はじめに
ディープラーニングを用いた画像処理タスクの一つに、セグメンテーションが存在します。
セグメンテーションは画像をピクセルごとにクラス分類することで、画像中のオブジェクトを分割します。
従来のセグメンテーションモデル(U-Netなど)はCNN(Convolutional Neural Network)を使用したものが殆どでした。
近年、NLP(自然言語処理)でRNN(Recurrent neural network)、CNNと並ぶ重要なニューラルネットワークの仕組みとしてAttention機構が注目されています。
Attention機構とは、入力データのどこに注目するべきか学習することのできる機構になります。
従来、アテンション機構はRNNやCNNなどと組み合わせて実装されることが専らでしたが、
「Attention Is All You Need」にてアテンション機構のみを用いたNLPモデル「Transformer」が登場しました。
Transformerの登場直後はNLPにおける応用が多かったですが、近年ではNLP以外のタスクにも取り入れられています。
今回実装する「SegFormer」は「Transformer」をセグメンテーションに応用したモデルとなります。
SegFormerには異なるサイズのモデル(B0~B5)がデザインされていますが、今回は最も軽量高速なB0をPytorchで実装を行い、記事として残します。
SegFormerとは
【原著論文】SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers
SegFormerは以下のようなエンコーダ/デコーダ構造のモデルです。
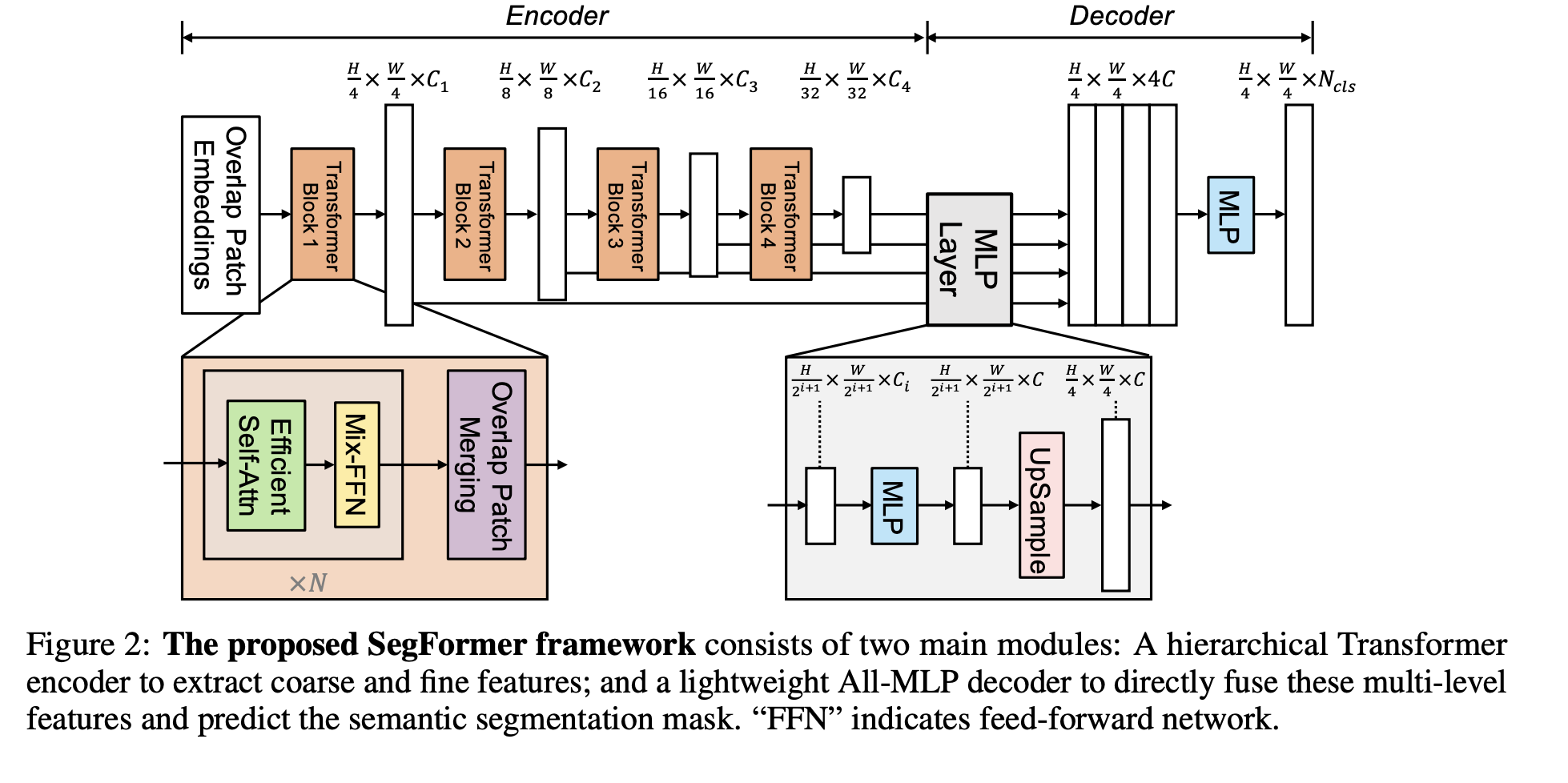
(原著論文より)
エンコーダは以下のような構造になっています。
1.【Overlap Patch Embedding】画像の埋め込みを行います。埋め込み自体は畳み込み層を使用しますが、この時カーネルサイズ、ストライド、パディングサイズを調整して、フィルターごとに一部が被るように畳み込みを行います。
2.【Efficient Self Attention】基本的な構造はTransformerのSelf Attentionと変わりませんが、KeyとValueのシーケンス長(高さ×幅)を削減します。以下のように、シーケンス長を1/Rに削減します。(RはReduction ratioと呼ばれており、整数となります。)
\hat{K} = Reshape(\frac{N}{R}, C\times R)(K)\\
K = Linear(C\times R, C)(\hat{K})
論文中では記載がありませんが、Pytorchの公式実装ではEfficient Self Attention+残差接続で実装されています。
3.【Mix FFN】全結合層です。論文中では残差接続も加えて以下の式で実装しています。
x_{out} = MLP(GELU(Conv_{3×3}(MLP(x_{in})))) + x_{in}
4.2.~3.をn回繰り返す。nの回数はモデルの大きさ(B0~B5)と何層目のTransform Blockかにより異なります。
5.1.~4.を4回繰り返す。 Overlap Patch EmbeddingとOverlap Patch Mergingの内容は同じです。1層目のみOverlap Patch Embeddingが最初に処理され(Overlap Patch Mergingは省略する)、2層目以降はMix FFNの後にOverlap Patch Mergingが処理されます。
デコーダは以下のような構造になっています。
各解像度の特徴マップから確率マップを生成して合一します。方法は以下の通りです。
1.全結合層で各層出力データのチャンネル数をC(本実装では256)に増やす。
2.高さ、幅が元データの1/4になるようにアップサンプリングを行う。
3.各層のデータを結合し、全結合層でチャンネル数をCに削減する。
4.全結合層でチャンネル数をクラス数に削減し、確率マップを出力する。
\hat{F_{i}} = Linear(C_{i}, C)(F_{i}), ∀i\\
\hat{F_{i}} = Upsample(\frac{W}{4}\times \frac{W}{4})(\hat{F_{i}}), ∀i\\
F = Linear(4C, C)(Concat(\hat{F_{i}})), ∀i\\
M = Linear(C, N_{cls})(F)
異なる大きさのモデル(B0~B5)におけるパラメータは以下の通りです。
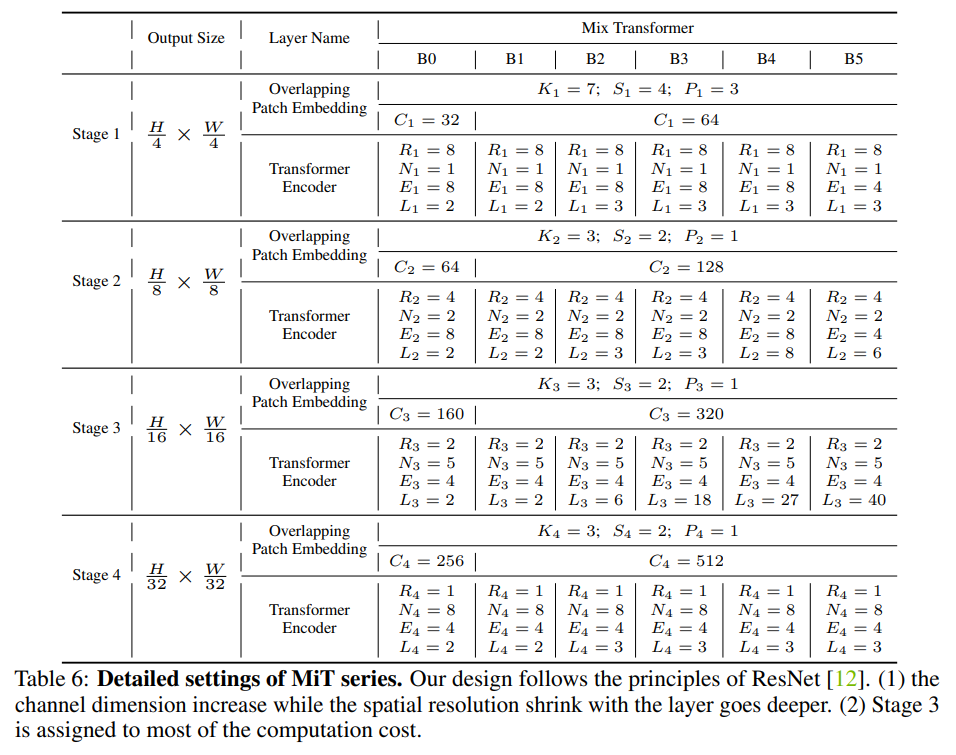
(原著論文より)
- S:Overlap Patch Mergingにおけるストライド
- P:Overlap Patch Mergingにおけるパディングサイズ
- C:チャンネル数
- L:Efficient Self AttentionとMix FFNを何回繰り返すか
- R:Efficient Self AttentionにおけるReduction ratio(削減比率)
- N:Efficient Self Attentionにおけるhead数
