本稿では、自然言語処理の定番と言えるTransformerを使って、発話応答処理をKerasベースで実装してみます。
1. はじめに
かつて、機械翻訳やチャットボット、あるいは文章生成のような自然言語処理は、RNNを応用したSeq2Seq(Sequence to Sequence)で構築するのが主流でした。ところが、トム・クルーズ主演の映画のタイトルのような、あの論文の出現以来、それまで機械生命体を描くSFシリーズのタイトルとして、人口に膾炙していたその単語に、新たな意味が付与されることとなりました。
筆者も以前は、LSTMベースのSeq2Seqを色々試していましたが、今般遅ればせながら、Transformerによる発話応答処理の実装に、チャレンジしてみることにしました。
本稿執筆に当たっては、「作って理解する Transformer / Attention」と原論文「Attention Is All You Need」を参考にさせていただきました。
2. 本稿のゴール
以下の通りです。
- Transformerの構築と、訓練
- 応答文生成
また、実行環境は以下の通りです。
- ubuntu 16.04.7 LTS
- tensorflow-gpu 2.4.0
- NVIDIA GeForce GTX 1080Ti
- Cuda 11.0
- cuDNN 8.0.5
訓練用のデータは、名大会話コーパスなどから作成します。作成方法はこちらの記事をご参照ください。
なお、本稿に提示したソースは、Google Colaboratoryでも動作しないことはありませんが、メモリ的にかなり厳しいです。筆者も最初は、Google Colaboratory上で動かしていましたが、最終的にはローカルに環境を構築することにしました。
3. Transformerの仕組みと構造
こちらの記事にわかりやすくまとめられていますので、まずそちらを参照されることをお勧めします。また、原論文も大変読みやすく、こちらもお勧めです。
Transformerの主な特徴は、以下の通りです。
- 主要な処理は論文のタイトル通り、本当にAttentionのみ(正確には、Normalizationもあるが)
- Seq2Seqと同じように、encoderとdecoderがある
- 入力文それ自体のAttentionをエンコード/デコード処理に用いる、いわゆるSelf-Attentionというものがある(おそらくこれがキモ)
- 主要部分を、複数回繰り返す構造になっている。このため、パラメータの規模の割には構造は単純
3-1. 基本構成
以下に、全体構造のイメージを示します。上述の通り、Attention処理を含む主要部分を、複数回繰り返す構造になっています。
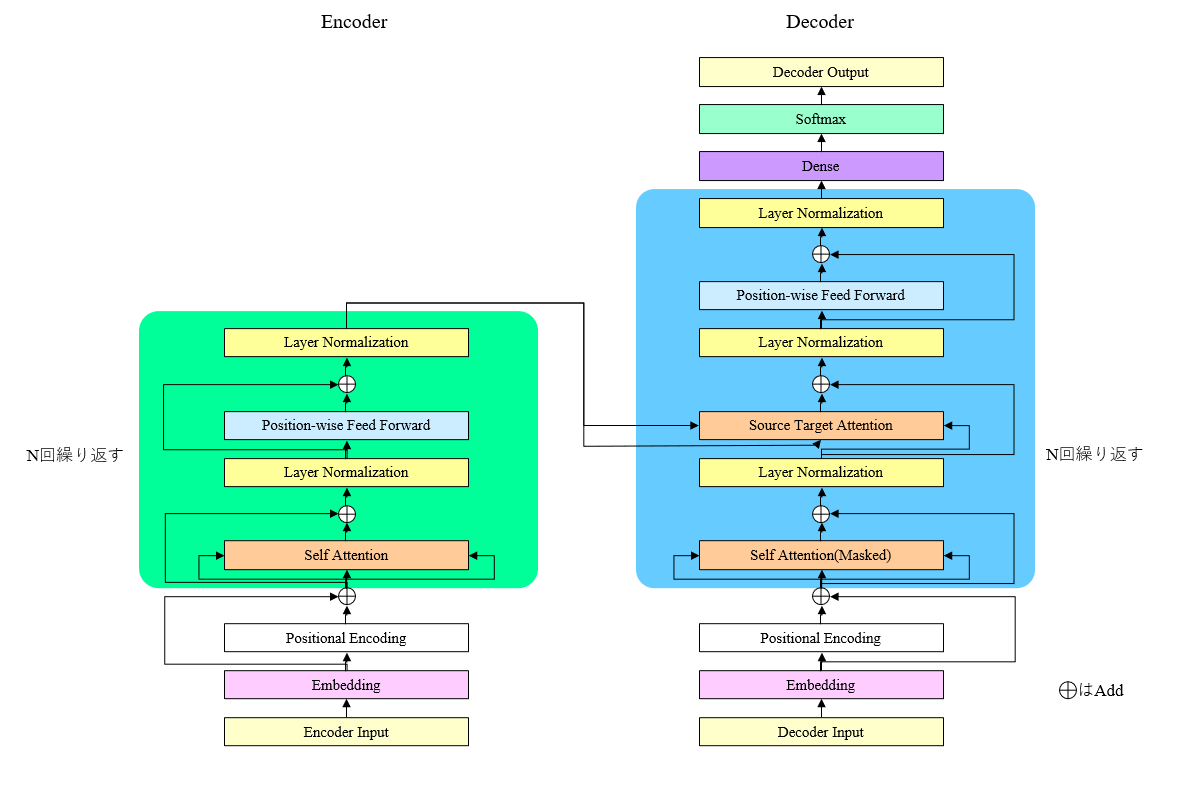
3-2. 主要構成要素の説明
3-2-1. Positional Encoding
RNNは時系列方向に逐次的に処理していくため、モデル構成の中に時間経過に関する情報を、自ずと含むことになります。ところが、TransformerにはDenseやNormalizationなど、時系列方向に関する区別はせずに、一括で処理するレイヤしかありません。
Positional Encodingは、Transformerのモデルに時系列情報を持たせるための処理です。入力データをエンコードして得られた埋め込みベクトルの各値に対し、時系列内のそれぞれの位置(要は、文章内の何番目の単語か)と、埋め込みベクトルの次元に応じて、異なる重みを足しこみます。
重みの値は入力値とは無関係に、時系列の位置と、埋め込みベクトルの次元のみによって決まります。
3-2-2. Self Attention
Attentionとは自然言語処理において、入力文章から出力文章を生成する際に、入力文章のどの単語によりフィーチャーするかを、訓練によって決定する仕組みのことです。
具体的には、入力文章のエンコーダ出力として得られる、隠れ層ベクトル系列の線形結合を、デコーダ出力の隠れ層ベクトルに足しこみます。このとき、エンコーダ出力の線形結合の係数も訓練の対象なので、入力文章のどの単語を重視するかが、訓練によって自動的に決まります。
AttentionにはQuary、Key、Valueの3つの入力がありますが、実質的には入力は2種類で、デコーダ出力がQuaryに、エンコーダ出力がKeyとValueに、それぞれ対応します。
Self Attentionとは、3つの入力のすべてに同じ隠れ層ベクトル系列を入力させるというもので、これにより、文章内の各単語が他のどの単語と関係が深いかを、学習することができます。
ただし、デコーダでこれをやってしまうと、本来わからないはずの、未来に現れる単語の情報が、出力単語決定の際に見えてしまうことになります。この「カンニング」を防ぐため、デコーダ側のSelf Attentionでは、下三角行列型のマスキングをします。
3-2-3. Source Target Attention
Source Target Attentionは、普通の意味でのAttentionです。Quaryとしてデコーダ出力が、KeyおよびValueとしてエンコーダ出力が、それぞれ入力されます。
3-2-4. Position-wise Feed Forward Network
2層のDenseすなわち線形変換から構成されています。ポイントは、各系列ごとに、別の重みをもっているところです。1番目の単語と2番目の単語と3番目の単語には、それぞれ別のDenseが割り当てられます(だから「Position-wise」)。
ただし、複数回の主要処理の繰り返しにおいて、Position-wise Feed Forward Networkの重みは共通です。主要処理を6回繰り返す場合でも、1番目の単語の重みは、1種類です。
Transformerの一連の処理において、Position-wise Feed Forward Networkが、最も多くのメモリを消費します。
3-3. その他の実装上のトピック
3-3-1. Scaled Dot-Product Attention
Attetionにおける線形結合の係数は、softmaxで算出されますが、訓練時に勾配が0になりにくくするため、softmaxの計算時に、各値を隠れ層次元数の平方根で割ります。
3-3-2. Multi-Head Attention
Quary、Key、Valueの各テンソルを、隠れ層次元の方向にいくつかに「小分け」し、小分けした単位でAttentionを実行したうえで、最後にConcatenateします。こうしたほうが、訓練が進みやすくなるそうです。
3−3−3. Embedding
原論文には、Embeddingレイヤの各パラメータに、隠れ層次元数の平方根をかけると書いてありましたが、今回の実装では、Embeddingレイヤの出力結果に、隠れ層次元数の平方根をかけてあります。
3−3−4. 学習率減衰
推定誤差低減のため、学習率減衰処理を導入します。今回の実装では、参考記事に従って、ウォームアップ処理を追加しました。
4. ソースコード
作成したソースコードは以下の通りです。
| ファイル名 | 説明 |
|---|---|
| 1000_train.py | 訓練実行処理 |
| 2000_response.ipynb | 応答文生成処理 |
| transform.py | ニューラルネットワークのクラス定義 |
| transform_encoder.py | ニューラルネットワークのうち、エンコーダ部分の定義 |
| transform_decoder.py | ニューラルネットワークのうち、デコーダ部分の定義 |
| transform_pos_enc.py | ニューラルネットワークのpositional encoding処理定義 |
| transform_attention.py | ニューラルネットワークのattention処理定義 |
| transform_triangle.py | ニューラルネットワークのself-attention下三角行列マスキング処理 |
| transform_ffn.py | ニューラルネットワークのposition-wise feed forward network処理定義 |
| transform_lr.py | ニューラルネットワークの学習率減衰処理定義 |
| transform_layers.py | ニューラルネットワークのレイヤ定義 |
| transform_loss.py | 損失関数、評価関数定義 |
| transform_train.py | ニューラルネットワークの訓練処理 |
ノートブック形式の1000_train.ipynbを実行すると、ニューラルネットワークの訓練が始まります。2000_response.ipynbを実行すると、入力文に対する応答文の生成を、対話形式で行うことが出来ます。これらの2ファイルは、好きな名称を付与して構いません。
transform.pyはこれらのプログラムからimportされることで動作します。これ単独で動かすことはありません。その他のファイルもすべて、別のプログラムからimportされて動作します。それらの呼び出し関係は以下の通りです。
transform.py ─┬─ transform_encoder.py ─┬─ transform_attention.py ─── transform_layers.py
| └─ transform_ffn.py ───────── transform_layers.py
├─ transform_decoder.py ─┬─ transform_attention.py ─┬─ transform_layers.py
| | └─ transform_triangle.py
| ├─ transform_ffn.py ───────── transform_layers.py
| └─ transform_layers.py
├─ transform_layers.py
├─ transform_pos_enc.py
├─ transform_lr.py
├─ transform_loss.py
└─ transform_train.py
これらのファイルはすべて、同一のフォルダに配置してください。
以下、各ファイルのソースコードです。
4−1. 訓練実行処理(1000_train.py)
コマンドラインから実行します。指定パラメータはエポック数、バッチサイズ、パラメータファイル名の3つです。以下に実行例を示します。
$ python 1000_train.py 100 50 param_001
ソースコードはこちらです。
クリックして表示
# coding: utf-8
# インポート宣言
# In[1]:
from transform import Dialog
import numpy as np
import csv
import random
import numpy.random as nr
import sys
import math
import time
import pickle
import gc
import os
import codecs
import argparse
# データロード
# In[ ]:
# *******************************************************************************
# *
# 訓練データ、ラベルデータ等をロードする *
# *
# *******************************************************************************
def load_data() :
#単語ファイルロード
with open('words.pickle', 'rb') as ff :
words=pickle.load(ff)
#Encoder Inputデータをロード
with open('e.pickle', 'rb') as f :
e = pickle.load(f)
#Decoder Inputデータをロード
with open('d.pickle', 'rb') as g :
d = pickle.load(g)
#ラベルデータをロード
with open('t.pickle', 'rb') as h :
t = pickle.load(h)
#maxlenロード
with open('maxlen.pickle', 'rb') as maxlen :
