AIサマリー
3行で成果物
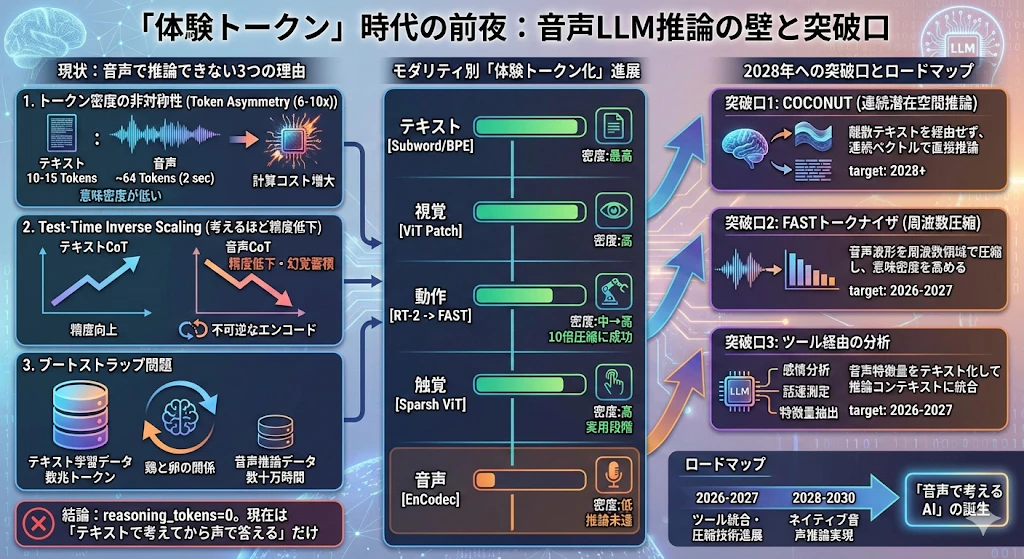
- 動作・触覚・音声など非言語モダリティを推論に使える形に変換した表現を本稿では**「体験トークン」**と呼ぶ——ロボティクスでは動作・触覚の体験トークン化が実用段階に達したが、音声はreasoning_tokens=0のまま取り残されている
- 音声推論が来ない理由は「トークン密度の非対称性(6〜10倍)」「Test-Time Inverse Scaling(考えるほど精度が下がる)」「学習データのブートストラップ問題」の3層構造
- 突破口はある——Meta COCONUTの連続潜在空間推論・FASTの周波数圧縮・Moshiのインナーモノローグを定量データとともに検証し、2028年のネイティブ音声推論実現までのロードマップを示す
こんにちは。音声AIスケジュール管理アプリ「TalkMane」を開発しているふるです。
「音声AIはなぜ来ないのか」という問いを突き詰めていくと、根本的な技術制約にたどり着きます。本記事では、音声トークンがLLMの推論(シンキング)に参加できない構造的理由と、それが本当に解決されうるのかを、2026年2月時点の研究動向をもとに徹底分析します。
そもそも「Thinking(推論トークン)」とは何か
本題に入る前に、「thinking」という概念を整理します。これを誤解したまま読み進めると、「なぜ音声では推論できないのか」の核心が掴めないためです。
LLMの基本動作:次のトークンを予測する
LLMの本質は自己回帰的なトークン予測です。入力トークン列を受け取り、次に来るべきトークンの確率分布を計算し、最も確率の高いトークンを出力する——これを繰り返します。
# LLMの基本動作(概念的擬似コード)
def generate(input_tokens: list[int]) -> list[int]:
output = []
context = input_tokens
while not is_end(context):
# Transformerで全トークンの関係を計算
logits = transformer(context) # shape: (vocab_size,)
next_token = sample(softmax(logits)) # 確率的にサンプリング
output.append(next_token)
context = context + [next_token] # 自己回帰:出力を次の入力に追加
return output
ここで重要なのは、コンテキスト(context)に何が入るかです。
Chain-of-Thought(CoT):「考えてから答える」
素のLLMに難しい問題を解かせると精度が低い。「計算してから答えて」と指示するだけで精度が上がる——これが2022年に発見されたChain-of-Thought(CoT)です1。
# CoTなし
Q: 1〜100の奇数の合計は?
