1. はじめに
Rapidash というGo用のキャッシュライブラリを公開しました。
以前 https://qiita.com/goccy/items/a54af6db3b8623e90c38 で紹介した Octillery 同様、弊社の負荷対策用ライブラリになります。
キャッシュというとコンテキストによって用途は様々ですが、 Rapidash はアプリケーションサーバの応答性能を向上させるために、主にデータベースの負荷分散を目的として開発したライブラリになります。
主な機能は以下のようなものです。
- 検索しか行わないテーブルのデータをアプリケーションサーバ起動時にデータベースからすべて吸い上げ、インデックスの定義に従ってメモリ上に
B+Tree構造で展開する。検索時は範囲検索もできる - 読み書きを行うテーブルのレコードを
memcachedやRedisといったキャッシュサーバに格納し、高速に検索したり検索クエリの負荷分散をおこなう ( いわゆるRead-Through/Write-Through) -
memcachedやRedisを利用したキャッシュの get/set 操作 - 2 や 3 を行う際に擬似的なトランザクションを利用できる
- キャッシュサーバが複数ある場合は、キャッシュキーの種類によって格納するサーバーを制御することができる
-
Consistent Hashingによるキャッシュサーバの増減への対応 -
reflectを使わない高速なエンコード・デコード処理 -
msgpackによるキャッシュの自動圧縮 - データベースやキャッシュサーバとやりとりする際に発行するクエリや値の可視化
Rapidash の内部は機能によって大きく3つのコンポーネントに分けられています。
1 で挙げた、検索しか行わないテーブルのレコードをキャッシュするためのコンポーネントを FirstLevelCache
2 で挙げた、読み書きを行うテーブルのレコードをキャッシュするためのコンポーネントを SecondLevelCache
3 で挙げた、単純なキャッシュの get/set をおこなうためのコンポーネントを LastLevelCache と呼んでいます。
Rapidash が提供するAPIを利用する限りにおいて、これらのコンポーネントの存在を意識する必要はありませんが、 以降では、上記で挙げた機能の詳細について説明する際にこれらの名前を利用したいと思います。
公開したライブラリは実はバージョン2で、もともとは reflect 全開のライブラリを作り、本番環境で1年以上運用していました。
それを処理速度や可読性の観点から見直していちから作り直し、今回晴れて公開の運びとなりました。
この時期に公開した理由として、来たる ISUCON9 で利用してもらえるのではという思惑があります。
実際自分が予選に出る際は Rapidash を使ったアプローチで予選突破を考えているので、もし役に立ったら何か書こうと思います。
この記事では、箇条書きで挙げた項目のうちいくつかをより詳細に掘り下げていき、 Rapidash でどんなことができるのかを説明したいと思います。
長いですが、お付き合いいただければ嬉しいです。興味を持っていただけたらぜひ ISUCON などで利用していただければ幸いです。
2. 検索のみのテーブルに対するキャッシュ
Rapidash 内部の FirstLevelCache の説明になります。
中身の話をする前に、まずは検索のみのテーブルに対する一般的なアプローチについて考えたいと思います。
( ※ このあたりの前段の話をスキップしたい方は 2.4 からお読みいただければと思います )
アプリケーションを運用する上で、稼働しているアプリケーションサーバから検索クエリしか飛ばないテーブルというものが存在すると思います。例えばマスターデータと呼ばれるようなデータセットがこれに該当します ( この記事ではマスターデータを 「アプリケーションのエンドユーザーの行動起因で変化しないようなデータセット」 と定義したいと思います )。
仮にマスターデータにバージョン番号が与えられているとして、あるバージョンとアプリケーションサーバのバージョンが 1 : 1 対応していたとします。この仮定のもとでは、マスターデータを更新した場合(例えばスキーマを変更した場合)は対応するアプリケーションのバージョンも上がることになるので、アプリケーションサーバのデプロイが必要になります。デプロイした後は、アプリケーションサーバが同じバージョンで動作している限り、参照しているマスターデータも同じものになります。
こういった仮定が成り立つ際に、マスターデータはどこに格納するべきでしょうか。
もっともシンプルなのは、各アプリケーションサーバが参照するデータの格納先を共通化することなので、例えばデータベースになると思います。おそらくマスターデータは元はエクセルなどで作られ、CSVあたりに変換されているでしょうから、それをデータベースに流し込むという流れになるかと思います。
これでアプリケーションはうまく動きます。...動きますが、同じ答えを得るために毎回クエリをデータベースに飛ばすのは無駄と考えることもできます。そういった場合は、 memcached や Redis などのキャッシュサーバをデータベースの前段におき、まるっとデータをキャッシュしてしまうアプローチが考えられます。こうすることで、検索時ははじめにキャッシュサーバから取り出し、もしキャッシュがない場合のみデータベースにクエリを飛ばすようにするというフローをとることができ、データベースに飛ぶクエリの数を劇的に減らし、応答性能を向上させることができます。この手のキャッシュサーバでマスターデータなどの検索しか行わないデータをキャッシュするアプローチには大きく二通りあると思っており、以下のようなやり方があると考えています。
2.1. アプリケーションサーバ全体で共通のキャッシュサーバを参照する場合
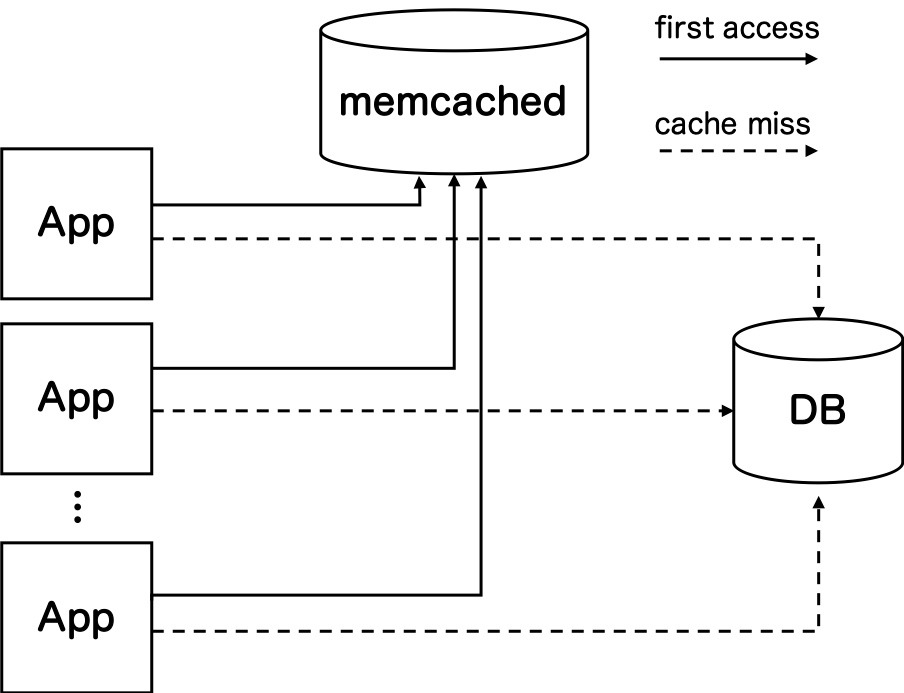
上図のように、複数のアプリケーションサーバから共通の memcached などのキャッシュサーバーにアクセスする場合があると思います。はじめに memcached に対してキャッシュを問い合わせ、なければデータベースにフォールバックする形でアクセスするような流れです。
もしキャッシュの内容を新しくしたい場合は、参照している memcached の内容をクリアしてから新しいキャッシュを格納します。
新しいキャッシュを格納するフローには、データベースから取得したデータを使ってアプリケーションサーバから書き込む場合や、キャッシュ書き込み用のスクリプトなどを用いる方法があるでしょう。
2.2. キャッシュサーバをアプリケーションサーバのサイドカーとして配置する場合

もうひとつ考えられるのは、アプリケーションサーバのサイドカーとしてキャッシュサーバーを配置する方法です。
上図のようにアプリケーションサーバと同じインスタンス上に memcached サーバを立てると、 App <=> memcached 間を unix domain socket 経由でやりとりできるようになるため、 2.1 で挙げた場合よりも高速にキャッシュの取得をおこなうことができるようになります。
しかしキャッシュを更新したい場合は、アプリケーションサーバが参照しているすべての memcached サーバのキャッシュを更新しなければいけません。このとき、すべてのサーバが同じ内容をキャッシュしている状態なので、そのうちどれか一台だけ更新してしまうと、その他との整合性がとれなくなってしまいます。そのため、更新する場合は全台をできる限り同時に更新する必要がありますが、どうしても完全に同時に行うことはできません。更新中にアプリケーションサーバAとBにリクエストがきた際は、AとBで同じマスターデータを参照する保証ができない可能性があるということを認識した上で運用しなければいけないことになります。
2.3 アプリケーションサーバ上に格納する場合
2.1 と 2.2 でキャッシュサーバを用いたマスターデータのキャッシュ方式を挙げましたが、どちらも一長一短という具合で、よりアプリケーションサーバに近いところでキャッシュしたほうが応答性能は高くなりますが、キャッシュ内容が複数箇所に分散するため、更新が大変になることを説明しました。
