はじめに
【前回】UNetを実装する
本記事は前回の記事の続きとなります。前回はMRIの3D情報から小腸・大腸・胃の領域を予測する為に3DのUNetを実装しました。
しかし、データ数が足らずうまく予測が出来ないという結果になりました。そこで今回は深さ方向に一定の間隔でデータを切ることで、データ数の不足を補うことを目指しました。また、2DのUNetと3DのUNetを組み合わせてモデルを構築し、精度よく予測可能かどうかの検証を行いました。
UNet
【参考】セグメンテーションのモデル
【原著論文】U-Net: Convolutional Networks for Biomedical Image Segmentation
UNetはセグメンテーションと呼ばれるタスクを処理するために考案されたモデルです。セグメンテーションとは画像の1ピクセルごとにどのクラスに属するか予測するタスクであり、代表的な応用事例として、自動運転・医療画像解析が挙げられます。
セグメンテーションを行うモデルはいくつかの構造に大別されますが、UNetはエンコーダ・デコーダ構造の代表的なモデルとなります。
このモデルは序盤(エンコーダ)に畳み込み層を用いた特徴量抽出を行い、終盤(デコーダ)で確立マップを出力します。
UNetの特徴は、skip connectionでエンコーダとデコーダの出力をチャンネル方向に結合することです(下図の灰色矢印)。これにより物体の位置情報を保持して高精度の予測を可能としています。

(原著論文より)
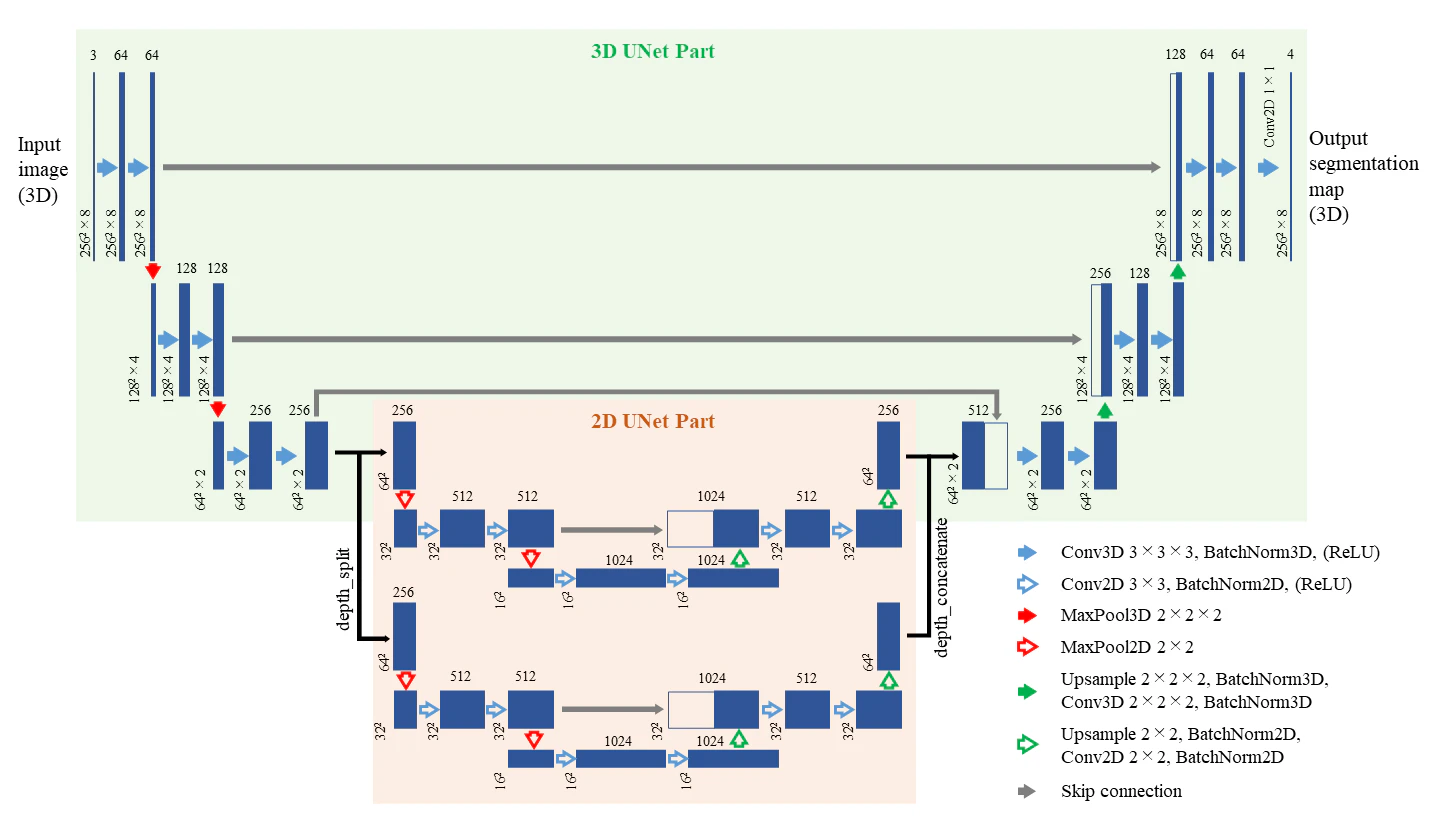
2.5D UNet
以下のように部分的に3DのUNetと2DのUNetを合体させたモデルを、便宜上2.5D UNetと呼んでいます。
2DのUNetの部分で2つに分岐していますが、これは3DのUpsamplingを行う際に2以上の深さが必要となる為、Upsamplingの直前で2つのデータを結合して深さ2を確保することが目的です。
データセット
データセットとしてKaggleの「UW-Madison GI Tract Image Segmentation」のデータセットを使用しました。本コンペティションはMRIの画像から小腸・大腸・胃の領域を予測し、その精度を競うものです。
環境
- Google Colaboratory Pro
コード
モジュールのimport
import pandas as pd
import numpy as np
import cv2
from matplotlib import pyplot as plt
from PIL import Image
from torch.utils.data import DataLoader
from torch.utils.data import Dataset as BaseDataset
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import transforms
from torchvision.transforms import functional
import albumentations as A
!pip install -U segmentation-models-pytorch
import segmentation_models_pytorch as smp
データのダウンロード・前処理については以下のリンクをご参照ください。データセットのtrain.csvにラベル情報が含まれており、これをpngファイルとして保存しています。
https://colab.research.google.com/drive/1O2E5v9tRGKa8XZl0FLNyHEOXteiAOspF?usp=sharing
学習用にデータフレームを作成しました。学習用のデータフレームは2106行×21列から成り、1行が1つの3Dデータに該当します。列は幅、高さ、深さなどのパラメータの他、各画像のパス、各ラベルのパスから構成されています。3Dデータの深さは8に統一しているため、画像のパスとラベルのパスはそれぞれ8個記載されています。(後のデータローダーで深さ方向に結合していきます。)
ラベル有のデータのみで学習していきます。
train_3D8_df = pd.read_csv("./train_3D8_df.csv")
val_3D8_df = pd.read_csv("./val_3D8_df.csv")
test_3D8_df = pd.read_csv("./test_3D8_df.csv")
train_df = train_3D8_df[train_3D8_df.label == 1].reset_index(drop=True) #ラベル有のデータのみ抽出
val_df = val_3D8_df[val_3D8_df.label == 1].reset_index(drop=True) #ラベル有のデータのみ抽出
test_df = test_3D8_df[test_3D8_df.label == 1].reset_index(drop=True) #ラベル有のデータのみ抽出
print(train_df.shape)