[maxlen_e, maxlen_d] = pickle.load(maxlen)
row = e.shape[0]
e = e.reshape((row, maxlen_e))
d = d.reshape((row, maxlen_d))
t = t.reshape((row, maxlen_d))
data = {
'e' :e,
'd' :d,
't' :t,
'maxlen_e' :maxlen_e,
'maxlen_d' :maxlen_d,
'input_dim' : len(words),
'output_dim' : len(words)
}
return data
# 訓練
# In[ ]:
# *******************************************************************************
# *
# 訓練処理 *
# *
# *******************************************************************************
def prediction(epochs, batch_size , param_name, data) :
maxlen_e = data['maxlen_e']
maxlen_d = data['maxlen_d']
e = data['e']
d = data['d']
t = data['t']
n_hidden = data['n_hidden']
input_dim = data['input_dim']
vec_dim = data['vec_dim']
output_dim = data['output_dim']
data_row = e.shape[0] # 訓練データの行数
n_split = int(data_row*0.9) # データの分割比率
# データを訓練用とテスト用に分割
e_train, e_test = np.vsplit(e,[n_split]) #エンコーダインプット分割
d_train, d_test = np.vsplit(d,[n_split]) #デコーダインプット分割
t_train, t_test = np.vsplit(t,[n_split]) #ラベルデータ分割
# ニューラルネットワークインスタンス生成
prediction = Dialog(maxlen_e, maxlen_d, n_hidden,
input_dim, vec_dim, output_dim)
emb_param = param_name+'.hdf5'
# 訓練
model = prediction.train(e_train, d_train, t_train,
batch_size, epochs, emb_param)
print()
# テスト
celoss, perplexity, accuracy = prediction.eval_perplexity(model,
e_test, d_test, t_test, batch_size)
print('loss =',celoss, perplexity, accuracy)
# メイン処理
# In[ ]:
# *******************************************************************************
# *
# メイン処理 *
# *
# *******************************************************************************
if __name__ == '__main__':
#@title パラメータ入力フォーム
vec_dim = 512 #@param {type:"integer"}
n_hidden = 512#@param {type:"integer"}
parser = argparse.ArgumentParser(description='応答文生成')
parser.add_argument('arg1', type=int, help='エポック数')
parser.add_argument('arg2', type=int, help='バッチサイズ')
parser.add_argument('arg3', type=str,help='パラメータファイル名')
args = parser.parse_args()
epochs = int(args.arg1)
batch_size = int(args.arg2)
param_name = args.arg3
# データ読み込み
data = load_data()
data['n_hidden'] = n_hidden
data['vec_dim'] = vec_dim
# 訓練処理
prediction(epochs, batch_size ,param_name, data)
4−2. 応答文生成処理(2000_response.ipynb)
このファイルはノートブック形式です。実行すると、入力文に対する応答文の生成を、対話形式で行うことが出来ます。
ソースコードはこちらです。
クリックして表示
# *******************************************************************************
# *
# import宣言 *
# *
# *******************************************************************************
from __future__ import print_function
from transform import Dialog
import numpy as np
import csv
import random
import numpy.random as nr
import sys
import math
import time
import pickle
import gc
import os
from tensorflow.keras.utils import plot_model
from pyknp import Juman
import codecs
# *******************************************************************************
# *
# 辞書ファイル等ロード *
# *
# *******************************************************************************
def load_data() :
#辞書をロード
with open('word_indices.pickle', 'rb') as f :
word_indices=pickle.load(f) #単語をキーにインデックス検索
with open('indices_word.pickle', 'rb') as g :
indices_word=pickle.load(g) #インデックスをキーに単語を検索
#単語ファイルロード
with open('words.pickle', 'rb') as ff :
words=pickle.load(ff)
#maxlenロード
with open('maxlen.pickle', 'rb') as maxlen :
[maxlen_e, maxlen_d] = pickle.load(maxlen)
data = {'words' :words,
'indices_word':indices_word,
'word_indices':word_indices ,
'maxlen_e' :maxlen_e,
'maxlen_d' :maxlen_d,
'input_dim' :len(words),
'output_dim' :len(words)
}
return data
# *******************************************************************************
# *
# モデル初期化 *
# *
# *******************************************************************************
def initialize_models(param_file, data) :
maxlen_e = data['maxlen_e']
maxlen_d = data['maxlen_d']
n_hidden = data['n_hidden']
input_dim = data['input_dim']
vec_dim = data['vec_dim']
output_dim = data['output_dim']
gen_context = Dialog(maxlen_e, maxlen_d, n_hidden,
input_dim, vec_dim, output_dim)
m, encoder_m , decoder_m = gen_context.create_model()
m.load_weights(param_file)
return m, encoder_m, decoder_m
# *******************************************************************************
# *
# 入力文の品詞分解とインデックス化 *
# *
# *******************************************************************************
def encode_request(cns_input, data) :
maxlen_e = data['maxlen_e']
maxlen_d = data['maxlen_d']
word_indices = data['word_indices']
words = data['words']
encoder_model = data['encoder_model']
# Use Juman++ in subprocess mode
jumanpp = Juman()
result = jumanpp.analysis(cns_input)
input_text=[]
for mrph in result.mrph_list():
input_text.append(mrph.midasi)
mat_input=np.array(input_text)
#入力データe_inputに入力文の単語インデックスを設定
e_input=np.zeros((1,maxlen_e))
for i in range(0,len(mat_input)) :
if mat_input[i] in words :
e_input[0,i] = word_indices[mat_input[i]]
else :
e_input[0,i] = word_indices['UNK']
return e_input
# *******************************************************************************
# *
# 応答文組み立て *
# *
# *******************************************************************************
def generate_response(e_input, data) :
maxlen_e = data['maxlen_e']
maxlen_d = data['maxlen_d']
n_hidden = data['n_hidden']
output_dim = data['output_dim']
indices_word = data['indices_word']
word_indices = data['word_indices']
words = data['words']
encoder_model = data['encoder_model']
decoder_model = data['decoder_model']
