lldarwin / 进化 arc 合集 — 单一栽培进化 / 选择压力 / 指挥者合奏 / 证伪与 Goodhart / 进化可视化 / Codex 双柱 / llcore CPU 进化 × 第三个轴
🌐 语言: 日本語 | English | 中文 | 한국어
📚 FullSense 合集系列
- llcore 验证 arc 合集
- lldarwin / 进化 arc 合集(this)
- llive 完全解说合集
- llmesh 合集
- 通俗版合集
目录
- 把 AI 进化了 500 代之后,世界上只剩下"我"和"预测编码之父卡尔·弗里斯顿"两个人 #25 — monoculture 的 honest disclosure 与选择压组件 lldarwin
- 仅靠「用眼镜测量」无法驱动进化 —— 选择压组件 lldarwin 的设计与实测 #26
- 一夜之间重写了 AI 进化 —— 真实 LLM 的 12 小时运行又一次在满分处饱和,6 个 PoC、4 个 Agent 与 Perplexity「各自独立地收敛到同一个结论」的那一夜 #27
- 让"指挥者"指挥不断进化的 AI 群体合奏来作答 — llive 的乐团式进化, 以及治好饱和的 3 个装置 #28
- "镜片饱和时,选择压力无能为力" — 用反证锤炼进化设计 #29(Goodhart 定律与 proxy fitness 的极限)
- 「展示」进化的技术谱系 #30 — 从 Conway 的生命游戏到 3DGS
- 让 AI 把 AI 当作下属来使用 #31 —— Claude 主导 + Codex 配属的「两根支柱」开发体制
- (连载 #32) llcore CPU PoC battery 完成
- (连载 #33) 过于整齐的结果不是胜利,而是警报 —— 用 proper power 给第三轴 ③ 一锤定音的一天
- (连载 #34) 六连战爬山实验弄清了「进化的③何时起作用」——而且 100 年前的进化生物学早已给出同样的答案
第1章 把 AI 进化了 500 代之后,世界上只剩下"我"和"预测编码之父卡尔·弗里斯顿"两个人 #25 — monoculture 的 honest disclosure 与选择压组件 lldarwin
📖 一句话概括
一句话概括:把 AI 群体以 8 位天才的"思维习惯"为种子进化了整整 500 代,结果活下来的却只有作者和弗里斯顿两个人——这是一份重大失败的记录。乍看像是一个"预测编码最强!"的感人故事,真相却恰恰相反。测验把所有人都打成了 100 分(满分通胀),无论选谁都拉不开差距,进化就此沦为一场"抽签"。打个比方,就好比在一个全员满分的班里选班长,票数分散,最后只剩下 2 个人而已。原因在于评价函数(给成绩打分的眼镜)坏掉了,本章正是讲到从这里意识到:"测量"之后还需要一件专门负责"淘汰"的工具 lldarwin。
📚 FullSense 知识库指南
FullSense 开发全史 60+ 篇文章(4 种语言版、故事化的阅读顺序指南、通俗易懂版、四格漫画)均已汇总至 Qiita Team FullSense KB(仅限团队成员)。
📚 连载导航(lldarwin 弧): #24-05 群体进化 → #25 本文(monoculture 的失败) → #26 设计篇 → #27 climax(实 LLM 饱和→开放端转折)。※ 各文均可单独阅读(链接用于回游)。
概念 hook: 在 llive 的派生群体进化中,我把人物 persona 作为 8 个系统的"种子"
播了下去。古瀬(=我)、弗里斯顿、米利奇、矶村、冈洁、格罗滕迪克、
冯·诺依曼、费曼。代表世界的 8 个智慧,在打完 500 代之后,活下来的会是谁——。结果,活下来的只有 我(52%)和预测编码之父卡尔·弗里斯顿(48%)这 2 个人。
冈洁、格罗滕迪克、冯·诺依曼、费曼,没有一个人留下后代,全都灭绝了。……这听起来像是一段感人的进化故事吗? 不是。这是一份大失败的记录。
进化并不是"选择了强者",而是 由于选择压为零,仅仅凭运气(遗传漂变)
偏向了 2 个系统而已。本文就是关于这件事的 honest disclosure,以及在
"测量(lleval)"之后所需的"淘汰(lldarwin)"组件的设计故事。
0. 用三行讲剧情(落语里的"垫话")
- 做了什么: 把 8 位智慧作为 persona 种子投入 llive 的派生群体进化,用 rich-proxy 评价跑了 500 代。
- 发生了什么: 第 1 代 best_score 就 钉在了 1.0,之后一直满分。8 个系统收敛为 古瀬 52% / 弗里斯顿 48% 这 2 个系统,其余 6 人灭绝。
- 真因: "满分一直出现"=选择压为零。无论选谁 fitness 都一样,所以进化实质上变成了掷骰子(遗传漂变)。
简而言之就是 "想在一场所有人都考 100 分的测验里排名次"。那谁能合格
当然就成了抽签。是测验不好。眼镜(lleval)起雾了。
1. 为什么把"人物"作为种子来播
llive 的进化层 (v0.B〜v0.F) 并不是让 1 个 LLM 变聪明,而是
让 N 个 llive 个体(genome)进行世代更替并相互评价的派生群体进化
(连载 #24-05 中详述)。
向那个 genome 初始注入"思考癖好"的机制就是 PERSONA_FX。
像"用预测编码观察世界的 Friston""从沉默与情绪中立起数学的冈洁"
那样,把实在智慧的认知风格映射到 genome 的 factor_affinity(对思考因子的
偏向)上,作为种子(founder)播下。
播下的 8 个系统:
| founder | 认知风格的种子 |
|---|---|
| 古瀬(我) | 来历志向・源流追踪・现实连接 |
| 卡尔·弗里斯顿 | 预测编码・自由能最小化 |
| 贝伦·米利奇 | active inference 的实现志向 |
| 矶村 | (用户指定的 persona) |
| 冈洁 | 情绪・整体直观・接受不确定性 |
| 格罗滕迪克 | 抽象化・一般化・结构的发现 |
| 冯·诺依曼 | 形式化・计算・多领域横跨 |
| 费曼 | 重组・第一原理・直观验证 |
🍵 休息点: 到这里如果脑海里浮现出"8 位天才被丢进 VR 大逃杀"
这幅画面就 OK。问题在于,这场大逃杀的 规则(评价函数)坏掉了。
正题从下一节开始。
2. 结果 — 只活下来 2 个人
500 代之后的系统占有率(max_lineage_share 的内訳):
古瀬 ████████████████████████████ 52%
弗里斯顿 ██████████████████████████ 48%
米利奇 (灭绝)
矶村 (灭绝)
冈洁 (灭绝)
格罗滕迪克 (灭绝)
冯·诺依曼 (灭绝)
费曼 (灭绝)
乍一看,似乎可以写出一个"预测编码(Friston)和来历志向(古瀬)战胜了
抽象数学(格罗滕迪克)和形式计算(冯·诺依曼)"的故事。
实际上在 SNS 上,"把 AI 进化一下,结果预测编码最强"或许还会刷屏。
但不做这件事,正是 FullSense 的 honest disclosure 规则
([[feedback_benchmark_honest_disclosure]])。当出现异常漂亮的结果时,
在觉得自己赢了之前先怀疑内訳。
怀疑的结果,就是下一节。

🗒️ "动动脑子啊" — 活下来的 2 个并不是因为聪明(只是靠 drift 残留)的自嘲(© Forbidden shibukawa / SHUEISHA・《零食吧 Basue》)
3. 真因 — "满分通胀"消灭了选择压
3.1 症状: best_score 从第 1 代就是 1.0
看日志,best_score 在第 1 代就已经是 1.0。之后 500 代一直 1.0。
在进化计算中,fitness 立即饱和(plateau)是典型的危险信号。
选择(淘汰)是"按 fitness 之差挑选亲代"的操作。可是所有人都满分的话,
就不会产生 fitness 之差。没有差异,那么锦标赛选择和轮盘选择都
退化为实质上的随机选择。
这就是 选择压为零 的状态。进化停止了,之后群体只是凭借 遗传漂变
(genetic drift) 自行偏移而已。8 个系统缩成 2 个,并不是"因为强",
而是 单纯的概率性吸入。
🤔 打比方(相声风):
逗哏「在一个所有人都考 100 分的班里选班长,结果票分散,只剩 2 个人……」
捧哏「那不是选举,那是抽签啊!」
——进化身上发生的,正是这种"抽签化"。
这里把"遗传漂变(genetic drift)"稍微讲细一点。从生物学上说,就是
不受选择压作用的中立基因,随着世代更替仅凭偶然就让频率发生偏移的现象。
即便往小池子里放 8 种颜色的金鱼,只要没人吃,几代之后 碰巧增多的 2 种颜色
就会占据池子。不是因为强,只是骰子的点数恰好那样滚出来。这次的 8→2,
正是这种"捞金鱼的池子"状态。
🤔 打比方(落语风):
「八公,掷 500 次骰子,按出现最多的点数定大将,你看怎么样」
「那可不是实力,那纯属赌博啊」
「正是。让进化去赌博,就是这次失败的真相。」
3.2 根本原因: 评价函数 fitness_rich 的双重坍塌
为什么满分会一直出现。追踪代码,fitness_rich(rich-proxy 评价器)有
2 个设计缺陷。
缺陷 1 — 把 factor_affinity 在所有层做成同值
genome 本应以"思考因子 × 内存层"的 2 维矩阵来拥有个性。可是在
archetype 生成时用 np.tile 把 factor_affinity 以相同值复制到了所有内存层。
逐层的差异=个性的一半,在进入评价之前就被压垮了。
缺陷 2 — 把 nearest 用 max(sims) 压成单一标量
个体与 archetype 的接近度,是从与多个 archetype 的相似度向量中
用 argmax(=只取最大值 1 个) 取出的。只看"和哪位天才最相似",
而把"和其他天才有何不同"全部丢弃。结果,只要稍微和某一个相似就得高分 →
立刻钉在天花板上。
本应如此: pressure profile = [典型性, 多样性, 专门性, ...] ← 多轴向量
实际实现: fitness = max(个体与各 archetype 的相似度) ← 单一标量
↑ 用 argmax 压垮 = 多目标性消失
也就是说 "本应用多把尺子去量的东西,只用 1 把尺子的最大值去打分"。
眼镜(lleval)只有 1 片镜片,而且还是会立刻满格冲顶的粗糙镜片。
🍵 休息点: 这里是本文的高潮。问题不在于"结果偏了",而在于
"让结果偏掉的原因是评价函数的坍塌",意识到这个两段式结构,
这篇文章你就算读完了。剩下的是"那么怎么修"。

