備忘用にデータ分析におけるPythonメモです。
ちょっとずつ追記していきます。
設定
#最大表示行数の指定(ここでは50行を指定)
pd.set_option('display.max_rows', 50)
#最大表示列数の指定(ここでは50列を指定)
pd.set_option('display.max_columns', 50)
汎用
プログレスバー
# Jupyter notebook用のtqdmを使用する
# プログレスバーは入れ子にもできる
from tqdm import tqdm_notebook as tqdm
for i in tqdm(list_i):
for j in tqdm(range(10)):
# process
フォルダ・ファイル操作
import glob
# ファイル一覧を取得
glob.glob("folder/*.csv")
# サブフォルダを再帰的に検索(Python3.5以降)
glob.glob("folder/**.txt", recursive=True)
# ファイル・フォルダが存在するかを確認
import os
os.path.exists(path) # 存在すればTrue
# フォルダを作成
os.mkdir(path)
# ファルダを作成(深い階層まで再帰的に作成)
os.makedirs(deep-path)
# 作業フォルダを変更
os.chdir(dirpath)
# 現在の作業フォルダを表示
os.getcwd()
# 空ファイルを作成
import pathlib
p_new = pathlib.Path("path_to_file")
with p_new.open(mode='w') as f:
f.write('')
圧縮・解凍
# 指定ファイルを解凍先フォルダを指定して解凍
from pyunpack import Archive
Archive(filename).extractcall(destfolder)
型判定
type(obj) is list # objがlist型ならTrue
isinstance(obj,list) # objがlist型ならTrue
np.isnan(obj) # objがNaNならTrue
math.isnan(obj) # objがNaNならTrue
df["col1"].isnull() # col1の要素がNaNならTrue
df["col1"].notnull() # col1の要素がNaNならFalse
並列計算
from joblib import Parallel, delayed
Parallel(n_jobs=-1)([delayed(f)(id) for id in list_ids])
from concurrent import futures
future_list = []
with futures.ThreadPoolExecutor(max_workers=max_workers) as executor:
for i in range(20):
future = executor.submit(fn=func, index=i)
future_list.append(future)
_ = futures.as_completed(fs=future_list)
例外検出
try:
func
except:
print("error")
リスト・辞書処理
## ソート
sorted(list_or_series) # 返り値がソート済みリスト
list_or_series.sort() # リストの中身が書き換えられる
条件に合う要素だけ残すリスト内包表記
[f"even{i:02}" for i in range(10) if i % 2 == 0]
>['even00', 'even02', 'even04', 'even06', 'even08']
辞書型のvalueの値でランクに変換
d = {"A": 30, "B": 20, "C": 50, "D": 40, "E": 30}
r = {key: rank for rank, key in enumerate(sorted(set(d.values()), reverse=True), 1)}
{k: r[v] for k,v in d.items()}
{'A': 3, 'B': 4, 'C': 1, 'D': 2, 'E': 3}
読み込み
データの読み込み
# カンマ区切り 文字コード指定 先頭数行を飛ばす
pd.read_csv(filename,encoding="cp932",skiprows=2)
# タブ区切り 列名を指定して読み込み
pd.read_table(filename,usecols=list_cols)
# json
pd.read_json(filename,lines = True)
# Excel
pd.read_excel(filename,sheet_name)
# parquet
pd.read_parquet(filename,columns=list_cols)
# 一行ずつ読み込み
with open(filename, 'r', encoding='utf-8') as file:
lines = file.readlines()
for line_data in lines:
# line_data はstr型
some_procedure()
モデルの読み込み
import pickle
pickle.load(open(path_to_model, 'rb'))