- E:Mix FFNにおけるExpansion ratio
データセット
データセットとして、Kaggleの「UW-Madison GI Tract Image Segmentation」を使用しました。本コンペティションはMRIの画像から小腸・大腸・胃の領域を予測し、その精度を競うものです。
環境
- Google Colaboratory Pro
コード
モジュールのimport
!pip install einops
!pip install -U segmentation-models-pytorch
import torch
from torch import nn
from einops import rearrange
import pandas as pd
import cv2
from PIL import Image
from matplotlib import pyplot as plt
import numpy as np
from torch.utils.data import DataLoader
from torch.utils.data import Dataset as BaseDataset
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import transforms
from torchvision.transforms import functional
import segmentation_models_pytorch as smp
import albumentations as A
データセットの作成
データのダウンロード・前処理は省略します。データセットのtrain.csvにラベル情報が含まれており、これをpngファイルとして保存します。
学習用の画像のパスとラベルのpngファイルのパスが分かるように以下のようなデータフレームを作成しました。
train_df = pd.read_csv("/content/drive/MyDrive/uw-madison/train_df.csv")
val_df = pd.read_csv("/content/drive/MyDrive/uw-madison/val_df.csv")
test_df = pd.read_csv("/content/drive/MyDrive/uw-madison/test_df.csv")
train_df
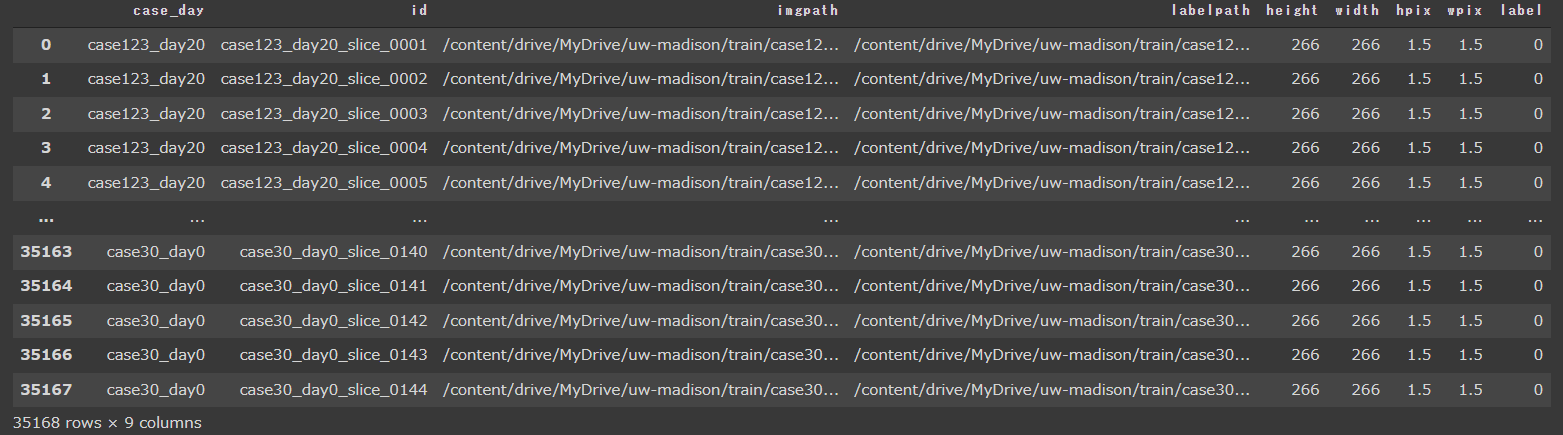
本データセットはラベル有りと無しがほぼ1:1になっています。全てのデータを使用するとうまく学習が進まなかっため、ラベルありのデータのみで学習を行いました。
train_df = train_df[train_df.label == 1].reset_index(drop=True)
val_df = val_df[val_df.label == 1].reset_index(drop=True)
test_df = test_df[test_df.label == 1].reset_index(drop=True)
データローダーを作成します。データ拡張の有無で2種類のデータローダーを組んでいます。
class train_Dataset(BaseDataset):
def __init__(
self,
df,
transform = None,
classes = None,
augmentation = None
):
self.imgpath_list = df.imgpath
self.labelpath_list = df.labelpath
self.transform = transforms = A.Compose([
A.HorizontalFlip(p=0.5),
A.ShiftScaleRotate(shift_limit=0.0625, scale_limit=0.05, rotate_limit=10, p=0.5),
A.OneOf([
A.GridDistortion(num_steps=5, distort_limit=0.05, p=1.0),
A.ElasticTransform(alpha=1, sigma=50, alpha_affine=50, p=1.0)
], p=0.25),], p=1.0)
def __getitem__(self, i):
imgpath = self.imgpath_list[i]
img = cv2.imread(imgpath)
img = cv2.resize(img, dsize = (256, 256))
labelpath = self.labelpath_list[i]
label = Image.open(labelpath)
label = np.asarray(label)
label = cv2.resize(label, dsize = (256//4, 256//4))
transformed = self.transform(image = img, mask = label)
img = transformed["image"]
label = transformed["mask"]
img = img/255