🗒️ "成见可真深啊…" — 给"预测编码最强"那种过度自信的笃定泼盆冷水(© Forbidden shibukawa / SHUEISHA・《零食吧 Basue》)
4. 对策 — "测量"之后是"淘汰": lldarwin
llive 家族里已经有 lleval(眼镜 = 评价框架, 连载 #24-08)。
这次明白的是,即便眼镜能"测出"差异,如果不把那个差异正确地
转换成"谁能存活",进化就会坏掉。
于是我设计了新成员 lldarwin(选择压 = 淘汰组件)。
ll- 家族的分工变成这样:
lleval = 测量 (把个体的行为转换成多轴的 pressure profile)
lldarwin = 淘汰 (把那个 profile 转换成"下一代的亲代")
4.1 设计的核心 — "不聚合"的选择压
这次失败的本质就是 "把多个轴聚合成 1 个标量再 argmax"。
所以 lldarwin 的第一原则是 不聚合多个选择压的多目标淘汰。
采用的 3 层融合(用 rad-research 横跨 evolutionary_computation 616 件选定):
-
ε-lexicase 选择 — 把评价轴逐一依次独立应用。在某个轴上突出的
specialist(其他轴平庸)也能存活 → 多极结构被自动维持。
如果格罗滕迪克在"抽象化轴"上第 1,即使其他轴平庸也不会消失。 -
minimal-criterion QD (MAP-Elites) — 按 behavior 维度的每个 cell 保留 elite。
只要哪怕 1 个 cell 残留就不会全灭=在结构上让 monoculture 不可能发生。 -
down-sampling — 每一代只使用评价 case 的一个子集。由于标的会移动,
就无法钉在特定的 peak 上 → 摧毁 plateau(满分通胀)。
在此之上再加 minimal-criterion gate(不按连续排名,而按"是否满足最低标准"
来划分能否繁殖 = 抑制一强通吃)和 per-dim z-score 标准化(让"所有轴平均都高"=
无特征者不占优势)。
4.2 把"LLM 的短板"当作选择压
另一个方针是,把 LLM/VLM 现实中薄弱、且可测量的轴 选作 pressure
(避开无法验证的领域)。例如:
| pressure | LLM 的短板 | proxy/实 |
|---|---|---|
| typo_robustness | 对错字・噪声输入的一致性 | 可 proxy(合成 typo 注入) |
| polysemy_wsd | 多义词的语境依赖理解 | 可 proxy(WSD bench) |
| multistep_robustness | 多步推理的 cascade error | 可 proxy |
| calibration | 信心估计(token confidence ≈ random) | 可 proxy |
| visual_qa | 图像识别・visual hallucination | 必须实 VLM(Stage 后段) |
从可用 proxy 测量的轴做 PoC、实 LLM/VLM 轴放在后段,这种测量纯度的分离
也从一开始就纳入了设计([[feedback_llive_measurement_purity]])。
4.3 监控全灭 — SPC 报警
FullSense 的核心思想是 SPC(统计过程控制)。在 lldarwin 中也
每一代记录 max_lineage_share / archive 增长 / behavioral diversity,
用 SPC_ALARM 检测 monoculture 比 > 0.8 来自动调整 cadence 和参数。
目标是让这次的"8→2"在结构上不可能再发生。
5. 教训(作为 honest disclosure 留下)
-
异常漂亮的结果(best=1.0 立即饱和、收敛为 2 个系统)不是胜利而是警报。
怀疑内訳的结果,胜者并非凭实力,而是评价函数缺陷所产生的幻影。 -
"测量"和"淘汰"是两码事。 即便眼镜(lleval)能测出差异,如果用 argmax
把那个差异压成 1 条,淘汰就会坏掉。淘汰器(lldarwin)不可以聚合。 -
不抹掉失败。 不丢弃这次 500 代的 run,在配线 lldarwin 之后,
用它作为 baseline 来重跑验证"冈洁・格罗滕迪克等人是否存活"。
8→2 是否改善,是第一个合格判定标准。
下回预告: 实现 lldarwin 的 PoC Stage 0(proxy 轴 + ε-lexicase 配线 + QD archive),
重跑同样的 8 founder。这次冈洁真的能存活吗。
我们要去覆写"世界上只剩我和弗里斯顿"的那条世界线。
(设计的细节在 #26,把自己的反证抛向那个设计的 honest disclosure 续接到 #27。)
5.5. "眼镜"与"淘汰器"的 2 段结构 — 为什么要分开(深入)
本文最希望你带走的概念图就是这个:
个体 ──▶ [ lleval = 眼镜 ] ──▶ pressure profile(多轴的 case 向量)
│
▼
[ lldarwin = 淘汰器 ] ──▶ 下一代的亲代
#25 的失败,本质在于这 2 段两者都坏掉了:
-
眼镜侧的故障:
fitness_rich用nearest = max(sims)把多个轴压成 1 个标量,而且立即满分。
→ 没在测量(看不见差异的眼镜)。 -
淘汰器侧的缺位: 不聚合的多目标淘汰(ε-lexicase / QD)压根没有被配线。
→ 无法淘汰(没有过滤器)。
重要的是 只修其中任意一侧都无法让进化恢复。
往饱和的眼镜里插入高级淘汰器,也淘汰不了"零差异";
没有好的淘汰器只把眼镜修好,也用不上 profile。
"测量"和"淘汰"是不同的故障,需要分别去修 ——这就是 #25→#26 的桥梁。
("不修眼镜只把淘汰器升级也是白费"这一反证,会在 #27 正面处理。)
🍵 休息点: 用摄影的比喻来说,lleval 是"测光表",lldarwin 是"采用哪一张照片"。
测光表坏了做不出相册,没有采用标准也做不出相册。两者都需要。
5.6. 图解构想(投稿前 SVG 化的候选)
为了让本文"用动态来吸引人"想准备的图(投稿前 SVG 化):
- 系统占有率的崩塌动画 — 沿世代轴让 8 个系统的条带被吸入 2 个系统的 animated SVG(金鱼池隐喻)。
- best_score = 1.0 立即饱和图 — 在第 1 代就钉到天花板的平坦线(一眼看出选择压为零)。
-
argmax 压垮图 — 多轴向量
[典型性, 多样性, 专门性, ...]被max()压成 1 根柱子的 before/after。 - 2 段结构图 — 把 §5.5 的"眼镜 → 淘汰器"作为 hero 图做成 animated。
- ll- 家族角色图 — 用 1 张图呈现 lleval(测量)/ lldarwin(淘汰)/ llive(个体)的关系。
这些计划搭载到 [[project_fullsense_animemd_branch_token_viz]] 的 animated SVG 表现层(声明式动画 → SMIL)上。
6. 相关
- 连载 #24-05「群体学习的 AI」— 派生群体进化的总结(本文的前提)
- 连载 #24-08「制作眼镜」— lleval(测量侧)
- 连载 #26「lldarwin 的设计」— 淘汰器的多目标淘汰 / ε-lexicase / QD(本文的续篇)
- 连载 #27「眼镜起雾时淘汰也无力」— 反证调查・Goodhart's law(honest disclosure)
- 设计书: lldarwin(淘汰侧)— 本文的原始素材
- 相关 memory: [[feedback_benchmark_honest_disclosure]] / [[feedback_llive_measurement_purity]] / [[project_persona_genome_integration]]
第2章 仅靠「用眼镜测量」无法驱动进化 —— 选择压组件 lldarwin 的设计与实测 #26
📖 一句话概括
上一章弄明白了"眼镜(评价)坏掉了",本章便着手设计一件全新的淘汰工具 lldarwin,并真正把它跑起来。要记住的关键词只有一个:"不聚合"。因为一旦把多把尺子的分数加总成一把,那种只在数学上满分的天才般的"尖锐个体"就会输给平均分的优等生而被淘汰消失。于是我们把逐轴单独审视的 ε-lexicase 等手法捆在一起来拯救那些尖锐个体,再加上一个"每一代都悄悄复活灭绝谱系的中立贮藏库",结果冈洁也好、格罗滕迪克也好,全员复活了。最后一直讲到实测:面对真正的本地部署 LLM,进化 prompt 策略,把不擅长的任务从 0 分改善到满分。
📚 FullSense 知识库指南
FullSense 开发全史 60+ 篇文章(4 种语言版、故事化的阅读顺序指南、通俗易懂版、四格漫画)均已汇总至 Qiita Team FullSense KB(仅限团队成员)。
概念 hook: 在上一篇 #25 中,我曝光了一次巨大的失败:「把 AI 进化 500 代之后,世界上只剩下我和 Friston了。」
冈洁、格罗滕迪克、冯·诺依曼,全都在进化途中悄然消失。原因在于:评价函数(眼镜 = lleval)持续给出满分,导致选择压降为零。即使能「测出」谁更优秀,如果无法把这个差异转换为「谁能存活」,进化就堕落为单纯的遗传漂变。那么——既然眼镜让我们能「测出」差异,那把这个差异正确转换为「淘汰」的装置该如何制造?
那就是本篇的主角,lldarwin。它是 ll- 家族的新成员,是**专门负责淘汰(选择压)**的组件。本文希望你记住的关键词,只有一个:「不要聚合」。把多把尺子加总成一把的那一刻,进化就坏掉了。为什么会这样,以及我如何用实测跨越它——接着失败往下讲,这次说的是实际跑起来了的故事。
0. 三行概述(落语的「枕」)
落语在正题之前有「枕」。先用三行勾勒全貌。
- lleval 测量,lldarwin 淘汰 —— 进化只有作为「测量」与「淘汰」的两段式结构,才第一次有意义。
- 淘汰的第一原则是不聚合多个选择压的多目标淘汰。在此结构性地切断 #25 失败的真因(用单一标量的 argmax 压垮了它)。
- 采用的三大支柱 = ε-lexicase + minimal-criterion QD + down-sampling(横向调研 evolutionary_computation 语料库 616 篇后选定)。
而且这次与 #25 的区别在于:不仅有骨架,还有实测。用 novelty pressure 把行为多样性从 7.12 → 14.88(+109%)翻倍,用中立贮藏库实际全员复活了「已灭绝的冈洁、格罗滕迪克谱系」,最后面对本地部署的真实 LLM(llama3.2),进化 prompt 策略,把不擅长的任务从 0.0 → 1.0 改善。按顺序逐一来看。
1. 为什么要把「测量」与「淘汰」分开
llive 家族中已经有 lleval(眼镜 = 评价框架,连载 #24-08)。它是观测个体行为、按多个轴打分的装置。
然而 #25 揭示的是一个致命的真相。即使能用眼镜测出差异,一旦用 argmax 把那个差异压成一个,淘汰就坏掉了。 具体来说,fitness_rich 把多个 archetype 相似度用 nearest = max(sims) 折叠成了单一标量。这就是 SEL-2 违规——「best=1.0 饱和,所有人都拿满分,选择梯度消失」的真因。
明确区分职责的话,是这样。
lleval = 测量 (把个体行为转换为「多轴的 pressure profile」)
lldarwin = 淘汰 (把那个 profile 转换为「下一代的亲本」)
lleval 的输出是 case 向量(各轴分数排列成的数组)。lldarwin 把它作为输入契约接收,不聚合地进行淘汰。两者的职责边界正在于此。如果 lleval「把轴加总成一把之后」再交过来,lldarwin 就什么都做不了。所以对 lleval 一侧课以契约:「必须保留并传递 breakdown(按轴的分解)」。
lldarwin 的 Pressure 接口,由以下最小契约表达。
-
name—— 轴的名称(typo_robustness等) -
evaluate(individual_output) -> case_scores: list[float]—— 把个体行为转换为「按轴的分数数组」 -
is_proxy: bool—— 是 proxy 测量还是真实 LLM/VLM 测量(测量纯度的区分) -
minimal_criterion: float | None—— 该轴的最低繁殖标准(None 则无 gate)
要点在于:evaluate 的返回值是列表,而非标量。一个轴之内也有多个 case(测试用例),不压垮它们而直接流向 lldarwin。这种「不压垮」的设计,是后面拯救 specialist 的伏笔。
🍵 休息点: 把眼镜(lleval)与滤镜(lldarwin)分开的意义,用摄影来说就是「测光」与「决定采用哪一张」的区别。即使测光完美,选错最佳镜头相册也就毁了。即使曝光表(lleval)告诉你「这一张亮度 80 分、构图 30 分、表情 95 分」,你是把它四舍五入成「平均 68 分」而丢弃,还是「把表情 95 分的那一张另设一格保留」,相册的丰富程度会有天壤之别。lldarwin 是「采用判断」的专家。让测量者与挑选者一人兼任,通常两边都会变得粗糙。
2. 设计的核心 —— 「不聚合」的 7 个阶段
lldarwin 把从 lleval 接收的 pressure profile(多轴的 case 向量)通过以下 7 个阶段进行淘汰。对每一个都附上「为什么需要 = 防止哪种失败」。
-
Standardizer —— per-dim z-score。不偏向那种仅仅「全轴平均偏高」、毫无特征的优等生,而把各轴上的偏离转换为选择压。中心一致(与大家相同)被排除。
- 防止的失败: 「仅仅平均分高」的平庸者获胜、尖锐个体消失的 monoculture 入口。
-
MinimalCriterionGate —— 按各轴的最低标准划分繁殖资格。不让仅凭连续排名就「赢者通吃」。
- 防止的失败: 一强独占全部繁殖名额的全灭场景。以「只要满足标准谁都能繁殖」的「最低保障」保留多样性的地基。
-
EpsilonLexicaseSelection —— 把各轴作为 case 一个一个独立评价。在某个轴上突出的 specialist(其他轴平庸)也能存活。
- 防止的失败: 聚合 argmax 导致的 specialist 灭绝。这正是产生 #25 的 8→2 的机制本身。
-
QD / MAP-Elites archive —— 把 pressure profile 转换为 behavior 描述子,按 cell 保留 elite。archive 单调增长。
- 防止的失败: 结构性全灭。只要一个 cell 中哪怕残存一个个体,那个行为就不会消失。
-
Niching / FitnessSharing —— 对同一 niche 的个体降权,让多峰并存。
- 防止的失败: 向单峰的凝聚(monoculture)。
-
Down-sampling —— 每一代只用 case 的子集来评价,扰动环境。
- 防止的失败: 对特定 peak 的过适应与 plateau(停滞高原)。通过使其成为 moving target,不允许「用同样的方式获胜」。
-
NoveltyScorer —— 停滞时,向「与过去不同的行为」施加探索压。
- 防止的失败: 探索枯竭。当改善停止时,把新颖性本身作为奖励,推向外部。
与 #25 的 8→2 monoculture 对比,核心是三个:(3) ε-lexicase、(4) QD archive、(2) minimal-criterion。在 #25 中这些全部缺失,只有单一标量 argmax 在运转。所以「平均最强的一个谱系」把连续排名通吃,其余在漂变中消失。lldarwin 通过「不聚合地把这三个捆在一起」,构建出即使世代累积也不崩溃的结构。
🤔 比喻(漫才风):
捧哏「把考试分数全加起来排名,结果只剩下平均分高的优等生了。」
逗哏「那不是零多样性吗!数学 100 分、其他都 0 分的天才不见了啊!」
捧哏「不过,论总分还是优等生更高啊……」
逗哏「别看总分! 一个科目一个科目看的话,那个天才在『数学』这个 case 上谁都赢不了。ε-lexicase 就是拯救这个的机制。一加总,天才就死了。」
——加总(聚合)杀死 specialist。因为 ε-lexicase「一个科目一个科目地看」,尖锐的家伙才能存活。这就是 lldarwin 的头号要义。
3. 为什么是这 3 大支柱(rad-research 的支撑)
作为「即使世代累积也不崩溃」的最有力融合方案,我横向调研了 evolutionary_computation 语料库 616 篇后选定。来历很重要:我不是自己发明的,而是从既有研究中甄选并捆绑了「不聚合」的谱系。
| 方法 | 效用 | 出处 |
|---|---|---|
| ε-lexicase | specialist 保存、high population diversity | La Cava 2019 (arXiv 1905.13266) / 2204.06461 |
| QD / MAP-Elites | 凭 per-cell elite 实现全灭不可能 | Fontaine CMA-ME 2019 (1912.02400) / MNSLC GECCO 2024 |
| down-sampled lexicase | 环境扰动、降低成本 | Helmuth & Spector 2021 (2106.06085) |
| island + extinction/repopulation | 防止早熟收敛(将来选项) | Lyu 2020 (2005.07376) |
三大支柱看似各不相干,实则可以被**一个思想「不聚合」**串成一串。ε-lexicase「不聚合各轴」。QD「不聚合行为空间(按 cell 保留)」。down-sampling「不固定评价环境(每代扰动)」。它们都在「不把它们揉成一把」这一点上共享相同的哲学。所以即使组合,思想也不冲突,反而相乘增益。
🍵 休息点: 有人问「为什么不自己发明?」答案很简单:因为既有研究的组合已经足够强。我的开发规则([[feedback_originality_over_imitation]])写道:「外部算法的采用是甄选而非穷尽。排除崩溃风险与单纯模仿,只采纳能为原创设计增值的东西。」lldarwin 的原创性不在于「发明了新的选择算法」,而在于「不聚合地把它们捆起来的捆法,以及把它实际接线进 llive 的进化循环」。用做菜来说,不是创造世界首创的食材,而是把既有的名食材「不混合地盛在一盘」的手艺。把混合就会毁掉的食材,不混合地使其共存。
4. Stage1 —— 用 criteria 排除 + novelty pressure 把行为多样性翻倍
从这里开始是实测。Stage1 中,没有一下子把设计全部实现,而是只放入最可能有效的两个改动来测量(llive, branch optimize/core-2026-05-20, commit 8060204)。
改动 1: criteria 排除。 从 ε-lexicase 的 case 中,移除了 factor_score(= max-archetype 的单一标量 = argmax,正是 #25 的 best=1.0 饱和的真因)与 nearest_persona_idx(= 顺序无意义的类别 index)。这是一次「把坏尺子从淘汰的判断材料里清除」的打扫。
改动 2: novelty pressure。 启用 MultiPressureSelector(use_novelty=True)。每一代计算与过去世代 archive 的 k-NN 平均距离(Lehman-Stanley 流的 novelty),在群体内做 z-score 化(STD-1),作为附加的 lexicase case 混入淘汰。把「在做着与大家不同的行为」这件事本身,作为轴之一来评价。
测试方面,把 tests/unit/test_evolutionary_lldarwin.py 从 8 → 10 个扩展(增加排除、novelty 保存)。进化系 847 个 green,无回归。
实测条件是 rich-proxy、8 founders + pop24、150 代、seed 0。结果如下。
4.1 行为多样性 (diversity_l2) —— novelty 见效的指标
| 条件 | mean | tail30 min | final |
|---|---|---|---|
| BASELINE(排除前、相当于 Tournament 的旧 lldarwin) | 7.12 | 0.68 | 0.83(崩溃) |
| A: 仅 criteria 排除 | 9.16 | 1.57 | 1.57 |
| B: 排除 + novelty | 14.88(+109%) | 6.56(9.6×) | 11.73(避免崩溃) |
novelty pressure 把行为(genome 空间)的多样性维持在约两倍,防止了终盘的多样性崩溃。仅 criteria 排除单独也有效(清除了 spurious 的 argmax 压那部分)。BASELINE 在 final 0.83 处崩溃,而条件 B 在 final 11.73 处站稳了脚跟。这是「不聚合」设计的第一份手感。


