
Web アプリケーションの稼働率をどう測るのがよいのか、実際に考えて仕組み化してみました。
稼働率というと HTTP の成功率や ALB の 5xx だけを見ればよさそうに思えますが、それだけでは「サービスが本当に使えているか」は判断しきれないことがあります。
たとえば、画面は表示できても、定期実行ジョブが止まっていたり、非同期処理が失敗していたりすると、利用者にとっては正常稼働とは言いづらい状態です。
この記事では、Web アプリケーションの基本的な稼働率の測定方法を整理しつつ、AWS を使って日次で集計する仕組みを実践した内容を紹介します。
まず結論
今回は、稼働率を次の3つで見ることにしました。
-
ALBが正常に応答しているか -
定期実行ジョブが定期実行されているか -
非同期処理が成功しているか
理由はシンプルで、この3つを見れば「入口」「内部処理の起点」「実際の結果」をざっくり押さえられるからです。
なぜ ALB だけでは足りないのか
最初は「ALB の 5xx を見れば十分では?」とも思いました。
でも、バッチ処理を伴うサービスではそれだけだと足りませんでした。
たとえば、
- 画面は開くけど定期実行ジョブが止まっている
- API は生きているけど非同期処理が失敗している
ということが普通に起こりえます。
利用者から見ると、これは「使える」とは言いづらいです。
なので、外から見える入口だけでなく、内部の定期処理と実処理も見ることにしました。
3つの指標をどう見ているか
1. ALB
ここはシンプルです。
5xx をサーバー要因の失敗として扱い、全リクエストに対する正常応答の割合を見ます。
計算イメージはこんな感じです。
(全リクエスト数 - 5xx件数) / 全リクエスト数
2. 定期実行ジョブ
サービスによっては、定期実行されるジョブが内部処理の起点になることがあります。
なので、このジョブが期待どおり動いていたかを見ます。
たとえば5分おきに動くなら、1日の期待回数は 288回 です。
そのため、考え方としてはこうです。
実施回数 / 288
これで「内部処理の起点がちゃんと動いていたか」が分かります。
3. 非同期処理
