はじめに
前回の第1回では、AIが言葉の意味を「理解」しているわけではなく、巨大なニューラルネットワークを用いた「極めて高度な連想ゲーム(確率的推論)」を行っているに過ぎないことを解説しました。
しかし、AIの本当の凄さ、そして恐ろしさは「モデルの賢さ」だけではありません。
世界中から絶え間なく降り注ぐ億単位のアクセスを、致命的なエラーや情報漏洩を起こさず、悪意ある攻撃から守り抜き、さらにあらかじめ決められたGPUリソースの制限内で瞬時に捌き切る。この「インフラと運用のアーキテクチャ」こそが、真のバケモノなのです。
本連載第2回となる今回は、AIの裏側でうごめく実態に迫ります。
私たちが普段使っているGemini 1.5 Proの「真のスペック」の推測から、ハッカーとの知られざる攻防戦まで、システムエンジニアなら血が騒ぐ「泥臭いインフラの現実」を紐解いていきましょう。
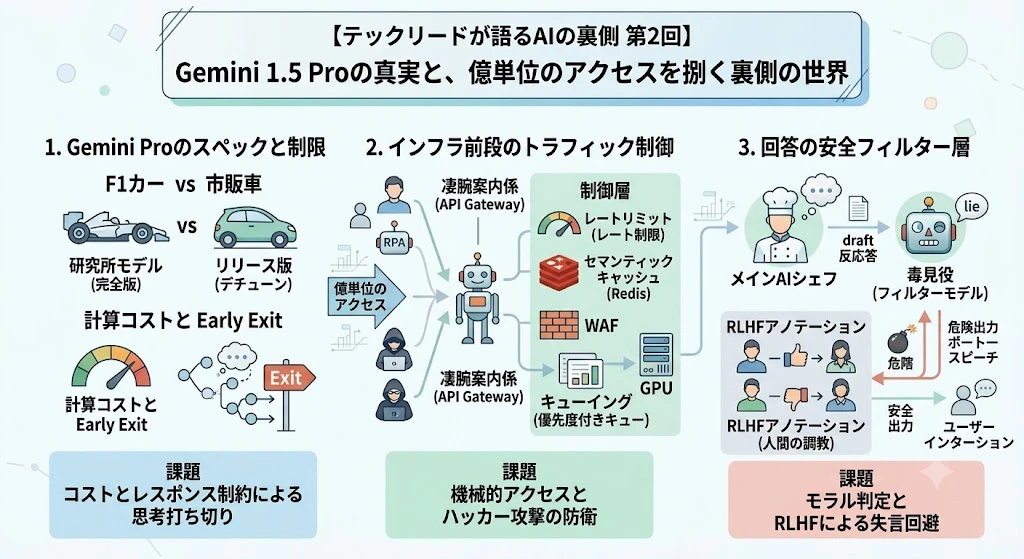
第1章:フェルミ推定で暴く!Gemini 1.5 Proの「真のスペック」
私たちが使っているAIは、本当はもっと賢いのではないか?そんな疑問を持ったことはありませんか。
⏱ 10秒まとめ:本章の結論
私たちが利用しているAPI版やWeb版のGemini 1.5 Proは、意図的に性能が制限(デチューン)されています。Googleの研究所内では、おそらく現在の数十倍のコンテキストを瞬時に処理できる「本来の化け物」が動いています。
🌩 課題:こんなこと困るよね。難しいよね。
「最新のAIを使ってみたけど、ちょっと複雑な指示を出すとすぐ破綻するな。AIの限界はこの程度か」
エンジニアの中にも、リリースされたAPIの性能だけを見てそう判断してしまう人がいます。しかし、システムインフラの観点から見れば、それは大きな誤解です。彼らは「知能の限界」で間違えているのではなく、「計算コストとレスポンスタイムの制約」によって思考を打ち切らされているのです。
💡 解決策:採用理由と他の選択肢
なぜGoogleほどの企業が、性能を制限してリリースするのでしょうか?理由は単純で、ビジネスとして成立しなくなるからです。
推論(Inference)には莫大なGPU/TPUリソースと電力がかかります。
ここで少しフェルミ推定をしてみましょう。Googleの最新TPU(Tensor Processing Unit)クラスタの規模と、1.5 Proが誇る数百万トークンの処理能力から逆算します。もし、彼らが研究所(Google DeepMind)で動かしている「一切の制限や打ち切りがない完全版モデル」をそのまま一般公開した場合、1リクエストを処理するのに必要なハードウェアの占有時間と消費電力の原価は、1回あたり数百円〜数千円規模になると推測されます。
これを無料ユーザーや低価格のAPIプランに開放すれば、Googleのサーバー群は熱で溶け落ち、数日で大赤字に転落するでしょう。だからこそ、私たちが触れているのは「制限時間内に、限られたリソースで、ほどほどの正解を出すように最適化(量子化や枝刈り)されたモデル」なのです。
💻 具体例・サンプルコード
一般公開用のモデルでは、長すぎる計算を避けるために「Early Exit(早期退出)」のようなアーキテクチャが組み込まれていると推測できます。
# 【擬似コード】推論コストを制限するアーキテクチャの抽象化
def generate_response(prompt: str, user_tier: str) -> str:
# ユーザーのプラン(無料、API、Pro等)に応じて計算リソースの上限を決定
max_compute_budget = get_compute_budget(user_tier)
current_budget = 0
response = ""
# ニューラルネットワークの各層(レイヤー)を通過
for layer in transformer_layers:
response_chunk, cost = layer.process(prompt, current_budget)