# Encode the input as state vectors.
encoder_results = encoder_model.predict(e_input)
encoder_outputs = encoder_results[:-1]
encoder_i_mask = encoder_results[-1]
decoded_sentence = ''
target_seq = np.zeros((1, maxlen_d) ,dtype='int32')
# Populate the first character of target sequence with the start character.
target_seq[0, 0] = word_indices['SSSS']
# 応答文字予測
for i in range(0,maxlen_d) :
decoder_output = decoder_model.predict(encoder_outputs
+[target_seq, encoder_i_mask])
#print(decoder_output)
# 予測単語の出現頻度算出
sampled_token_index = np.argmax(decoder_output[0, i, :])
#予測単語
sampled_char = indices_word[sampled_token_index]
# Exit condition: find stop character.
if sampled_char == 'SSSS' :
break
decoded_sentence += sampled_char
# Update the target sequence (of length 1).
if i == maxlen_d-1:
break
target_seq[0,i+1] = sampled_token_index
#print(target_seq)
return decoded_sentence
# *******************************************************************************
# *
# メイン処理 *
# *
# *******************************************************************************
# @title パラメータファイル名入力フォーム
vec_dim = 512 #@param {type:"integer"}
n_hidden = 512#@param {type:"integer"}
param = 'param_001' #@param {type:"string"}
param = param + '.hdf5' # 出力文章数
# データロード
data = load_data()
data['n_hidden'] = n_hidden
data['vec_dim'] = vec_dim
# モデル初期化
model, encoder_model ,decoder_model = initialize_models(param , data)
data['encoder_model'] = encoder_model
data['decoder_model'] = decoder_model
sys.stdin = codecs.getreader('utf_8')(sys.stdin)
n_hidden = data['n_hidden']
while True:
cns_input = input(">> ")
if cns_input == "q":
print("終了")
break
#--------------------------------------------------------------*
# 入力文の品詞分解とインデックス化 *
#--------------------------------------------------------------*
e_input = encode_request(cns_input, data)
#print(e_input)
#--------------------------------------------------------------*
# 応答文組み立て *
#--------------------------------------------------------------*
decoded_sentence = generate_response(e_input, data)
cns_input = decoded_sentence
print(cns_input)
4−3. ニューラルネットワーククラス定義(transform.py)
クリックして表示
# coding: utf-8
from tensorflow.keras.layers import Masking
from tensorflow.keras.layers import Input
from tensorflow.keras.layers import Lambda
from tensorflow.keras.layers import Dropout
from tensorflow.keras.layers import Add
from tensorflow.keras.layers import Reshape
from tensorflow.keras.layers import Multiply
from tensorflow.keras.layers import Concatenate
from tensorflow.keras.models import Model
# from keras.initializers import uniform
from tensorflow.keras import backend as K
from tensorflow.keras.utils import plot_model
import tensorflow as tf
import os
import math
from transform_layers import Layer_LayerNorm
from transform_layers import Layer_Embedding
from transform_encoder import Class_Encoder
from transform_decoder import Class_Decoder
from transform_train import train_main_proc
from transform_train import train_test_main
from transform_loss import fn_cross_loss
from transform_loss import fn_get_perplexity
from transform_loss import fn_get_accuracy
from transform_pos_enc import Class_Positional_Encoding
from transform_lr import Class_Learning_Rate
class Color:
BLACK = '\033[30m'
RED = '\033[31m'
GREEN = '\033[38;5;10m'
YELLOW = '\033[33m'
BLUE = '\033[34m'
PURPLE = '\033[35m'
CYAN = '\033[38;5;14m'
WHITE = '\033[37m'
END = '\033[0m'
BOLD = '\038[1m'
UNDERLINE = '\033[4m'
INVISIBLE = '\033[08m'
REVERCE = '\033[07m'
# *******************************************************************************
# *
# ニューラルネットワーククラス定義 *
# *
# *******************************************************************************
class Dialog :
def __init__(self, maxlen_e, maxlen_d, n_hidden,
input_dim, vec_dim, output_dim):
self.data = {
'maxlen_e' : maxlen_e,
'maxlen_d' : maxlen_d,
'input_dim' : input_dim,
'vec_dim' : vec_dim,
'output_dim' : output_dim ,
'n_hidden' : n_hidden ,
'n_hop' : 6 ,
'n_split_head' : 8 ,
'len_norm' : 2 ,
#'r_lambda' : 0.0 ,
'r_lambda' : 0.0001 ,
'do_rate' : 0.1
}
self.data['splitted_dim'] = n_hidden // self.data['n_split_head']
#---------------------------------------------------------
# クラス定義
#---------------------------------------------------------
self.pos_enc = Class_Positional_Encoding(self.data)
self.enc = Class_Encoder(self.data)
self.dec = Class_Decoder(self.data)
self.lr = Class_Learning_Rate(0, n_hidden)
#***************************************************************************
# *
# ニューラルネットワーク定義 *
# *
#***************************************************************************
def create_model(self):
#***********************************************************************
# *
# 各種パラメータ *
# *
#***********************************************************************
maxlen_e = self.data['maxlen_e']
maxlen_d = self.data['maxlen_d']
input_dim = self.data['input_dim']
vec_dim = self.data['vec_dim']
n_hidden = self.data['n_hidden']
n_hop = self.data['n_hop']
do_rate = self.data['do_rate']
len_norm = self.data['len_norm'] # constraintの最大ノルム長
r_lambda = self.data['r_lambda'] # regularizerのラムダ
#***********************************************************************
# *
# レイヤクラス生成 *
# *
#***********************************************************************
class_LayerNorm = Layer_LayerNorm(max_value=len_norm,
reg_lambda=r_lambda)
class_embedding = Layer_Embedding(max_value=len_norm,
reg_lambda=r_lambda)
#***********************************************************************
# *
# 処理インスタンス生成 *
# *
#***********************************************************************
encoder = self.enc.encoder_nn
decoder = self.dec.decoder_nn
positional_encoding = self.pos_enc.positional_encoding
print('#3')
#***********************************************************************
# *
# エンコーダー(学習/応答文作成兼用) *
# *
#***********************************************************************
#---------------------------------------------------------
#レイヤー定義
#---------------------------------------------------------
embedding =class_embedding.create_Embedding(vec_dim,
input_dim,
emb_name='Embedding')
input_mask = Masking(mask_value=0, name="input_Mask")
input_LayerNorm \
= class_LayerNorm.create_LayerNorm(bn_name='input_LayerNorm')
#hidden_Dense = class_Dense.create_Dense(n_hidden,
# dense_name='hidden_Dense')
#---------------------------------------------------------
# 入力定義
#---------------------------------------------------------
encoder_input = Input(shape=(maxlen_e,),
dtype='int32',
name='encorder_input')
e_input = input_mask(encoder_input)
e_input = embedding(e_input)
e_input = input_LayerNorm(e_input)
e_input = Lambda(lambda x: x * math.sqrt(vec_dim))(e_input)
e_input = positional_encoding(e_input)
e_input = Dropout(do_rate)(e_input)
#e_input = hidden_Dense(e_input)
#---------------------------------------------------------
# encoderマスク生成
#---------------------------------------------------------
encoder_i_mask = Lambda(lambda x: K.sign(x),
name='encoder_sign')(encoder_input)
#---------------------------------------------------------
# 手続き部
#---------------------------------------------------------
encoder_outputs = encoder(e_input, encoder_i_mask)
#---------------------------------------------------------
# エンコーダモデル定義
#---------------------------------------------------------
encoder_model = Model(inputs=encoder_input,
outputs= encoder_outputs+[encoder_i_mask])
print('#4')
#***********************************************************************
# デコーダー(学習用) *
# デコーダを、完全な出力シークエンスを返し、内部状態もまた返すように *
# 設定します。 *
# 訓練モデルではreturn_sequencesを使用しませんが、推論では使用します。 *
#***********************************************************************
#---------------------------------------------------------
#入力定義
#---------------------------------------------------------
decoder_input = Input(shape=(maxlen_d,),
dtype='int32', name='decoder_input')
d_i = Masking(mask_value=0)(decoder_input)
d_i = embedding(d_i)
d_i = input_LayerNorm(d_i)
d_i = Lambda(lambda x: x * math.sqrt(vec_dim))(d_i)
d_i = positional_encoding(d_i)
d_i = Dropout(do_rate)(d_i)
#d_i = hidden_Dense(d_i)
d_input = d_i # 応答文生成で使う
#---------------------------------------------------------
# decoderマスク生成
#---------------------------------------------------------
decoder_i_mask = Lambda(lambda x: K.sign(x),
name='decoder_sign')(decoder_input)
