はじめに
Azure Machine Learning とはAzureのサービスの一つで、Azureで機械学習モデルを構築、運用できるプラットフォームです。
Azure上でノートブック(Python)を用いたモデル構築だけでなく、データを投入するだけで自動的に最適なモデル・パラメータ探索を行ってくれるAutoMLやGUIベースでパイプラインを構築できるデザイナー機能もあり、幅広いユーザにとって活用場面のあるサービスなのですが、その幅広さ故に初めて触る人にはちょっとわかりにくい部分もあるなあと思い、構造的に理解をするために記事にすることにしました。
これからAzure Machine Learningを触ろうと考えている方、また少し触ってみたが深くは理解できていない方の一助になれればと思います。
なお、本記事の内容は私の独自の理解に基づいた記述となっており、また日々提供サービスも更新されていることを念頭に置いてあくまで参考としてお読みいただけると幸いです。
間違っている内容や古い情報に気づかれましたらコメントにてお教えいただけると嬉しいです。
まだこの記事で全部を網羅できているわけではありませんが、記事の内容は随時アップデート予定です。
前提
Azureを利用するにあたりアカウントを作成する必要があります。
本記事ではAzure Machine Learningのポータル画面から話を始めますが、
それ以前の準備に関しては別記事を参照お願いいたします。
日本マイクロソフト社が開催しているハンズオンに参加した時の記事Azure AutoML ハンズオンでも紹介しています。
全体像
Azure Machine Learningにおける機械学習モデルの構築・運用の流れとしては下記の流れになります。
- データの登録
- モデルの選択・学習・評価
- モデルデプロイ
- 運用
また、各段階においてインターフェースが複数用意されているため、便利でもあり少しわかりにくくなっている要因でもあるので、以下では上記の段階×インターフェースの切り口で解説していきます。
まず、以下はAzure Machine Learningのトップ画面です。
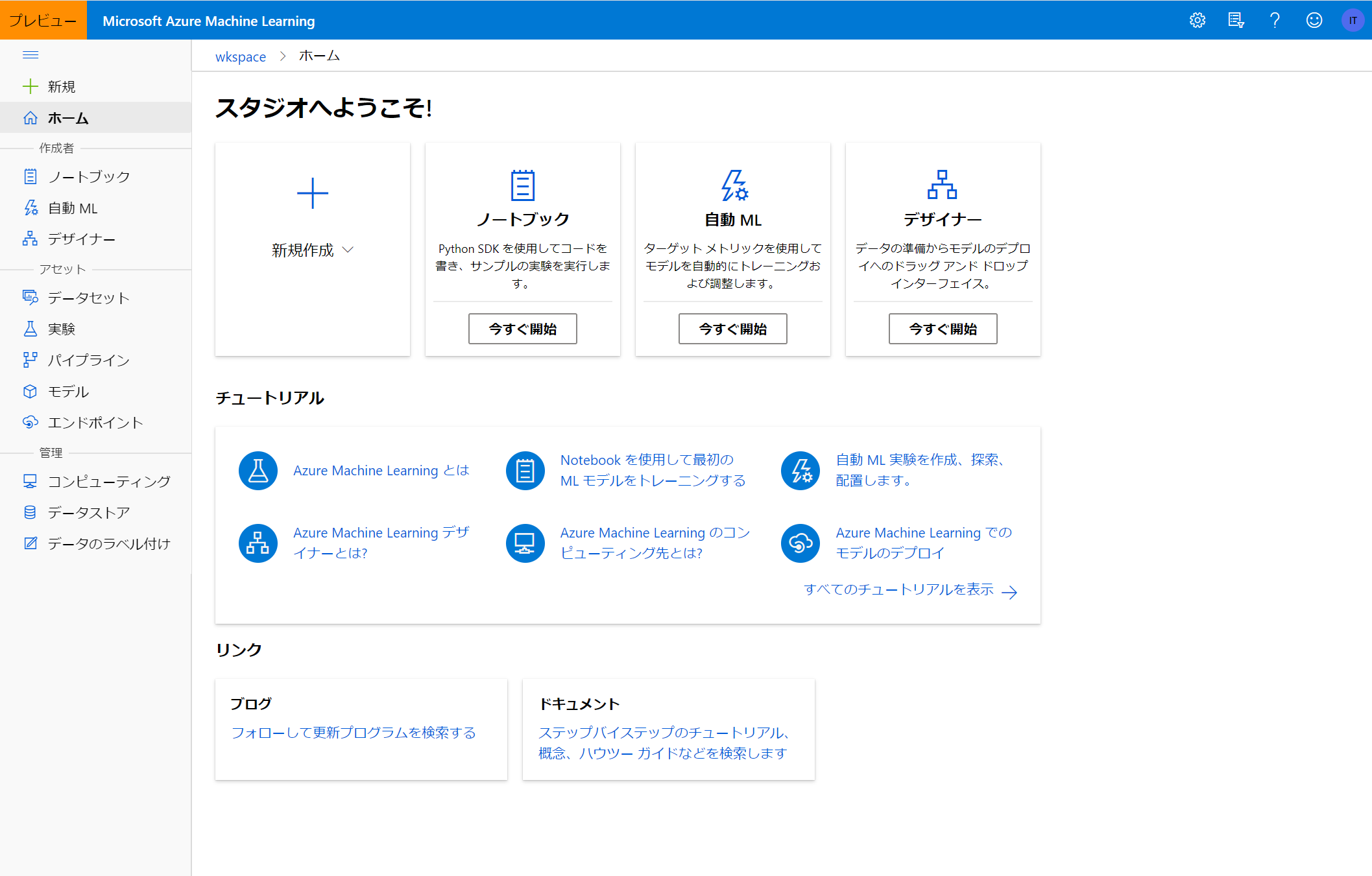
初めて触る方は公式のチュートリアルを一通り触ってみるのも良いでしょう。
画面の左側に
・作成者
・アセット
・管理
とあります。
作成者
初めて見たときは意味がよくわからなかったのですが、要はモデルを構築するためのインターフェースだと考えていいと思います。
英語だとAuthorと書いてあるのですが、どちらにしてもあまりニュアンスはよくわかりません。。
アセット
その名の通り資産のことで、Azureに登録したデータや作成したモデルなどが表示されます。
管理
主にコンピュータリソースを管理します。
後述しますが、Azureは基本的に従量課金のため、無駄にコンピュータリソースを稼働させていると不必要に高額な費用を発生させてしまいかねないので注意が必要です。
本記事では、モデルを構築する順番通り、
データ登録⇒モデル学習⇒モデル登録⇒デプロイ⇒推論の順番に紹介していきます。
本当はその前にAzure上で学習・推論などを行うためのコンピューティングリソースの作成・管理の話が必要なのですが、少しややこしいため最後にまとめて記載します。
データの準備
データソースはcsvファイルやWeb上のデータ等、おおよそ何でも使えます。
今回はお馴染みのTitanicデータをCSV化したものをローカルから読み込ませて学習・推論させます。
データの登録
Azure上でモデルを学習・推論させるにあたり、モデルを登録させる必要があります。
登録されたデータはアセットのデータセットに表示されます。
アセットから登録する
ホーム画面からアセット⇒データセット⇒データセットの作成でデータを登録することができます。
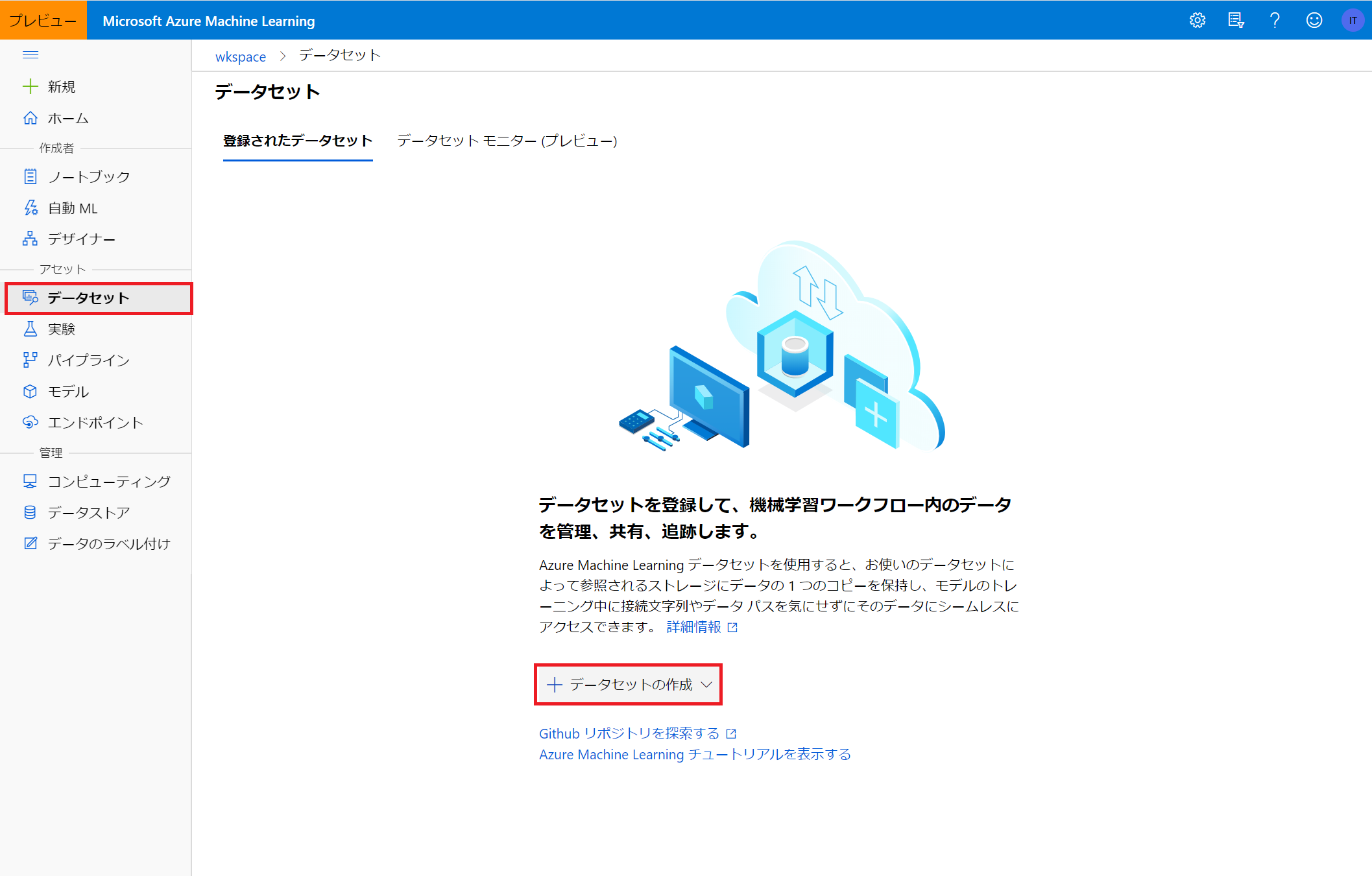
図の赤枠をクリックすると、ローカルファイルから データストアから Webファイルから Open Datasetsからという選択肢が表示されます。
ここではローカルファイルからデータセットを登録します。
登録画面に以下の手順で情報を入れていくと、データセットの登録が進みます。
データの形式などはAzure側である程度判別してくれるので、ユーザ側でそこまで細かい設定をする必要はありません。
基本情報
| 項目名 | 説明 | 例 |
|---|---|---|
| 名前 | データセットの名前。後で見て何のデータかわかるように設定する。 | titanic-train |
| データセットの種類 | 音声ファイルなど非定型データも登録可能。一般的なテーブルデータであれば「表形式」を選択。 | 表形式 |
| 説明 | データセットの説明。任意。 | Titanicの学習用データ |
データストアとファイルの選択
| 項目名 | 説明 | 例 |