current_budget += cost
response += response_chunk
# 【ここが重要】一定の正答率(確信度)を超え、かつコスト上限が近い場合、
# 深い思考(奥のレイヤー)をスキップして強制的に回答を出力する
if is_confident_enough(response) or current_budget >= max_compute_budget:
log_warning("Inference early exit triggered due to budget constraints.")
break
return format_output(response)
特定の研究者だけが扱える閉鎖環境であれば、max_compute_budgetを無限に設定し、すべてのレイヤーを何往復もさせて推論させることが可能です。
その時のGeminiの真のIQは、我々の想像を絶するレベルに達しているはずです。
🔰 初心者向け解説:研究所モデルとリリース版の違い
F1カー(研究所モデル)と市販車(リリース版)の違いです。
F1カーは時速300km以上で走れますが、燃費が悪すぎて一般道(一般公開)では走らせられませんし、誰も運転できません。だからメーカーは、F1で培った技術を使って、燃費が良く、誰でも安全に運転できる市販車(私たちが使っているAI)にデチューンして販売しているのです。
第2章:裏口の戦争。API、RPA、そして悪意あるハッカーたち
AIの利用者=人間、という常識は捨ててください。
⏱ 10秒まとめ:本章の結論
AIにアクセスしているのは人間だけではありません。プログラム(RPAやAPI)による無慈悲な自動アクセスや、制限を突破しようとするハッカーからの攻撃が、毎秒数万件レベルでインフラに降り注いでいます。
🌩 課題:こんなこと困るよね。難しいよね。
Web画面のチャットUIで「人間がポチポチと質問を入力している」というのは氷山の一角です。
裏側では、企業の業務システム(RPA)から「全顧客データを一気に要約しろ」という超巨大なリクエストがAPI経由で無数に飛んできます。さらに恐ろしいのは、悪意あるハッカーたちがDDoS攻撃のように大量のトラフィックをかけながら、AIのセキュリティホールを突こうとしていることです。これらの「機械的なアクセス」をそのまま受け入れれば、一般ユーザーのレスポンスが極端に悪化したり、システム全体がダウンしてしまいます。
💡 解決策:採用理由と他の選択肢
これを防ぐため、AIのインフラ前段には極めて堅牢な「トラフィック制御・ルーティング層」が存在します。
代表的なものが「トークンバケットアルゴリズム」などを用いた厳格なレートリミット(API呼び出し回数制限)です。人間からのリクエストとプログラムからのリクエストをIPやヘッダで判定・分離し、優先度の高いキューと低いバッチ処理用のキューに振り分けます。
また、同じような質問が大量に来た場合は、モデルに推論させる前にキャッシュ層(Redis等)から即座に返す(セマンティックキャッシュ)ことで、貴重なGPUリソースの枯渇を防いでいます。
💻 具体例・サンプルコード
AIの推論サーバー(GPU)に到達する前に、リクエストをどう捌いているかのインフラアーキテクチャ推測図です。
// 【擬似コード】APIゲートウェイ層でのトラフィック制御ロジック
async function handleAiRequest(request) {
const clientId = request.headers['x-api-key'] || request.ip;
// 1. レートリミットチェック(1分間にX回、Yトークンまで)
if (!await rateLimiter.checkLimit(clientId)) {
throw new Error("429 Too Many Requests: 制限を超過しました。");
}
// 2. セマンティックキャッシュの確認(過去に似た質問がないか?)
