ブログからの転記のため、以下の元記事の方が見やすいかも知れません。
Unity + ML-Agentsで流行りの強化学習(ディープラーニング)を始める【2020年最新】1.6.0-preview | Genki Tech

以前からやりたいと思っていたAI技術、ディープラーニングを遂に始めました。元々これがやりたくて、やるなら記事を書きたいと思ってWordPressやGatsbyを使い始めたので、1カ月近く回り道してしまいました。
更新が早いせいか古い情報も沢山あったため、出来るだけ最新の情報でまとめてみました。
どんな仕組みなの?
調べていると、Unity、ML-Agents、Python、Anacondaとか出てきて、僕も最初どんな関係で動くのかわからなかったのでまとめてみました。
- Unity。3Dゲーム等が作れる総合開発環境
- ML-Agents(Unity拡張パッケージ)。Unity上でディープラーニングを使うための拡張パッケージ。計算済みの知能を再生したり、次にあるPytyonの拡張機能と連携した学習機能を提供。
- ML-Agents(Python拡張パッケージ)。Unityの拡張パッケージML-Agentsと連携して学習させる、学習機能のコア部分。
- Python。上の学習を機能させるのがPythonらしい。
- Anaconda。PythonをそのままPCに入れると環境が汚れがちなので、Pythonの管理のために使用。
まとめると、再生させるだけならPythonは不要。学習させたいならPythonのインストール必須(言語自体の知識は不要)。PC環境をPythonで汚したくないならAnacondaで管理すると幸せらしい。
Unityのインストールとプロジェクトの準備
UnityのサイトからUnity Hubをダウンロードしてインストールします。Unity Hubを入れるとUnityのバージョン管理ができるのでお勧めです。
Unity Hubを起動し、「新しいプロジェクトを作成」から、今回は「3D」を選択します。Unityの細かい説明は省略していますので、分からない部分は立ち止まって調べながらご覧いただければと思います。
UnityのプロジェクトにML-Agentsをインストール
割と最近パッケージ管理からも追加できるようになったようですが、更新が早くて追いついていないよう(現地点で最新はRelease10の1.6.0-preview、パッケージマネージャーの最新は1.0.6)なので、GitHubからML-Agentsプロジェクトをダウンロードしてパッケージ追加します。こっちにはサンプルも沢山あります。
ダウンロードして解凍し、任意の場所に配置します。(その場所がプロジェクトなどから参照され続けます。何も考えずにdowloadsフォルダをそのまま参照してたらうっかり消して環境再構築が面倒でした)
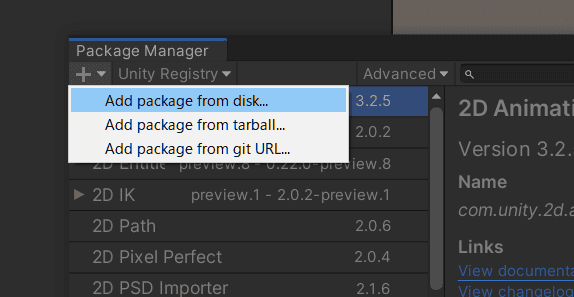
Unityの上のメニューから「Window」>「Package Manager」> 左上の「+」> 「Add package from disk」から、解凍したフォルダにある「com.unity.ml-agents」フォルダの「package.json」を開いてパッケージ追加します。
シーンを構成
Unityの「Hierarchy」タブ内に、空のオブジェクトを「Create Empty」で作成し、その中に「Cube」「Sphere」「Plane」を作成して、「Cube」と「Sphere」をいい感じの位置に移動します。(Planeは動かさない)

Sphereを選択し、「Inspector」タブにある「AddComponent」から、「RigidBody」を追加し、ボールが物理挙動をするようにします。
ついでにボールがBoxにぶつかった判定は今回コード上で行ってしまうので、Boxを選択し、「Inspector」>「Box Collider」をOFFにして、余計な当たり判定を消しときます。
再びSphereを選択し、「AddComponent」で「new Script」を指定してスクリプトを作成します。今回はtest.csにしました。なんでもいいですが、クラス名と一致している必要があるようです。(適当にやってたら若干ハマりました)
スクリプトの実装
まずは、キー操作で対象を動かせるようにします。
Assetsフォルダに作られたスクリプトファイルをダブルクリックで編集状態にします。VS Codeを使用している場合は以下のような設定で、「Editor Attaching」を有効にしておくとインテリセンスが効いてめちゃくちゃ便利です。