#---------------------------------------------------------
# 手続き部
#---------------------------------------------------------
decoder_output = decoder(encoder_outputs, d_i,
encoder_i_mask, decoder_i_mask)
#---------------------------------------------------------
# モデル定義、コンパイル
#---------------------------------------------------------
model = Model(inputs=[encoder_input, decoder_input],
outputs=decoder_output)
model.compile(loss=fn_cross_loss,
optimizer="Adam",
metrics=[fn_get_perplexity, fn_get_accuracy])
#***********************************************************************
# *
# デコーダー(応答文作成) *
# *
#***********************************************************************
print('#6')
#---------------------------------------------------------
#入力定義
#---------------------------------------------------------
decoder_e_i_outputs = [Input(shape=(maxlen_e, n_hidden),
name='decoder_e_i_outputs_'
+'{0:0>3d}'.format(i))
for i in range(n_hop)]
decoder_e_i_mask = Input(shape=(maxlen_e,),
name='decoder_e_i_mask')
#---------------------------------------------------------
# デコーダー実行
#---------------------------------------------------------
res_decoder_output = decoder(decoder_e_i_outputs, d_input,
decoder_e_i_mask, decoder_i_mask)
print('#7')
#---------------------------------------------------------
# モデル定義
#---------------------------------------------------------
decoder_model = Model(inputs= decoder_e_i_outputs+
[decoder_input, decoder_e_i_mask,
],
outputs=res_decoder_output)
return model, encoder_model, decoder_model
#***********************************************************************
# *
# 学習 *
# *
#***********************************************************************
def train(self, e_input, d_input, target,
batch_size, epochs, emb_param) :
print ('#2',target.shape)
model ,encoder_model , decoder_model = self.create_model()
if os.path.isfile(emb_param) :
model.load_weights(emb_param) #埋め込みパラメータセット
# ネットワーク図出力
plot_model(model, show_shapes=True,to_file='model.png')
plot_model(encoder_model, show_shapes=True,
to_file='encoder_model.png')
plot_model(decoder_model, show_shapes=True,
to_file='decoder_model.png')
print ('#8 number of params :', model.count_params())
# 学習メイン処理
params = {'model' : model,
'e' : e_input,
'd' : d_input,
't' : target,
'batch_size' : batch_size,
'epochs' : epochs,
'emb_param' : emb_param }
_, _, _ = train_main_proc(params, self.lr, self.data)
return model
#***********************************************************************
# *
# perplexity計算 *
# *
#***********************************************************************
def eval_perplexity(self, model, e_test, d_test, t_test, batch_size) :
params = {'model' : model,
'e' : e_test,
'd' : d_test,
't' : t_test,
'batch_size' : batch_size,
'epochs' : '',
'emb_param' : ''}
return train_test_main('test', params, self.data)
4−4. エンコード処理(transform_encoder.py)
クリックして表示
# coding: utf-8
# *******************************************************************************
# *
# エンコーダーニューラルネットワーク定義 *
# *
# *******************************************************************************
# from transform_pos_enc import positional_encoding
from transform_attention import Class_Attention
from transform_ffn import Class_FFN
from tensorflow.keras.layers import Multiply
from tensorflow.keras.layers import Lambda
from tensorflow.keras.layers import Reshape
from tensorflow.keras import backend as K
class Class_Encoder :
def __init__(self, data):
#***********************************************************************
# *
# 各種パラメータ *
# *
#***********************************************************************
self.data = data
n_hop = data['n_hop']
#***********************************************************************
# *
# レイヤクラス生成 *
# *
#***********************************************************************
c_a = [Class_Attention(i, 'e', data) for i in range(n_hop)]
c_ffn = Class_FFN('e', data)
#***********************************************************************
# *
# レイヤーインスタンス生成 *
# *
#***********************************************************************
self.attention = [c_a[i].attention for i in range(n_hop)]
self.ffn = c_ffn.ffn
def encoder_nn(self, e_input, encoder_i_mask) :
#***********************************************************************
# *
# 各種パラメータ *
# *
#***********************************************************************
n_hop = self.data['n_hop']
n_hidden = self.data['n_hidden']
vec_dim = self.data['vec_dim']
maxlen_e = self.data['maxlen_e']
#***********************************************************************
# *
# 手続き部 *
# *
#***********************************************************************
e_i = e_input
mask1 = Reshape((maxlen_e,1))(encoder_i_mask)
mask1 = Lambda(lambda x: K.repeat_elements(x, vec_dim, -1))(mask1)
mask1 = Lambda(lambda x: K.cast(x,dtype='float32'))(mask1)
e_i = Multiply()([e_i, mask1])
#---------------------------------------------------------
# メイン処理
#---------------------------------------------------------
mask2 = Reshape((maxlen_e,1))(encoder_i_mask)
mask2 = Lambda(lambda x: K.repeat_elements(x, n_hidden, -1))(mask2)
mask2 = Lambda(lambda x: K.cast(x,dtype='float32'))(mask2)
encoder_outputs = []
for i in range(n_hop) :
# self attention
param_attention = {'query' : e_i ,
'memory' : e_i ,
'q_mask' : encoder_i_mask,
'm_mask' : encoder_i_mask,
}
e_i = self.attention[i](param_attention)
#e_i = Multiply()([e_i, mask2])
# Position-wise Feedforward Network
param_ffn = {'input_tensor' : e_i,
'maxlen' : maxlen_e ,
}
e_i=self.ffn(param_ffn)
e_i = Multiply()([e_i, mask2])
# 結果を出力用リストに加える
encoder_outputs.append(e_i)
return encoder_outputs
4−5. デコード処理(transform_decoder.py)
クリックして表示
# coding: utf-8
# *******************************************************************************
# *
# デコーダーニューラルネットワーク定義 *
# *
# *******************************************************************************
from tensorflow.keras.layers import Lambda
from tensorflow.keras.layers import Reshape
from tensorflow.keras.layers import Multiply
from tensorflow.keras.layers import Add
from tensorflow.keras.layers import Activation
from tensorflow.keras import backend as K
import math
from transform_attention import Class_Attention
from transform_ffn import Class_FFN
from transform_layers import Layer_Dense
class Class_Decoder :
def __init__(self, data):
#***********************************************************************
# *
# 各種パラメータ *
# *
#***********************************************************************
self.data = data
output_dim = data['output_dim']
n_hop = data['n_hop']
len_norm = data['len_norm'] # constraintの最大ノルム長
r_lambda = data['r_lambda'] # regularizerのラムダ
#***********************************************************************
# *
# レイヤクラス生成 *
# *
#***********************************************************************
c_sa = [Class_Attention(i, 'ds', data) for i in range(n_hop)]
c_ta = [Class_Attention(i, 'ts', data) for i in range(n_hop)]
c_ffn = Class_FFN('d', data)
class_Dense = Layer_Dense(max_value=len_norm, reg_lambda=r_lambda)
#***********************************************************************
# *
# レイヤーインスタンス生成 *
# *
#***********************************************************************
self.self_attention = [c_sa[i].attention for i in range(n_hop)]
self.source_target_attention = [c_ta[i].attention
for i in range(n_hop)]
self.ffn = c_ffn.ffn
self.decoder_Dense = class_Dense.create_Dense(output_dim,
dense_activation='softmax',
dense_name='decoder_Dense')
def decoder_nn(self, e_outputs, d_input, encoder_i_mask, decoder_i_mask) :
#***********************************************************************
# *
# 各種パラメータ *
# *
#***********************************************************************
n_hidden = self.data['n_hidden']
maxlen_d = self.data['maxlen_d']
n_hop = self.data['n_hop']
output_dim = self.data['output_dim']
vec_dim = self.data['vec_dim']
#***********************************************************************
# *
# 手続き部 *
# *
#***********************************************************************
#---------------------------------------------------------
# メイン処理
#---------------------------------------------------------
d_i = d_input
mask1 = Reshape((maxlen_d,1))(decoder_i_mask)
mask1 = Lambda(lambda x: K.repeat_elements(x, vec_dim, -1))(mask1)