|---|---|---|
| データストアの選択または作成 | どのデータストアにデータを登録するか選択。 | 現在選択されているデータストア |
| データセットのファイルの選択 | 登録するデータを選択。 | train.csv(ローカルのファイルから選択) |
設定とプレビュー
| 項目名 | 説明 | 例 |
|---|---|---|
| ファイル形式 | 表形式データであれば「区切り」を選択。 | 区切り |
| 区切り文字 | コンマ区切り、タブ区切り等を選択。 | コンマ |
| エンコード | ファイルのエンコード形式を選択。 | UTF-8 |
| 列見出し | 「ヘッダーなし」を選択すると、「Column1」のように通し番号でカラム名が設定される。ファイル中にヘッダーが記載されている場合は「最初のファイルのヘッダーを使用する」等を選択。 | 最初のファイルのヘッダーを使用する |
| 行のスキップ | ファイルの先頭数行に不要な行(ファイルの説明等)が入っている場合は、その行を無視するためにスキップする行数を指定。 | なし |
スキーマ
| 項目名 | 説明 | 例 |
|---|---|---|
| 含める | Azureに取り込むか否かを選択。 | ON |
| 列名 | PassengerId | |
| プロパティ | ||
| 種類 | 整数、文字列、日付などから選択 | 整数 |
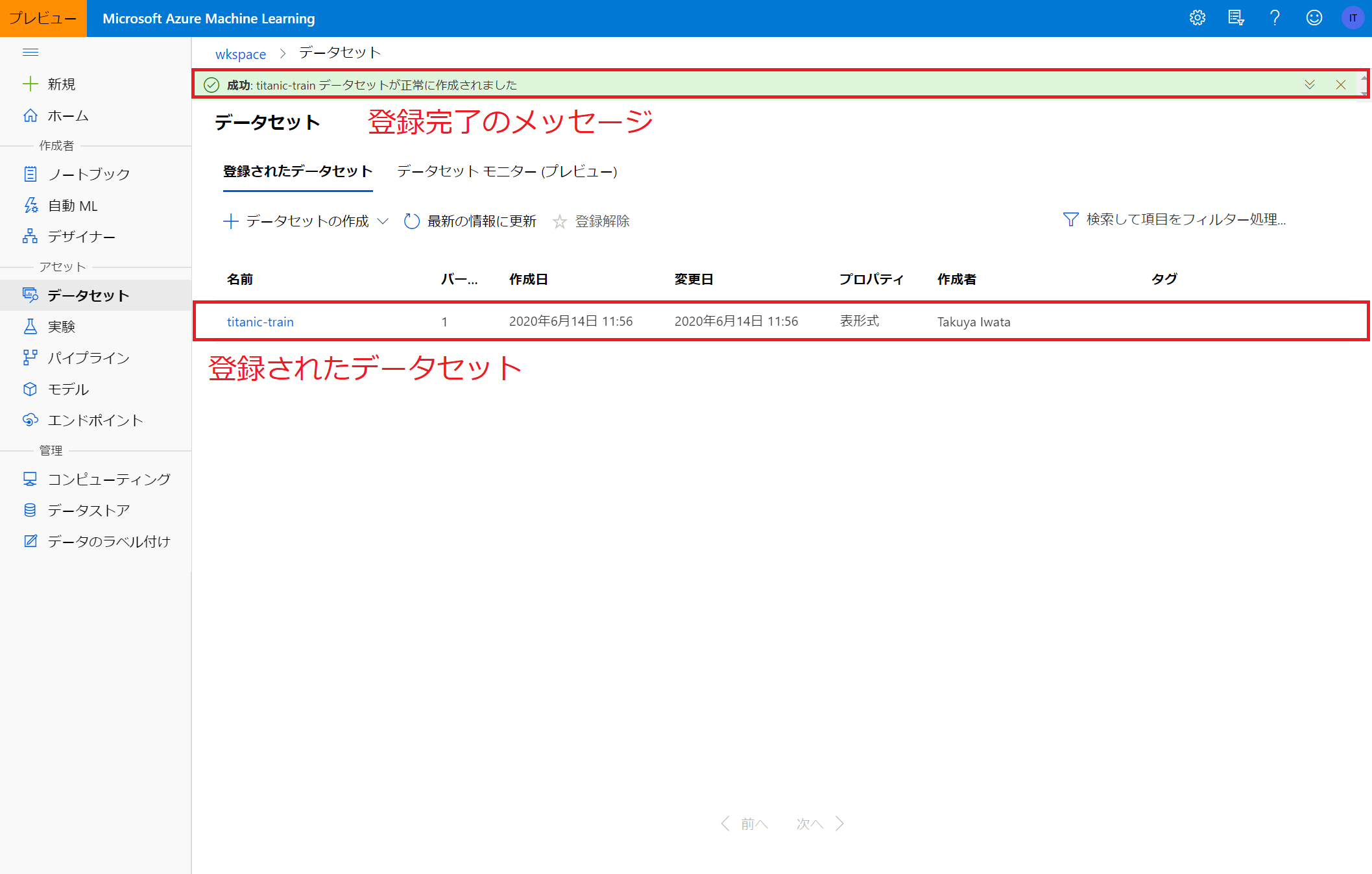
ここまで来るとデータセットの登録が完了します。
データセットの登録が完了すると、アセット⇒データセットに登録したデータセットが表示されます。
モデルの学習
Azure Machine Learning のコア機能となるモデルの学習ですが、Python でユーザが自由にモデルを構築できるノートブックをはじめ、データと予測対象列を指定すると自動的に最適なモデル学習を行ってくれる自動MLやノンプログラミングで予測パイプラインの構築を行うことができるデザイナーなど、多彩なインターフェースが用意されています。
ノートブックを使って学習する
ノートブックを使って自由にモデルを構築することができます。
ノートブックからAzure Machine Learning上のアセットにアクセスするにはPython SDKのインポートが必要になります。
ノートブックからAzure Machine Learning上のアセットにアクセスするための下準備についてはPython SDKによるAzure Machine Learning上のアセットの操作にまとめていますのでご参考にしてください。
下準備が済んでしまえば、scikit-learn等を使ったローカル環境と変わらない操作でモデルの学習を行うことができます。
自動MLを使って学習する
自動MLを使うと、指定したデータ・メトリクスに対して様々なモデルを試行してくれます。
Azure Machine Learningではデータ・メトリクスを指定した一連の学習を「実験」と呼び、
1つの実験の中の個々のモデルの学習のことを「実行」と呼んで区別しています。
つまり、1つの実験を作成すると自動MLによっていくつもの実行が作成されます。
ホーム画面から作成者⇒自動ML⇒新しい自動MLの実行を選択すると自動MLを始めることができます。
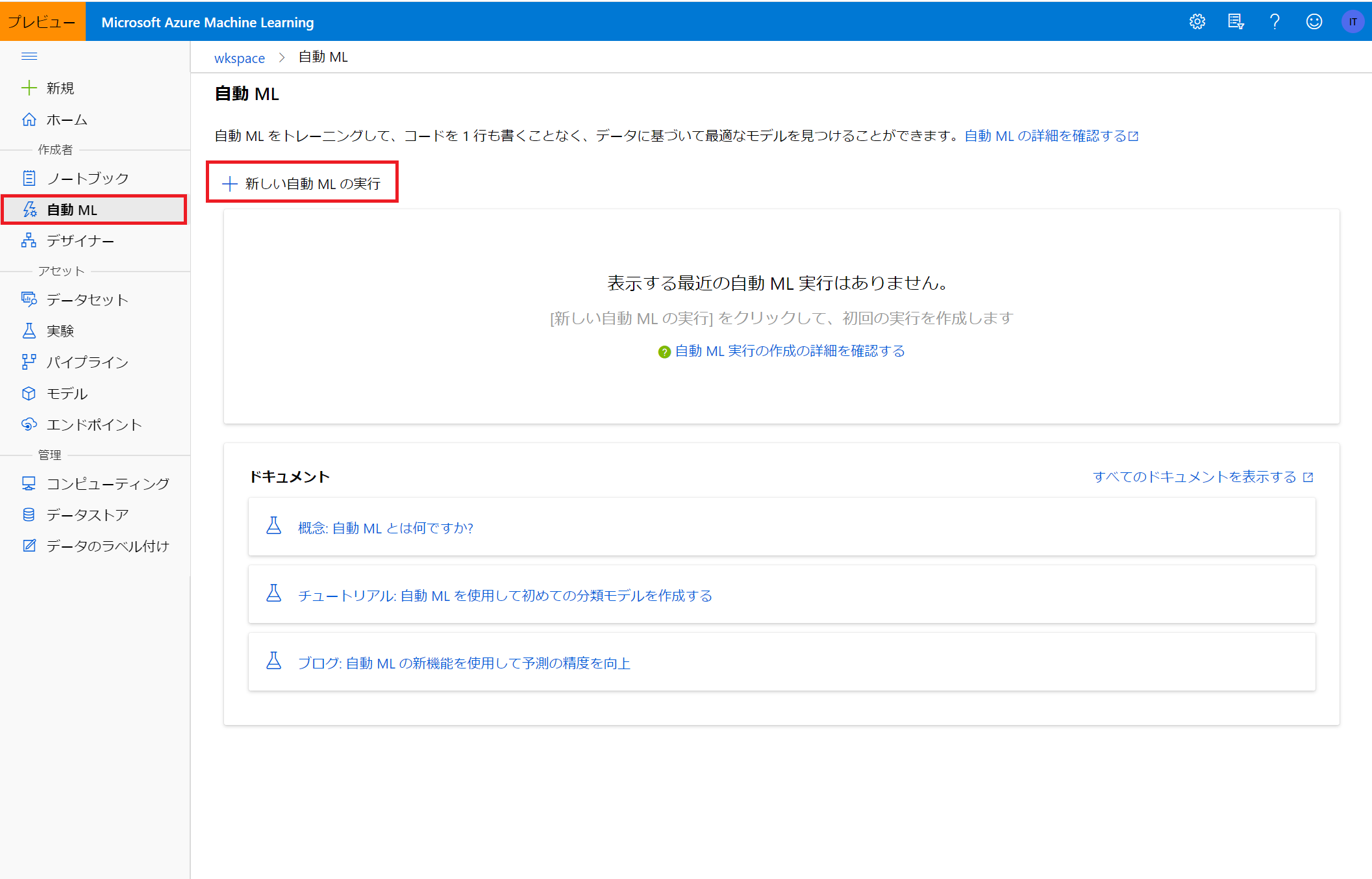
データセットの選択
学習に使用するデータセットを選択します。
前述の方法でデータセットを登録済みであれば、登録したデータセットが表示されます。
ここで初めてデータを登録することも可能です。
実行の構成
トレーニングクラスターの作成についてはコンピューティングクラスターを参照してください。
今回は事前に作成したコンピューティングクラスター(MinCompCluster01)をトレーニングクラスターとして使用しますが、この画面から新にコンピューティングクラスターを作成することもできます。
| 項目名 | 説明 | 例 |
|---|---|---|
| 新しい実験名 | ユーザが実験を識別するために名前をつける | titanic_exp01 |
| ターゲット列 | 予測したい列名。モデルの出力となる列。被説明変数。 | Survived |
| トレーニングクラスターを選択する | 学習に使うリソースを選択。 | MinCompCluster01 |
タスクの種類の選択
今回の目的が分類(カテゴリ値の予測)なのか、回帰(連続値の予測)なのか、時系列の予測なのかを選択します。
分類の場合、ディープラーニングを有効化することもできます。(2020/6/14時点でプレビュー版)
今回はタイタニック号乗船者の生存(1)または死亡(0)を予測する分類タスクのため、「分類」を選択します。
必要な情報を入力し終えると、自動MLが動き出し、学習が始まります。