以下のコードを上書き貼り付けします。後で軽く説明します。
using UnityEngine;
using Unity.MLAgents;
using Unity.MLAgents.Actuators;
using Unity.MLAgents.Sensors;
using Random = UnityEngine.Random;
public class test : Agent
{
Rigidbody rBody;
public Transform target;
//前回の距離を保持
float previousDistance;
// 初期化
public override void Initialize()
{
rBody = GetComponent<Rigidbody>();
}
// エピソード開始時
public override void OnEpisodeBegin()
{
// 落ちたらリセット
if (this.transform.localPosition.y < 0)
{
this.rBody.angularVelocity = Vector3.zero;
this.rBody.velocity = Vector3.zero;
this.transform.localPosition = new Vector3(0.0f, 0.5f, 0.0f);
}
// 箱をランダムに配置
target.localPosition = new Vector3(Random.value * 8 - 4, 0.5f, Random.value * 8 - 4);
//前回の距離を記録
previousDistance = Vector3.Distance(this.transform.localPosition, target.localPosition);
}
// 観測値取得時
public override void CollectObservations(VectorSensor sensor)
{
sensor.AddObservation(target.localPosition); //TargetのXYZ座標
sensor.AddObservation(this.transform.localPosition); //RollerAgentのXYZ座標
sensor.AddObservation(rBody.velocity.x); // RollerAgentのX速度
sensor.AddObservation(rBody.velocity.z); // RollerAgentのZ速度
}
// 行動実行時
public override void OnActionReceived(ActionBuffers actionBuffers)
{
// ボールに力を加える
rBody.AddForce(actionBuffers.ContinuousActions[0] * 10, 0, actionBuffers.ContinuousActions[1] * 10);
// 前回より近づいた分報酬。離れた分お叱り
var nowDistance = Vector3.Distance(this.transform.localPosition, target.localPosition);
AddReward((previousDistance - nowDistance) * 0.1f);
previousDistance = nowDistance;
//時間の経過とともにお叱り
AddReward(-0.01f);
// 箱に接触した場合は報酬を与えてリセット。
if (Vector3.Distance(this.transform.localPosition, target.localPosition) < 1.0f)
{
AddReward(10.0f);
EndEpisode();
}
// 落下した時場合はお叱りを与えてリセット。
if (this.transform.localPosition.y < 0)
{
AddReward(-13.0f);
EndEpisode();
}
}
// キー入力をパラメータに変換
public override void Heuristic(in ActionBuffers actionsOut)
{
var actions = actionsOut.ContinuousActions;
actions[0] = Input.GetAxis("Horizontal");
actions[1] = Input.GetAxis("Vertical");
}
}
保存するとShpereのコンポーネントで先ほど追加したスクリプトに「target」が指定できるようになるため、Boxをドラッグドロップなどで設定しておきます。
ML-Agentsのコンポーネント設定
上のスクリプトには、ML-Agentsで学習するためのコードと、学習したものを再生するためのコードと、手動操作で動かすためのコードが仕組まれています。とりあえず手動で試したいんですが、先にML-Agentsのプラグインで設定を入れてあげる必要があります。
Sphereにコンポーネント「Decision Requester」を追加します。
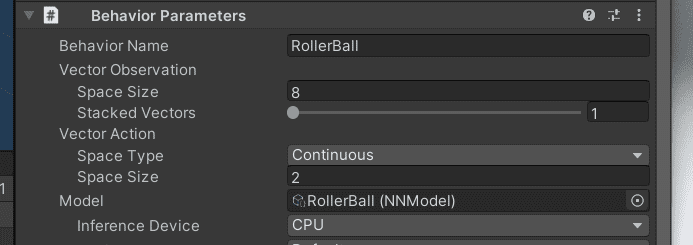
Sphereにコンポーネント「Behavior Paremeters」を追加し、「Behavior Name」に「RollerBall」、「Vector Observation」>「Space Size」を8、「Vector Action」>「Space Type」を「Continuous」、「Space Size」を2に変更します。(「Behavior Name」は、あとで学習時に設定名として使用します)

一度実行し、方向キーでコントロールでき、ターゲットを取れた時や落ちたときの動作が正しいことを確認します。

PythonのインストールとML-Agentsの設定
学習させるための環境構築を行います。
Pythonの管理を楽にやりたいのでAnacondaのページの下の方からWindowsバイナリをダウンロードしてインストールします。
インストール中に「Add Anaconda3 to PATH environment variable」と言うチェックを付けると自動でパスが通るので便利ですが、既にPythonが入っていると競合したりするみたいなので、自分はいつ入れたか分からないPythonを一度全部アンインストールして、Anacondaをインストールしました。