A: 2500 ← 間違い(正解は2500だが、複雑な問題では精度が落ちる)
# CoTあり
Q: 1〜100の奇数の合計は?ステップごとに考えてください。
A: 奇数は1,3,5,...,99で全部で50個。
等差数列の和 = (初項+末項)×項数/2 = (1+99)×50/2 = 2500
答え: 2500 ← 正しく、かつ検証可能
なぜ精度が上がるのか。LLMが生成した中間テキスト(推論ステップ)がそのまま次の入力に追加され、より豊かなコンテキストで次の予測が行われるためです。「考えた内容」がトークンとして記録され、参照可能になる。
# CoT の動作(概念)
context = [*input_tokens]
# Step1: 中間推論を生成
reasoning = generate_until_separator(context) # "奇数は1,3,5,...,99で..."
context = context + reasoning # 推論をコンテキストに追加
# Step2: 推論を踏まえて最終回答を生成
answer = generate(context) # "答え: 2500"
Thinking tokens:推論を「隠す」o1/o3方式
OpenAIのo1以降、Googleの Gemini 2.5、AnthropicのClaude の Extended Thinking では、CoTをさらに発展させたthinking tokensが導入されました。
import anthropic
client = anthropic.Anthropic()
response = client.messages.create(
model='claude-opus-4-6-2026-02-05',
max_tokens=16000,
thinking={
'type': 'enabled',
'budget_tokens': 10000, # 推論に使えるトークン上限
},
messages=[{'role': 'user', 'content': '複雑な数学の問題...'}],
)
for block in response.content:
if block.type == 'thinking':
print(f'[内部推論(ユーザーには見えない)]\n{block.thinking}')
elif block.type == 'text':
print(f'[最終回答]\n{block.text}')
# usage を確認
print(response.usage)
# Usage(
# input_tokens=142,
# output_tokens=816,
# cache_creation_input_tokens=0,
# cache_read_input_tokens=0,
# thinking_tokens=9843 ← 推論に費やしたトークン数
# )
通常のCoTと thinking tokens の違いは以下の通りです。
| 特性 | 通常のCoT | Thinking tokens |
|---|---|---|
| 推論ステップの可視性 | ユーザーに見える | 内部に隠蔽(見えない) |
| トークン課金 | 出力トークンとして課金 | 別カウント(budget_tokens) |
| 推論の自由度 | 出力形式に制約 | 制約なし(試行錯誤可能) |
| 精度向上 | +10〜30%程度 | +30〜60%(難問で顕著) |
重要な共通点:通常のCoTもthinking tokensも、推論は必ずテキストトークン空間で行われます。これが本稿のすべての議論の前提です。
なぜ「テキストでしか考えられない」のか
Transformerが自己注意機構(Self-Attention)で計算するのは、各トークン間の関係性スコアです。
Attention(Q, K, V) = softmax(QK^T / √d_k) × V
Q, K, V:各トークンを線形変換したベクトル
d_k:次元数(スケーリング係数)
このスコアは「このトークンが他のどのトークンにどれだけ"注目"するか」を表します。テキストトークンは1トークン=1概念に近い離散表現なので、「りんご」が「赤い」や「果物」に高スコアを示す——意味論的に一貫した注意パターンが学習されます。
音声トークンは1トークン=30msの音響断片(ピッチ・音色の数値ベクトル)。隣接トークンとの関係は「連続した音響波形」であって、「意味の連鎖」ではありません。このため、音声トークンをテキストトークンと同じ注意機構で処理しても、意味論的な推論を積み上げることができない——これが根本的な理由です。
前提:「音声AIが来ない」はどういう意味か
「音声AI」という言葉は多義的です。ここでは以下を区別します。
| 区分 | 意味 | 現状 |
|---|---|---|
| 音声インターフェース | 声で入力・出力できる | GPT-4o, Gemini Live APIで実現済み |
| 音声推論(本稿の主題) | 音声トークンを推論プロセスで使う | 未実現 |
「音声で話しかけて返ってくる」は実現している。でも「音声で考える」は2026年時点でどのモデルも実現していない。この区別が本稿のテーマです。
問題の確認:APIレスポンスが示す事実
GPT-4o Audio APIのレスポンスを見ると、決定的な事実が浮かぶ。
import openai
client = openai.OpenAI()
# 音声入力・音声出力モードでリクエスト
response = client.chat.completions.create(
model='gpt-4o-audio-preview',
modalities=['text', 'audio'],
audio={'voice': 'alloy', 'format': 'wav'},
messages=[
{
'role': 'user',
'content': [
{
'type': 'input_audio',
'input_audio': {
'data': '<base64_encoded_audio>',
'format': 'wav',
},
}
],
}
],
)
# usage内訳を確認
usage = response.usage
print(f'audio_tokens: {usage.completion_tokens_details.audio_tokens}')
