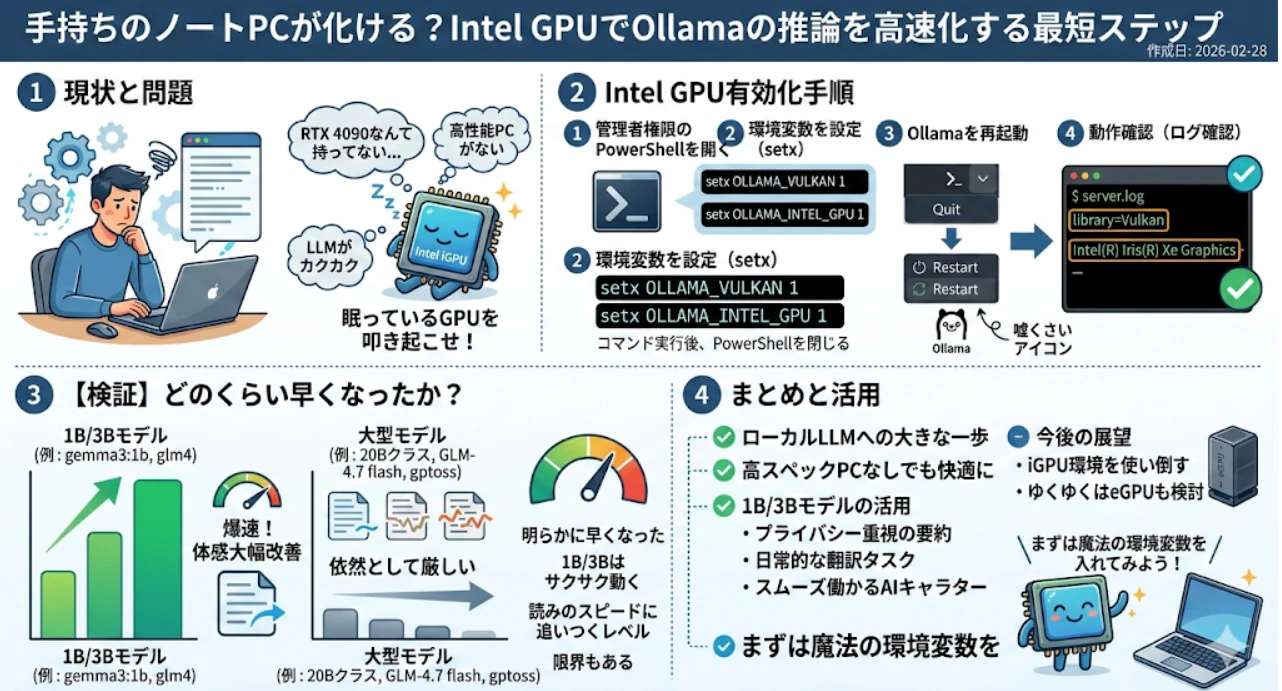
手持ちのノートPCが化ける?Intel GPUでOllamaの推論を高速化する最短ステップ
作成日: 2026-02-28
はじめに
ローカルLLMが盛り上がっている昨今。「RTX 4090なんて持ってないし...」と、手を出せずにいませんか? 私もその一人でした。
高性能PCがない環境では、LLMの応答が一行ずつ、忘れた頃にやってくる。そんな「カクカク」のストレスから解放されるために、ノートPCに眠っているIntel GPU(iGPU)を叩き起こす設定を試しました。この記事では、その手順と「どのくらい快適になったか」をまとめます。
ノートPCでIntel GPUを有効化する手順
前提として筆者のPCスペックを簡単にまとめます。
- iGPU搭載: Intel Iris Xe Graphics
- メモリ: 16GB
- CPU: 12スレッド
今回試したのは、OllamaのVulkan経由でIntel iGPUを使う方法です。ポイントは環境変数を有効化してOllamaを再起動し、ログで実際にGPUが使われていることを確認することでした。
-
ユーザー環境変数を設定
PowerShellを管理者権限で開き、以下のコマンドを実行します。
setx OLLAMA_VULKAN 1
setx OLLAMA_INTEL_GPU 1
※ setx コマンドを実行した後は、設定を反映させるためにPowerShellを一度閉じ、さらにタスクトレイにあるOllamaを完全に終了(Quit)させてから再起動してください。
-
動作確認
再起動後、Ollamaのserver.logを確認し、library=VulkanとIntel(R) Iris(R) Xe Graphics(またはお手持ちのGPU名)が出力されていることを確認します。
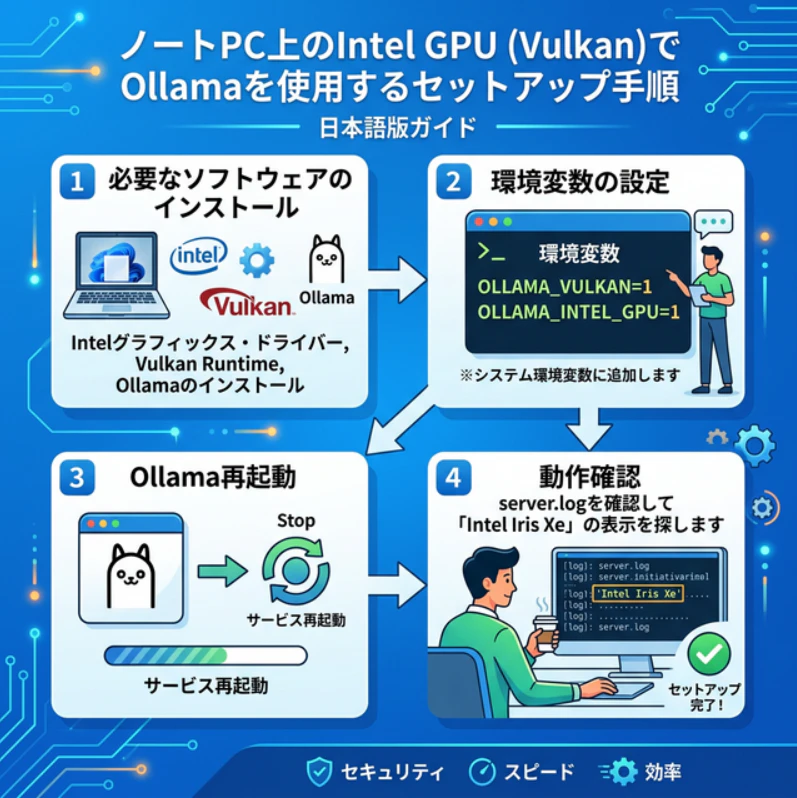
OllamaでIntel GPU(Vulkan)を有効化する流れ(環境変数設定→再起動→ログ確認)。余談ですがAIに作成させた画像なのでOllamaのアイコンがあり得ないくらい嘘くさくなっています。
【検証】どのくらい早くなったか?