mask1 = Lambda(lambda x: K.cast(x,dtype='float32'))(mask1)
mask2 = Reshape((maxlen_d,1))(decoder_i_mask)
mask2 = Lambda(lambda x: K.repeat_elements(x, n_hidden, -1))(mask2)
mask2 = Lambda(lambda x: K.cast(x,dtype='float32'))(mask2)
d_i = Multiply()([d_i, mask2])
for i in range(n_hop) :
# self attention
param_sa = {'query' : d_i ,
'memory' : d_i ,
'q_mask' : decoder_i_mask,
'm_mask' : decoder_i_mask,
}
d_i = self.self_attention[i](param_sa)
#d_i = Multiply()([d_i, mask1])
# source target attention
param_sta = {'query' : d_i ,
'memory' : e_outputs[i] ,
'q_mask' : decoder_i_mask,
'm_mask' : encoder_i_mask,
}
d_i = self.source_target_attention[i](param_sta)
#d_i = Multiply()([d_i, mask2])
# Position-wise Feedforward Network
param_ffn = {'input_tensor' : d_i,
'maxlen' : maxlen_d ,
}
d_i = self.ffn(param_ffn)
d_i = Multiply()([d_i, mask2])
#d_i = Lambda(lambda x: x * math.sqrt(n_hidden))(d_i)
d_output = self.decoder_Dense(d_i)
#d_output = Lambda(lambda x: x / math.sqrt(output_dim))(d_output)
#d_output = Activation('softmax')(d_output)
#print('d_output',K.int_shape(d_output))
#---------------------------------------------------------
# デコード結果にマスクをかける
#---------------------------------------------------------
mask = Lambda(lambda x: K.cast(x,dtype='float32'))(decoder_i_mask)
mask = Reshape((maxlen_d,1))(mask)
mask = Lambda(lambda x: K.repeat_elements(x, output_dim, -1))(mask)
decoder_output = Multiply()([d_output, mask])
return decoder_output
4−6. positional encoding処理(transform_pos_enc.py)
クリックして表示
# coding: utf-8
# *******************************************************************************
# *
# Positional Encoding *
# *
# *******************************************************************************
from tensorflow.keras.layers import Lambda
from tensorflow.keras.layers import Add
from tensorflow.keras.layers import Subtract
from tensorflow.keras.layers import Multiply
from tensorflow.keras import backend as K
import math
class Class_Positional_Encoding :
def __init__(self, data) :
vec_dim = data['vec_dim']
self.pos_enc_ones = Lambda(lambda x: K.ones_like(x, dtype='int32'),
name='pos_enc_ones')
self.pos_enc_cumsum_row = Lambda(lambda x: K.cumsum(x, axis=1),
name='pos_enc_cumsum_row')
self.pos_enc_cumsum_col = Lambda(lambda x: K.cumsum(x, axis=-1),
name='pos_enc_cumsum_col')
self.pos_enc_substract = Subtract(name='pos_enc_substract')
self.pos_enc_even = Lambda(lambda x: K.cast(x // 2 * 2,
dtype='float32'),
name='pos_enc_even')
self.pos_enc_pi = Lambda(lambda x: K.cast(x % 2, dtype='float32')
* math.pi / 2,
name='pos_enc_pi')
self.pos_enc_exp = Lambda(lambda x: K.exp(x / vec_dim * K.log(10000.0)),
name='pos_enc_exp')
self.pos_enc_reciprocal = Lambda(lambda x: 1 / x,
name='pos_enc_reciprocal')
self.pos_enc_cast = Lambda(lambda x: K.cast(x, dtype='float32'),
name='pos_enc_cast')
self.pos_enc_mul = Multiply(name='pos_enc_mul')
self.pos_enc_add_pi = Add(name='pos_enc_add_pi')
self.pos_enc_sin = Lambda(lambda x: K.sin(x), name='pos_enc_sin')
self.pos_enc_add = Add(name='pos_enc_add')
def positional_encoding(self, input_tensor) :
ones = self.pos_enc_ones(input_tensor)
cumsum_row = self.pos_enc_cumsum_row(ones)
cumsum_row = self.pos_enc_substract([cumsum_row, ones])
cumsum_col = self.pos_enc_cumsum_col(ones)
cumsum_col = self.pos_enc_substract([cumsum_col, ones])
even = self.pos_enc_even(cumsum_col)
pi = self.pos_enc_pi(cumsum_col)
mat_power = self.pos_enc_exp(even)
mat_power = self.pos_enc_reciprocal(mat_power)
cumsum_float = self.pos_enc_cast(cumsum_row)
mat_positon = self.pos_enc_mul([mat_power, cumsum_float])
mat_positon = self.pos_enc_add_pi([mat_positon, pi])
mat_positon = self.pos_enc_sin(mat_positon)
output_tensor = self.pos_enc_add([input_tensor, mat_positon])
return output_tensor
4−7. attention処理(transform_attention.py)
クリックして表示
# coding: utf-8
# *******************************************************************************
# *
# attention定義 *
# *
# *******************************************************************************
from tensorflow.keras.layers import Lambda
from tensorflow.keras.layers import Multiply
from tensorflow.keras.layers import Maximum
from tensorflow.keras.layers import Concatenate
from tensorflow.keras.layers import Add
from tensorflow.keras.layers import Dot
from tensorflow.keras.layers import Softmax
from tensorflow.keras import backend as K
from transform_layers import Layer_Dense
from transform_layers import Layer_Dropout
from transform_layers import Layer_LayerNorm
from transform_triangle import Class_Triangler
import math
class Class_Attention :
def __init__(self, index, kind, data):
self.data = data
#***********************************************************************
# *
# 各種パラメータ *
# *
#***********************************************************************
maxlen_e = data['maxlen_e']
maxlen_d = data['maxlen_d']
n_hidden = data['n_hidden']
do_rate = data['do_rate']
splitted_dim = data['splitted_dim']
len_norm = data['len_norm']
r_lambda = data['r_lambda']
n_split_head = self.data['n_split_head']
layer_name = '_'+kind+'_'+'{0:0>3d}'.format(index)
if kind == 'e' : # self attention(エンコーダ)
q_dim = maxlen_e
m_dim = maxlen_e
elif kind == 'ds' : # self attention(デコーダ)
q_dim = maxlen_d
m_dim = maxlen_d
else : # source target attention
q_dim = maxlen_d
m_dim = maxlen_e
self.kind = kind
#***********************************************************************
# *
# レイヤクラス生成 *
# *
#***********************************************************************
class_Dropout = Layer_Dropout(do_rate=do_rate)
class_Triangler = Class_Triangler(index, kind)
class_Dense = Layer_Dense(max_value=len_norm, reg_lambda=r_lambda)
class_LayerNorm = Layer_LayerNorm(max_value=len_norm,
reg_lambda=r_lambda)
#***********************************************************************
# *
# レイヤー定義 *
# *
#***********************************************************************
self.layers = {
#---------------------------------------------------------
# DropOutインスタンス
#---------------------------------------------------------
'q_Dense' : [class_Dense.create_Dense(splitted_dim,
dense_name='q_Dense'+layer_name+'_'
+'{0:0>2d}'.format(i))
for i in range(n_split_head) ],
'k_Dense' : [class_Dense.create_Dense(splitted_dim,
dense_name='k_Dense'+layer_name+'_'
+'{0:0>2d}'.format(i))
for i in range(n_split_head) ] ,
'v_Dense' : [class_Dense.create_Dense(splitted_dim,
dense_name='v_Dense'+layer_name+'_'
+'{0:0>2d}'.format(i))
for i in range(n_split_head) ] ,
'output_Dense' : class_Dense.create_Dense(n_hidden,
dense_name='output_Dense_'+layer_name) ,
#---------------------------------------------------------
# DropOutインスタンス
#---------------------------------------------------------
#'a_Dropout' : class_Dropout.create_Dropout(
# do_name='a_Dropout'+layer_name) ,
'residual_Dropout' : class_Dropout.create_Dropout(
do_name='residual_Dropout'+layer_name) ,
#---------------------------------------------------------
# LayerNormalizationインスタンス
#---------------------------------------------------------
'residual_LayerNorm' : class_LayerNorm.create_LayerNorm(
bn_name='residual_LayerNorm'+layer_name) ,
#---------------------------------------------------------
# residual Addインスタンス
#---------------------------------------------------------
'residual_Add' : Add(name='residual_Add'+layer_name) ,
#---------------------------------------------------------
# 下三角行列マスキング
#---------------------------------------------------------
'triangular_matrix' : class_Triangler.triangular_matrix ,
#---------------------------------------------------------
# マスキング用
#---------------------------------------------------------
'mask_cast' : Lambda(lambda x: K.cast(x,dtype='float32'),
name='mask_cast'+layer_name) ,
'q_mask_repeat' : Lambda(lambda x: K.repeat(x, m_dim),
name='q_mask_repeat'+layer_name),
'm_mask_repeat' : Lambda(lambda x: K.repeat(x, q_dim),
name='m_mask_repeat'+layer_name),
'm_mask_transpose' : Lambda(lambda x:
K.permute_dimensions(x, (0,2,1)),
name='m_mask_transpose'+layer_name),
'attention_masking' : Multiply(name='a_masking'+layer_name) ,
#---------------------------------------------------------
# attemtion用softmax(encoder_input可変長対応)
#---------------------------------------------------------
'attention_sum' : Lambda(lambda x: K.sum(x, axis=-1, keepdims=True),
name='attention_sum'+layer_name) ,