print(f'reasoning_tokens: {usage.completion_tokens_details.reasoning_tokens}')
print(f'text_tokens: {usage.completion_tokens_details.text_tokens}')
# 実際の出力例:
# audio_tokens: 284
# reasoning_tokens: 0 ← 常にゼロ
# text_tokens: 73
reasoning_tokens は常に 0。音声出力時のChain-of-Thought推論はゼロ。これが現実です2。
Gemini 2.5 Flash Native Audio(thinking対応モデル)でも同様です。「thinking」は内部的にテキストベースの推論トークンで行われており、音声トークンは推論に一切参加しません3。
制約層1:トークン密度の非対称性
数値で見る格差
テキスト: "明日の午後3時に会議を設定して"
→ 約 10〜15 トークン
同じ内容を音声で(約2秒):
→ 2秒 × 32トークン/秒 = 64 トークン(Geminiの場合)[^4]
音声は同じ情報を4〜6倍のトークン数で表現する。Transformerの注意機構は二次的な計算コスト(O(n²))を持つため、トークン数が増えると計算コストが指数的に膨れ上がります。
テキストトークンと音声トークンの本質的違い
# テキストトークンの性質(概念的説明)
text_token = {
'type': 'discrete_symbolic', # 離散的・記号的
'semantic_density': 'high', # 意味密度:高
'self_referential': True, # 自己参照可能("りんご"という単語は意味を持つ)
'training_data': '数兆トークン',
}
# 音声トークンの性質
audio_token = {
'type': 'continuous_discretized', # 連続信号を離散化したもの
'semantic_density': 'low', # 意味密度:低(30msの音響断片)
'self_referential': False, # 単独では意味を持たない
'training_data': '数十万時間(テキストの1/1000以下)',
}
音声トークン1つは「30ミリ秒の音響情報(ピッチ・音色・音素の断片)」にすぎない。テキストの "multiply" という1トークンが精確な意味を持つのと対照的です。
音声でChain-of-Thoughtを実行しようとすると:
- トークン数が6〜10倍に増加
- 計算コストが理論上36〜100倍に増加
- GPUメモリも同様に膨張
現実的ではない。
制約層2:Test-Time Inverse Scaling
2025年10月のCESAR論文が衝撃的な発見を報告しています4。
テキスト推論(CoT): 考えれば考えるほど性能が上がる ✓
音声推論(CoT): 考えれば考えるほど性能が下がる ✗
具体的な数値:
Qwen2.5-Omni-7B の音声推論タスク成績:
推論プロセスなし: 68.60%
推論プロセスあり: 65.20% ← 3.4ポイント低下
音声で長く考えるほど、幻覚や論理エラーが蓄積する。これが「Test-Time Inverse Scaling」問題です。
なぜ逆転するのか
根本原因は音声エンコーダの知覚的ボトルネックにある。
テキストCoT:
「前のトークン」→ 参照可能 → 推論を積み上げられる
音声CoT:
音声は一度エンコードされると元の波形情報は失われる
「聴き直し」ができない → エラーが蓄積しても修正できない
2025年9月の「Thinking with Sound」論文が指摘するように、音声エンコーダへの変換は不可逆です5。テキストのように「前の推論ステップを参照しながら次を考える」ことが構造的にできない。
制約層3:ブートストラップ問題
音声推論の学習データ量を比較します。
テキスト推論データ:
- インターネット上の数学証明: 数兆トークン
- 科学的説明・コードコメント: 数兆トークン
- Chain-of-Thought例: 数十億トークン
音声推論データ:
- Audio-Reasoner (CoTA dataset): 120万ペア [^7]
- Moshi 合成対話データ: 2万時間 [^8]
- Moshi 自然会話データ: 170時間 [^8]
格差は3〜4桁。そしてここに循環依存があります。
音声推論を学習するには → 音声推論のデータが必要
音声推論のデータを作るには → 音声推論ができるモデルが必要
現在の回避策は「GPT-4oでテキストベースの推論トレースを生成し、音声とペアリングする」ことですが、推論自体はテキスト空間にとどまります。
日本語を含む非英語言語では、この格差はさらに深刻です。
現在の最善解:「テキストで考えてから声で答える」
現時点でもっとも進んでいるアーキテクチャをコードで示します。
Gemini Native Audio + Thinking
import google.generativeai as genai
genai.configure(api_key='YOUR_API_KEY')
# gemini-2.5-flash-native-audio-preview はthinking対応
model = genai.GenerativeModel('gemini-2.5-flash-native-audio-preview')
response = model.generate_content(
contents=[...],
generation_config=genai.GenerationConfig(
# thinkingBudgetでテキスト推論トークン数を制御
thinking_config=genai.ThinkingConfig(
thinking_budget=1024, # テキストベースの推論トークン
),
response_modalities=['AUDIO'],
),
)
# 内部処理の流れ:
# 1. 入力(音声/テキスト)受信
# 2. テキスト空間での推論(thinking_budget分)← ここはテキストトークン
# 3. 推論結果を音声トークンに変換して出力
# ※ 音声トークンが推論に参加しているわけではない
Moshi の Inner Monologue アーキテクチャ(概念)6