print(train_df.columns)
実行結果
(2106, 21)
Index(['id', 'caseday', 'imgpath_0', 'imgpath_1', 'imgpath_2',
'imgpath_3', 'imgpath_4', 'imgpath_5', 'imgpath_6', 'imgpath_7',
'labelpath_0', 'labelpath_1', 'labelpath_2', 'labelpath_3',
'labelpath_4', 'labelpath_5', 'labelpath_6', 'labelpath_7', 'height',
'width', 'label'],
dtype='object')
データローダーを作成します。
additional_image_targets = {f"image{i+1}": "image" for i in range(8 - 1)}
additional_label_targets = {f"mask{i+1}": "mask" for i in range(8 - 1)}
additional_targets8 = dict(additional_image_targets, **additional_label_targets)
data_transforms8 = A.Compose([
A.HorizontalFlip(p=0.5),
A.ShiftScaleRotate(shift_limit=0.0625, scale_limit=0.05, rotate_limit=10, p=0.5),
A.OneOf([
A.GridDistortion(num_steps=5, distort_limit=0.05, p=1.0),
A.ElasticTransform(alpha=1, sigma=50, alpha_affine=50, p=1.0)
], p=0.25),],
additional_targets = additional_targets8, p=1.0)
以下、コードが冗長ですが次の処理を行っています。
1.各深さの画像とラベルを読込み、(256,256)にリサイズした後深さ方向に結合
2.Albumentationsの引数とするため辞書型のデータを作成
3.Albumentationsによるデータ拡張
4.変換後のデータを再度深さ方向に結合
5.画像は各RGBの値を0~1に変換(255で割る)
6.ラベルは0(background)、1(large_bowel)、2(small_bowel)、3(stomach)で表されているため、これをOne-Hot エンコーディング
7.画像・ラベルデータを(バッチサイズ、チャンネル数、深さ、高さ、幅)に変換
class Dataset(BaseDataset):
def __init__(
self,
df
):
self.depth = 8
self.imgpath_list = [[df.iloc[i,:][f"imgpath_{h}"] for h in range(self.depth)] for i in range(len(df))]
self.labelpath_list = [[df.iloc[i,:][f"labelpath_{h}"] for h in range(self.depth)] for i in range(len(df))]
self.transform8 = data_transforms8
def __getitem__(self, i):
imgpathes = self.imgpath_list[i]
labelpathes = self.labelpath_list[i]
for j in range(self.depth): #画像とラベルデータの読み込み
img = cv2.imread(imgpathes[j])
img = cv2.resize(img, dsize = (256, 256))
label = Image.open(labelpathes[j])
label = np.asarray(label)
label = cv2.resize(label, dsize = (256, 256))
if j == 0: #深さ方向に結合
img_3D = [img]
label_3D = [label]
else:
img_3D = np.vstack([img_3D, [img]])
label_3D = np.vstack([label_3D, [label]])
d1 = {"image": img_3D[0,:,:,:]} #Albumentationsに代入する為の辞書型データを作成
d2 = {f"image{i+1}": img_3D[i+1,:,:,:] for i in range(self.depth - 1)}
d3 = {"mask": label_3D[0,:,:]}
d4 = {f"mask{i+1}": label_3D[i+1,:,:] for i in range(self.depth - 1)}
dic = dict(d1, **d2, **d3, **d4)