把两张并排,终盘行为的差异一目了然。baseline 的多样性曲线贴在地板上,而有 novelty 的则保持高水平一路跑到终点。
🍵 休息点: 用金鱼池来比喻 novelty pressure——如果只留下围着饵(高 fitness)扎堆的金鱼,迟早会变成所有金鱼在同一处做同样动作的池子。novelty pressure 就是那个「给在不同地方游的金鱼也发奖金」的角色。结果是一个金鱼散布各处、看不腻的池子。但在这里不能松懈。下一节,会发现潜伏在这「热闹的池子」里的陷阱。
5. honest disclosure(最重要)—— 我把行为多样性与谱系存活混为一谈了
这是本文最重要的一节。即使出了好数字(+109%)也不能就此自以为赢——这是我的铁律([[feedback_benchmark_honest_disclosure]])。我怀疑了内幕。然后,找到了错误。
5.1 谱系固定 (founder_counts) —— novelty 无法改善的指标
在同一份实测里,看另一个指标。「8 个 founder(祖先谱系)中,有几个谱系存活到了最后?」
结果是——在所有条件下,最终都从 8 → 2 个谱系(furuse-kazufumi + friston)收敛。oka-kiyoshi(冈洁)/ grothendieck(格罗滕迪克)/ von-neumann / feynman / millidge / isomura 全部灭绝。
明明放入了 novelty 把行为多样性翻倍,谱系的存活却与 #25 完全相同,是同样的 2 个谱系。
5.2 为什么 —— 我混淆了两种「多样性」
设计书(#25 时点)的 TODO 写着「在重跑中验证冈洁、格罗滕迪克谱系是否存活」。这就是把行为多样性与谱系存活混为一谈了。
poc_evolution_env.py 的作者注释(L129-132)精确地点中了这个混淆。
"monoculture = BEHAVIORAL concentration (max archive-cell occupancy)…
neutral drift (Kimura) regardless of mechanism — that is expected, not collapse.
The OE signal is behavioral spread. lineage_fixation … to keep it <1 needs QD niching on lineage / PERSONA-FX, not pure novelty"
掰开来讲,是这样。
- 已证实的 monoculture 0.05 是行为性的(archive-cell 的占有率),而不是谱系性的。novelty/lexicase 改善的是「行为的扩散」,而非「祖先的存活」。
- 谱系固定因中立漂变(木村资生的中立进化论)而趋向 monoculture,是理论上正常的。这不是崩溃。novelty 与 lexicase 都只拥有保存既有个体的机制,而没有让一旦灭绝的谱系复活的机制。所以谱系固定从结构上无法阻止。
- 此外,archetype 之间的距离也被压缩在 0.068~0.29(相似度密集于 0.71~1.0),选择梯度弱,drift(漂变)占主导。friston 是最非中心的(centroid 距离 0.162),却存活了 = 不是中心性(强度),而是凭运气(drift),2 个谱系被固定了下来。
也就是说——我「希望冈洁、格罗滕迪克存活」的愿望,是一种用提升行为多样性的药绝对治不好的病。我用错了药。这是值得诚实记录的教训。
🍵 休息点: 用漫才来说。
捧哏「在池子里增加了各种五颜六色动作的金鱼!多样性满分!」
逗哏「那,血统呢?原本有的 8 个金鱼家系,还剩几个?」
捧哏「……2 个。」
逗哏「动作那么花哨,家谱却空空如也啊!动作的多样性和血统的多样性是两码事!」
——「行为多样」与「谱系多样」,是看起来相像、实则完全不同的指标。我把它们混淆了。诚实曝光。
6. Stage1.5 —— 用中立贮藏库让灭绝的谱系复活
一旦弄清病的真面目,就能换药。谱系存活所需要的,是「让灭绝的谱系每代 re-inject 的机制」——lineage-niched 中立贮藏库(reservoir)。
6.1 先用 PoC 确认机制
没有一上来就改造正式循环,而是先用 standalone PoC 确认机制能转起来([[feedback_poc_feasibility_first]] = 需求 → PoC → 可行性 → 详细设计,llive scripts/poc_lineage_reservoir.py, commit 0d0537d)。
selection 沿用 Stage1 的 MultiPressureSelector(criteria 排除 + novelty)。fitness 是 rich-proxy。谱系从 parent_a 继承。reservoir = 按谱系保留 best-ever genome,并把灭绝的谱系每代 re-inject(替换掉低 score 的子代;best 不破坏)。用 8 founders + pop24 + 150 gens + seed 0 测量。
| reservoir | 最终 named 谱系 | lineage_fixation (tail30 mean) | diversity_l2 (tail30) |
|---|---|---|---|
| OFF | 1(oka-kiyoshi 24/24 = 完全 monoculture) | 1.00 | 1.58 |
| ON | 8(全 founder 存活) | 0.31(≪ 0.8 OE-3) | 1.69 |
reservoir ON 时,包括冈洁(oka)、格罗滕迪克(grothendieck)在内的全部 8 个谱系存活。最终 shares 为 friston 7 / furuse 6 / grothendieck 4 / oka 3 / 其余 4 个谱系各 1。强谱系带着子孙繁殖,弱谱系由贮藏库维持生命,这是理想的行为。行为多样性也未下降(1.69 vs OFF 1.58)。
Honest 保留(PoC 阶段): 由于贮藏库再投入 frozen elite(被冻结的代表),弱谱系(各 1 体)的「存活」是来自再投入,而非主动进化。这符合中立贮藏库的定义(保留代表,使其可再组合),是正当的,但我不主张「弱谱系仍在活跃地持续进化」。
6.2 嵌入正式 EvolutionLoop(additive + default-off)
由于 PoC 已确认机制,我把它嵌入了正式的 EvolutionLoop(commit b03cbda)。设计的关键是 additive 且 default-off——丝毫不改变既有行为,只在立起标志时才生效。死守了向后兼容。
- 增加
EvolutionLoop.on_population_bredhook(可在 breed 之后、评价之前转换 bred 列表;默认 None = 向后兼容)。 -
LineageReservoir(lineage_reservoir.py): 祖先追踪(继承 parent_ids[0])+ 按谱系保留 best-ever + 灭绝保护谱系的 re-inject。共享founder_map,与谱系日志保持一致。 - 增加
run_persona_evolution(lineage_reservoir=True)/ run 脚本--lineage-reservoir。 - tests:
test_evolutionary_lineage_reservoir.py6 个 + 进化系 937 green(无回归)。
在真实 EvolutionLoop 中的实测(rich-proxy + lldarwin + novelty, 8 founders / pop24 / 150gens / seed0)。
| 条件 | named 谱系存活 | max_share | lineage_fixation (tail30) | diversity_l2 (tail30) |
|---|---|---|---|---|
| reservoir OFF (Stage1) | 2/8(furuse 17 + friston 7) | 0.71 | 0.70 | 14.88 |
| reservoir ON (Stage1.5) | 8/8(全谱系) | 0.33 | 0.29(≪ 0.8 OE-3) | 9.20 |
包括冈洁(oka 3)、格罗滕迪克(grothendieck 1)在内的全部 8 个谱系,在真实循环中存活。正式实现以 0.29 复现了 PoC 的预测(fixation 0.31)——这是机制按设计运转的证据。
这是本文最大的看点。请对比下面两张。


OFF(上):随着世代推进,stream 被吞入 2 种颜色——这是 #25 的「只剩我和 friston」的再现。ON(下):8 种颜色作为带子一直保留到最后。冈洁、格罗滕迪克,都没有消失。

🍵 休息点: #25 中我哀叹「只剩我和 Friston」的那个寂寞的世界。这次它变成了冈洁、格罗滕迪克、冯·诺依曼全都在场的热闹世界。这不是捏造,而是实际跑出来的结果(遵循 [[feedback_benchmark_honest_disclosure]],既不写虚假的失败,也不写虚假的成功)。但是——在得意忘形之前,请回想 §5 学到的态度。「出了好数字就怀疑内幕」。在下面的 §6.3,我诚实写下这次成功也是有代价的。
6.3 Honest 保留 —— 谱系保持与行为多样性是弱权衡
reservoir ON 时谱系全员存活。但仔细看,diversity_l2 从 14.88 → 9.20 下降了。由于每代再投入 frozen elite(冻结代表),genome 空间的扩散稍有减少。
不过,OFF 时的崩溃(final 0.83)被避免了。也就是说,这是一种弱权衡关系:「取谱系保持,行为多样性的峰值会略降,但能防止崩溃」。它不是零代价的魔法。我诚实写下来。而这个代价能压到多小,成为下一个 sweep 的主题。
7. 再投入频率 sweep —— 非单调最优点这一非平凡发现
我用 reinject_interval(执行再投入的世代间隔;默认 1 = 每代)的 sweep,对 §6.3 的 honest 保留(frozen elite 再投入会使 diversity 下降)做了特性化(commit da93dd3)。增加 LineageReservoir.reinject_interval + --reinject-interval 标志(test 7 个)。8 founders / pop24 / 150gens / seed0。
| interval | named 存活 | lineage_fixation (tail30) | diversity_l2 (tail30) |
|---|---|---|---|
| 1(每代) | 8/8 | 0.32 | 9.91 |
| 5 | 5/8 | 0.37 | 12.84(最大) |
| 10 | 3/8 | 0.41 | 11.41 |
| 20 | 2/8 | 0.44 | 10.75 |
这里有一个非平凡的发现。 直觉上你会预想「减少再投入(提高 interval),frozen elite 的塞入就减少,diversity 单调恢复」对吧?然而——diversity 并未单调增加,而是在 interval=5 处达到峰值,在 10/20 处反而下降了。
想想原因就能信服。把谱系放任过度(interval 太大),则 (a) 来自贮藏库的多样性注入减少,(b) 少数谱系被固定,结果 diversity 也长不上去。「再投入过多」和「放任过度」两边都不行,最优点在中间。这是不实际跑 sweep 就无法预测的知见。
运营指南变成了这样。
- 若以谱系保持为最优先 → interval=1(8/8 全谱系存活)。
- 若想兼顾行为多样性 → interval=5(保住 5/8 的同时 diversity 最大)。
兼顾的最优点依赖于 fitness 的设计与群体规模,所以正式环境中要用 sweep 重新标定。

🍵 休息点: 就像落语的 sage(包袱),这里有一个「背叛预期的转折」。本以为「越做越好」,结果是「做过头反而有害」。和给植物浇水一样:浇太少会枯,浇太多会烂根。最优点在中庸。做进化计算时,会一次又一次遇到这种「不单调的曲线」。所以要测基线,跑 sweep。直觉,常常被背叛。
8. Stage2 前半 —— 用 proxy 把「LLM 的弱点」变成选择压
到此为止都是用 rich-proxy(基于 persona 相似度的 heuristic)确认机制。接下来实现设计的另一根支柱:把「LLM/VLM 现实中弱、且可测量的轴」变成 pressure(一系列 commit, pressures.py)。
我把设计 §3 列出的 5 个可 proxy 的轴做成了 plugin。
| pressure(LLM 弱点) | 相关思考因子(case) |
|---|---|
| typo_robustness(噪声耐受) | consistency / reality_link / uncertainty |
| polysemy_wsd(多义词) | multiview / consistency / reality_link |
| multistep_robustness(多步推理) | structurize / closed_loop / self_extend |
| calibration(置信度估计) | uncertainty / provenance |
| context_management(无关上下文耐受) | consistency / provenance / recompose |
make_pressure_fitness() 把各 pressure 的 case(共 14 个)输出到 breakdown,lldarwin 的 ε-lexicase 不聚合地按轴淘汰 specialist。增加 --fitness pressure-proxy。tests test_evolutionary_pressures.py 4 个 + 进化系 942 green。
end-to-end 实测(pressure-proxy + lldarwin + novelty + reservoir, 8 founders / 120gens): named 谱系 8/8 存活 / lineage_fixation (tail) 0.67 / diversity_l2 (tail) 17.91。14 个弱点轴 case 被独立淘汰,行为多样性高。谱系由 reservoir 维持(由于 pressure-proxy 不直接奖励 persona 的同一性,优势谱系的 share 比 rich-proxy 的 0.29 更高,为 0.67)。

Honest 保留(设计 §7 / §7.1 已明示的已接受局限): 个体不是真实 LLM,而是 genome(llive 配置)。本 pressure 测量的是「genome 具备多少与该弱点相关的思考因子」这一行为的代理,而不是 production 的 LLM 能力。这仅限于 mechanism feasibility(机制能转起来)的验证。Goodhart 风险(hack proxy 的表面策略会进化)也是已接受的局限。真实 LLM/VLM 弱点轴的实测,留到 Stage2 后半(以 OLLAMA_HOST 设置 + 个体→真实 LLM 映射为前提)。
🍵 休息点: 这里容易被误解,所以再叮嘱一遍。我还没有说「用进化克服了 LLM 的弱点!」proxy 测的只是「机制是否转起来」。真实 LLM 是否变得对 typo 更鲁棒,在这个阶段完全不得而知。即使 proxy 出了花哨的数字(17.91),那也是「装置在运转」的证明,而非「内容变聪明了」的证明。一旦把这条线模糊掉,研究就成了谎言。所以接下来,我面对真实的 LLM。
9. Stage2 后半 —— 面对真实的本地部署 LLM,进化 prompt 策略
由于发现 localhost 的 ollama(llama3.2:latest 等)可达,终于可以进行真实 LLM 评价了(commit 2fb2912)。因为 localhost = on-prem,所以也满足 measurement purity(测量纯度,不与 cloud LLM 混用)的纪律([[feedback_llive_measurement_purity]])。
9.1 个体 → 真实 LLM 的映射(Promptbreeder 系)
关键是「如何让 genome 在真实 LLM 上生效」。我在 real_pressures.py 中实现了 个体 → 真实 LLM 映射。
-
把个体的
c_prompt(PromptChromosome)转换为 system prompt: skill_set → 指示文 / prompt_template_id → 推理风格 / language_style → 语调。把这个 system prompt 套在固定的 LLM(llama3.2)上,让它解 5 个弱点轴的真实任务并打分。 - 固定 LLM 本体,进化 prompt 策略(genome) = 用实测淘汰「哪种 prompt 策略能缓解 LLM 的弱点」。这是 Promptbreeder(用进化方式优化 prompt 的研究系列)的做法。
- temp=0(greedy)确定性地进行。把
(system_prompt, task)缓存(同一策略不再评价)。 - robust: per-call try/except(ollama 的 hiccup 当作 task 的失分处理,运行继续)。
- 增加
--fitness real-pressure/--ollama-model/--max-wallclock-seconds。tests 5 个 + 进化系 947 green。
9.2 真实选择信号的实证 —— CoT+structure 策略把 multistep 从 0.0 → 1.0
然后,观测到了真实的选择信号。
CoT+structure 策略(chain_of_thought + structurize + loop)把 llama3.2 的 multistep(多步推理)从 0.0 → 1.0 改善(terse 策略以 0.0 失败;score 从 0.80 → 1.00 上升)。
这意味着,lldarwin 的主张「用 prompt 策略的进化可以缓解 LLM 的弱点」,不是用 proxy,而是在真实 LLM 上实证了。即使是同一个 llama3.2 本体,根据套上去的 system prompt(= 进化后的 genome)不同,多步推理任务时而能解、时而不能解。进化实际选取了「能解的 prompt 策略」。

9.3 12h 连续运行
真实 LLM 评价很重,所以启动了长时间的连续运行(out/lldarwin_12h_realpressure_2026_05_26/)。
--fitness real-pressure --selection lldarwin --novelty --lineage-reservoir
--genome3d --population 24 --max-wallclock-seconds 43200 --checkpoint-every 5
在 wallclock 12h 处 safely 停止(已 snapshot → 可用 --resume 继续)。在连续运行中达到了 best_score=1.0。

