0. 概要
NSSOLアドベントカレンダー7日目担当分です。
昨日は
初めてアジャイルをやってみたという記事でした。ぜひご覧ください。
今回は、一般人が分析するのは困難だろう「医療データ」を実際に触ってみて、医療データ分析に興味を持とう、という話です。
(2025/05/30追記)
事例調査を実施しました。
https://qiita.com/gg_hatano/items/4b36cd51b5064cbd0bb4
1. 背景:データ活用と安全管理の両立
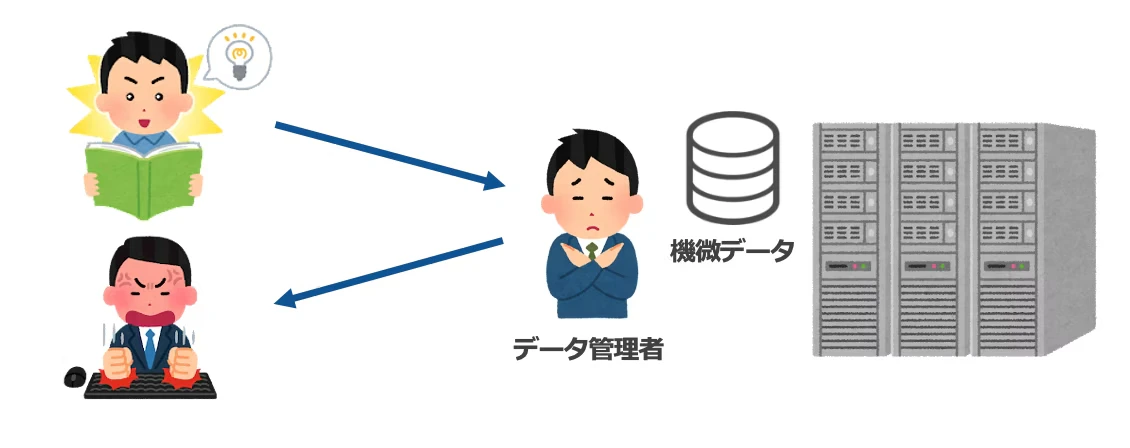
データ活用が当然になっている昨今、現場ではプライバシー保護とデータ活用の両立が課題になることがあります。
データ分析やシステム開発のために、実データかそれに近いデータが欲しくなることは多々あります。ただ、顧客情報や営業秘密といった機微な情報が含まれる場合、一般的には、当該データ取得までに様々な稟議・手続き等が必要になります。
「まずはデータを少し触ってみたい」「思いついたアイディアを検証したい」といったライトなニーズである場合、大きな負荷をかけて稟議や審査対応をする・してもらうのは、コスパが悪いです。結果、アイディア止まりになって立ち消えになってしまいます。
2. 合成データについて
2.1. 合成データとは
最近、合成データに注目が集まっています。合成データとは、元データの特徴を保存しつつ、実際の個人とは紐づかない、全く新しいデータを生成する技術です。
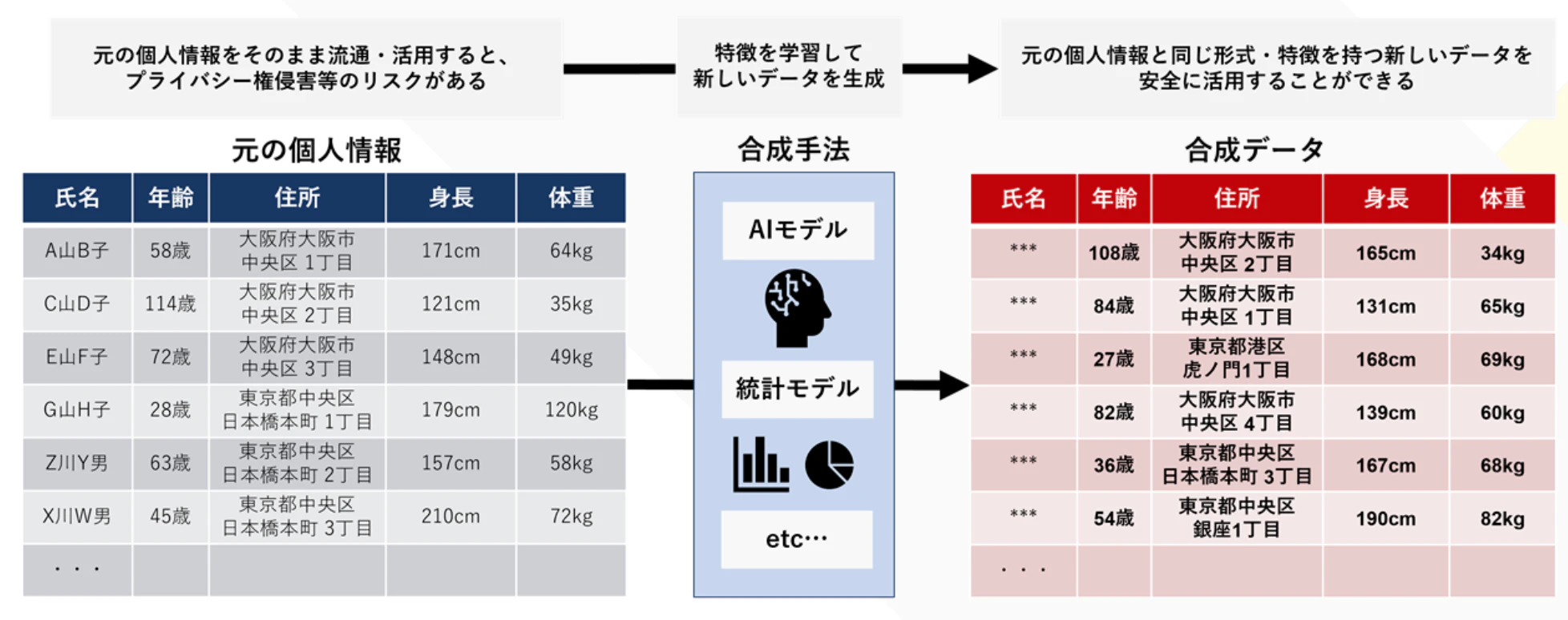
合成データの用途の例として、以下のようなものが挙げられます:
- データの特徴の把握: 実データを直接扱わずに、データ構造やデータの特徴を理解する
- プログラムの試作: 分析用プログラムやアプリケーションの開発初期段階で、テストデータとして使用する
もし、合成データの技術概要や法令等 について興味を持って頂けましたら、当社の技術動向記事をご覧ください。
本記事では、実際に合成データを使った様子をご紹介します。
2.2. 合成データの利用事例
海外では、事前検証用や機械学習に用いる安全なデータとして、合成データが作成・公開されている例があります。
-
N3C (National COVID Cohort Collaborative)
N3Cは、約800万件のCovid-19データを提供しています。合成データは一般人も利用できます。研究機関に所属している人であれば、De-identified データ:実データを加工したデータの研究利用もできそうです。 -
Simulacrum
Simulacrumは、イギリスで収集した臨床データの合成データセットを提供するサービスです。合成データの分析を通じて仮説を検証し、作成したプログラムや研究企画書を提出することで、研究用の実データを使用することができます -
その他
随時追記していきます
今回はSimulacrumから取得できる合成患者データを使ってみます。
3. Simulacrumを使ってみる
