はじめに
次の投稿で、非連続回帰デザインをベイズでモデリングする予定なのですが、その前座として、回帰分断デザイン(RDD)をPythonで実行しました。
データセット
補講授業とテストの点数のデータセット
学生のテストの点数(春)と、テストの点数(秋)がある。春のテストの点数が60点以下の生徒は、補講を受けている。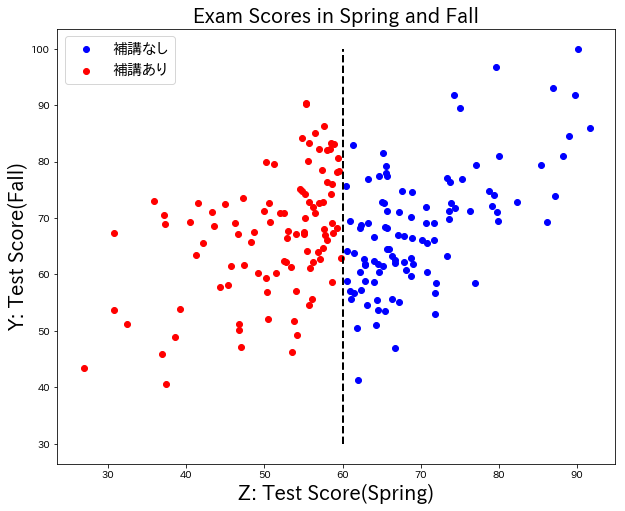
目的
補講授業による点数上昇の効果を見たい。
方法
単純に、補講を受けた生徒、受けていない生徒の平均値の比較等を行うことはできない(補講の効果が、点数が高い生徒と点数が低い生徒で同一に現れるとは考えにくく、何かしらのバイアスを含んでいると考えられるから)。
そこで、今回はRDDを行う。
方法は単純。
①補講を受けた生徒、受けていない生徒のそれぞれで単回帰を行う。
②60点付近での単回帰の差分を求める(60点付近の生徒であれば、生徒の背景が揃っていると考えられるため)。
結果
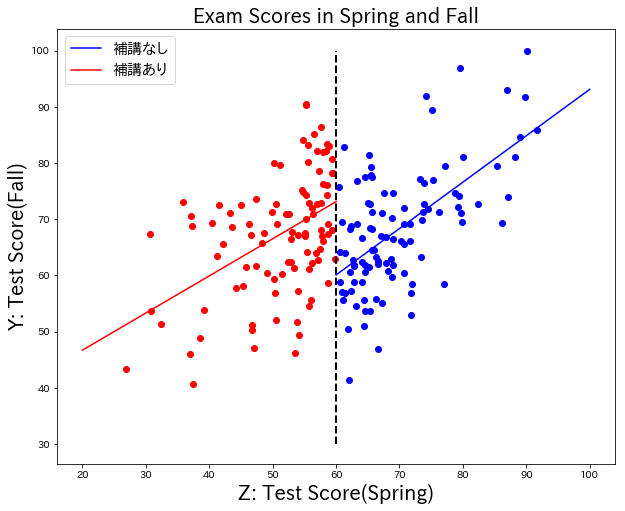
補講を受けた生徒、受けていない生徒のそれぞれで回帰を引くと、このような結果になった。
60点前後での回帰直線の差は、13.04だった。
結論
補講を受けると成績が上がる。
補講を受けることによる効果は、大体13点くらい点数を上げる効果がありそう。
コード
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn import linear_model
%matplotlib inline
exam_score = pd.read_csv("../Desktop/exam_score.csv")
# 補講を受けていない生徒に単回帰
exam_score_0 = exam_score[exam_score["T"] == 0.0]
X_0 = exam_score_0["Z"].reshape(-1, 1)
Y_0 = exam_score_0["Y"].as_matrix()
clf = linear_model.LinearRegression(fit_intercept=True, normalize=False, copy_X=True, n_jobs=1)
clf.fit(X_0, Y_0)
coef_0 = clf.coef_
intercept_0 = clf.intercept_
# 補講を受けた生徒に単回帰
exam_score_1 = exam_score[exam_score["T"] == 1.0]
X_1 = exam_score_1["Z"].reshape(-1, 1)
Y_1 = exam_score_1["Y"].as_matrix()
clf1 = linear_model.LinearRegression(fit_intercept=True, normalize=False, copy_X=True, n_jobs=1)
clf1.fit(X_1, Y_1)
coef_1 = clf1.coef_
intercept_1 = clf1.intercept_
# 補講の効果を算出
print((coef_1[0] * 60 + intercept_1) - (coef_0[0] * 60 + intercept_0))
# 直線を引く
x1 = list(range(20, 70, 10))
x0 = list(range(60, 110, 10))
y1 = [coef_1[0] * i + intercept_1 for i in x1]
y0 = [coef_0[0] * i + intercept_0 for i in x0]
# グラフ
fig = plt.figure(figsize = (10, 8))
# FigureにAxesを1つ追加
ax = fig.add_subplot(111)
ax.plot(x0, y0, color = "blue")
ax.plot(x1, y1, color="red")
ax.scatter(X_0, Y_0, color="blue")
ax.scatter(X_1, Y_1, color="red")
ax.vlines(60, 30, 100, linestyle='dashed', linewidth=2)
ax.set_ylabel("Y: Test Score(Fall)", fontsize=20)
ax.set_xlabel("Z: Test Score(Spring)",fontsize=20)
ax.set_title("Exam Scores in Spring and Fall", fontsize=20)
ax.legend(["補講なし", "補講あり"], fontsize=15)
参考ページ
Rで回帰分断デザイン
https://qiita.com/saltcooky/items/b7cb016498d2dd7b327e