では、よりアプリケーションサーバに近いところということで、アプリケーションサーバそれ自体にマスターデータをキャッシュしてしまう方法はどうでしょうか。
アプリケーションサーバ上に展開できれば、キャッシュサーバにアクセスするよりも高速にキャッシュにアクセスできます。しかし、更新時はアプリケーションサーバ自体に更新用の口を用意してやる必要があるため、サイドカーとして動作しているキャッシュサーバを更新するよりも大変とも考えられます。
では応答性能と更新時の不整合状態のどちらかを犠牲にしなければならないのかというとそういうわけでもなく、やり方次第では両立させることができます。
例えば弊社ではアプリケーションサーバ上にマスターデータをキャッシュする方式をとっていますが、新旧のキャッシュが混在する時間をなくすことも同時に実現しています。
2.3.1 アプリケーションサーバと参照するマスターデータを 1 : 1 対応させる仕組み
弊社では、マスターデータはオリジナルをエクセルで管理し、そこから生成したCSVをバージョン管理しています。
CSVが格納されたリポジトリを master_data リポジトリとすると、この master_data リポジトリをアプリケーションサーバのコードを管理している server リポジトリから git-submodule でマウントして利用しています。こうすることで、ある revision のサーバコードとマスターデータの revision を 1 : 1 対応させています。

弊社では Octillery を用いてデータベースのシャーディングを行っていますが、このライブラリはアクセス対象のデータベースのDSNをすべて YAML ファイルに書き下す仕様にしています。このため、マスターデータをデータベースに格納する場合はそのDSNを YAML ファイルに記載することになるのですが、ここでデータベース名として master_data リポジトリの revision を付与するようにしています。こうすると、 server リポジトリがマウントしている mater_data リポジトリの revision が変わるたびに異なるデータベースが作られることが前提となります。
アプリケーションサーバは、起動時に Rapidash を利用してマスターデータをすべて吸い上げメモリ上にキャッシュしてから Listen します。
言い換えれば、マスターデータの内容を更新したい場合は、 master_data のリポジトリを更新したあと、 server リポジトリから master_data リポジトリへの参照を更新して YAML ファイルを書き直し ( 実際はこのあたりは自動でおこなっています ) 、アプリケーションサーバを起動し直すことになります。
2.3.2. 新旧のキャッシュが混在しないための仕組み
弊社のデプロイ方法は Blue Greenデプロイを利用しています。このためデプロイ時にはスタンバイ側にアプリケーションサーバがすべて起動していることが前提となります。
ここで新旧のアプリケーションサーバが参照するマスターデータはどうなっているでしょうか。
古いアプリケーションサーバを A 、新しいアプリケーションサーバを B とすると、A、B の前後でマスターデータが更新された場合、次のように別々のマスターデータをキャッシュしている状態になります。
※ マスターデータの revision が a => b に変化したとする
- A がキャッシュしている対象のデータベースは
master_data_a - B がキャッシュしている対象のデータベースは
master_data_b
つまり B は新しいマスターデータをキャッシュした状態で立ち上がっていることになります。この状態でアクティブ・スタンバイをロードバランサーで切り替えることで、ある時点を境に完全にマスターデータの参照先を切り替えることが可能になります。
2.4 FirstLevelCache の使い方
前置きが長くなってしまいましたが、 2.3 で説明したような方法で弊社ではマスターデータをキャッシュしています。
弊社では PWAゲーム を運用しているのですが、ブラウザでゲームを提供する場合はクライアント側でマスターデータを管理するアプローチをとることが難しく ( クライアント側でもつデータベースの容量制限やデータの漏洩等の観点から ) 、サーバから返却するHTTPレスポンスに都度マスターデータへの参照をもたせています。このため、マスターデータを検索する回数も無視できるものではなく、アプリケーションサーバにキャッシュするアプローチをとろうと決めました。
Rapidash の FirstLevelCache はこのために開発されたコンポーネントです。データベースのインデックス構造をそのままアプリケーションサーバ上に展開するようなイメージで実装しました。
キャッシュする際のデータ構造は B+Tree を採用しており、範囲検索も行うことができます。
例えば次のような events テーブルがあったとすると
CREATE TABLE events (
id bigint(20) unsigned NOT NULL,
event_id bigint(20) unsigned NOT NULL,
term enum('early_morning', 'morning', 'daytime', 'evening', 'night', 'midnight') NOT NULL,
start_week int(10) unsigned NOT NULL,
end_week int(10) unsigned NOT NULL,
created_at datetime NOT NULL,
updated_at datetime NOT NULL,
PRIMARY KEY (id),
UNIQUE KEY (event_id, start_week)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
次のように検索することができます ( ※エラー処理は省略 )
package main
import (
"database/sql"
"time"
_ "github.com/go-sql-driver/mysql"
"go.knocknote.io/rapidash"
)
type Event struct {
ID int64
EventID int64
Term string
StartWeek uint8
EndWeek uint8
CreatedAt time.Time
UpdatedAt time.Time
}
// デコードのために用いるメソッド
func (e *Event) DecodeRapidash(dec rapidash.Decoder) error {
e.ID = dec.Int64("id")
e.EventID = dec.Int64("event_id")
e.Term = dec.String("term")
e.StartWeek = dec.Uint8("start_week")
e.EndWeek = dec.Uint8("end_week")
e.CreatedAt = dec.Time("created_at")
e.UpdatedAt = dec.Time("updated_at")
return dec.Error()
}
// スキーマとGoの型との関係を Rapiash に教えるための Struct を作る
func (e *Event) Struct() *rapidash.Struct {
return rapidash.NewStruct("events").
FieldInt64("id").
FieldInt64("event_id").
FieldString("term").
FieldUint8("start_week").
FieldUint8("end_week").
FieldTime("created_at").
FieldTime("updated_at")
}
