0. はじめに
こんにちは。都内でエンジニアをしている、@gkzvoiceです。
今回は、ajitofm 44: RDB The Right Wayをきっかけに、以下の本↓を読みました。
何度も読み返す一冊となりそうなので、本記事が道しるべとなればいいなと思い、記事を起こすことにしました。
※「書評」というほど私のRDBの理解力がなく、考察まで含んだ内容にはできておりません。
※お時間が無い方、本書がどんな本か、チラ見されたい方は、著者の登壇資料をご参照されることをオススメします。
ajitofm 44: RDB The Right Wayhttps://t.co/91XF02Dmry
— gakuji tamaki@July Tech Festa 2020運営スタッフ (@gkzvoice) March 10, 2020
>キャッシュ中毒(笑)
正しいデータは正しい設計に宿るhttps://t.co/g4Ku6vCrqf
失敗から学ぶRDBの正しい歩き方 その1 / learn-from-failure-1https://t.co/vajPmpDaFa#ajitofm
1. 本書の目次
- 第1章 データベースの迷宮
- 第2章 失われた事実
- 第3章 やり過ぎたJOIN
- 第4章 効かないINDEX
- 第5章 フラグの闇
- 第6章 ソートの依存
- 第7章 隠された状態
- 第8章 JSONの甘い罠
- 第9章 強過ぎる制約
- 第10章 転んだ後のバックアップ
- 第11章 見られないエラーログ
- 第12章 監視されないデータベース
- 第13章 知らないロック
- 第14章 ロックの功罪
- 第15章 簡単過ぎる不整合
- 第16章 キャッシュ中毒
- 第17章 複雑なクエリ
- 第18章 ノーチェンジ・コンフィグ
- 第19章 塩漬けのバージョン
- 第20章 フレームワーク依存症
2. 本書のおすすめポイント
- RDSに関連するアンチパターンを学ぶことに重きを置いている。
- 「はじめに」ではアンチパターンを学ぶ意義についてこのように解説されています。
データベースは長く付き合っていかねばならない相手であり、開発者はその特性ゆえの問題にぶつかることがあります。そういった、開発の現場で実際に起こっている、発生しやすいリレーショナルデータベース(RDB)全般の問題をアンチパターンとして紹介していきます。
- 各章ごとに、構成が同じでテンポよく読みやすい。
- 起きがちなアンチパターンの紹介
- 取り上げられたアンチパターンの問題点と再発防止策を解説
- 章末にて、アンチパターンのポイントが解説されている。
これにより、読み返す際、あるいは読み始める前に自分のなかにインデックスを設けることができた。
3. 読んだ感想
- トレードオフの関係となっている手段が多く、一様にポリシーを決めて対処できるものではない。
- Amazon RDSなどマネージドサービスを使った場合、本書で取り上げられているアンチパターンはどこまで未然に防ぐことが出来るのか、また別のアンチパターンが生まれるのか気になった。
- そのような資料などをご存知の方がいらっしゃれば、コメントにてご連絡いただけるとうれしいです。
4. 章ごとに気になったこと
「第2章 失われた事実」より
- ステータスの遷移など時系列で情報を追いたい場合、その情報を上書きすることは望ましくない。
- 情報を追うことを優先しすぎると、レコードの保存量は増え、ひいてはテーブルサイズの肥大化を招く。
履歴の保存とパフォーマンスの向上はトレードオフの関係。
「第3章 やり過ぎたJOIN」より
- MYSQLとPostgresqlとでサポートしているjsonのアルゴリズムが異なるので注意。
- JSONのアルゴリズムに注意して実装する以外の方法として、そもそも別テーブルに分けることでシンプルに出来ないか考えることも。
「第4章 効かないINDEX」より
