謝意
注意!!!
この記事は完全にやらかしています
ストックしてくれた人、申し訳ないです。
@hal27 様の指摘で気づくことができました、ありがとうございます。
・やらかしたこと
スクレイピング段階から致命的なミスを犯しました。
レース時点から前走3レース分のデータを取得していたつもりですが、実はスクレイピング実行時刻から最新の3レース分の情報を取得していました。
ただ、前走の情報を全く使わずに予測したところ、平均して90%ほどの回収率だったので、
正しいデータを使っても、100%は超えれるんじゃないかと思っています。
やり直します!
この記事はやらかしちゃっててるんだなと思いながら見て下さい。(特に前走情報のスクレイピング部分に気を付けてください)
はじめに
最近データ分析にはまっています。
データ分析コンペのKaggleをやっていて、私がよく思うのは**「売上予測?もっと面白いテーマはないのかい?**」です。
そんなわけで、勉強も兼ねて一から競馬予測モデルを作ることにしました。上手くいけば金儲けもできるし、競馬好きの私にとっては最高の分析テーマです。
ほぼ初心者ですが、結果として**回収率が安定して100%**を超えるようなモデルが作成できたので、この記事では、競馬モデル作成までのおおざっぱな流れと、シミュレーション結果の詳細について記載していきます。考え方でおかしなところがあればご指導お願いします。
条件設定
出走馬の走破タイムを予測し、最も速いタイムの馬に単勝掛けします。
巷では、1着の馬の的中率を挙げるようなモデルが多かったですが、回収率が思うように伸びてないようなものが多かったように思います。それならば、純粋にタイムを予測してから賭けると、いい感じになるかも?**(暴論)**と思い、この設定にしました。
本当は他にも理由がありまして.....
競馬では、人気馬は能力値以上に多くの人が賭けてしまうそうです。(参考:人気馬を軸にしたら勝てない理論)
つまり、1着的中率を追求するより、オッズにも目を向けて予想することで回収率を上げれるのかもしれません。
ただ、私は余裕をもって馬券を買いたいので、レース直前に確定するオッズを特徴量に組み込みたくないのです。
どうしようかな...
競馬は様々な要因が絡むので、純粋に走破タイムを予測するのは困難です。困難だからこそ、人が賭けないような期待値の高い馬を予測してくれるのではないか?(暴論)。よし、走破タイムで行こう。
学習対象とシミュレーション対象
京都に住んでいるので、京都競馬のみを対象としました。データは、2009年から2019年までのほぼ全レース(データの前処理の項で説明します)とします。
それらを学習用データとテスト用データに分けて、テストデータに対してシミュレーションを行いました。合計で7年分のシミュレーションです。
以下はデータ分割の内容です。
| 学習用データ | テスト用データ |
|---|---|
| 2009~2018 | 2019 |
| 2009~2017 | 2018 |
| 2009~2016 | 2017 |
| 2009~2015 | 2016 |
| 2009~2014 | 2015 |
| 2009~2013 | 2014 |
| 2009~2012 | 2013 |
万が一リークする場合も考え、学習データはテストデータより前の年にしています。
扱った特徴量の詳細は以下で説明します。
モデル作成までの流れ
- データの取得(webスクレイピング)
- データの前処理
- モデル作成
1. データの取得
お金を払えばデータを簡単に取得できそうですが、勉強も兼ねてwebスクレイピングでデータを取得しました。
まずはHTML・CSSをProgateで簡単に勉強です。最低限知識がないとどこに欲しいデータがあるかわからなかったからです。
WEBスクレイピングに関しては、以下の記事を参考に作成しました。正直ここが一番大変だった気がします。(例外処理が多すぎる!)