type Events []*Event
func (e *Events) DecodeRapidash(dec rapidash.Decoder) error {
len := dec.Len()
*e = make([]*Event, len)
for i := 0; i < len; i++ {
var event Event
if err := event.DecodeRapidash(dec.At(i)); err != nil {
return err
}
(*e)[i] = &event
}
return nil
}
func main() {
conn, _ := sql.Open("mysql", "...")
cache, _ := rapidash.New()
// events テーブルの内容を吸い上げる
cache.WarmUp(conn, new(Event).Struct(), true)
tx, _ := cache.Begin()
// SELECT * FROM events
// WHERE `event_id` = 1 AND
// `start_week` <= 3 AND
// `end_week` >= 3 AND
// `term` = daytime
builder := rapidash.NewQueryBuilder("events").
Eq("event_id", int64(1)).
Lte("start_week", uint8(3)).
Gte("end_week", uint8(3)).
Eq("term", "daytime")
var events Events
tx.FindByQueryBuilder(builder, &events)
}
今のところサポートしているクエリは、 Eq , Neq , Gt , Lt , Gte , Lte , In です。
3. 読み書きをおこなうテーブルに対するキャッシュ
データベースから引いた検索結果を memcached や Redis などのキャッシュサーバに格納し、検索時にデータベースより先にキャッシュサーバを見て、値が存在する場合はそれを返すようにすることで、データベースへの読み込み負荷を減らしたり、検索速度を向上させるアプローチがあります。
データベースへの読み書き操作をプロキシしてキャッシュ操作するような構成になるため、よく Read Through/Write Through caching と呼ばれたりします。関連するライブラリとしては https://github.com/hooopo/second_level_cache などがあり、こちらは前職で利用していたこともあって参考にさせていただきました。
Rapidash 内部では SecondLevelCache というコンポーネントで実装されています。
Rapidash を作る上で、このコンポーネントをどう設計するかがとにかく難しく、難産でした。
一世代前はキャッシュまわりの機能とデータベースへのアクセスが疎になるように作ろうとして、キャッシュアクセスの部分だけを実装していましたが、それだと結果的にだいぶ使いづらくなってしまったため、新しいバージョンではデータベースとキャッシュへのアクセスをまとめてやる形のインターフェースを提供する方針にしました。結果として、見方によっては後ろにキャッシュサーバがある前提で動く ORM のように振る舞います。
まずは、 SecondLevelCache がどのようなルールのもとにキャッシュの取得・作成・更新・削除を行っているかを説明したいと思います。
3.1 SecondLevelCache の仕組み
プライマリキーやユニークキーなどインデックスが貼られたカラムに対して CRUD 操作を行った際に、データベース操作と同時にキャッシュの作成や削除を行います。
キャッシュを利用するにはインデックスが効くクエリを EQ (または IN) 条件で検索しなければならないという制約があり、そうでないクエリを用いた場合にはキャッシュを使わずにデータベース操作のみ行うような挙動になります。
以降では、CRUDの各操作について、 Rapidash がどういったルールの基にキャッシュの作成や削除を行っているかということについて説明したいと思います。
説明のために、まず PRIMARY KEY , UNIQUE KEY , KEY が指定されているテーブル( user_logins )を用意します。
( 各カラムには特に意味はありません。インデックスの説明をするために作ったカラムと捉えてください )
CREATE TABLE IF NOT EXISTS user_logins (
id bigint(20) unsigned NOT NULL AUTO_INCREMENT,
user_id bigint(20) unsigned NOT NULL,
user_session_id bigint(20) unsigned NOT NULL,
login_param_id bigint(20) unsigned NOT NULL,
name varchar(255) NOT NULL,
created_at datetime NOT NULL,
updated_at datetime NOT NULL,
PRIMARY KEY (id),
UNIQUE KEY (user_id, user_session_id),
KEY (user_id, login_param_id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
3.1.1 READ (レコードの検索処理)

検索処理では、上図で示したように
- キャッシュサーバに対し、キャッシュがないか問い合わせる
- キャッシュがなかった場合や古かった場合はデータベースへ問い合わせる
- レコードが見つかればその値を、見つからなければネガティブキャッシュをキャッシュサーバーに追加
といったことを行います。クエリには IN 句を使った複数検索を用いることを許可しており、キャッシュサーバーに問い合わせる場合は複数のキーに対して同時に問い合わせることになります。このとき、見つかった値だけを先にデコードし、デコードに失敗したもの(キャッシュが古く型が合わなかったとみなす)やそもそも見つからなかったキーの組み合わせからデータベースに問い合わせるためのSQLを生成し問い合わせます。
検索結果があった場合はそれをデコードし、最後に検索結果をキャッシュサーバーに追加します。
キャッシュサーバーに問い合わせる場合は、ある検索クエリに対して 1回、または2回のキャッシュ取得リクエストを発行します。これはクエリに用いているインデックスの種類により決まり、
-
PRIMARY KEYを用いたクエリの場合は1回 -
UNIQUE KEYまたはKEYを用いたクエリの場合は2回になります。
これらを上で挙げた user_logins テーブルを用いて説明します。
3.1.1.1. PRIMARY KEY を用いた検索の場合
rapidash.NewQueryBuilder("user_logins").Eq("id", uint64(1))
といったクエリを作って検索する場合は、 PRIMARY KEY を利用した検索になるため一回だけ取得リクエストを発行することになります。
これは In を使って複数の値を取得する場合も同じです。
rapidash.NewQueryBuilder("user_logins").In("id", []uint64{1, 2, 3, 4, 5})
上記のクエリビルダーが渡されると、内部では SecondLevelCache がプレフィックスやテーブル名を付与し、
r/slc/user_logins/id#1 のようなキーを作成します。そしてこの id#1 から id#5 までを一回でキャッシュサーバに対して問い合わせます。
PRIMARY KEYを用いたクエリ ( r/slc/user_logins/id#1 ) ==> レコード本体
3.1.1.2 UNIQUE KEY を用いた検索の場合
rapidash.NewQueryBuilder("user_logins").