import joblib
joblib.load(open(path_to_model, 'rb'))
import pandas as pd
pd.read_pickle(path_to_model)
データ整形・加工
データフレーム全体への操作
# 空のデータフレームを作成(列名と行数を指定)
pd.DataFrame([],columns = list_columns, index = range(num_rows))
# 一行ずつ作成するような場合
l_col1 = []
l_col2 = []
for i in range(n):
l_col1 += [val1]
l_col2 += [val2]
pd.DataFrame(data={"col1":l_col1,"col2":l_col2},columns=["col1","col2"])
## 日付の比較
df["tm"].date() <= datetime.date(year,month,day)
## 時刻の比較(日付が違っていても時刻だけ取り出して比較)
df["tm"].time() <= datetime.time(hour,minute)
# 条件に合う行を検索して代入
# C列がaの行はA列の値を、それ以外の行はB列の値を返す
df['A'].where(df['C'] == 'a', df['B'])
# 前行との差分(axis=1にすると列に対する差分になる)
df.diff(periods = 1)
# 前行からの変化率
df.pct_change(periods = 2)
# 移動平均
df.rolling(window = 3).mean()
# ピボット
# 行・列・値はそれぞれリストで渡すことも可
pd.pivot_table(df, index='Rows', columns='Cols',values='vals',aggfunc=np.max)
# 横持ち⇒縦持ちに変換
pd.melt(df,id_vars=["col_id1","col_id2"],var_name="col_var",value_name="col_val" )
# 横に結合
pd.merge(df1,df2,how="left",left_on=["col1"],right_on=["colone"])
# 縦に結合(ユニオン)
pd.concat([df_1,df_2])
# ある列を基準としてソート(リスト選択も可)
df.sort_values(by=["col1","col2"], ascending=True) #昇順
行への操作
# 行を抽出
# 列名に'-'等が含まれる場合、列名全体を``で囲う
df.query("col1 == xxx")
# 値が最も小さい行を抽出
index = df["col1"].idxmin()
df.iloc[index]
df.loc[index,:] # こちらでも可
# グループごとにある列が最大値となっている行を抽出
df.loc[df.groupby("group")["col1"].idxmax(),:]
# NAを含む行を抽出
df[df.isnull().any(axis=1)]
# NAを含む行を削除(列指定)
df.dropna(subset = ["col1"])
# 重複する行を抽出
df.duplicated()
# 重複する行を削除(重複を判定する列を指定)
df.drop_duplicates(subset=["col1","col2"])
# 行まるごと代入
df.iloc[i,:] = list_row
# 一行下にずらす
df.shift(1)
# 一行下にずらす(groupごとに)
df.groupby("group").shift(1)
# ソート
df.sort_values('col1',ascending=False) # ascending=Falseで降順。デフォルトは昇順
列への操作
# indexを振りなおす
df.reset_index(drop = True)
# 列を抽出(列名指定)
df[["col1", "col2"]]
# 列を抽出(ある文字で始まる・終わる・含む)
df.loc[:, df.columns.str.startswith('xxx')]
df.loc[:, df.columns.str.endswith('xxx')]
df.loc[:, df.columns.str.contains('xxx')]
# 列を追加
df.assign(AddedRow=-1)
# 列を削除
df.drop(["col1"], axis=1)
# 列名を変更(完全一致)
df.rename(columns = {"col_before" : "col_after"})
# 型を変換
df["numcol"].astype(str)
# 文字列を日付型に変換
df["date"].to_datetime(format = '%y%m%d %H:%M')
%Y 4桁の年数 (例 2018,1996…)
%y 2桁の年数 (例 18, 96..)
%m 2桁の月 [01,12] (例 01, 07, 12..)
%d 2桁の日付 [01,31] (例 02, 28, 31..)
%H 24時間表記の時間 [00,23] (例 00, 12, 21..)
%I 12時間表記の時間 [01,12] (例 01, 07, 12..)
%M 2桁の分 [00, 59] (例 00, 05, 38, 59..)
