がたくさんあるCLIをまず入れます。
※ 主な機能
-
transpose:import文置き換え。利用するためには必須 -
migrate: シャード先も含めてデータベースマイグレーションを行うためのコマンド(今のところMySQLのみ) (内部でschemalexを利用しています) -
import: CSVから初期データを投入するためのコマンド(今のところMySQLのみ) -
console: シャードされているかどうかを意識することなく使えるMySQLクライアント (開発中) -
install: データベースアダプタをインストールするためのコマンド -
shard: シャードキーを入力に、どのデータベースに分散されるかを表示するコマンド
go get -u go.knocknote.io/octillery/cmd/octillery
4.2 ライブラリとしてインストールする
go get -u go.knocknote.io/octillery
何かしらパッケージマネージャをお使いの場合は上記のパスを書いてください
4.3 Import文を置き換える
例えば vendor 配下にある ORM の import 文を置き換えたければ
octillery transpose vendor
--dry-run オプションを付けると、置き換え時の差分だけ表示してくれます
4.4 データベースアダプタをインストールする
octillery install --mysql
4.5 データベース・テーブルを準備する
CREATE TABLE `posts` (
`id` bigint unsigned NOT NULL AUTO_INCREMENT,
`user_id` bigint unsigned NOT NULL,
`created_at` datetime NOT NULL,
`updated_at` datetime NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `uq_posts_01` (`user_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
というスキーマを schema.sql として保存して
default: &default
adapter: mysql
encoding: utf8mb4
username: root
master:
- localhost:3306
tables:
posts:
shard: true
shard_key: user_id
shards:
- post_shard_1:
<<: *default
database: posts_shard_1
- post_shard_2:
<<: *default
database: posts_shard_2
という YAML を databases.yml として保存すれば
octillery migrate --config databases.yml schema.sql
でシャード先にテーブルを作ってくれます。
4.6 ライブラリを使う
package main
import (
"go.knocknote.io/octillery"
"go.knocknote.io/octillery/database/sql"
)
func main() {
if err := octillery.LoadConfig("databases.yml"); err != nil {
panic(err)
}
db, _ := sql.Open("mysql", "")
db.QueryRow("...")
}
octillery.LoadConfig() で YAML ファイルを読み込めば準備完了です。
このあと sql.Open して db.QueryRow("select * from posts where user_id = 1") などとすれば、 user_id の値にしたがって posts_shard_1 か posts_shard_2 のどちらかにクエリが飛び、結果を返してくれるようになります。
5. おわりに
今回紹介したデータベースシャーディングライブラリは、今年の春先に公開したスマートフォン向けブラウザゲームで本番利用されております。
クライアント・サーバー・インフラすべてを弊社の限りある人員で開発する必要があり、かつ高負荷が予想されるタイトルだったため、小さい開発コストで最大限のパフォーマンスを出す必要がありました。そんな中で Octillery はとても活躍してくれているので、公開することで一つでも多くのプロジェクトに貢献できることを願っています。
今回紹介したライブラリ以外にも、フルマネージドなキャッシュライブラリや軽量なアプリケーションフレームワークを開発しており、どちらも非常に活躍してくれています。なるべく早く公開したいと思っていますので、ご期待いただければ幸いです。
できるだけ多くの方に使っていただきたいと思っていて、ここが使いにくいとか機能要望なども随時募集しておりますので、コントリビュートをお待ちしております!
(おまけ) 公開を控えているライブラリのロゴをちょっと紹介