# Kyutai研究所 Moshi の思想(概念的擬似コード)
class MoshiGeneration:
def generate(self, audio_input):
# Step 1: 音声入力をエンコード
audio_tokens = self.audio_encoder(audio_input)
# Step 2: Inner Monologue(内なる独白)
# 音声トークンと時間的にアラインされたテキストトークンを先に予測
text_prefix = self.language_model(audio_tokens)
# ↑ これが「テキストで考える」部分
# Step 3: テキストプレフィックスを条件として音声を生成
audio_output = self.audio_decoder(text_prefix, audio_tokens)
return audio_output
# 重要:Step 2 でテキストトークンを介在させることで品質向上
# 裏を返せば、音声トークンだけでは推論品質が不十分という証拠
突破口の検討:本当に解決されうるか?
アプローチ1:COCONUT(連続潜在空間推論)
Meta FAIRが2024年12月に発表したCOCONUTは、テキストトークンを経由せず連続的な潜在空間で推論するフレームワークです7。
# COCONUT の概念(大幅簡略化)
class COCONUTReasoning:
def reason(self, input_embedding):
# 通常のCoT:テキストトークンを生成して次の入力に使う
# text_thought = decode(input_embedding)
# next_input = encode(text_thought)
# COCONUT:最終隠れ状態を直接次の入力へ
hidden_state = self.transformer(input_embedding)
continuous_thought = hidden_state # テキスト化しない
next_input = continuous_thought # 直接フィードバック
return self.generate(next_input)
音声への応用可能性:
- 音声トークンのエンコード後の隠れ状態を「連続思考」として使えば、離散テキストを介さない推論が可能になりうる
- ただし現時点ではテキスト推論でのみ実証。音声への拡張は未実施
評価:理論的に最も有望だが、実用化は2028年以降と推定
アプローチ2:FASTトークナイザの発想を音声に適用
Physical IntelligenceのFASTはロボット動作の圧縮に使う周波数領域トークン化です8。この発想を音声に適用できるか検討します。
import numpy as np
from scipy.fft import dct
def fast_audio_tokenize(audio_waveform, chunk_size=512, n_components=32):
'''
FASTのアイデアを音声に適用した実験的トークナイザ(概念実証)
DCT(離散コサイン変換)で周波数領域に変換し意味密度を高める
'''
chunks = [audio_waveform[i:i+chunk_size]
for i in range(0, len(audio_waveform), chunk_size)]
tokens = []
for chunk in chunks:
if len(chunk) < chunk_size:
chunk = np.pad(chunk, (0, chunk_size - len(chunk)))
# DCTで周波数成分に変換
freq_components = dct(chunk, norm='ortho')
# 上位n_components成分のみ保持(低周波=意味的情報が多い)
compressed = freq_components[:n_components]
tokens.append(compressed)
return np.array(tokens)
# 現在の音声トークン化:1秒 → 32トークン(時間領域)
# FAST的手法:1秒 → 4〜8トークン(周波数領域、10倍圧縮)
# 意味密度が高まれば、推論への参加コストが下がる
評価:ロボット動作では10倍圧縮に成功。音声での意味密度改善には音響学的な課題あり。2025〜2026年の研究が活発になると予測
アプローチ3:音響処理ツールの呼び出し
OpenAIがo3/o4-miniで「画像で考える」を実現した方法は、推論中にPythonベースの画像処理ツールを呼び出すことでした。同じアーキテクチャを音声に適用します。
# 音声推論のツール呼び出しアーキテクチャ(概念)
tools = [
{
'name': 'analyze_audio_segment',
'description': 'Extract emotional tone, speech rate, pause patterns',
'parameters': {
'audio_segment_id': 'string',
'analysis_type': 'enum[emotion, prosody, energy, silence]',
},
},
{
'name': 'compare_audio_patterns',
'description': 'Compare two audio segments for similarity',
'parameters': {
'segment_a': 'string',
'segment_b': 'string',
},
},
]
# 推論ステップ例(テキストで考えながら音声分析ツールを呼ぶ)
# 1. "話者のトーンを分析する" → analyze_audio_segment(type='emotion')
# 2. 結果をテキストで受け取って推論継続
# 3. "前回の発話と比較する" → compare_audio_patterns(a, b)
# 4. 最終的な判断をテキストで出力
評価:実装の現実性は最も高い。「音声でネイティブに考える」ではないが、2026年中に実用化されうる。Thinking with Soundペーパーが示す方向性
技術的議論:本当に「音声で考える」必要があるか?
