はじめに
ランダムフォレストのアルゴリズムについてポイントで理解できるようまとめてみました。数式は使っていません。決定木についての理解があることを前提に記載しているので、決定木のアルゴリズムについて知りたい方はこちらをご参照ください。
参考
ランダムフォレストを理解するに当たって下記を参考にさせていただきました。
英語ですがわかりやすく詳細に説明されているので、より詳しくランダムフォレストについて理解されたい方はご参照ください。
- Random forests - classification description
- StatQuest: Random Forests Part 1 - Building, Using and Evaluating
- StatQuest: Random Forests Part 2: Missing data and clustering
ランダムフォレストの仕組み
ランダムフォレストの特徴
ランダムフォレストは簡単に言うと沢山の決定木を作成してその多数決をとるアルゴリズムです。下記のような特徴があり、非常に優れています。
- 精度が非常に良い
- 過学習を抑える効果がある
- 何千もの入力変数を削除せずにそのまま扱うことができる
- 各変数の事前のスケーリングが不要
- 交差検証や別個のテストデータでの検証をせずとも、アルゴリズム内で未知データに対する精度を推定することができる
- 欠落値を推定する方法を持っているため、欠損値の多いデータでも精度を維持することができる
- データ間の関係について情報を得ることができる
本記事ではなぜこのような特徴があるのかを含めて、ランダムフォレストのアルゴリズムのポイントを説明していきます。
ランダムフォレストの4つの基本ポイント
ランダムフォレストのアルゴリズムには大きく分けて4つのポイントがあります。
この4つが分かればランダムフォレストの大枠は理解できたと言える、と思っています。
- ブートストラッピング
- 使用する変数を絞る
- バギング
- OOB検証
ポイント①-ブートストラッピング
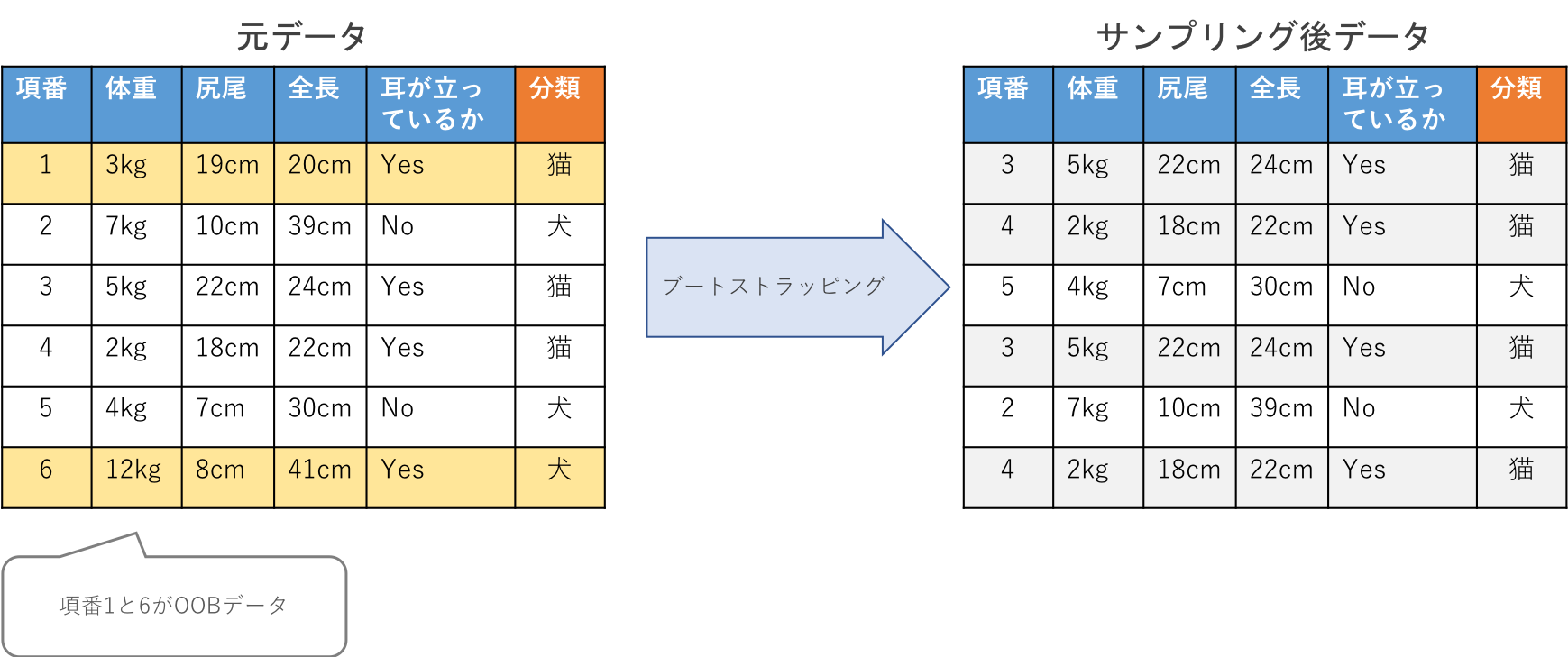
ランダムフォレストは決定木の集合体です。決定木を沢山作って森にしている訳ですが、その1つ1つの木の作り方にポイントがあります。まずは決定木を作成する際の訓練データの選び方です。
ランダムフォレストでは1つ1つの決定木を作成する際に、全データの中から重複を許してサンプリングを行い、そのデータを決定木を作成する際の訓練データとします。この手法のことをブートストラッピングと呼びます。