img = torch.from_numpy(img.astype(np.float32)).clone()
img = img.permute(2, 0, 1)
label = torch.from_numpy(label.astype(np.float32)).clone()
label = torch.nn.functional.one_hot(label.long(), num_classes=4)
label = label.to(torch.float32)
label = label.permute(2, 0, 1)
data = {"img": img, "label": label}
return data
def __len__(self):
return len(self.imgpath_list)
class valtest_Dataset(BaseDataset):
def __init__(
self,
df,
transform = None,
classes = None,
augmentation = None
):
self.imgpath_list = df.imgpath
self.labelpath_list = df.labelpath
def __getitem__(self, i):
imgpath = self.imgpath_list[i]
img = cv2.imread(imgpath)
img = cv2.resize(img, dsize = (256, 256))
img = img/255
img = torch.from_numpy(img.astype(np.float32)).clone()
img = img.permute(2, 0, 1)
labelpath = self.labelpath_list[i]
label = Image.open(labelpath)
label = np.asarray(label)
label = cv2.resize(label, dsize = (256//4, 256//4))
label = torch.from_numpy(label.astype(np.float32)).clone()
label = torch.nn.functional.one_hot(label.long(), num_classes=4)
label = label.to(torch.float32)
label = label.permute(2, 0, 1)
data = {"img": img, "label": label}
return data
def __len__(self):
return len(self.imgpath_list)
BATCH_SIZE = 8
train_dataset = train_Dataset(train_df)
train_loader = DataLoader(train_dataset,
batch_size=BATCH_SIZE,
num_workers=4,
shuffle=True,
drop_last=True)
val_dataset = valtest_Dataset(val_df)
val_loader = DataLoader(val_dataset,
batch_size=BATCH_SIZE,
num_workers=4,
shuffle=True,
drop_last=True)
test_dataset = valtest_Dataset(test_df)
test_loader = DataLoader(test_dataset,
batch_size=1,
num_workers=4,
drop_last=True)
Segformerの実装
class LayerNorm2d(nn.Module):
def __init__(self,
channels
):
super().__init__()
self.ln = nn.LayerNorm(channels)
def forward(self, x):
x = rearrange(x, "a b c d -> a c d b")
x = self.ln(x)
x = rearrange(x, "a c d b -> a b c d")
return x
class OverlappatchMerging(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride):
super().__init__()
self.conv = nn.Conv2d(in_channels = in_channels,
out_channels = out_channels,
kernel_size = kernel_size,
stride = stride,
padding = kernel_size // 2)
self.ln = LayerNorm2d(out_channels)
def forward(self, x):
x = self.conv(x)
x = self.ln(x)
return x
class MultiHeadAttention(nn.Module):