スクレイピング対象のサイトは https://www.netkeiba.com/ です。
以下は実際にスクレイピングして得たデータです。コードは付録に載せています。
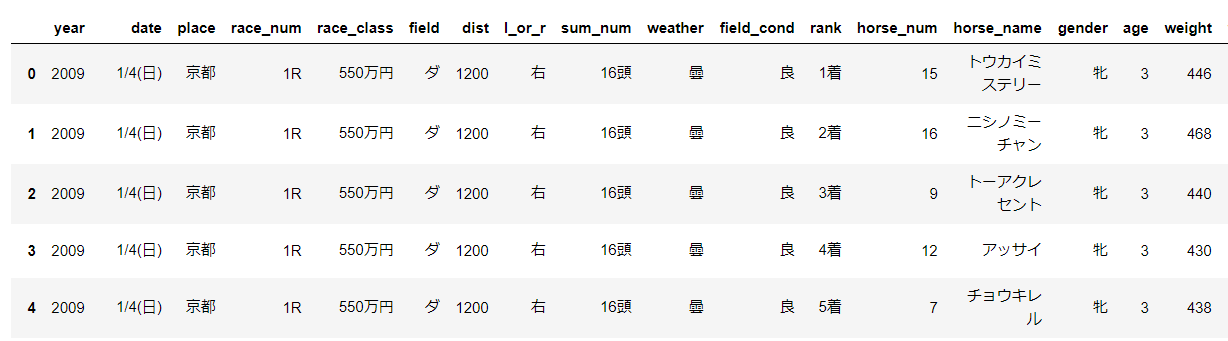
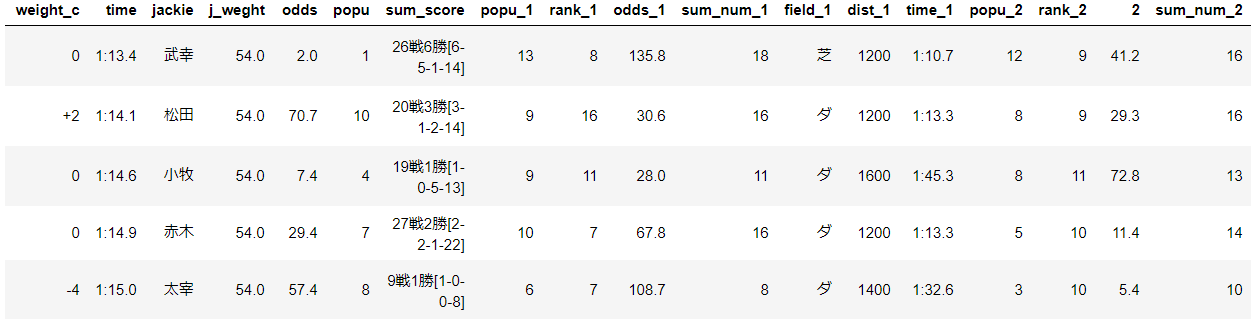
取得したデータは以下の通りです
| feature | 説明 | feature | 説明 |
|---|---|---|---|
| race_num | 第何レース | field | 芝かダートか |
| dist | 距離 | l_or_r | 右回りor左回り |
| sum_num | 頭数 | weather | 天候 |
| field_cond | 馬場状態 | rank | 着順 |
| horse_num | 馬番 | horse_name | 馬名 |
| gender | 性別 | age | 年齢 |
| weight | 馬の体重 | weight_c | 騎手の体重 |
| time | 走破タイム | sum_score | 通算成績 |
| odds | 単勝オッズ | popu | 人気 |
+で前走3レース分のデータを得ています。
この中で、走破タイム、着順、オッズ、人気、馬名の特徴量は学習データとして使っていません。
また、**前走3レース分ない馬については情報を削除しています。**しかし、各レースで一頭でも情報が残っていれば、その中で一番早い馬を予測します。当然、消し去ったデータに一着馬がいれば予想は外れることになります。
一年あたり大体450レース分のデータが残ります。(ほぼ全レース)
2. データの前処理
得られたデータを機械学習モデルに入れられるように変換します。といっても、カテゴリ変数をラベルエンコーディングしたり、文字型を数値型に変化しただけです。
