はじめに
単回帰分析についてはscikit-learnのlinear_model.LinearRegression()モデルを用いれば簡単に行うことができます。ここではは単回帰分析の原理をおさらいしたうえでLinearRegression()を使わずに地道に単回帰分析を行います。具体的にはCPUの一覧データを用いて「半導体回路の集積密度は1年半~2年で2倍となる」というムーアの法則が経験的に成り立つことを示して行きたいと思います。
単回帰分析の原理
単回帰分析は目的変数(y)を1つの説明変数(x)で予測するもので、それらの間の関係性をy=ax+bという一次式の形で表します。例えば、生徒たちの学習時間(x)と成績(y)のように、サンプルデータとしてxとyの組が複数得られている場合、これらのデータに基づき、例えば、新たな学習時間(x)が分かったとき、対応する成績(y)予測を可能にするのが単回帰分析です。
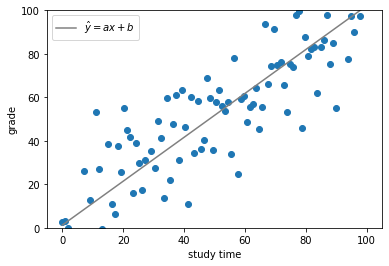
単回帰分析を行うことは、直線y=ax+bを求めることに相当します。では、傾きa及びy切片bはどのように求めるのでしょうか。
ここで最小二乗法の概念が登場してきます。最小二乗法という手法を用いるとa,bを求めることができるのです。
求める回帰直線を以下のように表現すると、
\hat{y}= ax+b
最小二乗法は以下のEを最小にするa, bを求めることに相当します。
E = \sum_{i=1}^{N} (y_i - \hat{y_i})^2 = \sum_{i=1}^{N} (y_i - (ax_i + b))^2 ・・・ (1)
(y_iはサンプルの各データポイントのy座標を、\hat{y_i}は直線\hat{y}= ax+b上の予測値のy座標を意味します。)
(余談ですが、以下のように単にデータポイントと予測値の差の和をとり、それを最小にする手法ではだめなのでしょうか。
\sum_{i=1}^{N} (y_i - \hat{y_i})
少し考えればわかるかもしれませんが、データポイントが予測値の上下に存在する場合、お互いキャンセルアウトしてしまい、見かけより全体の差分が少なく算出されてしまうため、二乗する必要があるのですね。)
さて、本題に戻りましょう。では上記(1)のEを最小にするa,bのペアを求めるためにはどうしたらいいでしょうか。(1)式はa,bを2変数とした2次式とみなすことができます(xi,yiは既知のため定数とみなすことができます)。
すなわち、a,bについて(1)式をそれぞれ偏微分し、それらが=0になるa,bのペアを求めてやればEを最小にするa,bを求めることができるのです。
では早速計算していきましょう。
\frac{\partial E}{\partial a} = \sum_{i=1}^{N} 2(y_i - (ax_i+b))(-x_i)
=2(-\sum_{i=1}^{N} x_iy_i + a\sum_{i=1}^{N}x_i^2+b\sum_{i=1}^{N}x_i)=0
\frac{\partial E}{\partial b} = \sum_{i=1}^{N} 2(y_i - (ax_i+b))(-1)
=2(-\sum_{i=1}^{N} y_i + a\sum_{i=1}^{N}x_i+b\sum_{i=1}^{N}1)=0
すなわち、
a\sum_{i=1}^{N}x_i^2+b\sum_{i=1}^{N}x_i=\sum_{i=1}^{N} x_iy_i ・・・ (2)
a\sum_{i=1}^{N}x_i+bN=\sum_{i=1}^{N} y_i ・・・ (3)
ここで
A =\sum_{i=1}^{N}x_i^2,\quad B =\sum_{i=1}^{N}x_i,\quad C =\sum_{i=1}^{N}x_iy_i,\quad D =\sum_{i=1}^{N}y_i
とおくと(2), (3)は
aA+bB=C ・・・ (2)'
aB+bN=D ・・・ (3)'
とできます。この連立方程式を地道に解いてみましょう(見づらさ解消のため以下ではΣの添字を省略します)。
(2)'\times N - (3)'\times B より\\
a(AN-B^2)=CN-BD\\
\therefore a = \frac{CN-BD}{AN-B^2}=\frac{N\sum x_iy_i-\sum x_i\sum y_i}{N\sum x_i^2-(\sum x_i)^2}\\=\frac{\bar{xy}-\bar{x}\bar{y}}{\bar{x^2}-\bar{x}^2} \quad(分母分子をN^2で割った) ・・・ (4)