Simulacrumのデータは、元データから統計モデルを作成し、そこからサンプリングされて生成されています。そのため、ある程度の統計的性質が再現されています。詳細に興味がある方は、ホワイトペーパーを御覧ください。
3.1. データの準備
Simulacrumのデータセットは、公式サイトから簡単にダウンロードできます。
ライセンスはCC BY 4.0です。本記事の末尾に、ライセンス関連の記載を配置します。
3.2. データの概要把握
まずはデータの概要を把握します。データファイルはたくさんあります。全部で12種類のcsvデータがありました。眺めるだけでも大変なので、まずは1つに決めます。腫瘍のデータ:sim_av_tumour.csvに注目します。
# データの読み込み
file_path = '/content/drive/MyDrive/simulacrum_v2.1.0/Data/sim_av_tumour.csv'
data = pd.read_csv(file_path)
data.shape
## データ件数と列数:(1995570, 37)
len(data["PATIENTID"].unique())
## 患者数:1871605人
患者187万人、合計で200万件のデータです。列を絞ってデータを観察します。
data = data[['PATIENTID', 'DIAGNOSISDATEBEST', 'SITE_ICD10_O2_3CHAR']]
data.head()
| PATIENTID | DIAGNOSISDATEBEST | SITE_ICD10_O2_3CHAR |
|---|---|---|
| 10000001 | 2017-03-31 | C44 |
| 10000002 | 2016-01-14 | C44 |
| 10000003 | 2018-12-10 | C44 |
| 10000004 | 2018-04-05 | C44 |
| 10000005 | 2018-04-23 | C44 |
合成された患者IDと、診断日、腫瘍のコードが記載されています。
腫瘍のコードは、ICD-10という規格に基づいて振られています。どういうコードかは、後で調べます。
とりあえず、どんな腫瘍があると診断されたか、件数を確認してみます。
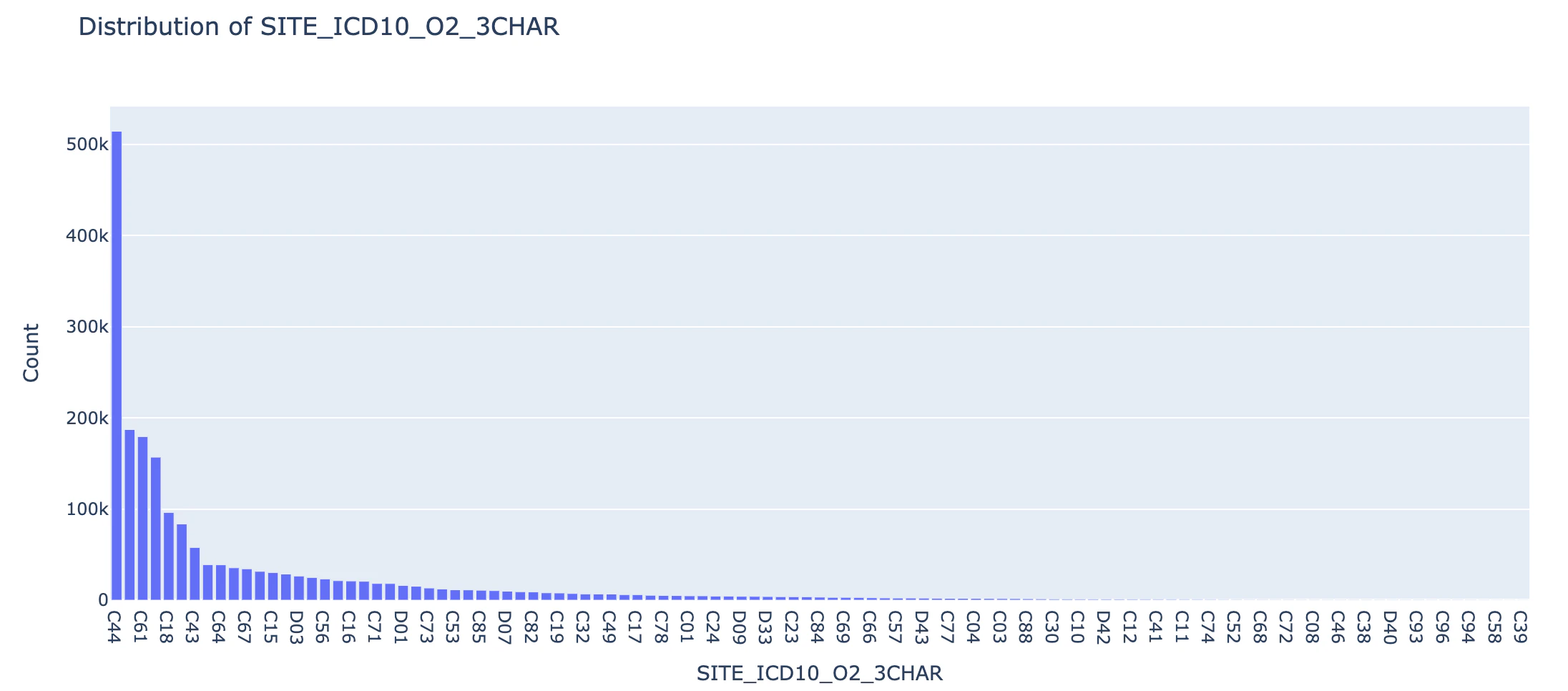
大半がC44で、ついでC61, C18が多いです。かなり偏ったデータに見えます。
各コードとその意味や現状の解釈について、整理します(ChatGPTに聞いてみます)。
| 項目 | C44: 皮膚のその他の悪性腫瘍 | C61: 前立腺の悪性腫瘍 | C18: 大腸の悪性腫瘍 |
|---|---|---|---|
| 分類名 | 皮膚のその他の悪性腫瘍 | 前立腺の悪性腫瘍 | 大腸の悪性腫瘍 |
| 説明 | メラノーマを除く皮膚がん。基底細胞がんや扁平上皮がんが含まれる。 | 男性生殖器の中で最も一般的ながん。高齢男性での発症率が高いが、進行が緩やかな場合が多い。 | 消化管における主要ながんで、結腸の部位によってさらに細分化される(例: C18.0〜C18.9)。 |
