LLMのアシストなしでのプログラミングはちょっと考えられなくなりましたね。
新しいマシンを入手したので、試運転も兼ねてローカルの LLMプログラミング環境を試したいなと思いやってみました。
環境
新しいといってもそれほどのスペックではないのですが、メモリをメインメモリとGPUメモリで共有できるので、エントリーレベルの外部GPUよりは有利?かと思って買いました。
- 機種: GMKtec製NucBox K8 Plus
- CPU: Ryzen 7 8845HS
- GPU: Radeon 780M
- メモリ: 32GB
- OS: Windows 11 Pro
セットアップ
ChatGPT と相談すると、非Nvidia GPUなら、CPUで演算せよとのお言葉。非CUDA環境の勝手もよくわからなかったので、まずはGPUは使わずにやってみます(早くもユニファイドメモリの意味消失😓)。
ほぼお試しなので、Linuxインストールとかデュアルブートにはせず、Windows 上に環境を作ろうということで、WSL2 を使うことにします(Windows ネイティブでもよさそうでした)。
WSL 2 と Ubuntu セットアップ
WSL 2 をインストールします。
wsl --install
次回からは wsl コマンドで起動せよと出ますが、今回はそのまま Ubuntu の起動までやってくれました。
'wsl.exe -d Ubuntu' を使用して起動できます
初期パスワードを設定します。ここから WSL 上の Ubuntu 操作です。
New password:
Retype new password:
passwd: password updated successfully
LLM の実行環境を提供してくれる Ollama を使います。
$ curl -fsSL https://ollama.com/install.sh | sh
>>> Installing ollama to /usr/local
[sudo] password for go:
>>> Downloading Linux amd64 bundle
パッケージをアップデート、先にやっておくべきだったか。
$ sudo apt update && sudo apt upgrade -y
Ollama をもう一回アップデート。古いの消したよ、とのこと。
$ curl -fsSL https://ollama.com/install.sh | sh
>>> Cleaning up old version at /usr/local/lib/ollama
Ollama を試す
Ollama が使えるようになったので、軽めの LLMモデルを持ってきて試します。
$ ollama pull gemma:2b
実行するとそのまま対話できました。
$ ollama run gemma:2b
>>> こんにちは、Ollama!日本語で返答してください
こんにちは!日本語で返答します。何能言しましたか?
APIも叩いてみます。
$ curl -X POST http://localhost:11434/api/generate -d '{
"model": "gemma:2b",
"prompt": "こんにちは、Ollama!日本語で返答してください。"
}'
{"model":"gemma:2b","created_at":"2026-01-03T08:16:25.910604275Z","response":"こんにちは","done":false}
{"model":"gemma:2b","created_at":"2026-01-03T08:16:25.94688802Z","response":"!","done":false}
{"model":"gemma:2b","created_at":"2026-01-03T08:16:25.984042545Z","response":"日本語","done":false}
{"model":"gemma:2b","created_at":"2026-01-03T08:16:26.019883488Z","response":"で","done":false}
{"model":"gemma:2b","created_at":"2026-01-03T08:16:26.055897523Z","response":"返","done":false}
{"model":"gemma:2b","created_at":"2026-01-03T08:16:26.092176896Z","response":"答","done":false}
{"model":"gemma:2b","created_at":"2026-01-03T08:16:26.128245838Z","response":"します","done":false}
{"model":"gemma:2b","created_at":"2026-01-03T08:16:26.164132641Z","response":"。","done":false}
{"model":"gemma:2b","created_at":"2026-01-03T08:16:26.200986782Z","response":"お","done":false}
{"model":"gemma:2b","created_at":"2026-01-03T08:16:26.237714277Z","response":"元気","done":false}
{"model":"gemma:2b","created_at":"2026-01-03T08:16:26.273235903Z","response":"ですか","done":false}
{"model":"gemma:2b","created_at":"2026-01-03T08:16:26.308725868Z","response":"?","done":false}
{"model":"gemma:2b","created_at":"2026-01-03T08:16:26.344008158Z","response":"","done":true,"done_reason":"stop","context":[968,2997,235298,559,235298,15508,235313,1645,108,32789,235394,235302,162470,235482,62938,235398,236572,236661,54934,235362,107,235248,108,235322,2997,235298,559,235298,15508,235313,2516,108,32789,235482,62938,235398,236572,236661,9178,235362,235545,88113,36310,235544],"total_duration":662176741,"load_duration":82645529,"prompt_eval_count":33,"prompt_eval_duration":142104673,"eval_count":13,"eval_duration":429576521}
レスポンスのところちゃんと読んでませんが、まあ動いていそうです。Ollamaすごいですね。あっという間に環境ができていきます。
VSCode
VSCode をインストールします。特にこだわりはないので Microsoft Store からインストールしました。
VSCode 中から LLM を呼び出すための Extention をインストールします。Continue という Extention です。

Continue のデフォルト設定に合わせて、Ubuntu 側でモデルを追加でダウンロードします。コードの生成と自然言語のやり取りなど役割分担するんですね。
name: Local Config
version: 1.0.0
schema: v1
models:
- name: Llama 3.1 8B
provider: ollama
model: llama3.1:8b
roles:
- chat
- edit
- apply
- name: Qwen2.5-Coder 1.5B
provider: ollama
model: qwen2.5-coder:1.5b-base
roles:
- autocomplete
- name: Nomic Embed
provider: ollama
model: nomic-embed-text:latest
roles:
- embed
設定ファイルの指定に合わせてモデルをダウンロード。
$ ollama pull llama3.1:8b
:
$ ollama pull qwen2.5-coder:1.5b-base
:
$ ollama pull nomic-embed-text:latest
:
試してみる!
ここまでの設定だけで先ほどローカルで起動したAPI経由で、コーディングのアシストができてしまいます。ちょっと Ollama 周り完成されすぎ、コワイ。
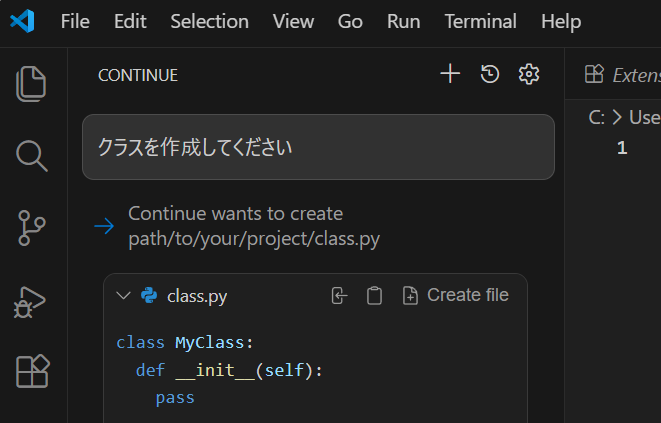
た・だ・し
めっちゃ遅いです。
うーん、どれくらい使えるかちょっと試す気にならないくらい遅いですね。。モデルの指定とか設定で多少早くなるものでしょうか。
今回のマシン、ミニPCなのですが Oculink 装備なので外付け GPU つけられるんですよね。やはり Nvidia 買わないとダメかなあ。何か発見ありましたらまた。