背景
プライベートマッチの結果を集計したいと言われました。
画像認識をやってみようかなと考えていましたが、読む場所が多いことと、画像のアップロードがそれなりに面倒だなと思いました。
楽してリザルトを取得できないかなと思っていたら API を叩いて Json で取得する方法があるそうです。
Splatoon2のAPIを叩いてみる
[Python]イカリング2のJsonを取得してみた
Splatoon2のAPIをPythonで叩いて戦績を取得・保存する
先駆者様に敬意を表しつつ、イカリング2 のAPI key をえいっと手に入れ、取得するスクリプトをやあっとコピペして実行してみると取得できました。
ちゃんちゃん。ではなかった。
課題
/api/resultsからの取得だと自分の情報しか入っていませんでした。
どうやら他の人の情報も取得するにはbattle_numberを指定して取得しないといけないようです。
しかしながら、battle_numberは人によって異なります。これは困った。
やること
-
/api/resultsからbattle_numberを取得、/api/results/[battle_number]の URL を作って Json ファイルとして取得する。 - 取得した Json ファイルの必要な情報を抜き出して CSV ファイルにする。
- 適当にいじって勝率を確認してみる。
環境
- ConoHa VPS@CentOS 7
- Python 3.6.5
お願い
Python も Json も使ったことがないのでしどろもどろになりながらやりました。
もっと効率的な方法があればご教示いただけると幸いです。
API key の取得
fiddle で確認して取得しました。
iPhone の通信はこちらの記事を参考にいたしました。
fiddlerでiPhoneの通信を見るためにやったことメモ
詳細なリザルトを取得する
- 下記記事を参考にして自分の API key を取得する。
- 過去 50 戦のリザルトを Json 形式で保存する。
import urllib
import codecs
from urllib.request import build_opener, HTTPCookieProcessor
from urllib.parse import urlencode
import http
from http.cookiejar import CookieJar
import json
import os
import pandas as pd
# 引数のJSONデータを戦績ごとにファイルに保存
def saveButtleResults(x_jsonData):
# /api/results で取得した results 項目を取得
p_jsonData = x_jsonData['results']
# 改行コードを削除
p_jsonData = json.dumps(p_jsonData, ensure_ascii=False).replace("\\n", "")
# Data Frame に変換
p_df = pd.read_json(p_jsonData)
# battle_number を抜き出す
p_bn = p_df['battle_number']
for p_battle_number in p_df['battle_number']:
# 取得する結果の API を作成
p_api = "https://app.splatoon2.nintendo.net/api/results/" + str(p_battle_number)
# 結果を取得
p_results = getJson(p_api)
# 出力ファイル名
p_outputFilePath = "results/result-buttle-" + str(p_battle_number) + ".json"
# この戦績ファイルが既に存在するか確認、なかったら作成・書き込み
if not(os.path.exists(p_outputFilePath)) :
p_outputFile = codecs.open(p_outputFilePath, "w", encoding="utf-8")
json.dump(p_results, p_outputFile, ensure_ascii=False, indent=4, sort_keys=True)
p_outputFile.close()
def getJson(x_url): # UrlにアクセスしJsonを取得
# 自分のイカリングの API key を入力
p_cookie = "iksm_session[自分のAPI key]"
p_opener = build_opener(HTTPCookieProcessor(CookieJar()))
p_opener.addheaders.append(("Cookie", p_cookie))
p_res = p_opener.open(x_url)
return json.load(p_res)
saveButtleResults(getJson("https://app.splatoon2.nintendo.net/api/results"))
詳細な Json ファイル最新50戦分が取得できました。
(はずかしいので情報は隠してます)
CSV ファイルにまとめる
Json ファイルの扱いがわからないのでなじみのあるデータフレームに変換します。
欲しいデータが散らばっていてどうやって取るのが楽なのかわからなかったので
個別にリストをリストにして、データフレームに変換してappendしていきました。
もっと良いやり方があれば教えてください。
- バトルID(バトルを区別するため)