「Anaconda Powershell Prompt」ではなく「PowerShell」でアクティブ環境を切り替えて操作したいので、以下のコマンドを実行して、「activate」コマンドを実行できるようにします。
> conda install -n root -c pscondaenvs pscondaenvs
新しいPython環境を作るため、以下のコマンドを実行します。(「ml-agents」は名前なので何でもOK)
> conda create -n ml-agents python=3.7
作った環境をアクティブにします。(「conda activate」ではなく「activate」です)
> activate ml-agents
Release10以降、デフォルトでPyTorchと言うパッケージが使用されるようなので、必ずPyTorchを先にインストールします。
> pip3 install torch==1.7.0 -f https://download.pytorch.org/whl/torch_stable.html
ML-Agentsのパッケージを追加します。
> pip3 install mlagents
cdコマンドで、GitHubからダウンロードしてきたML-Agentsのフォルダに潜り、パッケージのインストールコマンドを実行します。
> cd ~(解凍ディレクトリ)~/ml-agents-release_10
> pip3 install -e ./ml-agents-envs
> pip3 install -e ./ml-agents
プロジェクトに学習用の設定ファイルを配置
Unityのプロジェクトフォルダ(Assetsとかがあるフォルダ)に1つだけ、学習のための設定ファイルを追加します。「config」フォルダに「rollerball_config.yaml」ファイルを作成し、以下の内容を入力します。
behaviors:
RollerBall:
max_steps: 1000000
簡単な学習ではほぼ既定値で大丈夫そうなので設定な設定にしておきます。
この「RollerBall」と言う名前だけは、Unityのコンポーネントで指定した「Behavior Parameters」の「Behavior Name」と一致している必要があります。
学習開始
いよいよ学習を始めます。
PowerShelldでプロジェクトフォルダに移動し、以下のコマンドを実行して学習待機状態にします。
> mlagents-learn config/rollerball_config.yaml --run-id=RollerBall
PowerShell上にこんなのが出て、待機状態になっていればOKです。

待機状態のうちにUnityを実行すると、ボールが落ちては戻る動作を繰り返して学習し始めます。

学習状況がPowerShell上にも表示されます。

学習の再開方法
今回はあまり賢くなる前に終わってしまったみたいです。実はわざとステップ数を少なく設定してました。ステップ数を増やして先ほどの続きから実行してみましょう。
behaviors:
RollerBall:
max_steps: 1000000
再開する場合、--resumeオプションを追加して実行し、Unityも再び実行します。
> mlagents-learn config/rollerball_config.yaml --run-id=RollerBall --resume
15万ステップくらいでちょっと上手になってきました。

学習を早く進めるため、Unity上でこれを複製してみることにします。一度Unityを停止します。(PowerShellの方を停止すると学習が再開できなくなる?みたいなので、必ずUnity上で停止)
学習の高速化
「Hierarchy」タブの「GameObject」を「Project」タブの「Assets」フォルダにドラッグ&ドロップし、「プレハブ」と言うものに変換します。青くなってればOK。

Ctrl+Dでこのプレハブを複製してシーン上で被らないように並べていき、学習を再度実行します。

PowerShellの出力結果からも成績が上がっているのが確認できますが、折角なのでGUIで細かく見てみましょう。もう一つPowerShellを起動し、Unityのプロジェクトフォルダに移動して、以下のコマンドを実行します。
tensorboard --logdir results --port 6006
ブラウザで「localhost:6006」にアクセスすると、進捗状況がグラフで表示されます。(少しデータが溜まるまでグラフは表示されないかも)
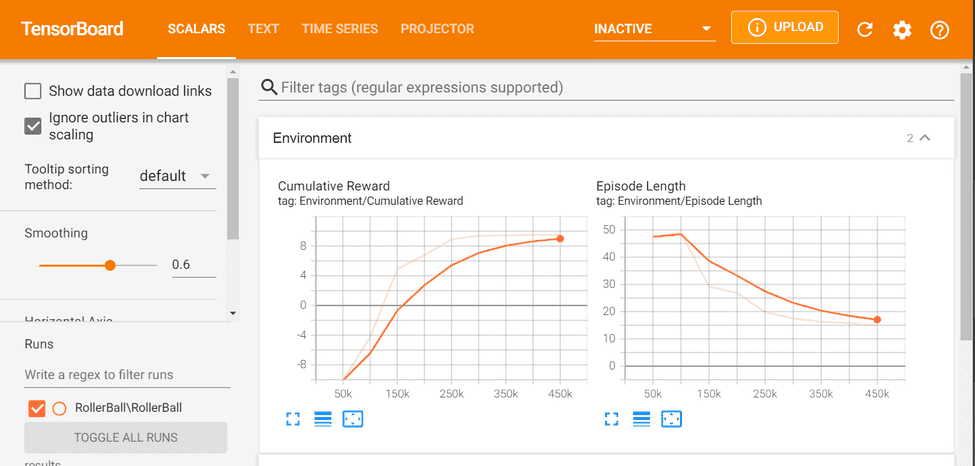
今回詳しくは扱いませんが、Rewardがどんどん増えていって、最終的には一定の値で収束するので、今の学習はそのあたりが上限、と言う感じです。(さらに上げるためには工夫が必要)
知能を適用
このあたりで一度Unityを停止し、出来上がった知能をセットして、Pythonなしで動作するようにします。
計算された知能はプロジェクトフォルダの「results」フォルダにあり、今回は「RollerBall.nn」と言うファイルが出来ているためそれをUnityのAssetsフォルダにコピーします。
コピーしたファイルをUnity上で、「Behavior Parameters」の「Model」にドラッグ&ドロップで適用します。
もうPowerShellの方は動かさなくて大丈夫です。Unityを実行してみましょう。
最終的にこうなりました。(これは早送りです)

このくらいの簡単な例だと、人間以上のプレイヤーを簡単に誕生させられることが分かりました。
次回は、中で何が起きてるの?と言う部分を説明したいと思います。