- INDEXが有効的に活用されているか
- 本問題に関連するアンチパターンとして、『SQLアンチパターン』で取り上げられている
「インデックスショットガン」も紹介 - 本問題と「インデックスショットガン」いずれも
MENTORの原則と呼ばれる対策が有効- Measure(測定)
- Explain(解析)
- Nominate(指名)
- Test(テスト)
- Optimize(最適化)
- Rebuild(再構築)
「第5章 フラグの闇」より
- 基本的にテーブルには状態を持たせることは避けたい。
- 削除済データが増えるとパフォーマンスが低下する。
- 削除フラグを利用したくなるケースとして、
削除したデータを検索したいなどいくつか紹介しているるが、できるだけテーブルに状態を持たせないことを推奨。
「第6章 ソートの依存」より
- ORDER BY区狙い v.s. WHERE句狙い
-
WHERE句がINDEXを活用でき、データを十分に小さく出来るか
-
- INDEXから高速にデータを取得する手段としてのORDER BY句は、Redisと似ている
- Redisはデータの永続化が苦手と棲み分けが必要。
「第7章 隠された状態」より
- 1つのデータに複数の属性を付与すると、コード上、実態が見えづらくなる。
- 交差テーブルが使えないか
「第8章 JSONの甘い罠」より
- JSONデータ型のメリットとデメリット
「第9章 強過ぎる制約」より
- 制約はRDBMSとアプリケーションのうち、どちらが担うか
- アプリケーションが担うメリットはデプロイも含めて変更が容易な点
「第10章 転んだ後のバックアップ」より
- バックアップとリストアは自動化出来ないか
- Amazon RDSはそれらのアウトソース先の候補
- リストアの定期化は、チーム全体でシステムへの理解を深めることに寄与
「第11章 見られないエラーログ」より
- ログの吐き出しすぎは、「見られなくなる」一因に
「第12章 監視されないデータベース」より
- ミドルウェアの監視項目として、以下の3つを紹介
- サービスの死活監視
- 特定条件のチェック監視
- 時系列データでのメトリックス監視
「第13章 知らないロック」より
- MYSQLとPostgresqlとでロックの仕様が異なる
「第14章 ロックの功罪」より
- 4つのトランザクション分離レベル
READ UNCOMMITTED(並列度が高い)- READ COMMITTED
- REPEATABLE READ
SERIALIZABLE(並列度が低い)
serializableは完全な直列処理になるためIsolationを担保していると言えますが、その分並列処理はできなくなります。逆に、read uncommittedはIsolationを犠牲にする代わりに並列度を高めています。
- 左記のトランザクション分離レベルと現象との関係性
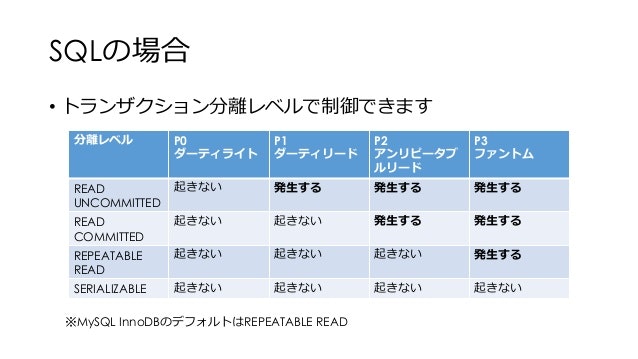
出所:こわくない同時実行制御
「第15章 簡単過ぎる不整合」より
- 外部キー制約のせいでデッドロックに悩まされても安易に非正規化にしない
- 非正規化の代替案
CHECK制約ENUM型
「第16章 キャッシュ中毒」より
- キャッシュを使うと以下の面倒なトラブルを招くことも。
- エラーの原因の切り分け
キャッシュはいつ、どのデータを参照したのかの特定が難しい
「第17章 複雑なクエリ」より
- 構文やサブクエリ、JOINなどを分け、不要なものがあれば排除
「第18章 ノーチェンジ・コンフィグ」より
- パフォーマンスが出ない原因は、
コンフィグがデフォルトのまま?
「第19章 塩漬けのバージョン」より
- マイナーバージョンアップをサボらず
「第20章 フレームワーク依存症」より
- ライブラリを選定する際、それがテーブルに悪影響を与えないか確認
- インプリシットカラム
- キーレスエントリー