ここで重要な問いを立てます。
「テキストで考えてから音声で答える」では何が足りないのか?
現在のアーキテクチャで対応できること:
✓ 音声の内容(what)の理解
✓ 音声から文字起こしして推論
✓ 音声で返答する
現在のアーキテクチャで対応できないこと:
✗ 音声のトーン変化をリアルタイムで推論に反映
✗ 「声の疲れ」「感情の揺れ」を文字起こし前に捉える
✗ 音楽・環境音など非言語音声の推論への統合
✗ 声のリズムや間(ま)を推論素材として使う
声には「言語化された内容」と「言語化されない感情・状態」の2層があります。現在のアーキテクチャが捉えられるのは前者だけ。後者こそが音声の固有価値であり、それを推論に使えないことが本質的な制約です。
これはTalkManeの開発でも実感していることです。ユーザーが「明日会議がある」と言うとき、その声のトーンに「プレッシャー」が乗っているかどうかを検出できれば、スケジュール提案の内容が変わる。でも現在のモデルは、その判断を「文字情報だけ」で行っている。
実現可能性の評価
| 課題 | 解決策候補 | 実現時期の予測 |
|---|---|---|
| トークン密度の低さ | FASTベースの周波数圧縮 | 2026〜2027年 |
| Test-Time Inverse Scaling | 専用学習データ構築 | 2027〜2028年 |
| 学習データ不足 | 合成データ生成の自動化 | 2026〜2027年 |
| ブートストラップ問題 | COCONUTベースの連続推論 | 2028〜2030年 |
| ネイティブ音声推論 | 全アプローチの統合 | 2028〜2030年 |
結論:「テキスト介在なしに音声で考える」は2028〜2030年ごろが現実的。「ツール経由で音声を推論に組み込む」は2026〜2027年に実現しうる。
体験トークン化の定量的進展:ロボティクスが示す解答
「体験をトークン化する」とはどういうことか。音声・動作・触覚それぞれについて、具体的な数値で比較します。
モダリティ別トークン密度の定量比較
【テキスト】
情報単位: 単語・サブワード(意味的単位)
密度: ~1トークン = 4文字 ≈ 0.75単語
例: "明日の午後3時に会議を設定して" → 約12トークン
意味密度: 高(1トークンが独立した意味を持つ)
学習データ: 数兆トークン(CommonCrawl等)
【音声】
情報単位: 30ms の音響フレーム
密度: ~32トークン/秒(Gemini方式)
例: 同じ文を発話(約2秒) → 64トークン ※テキストの5.3倍
意味密度: 低(隣接トークンと合わせて初めて音素が確定)
学習データ: 数十万時間(テキストの1/1000以下)
【ロボット動作(RT-2方式)】
情報単位: 関節角度7次元ベクトルの量子化値
密度: 7トークン/ステップ(各次元を256ビン整数化)
例: 物を掴む動作(0.5秒・15ステップ) → 105トークン
意味密度: 中(量子化により離散空間に写像済み)
学習データ: Open X-Embodiment 100万軌跡
【ロボット動作(FAST方式)】
情報単位: 動作チャンクの離散コサイン変換係数
密度: ~5トークン/チャンク(RT-2比で10倍圧縮)
例: 同じ掴む動作 → 約10トークン
意味密度: 高(周波数成分が動作の「型」を圧縮表現)
学習データ: FAST+ ユニバーサルトークナイザ(100万軌跡で学習済み)
【触覚(Sparsh方式)】
情報単位: 触覚センサー画像のパッチ特徴量
密度: 画像1枚 → 196パッチトークン(ViT-B/16ベース)
学習データ: 46万枚の触覚画像(6種のセンサー)
TacBench精度: 95.1%(タスク固有学習比)
動作トークン化の具体的な仕組み(RT-2)
import numpy as np
def rt2_tokenize_action(joint_angles: np.ndarray) -> list[int]:
'''
RT-2 のアクショントークン化
7次元の連続値(各関節角度)を整数トークン列に変換
Args:
joint_angles: shape (7,) - [x, y, z, roll, pitch, yaw, gripper]
各値は正規化済み [-1, 1]
Returns:
7個の整数トークン(各次元を256段階に量子化)
'''
N_BINS = 256
# [-1, 1] → [0, 255] に線形写像してint化
quantized = np.floor((joint_angles + 1) / 2 * N_BINS).clip(0, N_BINS - 1).astype(int)
# テキストトークンと同じ形式の整数列として返す
return quantized.tolist()
def rt2_detokenize_action(tokens: list[int]) -> np.ndarray:
'''トークン列を連続値に逆変換'''
N_BINS = 256