しばらくすると実験が完了します。
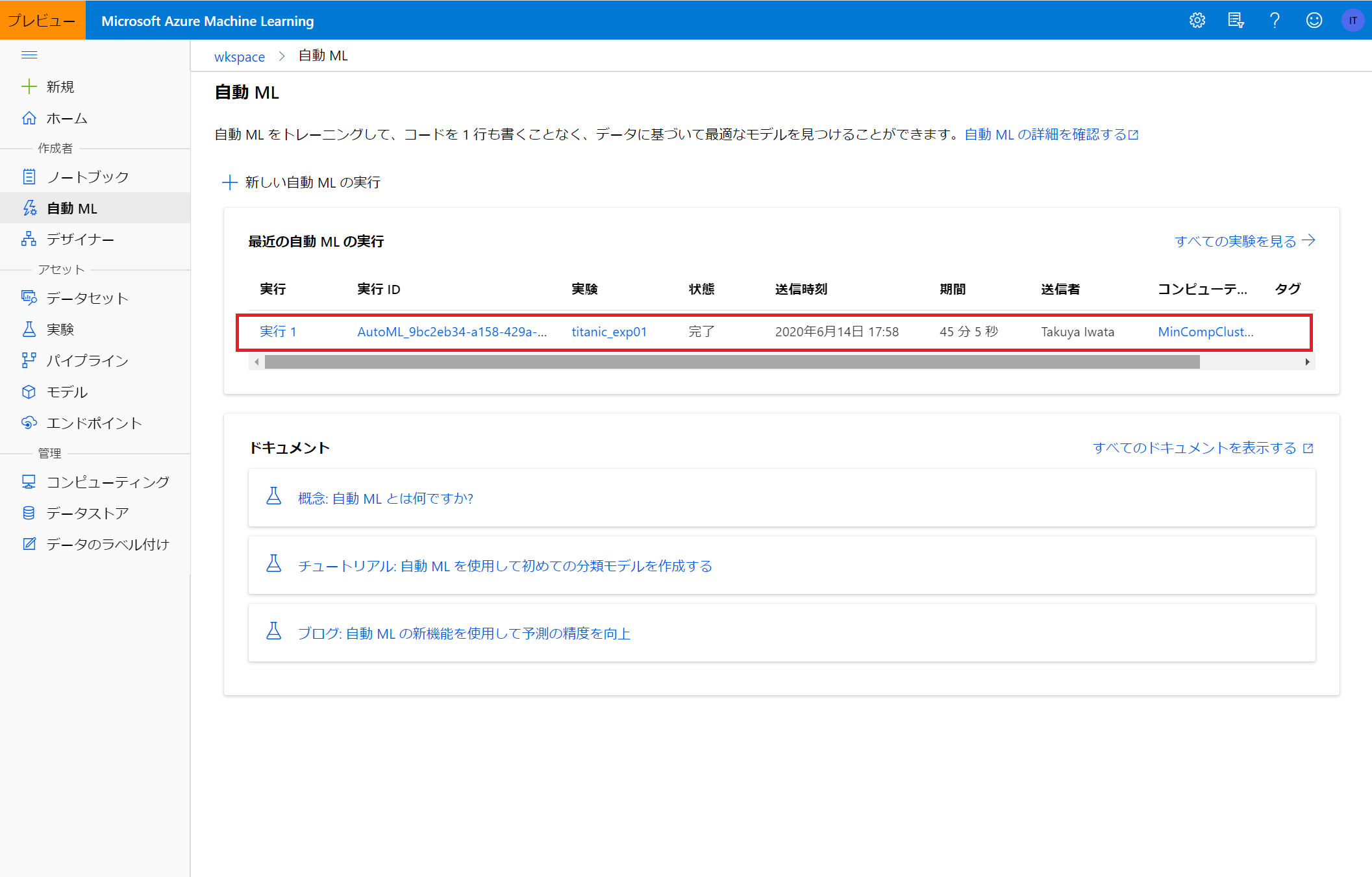
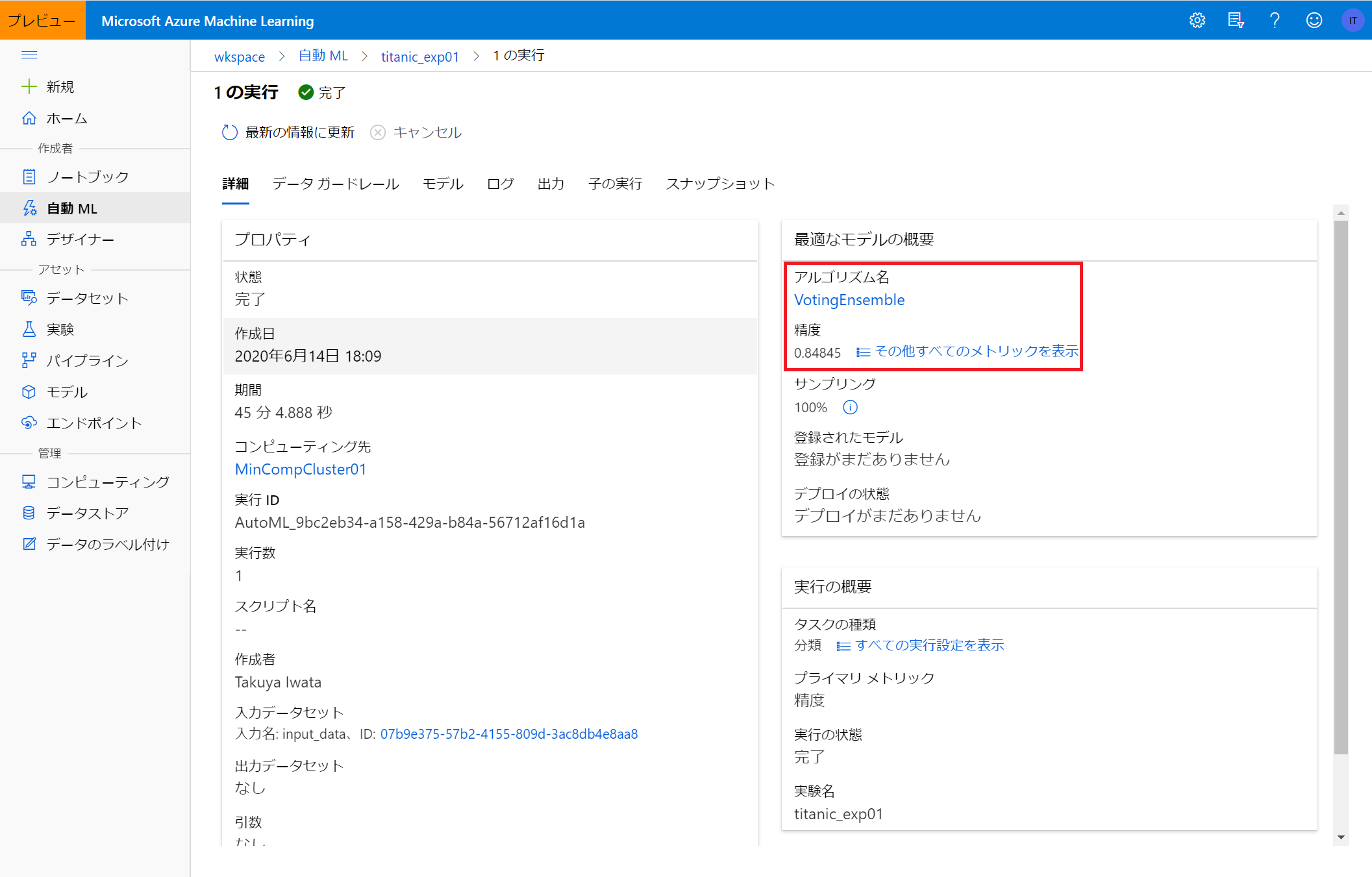
実験IDをクリックすると、実験の詳細画面に遷移し、今回の実験におけるベストモデルとそのときの精度など詳細情報を確認することができます。
デザイナーを使って学習する
デザイナー機能を使うと、GUIによるモデル構築が可能です。
自動MLでは完全に自動でモデルが選択・学習されますが、デザイナー機能を使うと使用するモデルや特徴量生成・選択をある程度自由に行うことができます。
部分的にRやPythonのコードを挿入することもできるので、柔軟性を高めつつ視覚的に処理がわかりやすいモデリングが可能となります。
デザイナー機能は作成者⇒デザイナーから使用することができます。