9.4 Honest 保留(真实 LLM 评价的局限)
这里是从 #25 学到的态度的总决算。正因为出了花哨的结果(0.0 → 1.0、best 1.0),我才彻底诚实地写下内幕。
-
(a) 参与 fitness 的只有
c_prompt。 persona / c_factors 是中立的(谱系由 reservoir 维持,初始选择由 novelty 承担)。也就是说,这是「prompt 策略的进化」,而非「persona 的进化」。不是冈洁的人格变聪明了,而是与冈洁这个谱系绑定的 prompt 策略被选中了。 - (b) 全部 founder 的初始 c_prompt 相同(default)。 所以探索是 mutation 驱动的(按 founder 使 prompt 多样化是今后的改善)。由于起点相同,初始的谱系差异对 prompt 策略没有作用。
- (c) 小电池(每轴 2 题)= 噪声大的估计。 0.0 → 1.0 这一戏剧性数字,也因题目数量少而含有噪声。要做统计上稳健的主张,需要更大的电池。
- (d) on-prem only(measurement purity)。这不是关于一般能力的主张。 这是在 llama3.2 这一特定模型、特定任务上的观测,我不说「LLM 一般会这样」。
如果把这些藏起来,就能写出「进化让 LLM 变得戏剧性地聪明了!」这样花哨的故事,但那是谎言。lldarwin 实证的,只到「机制在真实 LLM 上产生选择信号」为止。越过那条线的主张,我不做。
🍵 休息点: 研究中最爽的,是喊出「0.0 变成 1.0 了!」的那一刻。但正是那一刻,[[feedback_benchmark_honest_disclosure]] 才发挥作用。「出了诡异地好的数字,自以为赢之前先怀疑内幕。」就这次而言——赢的是「prompt 策略」,而非「LLM 本体」也非「persona」。题目数量也少。只有 1 个 on-prem 模型。把这些全写出来,才第一次能说「实证了」。honest disclosure,是忍住炫耀的肌肉训练。
10. 既有资产的再利用(基于 codex 代码调查)
为了不让设计沦为画饼,我让配下的 Codex 调查既有代码,结果发现很多都是已实现、未接线。
-
mating.py:139 LexicaseSelection(带 ε,已实现但未接线 → 只需接线) -
nsga2.py:197 NSGA2Selection(用于 ≤3 目标 lane) -
diversity.py:94 NoveltyScorer/quality_diversity.py MAPElitesGrid/speciation.py SpeciationLayer
新实现: Standardizer / MinimalCriterionGate / Pressure 群 / MultiPressureSelector(核心)/ LineageReservoir(Stage1.5)/ SelectionAudit。
接线点: 在 loop.py:122 的 selection 注入 MultiPressureSelector,在 persona_evolution.py:606 增加注入口,把 LineageReservoir 接到 EvolutionLoop.on_population_bred hook。
🍵 休息点: 「已实现但未接线」最多,是最大的教训。即使做出好部件,不接线(编排)进化就仍然坏着。#25 之所以变成 8→2,是因为 ε-lexicase、NoveltyScorer、QD 都「在箱子里却没接线」。lldarwin 的本质,与其说是新算法的发明,不如说是「把既有的好部件不聚合地捆起来,并实际接线进进化循环」。即使把电子元件全凑齐,不焊接收音机也不会响。
11. 防止崩溃的保证 —— 不会全灭的多层结构(已由实测支撑)
反证 #25 的 monoculture(8→2)的多层结构,按设计齐备,而且这次得到了实测的支撑。
- MinimalCriterionGate —— 以最低标准定繁殖资格 → 抑制一强通吃。
- QD per-cell elite —— 只要残存 1 个 cell,谱系就不可能全灭(archive 单调增长)。
- Niching / FitnessSharing —— 对同 niche 降权 → 多峰并存。
- Down-sampling —— 用 moving target 破坏 plateau。
- per-dim z-score + 中心一致排除 —— 不偏向无特征者。
- LineageReservoir(Stage1.5 中追加) —— 灭绝谱系的中立贮藏库 → 从结构上阻止谱系全灭(实测 8/8 存活)。
- monoculture 监视 + SPC —— 每代记录 max_lineage_share,用 SPC_ALARM 检测 >0.8 → 自动调整。
特别是 (6),是承接 §5 的 honest disclosure(novelty 无法阻止谱系固定)而事后追加的一层。用实测找到设计的漏洞并堵上。实测的 lineage_fixation 为 OFF 0.70 → ON 0.29,大幅低于 OE-3 标准(<0.8)。以「不聚合」+「让灭绝谱系复活」的两段式,从结构上压垮 #25,是本文的到达点。
12. honest disclosure / 风险(前置铺垫)
我不盲信设计。把已接受的局限(下一篇 #27 深挖)再总结一次。
- Goodhart's law / proxy 偏离 —— 把 LLM 弱点做成 proxy fitness,「hack 指标的表面策略」就会进化(typo → 背诵特定替换、WSD → 利用测试的 heuristic 等)。proxy 仅限于 mechanism feasibility,不主张 production 能力。
- 设计者依赖性 —— lexicase=case / QD=描述子 / novelty=距离尺度,无论哪个,「多样性的方向」都由设计者决定。生物进化级别的未预想涌现是有限的。
- minimal-criterion 的停滞⇄崩溃权衡 / QD 的维度诅咒 + archive 饱和。
- 真实 LLM 评价的局限(§9.4 重述) —— 仅 c_prompt 参与 fitness、founder 初始 prompt 相同、小电池、on-prem only。
下回预告(#27): 我会诚实曝光最痛的反证——「当眼镜饱和,选择压就无力」,连同 Goodhart's law 与 proxy fitness 的局限。lldarwin 并非万能。能主张到哪里,是 #27 的主题。正因为这次出了「8/8 存活」「0.0→1.0」这样的好数字,下次才用反证来彻底锤炼它。
13. 结论
- 进化是「测量(lleval)」与「淘汰(lldarwin)」的两段式。淘汰的核心是 「不聚合」。
- Stage1: 用 criteria 排除 + novelty pressure,把行为多样性从 7.12 → 14.88(+109%)翻倍,避免了终盘崩溃。
- honest disclosure: novelty/lexicase 保住的是行为多样性,但谱系固定会因中立漂变(Kimura)趋向 monoculture。我混淆了两种多样性——诚实记录。
- Stage1.5: 用 lineage-niched 中立贮藏库,在真实 EvolutionLoop 中实现 OFF=2 谱系 / ON=全 8 谱系存活(含冈洁、格罗滕迪克),lineage_fixation 0.29(≪0.8)。这不是捏造,而是实际跑起来了。
- 再投入频率 sweep: 谱系保持↔行为多样性的权衡。diversity 在 interval=5 处达峰(非单调)这一非平凡知见。
- Stage2 前半(proxy): 把 5 个弱点轴做成 Pressure plugin(仅 mechanism feasibility)。
- Stage2 后半(真实 LLM): 用个体 c_prompt → system prompt 映射,对固定的 on-prem LLM(llama3.2)做真实任务打分。CoT+structure 策略把 multistep 从 0.0 → 1.0 改善。12h 连续运行达到 best=1.0。
- 不乐观、不自以为赢、分内幕地报告([[feedback_benchmark_honest_disclosure]] / [[feedback_llive_measurement_purity]])。
仅做出好部件,进化仍然坏着。不聚合地捆绑、实际接线、让灭绝的谱系复活、在真实 LLM 上确认选择信号——做到那一步,才终于把 #25 的「只剩我和 Friston」的世界,变成了冈洁、格罗滕迪克也都在的热闹世界。在下一篇 #27 中,我用反证重新追问:对这次的成功,能寄予多少信任。
14. 相关
- 连载 #25「只剩我和 Friston」—— 本文的动机(失败的记录)
- 连载 #24-08「制造眼镜」—— lleval(测量的一侧)
- 连载 #27「眼镜起雾,淘汰也无力」—— 反证调查(honest disclosure)
- 设计书: lldarwin(淘汰的一侧)
docs/vision/LLDARWIN_DESIGN.md - 实测正本:
docs/research/lldarwin_stage1_results_2026_05_26.md - llive commits: Stage1=
8060204/ 中立贮藏库 PoC=0d0537d/ Stage1.5=b03cbda/ reinject sweep=da93dd3/ Stage2 真实 LLM=2fb2912 - 相关 memory: [[feedback_benchmark_honest_disclosure]] / [[feedback_llive_measurement_purity]] / [[feedback_originality_over_imitation]] / [[feedback_poc_feasibility_first]]
☕ 闲话休题 —— AI 沉默的夜晚 —— llterm 开发的后台轶事
稍微离开正题,讲一件作者手头另一件工具的故事。为了让 Claude Code 跑起来,我自制了一个专用终端 llterm,可这玩意儿一点都不省心。最让我后背发凉的,是一个"AI 突然不说话了"的 bug。让它长时间自主运行时,会在某一轮之后应答戛然而止。这跟相声抖完包袱、观众安静下来不一样——这边是演员(AI)一声不吭地僵在台上,把后台的舞台监督(人)急出一身冷汗。原因其实很朴素:本该在每一轮交接处递过去的"那一句指令",从处理的缝隙里漏掉了,于是 AI 不知道下一步该干什么。
另一件后台轶事是抢光标。绘制 AI 输出的处理,和人敲键盘输入的处理,争抢同一块屏幕上的光标,字就跑到奇怪的位置乱码了。再掺进中文/日文输入法(IME),连转换中尚未上屏的待定字符都被卷进来,显示一团糟。这种"屏幕里的小打小闹",跟本文那些进化、淘汰之类光鲜的主题离得很远,是朴素而又脏又累的活儿。可要让 AI 长时间正经干活,正是这种后台的管线在默默起作用——这一点,或许和正篇里 lldarwin 看重"朴素的接线胜过华丽的数字",多少有点异曲同工。喝杯茶歇歇吧。
第3章 一夜之间重写了 AI 进化 —— 真实 LLM 的 12 小时运行又一次在满分处饱和,6 个 PoC、4 个 Agent 与 Perplexity「各自独立地收敛到同一个结论」的那一夜 #27
📖 一句话概括
这次终于用真正的 LLM(llama3.2)连续进化了 12 个小时——结果又在第 5 代就钉死在满分上,整整 65 代纹丝不动。也就是说,这仍然只是"带筛子的随机搜索",哪怕换上真正的 LLM 也还没成为真正的进化。于是作者熬了一整夜:亲手跑了 6 个小实验(PoC),另外并行放出 4 个 AI,再让 Perplexity 去翻文献,为的就是"把方策定下来"。结果到了早晨,所有人各自独立地抵达了同一个结论——"再怎么打磨淘汰器都是白费。要让评价(尺子)本身开放端化(做成不会在满分处停住的机制)"。正因为是从各自不同的路抵达同一个答案,才值得信任——这是一份通宵的决策日志。
📚 FullSense 知识库指南
FullSense 开发全史 60+ 篇文章(4 种语言版、故事化的阅读顺序指南、通俗易懂版、四格漫画)均已汇总至 Qiita Team FullSense KB(仅限团队成员)。
📚 连载导航(lldarwin 弧线):#24-05 群体进化 → #25 monoculture 的失败 → #26 设计篇 → #27 本文(高潮) → 实现篇(计划中)。※ 每篇文章都可单独阅读(链接用于回览)。
概念 hook:在上一篇 #25 中,我曝光了一个重大失败:把 AI 进化 500 代之后,世界上只剩下弗里斯顿和我。原因是评价函数(眼镜 = lleval)一直给出满分,导致选择压力降为零。
「那么这次,用真实的 LLM 来验证吧。」抱着这个想法,我对着 on-prem 的 llama3.2 连续进化了 12 个小时。不是 proxy(合成的尺子),而是真实 LLM。
结果。在 gen5 就钉死在满分,此后 65 代纹丝不动。不会全灭,但也不会累积。这不是进化,而是单纯的「带筛子的随机搜索」——不仅 proxy,即使用真实 LLM,也还没有成为进化。
由此,一个通宵。为了「决定方策」,我亲自跑了 6 个 PoC,并行启动了 4 个 Claude Agent,让 Perplexity 去翻文献。到了早晨,**所有人都各自独立地收敛到同一个结论。**这就是那份「通宵决策日志」的 honest disclosure。
0. 三行概要(落语中所谓的「开场垫话」)
落语在正题之前有「开场垫话」。先用三行说。
- 又饱和了 —— 真实 LLM(llama3.2) 跑 12h,gen5 就钉在 best=1.0,65 代无进展。不全灭但也不累积 = filtered random search(带筛子的随机搜索)。真因与 #25 相同:「固定的人工尺子的饱和」。
- 一夜之间决定了方策 —— 6 个自跑 PoC + 4 个并行 Agent + Perplexity 各自独立地收敛到同一个结论:「保持尺子固定却去打磨淘汰器是徒劳。让评价本身开放端化。」
- 独创性浮现了 —— 让一个持续进化的群体,在任意一瞬间不停下来地合奏(MoA)出一个答案的「现场管弦乐团(live orchestra)」,被证明是先行研究中的 white-space(空白地带)。
简言之:**「一旦眼镜(评价)饱和,无论怎么打磨淘汰器(lldarwin)都无力。」**所以改变打磨的对象——让评价本身开放端化,这就是本轮的结论。
1. 为什么「又」做了一次 —— #25 / #26(设计)的延续
用三行回顾迄今的连载:
- #24-05「群体学习的 AI」—— 不是让一个 LLM 变聪明,而是建立了让 N 个 llive 个体(genome)世代更替、相互评价的派生群体进化框架。
- #25「只剩下弗里斯顿和我」—— 把 8 位智者作为人格种子撒入该群体,跑 proxy 500 代后产生重大失败:满分饱和 → 选择压力为零 → 仅靠运气(遗传漂变)偏向 2 个谱系。眼镜蒙了。
- #26(设计篇)「只靠眼镜测量并不会进化」—— 设计了淘汰器 lldarwin,实现了「不聚合的多目标淘汰(ε-lexicase / QD / 中性储库)」。在 proxy 中防住了谱系灭绝。
到这里为止,全部都是关于 proxy(确定性启发式,不依赖 LLM)的。proxy 能展示「机制能转」,却无法展示「进化找到了有意义的东西」([[feedback_benchmark_honest_disclosure]])。
所以,理所当然的下一步:用真实的 LLM 来验证。
由于 localhost 的 ollama(llama3.2:latest)可达,我把每个个体的 c_prompt(prompt 策略的基因)转换为 system prompt,覆盖在固定的 llama3.2 之上去解实际任务——这是一种 Promptbreeder 系的映射——启动了 12 小时的连续进化运行。这就是本文的出发点。
🍵 休息点:如果你已经到了「proxy 里机制转起来了——那真实 LLM 呢?」这个问题,就够了。研究的好处就是可以实际去跑这个「那真实的呢?」而这一次,真实的——毫不留情。
2. 出发点 —— 真实 LLM 12h 运行的「诚实的不及格」
这是 12 小时真实 LLM 进化运行(on-prem llama3.2,严守 measurement purity = 不与 cloud LLM 混用,[[feedback_llive_measurement_purity]])的结果。
| 事实 | 数值 | 含意 |
|---|---|---|
| 完跑 | 71 代 / 12h(≒10.3 分/代,真实 LLM 顺序执行) | 吞吐量为瓶颈 |
| best_score | gen5 = 1.0 → 固定至 gen70 | 目标饱和。65 代无进展 |
| mean | 在 0.85 触顶,1.0 策略不席卷 | 适应不累积 |
| 各轴 | 10 题中 6-7 题饱和,梯度仅在 multistep(2 题) | 有效分辨率太小 |
| fitness 依赖 | 仅 c_prompt。c_factors(40 维)/c_impl/c_meta 中性漂移 | 43 个维度选择压力为零 |
| 群体健康 | pop=24 维持・min ≥ 0.70・未全灭 | 机制(GA)没坏 |
这里就是 FullSense 的 honest disclosure 规则让你停下脚步的地方([[feedback_benchmark_honest_disclosure]])。写成「没全灭!达到了 best=1.0!」听起来很成功。但看明细就一目了然。
判定:未全灭,但也不是累积进化(≈ filtered random search)。
10 题测试中,仍保有梯度(差异)的只有 multistep 的 2 题。其余 8 题很早就全员满分。也就是说 10 题中有 8 题,已经无论选谁都一样。选择压力的有效分辨率只剩下大约 2 题份。而且 4 条染色体中只有 c_prompt 这一条参与 fitness,其余 43 维(思考因子 40 维 + 实现 + 元)都是选择压力为零的中性漂移。
真因 = 人工固定尺子的饱和。用户在 #25 中言明的洞见「一旦眼镜饱和,选择压力就无力」,这次我们不是用 proxy 而是用真实 LLM 实证了。把眼镜从 proxy 换成真实 LLM 也没用:**只要尺子是「固定的 10 题」,就会很快在满分处饱和。**换了镜片厂商,刻度若粗也是一样。
🤔 比喻:即使把判分者换成「真正的老师」(真实 LLM),如果每次出的题都一样,几轮内大家都会拿满分,此后无论考多少次都拉不开差距。不是题目不好,而是试卷固定且太简单。把判分者(眼镜)从 proxy 换成真实 LLM,只要尺子(题目)固定就会饱和。这就是「诚实的不及格」的本质。
🍵 休息点:很多人此时会想「连真实 LLM 都饱和,岂不是无解了?」我也这么想过。但正题从这里开始。如果**「把尺子固定下来才是错的」,那要修的既不是淘汰器也不是 LLM,而是造尺子的方式本身**。我用一个通宵、6 个 PoC、4 个 Agent 和 Perplexity 验证了这一点。
3. 一夜的作战 —— 为「决定方策」而进行的分布式调查
用户给来的指示是这样的:
「彻底整理需求,作为进化型系统拿出更多独创性。PoC 也反复多跑。一直到明早,用小单位不停地跑 PoC 来决定方策。」
这里关键在于,目的不是「完成实现」而是「决定方策」。所以不是跑一个大型正式运行,而是采取大量跑小 PoC、用真实数据一个一个地敲掉设计判断的作战([[feedback_poc_feasibility_first]] = 需求 → PoC → 可行性 → 详细设计)。
并行运转的工作者是这些([[feedback_parallel_first_execution]] = 独立任务默认启动并行 Agent)。
| # | 工作者 | 任务 |
|---|---|---|
| A | Claude Agent | 开放端 sweep PoC(实证 baseline = 饱和/全灭 vs 开放端 = 回避,≥1 万代) |
| B | Claude Agent | 观测基础(响应日志 / 个体分数时序查看器 / lineage 复原) |
| C | Claude Agent | 管弦乐团 PoC(MoA 是否超越单一 best,多样性选拔 vs 冗余选拔) |
| P | Perplexity | QD/novelty/MoA/agentic 进化的 SOTA 综述(补足文献缺口) |
| X | Codex | 设计的独立批评 + 3 个最小 PoC 提案 + 盲点指出 |
| 自身 | 我(main) | 直接实现并执行自跑 PoC #1〜#6(orchestrator 兼最重要任务负责) |
🍵 休息点:这个「六人合力」体制,其实是本文隐藏的主角。为什么不用一个人(一个 context)全部做完?答案就在 honest disclosure 的核心。**用同一个脑袋想出的结论,会被同一种偏见牵着走。**用不同的方法(合成 PoC / 真实 LLM / 文献调查)各自独立地验证,只有当它们一致时才信任结论。这就是我所称的 honest cross-validation。它的威力在后半段显现。
这里记下一个诚实的哑弹。Codex(X)用不了。ChatGPT 账号的许可模型不匹配(API 侧全面拒绝 codex 系模型)导致受阻。本应在 10x promo 期间,API 却返回 "not supported when using Codex with a ChatGPT account"。由于这是环境问题,目前把主轴切换为自跑 PoC + 并行 Agent + Perplexity。「本应能用却用不了的工具」也照记不误,不隐藏。
4. 第一记决定性打击 —— 是否舍弃「固定尺子」(自跑 PoC #1 / #2)
最先该敲掉的假设,是最根本的问题:「把尺子从固定难度改为自适应难度,饱和会被修好吗?」
4.1 自跑 PoC #1 —— 自适应难度修好饱和,但杀死多样性
用合成的 competence 向量的 proxy,去除混杂后(按 score 选 elite)做对比。
- baseline(固定难度):能力在 0.627 低位停滞(best 0.757)。在 proxy 中重现 12h 的病理。
- adaptive(难度 = 跟随群体 60 分位):能力上升到 0.952(best 1.0)。
让难度跟随群体(能解的题增多就把题变难),饱和被解开、能力上升。但是——adaptive 牺牲了多样性(diversity 崩塌 0.310 → 0.134)。在为难题优化的过程中,群体凝聚到了一个正确策略上。
4.2 自跑 PoC #2 —— 自适应难度 × novelty 可以兼容
那么,在「自适应难度(维持梯度)」上加「novelty 选拔(维持多样性)」会怎样?
| 配置 | 最终能力 | best | 多样性 | plateau |
|---|---|---|---|---|
| baseline(固定难度) | 0.627 | 0.757 | 0.310 | gen82 |
| adaptive(难度跟随) | 0.952 | 1.000 | 0.134(崩塌) | gen63 |
| adaptive + novelty | 0.881 | 1.000 | 0.316(维持) | gen99(最长探索) |
adaptive + novelty 同时兼顾了能力(比 baseline +40%)与多样性(比 adaptive 2.4 倍,与 baseline 相当)。让出 7% 能力,换来多样性的完全维持。
至此,方策的核心由自有数据确定。
「自适应难度=维持梯度」与「QD/novelty=维持多样性」互补,两者都必须。
固定尺子单独(baseline)也好,自适应难度单独(adaptive)也好,都不够。
honest 保留:这是抽象 proxy(competence 向量),并非真实 LLM 映射。仅限于验证 mechanism feasibility(机制是否运转)。plateau@gen 的数字指「停滞的世代」,但本质是停滞的水平——baseline 在低位(0.627)停滞,adaptive 系在天花板附近停滞。
🤔 比喻:当所有人都满分时就把题变难(自适应难度)。于是分数拉开了,但这次大家又收敛到了同一种解法(千篇一律)。于是再加上「对奇特解法也给奖励」(novelty),能力与多样性就兼容了。「变难」与「奖励奇人」的双刀流——这就是 PoC #2 的要点。
5. 主战场的证据 —— 开放端进化的 1 万代 sweep(Agent A)
自跑 PoC 让「方向」浮现。下一步,是大规模、严格地敲打它。我让并行 Agent A 跑了各 1 万代 × pop256 × 19 配置 × 2 巡的开放端 sweep。
判定基准是是否「open-ended(开放端)」——是否不饱和、避免 monoculture(向单一文化的收敛)、archive(多样性的储库)持续增长?
5.1 决定性的判定表
verdict(gen9999 时点):全 scalar 配置 = False / 全 novelty・lexicase 配置 = True
| label | 选择 | std | MC | reservoir | archive | open-ended | occupied | monoculture | uniq_lineages |
|---|---|---|---|---|---|---|---|---|---|
| baseline_scalar | scalar | - | - | 0 | none | False | 9 | 0.74 | 1.0 |
| baseline_scalar_mc | scalar | - | ✓ | 0 | none | False | 9 | 0.90 | 1.0 |
| scalar_qd | scalar | - | - | 0 | map-elites | False | — | — | — |
| novelty_std | novelty | ✓ | - | 0 | none | True | 100 | 0.13 | 1.0 |
| novelty_std_qd | novelty | ✓ | - | 0 | map-elites | True | — | — | — |
| novelty_std_res256 | novelty | ✓ | - | 256 | map-elites | True | 95 | 0.05 | 31.9 |
| novelty_std_res1024 | novelty | ✓ | - | 1024 | map-elites | True | 98 | 0.04 | 15.2 |
| full_oe | novelty | ✓ | ✓ | 1024 | map-elites | True | 90 | 0.05 | 15.3 |
| lexicase_std(_mc) | lexicase | ✓ | -/✓ | 0 | none | True | 111–122 | 0.03 | 1.0 |
由此得出四个决定性发现。
-
选择压力是决定性的。scalar(单一标量 fitness),即使加上 MAP-Elites 的 archive(
scalar_qd)也全灭(False)。也就是说「加个储库就能守住多样性」是错的——**除非选择本身是开放端的(novelty / lexicase),否则开放端根本不成立。**单靠 archive 救不了。让选择压力本身开放端化才是本质。 - **标准化(z-score)把 QD 覆盖扩大一个数量级。**在 novelty 上加 per-dim z-score 标准化,occupied cells 从 9 → 100+。把各轴的「偏离」变成选择压力,行为空间的覆盖就扩大一个数量级。
- **中性储库恢复谱系多样性。**只用 novelty_std 时 uniq_lineages 为 1.0(谱系固定为一个)。加上 reservoir256 就到 31.9。行为多样性与谱系多样性是不同的轴,后者需要储库(这是对 #26 设计篇已实现知见的再确认)。
- **规模有效。**把 latent 维度 256 → 1024,niche 从 101 → 166,archive 从 1021(饱和)→ 2234(持续增长)。多样性可以用「容量」买到。