今回扱うモデルのアルゴリズム木モデルの一種なので、標準化などは行っていません。
また、取得した特徴量を使って、新たな特徴量を何個か作っています。(距離とタイムから速さなど)
3. モデル作成
勾配ブースティング決定木アルゴリズムのLightGBMライブラリを使用して実装しました。Kaggleなんかで最近よく使われているあれです。
以下は実装コードです。
lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_valid, y_valid, reference=lgb_train)
params = {'objective': 'regression',
'metric': 'rmse',
}
model = lgb.train(
params, lgb_train,
valid_sets=[lgb_train, lgb_eval],
verbose_eval=10,
num_boost_round=1000,
early_stopping_rounds=10)
御覧の通り何の工夫も行っていません(笑)
Optunaなどを使ってパラメータチューニングを行ってみたのですが、いかんせん評価関数と回収率は別ものなので、回収率向上にはそれほどつながりませんでした。
シミュレーション
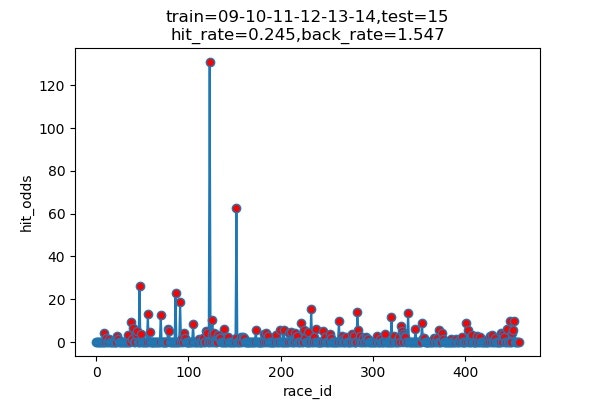
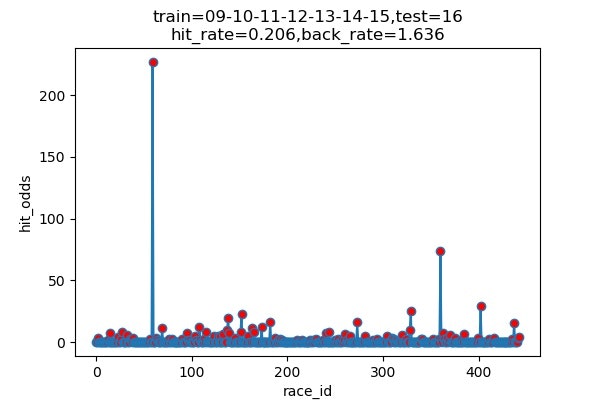
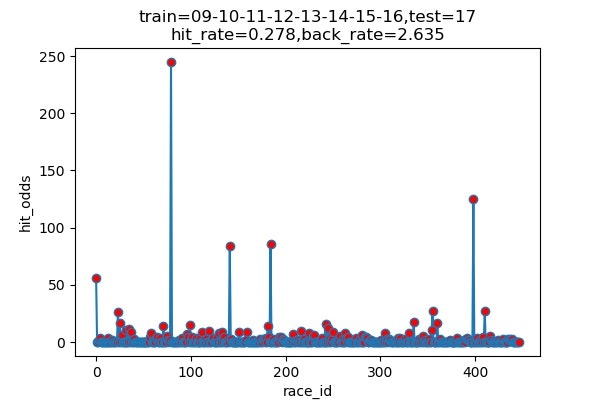
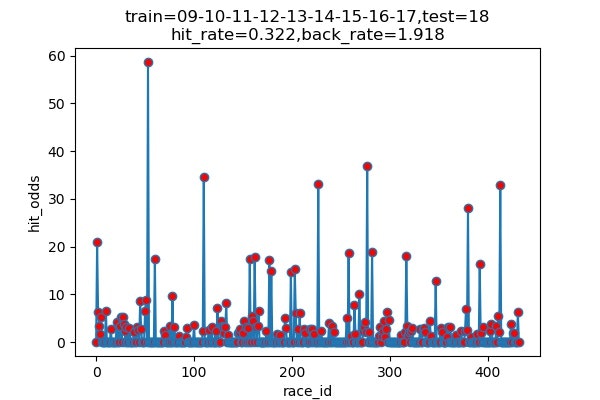
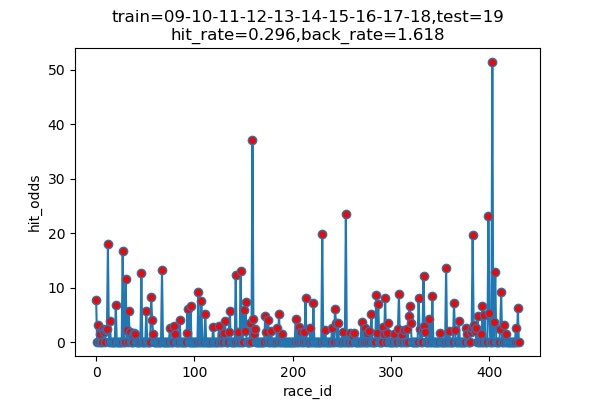
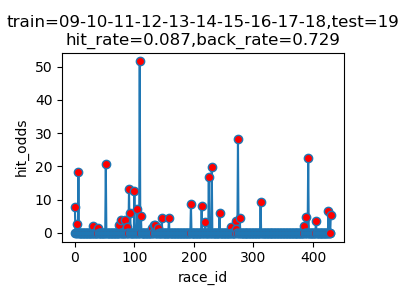
以下は7年分のシミュレーション結果です
横軸 : 何レース目か
