概要
私は株式会社ZUUで、主にバックエンドの開発を担当しており、フロントエンド、インフラに関する業務も担当しています。
今回取り上げる内容は、SQLの書き方一つでパフォーマンスがどれだけ改善できるかを、実例をもとに記述していきます。
シナリオ
使用しているDBMSはPostgreSQL12です。
話を単純化するために単純な例で説明します。今回は投稿記事を管理するケースを想定します。投稿される記事には複数の画像が載っており、全ての画像がアップロード完了していれば記事として有効なものと考えます。
テーブルはarticles, imagesを用意します。
実際にデータを入れてみるとこんな感じ。
articles
| id | title | published_at |
|---|---|---|
| 1 | 物価上昇はいつまで続くのか | 2022-08-01 10:00:00 |
| 2 | クーラーの適切な使い方 | 2022-08-10 13:00:00 |
| 3 | 熱戦続く甲子園 | 2022-08-15 16:00:00 |
images
| id | article_id | filename | status |
|---|---|---|---|
| 1 | 1 | breads.jpg | uploaded |
| 2 | 1 | vegetables.jpg | uploaded |
| 3 | 1 | udon.jpg | upload_failed |
| 4 | 2 | airconditioner.jpg | uploaded |
| 5 | 2 | kakigori.jpg | uploaded |
| 6 | 3 | koshien.jpg | waiting |
この例だと、全ての画像がアップロード完了している、つまり記事として有効なものは記事2の「クーラーの適切な使い方」という記事になります。では記事2だけをどうやって取得するか考えてみましょう。
SQL
改善前
改善前のSQLはこちら。全て"uploaded"の記事idを取得してきて、その記事idに含まれる記事を取得してくるようなSQLです。
SELECT * FROM articles
WHERE id IN (
SELECT article_id FROM images
GROUP BY article_id
HAVING (EVERY(status = 'uploaded'))
);
改善後
上記のSQLを以下のように修正しました。改善後のSQLでは、GROUP BYもHAVINGも使用せずに済むし、WHERE INも使用しないのでコストを大幅に削減することができる。
SELECT * FROM articles AS a
WHERE (
SELECT COUNT(i.id) FROM images AS i
WHERE i.article_id = a.id
AND i.status != 'uploaded'
) = 0;
追記(2022/09/08)
当記事を投稿した際には、「WHERE-INをやめたから処理が速くなった」という内容でした。しかし、何人かの方に「理由はWHERE-INではないのでは?」とコメントをいただきました。その後検証したところ、ご指摘の通り根本理由はWHERE-INではないことがわかりました。
問題は対象を絞り切れていないままWHERE-INを使用していたことでした。実際のデータではほとんどのデータでstatus='uploaded'だったので、WHERE id IN (数十万データ)を実施していることになっていました。
ここで発想の転換をして条件をstatus='uploaded'でなくstatus!='uploaded'を使用した次のSQLを使ってみました。
SELECT * FROM articles
WHERE id NOT IN (
SELECT article_id FROM images
WHERE status != 'uploaded'
);
こちらのSQLでも「改善後」に記載したSQLと同等の結果を得ることができました。
今回はいただいたコメントをもとに色々勉強させていただきました。コメントをくださったみなさま、ほんとうにありがとうございました!!