最後に、実際の非同期処理が成功したかを見ます。
ここは成功件数と失敗件数を集計して、成功率を出します。
成功件数 / 総実行件数
ここを見ておくと、「システムは動いていたけど肝心の処理は失敗していた」を拾いやすくなります。
失敗を全部同じ扱いにしない
もう1つ大事だったのがここです。
処理失敗の中には、
- システム側の問題
- 外部サービスの制限
- 利用者設定の問題
が混ざります。
これを全部まとめて稼働率低下に入れると、数字は作れても改善しにくくなります。
なので、「障害として数える失敗」と「運用上ありえるので除外する失敗」を分けて扱うようにしました。
この整理をしておくと、稼働率がただの報告用の数字ではなく、改善に使える数字になります。
日次集計の仕組み
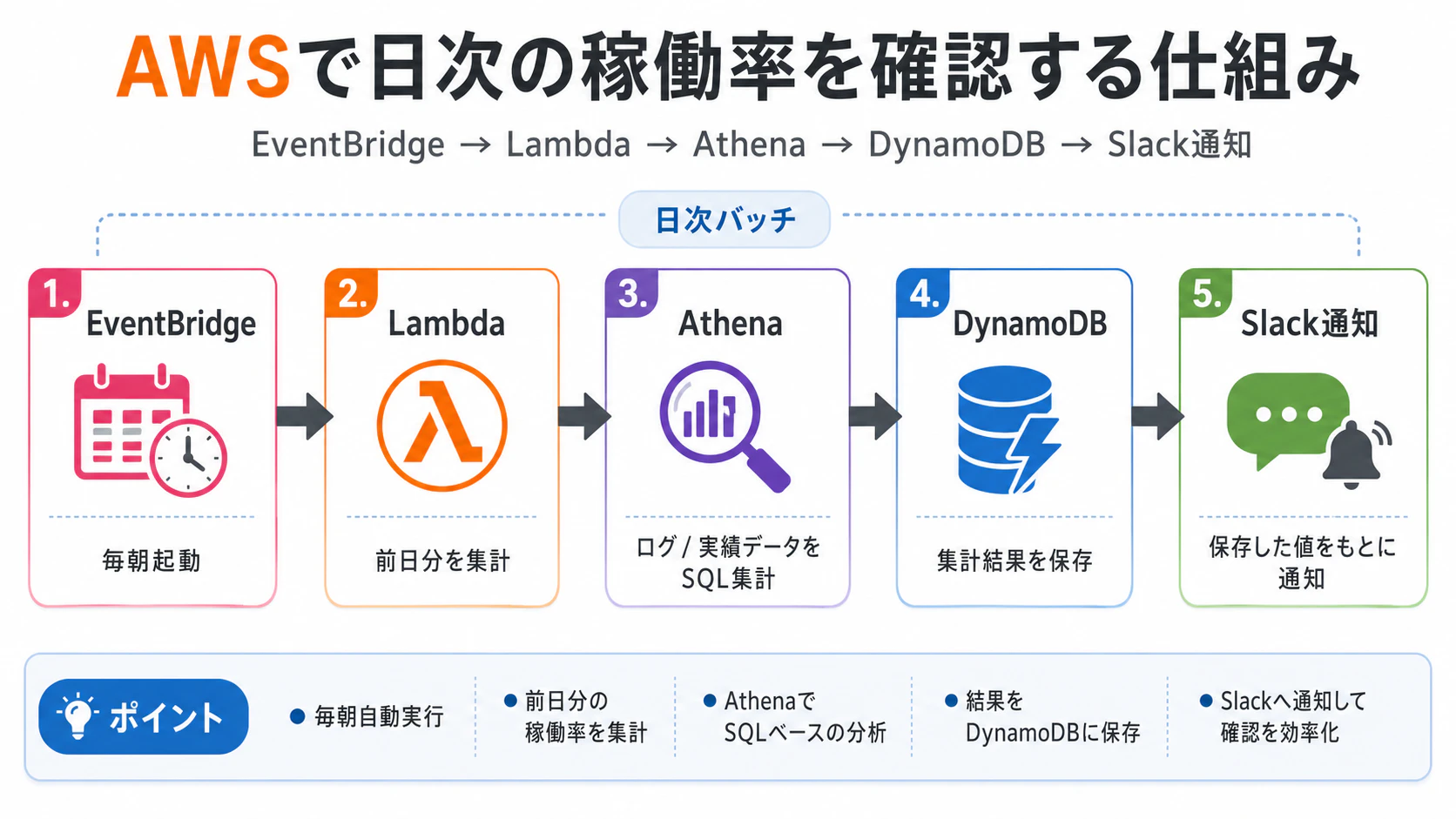
集計は AWS 上で日次実行しています。
構成はかなりシンプルで、
EventBridge -> Lambda -> Athena -> DynamoDB
という流れです。
-
EventBridgeで毎朝起動 -
Lambdaで前日分を集計 -
Athenaでログや実績データを SQL 集計 - 結果を
DynamoDBに保存 - 保存した値をもとに通知
という形にしました。
ログ集計を SQL で書けるので、あとから見返しやすいのもよかったです。
これで何がよくなったか
この形にしてから、稼働率が下がったときに
- 入口の問題なのか
- 定期実行ジョブの問題なのか
- 実際の非同期処理の問題なのか
を切り分けやすくなりました。
稼働率は「高いか低いか」だけ見てもあまり役に立ちません。
どこが落ちているのか分かる形にしておくと、改善につながりやすいです。
まとめ
今回やってみて、稼働率は「サーバーが落ちていないこと」だけでは測りきれないとあらためて感じました。
特に、バッチ処理を伴うサービスでは、
ALB定期実行ジョブ非同期処理
の3つを見るだけでも、かなり実態に近い数字になります。
もしこれから稼働率を整備するなら、まずは
「このサービスが使えている状態って何だろう?」
を決めるところから始めるのがよさそうです。