同様にして、
(2)'\times B - (3)'\times A より\\
b(B^2-AN)=BC-AD\\
\therefore b = \frac{BC-AD}{B^2-AN}=\frac{\sum x_i\sum x_iy_i-\sum x_i^2\sum y_i}{(\sum x_i)^2-N\sum x_i^2}=\frac{\sum x_i^2\sum y_i-\sum x_i\sum x_iy_i}{N\sum x_i^2-(\sum x_i)^2}\\=\frac{\bar{x^2}\bar{y}-\bar{x}\bar{xy}}{\bar{x^2}-\bar{x}^2} \quad(分母分子をN^2で割った) ・・・ (5)
これで、Eを最小にするa,bのペアが求まったことになります。サンプルデータのデータポイントのx座標やy座標を(4),(5)の式に代入してあげれば簡単にa,bを求めることができるのですね。
求める回帰直線は最終的に(4), (5)から
\hat{y}=ax+b=\frac{\bar{xy}-\bar{x}\bar{y}}{\bar{x^2}-\bar{x}^2}x+\frac{\bar{x^2}\bar{y}-\bar{x}\bar{xy}}{\bar{x^2}-\bar{x}^2} ・・・ (6)
と表すことができます。
ムーアの法則
ここまで長々と単回帰分析の原理を見てきました。
さてここで単回帰分析を用いて「半導体回路の集積密度は1年半~2年で2倍となる」というムーアの法則が経験的に成り立っているのかを見ていきたいと思います。まずはこちらを参考にCPUのプロセッサー数の歴史的変遷を示した一覧表のCSVをスクレイピングにより取得してみましょう。
下準備
データが取得できたら、早速コーディングしていきましょう。まずは取得したデータを見てみましょう。
import re
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
df = pd.read_csv('processor.csv', sep='\t')
df
こんな感じのデータが出力されます。
続いて、CPUのリリース年とトランジスタ数のみ抽出し新たにdf1として出力してみましょう。
df1 = pd.concat([df['Date ofintroduction'], df['MOS transistor count'] ], axis=1)
df1
以下のようになります。
transistor countのデータのうち、「?」となっているものは利用できませんので排除してしまいましょう。
df2 = df1[df1['MOS transistor count'] != '?']
df2.head(10)
下のようにきれいになりました。

データをみると、リリース年やトランジスタ数のあとに注釈の[]が残っていてしまっていますね。また、トランジスタ数の3桁区切りのカンマが邪魔なのでこれらを以下の操作により除去していきましょう。
# 数字以外のもの(3桁区切りカンマ)除去のために指定
decimal = re.compile(r'[^\d]')
# リリース年について注釈の「[」の左側部分のみ抽出し、「year」カラムとしてあらたにdf2に追加
df2['year'] = df2['Date ofintroduction'].apply(lambda x: int(x.split('[')[0]))
# トランジスタ数について最初にマッチする数字部分(カンマ含む)を抽出しその後カンマ除去、「transistor count」カラムとしてあらたにdf2に追加
df2['transistor count'] = df2['MOS transistor count'].apply(lambda x: int(decimal.sub('', re.match(r'[\d, \,]+', x).group() )))
# 出力
df2
結果は以下のようになり、あらたに「year」、「transistor count」カラムが追加されきれいなデータが入っているのがわかると思います。
プロット
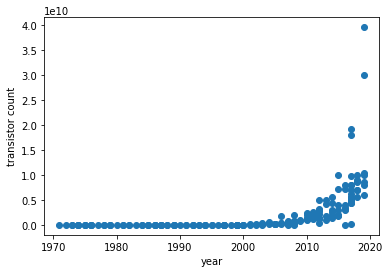
きれいにしたデータをもとに横軸「year」、縦軸「トランジスタ数」の散布図を描いてみましょう。
# サンプルデータの散布図
X = df2['year']
Y = df2['transistor count']
plt.scatter(X, Y)