縦軸 : 的中した場合の単勝オッズ(外れた場合は0)
hit_rate : 的中率
back_rate : 回収率
titleのtrainとtestはそれぞれに使ったデータの期間を表しています。(09は2009年)
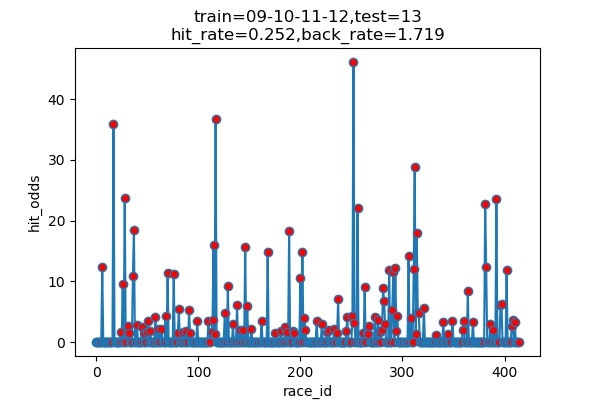
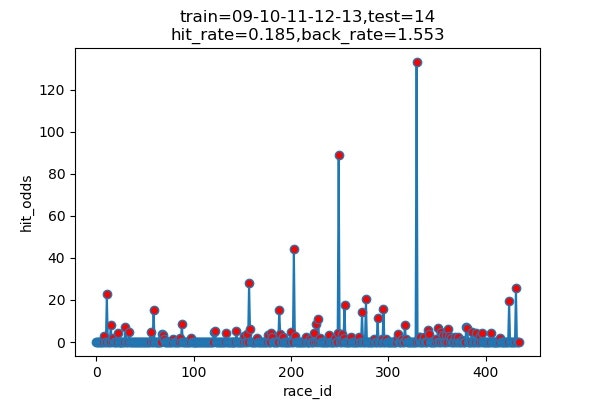
以下に結果をまとめます
| シミュレーション年度 | 的中回数 | 的中率 | 回収率 |
|---|---|---|---|
| 2013 | 116/460 | 25.2% | 171.9% |
| 2014 | 89/489 | 18.5% | 155.3% |
| 2015 | 120/489 | 24.5% | 154.7% |
| 2016 | 101/491 | 20.6% | 163.6% |
| 2017 | 131/472 | 27.8% | 263.5% |
| 2018 | 145/451 | 32.2% | 191.8% |
| 2019 | 136/459 | 29.6% | 161.7% |
| 平均 | ------ | 25.5% | 180.4% |
上出来すぎです。
的中率はまあまあですが、驚いたのは、オッズの高い馬をちょくちょく当ててきていることです。
2017年には、250倍の馬当ててるし!
気になるので、中身を見てみましょう
以下はその日のレースの内容です。(time_pred順にsortしています)
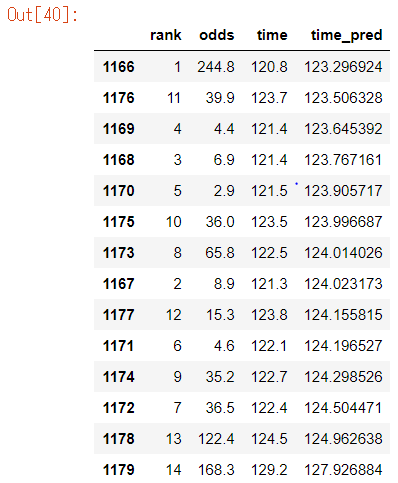
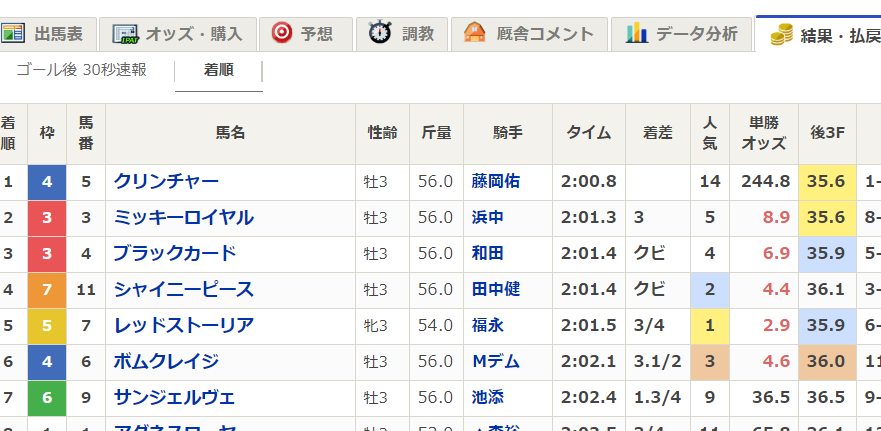
マジで当ててる。
何か間違っているのではないかと怖くなってきました。そもそもこんな簡単に100%を超えてしまっていいのでしょうか。
こういう時は何を調べたら、正しいといえるのでしょうか.....
