前回までのおさらい
POG上達のためのデータ解析2 〜jupyter notebookで解析編〜では馬のプロフィールとPOG期間中の獲得賞金との間の因果関係を解析し、「牝馬が不利」、「早生まれほど有利」などのおおまかな傾向を把握することができた。
今回の目的
回帰分析による馬のプロフィールに基づいたPOG期間賞金予測の可能性を見極める。
データ解析
質的データの取り扱い
いまいちど解析対象であるデータの中身を見てみよう。

各馬のプロフィールに基づいて賞金額を予測したいので、目的変数は「POG期間賞金_通年」、説明変数は「性別」、「生まれ月」、「調教師」、「馬主」、「生産者」、「産地」、「セリ取引価格」、「父」、「母父」とするのが妥当であろう。ただし、「セリ取引価格」は前回の解析で有意な関係性が見いだせなかったため、今回は解析対象外とする。
ところで、説明変数のうち、「セリ取引価格」以外はいわゆる質的データである。したがって、このままでは回帰分析ができない。
このような場合、質的データをダミー変数に変換することで量的データとして扱えるようにしてから回帰分析を行うのが一般的なやり方*のようである。
*新商品のビタミン飲料はどれくらい売れるか予測する -ダミー変数を用いた回帰分析-
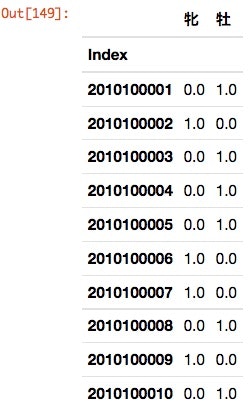
pandasには質的データをダミー変数に変換する関数が用意されている。
以下に一例を示す。
horse_df = pd.read_csv('./horse_db/horse_prof_2010_2014_mod.csv', encoding='utf-8', header=0, index_col=0)
pd.get_dummies(horse_df[u'性別'])[:3]
単回帰分析
今回の解析ではstatsmodelsモジュールのOLS(最小二乗法)を用いる。
解析に用いたコードを以下に示す。
# モジュールのインポート
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(font='Osaka')
import statsmodels.api as sm
import IPython.display as display
%matplotlib inline
# 解析元データ読み込み
horse_df = pd.read_csv('./horse_db/horse_prof_2010_2014_mod.csv', encoding='utf-8', header=0, index_col=0)
# horse_df = horse_df[:50]
# 質的データをダミー変数に変換
use_col = [
u'性別',
#u'生まれ月',
#u'調教師',
#u'馬主',
#u'生産者',
#u'産地',
#u'父',
#u'母父',
]