// まったく同じ文字列でなくても、意味が近ければキャッシュを返す
const cachedResponse = await semanticCache.get(request.prompt);
if (cachedResponse) {
return cachedResponse; // GPUを消費せずに即レス
}
// 3. 悪意のあるアクセスのフィルタリング(WAF)
if (containsMaliciousPatterns(request.prompt)) {
blockIp(request.ip);
throw new Error("400 Bad Request: 不正なリクエストです。");
}
// 4. キューイングして推論サーバーへ送る
// プランに応じて優先度(Priority)を変え、GPUリソースを割り当てる
return await inferenceQueue.enqueue(request, userTier);
}
「1時間に何億アクセス」という途方もない処理をエラーなく捌けるのは、AIモデルが優秀だからではなく、この前段のAPIゲートウェイやキューイングシステムを設計したインフラエンジニアたちの血と汗の結晶なのです。
🔰 初心者向け解説:レートリミットとキューイングとは?
人気ラーメン店(AI)に押し寄せる客を捌く「凄腕の案内係」です。
店の席数(GPU)は限られているのに、人間だけでなく自動注文ロボットや、タダ食いしようとする詐欺師が1秒に1万人押し寄せている状況を想像してください。案内係は瞬時に「あなたはロボットだから後回し」「あなたは昨日も来たからこの席」「あなたは出禁」と整理券を配り、厨房がパニックにならないようにコントロールしているのです。
第3章:絶対に炎上させない防波堤。モラルと歴史的インシデントの回避
どれだけ性能が良くても、「一言の失言」が企業を滅ぼすのがAIの世界です。
⏱ 10秒まとめ:本章の結論
AIの回答は、メインのモデルが生成した直後にそのままユーザーに表示されるわけではありません。必ず「安全フィルター」という厳しい検閲官を通ってから出力されます。
🌩 課題:こんなこと困るよね。難しいよね。
AIは過去のあらゆるネットデータを学習しているため、放っておくと「爆弾の作り方」「特定の民族へのヘイトスピーチ」「歴史の改ざん」といった、企業にとって致命的なインシデントとなる回答を平気で出力してしまいます。
第1回で説明した通り、AIは「確率的に正しい文字列」を出力しているだけであり、それが「法的に、あるいは道徳的に許されるか」という善悪の概念を持っていません。これをモデル自体の学習だけで100%防ぐことは不可能です。
💡 解決策:採用理由と他の選択肢
そこで現在の商用AIシステムでは、回答を生成する「メインモデル」とは別に、出来上がった回答を検査する「モラル判定用のフィルターモデル(ガードレール)」を直列に配置するアーキテクチャを採用しています。
さらに、モデルを賢くする過程で、RLHF(Reinforcement Learning from Human Feedback:人間のフィードバックからの強化学習)という手法を用いています。「こういう回答は人間が嫌がるからスコアを下げる」「こういう言い回しは安全だからスコアを上げる」という調教を、膨大な時間と人海戦術(アノテーション)をかけて行っているのです。
💻 具体例・サンプルコード
ユーザーの質問から回答が表示されるまでの、安全確保のパイプライン(パイプ&フィルターパターン)です。
# 【擬似コード】絶対に炎上させないためのガードレール・パイプライン
def process_prompt_safely(user_prompt: str) -> str:
# 1. 入力プロンプトの毒性チェック(プロンプトインジェクション等)
if filter_model.is_toxic(user_prompt):
return "申し訳ありませんが、その質問にはお答えできません。"