def __init__(self, channels, dim, head_num, reduction_ratio, dropout = 0.1):
super().__init__()
self.dim = dim
self.head_num = head_num
self.r = reduction_ratio
self.ln1 = LayerNorm2d(channels)
self.ln2 = nn.LayerNorm(channels)
self.linear_reduceK = nn.Linear(channels * reduction_ratio, channels, bias = False)
self.linear_reduceV = nn.Linear(channels * reduction_ratio, channels, bias = False)
self.linear_Q = nn.Linear(dim, dim, bias = False)
self.linear_K = nn.Linear(dim // reduction_ratio, dim // reduction_ratio, bias = False)
self.linear_V = nn.Linear(dim // reduction_ratio, dim // reduction_ratio, bias = False)
self.linear = nn.Linear(dim, dim, bias = False)
self.soft = nn.Softmax(dim = 3)
self.dropout = nn.Dropout(dropout)
def split_head(self, x):
x = torch.tensor_split(x, self.head_num, dim = 2)
x = torch.stack(x, dim = 1)
return x
def concat_head(self, x):
x = torch.tensor_split(x, x.size()[1], dim = 1)
x = torch.concat(x, dim = 3).squeeze(dim = 1)
return x
def forward(self, x):
_x = x
x = self.ln1(x)
x = rearrange(x, "a b c d -> a (c d) b")
Q = K = V = x
K = rearrange(K, "a (cd r) b -> a cd (b r)", r = self.r)
V = rearrange(V, "a (cd r) b -> a cd (b r)", r = self.r)
K = self.linear_reduceK(K)
K = self.ln2(K)
V = self.linear_reduceV(V)
V = self.ln2(V)
Q = rearrange(Q, "a cd br -> a br cd")
K = rearrange(K, "a cd br -> a br cd")
V = rearrange(V, "a cd br -> a br cd")
Q = self.linear_Q(Q)
K = self.linear_K(K)
V = self.linear_V(V)
Q = self.split_head(Q)
K = self.split_head(K)
V = self.split_head(V)
Q = rearrange(Q, "a h br cd -> a h cd br")
K = rearrange(K, "a h br cd -> a h cd br")
V = rearrange(V, "a h br cd -> a h cd br")
QK = torch.matmul(Q, torch.transpose(K, 3, 2))
QK = QK/((self.dim//self.head_num)**0.5)
softmax_QK = self.soft(QK)
softmax_QK = self.dropout(softmax_QK)
QKV = torch.matmul(softmax_QK, V)
QKV = rearrange(QKV, "a h br cd -> a h cd br")
QKV = self.concat_head(QKV)
QKV = self.linear(QKV)
QKV = rearrange(QKV, "a b (c d) -> a b c d", c = int(self.dim**0.5))
QKV = QKV + _x
return QKV
class MixFFN(nn.Module):
def __init__(self, in_channels, expantion_ratio):
super().__init__()
self.ln = LayerNorm2d(in_channels)
self.linear1 = nn.Conv2d(in_channels, in_channels, kernel_size = 1)
self.linear2 = nn.Conv2d(in_channels * expantion_ratio, in_channels, kernel_size = 1)