Eq("user_id", uint64(1)).
Eq("user_session_id", uint64(1))
といったクエリを作って検索する場合は、 UNIQUE KEY を利用した検索になるため2回取得リクエストを発行することになります。
これは In を使って複数の値を取得する場合も同じです。
rapidash.NewQueryBuilder("user_logins").
In("user_id", []uint64{1, 2, 3, 4, 5}).
Eq("user_session_id", uint64(1))
※ In はクエリ作成の過程で一度しか利用できない制限を設けています
上記のクエリビルダーが渡されると、内部では SecondLevelCache がプレフィックスやテーブル名を付与し、
r/slc/user_logins/uq/user_id#1&user_session_id#1 のようなキーを作成します。そしてこの uq/user_id#1&user_session_id#1 から uq/user_id#5&user_session_id#1 までをまず一度にキャッシュサーバーに対して問い合わせます。
uq とついたキーの検索結果は、その結果に対応する PRIMARY KEY を用いた検索キーとなっています。
つまり、 r/slc/user_logins/uq/user_id#1&user_session_id#1 で検索した際、もともとこのキャッシュが { id:1, user_id:1, user_session_id:1 } というレコードから作成されたキャッシュである場合は、検索結果が r/slc/user_logins/id#1 となります。
SecondLevelCache ではレコードの値自体を取得するためのキーを PRIMARY KEY を使ったものに限定しています。このため、 UNIQUE KEY を用いてキャッシュを取得する場合は、まず UNIQUE KEY を用いたクエリから PRIMARY KEY を用いたクエリを取得し、その後本来の値を得る多段リクエスト構成になります。
このため、2度のリクエストが発生することになります。
UNIQUE KEY =(1回目のリクエスト)=> PRIMARY KEY =(2回目のリクエスト)=> レコード本体
3.1.1.3 KEY を用いた検索の場合
rapidash.NewQueryBuilder("user_logins").
Eq("user_id", uint64(1)).
Eq("login_param_id", uint64(1))
といったクエリを作って検索する場合は、 KEY を利用した検索になるため2回取得リクエストを発行することになります。
これは In を使って複数の値を取得する場合も同じです。
rapidash.NewQueryBuilder("user_logins").
In("user_id", []uint64{1, 2, 3, 4, 5}).
Eq("login_param_id", uint64(1))
基本的には 3.1.1.2 で説明した UNIQUE KEY を用いた検索方法と同じ流れですが、 KEY の場合は UNIQUE KEY と違い検索結果が複数ある可能性があるため、 PRIMARY KEY を用いた検索キーが複数取得される可能性があります。
例えば上のクエリの場合、まず検索のために以下の5つのキーが作成されます
r/slc/user_logins/idx/user_id#1&login_param_id#1r/slc/user_logins/idx/user_id#2&login_param_id#1r/slc/user_logins/idx/user_id#3&login_param_id#1r/slc/user_logins/idx/user_id#4&login_param_id#1r/slc/user_logins/idx/user_id#5&login_param_id#1
これらのキーを使ってまずキャッシュサーバーに問い合わせます。
すると、それぞれのキーから複数の値が返ってくる可能性があるため、例えば以下のような検索結果になります。
-
r/slc/user_logins/idx/user_id#1&login_param_id#1r/slc/user_logins/id#1r/slc/user_logins/id#10
-
r/slc/user_logins/idx/user_id#2&login_param_id#1r/slc/user_logins/id#2r/slc/user_logins/id#11
-
r/slc/user_logins/idx/user_id#3&login_param_id#1r/slc/user_logins/id#3
-
r/slc/user_logins/idx/user_id#4&login_param_id#1r/slc/user_logins/id#4
-
r/slc/user_logins/idx/user_id#5&login_param_id#1r/slc/user_logins/id#5
この結果から、検索結果の7つのキーを使ってもう一度キャッシュサーバーに問い合わせて値を得ます。まとめると、KEY を用いたクエリから 複数の PRIMARY KEY を用いたクエリを取得し、その後本来の値を得る多段リクエスト構成になります。
このため、2度のリクエストが発生することになります。
KEY =(1回目のリクエスト)=> 複数の PRIMARY KEY =(2回目のリクエスト)=> 複数のレコード
3.1.2 CREATE (レコードの追加処理)
追加処理では、データベースへの INSERT とキャッシュの削除を行います。
レコードが追加されることによって、追加したレコードが検索対象になる可能性のあるキャッシュを消さなければいけません。そのために、 INSERT 時の値を用いてあらかじめテーブルに設定されているインデックスのすべての組み合わせを作成します。
例えば、
{ id: 1, user_id: 1, user_session_id: 1, login_param_id: 1, name: ... }