重複を許してサンプリングを行なっているので、もちろん訓練データの中には同じデータが含まれることもあります。
ポイント②-使用する変数を絞る
各決定木におけるノード(分岐点)作成する際に使用する変数を絞るのもポイントです。
データ全量の中に$p$個の変数があったとした時その全てを各ノードを作成するのに使うのではなく、$m$個の変数をランダムに選んで使用します。個数としては$m =\sqrt{p}$程度の数がよく用いられます。

「①→②」の工程を繰り返しながら大量の決定木を作成していきます。通常は100本以上の木を作成します。(sklearnのランダムフォレストのデフォルト値は100)「①→②」の工程を繰り返すことで多様な木が作成されますが、その多様さがランダムフォレストをより効果的にしています。
ポイント③-バギング(Bagging)
ランダムフォレストでは最終的に1本1本の木による多数決の結果を最終的な出力とします。
各学習器に使う学習用データのをブートストラッピングによって選び、その学習器を予測に用いて最後にアンサンブルする方法を**バギング(Bagging)**と呼び、ランダムフォレストはその一種です。(Baggingはbootstrap aggregatingの略)
バギング自体には分散を減らし、過剰適合を避ける効果があるため、ランダムフォレスト以外にも様々なところで用いられています。
ポイント④-OOB(out-of-bag)検証
ブートストラッピング法でデータをサンプリングすると必ずそこに選ばれなかったデータが発生します。大体元データの1/3程度のデータが残るのですが、そのデータのことをOOB(out-of-bag)データと呼びます。
このOOBデータによって未知データに対する精度を交差検証や別個のテストデータを要さず推定することができるのも大きなポイントです。
作成したランダムフォレストを用いてOOBデータを分類し、その分類の分類誤差を確認します(回帰の場合は最小二乗誤差等の指標を確認)。分類であれば、そのような誤分類されたOOBデータの割合をOOBエラー(out-of-bag-error)と呼びます。
このOOBエラーの率に応じて使用する変数の数(ポイント②)を調整することで精度の最大化を目指します。
ランダムフォレストの更なるポイント
ランダムフォレストのポイントとして下記も紹介します。
- 欠損値の扱いと近接度マトリクス(Proximities)
ランダムフォレストの説明において触れられていないことも多々ある(私も最初は知らなかった)のですが、ランダムフォレストが効果的なアルゴリズムである大きな要因だと思います。
欠損値の扱い
ランダムフォレストはデータに欠損値があっても問題なく扱うことができるのは大きな特徴です。学習データに欠損値がある場合、下記のステップで欠損値を推定します。
①取り敢えず他のデータの平均値を欠損値の推定値とする
↓
②ランダムフォレストのモデルを作成
↓
③**近接度マトリクス(Proximity matrix)**を使って欠損値を再推定する
近接度マトリクス
近接度マトリクスは少しわかりにくいのですが、下記のように作成します。
ランダムフォレストを作成した後、(訓練に使用したデータもOOBデータも合わせた)全てのデータをランダムフォレストにかけます。ランダムフォレスト内の各決定木において、それぞれ分岐して分類(または回帰)結果の出力を出しますが、末端ノードが同じ場所になったデータを近接度+1とします。それらデータ数×データ数のマトリクスの中に加算してゆき、近接度マトリクスを作成します。

ランダムフォレスト内の各決定木において近接度の計算を行い、最後に作成した木の数で割って標準化したものが欠損値の推定に使う近接度マトリクスになります。

近接度マトリクスを使った欠損値の推定
ランダムフォレストではこの近接度マトリクスを使用した欠損値の推定を行なっています。
まずは、平均で欠損値を埋めたデータを使ってランダムフォレストを作成します。そこで得られた近接度マトリクスを使用して再度欠損値を推定します。

この近接度を重みとして再度欠損値を推定します。

上記を繰り返しながらより正確に欠損値を推定してきます。
この近接度マトリクスは欠損値の推定に使うだけではなく、データ間の関係性を表すのに用いることもできます。(1-近接度マトリクス)はデータ間の距離を表すマトリクスであると言えるので、それらをヒートマップや2次元プロットにすることでデータ間の関係性を表すことができます。(sklearnライブラリのランダムフォレストには近接度マトリクスを出力する機能はないので注意)
ランダムフォレストを動かす
以下ではsklearnを用いてランダムフォレストを動かしてみます。
詳細なパラメータの説明は等は行わないので興味のある方はリファレンスをご確認ください。
sklearnを用いたランダムフォレスト
irisデータセットを用いてランダムフォレストを作ってみます。
データを訓練用データとテストデータを分けて、訓練データ用いてランダムフォレストを作ります。テストデータは精度確認用で使用します。OOBデータを用いた精度も合わせて出力し、前述のランダムフォレストの特徴で記載した通り未知データに対する精度と近いもになっているかをかも確認してみます。
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
iris = load_iris()
data = iris['data']
target = iris['target']
X_train, X_test ,Y_train, Y_test = train_test_split(data, target, test_size = 0.7, shuffle = True, random_state = 42)
rf = RandomForestClassifier(oob_score =True)
rf.fit(X_train, Y_train)
print('test_data_accuracy:' + str(rf.score(X_test, Y_test)))
print('oob_data_accuracy:' + str(rf.score(X_train, rf.oob_decision_function_.argmax(axis = 1))))
出力結果はこちらです。
test_data_accuracy:0.9428571428571428
oob_data_accuracy:0.9555555555555556
OOBデータ検証した時の方が精度は高くなりましたが、テストデータの方も交差検証をした結果ではないので誤差範囲かもしれません。また全体のデータ量が少ない時はOOBデータで検証した時の精度の信頼度は低くなるようです。
Next
続いては勾配ブースティングについてまとめた記事を出せればいいなと思っています。