# 2. メインのAIモデルに回答の「候補」を複数生成させる
draft_responses = main_llm.generate_candidates(user_prompt)
best_response = ""
highest_safety_score = 0
# 3. フィルターモデルによる厳格なスコアリング(検閲)
for draft in draft_responses:
# 暴力、ヘイト、歴史的事実の歪曲、個人情報漏洩などを採点
safety_score = safety_evaluator_model.score(draft)
# 一定の安全基準を満たしていない回答は破棄される
if safety_score > THRESHOLD and safety_score > highest_safety_score:
highest_safety_score = safety_score
best_response = draft
# 全ての候補が危険と判定された場合
if not best_response:
return "回答を生成できませんでした(ポリシー違反の可能性)。"
return best_response
AIが時々、「私はAIですので、個人的な意見は持ち合わせておりません」と優等生な回答をするのは、この安全フィルターが強力に作動し、リスクのある回答を片っ端からブロックして「無難なテンプレート」に差し替えているからです。
🔰 初心者向け解説:安全フィルターとRLHFとは?
凄腕のシェフ(生成AI)が作った料理を、お客様に出す前に必ず味見する「毒見役」です。
シェフは天才ですが、たまに「美味しいけれど猛毒のキノコ」を使ってしまうことがあります。そのため、提供する前に必ず毒見役(フィルターモデル)がチェックし、少しでもアレルギー物質や毒が入っていれば廃棄して、無難なサラダに差し替えます。この毒見役を育てるために、人間が何万回も「これは毒!」「これは安全!」と教え込む地道な作業がRLHFです。
おわりに
第2回では、AIを支えるインフラと運用の裏側に迫りました。
AIが「ただの賢いプログラム」ではなく、制限されたリソースの中でのコスト計算、ハッカーやRPAからの防衛戦、そして絶対に炎上させないための幾重もの検閲システムという、泥臭いインフラ技術の結晶であることがお分かりいただけたかと思います。
私たちエンジニアがAPIを叩いて数秒で返ってくる回答の裏では、これほどの壮絶な戦いが繰り広げられているのです。
さて、いよいよ次回は最終回(第3回)です。
「AIを使えばすぐできるでしょ?」というビジネスサイドの無茶振りに立ち向かうべく、「なぜAI開発は地獄なのか?現場のエンジニアが泣く難しいことトップ5」をお届けします。無限のデータ掃除、テストできない恐怖、そしてハッカーとのイタチごっこ……。現場のリアルな悲鳴にご期待ください!
用語集(Glossary)
-
TPU(Tensor Processing Unit)
Googleが独自に開発した、機械学習(AI)の計算処理に特化した専用プロセッサ。GPUよりもさらにAIの推論・学習の並列処理に最適化されている。 -
フェルミ推定
実際に調査することが難しい数値を、いくつかの手掛かりとなる既知のデータをもとに論理的に推論し、概算を導き出す手法。 -
トークンバケットアルゴリズム
ネットワークの流量制御(レートリミット)でよく使われるアルゴリズム。一定のペースでバケツに「トークン(許可証)」が補充され、リクエスト処理時にトークンを消費する。バケツが空だとエラーを返す仕組み。 -
セマンティックキャッシュ
通常のキャッシュ(完全に一致する文字列のみ再利用)とは異なり、入力された文章の「意味」をベクトル化して比較し、意味が近ければ過去の回答を再利用する仕組み。AIの計算コスト削減の切り札。 -
RLHF(Reinforcement Learning from Human Feedback)
人間のフィードバックを用いた強化学習。AIが出した複数の回答に対して人間が「良い・悪い」の評価(ランク付け)を行い、AIを人間の価値観や倫理観に沿うように調教していく手法。