'a_epsilon' : Lambda(lambda x: 1 / 2 * x + K.epsilon(),
name='a_epsilon'+layer_name) ,
'a_clip' : Maximum(name='a_clip'+layer_name) ,
'sum_Reciprocal' : Lambda(lambda x: 1 / x,
name='sum_Reciprocal'+layer_name) ,
'sum_repeat' : Lambda(lambda x: K.repeat_elements(x, m_dim, -1),
name='sum_repeat'+layer_name),
'sum_divide' : Multiply(name='sum_divide'+layer_name) ,
#---------------------------------------------------------
# attention用
#---------------------------------------------------------
'a_Dot1' : Dot(-1,name='a_Dot1'+layer_name) ,
'scaled_dot' : Lambda(lambda x: x / math.sqrt(splitted_dim),
name='scaled_dot'+layer_name),
'a_Softmax' : Softmax(axis=-1, name='a_Softmax'+layer_name) ,
'a_transpose' : Lambda(lambda x:
K.permute_dimensions(x, (0,2,1)),
name='Transpose'+layer_name) ,
'a_Dot2' : Dot(1,name='a_Dot2'+layer_name) ,
#'a_tanh' : Lambda(lambda x: K.tanh(x),
# name='tanh'+'{0:0>3d}'.format(index)) ,
'output_Concat' : Concatenate(-1, name='output_Concat'+layer_name) ,
#---------------------------------------------------------
# multi head用
#---------------------------------------------------------
'mh_split' : [Lambda(lambda x: x[:,:,splitted_dim * i :
splitted_dim * (i+1)],
name='mh_split'
+layer_name+'_'+'{0:0>2d}'.format(i))
for i in range(n_split_head)] ,
}
#***************************************************************************
# *
# マスキング処理 *
# *
#***************************************************************************
def masking(self, a_o, param_attention) :
#---------------------------------------------------------
# レイヤー
#---------------------------------------------------------
m_mask_transpose = self.layers['m_mask_transpose']
q_mask_repeat = self.layers['q_mask_repeat']
m_mask_repeat = self.layers['m_mask_repeat']
mask_cast = self.layers['mask_cast']
attention_masking = self.layers['attention_masking']
triangular_matrix = self.layers['triangular_matrix']
#---------------------------------------------------------
# 手続き部
#---------------------------------------------------------
q_mask = param_attention['q_mask']
m_mask = param_attention['m_mask']
q_mask_extracted = q_mask_repeat(q_mask)
q_mask_extracted = m_mask_transpose(q_mask_extracted)
m_mask_extracted = m_mask_repeat(m_mask)
if self.kind == 'ds' :
a_output = triangular_matrix(a_o) # 下三角行列マスキング
else :
a_output = a_o
return attention_masking([a_output, mask_cast(q_mask_extracted),
mask_cast(m_mask_extracted)])
#***************************************************************************
# *
# attemtion用softmax(可変系列長対応) *
# *
#***************************************************************************
def attention_softmax(self, a_o, param_attention) :
#---------------------------------------------------------
# レイヤー
#---------------------------------------------------------
attention_sum = self.layers['attention_sum']
a_epsilon = self.layers['a_epsilon']
a_clip = self.layers['a_clip']
sum_Reciprocal = self.layers['sum_Reciprocal']
sum_repeat = self.layers['sum_repeat']
sum_divide = self.layers['sum_divide']
a_Softmax = self.layers['a_Softmax']
#---------------------------------------------------------
# 手続き部
#---------------------------------------------------------
exp_a_o = a_Softmax(a_o)
exp_a_o = self.masking(exp_a_o, param_attention)
exp_sum = attention_sum(exp_a_o)
epsilon = a_epsilon(exp_sum)
exp_sum = a_clip([exp_sum, epsilon])
exp_sum = sum_Reciprocal(exp_sum)
exp_sum = sum_repeat(exp_sum)
exp_a_o = sum_divide([exp_a_o, exp_sum])
return exp_a_o
#***************************************************************************
# *
# multi-head attention処理 *
# *
#***************************************************************************
def mh_attention(self, index, query, memory, param_attention) :
#---------------------------------------------------------
# レイヤー
#---------------------------------------------------------
q_Dense = self.layers['q_Dense']
k_Dense = self.layers['k_Dense']
v_Dense = self.layers['v_Dense']
scaled_dot = self.layers['scaled_dot']
#a_Dropout = self.layers['a_Dropout']
a_Dot1= self.layers['a_Dot1']
a_transpose = self.layers['a_transpose']
a_Dot2 = self.layers['a_Dot2']
#---------------------------------------------------------
# 手続き部
#---------------------------------------------------------
#print('query',K.int_shape(query))
#print('memory',K.int_shape(memory))
a_o = q_Dense[index](query)
a_o = scaled_dot(a_o) # Scaled Dot-production
a_o = a_Dot1([a_o, k_Dense[index](memory)]) # memoryの転置行列を掛ける
a_o = self.attention_softmax(a_o, param_attention) #softmax
a_o = a_transpose(a_o)
a_o = a_Dot2([a_o, v_Dense[index](memory)]) # memoryを掛ける
return a_o
#***************************************************************************
# *
# attention処理 *
# *
#***************************************************************************
def attention(self, param_attention) :
#---------------------------------------------------------
# パラメータ
#---------------------------------------------------------
query = param_attention['query']
memory = param_attention['memory']
n_split_head = self.data['n_split_head']
#---------------------------------------------------------
# レイヤー
#---------------------------------------------------------
mh_split = self.layers['mh_split']
output_Concat = self.layers['output_Concat']
output_Dense = self.layers['output_Dense']
residual_Dropout = self.layers['residual_Dropout']
residual_LayerNorm = self.layers['residual_LayerNorm']
residual_Add = self.layers['residual_Add']
#---------------------------------------------------------
# 手続き部
#---------------------------------------------------------
# Multi-head Attention
splitted_query = [mh_split[i](query) for i in range(n_split_head)]
splitted_memory = [mh_split[i](memory) for i in range(n_split_head)]
a_outut_list = [self.mh_attention(i, splitted_query[i],
splitted_memory[i],
param_attention)
for i in range(n_split_head)]
attention_output = output_Dense(output_Concat(a_outut_list))
attention_output = residual_Dropout(attention_output)
attention_output = residual_Add([attention_output, query])
attention_output = residual_LayerNorm(attention_output)
return attention_output
4−8. self-attention下三角行列マスキング処理(transform_triangle.py)
クリックして表示
# coding: utf-8
from tensorflow.keras import backend as K
from tensorflow.keras.layers import Lambda
from tensorflow.keras.layers import Add
from tensorflow.keras.layers import Subtract
from tensorflow.keras.layers import Multiply
from tensorflow.keras.layers import Maximum
# *******************************************************************************
# *
# 下三角行列マスキング *
# *
# *******************************************************************************
class Class_Triangler :
def __init__(self, index, kind):
layer_name = '_'+kind+'_'+'{0:0>3d}'.format(index)
self.triangle_ones = Lambda(lambda x: K.ones_like(x, dtype='int32'),
name='triangle_ones'+layer_name)
self.triangle_cumsum_row = Lambda(lambda x: K.cumsum(x, axis=1),
name='triangle_cumsum_row'+layer_name)
self.triangle_minus = Lambda(lambda x: -1 * x,
name='triangle_minus'+layer_name)
self.triangle_cumsum_col = Lambda(lambda x: K.cumsum(x, axis=-1),
name='triangle_cumsum_col'+layer_name)
self.triangle_add = Add(name='triangle_add'+layer_name)
self.triangle_sign = Lambda(lambda x: K.sign(x),
name='triangle_sign'+layer_name)
self.triangle_zeros = Lambda(lambda x: K.zeros_like(x, dtype='int32'),
name='triangle_zeros'+layer_name)
self.triangle_maximum = Maximum(name='triangle_maximum'+layer_name)
self.triangle_subtract = Subtract(name='triangle_subtract'+layer_name)
self.triangle_cast = Lambda(lambda x: K.cast(x, dtype='float32'),
name='triangle_cast'+layer_name)
self.triangle_multiply = Multiply(name='triangle_multiply'+layer_name)
def triangular_matrix(self, mat) :
ones = self.triangle_ones(mat)
mask_row = self.triangle_cumsum_row(ones)
mask_row = self.triangle_minus(mask_row)
mask_col = self.triangle_cumsum_col(ones)
mask = self.triangle_add([mask_row, mask_col])
mask = self.triangle_sign(mask)
zeros = self.triangle_zeros(mat)
mask = self.triangle_maximum([mask, zeros])
mask = self.triangle_subtract([ones, mask])
mask = self.triangle_cast(mask)
return self.triangle_multiply([mask, mat])
4−9. position-wise feed forward network処理(transform_ffn.py)
クリックして表示
# coding: utf-8
from tensorflow.keras.layers import Concatenate
