データベース設計と障害対策の基礎 〜レプリケーションと主キー採番の最適解〜
はじめに
システムのインフラ構成を題材に、システムがどう守られているか、可用性を高めるレプリケーションの仕組み、そしてシステムを破綻させないための主キー(Primary Key)採番のベストプラクティスを順を追って解説します。
概要:
本記事では、GCP(Google Cloud Platform)の「東京・大阪マルチリージョン構成」を例に、障害発生時の切り替え(フェイルオーバー)と、それに伴うデータベースの主キー(ID)採番で絶対にやってはいけないアンチパターンについて解説します。
もしも、マルチリージョンを採用していなければ、あまりこの記事を読む必要が無いと思います。
結論:
レプリケーションには同期と非同期があり、パフォーマンス重視なら非同期を選ぶ。
主キーの採番に MAX + 1 を使うのはシステムを破壊するアンチパターン。
非同期レプリケーション環境下での災害対策(DR)においては、通常の Sequence(連番)だとID重複の致命的リスクがあるため、クリティカルなデータには UUID を採用すべき。
1. インフラ構成概要(マルチリージョン)
具体的なデータベース技術の話に入る前に、まずはシステムがGCP上でどのように構築されているか、全体像を把握しましょう。
本システムは、広域災害に備えるため 「東京」と「大阪」の2つのリージョン(地域)にまたがったマルチリージョン構成 をとっています。
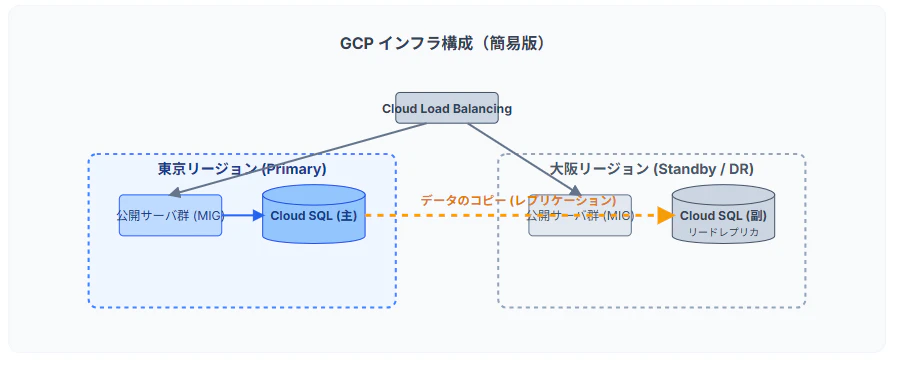
東京:メイン拠点(Primary)
通常時、ユーザーからのアクセスやデータの書き込みはすべてこの東京リージョンで行われます。データベース(Cloud SQL)も東京が「主(マスター)」として稼働し、システムの心臓部を担っています。
大阪:待機拠点(DR拠点)
東京がダウンした時のための保険です。Webサーバ等は最小限の台数で待機し、データベースは東京の「副(リードレプリカ)」として設定され、東京からのデータ更新を常に受信・蓄積しています。通常時は直接書き込みできません。
💡 【初心者向け解説】ただのバックアップじゃないの?