リアルでやってみるしかないですね!
以下は一応探ってみたことです。
・当日に使える特徴量だけを使っているか
・回収率の計算式は合っているか
・ネットの情報と齟齬はないか?
・予想タイムが最も早い者を選択できているか
・作成モデルを様々な方向から遊んでみる
モデルで遊んでみた
折角なのでいろいろ検証してみます。
1 一番遅いと予測した馬をかけてみる
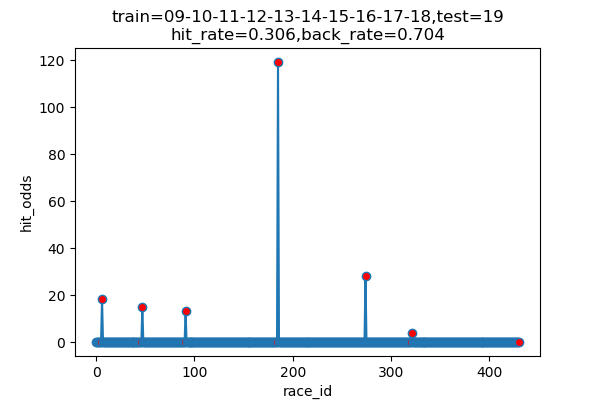
6回だけ当てています。
2 特徴量の重要度
以下はlightGBMのfeature-importannces(2019)です。
a,b,cはそれぞれ前走、前々走、前前々走の馬の速さ(dist/time)です。
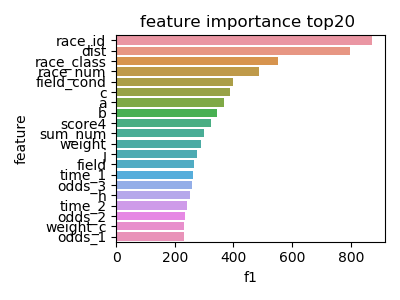
タイムを予測しているのでdist(レース距離)が重要なのはわかりますが、race_id(その年の何レース目か)が重要なのははて?
季節をタイムを予測するのに重要なのでしょうか。
他にもrace_cond(馬場状態),race_num(その日第何レース)など、環境が大きな重要度を占めています。
※追記を書きました。(2020/05/28)
3 n番人気をかけ続けるとどうなるか?