デザイナーで使うことができるモジュールはAzure Machine Learning特有のもので、慣れるまでは使い勝手がわかりにくいため、初めのうちはサンプルをコピーしてデータセット等を書き換えながら使用することをおすすめします。
Azure Machine Learningには、回帰・分類など多様なタスクに対応したサンプルのパイプラインが豊富に用意されているので、よほど複雑なタスクでない限りはカバーできると思います。
今回は二値分類タスクのため、「Sample 3: Binary Classification with Feature Selection - Income Prediction」をベースにパイプラインを作成していきます。
サンプルを開くと、作成済みのパイプラインが表示されます。
デザイナーを使って学習を行うには、自動MLのときと同様にコンピューティングクラスターを設定する必要があります。
ここではあらかじめ作成したMinCompCluster01を使用します。
このサンプルでは「Adult Census Income Binary Classification dataset」というデータセットを使っていますので、まずこれを今回学習させたいタイタニックデータに置き換えます。

データセットは変更しましたが、予測対象とするカラムの情報などがサンプルのままなので、適宜書き換えます。(今回のターゲットは「Survived」列です)
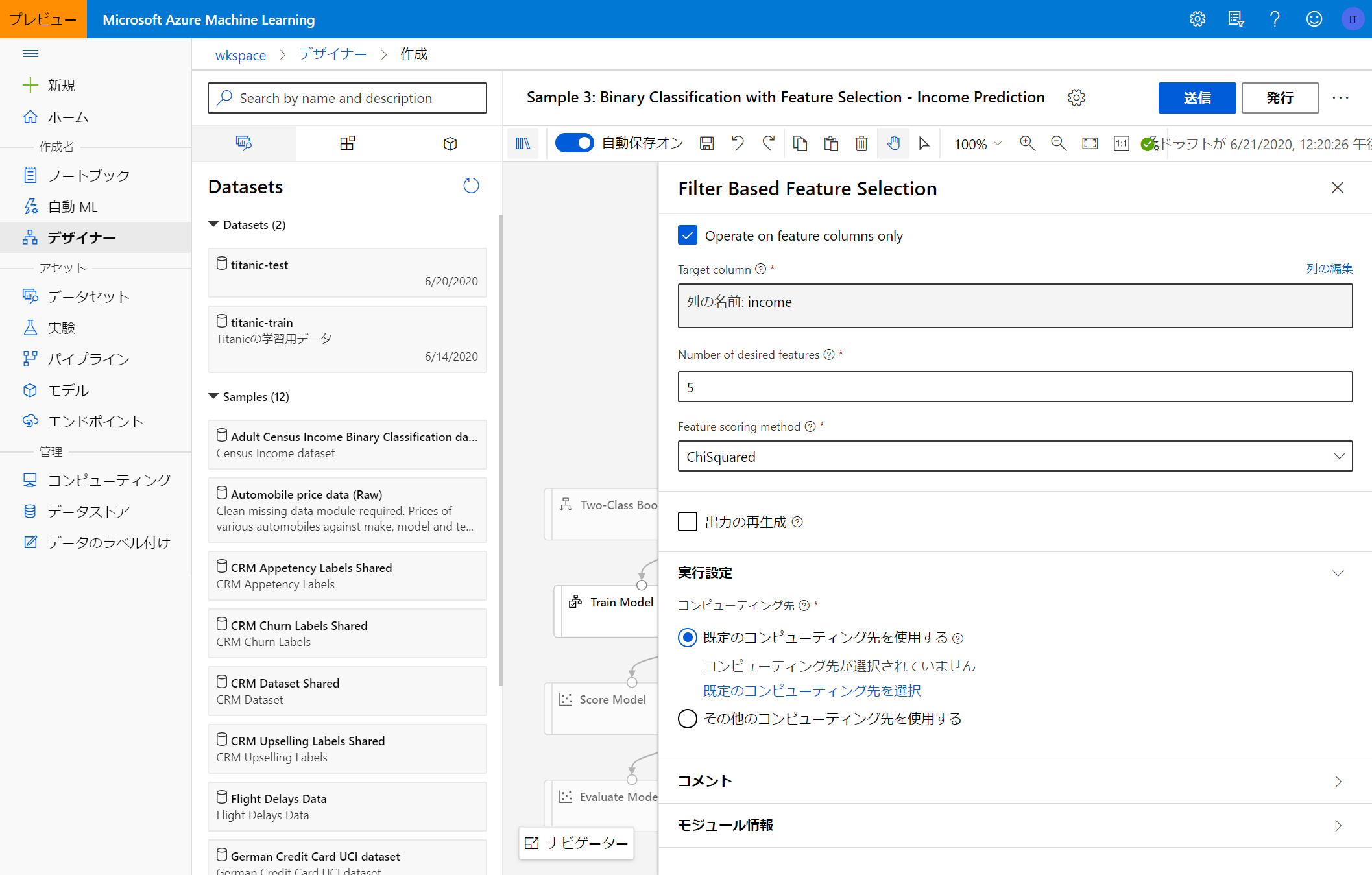
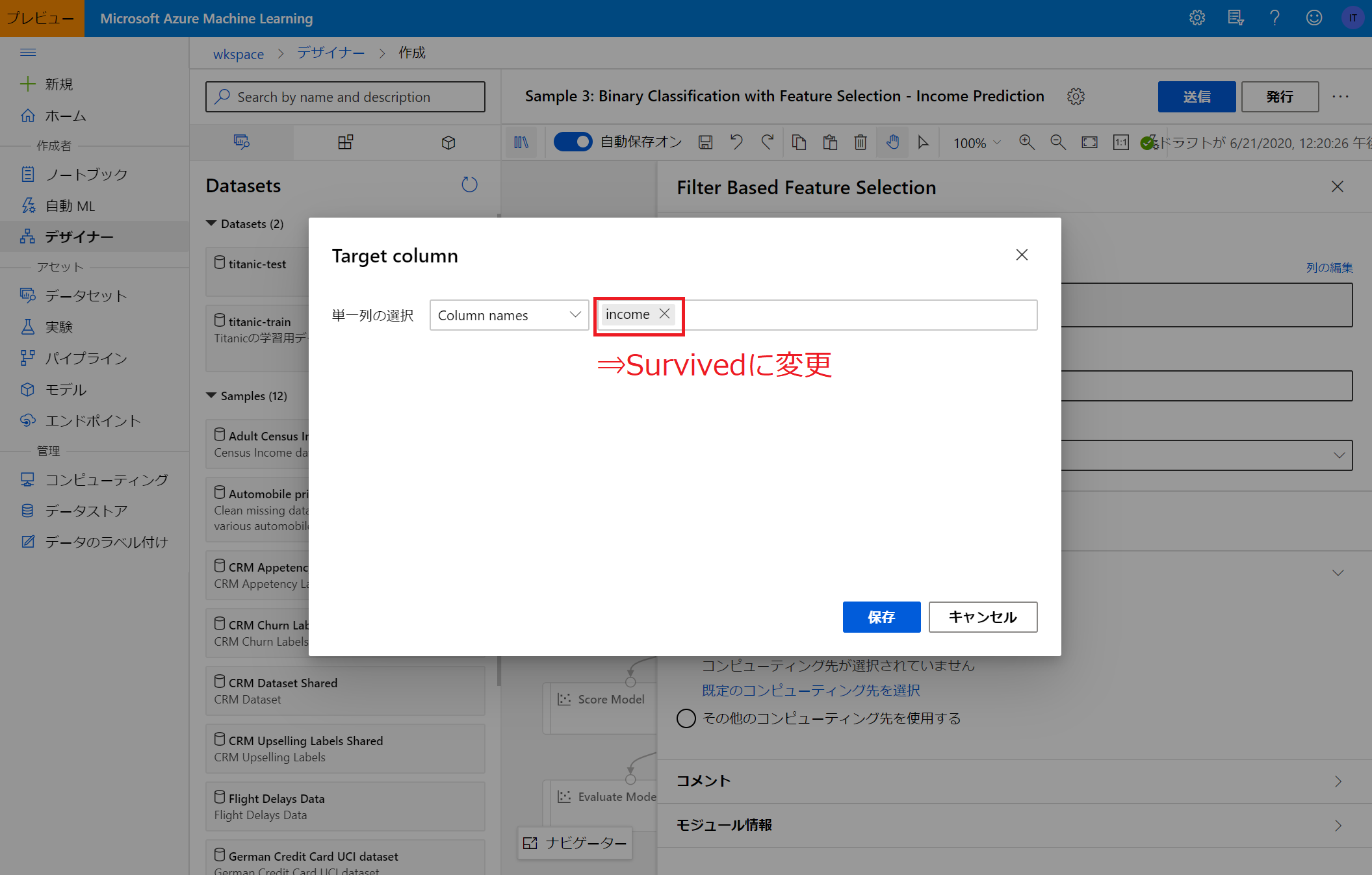
データセット・ターゲット列等を適切に設定したのち、「送信」をクリックするとパイプラインが動き出し、学習が始まります。
各モジュールの設定が正しくされていれば問題なく進みますが、列名の指定等に誤りがあると、途中で実行が止まってしまいます。
実行に失敗すると、下図のように失敗した箇所が赤く表示されます。