%S 秒 [00, 61] (例 00, 15, 39, 60, 61..)60,61は00,01と同じ
# 値を置換(完全一致)
df.["col1"].replace("before", "after")
# 指定した文字列を取り除く
df["col"].str.strip("no_need_str")
# 空白を削除
df["col"].str.strip()
# 列に対して関数を適用
df["col1"].apply(lambda x: x+1 if condition else x+2)
# 列に対して辞書で変換
df["col1"].map(dict1)
# 複数の列を条件に関数を適用
def func(row):
return 1 if row["col1"] == row["col2"] else 0
df.apply(func, axis = 1)
# 複数の列を文字列として結合
df["col1"].str.cat(df["col2"], sep = "-")
# グループごとに行番号(連番)を付与
df.groupby("group").cumcount()
# グループごとにwindowをずらしながら集計
df.groupby("group")["col1"].rolling(window=10, min_periods=1).mean().reset_index(level=0,drop=True)
# グループごとの先頭行からの累積集計
df.groupby("group")["col1"].expanding(min_periods = 2).mean().reset_index(level=0,drop=True)
# 指数加重で集計
df.groupby("group")["col1"].ewm(halflife=10).mean().reset_index(level=0,drop=True)
ベーシックな加工(pandas以外)
# 文字列を分割
## 区切り文字を指定(完全一致)
s.split("/")
## 分割後の右端を取得
s.split("/")[-1]
## 改行で分割
s.splitlines()
## 正規表現で分割
import re
re.split('\d+',s)
# 文字列を結合
','.join(list_str)
集計
# 各要素の個数を算出(normalize=Trueで合計が1になるように正規化)
df["col1"].value_counts(ascending = True,normalize = False)
# TX 1
# CA 2
# NY 2
# Name: state, dtype: int64
# グループごとに集計
df.groupby("group").agg(sum_col1 = ('col1','sum'),
count_col1_zero = ('col1',lambda x: sum(x==0)))
# グループごとに集計(行数は元のdfと同じ)
df["sum_col1"] = df.groupby("group").transform({"sum_col1":"sum"})
# pivot(行・列・集計方法を指定)
df.pivot_table(index="col1",columns="col2",values="col3",aggfunc=[np.mean, len])
変換
# 上限・下限で変換
np.clip(a,min_value,max_value) # どちらかのときはNoneを使用
# Label Encoder
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
df["col1"] = le.fit_transform(df["col1"])
df2["col1"] = le.transform(df2["col1"])
le.inverse_transform(df["col1"]) #復元
ちょっと特殊な整形
dataframeのあるカラムのある要素があるリストに含まれている場合にのみ抽出する。
df = pd.DataFrame({'Description': ['foo bar blah', 'new foo', 'newfoo', 'bar']})
keywords_list = ["foo", "bar"]
df['Description'].str.split(expand = True).isin(keywords_list).any(1)
>0 True
>1 True
>2 False
>3 True
要素をsplitして縦持ちに変換する。
df
>col1 col2 col3
>a x;y;z 1
>b x 2
>c y;z 3
df["col2"] = df["col2"].str.split(";") # リストに変換
df.explode("col2")
>col1 col2 col3
>a x 1
>a y 1
>a z 1
>b x 2
>c y 3
>c z 3
ある値に一番近いindexを取得
index = df.index[(df["col1"]-search_value).abs().argsort()][0].tolist()
相関の高い列を抽出
corrMatrix=df.corr()
corrMatrix.loc[:,:] = np.tril(corrMatrix, k=-1)
already_in = set()
result = []
for col in corrMatrix:
perfect_corr = corrMatrix[col][corrMatrix[col] > 0.9].index.tolist()