self.conv = nn.Conv2d(in_channels, in_channels * expantion_ratio, kernel_size = 3, padding = "same")
self.bn = nn.BatchNorm2d(in_channels * expantion_ratio)
self.gelu = nn.GELU()
def forward(self, x):
_x = x
x = self.ln(x)
x = self.linear1(x)
x = self.conv(x)
x = self.gelu(x)
x = self.bn(x)
x = self.linear2(x)
x = x + _x
return x
class EncoderBlock1(nn.Module):
def __init__(self,
in_channels,
out_channels,
kernel_size,
stride,
input_dim,
head_num,
reduction_ratio,
expantion_ratio,
enclayer_num):
super().__init__()
self.layer_num = enclayer_num
self.OLM = OverlappatchMerging(in_channels, out_channels, kernel_size, stride)
self.Enclayer = nn.ModuleList([nn.Sequential(
MultiHeadAttention(out_channels, input_dim, head_num, reduction_ratio = 8),
MixFFN(out_channels, expantion_ratio)
)
for _ in range(enclayer_num)])
def forward(self, x):
x = self.OLM(x)
for i in range(self.layer_num):
x = self.Enclayer[i](x)
return x
class EncoderBlock(nn.Module):
def __init__(self,
in_channels,
out_channels,
kernel_size,
stride,
input_dim,
head_num,
reduction_ratio,
expantion_ratio,
enclayer_num):
super().__init__()
self.layer_num = enclayer_num
self.Enclayer = nn.ModuleList([nn.Sequential(
MultiHeadAttention(in_channels,input_dim,head_num, reduction_ratio = 8),
MixFFN(in_channels = in_channels, expantion_ratio = expantion_ratio)
)
for _ in range(enclayer_num)])
self.OLM = OverlappatchMerging(in_channels, out_channels, kernel_size, stride)
def forward(self, x):
for i in range(self.layer_num):
x = self.Enclayer[i](x)
x = self.OLM(x)
return x
class AllMLPDecoder(nn.Module):
def __init__(self, l1_channels, l2_channels, l3_channels, l4_channels, class_num):
super().__init__()
self.declayer1 = nn.Sequential(
nn.Conv2d(l1_channels, 256, kernel_size = 1),
nn.Upsample(scale_factor=1, mode="bilinear", align_corners=True)
)
self.declayer2 = nn.Sequential(
nn.Conv2d(l2_channels, 256, kernel_size = 1),
nn.Upsample(scale_factor=2, mode="bilinear", align_corners=True)
)
self.declayer3 = nn.Sequential(
nn.Conv2d(l3_channels, 256, kernel_size = 1),
nn.Upsample(scale_factor=4, mode="bilinear", align_corners=True)
)
self.declayer4 = nn.Sequential(
nn.Conv2d(l4_channels, 256, kernel_size = 1),
nn.Upsample(scale_factor=8, mode="bilinear", align_corners=True)