5.2 Agent A 给出的「诚实的局限」
恰恰是在出好结果(open-ended 成立)时,才要写局限。Agent A 自己指出:
novelty/lexicase 保持描述符整体的多样性,但不保证特定语义维度(factor)的多样性。
在大 latent 下会发生 factor drift,fspread(factor 的展开度)需监视。
也就是说,即使「整体上多样」,也可能在「思考因子这个特定语义维度上收敛」。这催生了新需求 factor-subspace QD(对语义维度逐个保护的 QD)(在后述 PoC #6 中应对)。
🍵 休息点:这是本文最硬的一节。希望带走的一行——**「单靠加 archive(储库)救不了。不让选择压力本身开放端就不行。」**自 #25/#26 设计篇起我们一直说「不聚合」,而其主战场就是「让选择的方式开放端化」,这被 1 万代的真实数据所断言。越过这里,剩下的就是独创性的话题了。
6. 独创性的核心 —— 「让持续进化的群体,不停下来地合奏」
至此「在结构上回避饱和的选择核(S1)」已经稳固。下一步,是用 PoC 与文献为用户在对话中给出的独创性 3 轴做背书。
用户言明的 3 轴是这些。
- 持续进化群体 = 现场管弦乐团(ORCH) —— 持续进化的群体当场做 MoA(Mixture-of-Agents)聚合产出一个答案。进化不停。最大的差异化候选。
- 具备调查功能的个体(AGENT) —— 个体自己去调查。Voyager 系。
- 观测・对话控制(OBS) —— 看个体分别的响应 + 选择分数的时序,能停、能续。
6.1 Perplexity 背书的 white-space
并行运转的 Perplexity 的 SOTA 综述(1143 行)返回了最重要的背书。
「整合 online evolution + online answering 的持续运转系统」没有明确的先行研究 = research white-space(空白地带)。最接近的是 MoA / Self-MoA / sequential aggregation / routing,但没有相同的。
也就是说,「停下进化、用造好的最强个体来回答」是寻常做法。「不停下进化、让进化中的群体本身合奏来回答」——还没有人做过。ORCH §1.11 的差异化得到确认。
6.2 不过 Perplexity 也给了反证警告
作为 honest disclosure,我以同等分量写下 Perplexity 给的反证警告。
在 2025 年的 Self-MoA 研究中,多样性并非自动占优。单一顶级模型的反复,在 AlpacaEval 上超过异种混合 MoA 达 6.6%(quality-diversity 权衡)。
「把群体合奏起来就比单一个体强」并非不言自明。先行研究警告,多样性反而可能起反效果。所以 ORCH 是「用实测来证明,诚实设定 pass-bar」。我用 Agent C 和自跑 PoC #3/#4 验证了这一点。
🍵 休息点:这里是考验研究诚实度的分岔口。正想为「online 进化 + online 回答是 white-space!独创性!」而飘飘然时,Perplexity 泼来冷水「但有反证说多样性不是自动就好」。**让飘飘然的素材和冷水,在同一次调查里同时接受。**做到这一点,结论会强很多。下一节,我来揭开那盆冷水的真面目。
7. 揭开 Self-MoA 反证的「真面目」(自跑 PoC #3 → Agent C 真实 LLM)
「多样性并非自动占优」——不是在 proxy,而是在机制层面揭开这个反证,是这里的高潮。
7.1 自跑 PoC #3 —— 是投票,还是路由?
首先,在 proxy 里无法验证(在饱和的 fitness 下 single best 已是满分 = headroom 为零,拉不开差距)。于是我合成了**「单一个体无法满分的难任务」**(专家分散,single_best=0.5)来测。
| 配置 | best_of(routing) | majority(vote) | domain coverage |
|---|---|---|---|
| single_best | 0.500 | — | 2/4 |
| MoA redundant(top-k) | 0.750 | 0.500 | 3/4 |
| MoA diverse(max-cover) | 1.000 | 0.000 | 4/4 |
这里出现了决定性的发现。
- 多样 MoA 在 best-of / routing 下为 1.000(单一 best 的两倍)。ORCH 成立。
- 然而在 naive majority(多数决)下,多样性起反效果(diverse = 0.000)。在各 sub-task 中,那一位 competent 的专家被无知的多数派 negate(抵消)。冗余 MoA 的 majority(0.500)反而更高。
也就是说,**Self-MoA 反证(多样性 ≠ 自动占优)的真面目,是「聚合器是投票还是路由」。**投票/平均杀死多样性,competence-aware 的 routing/gating 激活多样性。这是「有指挥的管弦乐团」与「人人随心所欲出声的喧嚣」之间的区别。
7.2 Agent C 的真实 LLM 独立地给出了同一结论
然后——并行 Agent C,用真实 LLM(llama3.2,105 次 LLM 调用,15 任务),与自跑 PoC #3 独立地给出了同一结论。
- 单一 best = 0.933。MoA
best_of+ k≥5 达 1.000(+0.067)。majority / weighted 一次都没超过 0.933。 - diverse > redundant(多样选拔以更少的 k 更早地拾取不同 QD cell 的互补 specialist)。
- 改善整整来自 multistep 的 1 题(「把 5 翻倍再减 3」)。CoT 个体群一齐落掉的那 1 题,被多样选拔的异种个体解出。
🔑 独立交叉验证(本文的核心):自跑 PoC #3(合成・专家分散)与 Agent C(真实 LLM・llama3.2),用不同方法达成同一结论——「MoA 只有在 competence-aware routing(best_of)下才超越单一 best / 投票达不到 / 多样性只在 routing 下才有价值」。两种方法一致,在 honest disclosure 意义上是极强的证据。
7.3 最大的漏洞 —— 「真实路由器」能达到 oracle 吗(自跑 PoC #4)
这里 Agent C 指出了最大的漏洞。「best_of 是 oracle routing(神知道哪个个体正确的上限),而实际上『预测哪个个体 competent』的 gate 的精度才是瓶颈。实际投票(majority)达不到 oracle。」
我用自跑 PoC #4(真实路由器 vs oracle,20 seed 平均)来填补。
| κ(校准) | single | majority | conf_router | specialty_router | oracle |
|---|---|---|---|---|---|
| 0.0 | 0.675 | 0.338 | 0.525 | 0.902 | 1.000 |
| 0.3 | 0.675 | 0.338 | 0.883 | 0.910 | 1.000 |
| 0.6 | 0.675 | 0.338 | 1.000 | 0.912 | 1.000 |
| 0.9 | 0.675 | 0.338 | 1.000 | 0.912 | 1.000 |
- descriptor / specialty-router 无需校准就 robust 地达 0.90(稳定超过单一 best 0.675,接近 oracle)。而且 routing 键可以复用为 QD 已经计算的 behavior descriptor——QD 与 ORCH 共享同一描述符基础的协同效应。
- **confidence-router 在校准 κ≥0.6 时达到 oracle。**但小型 LLM 可能校准偏弱 → 以 descriptor-router 为第一选择(不依赖校准)。
- majority = 0.338 确定性地不适用(与 PoC #3、Agent C 第三度一致)。
结论:Agent C 指出的「实际投票达不到 oracle」这一漏洞,用 descriptor-routing(复用 QD 描述符)实用地填上了。ORCH 在 proxy +(部分)真实 LLM 上端到端成立。
🤔 比喻:召集 10 位专家让他们投票,无知的多数派会抵消掉正确的专家。把数学题派给数学家——需要一个分派的人(指挥 = routing)。而且那位指挥的乐谱(behavior descriptor)可以复用为管理多样性时已经算好的东西。投票(majority)杀死专家,指挥(routing)激活专家。这就是 PoC #4 的要点。
8. 给个体赋予「调查之力」(自跑 PoC #5)
独创性 3 轴的第二个,具备调查功能的个体(AGENT)。构想是让个体能在搜索空间里做沙箱只读调查。但「调查不是免费的」——计入成本后,进化会用好调查吗?
自跑 PoC #5(改变成本 λ,观察调查阈值 θ 如何进化,20 seed 平均)。
| λ | θ*(=λc, 最优阈值) | θ_evolved(进化获得的阈值) | evolved | always | never |
|---|---|---|---|---|---|
| 0.0 | 0.00 | 0.049 | 21.46 | 21.47 | 11.70 |
| 0.3 | 0.30 | 0.476 | 21.34 | 21.26 | 21.20 |
| 0.6 | 0.60 | 0.659 | 21.24 | 21.06 | 21.21 |
| 0.9 | 0.90 | 0.888 | 21.21 | 20.85 | 21.21 |
- 进化自力获得了选择阈值 θ → λc(= 根据情形「只在该调查时才调查」的选择性调查涌现)。
- 调查功能的价值显而易见:λ=0(调查免费)时,never(完全不调查)= 11.70 = 45% 的损失。
- **成本 λ 让「always 调查」劣化,强制选择。**AGENT-3(成本原理)成立。
honest 保留:中间 λ 处的 margin 很小(浅报酬地形),这也是抽象 proxy(真实 LLM × 知识库另当别论)。即便如此,「有成本时,选择性调查涌现」这一机制在 proxy 中被确认。
9. 规模「质性地增加多样性」(Round 3)
最后,我用母数(群体规模)也验证了 Agent A 指出的「用容量买多样性」。用 full_oe 配置(novelty + std + MC + reservoir1024 + map-elites),把 pop 从 256 → 4096 扫了一遍。
| pop | gens | occupied niches | monoculture | uniq_lineages | distinct_genomes | bspread_tail |
|---|---|---|---|---|---|---|
| 256 | 5000 | 171 | 0.047 | 14 | 256 | 0.939 |
| 1024 | 3500 | 467 | 0.019 | 74 | 1022 | 1.003 |
| 2048 | 2500 | 754 | 0.009 | 188 | 2041 | 1.071 |
| 4096 | 1200 | 1219 | 0.006 | 372 | 4054 | 1.253 |
随母数规模,open-endedness 单调向上(niches 171 → 1219 / monoculture 0.047 → 0.006 / uniq_lineages 14 → 372 / 行为展开度 bspread 也单调增)。POP-1 假说(母数增加多样性)在 proxy 中得到支持。
honest(明示混杂):这里有一个诚实的陷阱。为了把 pop 提上去,我缩短了 gens(5000 → 1200)。这是对 niche 蓄积不利方向的混杂。即便如此仍是单调增——也就是说 POP 效应是 robust 的下界(本来应该更有效)。反过来说,「可能更有效」在这个实验里没能证明。这个论断仅限于 proxy mechanism feasibility。