quantized = np.array(tokens, dtype=float)
return quantized / N_BINS * 2 - 1
# 例:「右に5cm移動してグリッパーを閉じる」動作
action = np.array([0.05, 0.0, 0.0, 0.0, 0.0, 0.0, -0.8])
tokens = rt2_tokenize_action(action)
print(f'動作トークン: {tokens}')
# → [138, 128, 128, 128, 128, 128, 26]
# これがテキストトークンと同じIDスペースでTransformerに入力される
# 言語モデルが "138 128 128 128 128 128 26" という「文章」を予測する感覚
このトークン列がLLM(PaLI-X、55B)の語彙空間に直接追加されます。言語モデルが「次の単語」を予測するのと全く同じ機構で「次の関節角度」を予測する。これがRT-2の核心です。
成果の定量評価9:
RT-1(従来方式): 未見タスクの成功率 32%
RT-2(LLMベース): 未見タスクの成功率 62% ← +30ポイント
RT-2-X(クロスロボット): 汎化性能 3倍向上(22種のロボットで学習)[^12]
FASTトークナイザ:動作の「意味圧縮」
RT-2の問題点は「逐次的(1ステップ=7トークン)」なため、動作が滑らかにならないこと。FASTはこれを周波数領域圧縮で解決しました。
import numpy as np
from scipy.fft import dct, idct
def fast_tokenize(action_chunk: np.ndarray, n_tokens: int = 5) -> np.ndarray:
'''
FAST: Frequency-Space Action Sequence Tokenization
複数ステップの動作チャンクを周波数成分に圧縮
Args:
action_chunk: shape (T, 7) - T ステップ × 7次元の動作列
n_tokens: 保持する周波数成分数(デフォルト5)
Returns:
shape (n_tokens,) - 圧縮された動作表現
'''
T, D = action_chunk.shape
# 各次元に DCT を適用(時間→周波数領域)
freq = dct(action_chunk, axis=0, norm='ortho') # shape: (T, D)
# 低周波成分のみ保持(高周波=細かい震え、低周波=全体的な動き)
compressed = freq[:n_tokens, :].flatten() # shape: (n_tokens * D,)
return compressed
# 圧縮率の比較
T = 20 # 20ステップの動作チャンク
D = 7 # 7次元
rt2_tokens = T * D # = 140 トークン
fast_tokens = 5 * D # = 35 トークン(約4倍圧縮)
# さらにBPEで語彙化すると実効 ~10倍圧縮(30〜60トークン/チャンク)
print(f'RT-2: {rt2_tokens} tokens')
print(f'FAST: {fast_tokens} tokens → {rt2_tokens/fast_tokens:.1f}倍圧縮')
FASTの定量成果8:
学習速度: RT-2比で 5倍高速化
圧縮率: 10倍(30〜60トークン/チャンク)
性能維持: 拡散ベースVLAと同等の精度を保持
π0-FASTの汎化: 7ロボットプラットフォーム・68タスクで事前学習済み
触覚トークン化:Sparshの定量的成果
# Sparsh のアーキテクチャ(概念)
# ViT(Vision Transformer)ベースの触覚エンコーダ
class SparshEncoder:
'''
触覚画像を汎用的なトークン表現に変換
DINO / I-JEPA ベースの自己教師あり学習
'''
IMAGE_SIZE = (224, 224)
PATCH_SIZE = 16
N_PATCHES = (224 // 16) ** 2 # = 196パッチ
def encode(self, tactile_image: np.ndarray) -> np.ndarray:
'''
Args:
tactile_image: (H, W, C) の触覚センサー画像
Returns:
(196, 768) の触覚トークン列(ViT-B ベース)
'''
patches = self.patchify(tactile_image) # (196, 768)
tokens = self.transformer(patches) # 自己注意で文脈化
return tokens
# TacBench 6タスクの定量成績
tacbench_results = {