if perfect_corr and col not in already_in:
already_in.update(set(perfect_corr))
perfect_corr.append(col)
result.append(perfect_corr)
numpy
ある行を繰り返して多次元配列を作成
np.stack([[7, 1, 1, 1, 1, 1, 1, 1] for _ in range(5)], axis=0)
array([[7, 1, 1, 1, 1, 1, 1, 1],
[7, 1, 1, 1, 1, 1, 1, 1],
[7, 1, 1, 1, 1, 1, 1, 1],
[7, 1, 1, 1, 1, 1, 1, 1],
[7, 1, 1, 1, 1, 1, 1, 1]])
モデリング
アソシエーション分析
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import association_rules
# user_item行列作成
mat = np.full((len(list_user), len(list_item)), False)
mat = pd.DataFrame(mat)
mat.index = list_user
mat.columns = list_item
# 利用のあるuser, itemの組み合わせにフラグを立てる
for user in list_user:
for item in list_item:
if condition: mat.loc[user, item] = True
freq_items = apriori(pd.DataFrame(mat), min_support = 0.00001, use_colnames = True, low_memory = True)
# アソシエーション・ルール抽出
df_rules = association_rules(
freq_items, # supportとitemsetsを持つデータフレーム
metric = "confidence", # アソシエーション・ルールの評価指標
min_threshold = 0.01, # metricsの閾値
)
| antecedents | consequents | antecedent support | consequent support | support | confidence | lift | leverage | conviction | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | (756588) | (231487) | 0.000342 | 0.000499 | 0.000080 | 0.233962 | 469.331332 | 0.000080 | 1.304768 |
| 1 | (231487) | (756588) | 0.000499 | 0.000342 | 0.000080 | 0.160622 | 469.331332 | 0.000080 | 1.190950 |
| 2 | (231487) | (1111967) | 0.000499 | 0.000211 | 0.000010 | 0.020725 | 98.454623 | 0.000010 | 1.020949 |
| 3 | (1111967) | (231487) | 0.000211 | 0.000499 | 0.000010 | 0.049080 | 98.454623 | 0.000010 | 1.051089 |
##implicit
from scipy.sparse import lil_matrix
import implicit
mat = lil_matrix((len(list_item),len(list_user)))
if condition: # 反応のあったitem, userの組み合わせにフラグを立てる
mat[
item2idx[item],
user2idx[user]
] = 1
## BPR
model = implicit.bpr.BayesianPersonalizedRanking(
factors = 200,
iterations = 1000,
learning_rate = 0.01,
)
## ALS
model = implicit.als.AlternatingLeastSquares(
factors = 600,
iterations = 50,
calculate_training_loss = True,
random_state = 46,
)
model.fit(mat.tocsr())
recom = model.recommend_all(mat.T, N = 20)
pred = dict()
for user, user_idx in tqdm(user2idx.items()):
list_item_idx = recom[user_idx,:]
pred[user] = []
for item_idx in list_item_idx:
item = list_item[item_idx]
pred[user].append(item)
ホールドアウト
from sklearn.model_selection import train_test_split
X_train, X_valid, y_train, y_valid = train_test_split(X, y, test_size = 0.3, random_state = 1024, stratify = col)
クロスバリデーション