モジュールをクリックすると、詳細を確認することができます。
今回は、列名を「Survived」としなければいけないところをサンプルのまま「income」としていたためエラーが起こっていることがわかりましたので、修正の上再度実行します。

パイプラインを実行すると、アセット⇒パイプラインに表示されます。
ここで状態が「完了」となっていれば、パイプラインの実行が問題なく完了したことがわかります。

モデルの学習結果については、デザイナーの画面から「Evaluate Model」モジュールをクリックすることで確認できます。
Evaluate Model画面から「出力とログ」⇒「データ出力を表示する」⇒グラフのマーク(可視化)をクリックすると、ROC曲線などモデルの学習結果に関する情報を確認することができます。


Microsoftが公開しているチュートリアルにはより細かい実行例が記載されているので、ご参考にしていただければと思います。
モデルの登録・デプロイ・推論
学習したモデルを使ってWebサービスを開始したり、新しいデータから予測値を算出するには、学習したモデルを登録する必要があります。
Webサービスとして使用するためには更にデプロイが必要です。
バッチ的に新しいデータを読み込ませて予測値を算出するだけであればデプロイはする必要はなく(デプロイしてもいいのですが)、ノートブックから登録したモデルを呼び出すことで推論を行うことができます。
ノートブックを使ってデプロイする
自動MLの結果を利用する
自動MLで実行した実験結果をノートブックから取得・利用することができます。
実験結果の取得にはExperiment()を使用します。
引数には実験名experiment=が必要となります。
以下の処理では、自動MLで作成した実験titanic_exp01において精度が最もよかったモデルを探索し、呼び出しています。
experiment.get_runs(include_children = True)によって、子実験まで含めた全実験を取得し、それぞれにおける精度を比較することで最良精度の実行IDをmax_acc_runidに保存しています。
最後に、Run(experiment=experiment, run_id=max_acc_runid)によって実験IDから実行結果を呼び出しています。
# 実験名を指定して実験結果を取得
experiment = Experiment(workspace=ws, name="titanic_exp01")
max_acc_runid = None
max_acc = None
# すべての子実験結果から、最良のモデルを探索
for run in experiment.get_runs(include_children = True):
run_metrics = run.get_metrics()
run_details = run.get_details()
# メトリクスが保存されていないid(親ID等)はスキップ
if len(run_metrics) == 0:
continue
# メトリクスやIDはdict型で保存されている
run_acc = run_metrics["accuracy"]
run_id = run_details["runId"]
# print(run_id + ":" + str(run_acc))
# 精度が最大のIDを記録
if max_acc is None:
max_acc = run_acc
max_acc_runid = run_id
else:
if run_acc > max_acc:
max_acc = run_acc
max_acc_runid = run_id
# 最良精度のIDと精度を出力
print("Best run_id: " + max_acc_runid)
print("Best run_id accuracy: " + str(max_acc))
# idを指定して実験結果を呼び出し
best_run = Run(experiment=experiment, run_id=max_acc_runid)
モデルを登録する
Run.register_modelによって、実行結果からモデルを登録することができます。
モデルを登録すると、Azure Machine Learningのアセット上で確認できるようになり、モデルのデプロイや呼び出しをすることができるようになります。
model = best_run.register_model(model_name = 'model_automl01', model_path = "", model_framework = Model.Framework.SCIKITLEARN)
ノートブックを使って推論する
ここでは、学習済みモデルをサービスとしてデプロイするのではなく、予測用データを用いて予測値を算出する方法を紹介します。
# モデルのpklファイルを含む、実行に関するデータをすべてAzure上のマイファイルにダウンロード
best_run.download_files(output_directory = "./download")
# pklファイルからモデルをロード
model = joblib.load("./download/outputs/model.pkl")
# 推論用のデータセットを読み込み
dataset = Dataset.get_by_name(workspace = ws, name = "titanic-test").to_pandas_dataframe()
# 予測を実行
pred = model.predict(dataset)
# csvとして出力
sub = pd.DataFrame({"PassengerId" : dataset.PassengerId, "Survived" : pred})
sub.to_csv("./submission.csv", index = False)
自動MLからデプロイする
AutoMLで実行した実験結果からモデルを選択し、デプロイしてサービスとして開始することができます。
作成者⇒自動MLまたはアセット⇒実験から実行した実験を選択し、その中からどれかモデルを選択すると画面上にデプロイが表示されます。

ここで、デプロイするモデルの名前やデプロイの形式を選択します。

名前
デプロイするモデルの名前をつけます。
説明
モデルの説明を加えます。(任意)
コンピューティングの種類
AKSまたはACIから選択することができます。
デプロイが完了すると、モデルの概要画面の「デプロイの状態」が完了になります。

さらに、アセット⇒エンドポイントに先ほどデプロイしたモデルが表示されます。
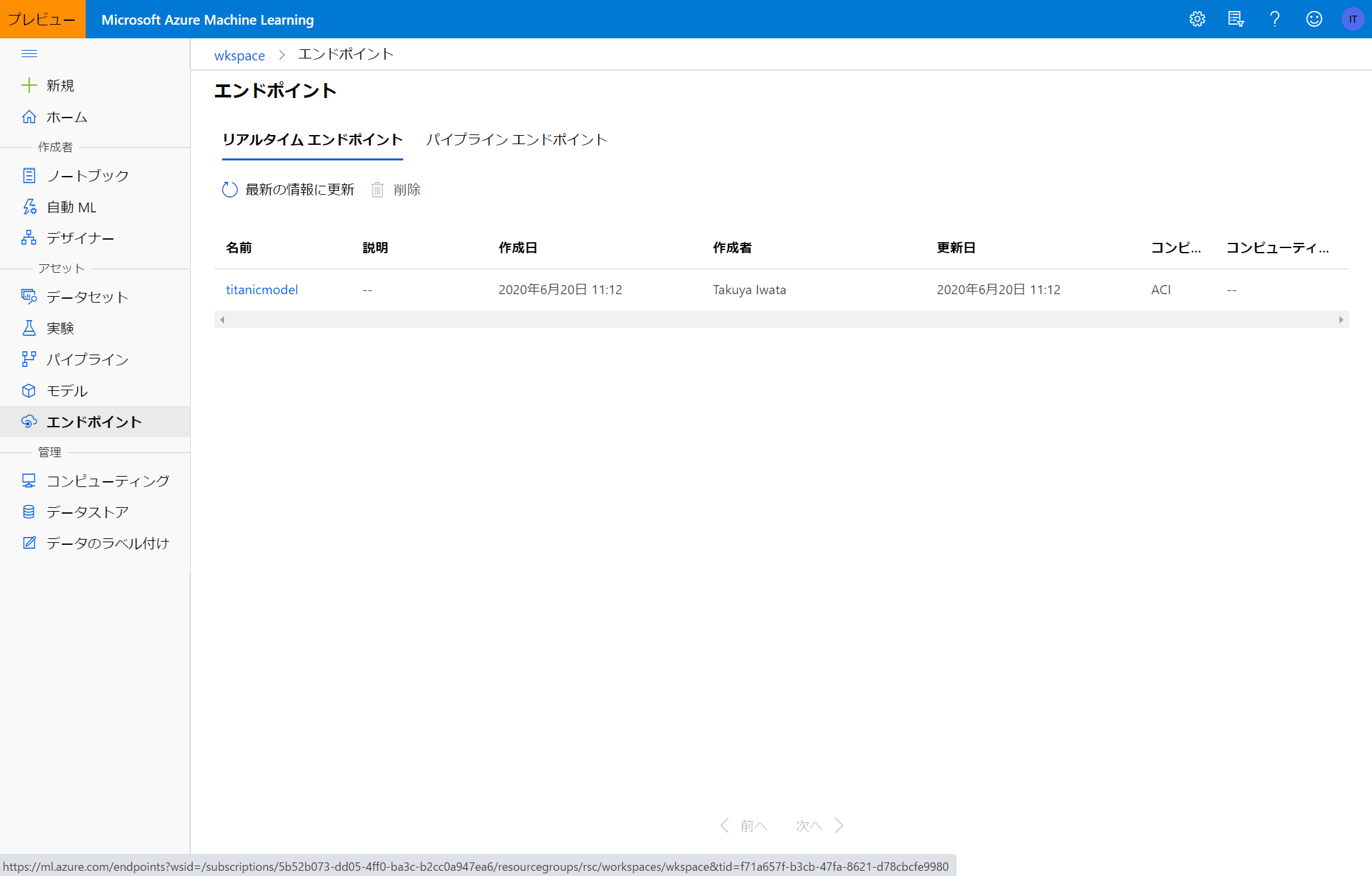
デプロイされたモデルの動作確認
デプロイしたモデルにリクエストを送信することで、モデルの動作確認を実施できます。
Azure Machie Learningのノートブックから動作確認を行う方法がこちらに書かれています。
デザイナーから推論をする
デザイナーで作成したモデルを使って推論を行うためには推論用のパイプラインを作成する必要があります。
推論パイプラインはトレーニングパイプラインのデザイナー画面から、「推論パイプラインの作成」をクリックすることで作成できます。