- プレイヤー名
- モード(レギュラー、ガチ、フェス)
- ルール(ナワバリ、エリア、ヤグラ、ホコ、アサリ)
- チームID(自分がいる方がA)
- ステージ名
- 結果
- 試合時間(レギュラー、フェスは 180 秒固定)
- 塗りポイント
- 使用武器
- キル数
- アシストキル数
- デス数
- スペシャル使用回数
import json
import pandas as pd
import csv
import glob
# ファイルの読み込み先の指定
p_dir = glob.glob("results/*")
# バトルID、名前、モード、ルール、チームID、ステージ、結果、試合時間、塗りポイント、使用武器、キル、アシストキル、デス、スペシャル
p_cols = ['id', 'name', 'mode', 'rule', 'team', 'stage', 'result', 'elapsed_time', 'paint_point', 'weapon', 'kill_count', 'assist_count', 'death_count', 'special_count']
# 空のデータフレームを作成
p_df = pd.DataFrame(index = [], columns = p_cols)
# ファイルがあるだけループ
for p_file in p_dir:
# json ファイルの読み込み
p_json = json.load(open(p_file, 'r'))
# 自チームのデータ
p_myteam = p_json['my_team_members']
# 他チームのデータ
p_otherteam = p_json['other_team_members']
# バトルID
p_id = [p_json['battle_number']] * (1 + len(p_myteam) + len(p_otherteam))
# 自プレイヤー名
p_name = [p_json['player_result']['player']['nickname']]
# 自チームの分のプレイヤー名を取得
for i in range(len(p_myteam)):
p_name.append(p_myteam[i]['player']['nickname'])
# 他チーム分のプレイヤー名を取得
for i in range(len(p_otherteam)):
p_name.append(p_otherteam[i]['player']['nickname'])
# バトルモードの取得
p_mode = [p_json['game_mode']['name']] * (1 + len(p_myteam) + len(p_otherteam))
# ルールの取得
p_rule = [p_json['rule']['name']] * (1 + len(p_myteam) + len(p_otherteam))
# チーム分け(自チームがA)
p_team = ['A'] * (1 + len(p_myteam)) + ['B'] * len(p_otherteam)
# ステージ
p_stage = [p_json['stage']['name']] * (1 + len(p_myteam) + len(p_otherteam))
# 結果
p_result = [p_json['my_team_result']['key']] * (1 + len(p_myteam)) + [p_json['other_team_result']['key']] * len(p_otherteam)
# 経過時間(ガチマッチ以外は 180 秒)
if 'gachi' in p_json['type']:
p_elps = [p_json['elapsed_time']] * (1 + len(p_myteam) + len(p_otherteam))
else:
p_elps = [180] * (1 + len(p_myteam) + len(p_otherteam))
# 塗りポイント
p_point = [p_json['player_result']['game_paint_point']]
for i in range(len(p_myteam)):
p_point.append(p_myteam[i]['game_paint_point'])
for i in range(len(p_otherteam)):
p_point.append(p_otherteam[i]['game_paint_point'])
# 使用武器
p_weapon = [p_json['player_result']['player']['weapon']['name']]
for i in range(len(p_myteam)):
p_weapon.append(p_myteam[i]['player']['weapon']['name'])
for i in range(len(p_otherteam)):
p_weapon.append(p_otherteam[i]['player']['weapon']['name'])
# キル数
p_kill = [p_json['player_result']['kill_count']]
for i in range(len(p_myteam)):
p_kill.append(p_myteam[i]['kill_count'])
for i in range(len(p_otherteam)):
p_kill.append(p_otherteam[i]['kill_count'])
# アシスト数
p_assist = [p_json['player_result']['assist_count']]