といった値のレコードを追加する場合は、あらかじめわかっているインデックスの組み合わせを使って
r/slc/user_logins/id#1r/slc/user_logins/uq/user_id#1&user_session_id#1r/slc/user_logins/idx/user_id#1r/slc/user_logins/idx/user_id#1&login_param_id#1
といったキャッシュキーが生成できます。もしこれらのキーの検索結果として既にネガティブキャッシュなどがつまれていると、追加したレコードを検索してもキャッシュからは「存在しないのが正」という情報が返り、検索結果に現れません。そのためこれらのキーを使ってキャッシュサーバーにキャッシュの削除の問い合わせを行います。
3.1.3 UPDATE (レコードの更新処理)
更新処理では、データベースへの UPDATE とキャッシュの更新・削除を行います。
すでに作られたキャッシュの値を更新・削除するためには、まず更新元となる値を取得しなければなりません。このため、検索処理と同様の方法(まずはキャッシュから、なければデータベースから取得する)で、クエリから更新対象の値を得ます。
その後、更新対象のカラムをなめてインデックスに関わるカラムが更新されていないかをチェックします。もしインデックスに関わるカラムが更新されていない場合、更新後の値を PRIMARY KEY に対応する値としてキャッシュサーバーに格納し、データベースのレコードを更新して終了です。
ですが、インデックスが貼られているカラムを更新する場合はもう少し複雑です。
更新される前の値で作られていたキーは、更新後には存在してはならないため、キャッシュの削除操作が必要になります。
具体的には、 UNIQUE KEY にかかわるカラムを更新した場合は、古い値で作っていた uq キーを削除する必要があり、 KEY にかかわるカラムを更新した場合は、古い値で作っていた idx キーの削除と、新しい値で作った idx キーの削除も行わねばなりません。新しい値で作ったほうも消す理由は、既に更新後の値のほうでキャッシュが作られている場合があり、そこには今更新した値が含まれていないため、検索に含まれなくなってしまうからです。
具体例を用いて説明すると以下のようになります。
例えば、キャッシュサーバーに以下のデータがあるとします。
-
r/slc/user_logins/id#1VALUE
-
r/slc/user_logins/uq/user_id#1&user_session_id#1r/slc/user_logins/id#1
-
r/slc/user_logins/uq/user_id#1&user_session_id#2Negative Cache
-
r/slc/user_logins/idx/user_id#1&login_param_id#1r/slc/user_logins/id#1r/slc/user_logins/id#10
-
r/slc/user_logins/idx/user_id#1&login_param_id#2r/slc/user_logins/id#11
このとき、 { id: 1, user_id: 1, user_session_id: 1, login_param_id: 1 } から
{ id: 1, user_id: 1, user_session_id: 2, login_param_id: 2 } に変更することを考えます。
user_session_id が 1 から 2 へ、 login_param_id が 1 から 2 へ変更されるため、UNIQUE KEY と KEY にかかわるカラムが変更されることになります。
このとき Rapidash は上記のキーに対して以下のような操作を行います。
-
r/slc/user_logins/id#1-
VALUE=> (更新後の値で書き込み)
-
-
r/slc/user_logins/uq/user_id#1&user_session_id#1=> (古いキーの削除)r/slc/user_logins/id#1
-
r/slc/user_logins/uq/user_id#1&user_session_id#2-
Negative Cache=> (r/slc/user_logins/id#1を書き込み )
-
-
r/slc/user_logins/idx/user_id#1&login_param_id#1=> (古いキーの削除)r/slc/user_logins/id#1r/slc/user_logins/id#10
-
r/slc/user_logins/idx/user_id#1&login_param_id#2=> (新しいキーの削除)r/slc/user_logins/id#11
上記の変更の結果、最終的な結果は以下のようになります。
-
r/slc/user_logins/id#1UPDATED VALUE
-
r/slc/user_logins/user_id#1&user_session_id#2r/slc/user_logins/id#1
3.1.4 DELETE (レコードの削除処理)
削除処理では、レコードの削除とキャッシュの削除を行います。キャッシュの削除に関しては、 PRIMARY KEY に対するキャッシュだけ消せばよいため、検索クエリに PRIMARY KEY が指定されている場合とそうでない場合で処理が異なります。
3.1.4.1 PRIMARY KEY が設定されている場合
rapidash.NewQueryBuilder("user_logins").In("id", []uint64{1, 2, 3, 4, 5})
上記のようなクエリを用いて削除する場合は、そのまま r/slc/user_logins/id#1 から r/slc/user_logins/id#5 までを削除するだけになります。
3.1.4.2 PRIMARY KEY が設定されていない場合
rapidash.NewQueryBuilder("user_logins").
In("user_id", []uint64{1, 2, 3, 4, 5}).