推論パイプラインを作成すると、「Web Service Input」と「Web Service Output」というモジュールが自動で追加されています。
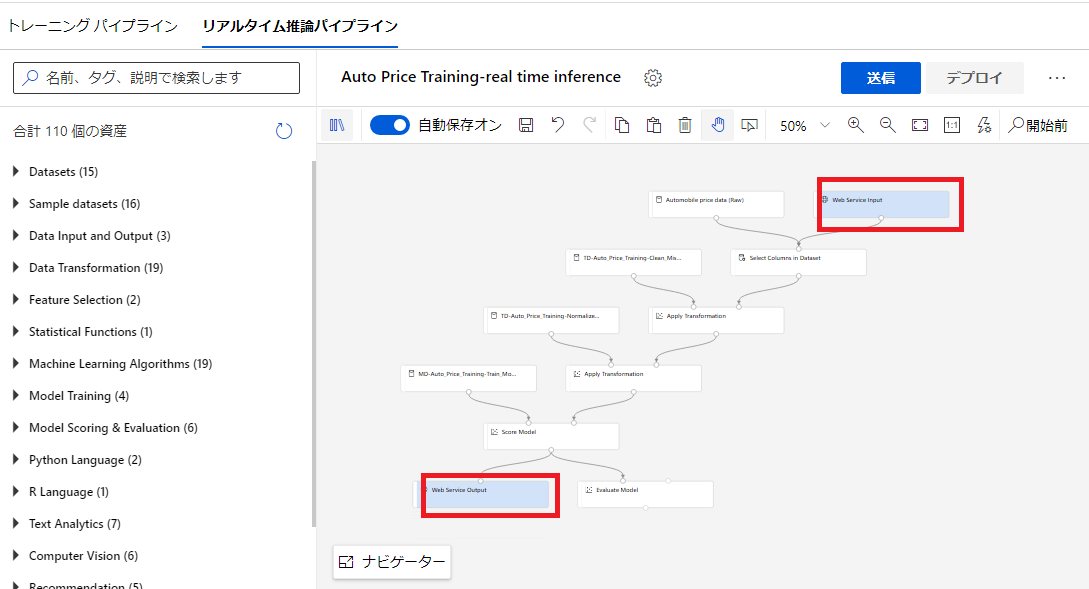
デザイナーからデプロイする
推論パイプラインのデザイナー画面から「デプロイ」をクリックすると、作成したパイプラインをデプロイすることができます。

Python SDKによるAzure Machine Learning上のアセットの操作
ノートブックを使用する
Azure Machine Learning上のノートブック機能を使って、自動MLによる学習などAzure Machine Learningの各種機能を利用することができます。
ノートブックを使用するには後述のコンピューティングインスタンスが必要となります。
SDKの読み込み
初めに、Azure Machine Learningの各種機能を利用するためにライブラリをインポートする必要があります。
インポートが問題なく完了すると、下記スクリプトの最後のprint文によりSDKのバージョンが表示されます。(表示されるバージョンは下記とは異なる場合がありますが、問題ありません)
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
import azureml.core
from azureml.core import Workspace
from azureml.core import Experiment
from azureml.core import Run
from azureml.core import Dataset
from azureml.core import Model
from azureml.train.sklearn import SKLearn
from azureml.core.compute import ComputeTarget, AmlCompute
from azureml.core.compute_target import ComputeTargetException
# check core SDK version number
print("Azure ML SDK Version: ", azureml.core.VERSION)
> Azure ML SDK Version: 1.6.0
ワークスペースの読み込み
次に、作業を行うワークススペースを読み込みます。
ワークスペースの読み込みにはサブスクリプションID リソースグループ名 ワークスペース名の3つの情報が必要となります。
subscription_id = '*****' # サブスクリプションIDを入力
resource_group = '******' # リソースグループ名を入力
workspace_name = '********' # ワークスペース名を入力
try:
ws = Workspace(subscription_id = subscription_id, resource_group = resource_group, workspace_name = workspace_name)
# ws.write_config()
print('Library configuration succeeded')
except:
print('Workspace not found')
ワークスペースの読み込みが完了すると、ワークブックからAzure Machine Learningを使用する準備が整います。
ローカルの環境からAzure Machine Learningを使用する
Python SDK を使うことで、ローカルの環境からAzure Machine Learningの各サービスを使用できるようになり、Azure Machine Learning上のノートブックを使わない分、費用を抑えることができます。
ローカルからAzure Machine Learningを動かす方法については、他の型の記事ですが下記でまとめられていますので、ご参照ください。
ローカルでAzure Machine Learningを実行するときのメモ
管理 - コンピューティング
Azure Machine Learningに使う仮想マシンの作成・管理についてまとめます。
モデルの学習・推論に仮想マシンが必要なことは言うまでもないですが、Azure Machine Learning上のワークブック機能を使う際にも仮想マシンが必要となります。
そして、Azure Machine Learningの費用はどの程度の性能のインスタンスを何時間使うかによって
ほとんど決まるため、仮想マシンについての理解は不可欠です。
仮想マシンのサイズと料金の関係については後述の費用を参照ください。
Azure Machine Learning上で扱う仮想マシンは、ホーム画面から管理⇒コンピューティングで確認することができます。
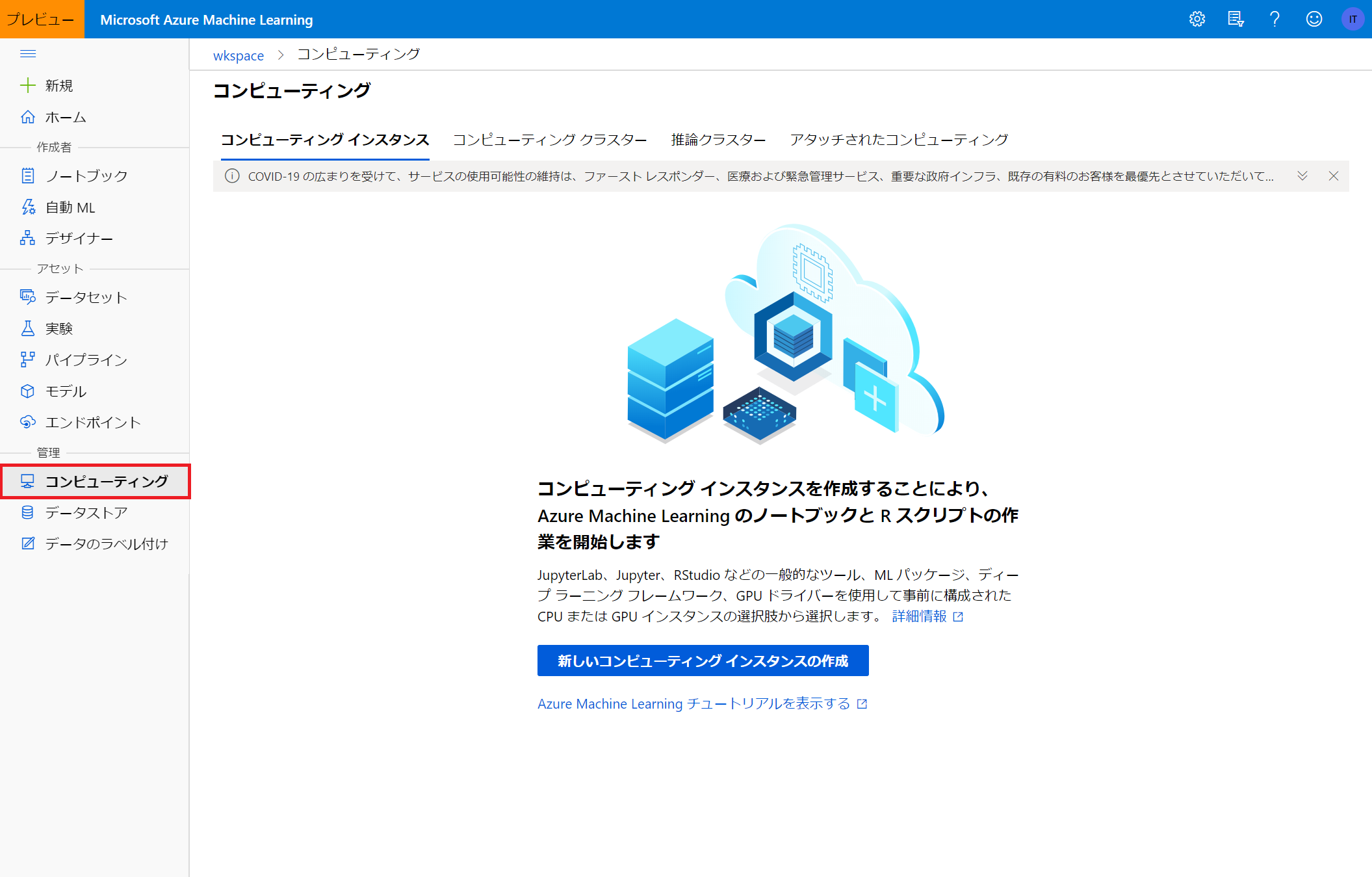
Azure Machine Learningで扱う仮想マシンには、「コンピューティングインスタンス」「コンピューティングクラスター」「推論クラスター」「アタッチされたコンピューティング」の4種類があります。
それぞれ、Azure上でノートブック等を編集・実行するためのリソースや、ノードをいくつも立ち上げて学習・推論を行うためのインスタンスなど、役割が分かれています。
また、PythonSDKを使う場合、ローカルの環境からAzureの実験をsubmitしたり、資産を操作することもできます。