EXPLAIN ANALYZE
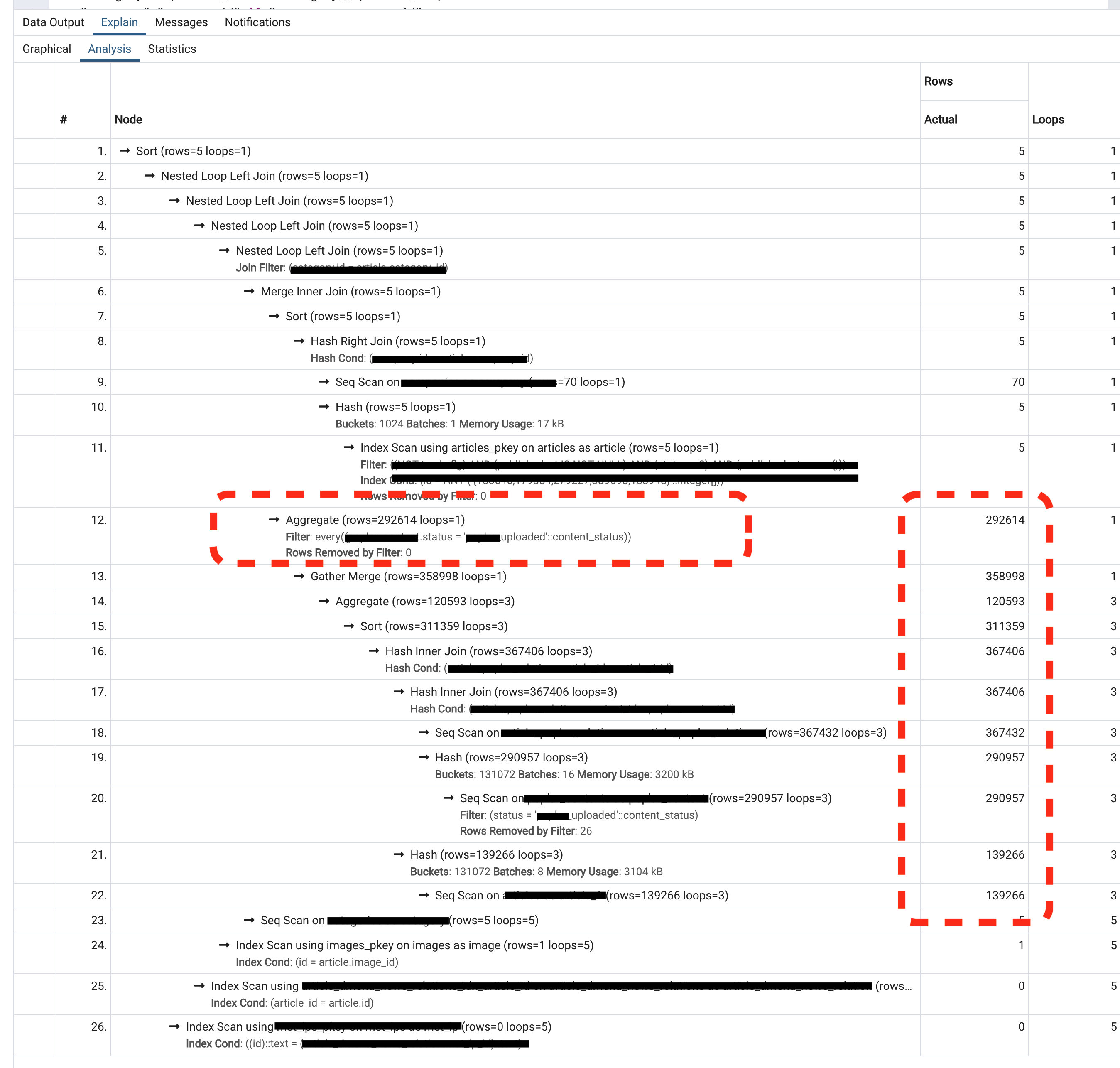
次に、改善前後でのEXPLAIN ANALYZEの結果をみてみましょう。ここで示す内容は説明のために用意した上記のシンプルなシナリオではなく、実際に運用されているデータに適用した結果です。複数のテーブルが関連し合う割と複雑なケースで、articlesは数十万レコードです(実際のデータに適用したものですので、一部隠蔽させていただきます)。
該当のWHERE部分(赤く囲った部分)での大幅な改善が見られます。
改善前
改善後

処理時間の比較
適用前後の実際のSQL処理時間を実際に計測してみました。処理時間を約97.8%削減することができました。
| 測定 | Before[ms] | After[ms] |
|---|---|---|
| 1回目 | 9,953 | 295 |
| 2回目 | 9,777 | 281 |
| 3回目 | 9,248 | 282 |
| 4回目 | 11,035 | 260 |
| 5回目 | 10,814 | 303 |
| 平均 | 10,165.4 | 284.2 |
DBのCPU負荷への効果
次にDBのCPU負荷を取得してみました。適用前後のある1日の負荷を比較しています。値は5分平均値です。
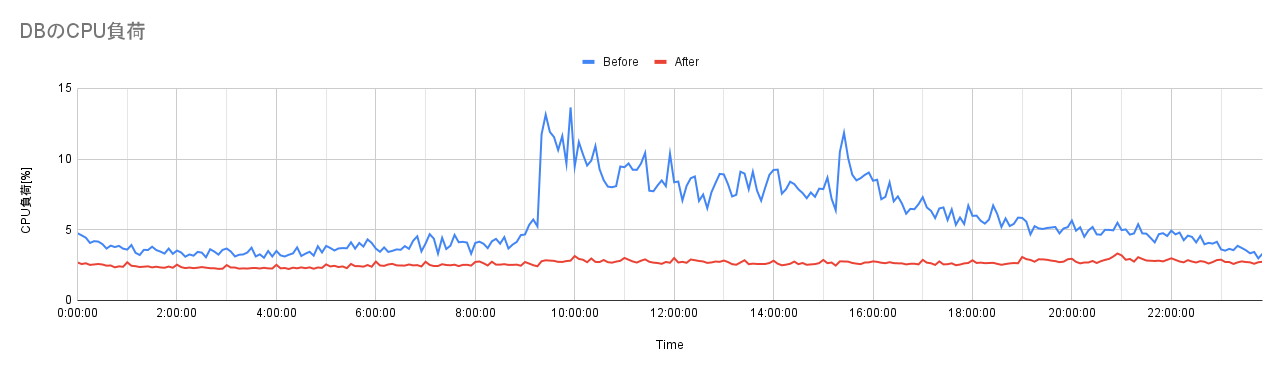
だいたい午前9時過ぎ頃に訪問ユーザ数が1日のピークを迎えて夕方から夜にかけて徐々にユーザ数が減っていきます。
適用前(Before)のCPU負荷もその訪問ユーザ数の変化に追従していることがわかります。一方、適用後(After)の負荷を見ると安定して低い水準を保っていますし、適用前の深夜帯よりも負荷が小さいことがわかります。
99パーセンタイル値比較で負荷を約71%削減できました。
当該SQLを使用したAPIレイテンシの変化