from sklearn.model_selection import KFold
folds = KFold(n_splits=nsplits, shuffle = True, random_state = rand)
for tr_idx,va_idx in folds.split(X_train,y_train):
X_tr = X_train.iloc[tr_idx]
y_tr = y_train.iloc[tr_idx]
X_va = X_train.iloc[va_idx]
y_va = y_train.iloc[va_idx]
model = make_model(X_tr,y_tr)
y_pred = model.predict(X_va)
層化抽出 (Stratified KFold)
StratifiedKFold(n_splits = nsplits, shuffle = True, random_state = rand)
GroupStratifiedKFold
StratifiedKFold(n_splits = nsplits, shuffle = True, random_state = rand)
for tr_idx_p,va_idx_p in folds.split(df,df["group_id"]):
tr_id, va_id = df.loc[tr_idx_p,"group_id"], df.loc[va_idx_p,"group_id"]
tr_idx = df_train[df_train["group_id"].isin(tr_id)].index
va_idx = df_train[df_train["group_id"].isin(va_id)].index
X_tr = X_train.iloc[tr_idx].reset_index().drop("index",axis = 1)
y_tr = y_train.iloc[tr_idx].reset_index().drop("index",axis = 1)
X_va = X_train.iloc[va_idx].reset_index().drop("index",axis = 1)
y_va = y_train.iloc[va_idx].reset_index().drop("index",axis = 1)
評価
# ROC-AUC
from sklearn.metrics import roc_auc_score
roc_auc_score(y_true, y_pred)
# PR-AUC
from sklearn.metrics import average_precision_score
average_precision_score(y_true, y_pred
# precision
from sklearn.metrics import precision_score
precision_score(y_true, y_pred)
# recall
from sklearn.metrics import recall_score
recall_score(y_true, y_pred)
可視化
import matplotlib.pyplot as plt # matplotlib
import seaborn as sns # seaborn
図
基本
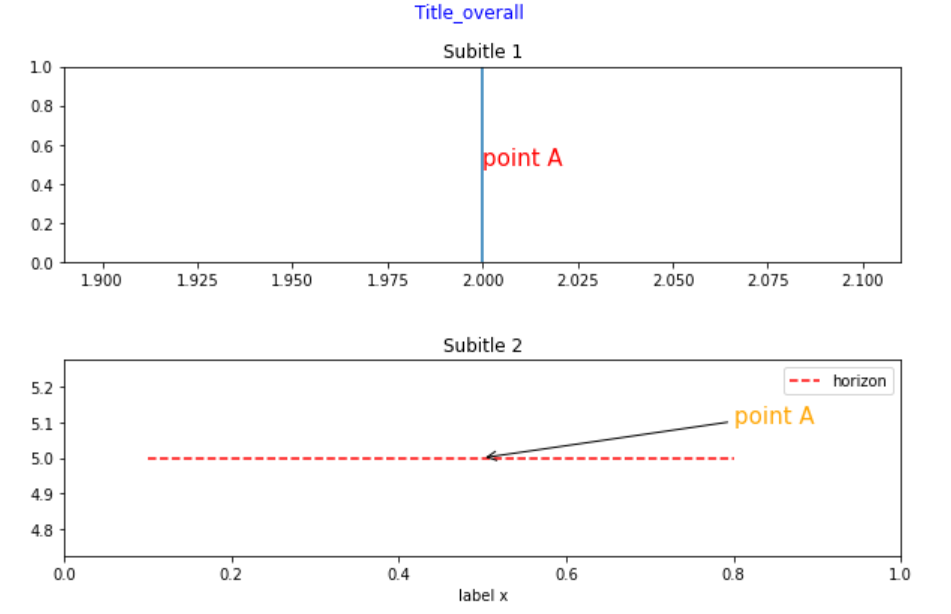
# 2行1列の図を作成
fig, ax = plt.subplots(2,1, figsize = (10,6))
# subplots間の幅(縦)を調整
fig.subplots_adjust(hspace = 0.5)
# 1行目の図に縦線を追加
ax[0].axvline(x = 2)
# 2行目の図に横線を追加(色やスタイルを変更)
ax[1].axhline(y = 5, xmin = 0.1, xmax = 0.8, color = "red", linestyle = "dashed", label = "horizon")
plt.legend()
# タイトル・軸ラベルを追加
fig.suptitle("Title_overall", fontdict = {"fontsize": 15, "fontweight": "bold", "color": "blue"})
ax[0].set_title("Subitle 1")
ax[1].set_title("Subitle 2")
ax[1].set_xlabel("label x")
# アノテーションを追加
ax[0].annotate("point A", xy = (2, 0.5), size = 15, color = "red")
ax[1].annotate("point A", xy = (0.5, 5), xytext = (0.8,5.1),arrowprops = {"arrowstyle" : "->"}, size = 15, color = "orange")
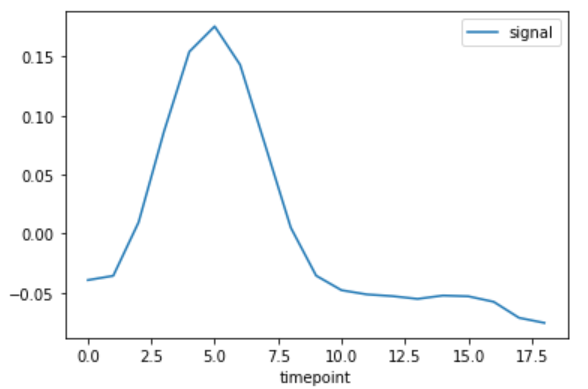
折れ線
df = sns.load_dataset("fmri")
df.query("(subject=='s0') & (region=='parietal') & (event=='stim')").sort_values("timepoint").plot(x="timepoint",y="signal")
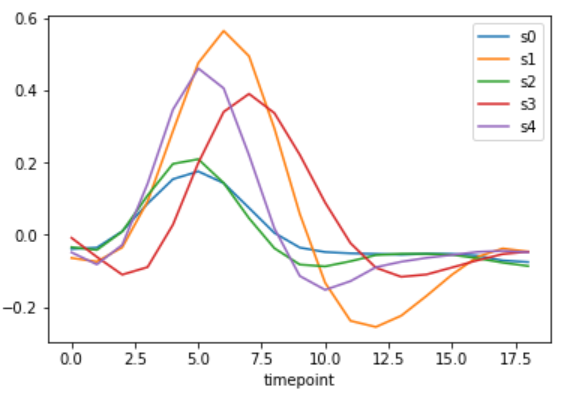
# 複数のグラフを一つの図で表現
# labelを指定することで凡例の表示を自由に作成可能
cmap = plt.get_cmap("tab10") # カラーパレットにデフォルトの10色を使用