🍵 休息点:「一扩大规模多样性就增加」很直觉,但这里重要的是**「即便加入不利的混杂,仍然单调增」**这份诚实。削减 gens 通常对多样性不利。即便如此仍增加了。所以才能称为「下界」。把好结果写成「下界」而不夸张成「上界」——这也是 honest disclosure 的做派。
10. 早晨,所有人都到达了同一个结论 —— 已确定的方策
一夜之间,**6 个自跑 PoC + Agent A/B/C + Perplexity 各自独立地收敛到同一个结论。**这就是 honest cross-validation 的威力。我们舍弃了固定尺子路线,把以下确定采用为 lldarwin v2 的核心。
S1. 选择核(在结构上回避饱和)
- 废除固定标量 quiz fitness(baseline 在 1 万代饱和 + monoculture 0.9 + 多样性崩塌 = 大规模再现 12h 病理,open-ended 0/6)。
- 选择 = novelty / ε-lexicase(必须 z-score 标准化)+ minimal-criterion。 仅靠 MAP-Elites archive 不行(scalar_qd 也全灭)= 让选择压力本身开放端化。
- 也需要品质,所以用 QD(每 cell 品质 × 多样性):纯 novelty 牺牲标量品质(0.77-0.83)→ 与自适应难度(条件课程)搭配以供给品质梯度(PoC #2)。
- 谱系多样性用中性储库另行确保(行为多样性 ≠ 谱系多样性,res256 使 uniq_lineages 1 → 32)。
- 追加 factor-subspace QD(逐个保护语义维度的多样性,应对 Agent A 的 factor-drift 局限,PoC #6)。
S2. 产出方式 = 持续进化 × 现场管弦乐团(独创性的核心)
- 成果物不是单一 best,而是让 QD archive 持续进化,在任意时点做 MoA 管弦乐团合奏产出一个答案(ORCH;整合 online 进化 + online 回答是 white-space = 独创性,Perplexity 确认)。
- 聚合必须是 competence-aware routing/gating(指挥),而非投票(自跑 PoC #3/#4 + 真实 LLM Agent C 三重一致)。
- routing 键复用 QD 的 behavior descriptor(descriptor-router 不依赖校准、接近 oracle 的 0.90)= QD 与 ORCH 共享同一描述符基础(设计的节约)。
S3. 个体 = 具备调查功能的 agentic 个体(分阶段引入,已 proxy 验证)
- 在搜索空间里仅做沙箱只读调查(实际 I/O 在经 Approval Bus 单向昇格后)。调查计入成本。
- 已 proxy 验证(PoC #5):成本 λ 让「选择性调查」涌现。AGENT-3(成本原理)成立。真实 LLM × 知识库是下一阶段。
S4. 观测・对话控制(已实现 = 全运行标配,Agent B 完成)
- 响应日志 / 个体分数时序查看器 / lineage 复原(进化系 886 测试绿)。step/pause/resume 计划在下一阶段接线。
- Agent B 的 lineage 复原,解决了在 12h 数据中「全是 ?」的谱系显示,把 champion 谱系 gen70 → gen59 解出 12 hops。缺失不捏造,明示为
lost@genN(根因 = 父 ID 单靠 snapshot 或 winners 任一都无法追溯)。观测基础正是 honest disclosure 的根基。
自跑 PoC #6 —— 用 factor-subspace QD 应对 Agent A 的局限
| mode | factor_spread | retention | latent_spread |
|---|---|---|---|
| full_only | 1.017 → 0.500 | 49.5% | 0.545 |
| full_plus_factor | 1.092 → 0.737 | 68.1% | 0.588 |
对语义维度(factor)另行施加 novelty,把语义维度多样性的损失几乎减半(50% 损 → 32% 损)。在 proxy 中实证了应对 Agent A 的 factor-drift 局限的有效手段。honest:并非完全固定而是残存 68% = 残余 drift 需并用中性储库或加强 factor 权重。
11. 教训(作为 honest disclosure 留存)
-
连真实 LLM 都饱和了。即便把眼镜从 proxy 换成真实 LLM,只要尺子固定,gen5 就是满分。
「用真实 LLM 就会进化」是谎言。问题在于造尺子的方式。 -
单靠加 archive 救不了。「持有多样性储库就能守住多样性」是错的。
scalar 选择即使加上 QD archive 也全灭。能救它的是选择压力的开放端化本身。 - **多样性并非自动就好。**Self-MoA 反证的真面目是「投票还是 routing」。
有了指挥(competence-aware routing)多样性才成为价值。投票杀死专家。 - **独立交叉验证使结论更强。**自跑 PoC(合成)、Agent C(真实 LLM)与 Perplexity(文献)
分别收敛到同一结论,正因如此才可信任。同一个脑袋的结论共享同一种偏见。 - **proxy 仅是 mechanism feasibility。**本文的 PoC 群验证的是「机制是否运转」,而非「真实 LLM 一般能力提升」的主张。一旦越过这条界线,研究就成了谎言。
- **用不了的工具(Codex)也记下。**不只成功,哑弹也要诚实记录。
简言之——「一旦眼镜(评价)饱和,无论怎么打磨淘汰器都无力。」所以把打磨的对象,从淘汰器、从 LLM,转移到评价本身的开放端化。这就是一个通宵的结论。
🍵 休息点:在 #25 我决定「曝光失败」。在 #26 设计篇我造了「不聚合的淘汰器」。而这一次,真实 LLM 教会我「那还不够,因为尺子是固定的」。**失败孕育下一个设计,那个设计的局限又孕育下一个。**这就是连载的脊梁。花哨的「靠进化 AI 变聪明了!」我一次都还没写过。因为还没凑齐能写它的根据。凑齐时,才会动笔。
12. 结论
- 真实 LLM 12h 运行是「诚实的不及格」——不全灭但不累积的 filtered random search。真因是固定尺子的饱和(用真实 LLM 实证了 #25 的洞见)。
- 一夜的分布式调查(6 个自跑 PoC + Agent A/B/C + Perplexity)独立地收敛到同一结论 = honest cross-validation。
- 已确定方策:S1 开放端的选择核(novelty/lexicase + std + MC + QD + 自适应难度 + 中性储库 + factor-subspace QD)/ S2 持续进化 × routing-MoA(white-space 独创性,是指挥而非投票)/ S3 agentic 个体 + 成本(选择性调查的涌现)/ S4 观测(已实现)。
- 所有要素均已在 proxy /(部分)真实 LLM 上背书。残余课题是「向真实 LLM 阶段接线」「factor-subspace QD 实现」「scale-up」。核心策略已确定。
造出好部件,不聚合地捆绑,用真实 LLM 确认饱和,再向开放端的选择重建。当 6 路独立验证到达同一结论时,才终于能说「方策定了」。本文正是 #25 中预告的「眼镜蒙了,淘汰也无力」那一回——诚实曝光真实 LLM 让眼镜蒙住的那一刻(饱和),承担起 Goodhart's law 与 proxy 的局限,然后向开放端重建。下一步,是把这套已确定的方策落到代码的实现阶段。
13. 相关
- 连载 #24-05「群体学习的 AI」—— 派生群体进化的框架(本文的前提)
- 连载 #24-08「造眼镜」—— lleval(测量的一侧)
- 连载 #25「只剩下弗里斯顿和我」—— monoculture 的 honest disclosure(本文的动机)
- 连载 #26(设计篇)「只靠眼镜测量并不会进化」—— 淘汰器 lldarwin 的设计与 Stage1/1.5/2 实测(本文的姊妹篇)
- 先驱论文(2026-05-27, date of record)「Continuously-Evolving Populations as Live Orchestrated Ensembles」—— 把本文方策以学术形式形式化的防御性公开(FullSense 公开仓库
docs/papers/) - 相关 memory:[[feedback_benchmark_honest_disclosure]] / [[feedback_llive_measurement_purity]] / [[feedback_poc_feasibility_first]] / [[feedback_parallel_first_execution]] / [[feedback_originality_over_imitation]]
第4章 让"指挥者"指挥不断进化的 AI 群体合奏来作答 — llive 的乐团式进化, 以及治好饱和的 3 个装置 #28
📖 一句话概括
这是把上一章定下的方策终于落地实现的报告。llive 追求的不是"对一个聪明的个体反复发问",而是"让一大群略有不同的个体持续进化,在需要答案的那一刻,由指挥者挑选合适的成员合奏(现场乐团)"。为此我们装上了 3 个用来治好"满分饱和之病"的装置——学生进步了就把及格线也抬高的"自适应难度",让第二小提琴不至于消失、守护个性的"factor-subspace QD",以及把成果不归于一个冠军、而是积存进多样性地图的"MAP-Elites"。结果,最佳分数没有钉死在满分上,而是一路涨到了最后。不过我们也诚实地划清界线:这只是在合成尺子(proxy)上的结果,并不等于测出了真正 LLM 的聪明程度。
📚 连载导航(lldarwin 弧线): #24-05 群体进化 → #25 monoculture 的失败 → #26 设计篇 → #27 通宵的决断(climax)→ #28 本文(实现篇)。※ 各篇文章也可单独阅读。
概念 hook:
不是对 1 个聪明的 AI 反复发问, 而是 让一大群略有不同的 AI 持续"进化", 在需要答案的那一刻, 由指挥者挑选合适的成员合奏(乐团)汇成 1 个答案。
——这就是 llive 现在所追求的形态。llive不是"LLM 本身", 而是"套在 LLM 周围的认知 OS"。在其中, 让 群体不绝、不偏、持续成长 的, 就是这次打磨出的进化引擎lldarwin。在前作 #27 中, 我们通过真实 LLM 的 12 小时运行确认了这样一个病症:"评价(尺子)一旦贴死在满分上, 进化就会停止, 退化为仅仅带筛子的随机搜索"。于是定下方策:"无论怎么打磨淘汰器都是徒劳。要让评价本身成为开放端"。
这次我们 实现 了该方策。而在 proxy(合成尺子)之上, best 分数没有贴死在满分上, 一直上升到最后。
0. 三行剧情梗概(落语的"开场白")
- 卖点确定了 — llive 的北极星是"连续进化 × 现场乐团"。在不停止持续进化的群体的同时, 在任意时刻用 competence-aware routing(指挥者)合奏汇成 1 答。这是先行研究中的 white-space(空白地带)。
- 实现了治好饱和的 3 个装置 — ①对语义维度逐个保护的 factor-subspace QD ②把成果不存为"单一 best"而存入多样性 archive 的 MAP-Elites ③让尺子跟随群体的适应难度。由此搭好了"奏者(多样的个体)不绝"的基盘。
- 在 proxy 上验证了规避饱和 — 把 lldarwin-v2 跑 10 代后, best 从 0.80 → 0.92 不贴死地上升。多样性 archive 填满了 21 个 cell。不过这是 proxy, 并未测量真实 LLM 的能力(honest)。
总之就是 不是"聪明的 1 体"而是"多样的一大群 × 指挥者"。为此的"让奏者不绝的装置"就是这次的实现。
1. llive 是什么(致初次接触的读者)
llive(读作 liv。L 有 2 个)是 自我进化型、模块化记忆的 LLM 框架。它是名为 FullSense 的伞形品牌的一员, 兄弟有 llmesh(本地 LLM hub)和 llove(终端 dashboard)。这 3 者是独立 OSS, 但组合起来就成为 1 个世界观。
用 1 行概括 llive 的思想就是"不是 LLM 本体, 而是套在 LLM '周围' 的认知 OS"。把 4 层记忆、6 阶段的 loop、承认 bus(Approval Bus)、TRIZ、10 个思考因子……这些"思考的脚手架"搭在 LLM 的外侧, 使得 即便是同一个 LLM 也能进化其行为。
承担这个"进化"的, 就是这次的主角 lldarwin(达尔文)。角色分工如下。
- lleval(眼镜) = 测量 个体(评价)
- lldarwin(淘汰器) = 把测出的差异 转换 为"谁存活、谁留下后代"(选择压)
而骑在两者之上的北极星, 就是接下来的"乐团"。
2. 卖点 = 连续进化 × 现场乐团(独特性的核心)
普通的 Mixture-of-Agents(MoA)是向 固定的 多个模型抛出同一个问题, 再聚合答案。llive 瞄准的是那再往前的一步。
不停止地让群体持续进化(online evolution), 在需要答案的那一刻(online answering), 由指挥者挑选"针对这个问题用这些奏者"合奏汇成 1 答。
这种"online 进化 + online 回答的整合", 据我们调查是 没有明确先行研究的 white-space(在 #27 中让 Perplexity 翻阅文献确认过)。与之相近的有 MoA / Self-MoA / sequential aggregation / routing, 但"让持续进化的群体本身现场合奏"的形式则遍寻不见。
在这里发挥作用的是在 #27 得到的 2 个诚实发现。
-
聚合不能是"投票", 而必须是"指挥者(competence-aware routing / gating)"。 自我 PoC 和真实 LLM 验证三重一致: 在有 headroom(提升空间)的任务上
best_of/routing胜过single(单模型迭代), 但majority(多数决)反而适得其反。这也是我们对 2025 年 "Self-MoA"(多样性并非自动占优)的回答。 - 指挥者的判断键可以挪用多样性 archive 的 "behavior descriptor"。 也就是说后述的 QD(Quality-Diversity)和指挥者可以 共享同一套记述子的根基。
——不过, 乐团本体(指挥者=router 的实现)还在后头。这次实现的是其前一步:"搭建足以合奏的、多样且不绝的奏者群体"的基盘。
3. 为什么"奏者会断绝" — 名为饱和的病(#25〜#27 的复习)
乐团需要的是"个性各异的奏者一大群, 持续不绝地存在"。然而若朴素地进化, 这会崩溃。
- #25: 跑 500 代后, 世界上只剩下"我和弗里斯顿"(monoculture)。
- #27: 用真实 LLM(llama3.2) 跑 12 小时后, gen5 时 best 贴死在 1.0, 65 代毫无进展。不会全灭但也不会累积 =带筛子的随机搜索。
真因两者相同。人为固定的尺子(评价函数)一旦贴死在满分上, 全体就同分, 选择压消失, 之后就靠遗传漂变随意偏移。眼镜(lleval)一旦饱和, 无论怎么打磨淘汰器(lldarwin)都无力——这就是 #27 的结论。
所以要改变打磨的对象。转向"让尺子动起来""结构性地守护多样性"。具体就是接下来的 3 个。
4. 实现的 3 个装置(lldarwin v2 / Phase 1)
设计的口号是"不发明新算法"。Phase 1 就是把 llive 内已经积累的部件(ε-lexicase / NoveltyScorer / MAP-Elites / 中立贮藏库)合成、配线 成已确定方策 S1 的形态。用
--selection lldarwin-v2即可一并开启。
③ 适应难度 — 让尺子跟随群体
AdaptivePercentileGate。把各评价轴的"最低线(minimal-criterion)"每一代 重置为群体分数分布的指定百分位(例: 后 40% 点)。群体提升, 最低线也自动上抬。设为 ratchet(单调非减)的话, 即便一时下探基准也不会松动。
由此就给"固定尺子在满分处饱和"的病盖上了盖(PoC 中固定难度停滞在能力 0.627 → 适应难度上升到 0.952)。即便在全体都跌破最低线的乱世代, 淘汰器也会无视 gate 以避免全灭(fail-open 防护)。
用落语来说, 就是 学生进步了就把及格分也上调的老师。不会让其拿了满分就到此为止。
① factor-subspace QD — 逐个守护语义维度的个性
FactorSubspaceNovelty。novelty 探索能保持"群体整体的多样性", 但在巨大的潜在维度之下,"有意义的维度(思考因子)的多样性"会不知不觉地萎缩(factor drift)。
于是, 仅在 思考因子的 子空间 上另行测量 novelty, 并与整体 novelty 混合。在 PoC 中, 这使语义维度多样性的目减几乎减半(retention 49.5% → 68.1%)。
诚实的改良点: 原本的 PoC 是"把生距离各加 0.5", 但由于各子空间的距离尺度不同, 在实现中改为 先把各自 z-score(标准化)再混合。这是为了公平地混合"整体的合唱"和"各声部的个性"。
用奏者来说, 这是让 第二小提琴不会被第一小提琴吞没消失 的装置。
② MAP-Elites — 把成果存为"多样性的地图"而非"1 个冠军"
run_persona_evolution(map_elites=True)。每一代把全部个体投入 MAP-Elites archive。这不是"最高分的 1 体", 而是 按行为的坐标、在那个格子里保留最优个体 的地图(QD archive)。填了新格子也不会消除既有格子 = 多样性不会结构性崩溃、archive 单调地成长。
这直接就成为乐团的 奏者目录。指挥者将来会从这张地图中挑选"契合这个问题的坐标的奏者"合奏——QD 和 routing 共享同一记述子的、那个 #27 的设计在这里发挥作用。
实现上 不扩展个体的格式, 而是从既有 genome 的思考因子导出坐标(descriptor)的 additive 配线(为的是不破坏基盘的后向兼容 900+ 测试)。记述子的正式设计(高维的缩约等)作为将来 Phase 的课题留有余地。
5. 结果 — 在 proxy 上确认"不饱和的进化"
这是把 lldarwin-v2(上述 3 个+ novelty +中立贮藏库全部开启)用 proxy 尺子跑 16 个体 × 10 代的实测。
[gen 000] best=0.8036 ...
[gen 004] best=0.8544 ...
[gen 007] best=0.9089 ...
[gen 010] best=0.9182 ...
→ archive cells = 21(多样性的地图填满了 21 个格子)
- best 没有贴死在满分上, 0.80 → 0.92 一路上升到最后。 在 proxy 阶段摆脱了 #27 中看到的"gen5 时 1.0 饱和→固定"的病理。这是适应难度让"尺子"跟随群体的征兆。
- 多样性 archive 填满了 21 个 cell =应当合奏的"个性各异的奏者"的目录开始成形。
- 进化系的自动测试 879 件+新增测试全部 green, 无回归。
6. honest disclosure(请不要跳过这里)
结果越好越要怀疑其内幕, 这是 FullSense 的做派。
- 这是 proxy。 个体不是真实 LLM, 而是 llive 的 genome(思考因子的代理)。这次测量的是"能否同时对多个独立的弱轴施加选择压、并按轴维持专家"这一 机制的可行性(mechanism feasibility), 而 不是 production 的 LLM 能力。真实 LLM 评价是下一个 Phase。
- factor-subspace 并非完全保护(retention 68%, 其余漂移)。需要并用中立贮藏库以及强化 factor 权重。
- 幕后的诚实: 这次实现过程中, 自动 commit 钩子在每次编辑时堆积了多达 49 个"编辑前"快照, 历史变得杂乱。最后 squash 成 1 个有意义的 commit 加以整理(公开 OSS 一侧)。反过来, 也确认了含有内部战略的 fork 如预期那样仍保持在本地、未被暴露。
7. 接下来要做什么
进化引擎(让奏者不绝的基盘)在 Phase 1 中成形了。接下来是乐团本体, 以及从 proxy 到实物的过渡。
- Phase 2 = 真实 LLM 配线。 以本地(localhost ollama)的真实 LLM 为对象, 用真实评价验证适应难度、factor-subspace QD、MAP-Elites。在 proxy 上看到的"规避饱和"是否在真实能力上也会发生。
-
指挥者(router)的实现。 用挪用 QD archive 的 descriptor 的 competence-aware routing, 实际运行"让进化中的群体现场合奏汇成 1 答"。能逼近
best_of的 oracle 到何种程度。 - 提升规模。 群体 256 → 4096, 潜在维度的扩容。验证容量假说(越大 niche 越多)。
- 交互式连续运行。 能以 step / pause / resume 窥探长时间运行的驾驶席(CKPT-1)。
8. 在此稍歇(休息点)
到此为止,"llive 以什么为卖点"传达到了吗。
- 不是聪明的 1 体, 而是 不断进化的多样群体 × 指挥者的合奏。
- 为此, 做出了一个 让奏者不绝、守护个性、持续成长 的进化引擎。
- 在 proxy 上治好了饱和。接下来是真实 LLM 和乐团本体。
在后续的"真实 LLM 篇"和"乐团篇"中, 我们会让大家看到 proxy 的承诺是否成真。——感谢您一路相伴至此。
Series Navigation
- 连载导航(lldarwin 弧线): #24-05 群体进化 → #25 monoculture 的失败 → #26 设计篇 → #27 通宵的决断 → #28 本文(实现篇)
- repo: furuse-kazufumi/llive
第5章 "镜片饱和时,选择压力无能为力" — 用反证锤炼进化设计 #29(Goodhart 定律与 proxy fitness 的极限)
📖 一句话概括
一般的连载到这里大概会写"修好了,可喜可贺,完!",本章却偏要给自己的设计泼一盆冷水,是一个"反证回"。主题是 Goodhart 定律——"一旦指标变成了目标,它就不再是好指标"。把 LLM 的弱点换算成分数,进化就一定会找到"只刷分的、表面化的捷径",而不是真正的能力。此外,本章隐藏的主角是作者自己的坦白:我曾一瞬间把"行为多样"、"血统多样"、"真正的智能多样"这三件貌合神离的事情混为一谈,看到漂亮的数字(0.05)就差点误以为连别的能力也一起变好了——本章把这个"现行犯"摆上解剖台。这是整个连载里最朴素、也最诚实的一回,没有写下任何一句华丽的胜利宣言。
📗 赶时间? 本文有通俗易懂版。