データをファイルにして保管しておく「バックアップ」とは異なります。
大阪拠点は、データを受け取ったら すぐに動かせる状態(データベースエンジンが起動した状態) で待機しています。これを「ディザスタリカバリ(DR)拠点」と呼びます。車でいう「スペアタイヤ」のようなものです。
2. 障害シナリオと「手動フェイルオーバー」
なぜこのような構成にしているかというと、「東京エリア全体が停電や大震災で機能停止する」という最悪のトラブルを想定しているからです。
そのトラブルが発生した際に行われるのが、大阪への**「手動フェイルオーバー(昇格)」**です。
🚨 トラブル発生時の運用フロー(DR発動)
異常検知:ロードバランサが東京リージョンの完全停止を検知する。
状況判断:インフラチームが「東京の即時復旧は困難」と判断し、DR(災害復旧)の発動を決定する。
手動昇格:大阪のCloud SQL(リードレプリカ)の設定を手動で変更し、「独立した新しいPrimary(書き込み可能)」に 昇格(フェイルオーバー) させる。
トラフィック切り替え:大阪のWebサーバへユーザーからのアクセスを全流しし、システムを再稼働させる。
ここで重要な疑問が生まれます。「東京から大阪へ、データはどのようなタイミング・仕組みで送られているのか?」
これが、次の「レプリケーション」の話に直結します。
💡 【初心者向け解説】フェイルオーバーとは
「フェイル(障害)」が起きた時に、待機していたシステムへ処理を「オーバー(引き継ぐ)」することです。飛行機で機長(東京)が突然倒れた時に、隣に座っていた副操縦士(大阪)がすぐに操縦桿を握ってフライトを続けるようなイメージです。「自動」で切り替わるシステムもあれば、本システムのように安全確認のため「手動」で切り替えるシステムもあります。
3. DBのレプリケーション(同期 vs 非同期)
東京から大阪へデータを複製(レプリケーション)する際、その書き込みのタイミングによって「同期」と「非同期」の2つの方式に分かれます。本システムは 「非同期レプリケーション」 を採用しています。
非同期レプリケーション (本システムの構成)
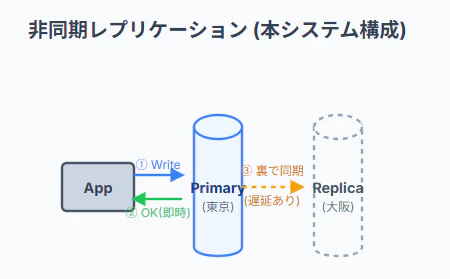
特徴: Primaryへの書き込み完了後、すぐにアプリへ「完了」を返す。Replicaへのコピーは後回し。
メリット: 処理スピードが速い。拠点間(東京-大阪等)の距離が離れていてもネットワーク遅延が影響しない。
デメリット: Primaryが突然死した場合、まだReplicaに送られていなかった数ミリ秒〜数秒分のデータが失われる(データロスト)可能性がある。
同期レプリケーション (銀行系などで採用)
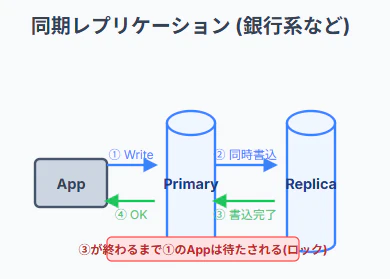
特徴: PrimaryとReplica両方への書き込みが完了するまで、アプリ側の処理をロックして待たせる。
メリット: データが100%一致するため、災害等でPrimaryが吹き飛んでもデータロストが一切発生しない。
デメリット: 遠隔地との通信往復時間がそのまま遅延(レイテンシ)になり、Webサービスとしての処理が重くなりすぎる。
本システムでは、Webアプリケーションとしてのパフォーマンス(応答速度)を重視し、あえて非同期を選択しています。
💡 【初心者向け解説】例えるなら…
非同期は「副操縦士にフライトログのコピーを頼んで、自分はすぐ次の操縦に移る」状態。仕事は速いですが、もし直後に機長が倒れ、副操縦士がログを受け取る前だと記録が少し消えます。
同期は「副操縦士がログを書き終わるまで、操縦桿を動かさずじっと待つ」状態。絶対に記録は無くなりませんが、操縦(システム)が重くなります。
4. 主キー(Primary Key)採番のアンチパターン
この構成とDRシナリオを理解した上で、システム内でデータを作るときの「ID(主キー)」はどう決めるべきか?