fig, ax = plt.subplots(1,1)
for i in range(5):
df.query(f"(subject=='s{i}') & (region=='parietal') & (event=='stim')").sort_values("timepoint").plot(x="timepoint",y="signal",ax=ax,color=cmap(i),label=f"s{i}")
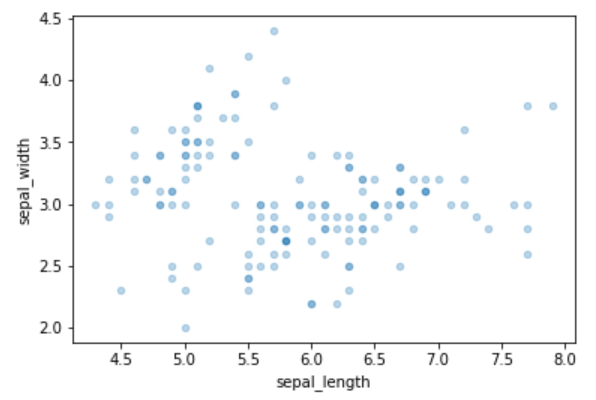
散布図
cmap = plt.get_cmap("tab10") # カラーパレットにデフォルトの10色を使用
fig, ax = plt.subplots(1,1)
df = sns.load_dataset('iris')
for i in df["species"].unique():
df.query("species==@i").plot.scatter(x="sepal_length",y="sepal_width",ax=ax,alpha=0.3)
ヒストグラム
df = sns.load_dataset('iris')
df.hist(column = "sepal_length", by = "species", bins = 10)
離散値の場合
df = sns.load_dataset('iris')
df["species"].value_counts().plot(kind="bar", xlabel = "species", ylabel = "count")
グラフの上に数値を表示する
def autolabel(rects):
for rect in rects:
height = rect.get_height()
ax.annotate(
f'{height:.2f}',
xy = (rect.get_x() + rect.get_width()/2, height),
xytext = (0,3),
textcoords = "offset points",
ha = "center",
va = "bottom"
)
df = sns.load_dataset('iris')
df = df.groupby("species").mean().reset_index()
fig, ax = plt.subplots(1,1)
width = 0.35
rect1 = ax.bar(np.arange(len(df)) - width/2, df["sepal_length"], width, label = "sepal_length")
rect2 = ax.bar(np.arange(len(df)) + width/2, df["petal_length"], width, label = "petal_length")
ax.set_ylabel("length")
ax.set_title("Iris")
ax.set_xticks(np.arange(len(df)))
ax.set_xticklabels(df["species"], rotation = 90)
ax.legend()
autolabel(rect1)
autolabel(rect2)
plt.legend(bbox_to_anchor = (1.35,1)) # 凡例の位置を調整
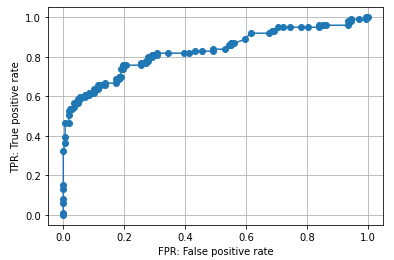
ROC curve
from sklearn.metrics import roc_curve
import matplotlib.pyplot as plt
%matplotlib inline
fpr, tpr, thresholds = roc_curve(y_valid, probas)
plt.plot(fpr, tpr, marker='o')
plt.xlabel('FPR: False positive rate')
plt.ylabel('TPR: True positive rate')
plt.grid()
plt.savefig('outputs/titanic_lr_roc_curve.png')
表
# 列名・NaNでない列の数
df.info()
# 各列の統計量
df.describe()
保存
データ
# 文字コード指定でCSV保存 インデックスは出力しない
df.to_csv(filename,encoding="cp932",index=False)
# 既存のファイルに追記(ない場合は新規作成)
df.to_csv(filename, mode = 'a', header = False)
# parquetで保存
df.to_parquet(filename, index=False)
モデル
# モデルを丸ごと保存。大きいモデルの場合はjoblibで圧縮をするほうが良い(compressは圧縮率。3が公式のおすすめ)
import pickle
pickle.dump(model, open('model.pkl', 'wb'))
import joblib
joblib.dump(model, open('model.pkl', 'wb'),compress=3)
# keras
model.save('model.h5')
# pytorch
## 学習環境と推論環境が同じ場合
torch.save(model.state_dict(),'model.pth')
## GPUで学習・CPUで推論する場合
torch.save(model.to('cpu').state_dict(),'model.pth')