Eq("user_session_id", uint64(1))
上記のようなクエリを使って削除する場合は、クエリに PRIMARY KEY が含まれていないため、まずその値を得ることから始めます。このときは SecondLevelCache は、上記のクエリから SELECT クエリを生成し、データベースへ問い合わせます。その結果得られた PRIMARY KEY の値を用いて削除操作を行います。
このため、キャッシュを考慮しなければ DELETE クエリだけデータベースに発行すればよかったところ、SELECT が余分に発行されてしまいパフォーマンスが落ちてしまう可能性があります。
3.2 SecondLevelCache の使いどころ
SecondLevelCache は良くも悪くもデータベースへの操作とキャッシュへの操作が密結合になり、両者は切っても切れない関係になります。キャッシュを扱うためには EQ や IN を用いたインデックスの効くクエリに限られるため、これらを利用しないクエリが頻繁に発行される場合は、キャッシュに対する余分な操作が走るぶんかえって遅くなってしまうことも考えられます。
このため、 SecondLevelCache の利用に適した状況は以下のようなものです。
読み書きをおこなうテーブルでかつ読み込み負荷を軽減したり高速に応答したい状況で
- インデックスを使った単純なクエリしか発行されない
-
DELETEを発行する際はほとんどがPRIMARY KEYを用いたクエリ -
SELECTを発行する場合は、範囲検索ではなくほとんどがEQやINでおこなう検索
※ SecondLevelCache はテーブル単位で利用できるものなので、アプリケーション全体で適応することが難しい場合は、特定のテーブルに限ってキャッシュを利用することもできます
3.3 SecondLevelCache の使い方
基本的な使い方は 2.4 で挙げた FirstLevelCache の場合と同様ですが、
SecondLevelCache はキャッシュサーバを使うことが前提となるため、 memcached や Redis を立ち上げる必要があります。
( ※ ここでは memcached を例に説明します )
CREATE TABLE IF NOT EXISTS user_logins (
id bigint(20) unsigned NOT NULL AUTO_INCREMENT,
user_id bigint(20) unsigned NOT NULL,
user_session_id bigint(20) unsigned NOT NULL,
login_param_id bigint(20) unsigned NOT NULL,
name varchar(255) NOT NULL,
created_at datetime NOT NULL,
updated_at datetime NOT NULL,
PRIMARY KEY (id),
UNIQUE KEY (user_id, user_session_id),
KEY (user_id, login_param_id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
上記のようなスキーマのテーブルがあることを前提として、検索するには以下のように記述します。
package main
import (
"database/sql"
"time"
_ "github.com/go-sql-driver/mysql"
"go.knocknote.io/rapidash"
)
type UserLogin struct {
ID int64
UserID int64
UserSessionID int64
LoginParamID int64
Name string
CreatedAt time.Time
UpdatedAt time.Time
}
// エンコードに必要な処理を記述する
func (u *UserLogin) EncodeRapidash(enc rapidash.Encoder) error {
if u.ID != 0 {
enc.Int64("id", u.ID)
}
enc.Int64("user_id", u.UserID)
enc.Int64("user_session_id", u.UserSessionID)
enc.Int64("login_param_id", u.LoginParamID)
enc.String("name", u.Name)
enc.Time("created_at", u.CreatedAt)
enc.Time("updated_at", u.UpdatedAt)
return enc.Error()
}
// デコードに必要な処理を記述する
func (u *UserLogin) DecodeRapidash(dec rapidash.Decoder) error {
u.ID = dec.Int64("id")
u.UserID = dec.Int64("user_id")
u.UserSessionID = dec.Int64("user_session_id")
u.LoginParamID = dec.Int64("login_param_id")
u.Name = dec.String("name")
u.CreatedAt = dec.Time("created_at")
u.UpdatedAt = dec.Time("updated_at")
return dec.Error()
}
// スキーマとGoの型との関係を Rapiash に教えるための Struct を作る
func (u *UserLogin) Struct() *rapidash.Struct {
return rapidash.NewStruct("user_logins").
FieldInt64("id").
FieldInt64("user_id").
FieldInt64("user_session_id").
FieldInt64("login_param_id").
FieldString("name").
FieldTime("created_at").
FieldTime("updated_at")
}
type UserLogins []*UserLogin
func (u *UserLogins) EncodeRapidash(enc rapidash.Encoder) error {
for _, v := range *u {
if err := v.EncodeRapidash(enc.New()); err != nil {
return err
}
}
return nil
}
func (u *UserLogins) DecodeRapidash(dec rapidash.Decoder) error {
len := dec.Len()
*u = make([]*UserLogin, len)
for i := 0; i < len; i++ {
var v UserLogin
if err := v.DecodeRapidash(dec.At(i)); err != nil {
return err
}
(*u)[i] = &v
}
return nil
}
func main() {
conn, _ := sql.Open("mysql", "...")
// memcached へのアドレスを指定して Rapidash インスタンスを作る
cache, _ := rapidash.New(rapidash.ServerAddrs("localhost:11211"))
// user_logins テーブルのスキーマを読み取ってインデックス構造を知る
cache.WarmUp(conn, new(UserLogin).Struct(), false)
// データベース用のトランザクションインスタンスを作る
txConn, _ := conn.Begin()
// データベース用トランザクションインスタンスを利用して、Rapidash のトランザクションインスタンスを作る
tx, _ := cache.Begin(txConn)
// SELECT * FROM user_logins
// WHERE `user_id` = 1 AND `user_session_id` = 1
builder := rapidash.NewQueryBuilder("user_logins").
Eq("user_id", int64(1)).
Eq("user_session_id", int64(1))
var userLogins UserLogins
tx.FindByQueryBuilder(builder, &userLogins)
// データベースへのトランザクションのコミットとキャッシュのコミットを同時に行う
// キャッシュサーバへ値を反映するのはこのタイミング
tx.Commit()
}
cache.Begin を使って *rapidash.Tx インスタンスを作り、そのインスタンスを通して CRUD 操作を行っていきます。
この際、 cache.Begin 時に *(database/sql).DB か *(database/sql).Tx を指定するようになっており、