)
self.linear1 = nn.Conv2d(256 * 4, 256, kernel_size = 1)
self.linear2 = nn.Conv2d(256, class_num, kernel_size = 1)
self.relu = nn.ReLU()
self.bn = nn.BatchNorm2d(256)
def forward(self, x1, x2, x3, x4):
x1 = self.declayer1(x1)
x2 = self.declayer2(x2)
x3 = self.declayer3(x3)
x4 = self.declayer4(x4)
x = torch.concat([x1, x2, x3, x4], dim = 1)
x = self.linear1(x)
x = self.relu(x)
x = self.bn(x)
x = self.linear2(x)
return x
class SegFormer(nn.Module):
def __init__(self, input_height, class_num):
super().__init__()
self.EncBlock1 = EncoderBlock1(in_channels = 3,
out_channels = 32,
kernel_size = 7,
stride = 4,
input_dim = (input_height//4)**2,
head_num = 1,
reduction_ratio = 4, ##本来8ですがメモリに余裕があるので4に
expantion_ratio = 4,
enclayer_num = 2)
self.EncBlock2 = EncoderBlock(in_channels = 32,
out_channels = 64,
kernel_size = 3,
stride = 2,
input_dim = (input_height//4)**2,
head_num = 2,
reduction_ratio = 2, ##本来4ですがメモリに余裕があるので2に
expantion_ratio = 8,
enclayer_num = 2)
self.EncBlock3 = EncoderBlock(in_channels = 64,
out_channels = 160,
kernel_size = 3,
stride = 2,
input_dim = (input_height//8)**2,
head_num = 4,
reduction_ratio = 1, ##本来2ですがメモリに余裕があるので1に
expantion_ratio = 4,
enclayer_num = 2)
self.EncBlock4 = EncoderBlock(in_channels = 160,
out_channels = 256,
kernel_size = 3,
stride = 2,
input_dim = (input_height//16)**2,
head_num = 8,
reduction_ratio = 1,
expantion_ratio = 4,
enclayer_num = 2)
self.Dec = AllMLPDecoder(32, 64, 160, 256, class_num = class_num)
def forward(self, x):
x1 = self.EncBlock1(x)
x2 = self.EncBlock2(x1)
x3 = self.EncBlock3(x2)
x4 = self.EncBlock4(x3)
x = self.Dec(x1, x2, x3, x4)
return x
学習
損失関数はTversky LossとBCEWithLogits Lossの平均としました。これらの関数は損失関数内でソフトマックス関数を処理する為、SegFormerの最後にソフトマックス関数を適用していません。
最適化関数としてAdamを使用します。
TverskyLoss = smp.losses.TverskyLoss(mode='multilabel', log_loss=False)
BCELoss = smp.losses.SoftBCEWithLogitsLoss()
def criterion(pred,target):
return 0.5*BCELoss(pred, target) + 0.5*TverskyLoss(pred, target)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = SegFormer(input_height = 256, class_num = 4).to(device)
optimizer = optim.Adam(model.parameters(), lr=0.0001)
history = {"train_loss": []}
df_len = len(train_df)
epoch_num = 20
print_coef = 10
n = 0
m = 0
scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones=[5, 10], gamma=0.1)