| 主な対象部位 | 顔、頭皮、首、体幹、四肢など、皮膚全般 | 前立腺(男性特有の器官) | 結腸(大腸の一部) |
| 件数が多い理由 | 世界で最も診断頻度が高いがんの一つであり、非メラノーマ性皮膚がんが特に多い。 | 高齢男性に多く、検診普及により診断率が上昇しているため。 | 男女問わず診断率が高いがんであり、特に高脂肪・低繊維の食生活がリスク要因として影響。 |
C44:皮膚のその他の悪性腫瘍は、世界的に診断頻度が高いみたいです。ここでヒストグラムを見ると、4位がC43になっています。これは悪性メラノーマ:皮膚の腫瘍でした(その他ではない方)。皮膚系の腫瘍は、診療の頻度が高いようです。
腫瘍の診断件数と言われると、当初はつい発症した件数、と思っていました。診断のハードルが低い腫瘍は発見されやすく、件数が伸びやすいのですね。なるほど。
3.3. 他テーブルとの結合
…皮膚がんが多いと言われても、正直、身の回りでは皮膚がんについてあまり聞かないな、と思いました。
データセットでは人種の偏りがある気がしたので、人種別の分析をしてみます。
同梱されていたデータ辞書ファイルを確認すると、別のテーブル:sim_av_patient.csvに人種(ETHNICITY)の列があったので、このテーブルを結合して集計してみます。一定件数(今回は10000件)以上のデータがある人種に絞って、人種別の腫瘍診断件数Top3を可視化してみました。

1行目は皮膚がんが多い人種で、グラフタイトルの人種を見ると、白人種系に見られる特徴のようです。
アジア系・黒人種系は、それぞれ違った傾向があるように見えます。
このデータで腫瘍の傾向を見る際には、人種別の分析が必要そうです。
3.4. 他の列・他のテーブルを利用した分析
- 診断日があるので、時系列や遷移について調査したくなりました
- ちょっとやってみましたが、大半を占める皮膚の腫瘍の扱いが手間でした
- 遺伝子や死因の情報を持つテーブルも合ったので結合して分析したくなりました
- 後で追記できたら追記します(Advent Calendarの担当日に間に合わなかった)
- 死因と診断に大きなギャップがある場合は、もしかしたら診断の頻度や機会が足りていないのかもしれません
4. まとめ
4.1. 感想や補足
- ① 感想:まずは1テーブルから触ってみて集計・可視化してみると、やりたいことや知りたいことが出てきて、ニーズ起点で学習・情報収集を進めることができました。業務でも医療データは触りますが、当然、自由には使えません。今回は楽しく探索できました。ICD-10の腫瘍コードも少し覚えました
- ② 感想:関連して、データやデータを使った業務改善のアイディア創出には、データを触ることが大事だと思います。安全・有用な合成データを作成して提供することで、データ活用を更に推し進めたり、データ活用への興味が高まったりするのではないか、と期待しています
- ③ 感想:プログラムの実装は、ChatGPT等に補助してもらえる時代になりました。ありがたいですね。思いついたことを自然言語で入力すれば、大体のプログラムは作ってもらえました