for i in range(len(p_myteam)):
p_assist.append(p_myteam[i]['assist_count'])
for i in range(len(p_otherteam)):
p_assist.append(p_otherteam[i]['assist_count'])
# デス数
p_death = [p_json['player_result']['death_count']]
for i in range(len(p_myteam)):
p_death.append(p_myteam[i]['death_count'])
for i in range(len(p_otherteam)):
p_death.append(p_otherteam[i]['death_count'])
# スペシャル数
p_special = [p_json['player_result']['special_count']]
for i in range(len(p_myteam)):
p_special.append(p_myteam[i]['special_count'])
for i in range(len(p_otherteam)):
p_special.append(p_otherteam[i]['special_count'])
# 入力したデータをデータフレームにする
p_df_tmp = pd.DataFrame(
{'id':p_id,
'name':p_name,
'mode':p_mode,
'rule':p_rule,
'team': p_team,
'stage': p_stage,
'result':p_result,
'elapsed_time':p_elps,
'paint_point':p_point,
'weapon':p_weapon,
'kill_count':p_kill,
'assist_count':p_assist,
'death_count':p_death,
'special_count':p_special},
columns=p_cols)
# データフレームに追加
p_df = p_df.append(p_df_tmp, ignore_index = True)
# csv ファイルに出力
p_df.to_csv('test.csv', index = False)
無事にとれました。
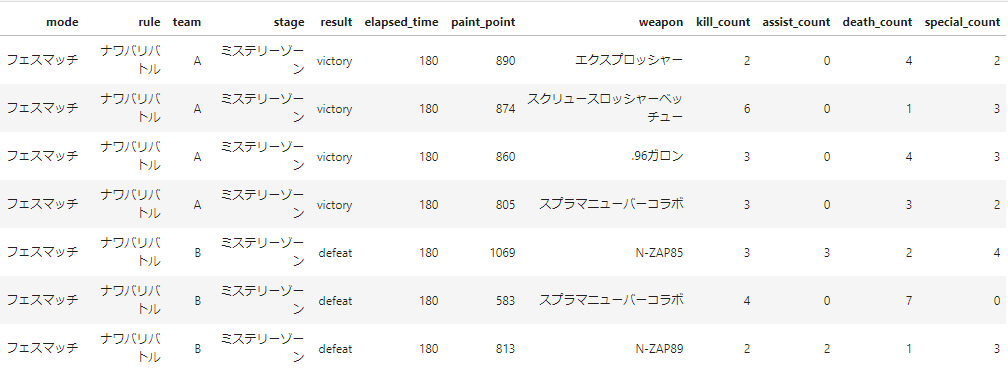
データを見てみる
取得したデータを簡単にまとめてみます。
import pandas as pd
# まとめた CSV ファイルを読み込む
p_df = pd.read_csv('test.csv')
# 自分の結果のみに絞る
p_df_myself = p_df[p_df.myself]
# 試合数と勝利数をカウントする
p_df_myself = p_df_myself.assign(
count = 1,
victory = lambda p_df : p_df["result"].apply( lambda x: 1 if x in 'victory' else 0 )
)
ルールごとに集約
# ルールごとに集約
p_groupby = p_df_myself.groupby('rule')['count', 'victory']
p_groupby = p_groupby.sum()
p_groupby['rate'] = round(p_groupby['victory'] / p_groupby['count'] * 100, 1)
p_groupby

全てのルール勝率が 50% ありました。(アサリに目を背けながら)
武器ごとに集約
# 武器ごとに集約
p_groupby = p_df_myself.groupby('weapon')['count', 'victory']
p_groupby = p_groupby.sum()
p_groupby['rate'] = round(p_groupby['victory'] / p_groupby['count'] * 100, 1)
p_groupby

最近エクスプロッシャーにハマっててどんなルールでも持ってます。
ヤグラはどうしても勝てないのでクラネオ持っちゃいます。
ステージごとに集約
# ステージごとに集約
p_groupby = p_df_myself.groupby('stage')['count', 'victory']
p_groupby = p_groupby.sum()
p_groupby['rate'] = round(p_groupby['victory'] / p_groupby['count'] * 100, 1)
p_groupby

海女美術大学が得意なのか!?と思いましたがリーグマッチでした。
全体的にもっと n 数が欲しいところです。ルールによっても武器や勝率で大分違うと思いますし。
プレイヤーごとの勝率や武器使用率等も出しましたが、プライベートのため割愛いたします。
まとめ
- イカリング2 から API key を取得し、
/api/resultsからbattle_numberを取得して 詳細なリザルトを Json 形式で取得しました。 - 適当に欲しい情報をデータフレームにして CSV 形式で保存しました。
- 集約関数を使って勝率の低さを目の当たりにしました。
感想
はじめて Python を使ってみましたが、前回の記事で準備した Jupyter Lab のお陰で楽しくできました。
見てるだけで面白かったので 2 日に 1 回くらいは実行して、n 数を増やしていきたいと思います。