transformed = self.transform8(**dic)
for j in range(self.depth):
if j == 0: #データ拡張後のデータを再度深さ方向に結合
img_3D = [transformed["image"]]
label_3D = [transformed["mask"]]
else:
img_3D = np.vstack([img_3D, [transformed[f"image{j}"]]])
label_3D = np.vstack([label_3D, [transformed[f"mask{j}"]]])
img_3D = img_3D/255 #RGBの値を0~1に
img_3D = torch.from_numpy(img_3D.astype(np.float32)).clone()
img_3D = img_3D.permute(3, 0, 1, 2) #(チャンネル数、深さ、高さ、幅)に変換
label_3D = torch.from_numpy(label_3D.astype(np.float32)).clone()
label_3D = torch.nn.functional.one_hot(label_3D.long(), num_classes=4)
label_3D = label_3D.to(torch.float32)
label_3D = label_3D.permute(3, 0, 1, 2) #(チャンネル数、深さ、高さ、幅)に変換
data = {"img": img_3D, "label": label_3D}
return data
def __len__(self):
return len(self.imgpath_list)
class valtest_Dataset(BaseDataset): #Albumentationsによるデータ拡張を行わない
def __init__(
self,
df
):
self.depth = 8
self.imgpath_list = [[df.iloc[i,:][f"imgpath_{h}"] for h in range(self.depth)] for i in range(len(df))]
self.labelpath_list = [[df.iloc[i,:][f"labelpath_{h}"] for h in range(self.depth)] for i in range(len(df))]
def __getitem__(self, i):
imgpathes = self.imgpath_list[i]
labelpathes = self.labelpath_list[i]
for j in range(self.depth):
img = cv2.imread(imgpathes[j])
label = Image.open(labelpathes[j])
label = np.asarray(label)
img = cv2.resize(img, dsize = (256, 256))
label = cv2.resize(label, dsize = (256, 256))
if j == 0:
img_3D = [img]
label_3D = [label]
else:
img_3D = np.vstack([img_3D, [img]])
label_3D = np.vstack([label_3D, [label]])
img_3D = img_3D/255
img_3D = torch.from_numpy(img_3D.astype(np.float32)).clone()
img_3D = img_3D.permute(3, 0, 1, 2)
label_3D = torch.from_numpy(label_3D.astype(np.float32)).clone()
label_3D = torch.nn.functional.one_hot(label_3D.long(), num_classes=4)
label_3D = label_3D.to(torch.float32)
label_3D = label_3D.permute(3, 0, 1, 2)
data = {"img": img_3D, "label": label_3D}
return data
def __len__(self):
return len(self.imgpath_list)
BATCH_SIZE = 3
train_dataset = Dataset(train_df)
train_loader = DataLoader(train_dataset,
batch_size=BATCH_SIZE,
num_workers=4,
shuffle=True)
val_dataset = valtest_Dataset(val_df)
val_loader = DataLoader(val_dataset,
batch_size=BATCH_SIZE,
num_workers=4,
shuffle=True)
test_dataset = valtest_Dataset(test_df)