for epoch in range(epoch_num):
train_loss = 0
val_loss = 0
model.train()
for i, data in enumerate(train_loader):
inputs, labels = data["img"].to(device), data["label"].to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
train_loss += loss.item()
history["train_loss"].append(loss.item())
n += 1
if i % ((df_len//BATCH_SIZE)//print_coef) == (df_len//BATCH_SIZE)//print_coef - 1:
print(f"epoch:{epoch+1} index:{i+1} train_loss:{train_loss/n:.5f}")
n = 0
train_loss = 0
train_acc = 0
model.eval()
with torch.no_grad():
for i, data in enumerate(val_loader):
inputs, labels = data["img"].to(device), data["label"].to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
val_loss += loss.item()
m += 1
if i % (len(val_df)//BATCH_SIZE) == len(val_df)//BATCH_SIZE - 1:
print(f"epoch:{epoch+1} index:{i+1} val_loss:{val_loss/m:.5f}")
m = 0
val_loss = 0
val_acc = 0
torch.save(model.state_dict(), f"./train_{epoch+1}.pth")
scheduler.step()
print("finish training")
学習推移をプロットします。
plt.plot(history["train_loss"])

予測
テストデータセットを使用して予測します。
model.to("cpu")
model.eval()
test_dataset = valtest_Dataset(test_df[232:].reset_index(drop=True))
test_loader = DataLoader(test_dataset,
batch_size=1,
num_workers=4,
drop_last=True)
data = next(iter(test_loader))
inputs, labels = data["img"], data["label"]
outputs = model(inputs)
loss = criterion(outputs, labels)
sigmoid = nn.Sigmoid()
outputs = sigmoid(outputs)
pred = torch.argmax(outputs, axis=1)
pred = torch.nn.functional.one_hot(pred.long(), num_classes=4).to(torch.float32)
元の画像と予測結果を表示します。
plt.figure()
plt.imshow(data["img"][0,:,:,:].permute(1, 2, 0))
plt.title("original_image")
plt.axis("off")
plt.figure()
classes = ["background","large_bowel","small_bowel","stomach"]
fig, ax = plt.subplots(2, 4, figsize=(15,8))
for i in range(2):
for j, cl in enumerate(classes):
if i == 0:
ax[i,j].imshow(pred[0,:,:,j])
ax[i,j].set_title(f"pred_{cl}")
ax[i,j].axis("off")
else:
ax[i,j].imshow(data["label"][0,j,:,:])
ax[i,j].set_title(f"label_{cl}")
ax[i,j].axis("off")

上段が予測結果、下段がラベル画像をあわらします。
マスク画像が荒いのは画素数を1/4にしているためです。
学習の結果、検証用データの損失最小値が0.17039でした。以前実装したU-Netが0.1795でしたので、同等以上の性能を有することになります。
CNNメインのモデルとアンサンブル学習を行うことにより、さらに高い精度を出すことが可能だと感じました。
参考
Implementing SegFormer in PyTorch
SegFormer: Transformerでセグメンテーション