4.2. 今後の取組み
- 感想①に関連して、データディクショナリからダミーデータを作ってみる仕組みを作りたくなりましたので、エイヤッと試作してみました。以下のデモ動画では、試しに横浜市のデータカタログからから、項目名を取得して、検証用のダミーデータを作っています。自治体が提供するデータを活用するアイディア検討に使えるかもしれません
- ②に関連して、安全な合成データを作る技術やルールの確立が重要に思えます。そのために、情報処理学会下部組織のデータ合成技術評価委員会に参画しています。適切なデータ合成の技術の整理・普及に貢献していきたいです。頑張ります
- ③に関連して、...は特になにもないです。いい時代ですね
以上です。
明日は、@ksasaoさんの「スマートグラス関連のなにか」らしいです。楽しみですね。
こちらの記事です
https://qiita.com/ksasao/items/98e7afa226b915a4787b
5. おわりに: 注意事項
- 今回利用・表示したデータは合成データであり、実際の個人に紐づくものではありません。もし仮に診断日・診断された腫瘍が一致した個人がいたとしても、それは偶然の一致です。データ合成方法やその安全性に関する詳細は、Simulacrumのデータ合成方法に関して記載されたホワイトペーパーをご覧ください
- 本記事で表示した分析した結果はあくまでも合成データの分析結果であり、実データの結果とは異なる可能性があります
6. Simulacrumに関するライセンス表示
この資料は、Health Data Insight CiC によって作成された以下のデータを利用しています:
-
データ名:Simulacrum Dataset Version 2.1.0 (2016-2019)
-
著作権者:Health Data Insight CiC
-
ライセンス:Creative Commons Attribution 4.0 International (CC BY 4.0)
-
本資料でのデータの加工・改変の有無:有
- 加工・可視化の方法は全てColaboratoryに記載しています
-
こちらのページに従って、以下の記載をします
This report used artificial data from the Simulacrum, a synthetic dataset developed by Health Data Insight CiC and derived from anonymous cancer data provided by the National Disease Registration Service, NHS England.
和訳:このレポートは、Health Data Insight CiCによって開発され、英国国民疾病登録サービス(NHS England)から提供された匿名のがんデータを基に作成された合成データセット「Simulacrum」の合成データを使用しました。