該当SQLを使用したAPIのレイテンシの変化を見てみます。2秒以上要したリクエストのカウントをヒストグラムで表しています。

9時ごろから訪問ユーザ数が増えていきます。そしてこの日の午後2時に改善後のSQLをデプロイしました。その効果は歴然です。適用前のある1日と適用後のある1日でカウント数を比較してみたところ、その数を約96%削減することができました。
まとめ
今回実施したSQLの改善内容はそんなに大きいものではありませんでしたが、ここまで大きい効果を得ることができました。これによってクラウドのリソースも減らすことができ、数十万円単位のコストカットも実現できるようになります(今月適用したので実際のコストカット額は分かりませんが、次回の請求額が楽しみです)。
SQLによるパフォーマンスへの影響を把握できるのはエンジニアだけだと思います。今回はサービスを運用する運用チームに対してエンジニアチームから課題をボトムアップし、それを改善してユーザへのレスポンスタイムを向上させ経費削減にも寄与でき、しっかりと事業にコミットできたということは大きいと思っています。エンジニアとして大きな喜びを感じた瞬間でもありました。
補足
今回はcount == 0を使ったWHERE句の事例を取り上げましたが、実はNOT EXISTを使った以下のSQLの方がパフォーマンスが向上する場合があります。
SELECT * FROM articles AS a
WHERE NOT EXISTS (
SELECT i.id FROM images AS i
WHERE i.article_id = a.id
AND i.status != 'uploaded'
);
count == 0では全てのレコードを取得する必要がありますが、一方NOT EXISTを使うと1つでもレコードが見つかるとそこで判定は終了するので全てのデータを参照する必要がありません。