はじめに
第1回・第2回では、Firebaseと既存SQL Serverを連携させるための設計と、サーバーサイドでの検証の仕組みを解説しました。第3回となる今回は、既存システムにいる数百〜数千のユーザーデータを、いかに安全・高速・一貫性を保ってFirebaseへ移行させるか、「一括移行ツール(WPFアプリ)」の具体的な設計と実装について解説します。
概要:
本記事では、既存ユーザーデータをFirebaseへ移行するための専用ツールの必要性と、複数システムをまたぐ登録処理でデータ不整合を防ぐための「疑似ロールバック(補償処理)」アーキテクチャ、および並列処理時の落とし穴について解説します。
結論:
「Web画面からの手作業」ではなく、CSVを使った専用ツールで安全かつ高速に一括処理を行う。
DBとFirebaseの整合性を保つため、「DB保存 → Firebase登録」の順序を厳守し、Firebase登録失敗時はDB側を取り消す「補償処理(疑似ロールバック)」を実装する。
エラー発生時も「処理を途中で止めない」設計にし、並列処理のやりすぎによるAPI制限(429エラー)に注意する。
1. なぜ専用ツール(WPFアプリ等)を作るのか
既存システムで稼働しているユーザーの情報を、Webの管理画面から1件ずつ手作業でFirebaseに登録し直すのは非現実的です。入力ミスも発生しやすく、途中でエラーが起きた際のリカバリも困難です。
そのため、大量のデータを安全に処理するための 専用移行ツール(今回はWPFアプリを想定) を開発します。
このツールが担う主要な機能は以下の4点です。
1.CSVからの一括登録: CsvHelper などのライブラリを活用し、名簿データを一括で読み込む。
2.IDの固定化: 第1回で解説した「GUID固定でのUID指定登録(Admin SDK)」を自動で実行する。
3.データ整合性の担保: 万が一の失敗時にデータを元に戻す「疑似ロールバック」を行う。
4.高速化: Parallel.ForEachAsync 等を用いた非同期・並列処理で数千件を一瞬でさばく。
💡 【初心者向け解説】手作業 vs 工場ライン
Web画面で1件ずつ登録するのは、職人が手作業で1つずつ製品を組み立てている状態です。専用ツールは、ベルトコンベアとロボットアームを備えた「工場ライン」を作ることです。設計には手間がかかりますが、一度作れば大量の製品をミスなく超高速で処理できます。
2. 最重要設計:疑似ロールバック(補償処理)
これが一括移行ツールの核心であり、分散システム設計のキモです。
第1回でも触れた通り、FirebaseはSQL Serverの「DBトランザクション(失敗したら全部無かったことにする魔法の機能)」に参加できません。そのため、万が一途中で処理が失敗した場合、 自前のプログラムで「無かったこと」にする処理(=補償処理・疑似ロールバック) を実装する必要があります。
🚨 登録処理の正しいフロー
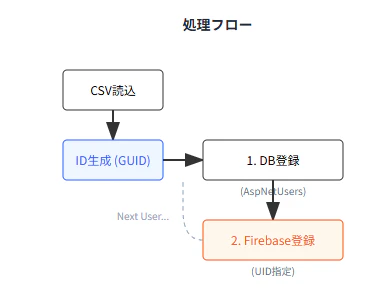
[GUIDを生成] 共通IDとなるGUIDを採番する。
[SQL Serverに保存] ← ここは通常のDBトランザクションで安全に保存(コミット)する。
[Firebaseに登録] 生成したGUIDをUIDに指定してFirebaseに登録する。
結果による分岐:
成功 → ✅ 登録完了
失敗 → ❌ SQL Serverから該当データを削除する(疑似ロールバック)
⚠️ なぜ「DB → Firebase」の順番なのか?
逆(Firebaseに登録 → DBに保存)にしてしまうと、DB保存が失敗した時に「Firebase上にだけ存在する孤立したユーザー(幽霊アカウント)」が生まれてしまいます。Firebase上のユーザー数が増えるとMAU(月間アクティブユーザー)課金に悪影響を及ぼす可能性があります。
DBのデータの方が削除(ロールバック)しやすいため、**「取り消しやすいDBを先に済ませる」**のが安全な設計です。
💡 【初心者向け解説】旅行の予約手配
「ホテル(DB)」と「飛行機(Firebase)」を予約するとします。ホテルはキャンセル無料ですが、飛行機は一度取るとキャンセルにお金がかかるとします。
この場合、絶対に「①ホテルを取る → ②飛行機を取る」の順番にすべきです。もし②飛行機が満席で取れなかったら、①のホテルをキャンセル(補償処理)すればダメージはゼロです。
3. CSVフォーマットとエラーハンドリングのポイント
一括登録に使用するCSVファイルの取り扱いにも、実運用を見据えた設計が必要です。
文字コードへの配慮: Shift-JIS または UTF-8(BOM付き)に確実に対応させ、文字化けを防ぐ。
項目の精査: Email、LastName、FirstName などの必須列と、CompanyCode などの業務固有の任意列を明確に分ける。
そして、最も重要なのが**エラーハンドリング(例外処理)**の設計です。
❌ 途中で止まるシステムは最悪のアンチパターン
1000件のデータを処理している最中、500件目でデータ不備によるエラーが発生したとします。この時、「処理を中断してツールを異常終了させる」のは絶対にやってはいけません。
残りの500件をやり直そうとした時、「どこまで登録が終わったか」が分からなくなり、再実行すると前半の500件で重複登録エラーの嵐になります。
⭕ 正しい設計:失敗はスキップして最後まで完走させる
1行失敗しても処理は絶対に止めず、 「エラー行の番号と理由だけをログに出力」 して、
次の行の処理へ進む(Continue)設計にします。
すべて終わった後、ログを見て失敗した数件だけを手直しして再実行するのがベストプラクティスです。
4. 並列処理(Parallel)での注意点と落とし穴
数千件のデータを1件ずつ直列で処理すると非常に時間がかかるため、C#の Parallel.ForEachAsync などを使って並列処理(マルチスレッド)を行います。しかし、ここにも落とし穴があります。
🚨 並列化の3つの罠
1.Firebase APIのレートリミット (429 Too Many Requests):
並列度(同時に実行する数)を限界まで上げすぎると、Firebase側から「攻撃(DoS)」とみなされて通信を遮断(429エラー)されます。
MaxDegreeOfParallelism の数値を適切に絞る(例:10〜20程度)調整が必須です。
2.ログ出力の順序崩壊:
複数のスレッドが同時に書き込みを行うため、ログの出力順序がバラバラになったり、ファイル書き込みが衝突したりします。
スレッドセーフなログ実装(ConcurrentQueue の活用など)が必要です。
3.UIスレッドのクラッシュ:
WPFなどのデスクトップアプリでは、裏側のスレッドから直接画面のプログレスバー(進捗状況)を更新しようとするとクラッシュします。
必ず Dispatcher.Invoke 等を使って、UIスレッドに処理を委譲して画面を更新する必要があります。
まとめ
ユーザーのデータ移行は、システム入れ替えにおいて最も神経を使う「心臓手術」のようなものです。
専用ツールを作り、安全かつ一貫した処理手順(DB先行)を自動化する。
トランザクションの壁を理解し、「疑似ロールバック(補償処理)」で不整合を防ぐ。
「止まらないシステム」を設計し、並列処理の罠(レートリミットやスレッドセーフ)を回避する。
次回は、このシリーズの最終回として「フロントエンド(React等)への組み込みとセッション管理の実装」について解説します!