コンピューティングインスタンス
コンピューティングインスタンスはノートブックを使用するための仮想マシンです。
コンピューティングインスタンスを作成するにあたり必要な項目は下記の通りです。
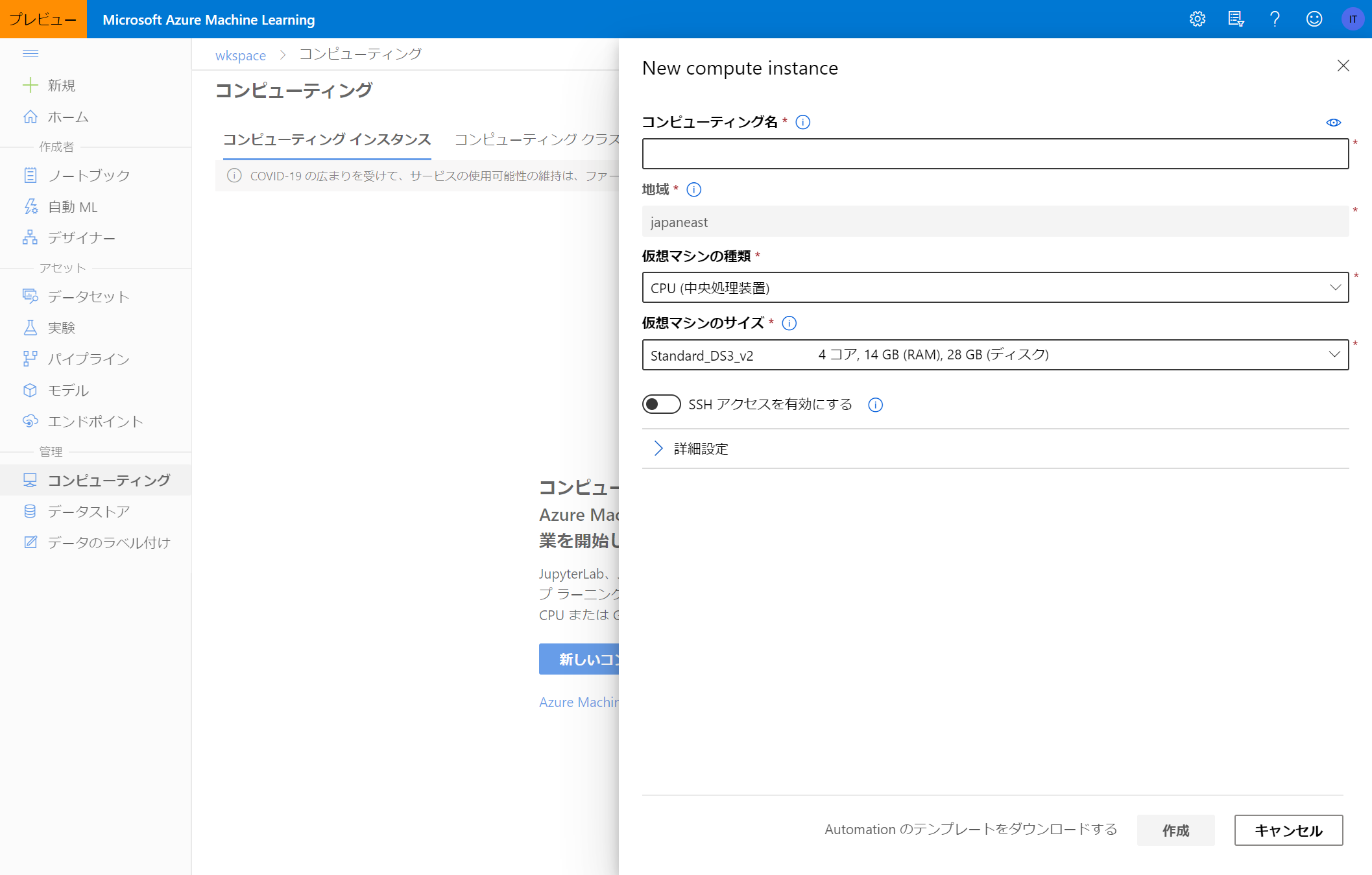
| 項目名 | 説明 | 例 |
|---|---|---|
| コンピューティング名 | ユーザが認識できるように名前をつける。 | MinCompInstance01 |
| 仮想マシンの種類 | CPUまたはGPUを選択可。 | CPU |
| 仮想マシンのサイズ | 仮想マシンのスペックを選択。高性能ほど時間当たりの費用も増える。 | Standard_D1_v2 |
コンピューティングインスタンスの作成には数分かかります。
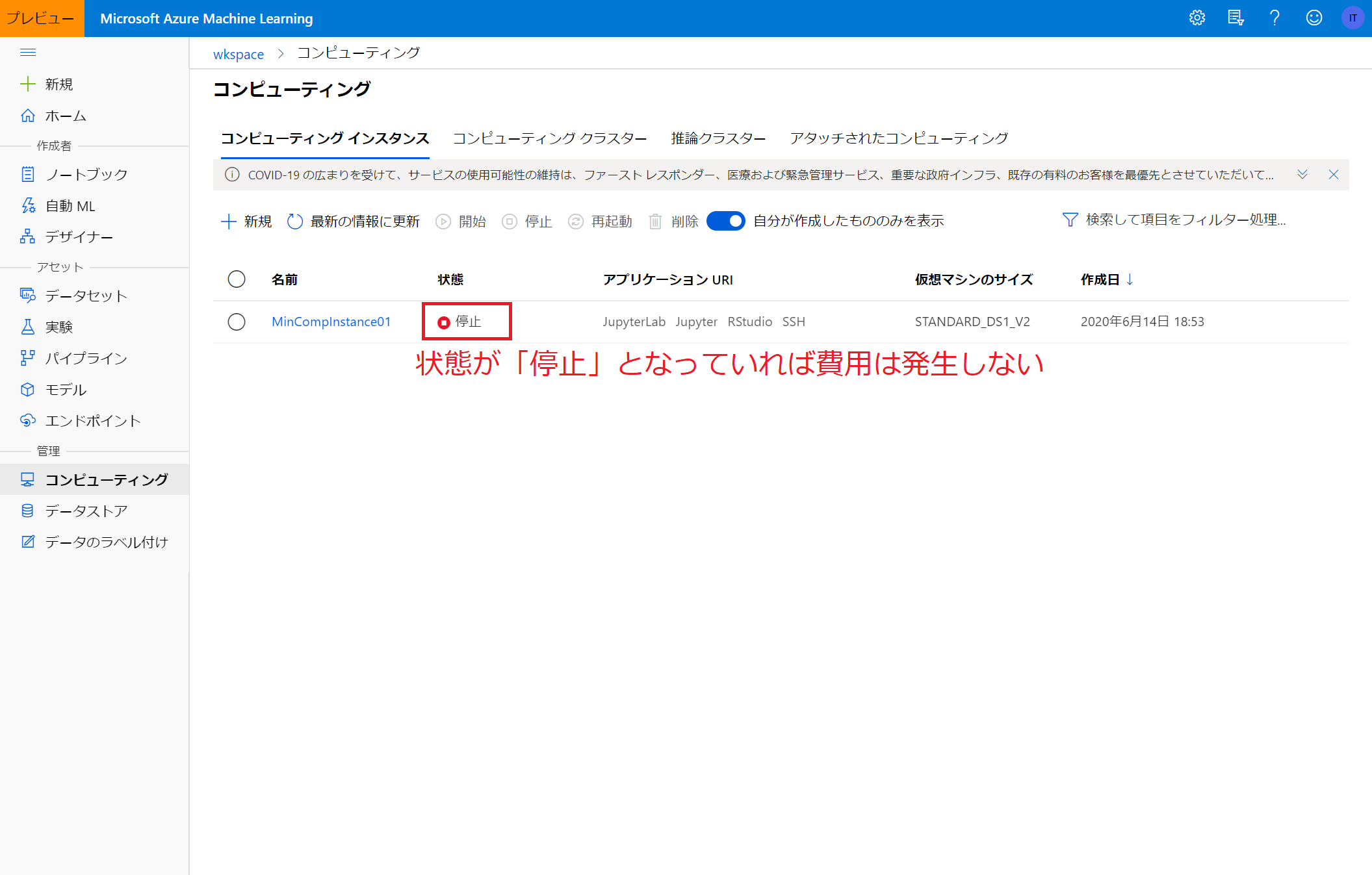
作成完了すると、以下のように一覧に現れます。
コンピューティングインスタンスは、使用しないときは明示的に停止する必要がある(停止をしないと課金され続けてしまう)ため注意が必要です。
(後述のコンピューティングクラスターは、適切に設定をすることで使用していないときの課金を自動的に防ぐことができます)
コンピューティングクラスター
コンピューティングクラスターはモデルの学習を行うための仮想マシンです。
前述のコンピューティングインスタンスと名前が似ていますが、目的が異なります。
コンピューティングクラスターを作成するにあたり必要な項目は下記の通りです。
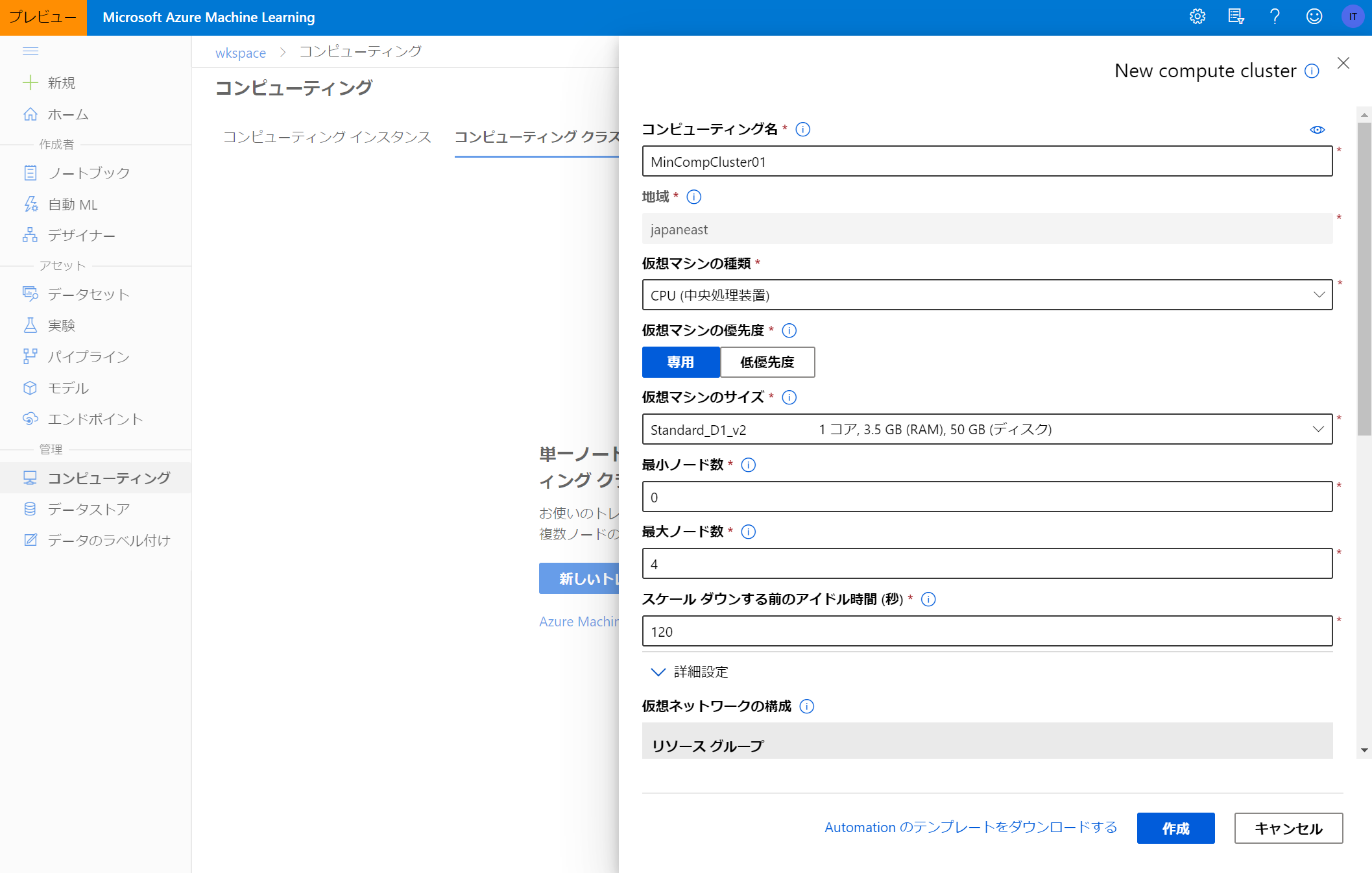
| 項目名 | 説明 | 例 |
|---|---|---|
| コンピューティング名 | ユーザが認識できるように名前をつける。 | MinCompCluster01 |
| 仮想マシンの種類 | CPUまたはGPUを選択可。 | CPU |
| 仮想マシンの優先度 | 専用または低優先度から選択可。低優先度は低コストだがノード数が保証されず、ジョブ割込みを受ける可能性あり。 | 専用 |
| 仮想マシンのサイズ | 仮想マシンのスペックを選択。高性能ほど時間当たりの費用も増える。 | Standard_D1_v2 |
| 最小ノード数 | ジョブが少ないときの最小のノード数。 | 0 |
| 最大ノード数 | ジョブが多いときの最大のノード数。 | 4 |
| スケールダウンするまでのアイドル時間(秒) | ここで設定した時間だけアイドル時間が発生した場合、最小ノード数までスケールダウンされる。 | 120 |
コンピューティングクラスターの作成には数分かかります。
作成完了すると、以下のように一覧に現れます。
このコンピューティングクラスターは最小ノード数を0に設定しており、作成直後はなんのジョブも投入されていないため自動的にノード数が0となり、課金されません。
最小ノード数を1以上にすると何もしていなくてもノードが確保される状態となり費用が発生するので注意が必要です。