if len(use_col) == 1:
dum = pd.get_dummies(horse_df[use_col[0]])
else:
dum = pd.get_dummies(horse_df[use_col])
# X, yの定義
X_col = dum.columns
y_col = u'POG期間賞金_通年'
tmp_df = pd.concat([dum, horse_df[y_col]], axis=1)
tmp_df = tmp_df.dropna()
tmp_df = tmp_df.applymap(np.int)
X = tmp_df[X_col].ix[:,:]
X = sm.add_constant(X)
y = tmp_df[y_col]
# モデル生成
model = sm.OLS(y,X)
# 結果
results = model.fit()
y_predict = results.predict()
plt.plot(y_predict, y, marker='o', ls='None', label='_'.join(use_col))
plt.xlabel(u'予測')
plt.ylabel(u'実測')
plt.legend(loc=0)
plt.title('R^2: %.3f, F: %.3f' % (results.rsquared, results.fvalue))
plt.savefig('./figure/fig_'+'_'.join(use_col)+'.png')
# display.display(results.summary())
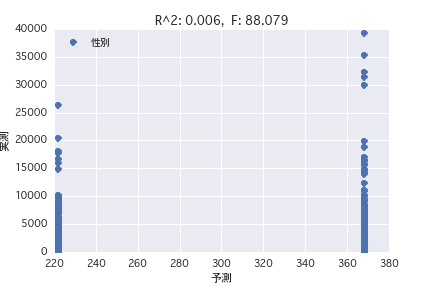
性別
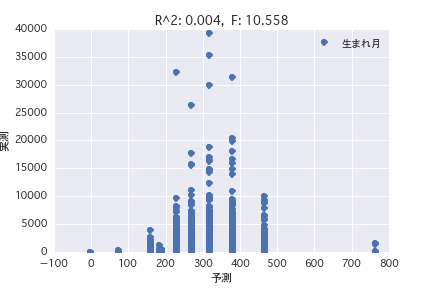
生まれ月
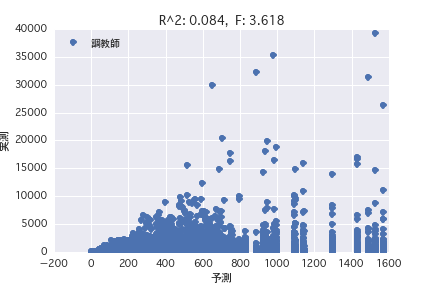
調教師
馬主
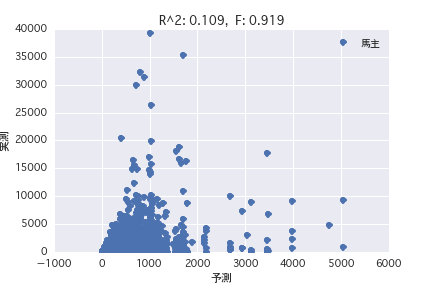
生産者
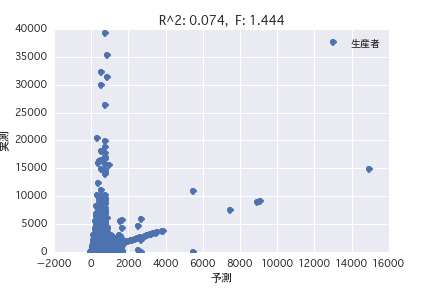
産地
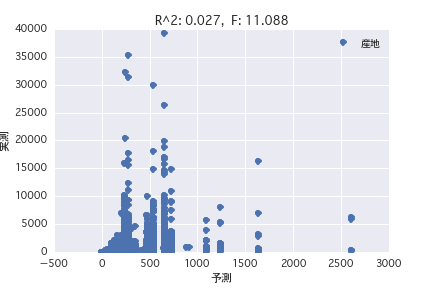
父
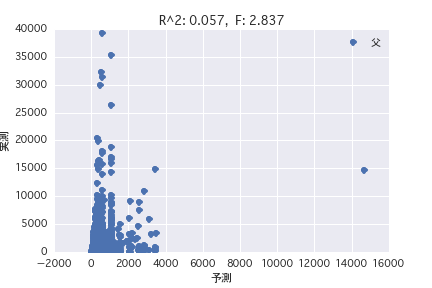
母父
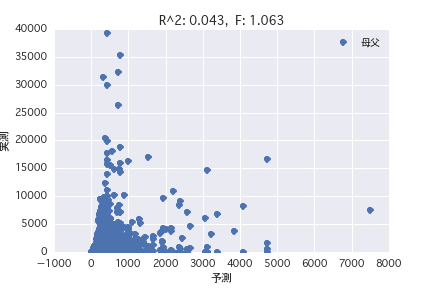
重回帰分析
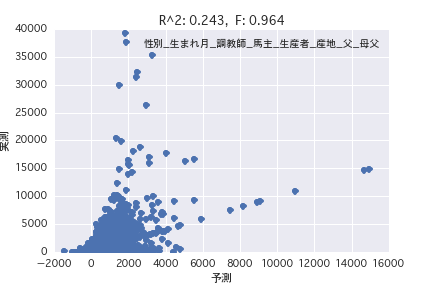
今回のまとめ
目的変数を「POG期間賞金_通年」、説明変数を馬のプロフィール各種(「性別」、「父」など)として回帰分析を行った。
単回帰分析、重回帰分析いずれもR^2が小さく、馬のプロフィールから賞金金額を予測することは難しいことがわかった。
今後
判別分析(未勝利、並のオープン馬、一流馬 の識別)
血統に着目した解析