内部ではキャッシュ操作と同時にデータベースへの読み書きも行います。
キャッシュとデータベースの値の状態が同期されることを保証するために、
キャッシュサーバへの値の反映は tx.Commit() が呼ばれた際にまとめておこなうようにしています。
※ トランザクションまわりの挙動については、 5章で詳しく解説します
4. 汎用キャッシュ
2 や 3 で挙げた機能は、データベースのレコードをメモリ上やキャッシュサーバー上にキャッシュし、いかに応答性能を高めるか(または負荷を分散させるか)ということにフォーカスしたものでした。
ただ、 memcached や Redis に値を出し入れするための汎用的なキャッシュライブラリも必要になるケースがあると思います。そうした要求に応えられるよう、 Rapidash にもキャッシュの保存・取得を扱う機能があります。
上記は LastLevelCache というコンポーネントで実装されており、以下の機能を持っています。
- キャッシュサーバーに対するCRUD操作
- キーに対してタグ付けをし、タグの種類によってキャッシュ対象のサーバーを制御する
- 疑似トランザクションによる書き込み遅延処理やキーに対するロック処理
-
reflectを使わずにキャッシュする値のエンコード・デコードを行う -
msgpackを用いた値の自動圧縮
使い方は以下のように行います。 ( ※ エラー処理は省略 )
cache, _ := rapidash.New(rapidash.ServerAddrs("localhost:11211"))
tx, _ := cache.Begin()
tx.Create("key1", rapidash.String("hello")) // この段階ではまだキャッシュサーバに値は反映されない
tx.Commit() // この時点でキャッシュサーバに反映される
通常のキャッシュサーバへの get / set を行いたいだけなら、直接対象キャッシュサーバのクライアントライブラリを利用する方法もあると思います。 そんな中、 Rapidash を通してキャッシュ操作することのメリットは、トランザクションと共にキャッシュを扱えることだと考えています。
たとえば、アプリケーションサーバのAPIの作り方として、処理の頭でトランザクションを作成し、処理中にエラーが発生したらすべてロールバック、最後まで通ればまとめてコミットする方法があると思いますが、こうしたやり方には Rapidash を通してキャッシュの取得・作成・削除をする旨味があると考えています。
5. 疑似トランザクションを用いたキャッシュ管理
SecondLevelCache , LastLevelCache を利用してキャッシュの取得・追加・更新・削除を行う場合は、
*rapidash.Tx というインスタンスを用いて行います(以下 Tx と呼びます)。
Tx は キャッシュに対するトランザクション機能を利用するためのものです。
いわゆる ACID 特性を完全に満たしているわけではないので、「疑似」トランザクションという表現を用います。
以下では、Rapidash が提供する機能を ACID になぞって説明します。
5.1 原子性
「原子性を満たす」というためには、トランザクションが完全に実行されるか・全く実行されないかのどちらかを保証しなければなりません。
Tx を通してキャッシュの追加・更新・削除操作をした場合は、Tx 上に保存されている値の操作になり、 (*rapidash.Tx).Commit() を実行したときにはじめてキャッシュサーバに変更が反映されます。
// rapidash.Tx インスタンスを作る
tx, _ := cache.Begin()
defer func() {
// Commit されていなければ Rollback する
tx.RollbackUnlessCommitted()
}()
// key1 で hello を追加
tx.Create("key1", rapidash.String("hello"))
// key1 を削除
tx.Delete("key1")
// キャッシュサーバ上の key1 を削除
tx.Commit()
例えば上記のコードでは、tx.Create() / tx.Delete() を実行した時点では、key1 に対する値の追加や削除を、実行しているアプリケーションのメモリ上の値に対してのみ行い、tx.Commit() を実行した時点ではじめて 削除操作のみ がキャッシュサーバに反映されます。( 同じ key に対する操作は最後に行った操作のみが反映されます )
仮に tx.Delete() の途中でエラーが発生しトランザクションが終了した場合は、tx.Commit() が実行されていないのでキャッシュサーバには何も反映されません。
このように、キャッシュサーバへの反映を tx.Commit() のタイミングで行うように遅延させることで、
キャッシュサーバに対する複数の操作を同じタイミングで行うことができるようになります。
次に、 tx.Commit() の中でエラーが発生するケースについて考えます。
...
tx.Create("key1", rapidash.String("hello"))
tx.Create("key2", rapidash.String("world"))
tx.Commit()
上記の例では、同じトランザクションの中で key1 と key2 に対する書き込み操作が行われています。
tx.Commit() の中でそれぞれの書き込みを行う際、 key1 だけ書き込みに成功し、 key2 の書き込みが失敗してしまった場合はどうすれば良いでしょうか。
原子性を満たすためには、 (1) key1 への操作をなかったことにするか (2) key2 への書き込みができるまでトランザクションを終了しないような仕組みが必要です。
Rapidash では、失敗した key2 への書き込みを何度がリトライすることで原子性を担保しようと試みますが、リトライする数にも上限があるため、絶対に成功するとは限りません。その場合は tx.Commit() からエラーが返り、 key1 のみ書き込まれた状態が生まれます。
他にも、key2 へ書き込もうとしたその瞬間にハードウェア障害やその他の原因でアプリケーションがクラッシュすることもあるかもしれません。この場合も key1 のみ書き込まれた状態が生まれてしまうため、原子性を担保しているとは言えません。
Rapidash では、こういったケースに対してあらかじめアプリケーション側で準備をしておくことで、 key2 に対してあとから変更操作を再実行できる仕組みを提供しています。
tx.Create("key1", rapidash.String("hello"))
tx.Create("key2", rapidash.String("world"))
tx.BeforeCommitCallback(func(tx *rapidash.Tx, queries []*rapidash.QueryLog) error {
// 変更対象のkeyとその操作の詳細が Commit が呼ばれる直前に渡される
return nil
})
tx.AfterCommitCallback(func(tx *rapidash.Tx) error {
// Commit が成功した場合に呼ばれる
return nil
}, func(tx *rapidash.Tx, failureQueries []*rapidash.QueryLog) error {
// Commit に失敗した場合に呼ばれる。
// failureQueries には失敗したクエリが入る
return nil
})
tx.Commit()
上記のように BeforeCommitCallback と AfterCommitCallback を設定しておくと Commit の前後をフックすることができ、 BeforeCommitCallback で得られた queries を WAL(Write Ahead Log) として書き出しておくことで、 Commit 中にアプリケーションがクラッシュしたとしても、もう一度 WAL からクエリを復元して発行することができるようになります。
仮にアプリケーションの処理が利用しているユーザー単位で閉じていることが保証されているならば、 BeforeCommitCallback の中でそのユーザーに対するロックを取得し、ロックがない状態でしか処理ができない仕組みを作ることで、不整合状態のキャッシュデータを参照してしまう二次被害を防ぐことができます。そしてアンロックする場合は、 WAL から rapidash.QueryLog を復元し、 (*Rapidash).Recover(queries) を実行することで未反映だった変更を適用することができ、無事不整合状態から復帰することが可能です。
上記のような処理は、分散トランザクションマネージャをアプリケーション側で実装するような場合にとる一例だと考えています。
Rapidash に関していえば、 LastLevelCache を使った汎用キャッシュを扱う上ではほとんど気にすることはないかもしれませんが、 SecondLevelCache を利用する場合はデータベースレコードのキャッシュを行うという性質上、利用しているデータベース上の値とキャッシュの値がずれては困るため、上記のような仕組みを利用すると安全に運用できます。