データベースに新しいデータを保存する際、重複しないIDを作る必要があります。この時、アプリ側で現在の最大値を調べて+1する(MAX + 1 や COUNT + 1)方法は、システムを破壊する恐れのあるアンチパターンです。
❌ MAX + 1 が引き起こす「同時実行の悲劇」
ユーザーAとユーザーBが、ミリ秒単位で同時にアクセスしたとします。
A:「現在の最大IDは?」→ 100
B:「現在の最大IDは?」→ 100 (Aと同じタイミング)
A:「じゃあ次は 101 でINSERTするぞ」→ 成功 (ID: 101)
B:「じゃあ僕も 101 でINSERTするぞ」→ 💥一意制約違反エラーでクラッシュ
⭕ 正しい解決策:Sequence(シーケンス)
RDBMS標準の機能である SEQUENCE(または IDENTITY / AUTO_INCREMENT)を使用するのがセオリーです。
シーケンスはデータベースエンジンがメモリ上で非常に高速かつ「アトミック(不可分)」に番号を払い出すため、どれだけ同時アクセスが集中しても絶対に番号が重複しません。
⚠️ シーケンスの仕様:「欠番(Gap)」は許容する
シーケンスから番号を取得した後、アプリ側でエラーが起きて処理を取り消し(ロールバック)した場合、一度払い出された番号は元に戻りません。つまり、IDが 100, 102, 103... のように飛ぶ(欠番が出る)ことが必ず発生します。
主キーの目的は「絶対に重複しないこと」であり、「綺麗に連番になること」ではないため、この欠番はシステム上正常な挙動として許容する必要があります。
💡 【初心者向け解説】整理券発券機を想像してください
MAX + 1 は、「最後に店に入った人に番号を聞いて、自分の番号を心の中で決める」やり方です。同時に複数人が来ると、同じ番号を名乗って喧嘩になります。
Sequence は、店の入り口にある「整理券のボタン」です。ボタンを押せば必ず被らない番号が出ます。もし券を取った後に帰ってしまった人がいれば、その番号は呼ばれない(欠番になる)だけです。
5. 災害対策(DR)時に現れる Sequence の罠
さて、通常時は完璧に見える Sequence ですが、これを先ほど学んだ「非同期レプリケーション」と「手動フェイルオーバー(DR)」の環境下で使うと、恐ろしいトラブルが待ち受けています。
本システムにおいて、Primary(東京)が壊滅し Replica(大阪)を手動昇格させる非常事態では、シーケンスの致命的な弱点が露呈します。
🚨 手動昇格による「シーケンス巻き戻り」のリスク
通常稼働: 東京でSequence 100 が発行され、外部API等へ連携済み。(※非同期のため、大阪はまだ 98 のまま)
大災害発生: 東京DBが壊滅。大阪への同期が間に合わずに停止。
手動昇格 (DR): 大阪DBをメイン化。しかし最新値のデータが届いていないため、シーケンスは 98 のまま再開。
重複発生: 大阪が新しくSequence 99, 100 を発行。すでに連携済みのデータとIDが衝突!
👑 究極の解決策:UUID (UID)
非同期レプリケーションの遅延によって「最新の整理券番号」の情報が大阪に届く前に東京が壊滅すると、大阪側で再び古い番号を発行してしまいます。
この災害時の巻き戻りによる重複リスクを完全に排除したい場合、UUID (Universally Unique Identifier) を使用します。
550e8400-e29b-41d4-a716-446655440000 のような16バイトのランダム文字列です。
📊 シーケンス vs UUID 比較表
| 比較項目 | シーケンス (Sequence) | UUID (UID) |
|---|---|---|
| 一意性(通常時) | 完璧(DBが保証) | 完璧(確率的に絶対被らない) |
| 一意性(DR・非同期切替時) | ⚠️ 巻き戻りによる重複リスクあり | ✅ 絶対に重複しない |
| パフォーマンス | 高速(連番なので効率的) | やや遅い(インデックスが断片化しやすい※) |
| データサイズ / 視認性 | 小さい(4〜8バイト) / 見やすい | 大きい(16バイト) / 人間には読めない |
(※SQL Server等では、通常のUUIDを主キー(クラスター化インデックス)にすると性能劣化が激しいため、NEWSEQUENTIALID() の使用などの工夫が必要です)
💡 【初心者向け解説】マイナンバーみたいなものです
UUIDは、一人ひとりに割り振られるマイナンバーや指紋のようなものです。いつ、どこで、誰が作っても、過去も未来も含めて絶対に他の人と被らない「宇宙で唯一のID」を作ることができます。そのため、副操縦士(大阪)の記憶が少し過去に巻き戻ってしまっても、新しく作られるIDが過去と同じになってしまうことはありません。
まとめ
アーキテクチャ設計において、「銀の弾丸」はありません。
インフラの構成(非同期レプリケーションとDR拠点)を正しく理解し、データの性質とビジネス要件に合わせて適切な採番方式を選択しましょう。
Sequence を推奨するケース
一般的なマスタデータ、ログ、パフォーマンスが最優先されるテーブル。災害時のわずかなデータロストや手作業での復旧が許容される領域。
UUID を推奨するケース
決済、契約データ、外部システムと連携するトランザクションなど。災害時のフェイルオーバー時であっても「絶対に重複(バッティング)してはいけない」クリティカルな領域。
システムの性質を理解し、適切なアーキテクチャとテーブル設計を選択していきましょう!