作成したモデルとは一切関係ありません(笑)
以下は2019年度の結果です
| n番人気 | 的中率 | 回収率 |
|---|---|---|
| 1番人気 | 30.9% | 71.1% |
| 2番人気 | 17.3% | 77.2% |
| 3番人気 | 15.3% | 90.3% |
| 4番人気 | 10.1% | 81.3% |
| 5番人気 | 8.4% | 100.5% |
| 6番人気 | 6.2% | 92.4% |
| 7番人気 | 3.2% | 64.2% |
| 8番人気 | 2.4% | 52.1% |
| 9番人気 | 1.5% | 48.2% |
| 10番人気 | 1.3% | 59.1% |
| 11番人気 | 1.5% | 127.6% |
| 12番人気 | 1.3% | 113.9% |
| 13番人気 | 1.5% | 138.6% |
| 14番人気 | 0.4% | 77.8% |
とても面白い結果です
回収率を狙うなら不人気馬を買い続けるのもありですね。
ほとんど当たらないので見ていても楽しくなさそうですが(笑)
面白いので2013~2019年の平均で見てみました。
| n番人気 | 的中率 | 回収率 |
|---|---|---|
| 1番人気 | 31.7% | 73.4% |
| 2番人気 | 20.0% | 83.7% |
| 3番人気 | 13.2% | 80.2% |
| 4番人気 | 9.9% | 81.9% |
| 5番人気 | 7.8% | 89.1% |
| 6番人気 | 5.5% | 89.8% |
| 7番人気 | 4.2% | 86.0% |
| 8番人気 | 2.4% | 64.8% |
| 9番人気 | 2.1% | 64.8% |
| 10番人気 | 1.7% | 80.9% |
| 11番人気 | 1.1% | 98.2% |
| 12番人気 | 1.0% | 69.4% |
| 13番人気 | 1.1% | 113.2% |
| 14番人気 | 0.2% | 35.4% |
| ※取得できたデータのみで行った検証なので注意 |
面白い
まとめ
ほぼ工夫無しで、回収率100%超えられる
lightGBMすごい
付録
汚いコードですがご了承ください。
・スクレイピング(レース情報と各馬のURLの取得)
def url_to_soup(url):
time.sleep(1)
html = requests.get(url)
html.encoding = 'EUC-JP'
return BeautifulSoup(html.text, 'html.parser')
def race_info_df(url):
df1 = pd.DataFrame()
HorseLink = []
try:
# year = '2018'
# url = 'https://race.sp.netkeiba.com/?pid=race_result&race_id=201108030409&rf=rs'
soup = url_to_soup(url)
if soup.find_all('li',class_='NoData') != []:
return df1,HorseLink
else:
race_cols = ['year', 'date', 'place', 'race_num' ,'race_class', 'field', 'dist', 'l_or_r',\
'sum_num','weather', 'field_cond', 'rank', 'horse_num', 'horse_name', 'gender', 'age',\
'weight', 'weight_c', 'time', 'jackie', 'j_weght', 'odds', 'popu']
# 共通項目 #
# Year = year
Date = soup.find_all('div', class_='Change_Btn Day')[0].text.split()[0]
Place = soup.find_all('div', class_="Change_Btn Course")[0].text.split()[0]
RaceClass = soup.find_all('div', class_="RaceDetail fc")[0].text.split()[0][-6:].replace('、','')
RaceNum = soup.find('span', id= re.compile("kaisaiDate")).text
RaceData = soup.find_all('dd', class_="Race_Data")[0].contents
Field = RaceData[2].text[0]
Dist = RaceData[2].text[1:5]
l_index = RaceData[3].find('(')
r_index = RaceData[3].find(')')
LOrR = RaceData[3][l_index+1:r_index]
RD = RaceData[3][r_index+1:]
SumNum = RD.split()[0]
Weather = RD.split()[1]
FieldCond = soup.find_all('span',class_= re.compile("Item"))[0].text
# Not 共通 #
HorseLink = []
for m in range(int(SumNum[:-1])):
HN = soup.find_all('dt',class_='Horse_Name')[m].contents[1].text
HL = soup.find_all('dt',class_='Horse_Name')[m].contents[1].get('href')
HorseLink.append(HL if HN!='' else soup.find_all('dt',class_='Horse_Name')[m].contents[3].get('href'))
HorseName = []
for m in range(int(SumNum[:-1])):
HN = soup.find_all('dt',class_='Horse_Name')[m].contents[1].text
HorseName.append(HN if HN!='' else soup.find_all('dt',class_='Horse_Name')[m].contents[3].text)
# print(soup.find_all('dt',class_='Horse_Name')[m].contents[3])
Rank = [soup.find_all('div',class_='Rank')[m].text for m in range(int(SumNum[:-1]))]
# ここから得られる情報も獲得
HorseNum = [soup.find_all('td', class_ = re.compile('Num Waku'))[m].text.strip() for m in range(1,int(SumNum[:-1])*2+1,2)]
Detail_Left = soup.find_all('span',class_='Detail_Left')
Gender = [Detail_Left[m].text.split()[0][0] for m in range(int(SumNum[:-1]))]