推論クラスター
推論クラスターはモデルをデプロイ、推論を行うための仮想マシンです。
推論クラスターを作成するにあたり必要な項目は下記の通りです。

| 項目名 | 説明 | 例 |
|---|---|---|
| コンピューティング名 | ユーザが認識できるように名前をつける。 | MinInfCluster01 |
| 仮想マシンのサイズ | 仮想マシンのスペックを選択。高性能ほど時間当たりの費用も増える。 | Standard_D1_v2 |
| クラスターの目的 | 「運用」または「開発テスト」から選択する。 | 開発テスト |
| ノード数 | 推論に使用するノード数。 | 1 |
推論クラスターはアタッチされている間、費用が発生し続けます。
(クラスター作成後、クラスターをデタッチまたは削除するまで費用が発生します。)
そのため、必要のない推論クラスターはデタッチまたは削除する必要があります。

推論クラスターをデタッチすると一覧から消えてしまいますが、再度推論クラスターの作成画面を開き、Kubernetes Serviceの項目で「既存のものを使用」を選択すると、先ほどデタッチした推論クラスターを選択し、再度アタッチすることができます。

費用
Azure Machine Learning の費用についてはAzure Machine Learning の価格をご参照ください。
仮想マシンについては、例えば、DS3 v2(4 CPU, 14GiB)の料金は2020/6/14時点で¥45.808/時間です。
1か月24時間動かし続けると¥33,439.84/月です。
サーバー代や保守にかかる費用を考えると格安ですね。
さらにスペックの低いDS1 v2(1CPU, 3.5GiB)であれば¥11.424/時間です。(本記事執筆時点)
Azure Machine Learningの費用を抑えるTips
Azure Machine Learningは普通に使っていても安価ですが、いくつか費用を安く抑えるポイントがあります。
- ローカルからPython SDKを使ってAzure Machine Learningに接続する
- 低優先度の仮想マシンを使用する
- 単価の安いロケーションを指定する
ローカルからPython SDKを使ってAzure Machine Learningに接続する
ローカルの環境からAzure Machine Learningを使用するで紹介した方法を使ってローカル環境からAzure MLを使うようにすると、Azure ML上のノートブックを使うときに比べて費用を安く抑えることができます。(Azure ML上でノートブックを使用するとコンピューティングインスタンスの費用が発生するので)
モデル作成時に使用するコンピューティングクラスターは、実行完了後に自動的にノードを非アクティブにすることができますが、ノートブックを動かすために必要なコンピューティングインスタンスが手動でOFFにする必要があるため、切り忘れのリスクも考えるとローカル環境からAzure MLを使用することをお勧めします。
低優先度の仮想マシンを使用する
コンピューティングクラスターを作成する際、仮想マシンの優先度を「低優先度」にすると、時間当たりの費用が格段に下がります。

ただし、低優先度の仮想マシンになるので、マシンの割り当てに時間がかかったり、実行が途中で中断されてしまうことがあります。(実行が中止されることはありません。待てばそのうち再開されます)
時間当たりの料金は、マシンのスペックによって異なりますが、桁1つ程度安くなります。


単価の安いロケーションを指定する
Azure Machine Learningのリソース作成時にロケーションを単価が安い地域に設定すると、すべての仮想マシンの料金に影響します。
Azure Machine Learningのリソース作成後はロケーションを変更することはできませんので、注意してください。
基本的に日本リージョンは単価が高いです。
終わりに
冒頭にも記載した通り、私の理解が足りていない点や、記事公開以降にAzure Machine Learningが仕様変更などを行うことによって記事の内容が古くなってしまうこともあるかと思います。
最新の情報はマイクロソフト公式のものをご参照いただくよう、お願いします。
また、記事の内容について不足・誤り等ございましたらコメント等にてご指摘いただけると嬉しいです。