test_loader = DataLoader(test_dataset,
batch_size=1,
num_workers=4)
2.5DのUNetモデルを構築します。
class TwoConvBlock_2D(nn.Module):
def __init__(self, in_channels, middle_channels, out_channels):
super().__init__()
self.conv1 = nn.Conv2d(in_channels, middle_channels, kernel_size = 3, padding="same")
self.bn1 = nn.BatchNorm2d(middle_channels)
self.rl = nn.ReLU()
self.conv2 = nn.Conv2d(middle_channels, out_channels, kernel_size = 3, padding="same")
self.bn2 = nn.BatchNorm2d(out_channels)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.rl(x)
x = self.conv2(x)
x = self.bn2(x)
x = self.rl(x)
return x
class TwoConvBlock_3D(nn.Module):
def __init__(self, in_channels, middle_channels, out_channels):
super().__init__()
self.conv1 = nn.Conv3d(in_channels, middle_channels, kernel_size = 3, padding="same")
self.bn1 = nn.BatchNorm3d(middle_channels)
self.rl = nn.ReLU()
self.conv2 = nn.Conv3d(middle_channels, out_channels, kernel_size = 3, padding="same")
self.bn2 = nn.BatchNorm3d(out_channels)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.rl(x)
x = self.conv2(x)
x = self.bn2(x)
x = self.rl(x)
return x
class UpConv_2D(nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
self.up = nn.Upsample(scale_factor=2, mode="bilinear", align_corners=True)
self.bn1 = nn.BatchNorm2d(in_channels)
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size = 2, padding="same")
self.bn2 = nn.BatchNorm2d(out_channels)
def forward(self, x):
x = self.up(x)
x = self.bn1(x)
x = self.conv(x)
x = self.bn2(x)
return x
class UpConv_3D(nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
self.up = nn.Upsample(scale_factor=2, mode="trilinear", align_corners=True)
self.bn1 = nn.BatchNorm3d(in_channels)
self.conv = nn.Conv3d(in_channels, out_channels, kernel_size = 2, padding="same")
self.bn2 = nn.BatchNorm3d(out_channels)
def forward(self, x):
x = self.up(x)
x = self.bn1(x)
x = self.conv(x)
x = self.bn2(x)
return x
class UNet_3D(nn.Module):
def __init__(self):
super().__init__()
self.TCB1 = TwoConvBlock_3D(3, 64, 64)
self.TCB2 = TwoConvBlock_3D(64, 128, 128)
self.TCB3 = TwoConvBlock_3D(128, 256, 256)
self.TCB4 = TwoConvBlock_2D(256, 512, 512)
self.TCB5 = TwoConvBlock_2D(512, 1024, 1024)
self.TCB6 = TwoConvBlock_2D(1024, 512, 512)
self.TCB7 = TwoConvBlock_3D(512, 256, 256)