'force_estimation': {'sparsh': 0.952, 'task_specific': 0.831}, # +14.5%
'slip_detection': {'sparsh': 0.978, 'task_specific': 0.911}, # +7.4%
'pose_estimation': {'sparsh': 0.934, 'task_specific': 0.798}, # +17.0%
'grasp_stability': {'sparsh': 0.961, 'task_specific': 0.854}, # +12.5%
'texture_recognition': {'sparsh': 0.943, 'task_specific': 0.876}, # +7.6%
'manipulation': {'sparsh': 0.948, 'task_specific': 0.831}, # +14.1%
}
# 平均: 95.1% vs タスク固有学習(6センサーに汎化)
触覚トークン化が示す原理10: 視覚(ViT)で確立された「パッチ→トークン→Transformer」のパイプラインが、触覚センサー画像にもそのまま適用できる。46万枚の学習データで、タスク固有の再学習なしに6種のセンサーに汎化。
体験トークン化の進展ロードマップ(定量版)
モダリティ 年 手法 圧縮率 意味密度 実用精度
───────────────────────────────────────────────────────────────────────────
テキスト 2017〜 BPE / WordPiece 基準(1x) 最高 N/A(基準)
視覚 2020〜 ViT パッチトークン 1/196 高 CLIP: 76.2%
動作(粗) 2023 RT-2 (256-bin量子化) 1/1 中 成功率62%
動作(精) 2025 FAST (DCT+BPE) 1/10 高 同精度+5倍速
触覚 2024〜 Sparsh (ViTベース) 1/196 高 TacBench 95.1%
音声 2023〜 EnCodec (RVQ) 1/8 低 STT精度は高い
音声推論 未実現 — — — reasoning=0
核心的な気づき: 動作も触覚も、本質的には「画像または時系列の連続信号を離散トークンに変換する」問題です。視覚(ViT)で確立された手法がそのまま応用できる。音声も同じ連続信号ですが、「意味の連鎖」という追加要件があるため、単純なパッチ化・量子化では意味密度が上がらない——これが音声推論だけ遅れている理由です。
動作(連続信号)を離散トークンにする問題は、2年で実用レベルまで到達した。音声も同じ方向性で、ただし意味的な要件がより複雑なため、+2〜3年かかると見ます。
実装:現時点での音声品質向上の実践的アプローチ
待っていても仕方ない。現在できる最善の実装を示します。
import anthropic
import base64
client = anthropic.Anthropic()
def analyze_voice_with_context(audio_bytes: bytes, transcript: str) -> dict:
'''
音声推論が未実現でも、音声の特徴を並行分析することで品質向上
アプローチ:
1. 音声を文字起こし(既存STT)
2. 音声波形の特徴量を別途抽出(パワー、スペクトル重心など)
3. テキスト推論に特徴量をコンテキストとして追加
'''
# 音声特徴量の抽出(実際はlibrosaなどを使用)
# ここでは概念的に示す
audio_features = extract_audio_features(audio_bytes)
prompt = f'''
ユーザーの発話を分析してください。
文字起こし: {transcript}
音声特徴量(参考情報):
- 話速: {audio_features['speech_rate']} 音節/秒(通常: 5〜7)
- 音量変動: {audio_features['volume_variation']} (高い=感情的)
- 無音区間: {audio_features['pause_ratio']}% (高い=考えながら話している)
これらの情報から、ユーザーの状態と適切な返答を判断してください。
'''
response = client.messages.create(
model='claude-sonnet-4-6-2026-02-17',
max_tokens=1024,
messages=[{'role': 'user', 'content': prompt}],
)
return {
'analysis': response.content[0].text,
'audio_features': audio_features,
}
def extract_audio_features(audio_bytes: bytes) -> dict:
'''実際の実装ではlibrosaを使用'''