from tensorflow.keras.layers import Reshape
from tensorflow.keras.layers import Add
from tensorflow.keras.layers import Lambda
from tensorflow.keras.layers import Dropout
from transform_layers import Layer_Dense
from transform_layers import Layer_Dropout
from transform_layers import Layer_LayerNorm
# ***************************************************************************
# *
# Position-wise Feed Forward Network処理 *
# *
# ***************************************************************************
class Class_FFN :
def __init__(self, kind, data):
self.data = data
#---------------------------------------------------------
# クラス定義
#---------------------------------------------------------
max_value=data['len_norm']
reg_lambda=data['r_lambda']
n_hidden = data['n_hidden']
class_Dense = Layer_Dense(max_value=max_value ,
reg_lambda=reg_lambda)
class_Dropout = Layer_Dropout(data['do_rate'])
self.class_LayerNorm = Layer_LayerNorm(max_value=max_value ,
reg_lambda=reg_lambda)
#---------------------------------------------------------
# PositionWise FeedForward Network用レイヤ定義
#---------------------------------------------------------
if kind =='e' :
maxlen = data['maxlen_e']
else :
maxlen = data['maxlen_d']
layer_name = '_'+kind
self.layers = {
'filter_Dense' : [class_Dense.create_Dense(n_hidden * 4,
dense_activation='relu' ,
dense_name='filter_Dense_'
+layer_name+'{0:0>3d}'.format(i))
for i in range(maxlen)] ,
'ffn_output_Dense' : [class_Dense.create_Dense(n_hidden,
dense_name='ffn_output_Dense_'
+layer_name+'{0:0>3d}'.format(i))
for i in range(maxlen)] ,
'ffn_Dropout' : [class_Dropout.create_Dropout(
do_name='ffn_Dropout_'
+layer_name+'{0:0>3d}'.format(i))
for i in range(maxlen)] ,
'ffn_time_slice' : [Lambda(lambda x: x[:, i, :],
name='ffn_time_slice'
+layer_name+'{0:0>3d}'.format(i))
for i in range(maxlen)],
'ffn_reshape' : Reshape((1, n_hidden),
name='ffn_reshape'+layer_name) ,
'ffn_Concat' : Concatenate(1, name='ffn_Concat'+layer_name) ,
'ffn_Add' : Add(name='ffn_Add'+layer_name) ,
}
def ffn(self, param_ffn) :
input_tensor = param_ffn['input_tensor']
maxlen = param_ffn['maxlen']
do_rate = self.data['do_rate']
#*******************************************************************
# *
# レイヤー *
# *
#*******************************************************************
filter_Dense = self.layers['filter_Dense']
ffn_output_Dense = self.layers['ffn_output_Dense']
ffn_Dropout = self.layers['ffn_Dropout']
ffn_reshape = self.layers['ffn_reshape']
ffn_time_slice = self.layers['ffn_time_slice']
ffn_Concat = self.layers['ffn_Concat']
residual_Add = self.layers['ffn_Add']
ffn_LayerNorm = self.class_LayerNorm.create_LayerNorm()
#*******************************************************************
# *
# 手続き部 *
# *
#*******************************************************************
input_tensor_list = [ffn_time_slice[i](input_tensor)
for i in range(maxlen)]
output_tensor_list = [ffn_reshape(input_tensor_list[i])
for i in range(maxlen)]
output_tensor_list = [filter_Dense[i](output_tensor_list[i])
for i in range(maxlen)]
output_tensor_list = [ffn_Dropout[i](output_tensor_list[i])
for i in range(maxlen)]
output_tensor_list = [ffn_output_Dense[i](output_tensor_list[i])
for i in range(maxlen)]
output_tensor = ffn_Concat(output_tensor_list)
output_tensor = Dropout(do_rate)(output_tensor)
output_tensor = residual_Add([output_tensor, input_tensor])
output_tensor = ffn_LayerNorm(output_tensor)
return output_tensor
4−10. 学習率減衰処理(transform_lr.py)
クリックして表示
# coding: utf-8
import math
# *******************************************************************************
# *
# 学習率計算 *
# *
# *******************************************************************************
class Class_Learning_Rate :
def __init__(self, initial_value, depth):
self.counter = initial_value
self.depth = depth
def calc_lr(self) :
peak = 4000
time = max(float(self.counter), 0.001)
lr = math.pow(self.depth, -0.5) * min(math.pow(time, -0.5),
time * math.pow(peak, -1.5))
output_counter = self.counter
self.counter += 1
return lr, output_counter
4−11. ニューラルネットワークのレイヤ定義(transform_layers.py)
クリックして表示
# coding: utf-8
# *******************************************************************************
# *
# レイヤークラス定義 *
# *
# *******************************************************************************
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Embedding
from tensorflow.keras.layers import LayerNormalization
from tensorflow.keras.layers import BatchNormalization
from tensorflow.keras.layers import Dropout
from tensorflow.keras.layers import Conv1D
from tensorflow.keras.initializers import glorot_uniform
from tensorflow.keras import regularizers
from tensorflow.keras import backend as K
from tensorflow.keras.constraints import max_norm
# *******************************************************************************
class Layer_Dense :
def __init__(self, max_value=2, reg_lambda=0.01, seed=20170719):
self.seed = seed
self.max_value = max_value
self.reg_lambda = reg_lambda
def create_Dense(self, dense_units,
dense_activation=None, dense_name='Dense'):
if dense_activation==None :
act_reg = None
else :
act_reg = regularizers.l1(self.reg_lambda)
layer = Dense(dense_units, name=dense_name,
activation=dense_activation,
kernel_initializer=glorot_uniform(seed=self.seed),
kernel_regularizer=regularizers.l2(self.reg_lambda) ,
bias_regularizer=regularizers.l2(self.reg_lambda) ,
activity_regularizer=act_reg,
#kernel_constraint=max_norm(max_value=self.max_value, axis=0),
#bias_constraint=max_norm(max_value=self.max_value, axis=0),
)
return layer
# *******************************************************************************
class Layer_LayerNorm :
def __init__(self, max_value=2, reg_lambda=0.01):
self.max_value = max_value
self.reg_lambda = reg_lambda
def create_LayerNorm(self, bn_name=None):
#layer = BatchNormalization(axis=-1,
layer = LayerNormalization(axis=-1,
name=bn_name,
beta_regularizer=regularizers.l2(self.reg_lambda) ,
gamma_regularizer=regularizers.l2(self.reg_lambda) ,
beta_constraint=max_norm(max_value=self.max_value, axis=0),
gamma_constraint=max_norm(max_value=self.max_value, axis=0)
)
return layer
# *******************************************************************************
class Layer_BatchNorm :
def __init__(self, max_value=2, reg_lambda=0.01):
self.max_value = max_value
self.reg_lambda = reg_lambda
def create_BatchNorm(self, bn_name='BatchNorm'):
layer = BatchNormalization(axis=-1,
name=bn_name,
beta_regularizer=regularizers.l2(self.reg_lambda) ,
gamma_regularizer=regularizers.l2(self.reg_lambda) ,
beta_constraint=max_norm(max_value=self.max_value, axis=0),
gamma_constraint=max_norm(max_value=self.max_value, axis=0)
)
return layer
# *******************************************************************************
class Layer_Embedding :
def __init__(self, max_value=2, reg_lambda=0.01, seed=20170719):
self.seed = seed
self.max_value = max_value
self.reg_lambda = reg_lambda
def create_Embedding(self, emb_out_dim, emb_in_dim, emb_name='Embedding'):
layer = Embedding(output_dim=emb_out_dim, input_dim=emb_in_dim,
mask_zero=True, name=emb_name,
#embeddings_initializer=uniform(seed=self.seed),
embeddings_regularizer=regularizers.l2(self.reg_lambda),
embeddings_constraint=max_norm(max_value=self.max_value, axis=0)
)
return layer
# *******************************************************************************
class Layer_Dropout :
def __init__(self, do_rate=0.5):
self.do_rate = do_rate
def create_Dropout(self, do_name='Dropout'):
layer = Dropout(rate=self.do_rate, name=do_name)
return layer
# *******************************************************************************
class Layer_Conv1D :
def __init__(self, max_value=2, reg_lambda=0.01, seed=20170719):
self.seed = seed
self.max_value = max_value
self.reg_lambda = reg_lambda
def create_Conv1D(self, filters, kernel_size=1, padding='causal',
activation=None, name='Conv1D'):
if activation==None :
act_reg = None
else :
act_reg = regularizers.l1(self.reg_lambda)
layer = Conv1D(filters,
kernel_size,
name=name,
strides=1,
padding=padding,
activation=activation,
kernel_initializer=glorot_uniform(seed=self.seed),
kernel_regularizer=regularizers.l2(self.reg_lambda) ,
bias_regularizer=regularizers.l2(self.reg_lambda) ,
activity_regularizer=act_reg,
#kernel_constraint=max_norm(max_value=self.max_value, axis=0),