self.TCB8 = TwoConvBlock_3D(256, 128, 128)
self.TCB9 = TwoConvBlock_3D(128, 64, 64)
self.maxpool_3D = nn.MaxPool3d(2, stride = 2)
self.maxpool_2D = nn.MaxPool2d(2, stride = 2)
self.UC1 = UpConv_2D(1024, 512)
self.UC2 = UpConv_2D(512, 256)
self.UC3 = UpConv_3D(256, 128)
self.UC4 = UpConv_3D(128, 64)
self.conv1 = nn.Conv3d(64, 4, kernel_size = 1)
def forward(self, x):
x = self.TCB1(x)
x1 = x
x = self.maxpool_3D(x)
x = self.TCB2(x)
x2 = x
x = self.maxpool_3D(x)
x = self.TCB3(x)
x3 = x
x_1, x_2 = x[:,:,0,:,:], x[:,:,1,:,:]
x_1, x_2 = self.maxpool_2D(x_1), self.maxpool_2D(x_2)
x_1, x_2 = self.TCB4(x_1), self.TCB4(x_1)
x4_1, x4_2 = x_1, x_2
x_1, x_2 = self.maxpool_2D(x_1), self.maxpool_2D(x_2)
x_1, x_2 = self.TCB5(x_1), self.TCB5(x_1)
x_1, x_2 = self.UC1(x_1), self.UC1(x_2)
x_1, x_2 = torch.cat([x4_1, x_1], dim = 1), torch.cat([x4_2, x_2], dim = 1)
x_1, x_2 = self.TCB6(x_1), self.TCB6(x_1)
x_1, x_2 = self.UC2(x_1), self.UC2(x_2)
x = torch.cat([torch.unsqueeze(x_1, 2), torch.unsqueeze(x_2, 2)], dim = 2)
x = torch.cat([x3, x], dim = 1)
x = self.TCB7(x)
x = self.UC3(x)
x = torch.cat([x2, x], dim = 1)
x = self.TCB8(x)
x = self.UC4(x)
x = torch.cat([x1, x], dim = 1)
x = self.TCB9(x)
x = self.conv1(x)
return x
GPU、最適化アルゴリズムの設定を行います。
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
unet = UNet_3D().to(device)
optimizer = optim.Adam(unet.parameters(), lr=0.001)
損失関数を設定します。損失はTversky LossとBCEWithLogits Lossの平均としました。これらの関数は損失関数内でソフトマックス関数を処理する為、UNetの最後にソフトマックス関数を適用していません。
TverskyLoss = smp.losses.TverskyLoss(mode='multilabel', log_loss=False)
BCELoss = smp.losses.SoftBCEWithLogitsLoss()
def criterion(pred,target):
return 0.5*BCELoss(pred, target) + 0.5*TverskyLoss(pred, target)
学習を行います。
history = {"train_loss": []}
n = 0
m = 0
for epoch in range(15):
train_loss = 0
val_loss = 0
unet.train()
for i, data in enumerate(train_loader):
inputs, labels = data["img"].to(device), data["label"].to(device)
optimizer.zero_grad()
outputs = unet(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
train_loss += loss.item()
history["train_loss"].append(loss.item())
n += 1
if i % ((len(train_df)//BATCH_SIZE)//10) == (len(train_df)//BATCH_SIZE)//10 - 1:
print(f"epoch:{epoch+1} index:{i+1} train_loss:{train_loss/n:.5f}")
n = 0