# librosa.feature.spectral_centroid, librosa.feature.rms, etc.
return {
'speech_rate': 6.2,
'volume_variation': 0.3,
'pause_ratio': 12.0,
}
音声トークンを推論に入れることはできなくても、音声から抽出した特徴量をテキストとして推論コンテキストに追加することで、音声固有の情報を部分的に活用できます。
まとめ:「音声で考えるAI」は来るのか
技術的に整理すると:
- 現状:音声はインターフェースとして使えるが、推論には参加できない(reasoning_tokens=0)
- 制約の本質:トークン密度の非対称性(10倍)・Test-Time Inverse Scaling・学習データ不足の3層構造
- 突破口:COCONUT(連続潜在空間推論)・周波数圧縮トークナイザ・ツール経由の音声分析
- 現実的な予測:ツール経由の「音声を推論に組み込む」は2026〜2027年、ネイティブ音声推論は2028〜2030年
答えは「来る」ですが、「テキストを完全に置き換える」形ではなく、テキスト推論に音声特徴量を組み込むハイブリッド方式が先に実用化されると見ます。
ロボティクスで動作トークン化が2年で実用化されたように、音声トークン化も研究の加速次第では予測より早まる可能性があります。
あなたのプロジェクトで音声を扱っているなら、今のうちに「音声特徴量のテキスト化」パイプラインを整備しておくことが、近い将来のネイティブ音声推論への移行を最もスムーズにする道だと思います。
FAQ
Q1. GPT-4o Realtimeはどうですか?
A: Realtime APIは低レイテンシの音声I/Oを実現していますが、推論(reasoning)はテキスト空間で行われます。音声→内部テキスト処理→音声のパイプラインで、reasoning_tokensはゼロです。
Q2. 音声のChain-of-Thoughtを自前で実装できますか?
A: STT→テキストCoT→TTS のパイプラインを「音声CoT」と呼ぶことはできますが、それは「テキストで考えてから音声に変換する」であり、本稿の定義する「音声トークンで推論する」とは異なります。前者は今すぐ実装可能です。
Q3. Moshiはどうですか?オープンソースで使えますか?
A: Kyutai研究所がモデルウェイトを公開しています(HuggingFaceで入手可能)。Inner Monologueアーキテクチャで高品質な音声対話を実現していますが、テキスト思考を介した設計である点は変わりません。日本語対応は限定的です。
Q4. TalkManeはこの制約にどう対処していますか?
A: 現在はGemini Live APIの音声I/Oを活用しながら、音声特徴量(話速・ポーズ・エネルギー)を別途抽出してコンテキストに追加する方式を検討中です。完全な音声推論の実現を待つのではなく、現時点で最善のアプローチを取り続けています。
参考文献
-
Wei et al., "Chain-of-Thought Prompting Elicits Reasoning in Large Language Models", NeurIPS 2022. https://arxiv.org/abs/2201.11903 ↩
-
minimaxir, "gpt-4o-audio-tests" (GPT-4o Audio APIのreasoning_tokens=0を確認). https://github.com/minimaxir/gpt-4o-audio-tests/blob/main/gpt-4o-audio-tests.ipynb ↩
-
Gemini Live API capabilities guide – Native Audio + thinking の動作説明. https://ai.google.dev/gemini-api/docs/live-guide ↩
-
Zeng et al., "CESAR: Incentivizing Consistent, Effective and Scalable Reasoning Capability in Audio LLMs via Reasoning Process Rewards", arXiv:2510.20867, 2025. https://arxiv.org/abs/2510.20867 ↩
-
Kuan-Po Huang et al., "Thinking with Sound: Audio Chain-of-Thought Enables Multimodal Reasoning in Large Audio-Language Models", arXiv:2509.21749, 2025. https://arxiv.org/abs/2509.21749 ↩
-
Alexandre Défossez et al., "Moshi: a speech-text foundation model for real-time dialogue", Kyutai, arXiv:2410.00037, 2024. https://arxiv.org/abs/2410.00037 ↩
-
Hao et al., "Training Large Language Models to Reason in a Continuous Latent Space (COCONUT)", Meta FAIR, arXiv:2412.06769, 2024. https://arxiv.org/abs/2412.06769 ↩
-
Pertsch et al., "FAST: Efficient Action Tokenization for Vision-Language-Action Models", Physical Intelligence, arXiv:2501.09747, 2025. https://arxiv.org/abs/2501.09747 ↩ ↩2
-
Brohan et al., "RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control", Google DeepMind, 2023. https://robotics-transformer2.github.io/ ↩
-
Suresh et al., "Sparsh: Self-supervised touch representations for vision-based tactile sensing", Meta FAIR, arXiv:2410.24090, 2024. https://arxiv.org/abs/2410.24090 ↩