Age = [Detail_Left[m].text.split()[0][1] for m in range(int(SumNum[:-1]))]
Weight = [Detail_Left[m].text.split()[1][0:3] for m in range(int(SumNum[:-1]))]
WeightC = [Detail_Left[m].text.split()[1][3:].replace('(','').replace(')','') for m in range(int(SumNum[:-1]))]
Time = [soup.find_all('td', class_="Time")[m].contents[1].text.split('\n')[1] for m in range(int(SumNum[:-1]))]
Detail_Right = soup.find_all('span',class_='Detail_Right')
Jackie = [Detail_Right[m].text.split()[0] for m in range(int(SumNum[:-1]))]
JWeight = [Detail_Right[m].text.split()[1].replace('(','').replace(')','')for m in range(int(SumNum[:-1]))]
Odds = [soup.find_all('td', class_="Odds")[m].contents[1].text.split('\n')[1][:-1] for m in range(int(SumNum[:-1]))]
Popu = [soup.find_all('td', class_="Odds")[m].contents[1].text.split('\n')[2][:-2] for m in range(int(SumNum[:-1]))]
Year = [year for a in range(int(SumNum[:-1]))]
RaceCols = [Year, Date, Place, RaceNum ,RaceClass, Field, Dist, LOrR,\
SumNum,Weather, FieldCond, Rank, HorseNum, HorseName, Gender, Age,\
Weight, WeightC, Time, Jackie, JWeight, Odds, Popu]
for race_col,RaceCol in zip(race_cols,RaceCols):
df1[race_col] = RaceCol
return df1,HorseLink
except:
return df1,HorseLink
・スクレイピング(各馬の今までのレース情報)
def horse_info_df(HorseLink, df1):
df2 = pd.DataFrame()
# print(HorseLink)
for n,url2 in enumerate(HorseLink):
try:
soup2 = url_to_soup(url2)
horse_cols = ['sum_score',\
'popu_1','rank_1','odds_1','sum_num_1','field_1','dist_1','time_1',\
'popu_2','rank_2','2','sum_num_2','field_2','dist2','time_2',\
'popu_3','rank_3','odds_3','sum_num_3','field_3','dist_3','time_3']
sec = 1
ya = soup2.find_all('section',class_="RaceResults Sire")
#ya = soup.find_all('div',class_="Title_Sec")
if ya !=[]:
sec = 2
tbody1 = soup2.find_all('tbody')[sec]
SomeScore = tbody1.find_all('td')[0].text
# print(SomeScore)
tbody3 = soup2.find_all('tbody')[2+sec]
HorseCols = [SomeScore]
for late in range(1,4):
HorseCols.append(tbody3.contents[late].find_all('td')[2].text) # Popu
HorseCols.append(tbody3.contents[late].find_all('td')[3].text) # Rank
HorseCols.append(tbody3.contents[late].find_all('td')[6].text) # Odds
HorseCols.append(tbody3.contents[late].find_all('td')[7].text) # SumNum
HorseCols.append(tbody3.contents[late].find_all('td')[10].text[0]) # Field
HorseCols.append(tbody3.contents[late].find_all('td')[10].text[1:5]) # Dist
HorseCols.append(tbody3.contents[late].find_all('td')[14].text) # Time
dfplus = pd.DataFrame([HorseCols], columns=horse_cols)
dfplus['horse_name'] = df1['horse_name'][n]
df2 = pd.concat([df2,dfplus])
except:
pass
return df2
追記
特徴量の重要度に関する考察 (2020/05/28)
feature-importancesでrace_idの重要度が高いことへの考察をします。
まず、次の2ステップからrace_idの重要度が高く見積もられていることがわかります。
1 race_idがない場合とある場合で比較
'race_id'の特徴量を消した場合、7年間すべての年で、回収率が10%程、testに対するrmseが0.1程悪くなりました。
このことから、race_idの特徴量が必要であることがわかります。
2 2番目に重要度の高いdistで1と同じことを行う
かなり予測精度が悪くなっていることがわかります。
1.2からrace_idの重要度が、現状より大きく見積もられていることがわかります。
<原因>
今回以下のようにランダムにvalid,trainを分けています。
X_train, X_valid, y_train, y_valid = train_test_split(X_train, y_train, test_size=0.3,\
random_state=0)
これにより、race_idがわかれば、おおよそのタイムがわかることになります。
以下は、試しにshuffle=Falseをいれて行ってみた結果です。
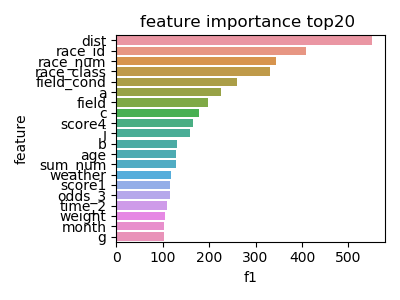
このようにrace_idの重要度は下がります。だたし、回収率やrmse'sがよくなることとは別次元のお話です。
現に悪くなりました。