設定前後で、推論速度(tokens per second)がどれだけ変化したかの実測値です。
(1回しか計測していないので悪しからず。。)
| モデル名 | 設定前 (CPUのみ) | 設定後 (Intel GPU) | 体感の差 |
|---|---|---|---|
| glm4 | 0.92 tok/s(45 tok / 49.15s) | 7.35 tok/s(45 tok / 1.20s) |
非常に大きい |
| gemma3:1b(825mb) | 55.58 tok/s(42 tok / 17.93s) | 118.03 tok/s(42 tok / 8.99s) | 大きい |
体感結果と限界
結果としては、明らかに早くなりました。1Bや3Bのモデルに関しては、読みのスピードに追いつくレベルで何のストレスもなく動きます。ノンストレスとまではいきませんがglm4もいい感じに動いてくれるようになったのは個人的には驚きでした。
ただし、依然として20Bクラスはまともに動かない場面が多いです。動かしたいモデルはいっぱいあるのに、GLM-4.7 flashやgptossのような重めの選択肢はノートPC単体では厳しい、というのが正直な感想です。
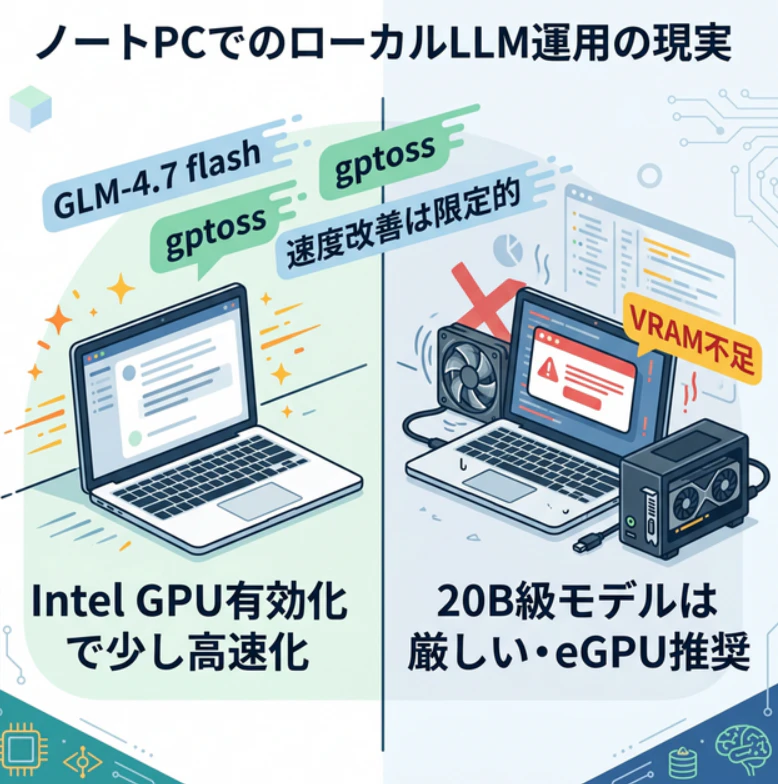
ノートPC単体運用の現実: 小幅改善はあるが、大型モデルには性能不足。
まとめ
ローカルLLMをガチってみたいけれど、高スペックPCはない。そんな方にとって、ノートPCでIntel GPUを有効化する方法は、試す価値のある「大きな一歩」になるはずです。
大型モデルには限界がありますが、1B/3Bモデルをローカルでサクサク動かせる環境は、プライバシー重視の要約や日常的な翻訳タスクに最適です。まずは手元のPCに「魔法の環境変数」を入れて、眠っているGPUを叩き起こしてあげましょう!
ゆくゆくはeGPU(外付けGPU)なども検討したいですが、まずはこの「iGPU環境」をどこまで使い倒せるか、さらに掘り下げていこうと思います。
記事のサマリ