train_loss = 0
unet.eval()
with torch.no_grad():
for i, data in enumerate(val_loader):
inputs, labels = data["img"].to(device), data["label"].to(device)
outputs = unet(inputs)
loss = criterion(outputs, labels)
val_loss += loss.item()
m += 1
if i % (len(val_df)//BATCH_SIZE) == len(val_df)//BATCH_SIZE - 1:
print(f"epoch:{epoch+1} index:{i+1} val_loss:{val_loss/m:.5f}")
m = 0
val_loss = 0
scheduler.step()
torch.save(unet.state_dict(), f"./train_depth8_{epoch+1}.pth")
print("finish training")
学習データとvalidationデータの損失はともに減少していました。
(lossの最小値 train:0.21373、validation:0.21385)
testデータに対して予測を行います。
validation用データセットの損失が最も低かったエポックの重みを使用します。
model = UNet_3D()
model.load_state_dict(torch.load("./train_depth8_13.pth"))
model.eval()
data = next(iter(test_loader))
inputs, labels = data["img"], data["label"]
outputs = model(inputs)
loss = criterion(outputs, labels)
sigmoid = nn.Sigmoid()
outputs = sigmoid(outputs)
pred = torch.argmax(outputs, axis=1)
pred = torch.nn.functional.one_hot(pred.long(), num_classes=4).to(torch.float32)
元の画像と予測結果を表示します。
plt.figure()
plt.imshow(data["img"][0,:,0,:,:].permute(1, 2, 0))
plt.title("original_image")
plt.axis("off")
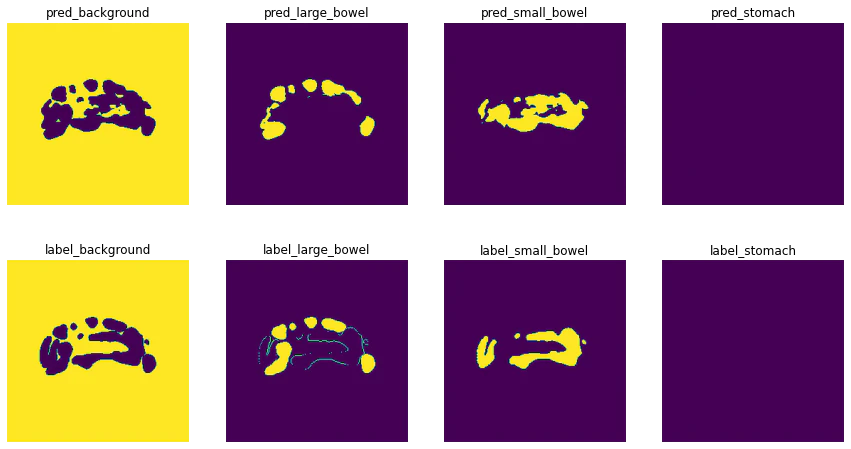
plt.figure()
classes = ["background","large_bowel","small_bowel","stomach"]
fig, ax = plt.subplots(2, 4, figsize=(15,8))
for i in range(2):
for j, cl in enumerate(classes):
if i == 0:
ax[i,j].imshow(pred[0,0,:,:,j])
ax[i,j].set_title(f"pred_{cl}")
ax[i,j].axis("off")
else:
ax[i,j].imshow(data["label"][0,j,0,:,:])
ax[i,j].set_title(f"label_{cl}")
ax[i,j].axis("off")
2D、3D、2.5D UNetの比較
同じ画像を各モデルで予測します。
最上段から2D_UNet、2.5D_UNet、3D_UNet、ラベルとなっています。
DiceLossは2D_UNetが0.552、2.5D_UNetが0.5536、3D_UNetが0.5580となりました。この画像の予測精度については2D_UNet>2.5D_UNet>3D_UNetとなりました。

次は各モデルで共通のテストデータセット(512枚)の予測を行い、損失(Tversky LossとBCEWithLogits Lossの平均)およびダイス損失のそれぞれの平均(各損失の和をデータセットの数で割る)を求めました。結果は以下の通りです。
| 評価指標 | 2D UNet | 2.5D UNet | 3D UNet |
|---|---|---|---|
| Tversky + BCE | 0.1795 | 0.2470 | 0.3420 |
| Dice | 0.3237 | 0.4455 | 0.6399 |
いずれの損失においても2D_UNet<2.5D_UNet<3D_UNetとなり、テストデータセット全体で2D_UNetの予測精度が高いという結果になりました。
3種のUNetを比較し、画像処理についてはとにかく多くの学習データを用意することが重要だと分かりました。当たり前ですが...
これらのモデルをアンサンブルすると、さらに予測精度が上がる可能性があります。
また、データ拡張の方法次第で各UNetの予測精度を高めることが可能かと思いますので、こちらも学んでいきたいと思います。