plt.xlabel('year')
plt.ylabel('transistor count')
plt.show()
トランジスタ数が指数関数的に増加しているのが見て取れますね。
さて、ここでトランジスタ数の対数をとりプロットし直してみましょう。
# サンプルデータの対数散布図
Y = np.log(Y)
plt.scatter(X, Y)
plt.xlabel('year')
plt.ylabel('transistor count')
plt.show()
きれいな直線関係が見えてきます。

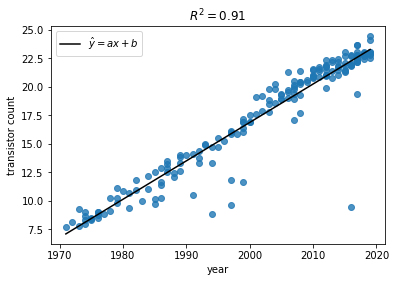
ここでこのプロットに単回帰分析を適用してみましょう。「単回帰分析の原理」で導出した(6)式をコードに落とし込んでみましょう。
# サンプルデータの対数散布図
Y = np.log(Y)
plt.scatter(X, Y ,alpha=.8)
# 回帰直線の導出
denom = (X**2).mean() - (X.mean())**2 # a, bの分母
a = ( (X*Y).mean() - X.mean()*Y.mean() ) / denom
b = ( Y.mean()*(X**2).mean() - X.mean()*(X*Y).mean() ) / denom
# 回帰直線の式
pred_Y = a*X + b
# R-squaredの計算
SSE_l = (Y - pred_Y).dot( (Y - pred_Y) )
SSE_m = (Y - Y.mean()).dot( (Y - pred_Y.mean()) )
r2 = 1 - SSE_l / SSE_m
plt.plot(X, pred_Y, 'k', label='$\hat{y}=ax+b$')
plt.title('$R^2 = %s$'%round(r2,2))
plt.ylabel('transistor count')
plt.xlabel('year')
plt.legend()
plt.show()
結果は以下のようになりました。(R-squared=0.91)
(ここでR-squaredについての補足説明をしますと、R-squaredは決定係数とも呼ばれ、回帰直線の予測モデルとしての妥当性を示す指標です。数式で表すと以下のように表すことができます(SqEはsquared errorの略です)。
R^2 = 1 - \frac{\sum SqE_{line}}{\sum SqE_{mean}}= 1 - \frac{\sum (y_i - \hat{y_i})^2}{\sum (y_i - \bar{y})^2}
この式ではmean、つまりサンプルデータの平均ラインを基準としたときのデータポイントのばらつきと、回帰直線を基準としたときのデータポイントのばらつきを比較がなされます。例えば、ΣSqElineの値がΣSqEmeanの値と等しくなる時、R2は0となり、回帰直線はデータポイントの平均値直線に一致し、予測モデルとして全くといっていいほど機能していないことを表します(回帰直線にはデータの代表値である平均直線以上としての機能が求められるべきです)。一方、ΣSqElineが0のとき、回帰直線上には全てのデータポイントが乗っており、予測モデルはデータポイントを完全に予測できていることになります。この時のR2は1となります。)
ムーアの法則の検証
さて、得られた回帰直線をもとにムーアの法則をざっくりと検証してみましょう。
今まで見てきたように、トランジスタ数(tc)と回帰直線の関係は以下のように表すことができます。
log(tc) = ax + b \\
\therefore tc = \exp(ax + b)
よってある年(x2)にある年(x1)のトランジスタ数の2倍のトランジスタ数に到達するとすると、
2 = \frac{\exp(ax_2 + b)}{\exp(ax_1 + b)} = exp(a(x_2-x_1))\\
\therefore log2 = a(x_2-x_1)\\
\therefore x_2 - x_1 = \frac{log2}{a}
つまり回帰直線の傾きaから計算したlog2/aはトランジスタ数が2倍にになるまでにかかる年数を意味することになります。早速これをもとに年数を計算してみましょう。
print("time to double:", round(np.log(2)/a,1), "years")
time to double: 2.1 years
トランジスタ数が2倍になるまでは約2年という結果になりました。
ムーアさん、すごいですね。