Commit 時にエラーが発生しにくくなる工夫
Commit 時にエラーとなり困ることのほとんどは、一部のみキャッシュの反映に成功してしまうという状況だと思います。
すべて反映に失敗してしまうケースにおいては、データベースにさえ反映していなければ単純にエラーとして扱うこともできると思います。
一部のキャッシュのみ反映できてしまう状況にはいろいろな要因があると思いますが、反映操作をキャッシュサーバに対する単一のコネクション上で行うことで軽減することができます。こうすることで、キャッシュサーバに接続できないことによるエラーやキャッシュサーバが複数ある状況を考慮せずにすみます。
ただ、だからといってすべてのキャッシュを同じサーバーに書いてしまってはスケールしないので、 Rapidash では分散ルールを定義する方法を提供しています。
これによって例えば、「あるユーザーに対するキャッシュ操作はすべて同じキャッシュサーバに対して行うようにする」といったことが可能になります。
具体的には SecondLevelCache で SecondLevelCacheTableShardKey(table string, shardKey string) というオプションを設定でき、SecondLevelCacheTableShardKey("user_logins", "user_id") のような形で設定すると、 user_logins テーブルへのキャッシュ操作の場合は、クエリに user_id が含まれることが前提となり、その user_id の値によって格納先のキャシュサーバが固定されるような挙動になります。(もちろん対象のキャッシュサーバを外せば、Consistent Hashing により新しいキャッシュサーバが割り当てられます)
5.2 一貫性
キャッシュという性質上、一貫性を保証すべきはキャッシュするデータを作ったオリジンのほうであり、もしそれがデータベースであればそちらで担保すべき話であるため、 Rapidash では特別考慮していません。言い換えれば Rapidash では対応できないことでもあります。
5.3 独立性
「独立性」とは他のトランザクションの結果を受けてはならないというものです。
Rapidash では、キャッシュキーに対する排他制御を行うために、 キーに対して楽観・悲観ロックができるオプションを用意しています。
5.3.1 キャッシュキーに対して楽観的ロックをおこなう
Rapidash インスタンスを初期化する際に
rapidash.SecondLevelCacheOptimisticLock(true)
rapidash.LastLevelCacheOptimisticLock(true)
を渡すことで有効になり、このとき同じキャッシュキーに対して複数のトランザクションから読み取り操作が行われ、
そのうちの1つが対象のキャッシュキーに対する書き込み操作に成功した場合、他のトランザクションで同じキャッシュキーに対して書き込み操作を行うことができないようになります。
txA, _ := cache.Begin()
txB, _ := cache.Begin()
var a string
txA.Find("key1", rapidash.StringPtr(&a)) // a => 'a'
var b string
txB.Find("key1", rapidash.StringPtr(&b)) // b => 'a'
txB.Update("key1", rapidash.String("b")) // key1 を b という値で更新
txB.Commit() // 更新を反映
txA.Update("key1", rapidash.String("c")) // 失敗
txA.Commit()
上記のように txB ですでに key1 に対して書き込み操作を終えていた場合、同じ key1 に対して txA で更新しようとしても失敗するというものです。これにより、同じ値を取得した複数のトランザクションがあった場合、その値を変更できるのが唯ひとつのトランザクションだけになります。
この実装には内部的に CAS ( Compare And Swap ) を利用しています。
5.3.2 キャッシュキーに対して悲観的ロックをおこなう
Rapidash インスタンスを初期化する際に
rapidash.SecondLevelCachePessimisticLock(true)
rapidash.LastLevelCachePessimisticLock(true)
を渡すことで有効になり、このとき同じキャッシュキーに対して変更を行うトランザクションが複数あった場合は、一番最初に変更を試みたトランザクションだけが成功するようになります。 ( コミットしているかは関係ありません )
txA, _ := cache.Begin()
txB, _ := cache.Begin()
txC, _ := cache.Begin()
txA.Create("key1", rapidash.String("a")) // ロックの取得に成功
txB.Create("key1", rapidash.String("b")) // ロックの取得に失敗
txA.Commit() // アンロック
txC.Create("key1", rapidash.String("c")) // ロックの取得に成功
上記のような例では txA の書き込み操作と同時に key1 へのロックをとるため、txB の書き込み操作は失敗します。
逆に、txA と txC の関係のように、 txA が Commit した後であれば txC の書き込み操作は行うことができます。
この実装は、該当のキャッシュキーに 1 : 1 対応するロック用のキーを生成し、そのキーをキャッシュサーバ ( memcached )に ADD コマンドで書き込むことで実現しています。ADD 操作はキャッシュサーバ上でアトミックな操作であり、かつすでにキーがある場合はエラーになることを利用しています。
※ 例えば HTTPサーバーでリクエストを受ける際に、あるユーザーからのリクエストをシーケンシャルにおこなうことを保証したい場合などに、ユーザーごとのセッション情報を LastLevelCache を使って管理することで実現することができます。
5.3.3 トランザクション分離レベル
Rapidash では、 Tx インスタンスを使うことで、読み書きを行ったキャッシュの情報を Tx インスタンスに閉じるようにしています。そのため、コミット前の値が他の Tx インスタンスから読まれることはありませんし、Tx 上にある一度引いた値が別のトランザクションの影響で書き換わることもないため、読み込み一貫性を満たしていると言えます。
ですので、自然にトランザクション分離レベルでいう SERIALIZABLE 相当の挙動になります。
※ ただし、 SecondLevelCache において参照しているデータベースのトランザクション分離レベルが REPEATABLE READ 以下であった場合、キャッシュが存在しない・または削除したあとに検索処理を行うとデータベースへの読み込みが発生するため、データベース側のトランザクション分離レベルに沿った挙動となります (分離レベルによっては Fuzzy Reads や Phantom Reads が発生する可能性があります)。
5.4 耐久性
「障害が発生してもトランザクションの結果は永続化しなければならない」という性質ですが、
キャッシュなのでキャッシュサーバが落ちれば消えてしまいます。なのでこの性質を満たせているとは言えませんが、キャッシュライブラリに対しての要件ではないと割り切っています。
6. まとめ
ここまで一通り読んでくださった方、ありがとうございます。
キャッシュライブラリが提供してくれると個人的に嬉しい機能を詰め込んだライブラリのため、ボリュームが大きくなってしまったことは否めませんが、実際に ISUCON8 の予選問題に対して適応してみた結果スコアの向上が見られたので、お試しいただければ嬉しいです。( このソースコードはのちほど公開します )
SecondLevelCache はメリットを受けられる条件が限られるため、なかなか利用するまでは難しいとは思いますが、 FirstLevelCache や LastLevelCache は比較的楽に導入できると考えています。
ここまでの文章量になっても、まだまだライブラリの機能や実装の工夫点などを説明しきれているわけではないので、機会があれば実例を交えながらまた何か書きたいと思います ( デコード処理の高速化方法とか memcached クライアントライブラリにちょっとしたパッチを当てて高速化したりといったような話など )。取り急ぎは https://godoc.org/go.knocknote.io/rapidash#Rapidash や https://godoc.org/go.knocknote.io/rapidash#Tx といったAPIドキュメントやテストコードでやろうとしていることを掴んでいただければ嬉しいです。
また、機能要望やバグ報告についても随時受け付けているので、日本語でも構いませんので https://github.com/knocknote/rapidash/issues に投げていただければ嬉しいです。よろしくお願いします!