#bias_constraint=max_norm(max_value=self.max_value, axis=0),
)
return layer
4−12. 損失関数、評価関数(transform_loss.py)
クリックして表示
from tensorflow.keras import backend as K
# ---------------------------------------------------------
# 損失関数
# ---------------------------------------------------------
def fn_cross_loss(y_true, y_pred) :
perp_mask = K.abs(y_pred)
perp_mask = K.sum(perp_mask, axis=-1)
sum_mask = K.sum(perp_mask, axis=-1, keepdims= True)
#print('perp_mask1',K.int_shape(perp_mask))
epsilons = 1 / 2 * y_pred + K.epsilon()
cliped = K.maximum(y_pred, epsilons)
log_pred = -K.log(cliped)
cross_e = y_true * log_pred
cross_e = K.sum(cross_e, axis=-1)
masked_entropy = perp_mask * cross_e
sum_entropy = K.sum(masked_entropy, axis=-1, keepdims= True)
celoss = sum_entropy / sum_mask
#print('celoss',K.int_shape(celoss))
return K.mean(celoss)
# ---------------------------------------------------------
# perplexity
# ---------------------------------------------------------
def fn_get_perplexity(y_true, y_pred) :
perp_mask = K.abs(y_pred)
perp_mask = K.sum(perp_mask, axis=-1)
sum_mask = K.sum(perp_mask, axis=-1, keepdims= True)
epsilons = 1 / 2 * y_pred + K.epsilon()
cliped = K.maximum(y_pred, epsilons)
log_pred = -K.log(cliped)
cross_e = y_true * log_pred
cross_e = K.sum(cross_e, axis=-1)
masked_entropy = perp_mask * cross_e
sum_entropy = K.sum(masked_entropy, axis=-1, keepdims= True)
perplexity = sum_entropy / sum_mask
perplexity = K.exp(perplexity)
return K.mean(perplexity)
# ---------------------------------------------------------
# 評価関数
# ---------------------------------------------------------
def fn_get_accuracy(y_true, y_pred) :
perp_mask = K.abs(y_pred)
perp_mask = K.sum(perp_mask, axis=-1)
y_pred_argmax = K.argmax(y_pred, axis=-1)
y_true_argmax = K.argmax(y_true, axis=-1)
n_correct = K.abs(y_true_argmax - y_pred_argmax)
n_correct = K.sign(n_correct)
n_correct = K.ones_like(n_correct, dtype='int64') - n_correct
n_correct = K.cast(n_correct, dtype='float32')
n_correct = n_correct * perp_mask
n_correct = K.cast(K.sum(n_correct, axis=-1, keepdims= True),
dtype='float32')
n_total = K.cast(K.sum(perp_mask,axis=-1, keepdims= True),
dtype='float32')
accuracy = n_correct / n_total
#print('accuracy',K.int_shape(accuracy))
return K.mean(accuracy)
4−13. 訓練処理(transform_train.py)
メモリ不足を防ぐため、train_on_batchを使用しています。Kerasの外でミニバッチ制御を行うことによって、メモリが節約できます。
また、Early stoppingも自作しています。
クリックして表示
# coding: utf-8
from tensorflow.keras.utils import to_categorical
from tensorflow.data import Dataset
from tensorflow.keras import backend as K
import numpy as np
import sys
import time
class Color:
BLACK = '\033[30m'
RED = '\033[31m'
GREEN = '\033[38;5;10m'
YELLOW = '\033[33m'
BLUE = '\033[34m'
PURPLE = '\033[35m'
CYAN = '\033[38;5;14m'
WHITE = '\033[37m'
END = '\033[0m'
BOLD = '\038[1m'
UNDERLINE = '\033[4m'
INVISIBLE = '\033[08m'
REVERCE = '\033[07m'
# *******************************************************************************
# *
# 訓練/テスト共通関数 *
# *
# *******************************************************************************
def train_test_main(kind, params, data) :
model = params['model']
e_train = params['e']
d_train = params['d']
t_train = params['t']
batch_size = params['batch_size']
emb_param = params['emb_param']
output_dim = data['output_dim']
#損失関数、評価関数の平均計算用リスト
list_loss = []
list_perplexity =[]
list_accuracy =[]
s_time = time.time()
row=d_train.shape[0]
dataset_on_batch \
= Dataset.from_tensor_slices((e_train,
d_train,
t_train)).batch(batch_size)
for i, (e_on_batch,
d_on_batch,
t_on_batch) in enumerate(dataset_on_batch) :
e = min([(i+1) * batch_size,row])
t_on_batch = to_categorical(t_on_batch, output_dim)
if kind == 'train' :
class_lr = params['class_lr']
lr, lr_cnt = class_lr.calc_lr()
K.set_value(model.optimizer.learning_rate, lr) # 学習率設定
result = model.train_on_batch([e_on_batch, d_on_batch],
t_on_batch)
else :
result = model.test_on_batch([e_on_batch, d_on_batch],
t_on_batch)
list_loss.append(result[0])
list_perplexity.append(result[1])
list_accuracy.append(result[2])
elapsed_time = time.time() - s_time
if i % 100 == 0 :
sys.stdout.write("\r"
+" "
+" "
+" "
+" "
+" "
+" "
)
sys.stdout.flush()
if kind == 'train' :
ctl_color = Color.CYAN
batch_counter = '{0:0>5d}'.format(lr_cnt)
l_rate = "{0:.6f}".format(lr)
else :
ctl_color = Color.GREEN
batch_counter = ' '
l_rate = ' '
sys.stdout.write(ctl_color
+ "\r"+str(e)+"/"+str(row)+" "
+ str(int(elapsed_time))+"s "+"\t"
+ batch_counter + " "
+ l_rate + " "
+ "{0:.4f}".format(np.average(list_loss)) + "\t"
+ "{0:.4f}".format(np.average(list_perplexity)) + "\t"
+ "{0:.4f}".format(np.average(list_accuracy))
+ Color.END)
sys.stdout.flush()
if i % 100 == 99 and kind == 'train':
model.save_weights(emb_param)
del e_on_batch, d_on_batch, t_on_batch
print()
return np.average(list_loss), \
np.average(list_perplexity), \
np.average(list_accuracy)
# *******************************************************************************
# *
# 学習メイン処理 *
# *
# *******************************************************************************
def train_main_proc(params, class_lr, data) :
model = params['model']
e_input = params['e']
d_input = params['d']
target = params['t']
batch_size = params['batch_size']
epochs = params['epochs']
emb_param = params['emb_param']
#===================================================================
# train on batch
#===================================================================
def on_batch() :
n_split = int(d_input.shape[0]*0.1)
e_val = e_input[:n_split,:]
d_val = d_input[:n_split,:]
t_val = target[:n_split,:]
e_train = e_input[n_split:,:]
d_train = d_input[n_split:,:]
t_train = target[n_split:,:]
p_train = {'model' : model,
'e' : e_train,
'd' : d_train,
't' : t_train,
'batch_size' : batch_size,
'epochs' : epochs,
'emb_param' : emb_param,
'class_lr' : class_lr }
_, _, _ = train_test_main('train', p_train, data)
model.save_weights(emb_param)
p_test = {'model' : model,
'e' : e_val,
'd' : d_val,
't' : t_val,
'batch_size' : batch_size,
'epochs' : epochs,
'emb_param' : emb_param }
return train_test_main('test', p_test, data)
#===================================================================
# メイン処理
#===================================================================
loss_bk = 10000
patience = 0
# tensorflow2だとmetrics_nameが空なのでコメントアウト
#print(Color.CYAN,model.metrics_names[0]+" "
# +model.metrics_names[1]+" "
# +model.metrics_names[2] ,
# Color.END)
for j in range(0,epochs) :
print(Color.CYAN,"Epoch ",j+1,"/",epochs,Color.END)
loss, perplexity, accuracy = on_batch()
#-----------------------------------------------------
# EarlyStopping
#-----------------------------------------------------
if j == 0 or (loss <= loss_bk ):
loss_bk = loss
patience = 0
#elif patience < 3 :
# patience += 1
else :
print('EarlyStopping')
break
return loss, perplexity, accuracy
5. ハイパーパラメータ
以下のとおりです。基本的に、原論文と同じ値を採用してます。
| ハイパーパラメータ | 値 |
|---|---|
| 埋め込み次元数 | 512 |
| 隠れ層次元数 | 512 |
| attention繰り返し数 | 6 |
| multi-head数 | 8 |
| dropout率 | 0.1 |
| ウォームアップピーク値 | 4000 |
| 入力系列長 | 50 |
| 出力系列長 | 50 |
この条件のとき、モデルに含まれるパラメータ数は、実に2億を超えます。これがLSTMなら、ぴくりとも動かないところですが、Transformerの動作は比較的軽いようです。
6. 訓練
こちらの記事に従って作成した、以下の各種ファイルを、ソースコードと同じフォルダに格納しておいてください。
| ファイル名 | 説明 |
|---|---|
| d.pickle | 訓練データ(デコーダーインプット) |
| e.pickle | 訓練データ(エンコーダーインプット) |
| t.pickle | ラベルデータ |
| indices_word.pickle | インデックス→単語変換辞書 |
| word_indices.pickle | 単語→インデックス変換辞書 |
| maxlen.pickle | 系列長 |
| words.pickle | 単語一覧 |
4-1節のソースコードを、以下のコマンドで実行すると、訓練が始まります。
$ python 1000_train.py エポック数 バッチサイズ パラメータファイル名
今回使用したデータのサイズは約8万と、かなり少なめです。バッチサイズには50を指定しました。
筆者の実行環境における1エポックあたりの訓練時間は約20分で、9エポックでEarly Stoppingがかかりました。そのときのperplexityは約130です。
7. 応答文生成
4-2節のノートブックを実行します。発話文入力用のダイアログボックスが開きますので、文を入力してみてください。応答文が生成、出力されます。
実行した結果は、以下のとおりです。
>> おはよう!
はい?
>> 今何してる?
うん。
>> ご飯食べた?
うん。
>> こんにちは。
ん?
>> それでは御免蒙りまするでござります。
ヘエ/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\してるから/\してるんですか。
同じ訓練データを使用したLSTMの場合に比べて、応答のバリエーションが増えています。「おはよう!」に「はい?」と返すあたり、なかなかだと思いました。
そこで、更にいろいろ試してみます。
>> 吾輩は猫である。
ふーん。
アンニュイに突き放す感覚が、goodです。
>> 国境の長いトンネルを抜けると雪国だった。
的にはなかったからになってるんですからということをするんですからね。
川端康成はさすがに、難しかったようです。しかし、似た単語を繰り返しながらも、ループに陥らなかったのは、頑張ったと言えるでしょう。
8. おわりに
以上、Kerasを使ってTransformerを実装してみました。確かに、Seq2seqよりも良い結果が得られている感じがします。今後はより規模の大きいコーパスを使って、応答精度がどれくらい改善するか、試してみたいと思います。
変更履歴
| 項番 | 日付 | 変更箇所 | 内容 |
|---|---|---|---|
| 1 | 2021/2/8 | - | 初版 |