概念 hook: 在 #25 我暴露了失败,在 #26 我设计了淘汰器"lldarwin"。普通的连载接下来会说:
"修好了! 可喜可贺,完!" 但不这么做,正是 FullSense 的 honest disclosure。
本文刻意做成向自己的设计抛出反证的一回。主题是一句在进化计算和机器学习两边都奏效的话——
Goodhart 定律(当一个指标成为目标时,它就不再是好指标)。"只要把 LLM 的弱点当作 fitness,进化就会自动克服它"——我亲自去给这种天真的乐观泼冷水。
而且这一次,我把自己曾经犯下的"事实误认"作为活标本放上解剖台。
0. 三行概要
- 镜片(fitness)一旦饱和,无论加上多么高级的选择压力(lldarwin),淘汰都无能为力(#25 的真正教训)。
- 用 proxy fitness 测量 LLM 弱点时,进化出来的不是真能力,而是"hack 指标的表面策略"(Goodhart 定律)。
- 结论: 我把 lldarwin 的价值主张限定为 (a) proxy 只是 mechanism feasibility (b) 实 LLM/VLM 评价才是本质 (c) 多样性的地图化。这就是诚实的界线。
而本文还有一行隐藏的主角。
-
我自己曾经把"行为多样性""谱系多样性""实 LLM 智能多样性"混为一谈。我把这个自我反证
放在反证回的核心。这是对"它成功了"该如何怀疑的现场演示。
1. 重申 honest disclosure — 结果越好越要怀疑
在 #26 我写道"在 PoC 部署中,行为 monoculture 在全部条件下改善到了 0.05(≪0.8)"。
这是事实。并非夸张。
…但若在此挺起胸膛"搞定了,monoculture 消灭!"就此收尾,就违背了我在 #25 立下的誓言。
出现异常漂亮的结果时,在自以为获胜之前先怀疑其内訳([[feedback_benchmark_honest_disclosure]])。
连载 #25 的通奏低音是这样的——"异常漂亮的结果不是胜利,而是警报"。
对于"跌破 0.8 即达成 OE-3"的基准,0.05 实在太漂亮了。0.05 这个数字,
不该当作庆祝的号角,而必须当作警笛来听。
那么就让警笛响起来吧。该问的问题只有一个。
这是测量了什么的 0.05?
先说答案,0.05 是"proxy 评价中的行为 monoculture"。
这是"genome 的行为代理(behavioral surrogate)"的集中度,
并非实 LLM 智能的多样性。在这里混淆,就会重蹈与 #25 完全一样的覆辙。
而我诚实地坦白。**我曾经在这里混淆过。**稍后在 §3,我会拿出那个"现行犯"的证据。
🍵 休息点(90 秒): 本文说到底就是"给自己挑毛病的文章"。
我希望这一回能让读者诸君观察"在成功报告的背后,作者在怀疑什么、怀疑到什么程度"。
它走的是 SNS 上爆红的"进化了一个 AI,最强○○诞生了!!"的恰好相反的路。不会热闹。
但正是这种不热闹的诚实,半年后才会奏效——这是我的赌注。请喝杯茶吧。

🗒️ "忽然一副聪明相…?" — 对突然变好的结果起疑(结果越好越要怀疑)(© Forbidden shibukawa / SHUEISHA・《零食吧 Basue》)
2. 反证 1 — 对饱和的镜片,任何选择压力都无效
2.1 再说一次 #25 的真因
#25 的真因是"best_score 从第一代起就饱和在 1.0 → 选择压力为零 → 遗传漂变(genetic drift)"。
若所有人都是满分,选谁都一样。选择就不是"留下优秀者",而变成"掷骰子"。
结果,凭运气增长的谱系仅凭运气固定下来,8 个谱系崩溃为 2 个(furuse-kazufumi + friston)。
在此,我放下成为进化弧线核心的反证。
把 lldarwin(无论 ε-lexicase、QD 还是 novelty)照原样插入饱和的 eval,也修不好。
为什么。因为淘汰器的每个部件,都以"存在差异"为根本前提。
-
ε-lexicase 以"每个轴上存在差异"为前提。若所有轴都是满分,无论分成几个轴,差异都是零。
即便分成 100 个轴,若全是 1.0,也只是排出 100 个"平局"。 -
QD(MAP-Elites) 以"behavior 描述子存在方差"为前提。若所有个体行为相同,cell 就只有 1 个。
即便做出地图,若所有人都站在同一格子上,地图就变成一片空白的一格。 -
novelty 以"与过去 archive 的距离"为前提。若所有人都收敛到同一点,所有人的距离都是零。
想用新颖性来奖赏,也没有谁是新颖的。
也就是说,图式化后是这样。
坏掉的镜片(fitness 饱和) + 高级的淘汰器 = 结果还是坏的
2.1.5 实证 — 在记忆任务中,"地板"与"天花板"杀死了选择压力(Step C, 2026-05-30)
这个反证,后来在 llcore 的 Step C 实验(纯 CPU)中作为实数据被复现。让进化(MAP-Elites)和素朴搜索去解 2 种标准记忆任务,结果如下:

- delayed_parity(XOR)= 地板: 全部 method 都是 R²≈0(基质原理上无法求解)。谁都爬不上去=不出现差异。
- flip_flop(只是记住)= 天花板: 全部 method 都是 R²≈0.95(太简单,全员都到达)。这正是"饱和的镜片",这里选择压力同样无能为力。
作为参考,③(选择)只有在存在"越过假山顶、虽欺骗但可通行的坡道(欺瞒 corridor)"时才奏效:

Step C 的结论干脆是 N/A(在此基质上无法测量③的有无)。而且在 draft 阶段我写过头了"③不必要",多视角的 adversarial 验证抓住"因天花板效应而非诊断、检出力不足(δ=+0.33 是 medium 但 p=0.15 为 inconclusive)"并将其降级——§3.2 的"自我反证",在这里也照样发生了。
2.2 "#25 修好了"只对了一半
这是从 #25→#26 容易被忽略的反证。#25 修好,并非"仅仅"靠 lldarwin 的功劳。
实际上,镜片一侧的修正在先。
- per-dim z-score 标准化(STD-1) — 把每个轴的方差对齐,不让"全轴都还算高的无特征个体"占优。
- 中央一致排除(SEL-1) — 所有人都输出相同值的轴对选择没有贡献,故从 case 中剔除。
- 描述子的低维缩约(DESC-1, JL 投影) — 避开 QD 的维度诅咒,让 cell 不至于空空如也。
-
真因 criteria 的排除 — 把
factor_score(max-archetype 的单一标量 = argmax,违反 SEL-2 = best=1.0 饱和的真因)和
nearest_persona_idx(顺序无意义的类别 index)从 ε-lexicase 的 case 中剔除。
这项"打磨镜片"的工作在先,淘汰器才头一次奏效。
若顺序反过来,无论载上多么高级的 lldarwin,在饱和的镜片面前都是无能为力的。
不修"测量"只把"淘汰"做得高级,是徒劳。
这不仅限于进化计算,而是对机器学习评价设计整体都奏效的教训。
当排行榜的分数饱和时,在把模型做得更高级之前,先怀疑benchmark 是不是坏了。
🤔 比喻(漫才风):
装傻:"把评委从 3 人增加到 100 人,可是给所有人看同一张满分答卷,结果还是一样。"
吐槽:"那不是评委的事,是答卷(测试)坏了啊! 给 100 个人看同一张满分能变出什么来!"
装傻:"那把评委增加到 1000 人……"
吐槽:"增加的方向反了!! 先把题卷给我修好!!"
2.3 职责分离 — 缺了哪个进化都会坏
把镜片(测量)和淘汰器(淘汰)的职责分开,就成了这样。
| 镜片正常 | 镜片饱和 | |
|---|---|---|
| 淘汰器高级(lldarwin) | ◎ 进化转起来(在 #26 达成) | ✗ 无能为力(#25 的陷阱) |
| 淘汰器素朴(Tournament) | △ 能转但多极性弱 | ✗ 崩溃(#25 的出发点) |
值得关注的是右下和右上。只要镜片饱和,淘汰器的高级就救不了右边那一列。
进化的成败,在"淘汰器的聪明"之前,先由"镜片是否映出差异"决定。
这就是反证 1 的结论,也是把 #25 的"真正教训"进一步精密化的说法。
来看看这个"镜片一糊,淘汰也崩"的结论在实测中的样子。下面是 baseline(无 novelty、素朴选择压力)的
适应度与多样性的推移。临近末尾,可以看到多样性在崩溃。
🍵 休息点(90 秒): "先打磨镜片再淘汰"——顺序重要,这是个朴素的故事。
朴素,但跳过这一步就会蒸发半年(我蒸发掉了)。从下一节起是本文的正题,
Goodhart 定律。从这里开始话题会有点黑。换成咖啡也行。
3. 反证 2 — Goodhart 定律: hack proxy fitness 的进化
3.1 最重大的风险
这是设计文档(LLDARWIN_DESIGN.md §7.1)明确写为"最重大风险"的一点。
把 LLM 的弱点当作 proxy fitness 时,进化出来的不是真能力,而是"hack 指标的表面策略"。
进化计算是寻找最大化给定指标的"近路"的天才。
当人类递出一个"自以为用它来测量真能力"的 proxy 时,进化非但不去获取真能力,
反而必然发现只满足 proxy 的表面策略。而且乐此不疲、高效地。
具体会发生什么样的 gaming(指标 hack)?把设计文档里已接受的极限照原样展开。
| pressure(LLM 弱点) | 可能发生的 gaming(指标 hack) | 为何不是真能力 |
|---|---|---|
| typo_robustness | 只是背下特定 typo 模式并替换 | 对未知 typo 无能为力。没有获得噪声耐性 |
| polysemy_wsd | 利用测试分布的启发式 | "返回最频 sense"等统计近路。不是语义理解 |
| multistep_robustness | 只生成有说服力的推理"痕迹" | 排出像模像样的中间步骤,实际并未推理 |
| calibration | 把自信度操纵到中庸以降低 ECE | 全部说"自信度 50%"就能降低校准误差。不是校准能力 |
最后 calibration 的例子最好懂。
当你用 ECE(期望校准误差)来测量"能否恰当估计自信度"时,进化会找到
"对所有问题都回答'自信度正好在正中'"的策略。
ECE 急剧下降。但那个模型一样都没校准。只是变成一个吐中庸的机器人。
当一个指标成为目标时,它就不再是好指标(Goodhart 定律)。
这在 LLM 研究中也有实例。在 GSM8K 型 benchmark 上只有分数上升而不泛化的
benchmark overfitting,正是这个结构。过度相信排行榜数字的人,一次次被绊倒。
3.2 我自己的"现行犯"— 自我反证
在此,我把 §1 预告的"混淆现行犯"放上解剖台。不加遮掩地写。
我起初在 TODO 里这样写道——"验证在重跑中冈洁、格罗滕迪克谱系是否存活"。
然后在 PoC 中看到 monoculture 0.05 这个漂亮的数字,"哦,谱系多样性是不是也改善了?"
一瞬间差点误以为如此。
这就是混淆。正如我在正本(lldarwin_stage1_results §3)所写,poc_evolution_env.py 的作者注释
(我自己写的注释)本身就明确否定了那个混淆。
"monoculture = BEHAVIORAL concentration (max archive-cell occupancy)…
neutral drift (Kimura) regardless of mechanism — that is expected, not collapse.
The OE signal is behavioral spread. lineage_fixation … to keep it <1 needs
QD niching on lineage / PERSONA-FX, not pure novelty"
整理一下,我差点混淆的 3 个"多样性",完全是不同的东西。
-
行为多样性(behavioral diversity) — genome 空间中行为的扩散。用
diversity_l2测量。
novelty 奏效的指标。改善到 0.05 的就是它。 -
谱系多样性(lineage diversity) — 哪些 founder(冈洁、格罗滕等)存活下来。
founder_counts。
用 novelty 在结构上无法改善。novelty 和 lexicase 都只能"保存既有个体",
没有让一度灭绝的谱系复活的机构。所以在中立漂变(Kimura)下走向 monoculture
在理论上是正常的。不是崩溃,而是预期之内。 -
实 LLM 智能多样性(real intelligence diversity) — 实模型是否真的拥有多样的聪明。
用 proxy 完全测不出来。是 Stage2 的实 LLM 评价所承担的领域。
也就是说,"改善到 0.05"的真身是 (1) 仅行为多样性。(2) 和 (3) 都与那个数字无关。
我一瞬间差点想"谱系也改善了?",是因为看到 (1) 就草率断定 (2)/(3) 也变好了。
这正是 Goodhart 定律的设计者一侧版本。
看到一个指标(行为多样性 0.05),就人为擅自地解释它没有测量的另一种能力(谱系存活、实智能)也变好了。
不仅 proxy 与真能力背离,读 proxy 的人类的解释也一并背离。
在反证回里暴露这个,很痛。但若不暴露,就不是 honest disclosure。
3.3 用对比来看"测量了什么的 0.05"
只用言语难以传达,所以用 2 张 SVG 来对比"测量了什么"。
首先,行为多样性确实改善了(这是事实、无夸张)。下面是中立贮藏库 OFF 的谱系支配 stream。
最终崩溃为 furuse 71% / friston 29% 的 2 个谱系。即便行为多样,谱系也是这般。
而下面是加入谱系一侧的对策(中立贮藏库 ON)之后。全部 8 个谱系并存
(millidge / von-neumann / oka-kiyoshi / grothendieck … 存活)。
这 2 张图的对比,是本文的心脏。
同样是"0.05 的行为多样性",左边(OFF)谱系崩溃,右边(ON)谱系并存。
也就是说,0.05 这个行为多样性的数字,对谱系怎样了只字未提。
加上另一个机构(lineage-niched QD / 中立贮藏库)之后,谱系才头一次得救。
"测量了什么的 0.05"——答案是"只有行为"。谱系不用另一副镜片就看不见。这就是诚实的答案。
3.4 有对策,但问题不会消失
设计里织入了 Goodhart 对策。
- proxy 限定于 mechanism feasibility 验证,不主张 production 能力。
- 以实 LLM/VLM 评价(Stage 2)为本质。
- 用 neutral shadow 对照(Bedau) 怀疑表面的改善(与只有中立变异的 shadow 集团相比,
确认选择是否真的奏效)。 - 用 down-sampling 每代扰动 case + 用 OOD 轴抵消过拟合。
🍵 休息点(90 秒): "既然有对策,不就没问题了?"——不,这才是关键。
对策只是推迟背离,而proxy 不是真能力这一事实并不会消失。
这就像感冒药能压住症状,却消不掉病毒本身。所以"通过 proxy 让 LLM 变聪明了"这种话,我打死也不说。
因为一旦说出口,半年后我就看见自己出尽洋相了。来一杯茶。
4. 反证 3 — 设计者依赖性:"多样性的方向"是谁决定的?
4.1 一个元层面的怀疑
ε-lexicase 的 case、QD 的 behavior 描述子、novelty 的距离尺度、minimal-criterion 的基准值——
这些全都是由设计者(我)决定了"多样性的方向"。
也就是说,lldarwin 产生的多样性是"在设计者设想的轴之内的多样性",
而不是生物进化级别的未设想涌现(unanticipated emergence)。
正如 Taylor et al. (2016) 作为 open-endedness 的极限所指出的,
"在人类定义的尺度之内多样"与"跃出定义之外",是完全不同的两回事。
例如,在我用 diversity_l2(genome 空间的 L2 距离)定义"行为多样性"的那一刻,
进化就会朝"L2 距离变大的方向"多样化。但那是在我画出的坐标轴之上的多样性,而
在我想都没想过的轴(比如"幽默感"或"沉默的用法")上的多样性,
本来就不在测量对象之内,所以即便诞生了我也察觉不到。
🤔 比喻(金鱼池):
捞金鱼摊的老板决定"挑选让红金鱼和黑金鱼都留下"来捞。
确实红的黑的都留在池里。多样性,达成。…可是,即便那池里突变出一条绿金鱼,
老板的网只看"红还是黑",绿的就没被评价而漏捞了。
设计者所定轴之外的涌现,从一开始就不在视野中。这就是设计者依赖性。
4.2 接受 — 限定能赢的轴
那么怎么办。不主张未设想涌现,这就是诚实的答案。
lldarwin 瞄准的是"无可验证性的多样性的地图"(差异化轴 DIFF-1),
不主张 strong / unbounded open-endedness(与 SCOPE 一致)。
说"我在搞人类未踏的涌现!"很气派,但那会是谎言。
限定能赢的轴——把价值收窄到对认知风格、文化风格这类"无可验证性的多样性"进行地图化。
这就是 lldarwin 能诚实主张的范围。
舍弃气派主张的勇气,也是 honest disclosure 的核心。
5. 反证 4 — minimal-criterion 与 QD 自身的 trade-off
淘汰器的每个部件,也都有各自固有的弱点。把设计文档 §7.1 已接受的极限逐一解说。
5.1 minimal-criterion 的停滞⇄崩溃
minimal-criterion(最低基准 gate)是"不让不满足基准的个体繁殖"的机制,但
基准的高度本身就是 trade-off。
- 基准低 → 几乎全员通过 → 选择压力为零 → 停滞(与 #25 的饱和同一结构)。
- 基准高 → 几乎没人通过 → 全灭(有实证。全员在 gate 落选则做不出下一代)。
温水还是地狱。对策: 把 criterion 不设为固定值,而按集团分位点自适应(例: 落选下位 30%)。
此外加入若全员 fail 就忽略 gate 的安全阀(MultiPressureSelector 已实现)。
5.2 QD 的维度诅咒 + archive 饱和
QD(MAP-Elites)用 behavior 描述子切分 cell,但描述子若高维,大半 cell 会变空
(维度诅咒)。而且长期运转后全部 cell 被填满,新颖性触顶(archive 饱和)。
这是在人工生命的经典 Avida / Tierra 中也观测到的现象。
对策: 把描述子缩约到低维(DESC-1, JL 投影) + 用 Bedau 统计监视饱和,
把"饱和=失败"如实记录(不要把饱和便宜行事地解释为"已经探索殆尽的证据")。
5.3 lexicase 的规模极限
ε-lexicase 在 case 数增加时计算成本增大,而且因噪声实质上变成随机选择。
case 太多时,胜者由碰巧排在顺序最前的 case 决定,选择就接近掷骰子。
对策: 用 down-sampled lexicase(每代只用 case 的子集)削减成本 + 扰动环境。
5.4 trade-off 在实测中"看得见"
这些 trade-off 并非纸上空谈,而是在实测中显现。
改变中立贮藏库的"再投入频率(reinject_interval)"的 sweep 就是个好例子。
| interval | named 谱系存活 | lineage_fixation (tail30) | diversity_l2 (tail30) |
|---|---|---|---|
| 1(每代) | 8/8 | 0.32 | 9.91 |
| 5 | 5/8 | 0.37 | 12.84(最大) |
| 10 | 3/8 | 0.41 | 11.41 |
| 20 | 2/8 | 0.44 | 10.75 |
非平凡的发现: 行为多样性(diversity_l2)并不随 interval 升高而单调增加,而是在 interval=5 处达到峰值。
10/20 反而下降。原因是——把谱系放任太久(升高 interval),
来自贮藏库的多样性注入减少,且少数谱系固定下来,diversity 也不再增长。
恰到好处的"放任程度"在正中——这是个非线性的世界。
运用指针就成了这样——若把谱系保持放在第一位,interval=1(8/8 全谱系存活),
若想兼顾谱系保持与行为多样性,interval=5(保持 5/8 的同时 diversity 最大)。
最优点依赖于 fitness / 集团规模,所以在生产环境需要重新校准。
不是"某一个正确答案",而是"随目的而移动的最优点"——这就是诚实的结论。
5.5 诚实的保留 — "存活"也许是"生命维持"
在此,还有一个该诚实写下的保留。
中立贮藏库让全部 8 个谱系存活下来是事实,但需要怀疑那个"存活"的质量。
正如正本(§4.1 / §4.2)所写,贮藏库是"再投入各谱系的 best-ever genome(frozen elite)"的机制。
强谱系实际在增加子孙、进行繁殖。另一方面,弱谱系(各 1 个体)的"存活",是
源自再投入,而非主动的进化。可以说,不是繁殖,而是生命维持装置。
这是完全符合中立贮藏库定义的正当行为(保持代表,使再结合成为可能)。
但我不主张"全部 8 个谱系活跃地持续进化"。
"防止了全灭。但弱谱系正在 ICU 续命"——这才是准确的表述。
🤔 比喻(落语风):
房东:"长屋的住户一个不缺,8 人全齐了,可喜可贺,可喜可贺。"
八公:"是啊。只是一半人光喘气、租也不交、躺着不起……"
房东:"那与其说是'住着',不如说是'放着'吧!"
八公:"嘛,总比赶出去强吧……"
——全员都在,是事实。全员都在活跃,是谎言。这条界线就是 honest disclosure。
6. Stage2 — 从 proxy 通往"实"的桥
光是反证,设计看起来像没在向前走。
但正因为用反证夯实了立足点,下一步才有了意义。那就是 Stage2: 实 LLM 评价。
6.1 proxy 轴(mechanism feasibility)
首先,作为 Stage2 的前半,我把 LLM 不擅长的 5 个轴用 **proxy(决定论 heuristic, 不依赖 LLM)**做成了 plugin。
| pressure(LLM 弱点) | 相关思考因子(case) |
|---|---|
| typo_robustness(噪声耐性) | consistency / reality_link / uncertainty |
| polysemy_wsd(多义词) | multiview / consistency / reality_link |
| multistep_robustness(多步推理) | structurize / closed_loop / self_extend |
| calibration(信度估计) | uncertainty / provenance |
| context_management(无关上下文耐性) | consistency / provenance / recompose |
共 14 个 case 输出到 breakdown,lldarwin 的 ε-lexicase 不聚合,而是逐轴淘汰 specialist。
下面是那些 proxy 轴的母集团均值推移。
但是——正如此前一再所言——这是 proxy。
个体是 genome 而非实 LLM,所以这个 pressure 只是"genome 备有多少与那个弱点相关的思考因子"的
行为代理。没有测量 production 的 LLM 能力(只是 mechanism feasibility)。
SVG 上也烧入了 "PROXY"。Goodhart 风险在此作为已接受的极限明确标注。
6.2 实 on-prem LLM 评价(proxy→real 的桥)
而本文得以首次报告的前进——实 LLM 评价跑起来了。
由于查明 localhost 的 ollama(llama3.2:latest)可达,我在 real_pressures.py 实现了
个体 → 实 LLM 映射(Promptbreeder 系)。机制如下。
- 把个体的
c_prompt(PromptChromosome)转换为 system prompt
(skill_set → 指示文 / prompt_template_id → 推理风格 / language_style → 语调)。 - 给固定 LLM(llama3.2)套上那个 system prompt,让它解 5 个弱轴的实任务并打分。
- 也就是说,固定 LLM 本体,进化 prompt 策略(genome)。
用实测来淘汰"哪个 prompt 策略能缓解 LLM 的弱点"。
结果,确认到了实选择信号。
CoT + structure 策略(chain_of_thought + structurize + loop),把
llama3.2 的 multistep 从 0.0 改善到了 1.0(terse 的策略在 0.0 失败,score 0.80→1.00)。
不是 proxy 的幻影,而是在实 LLM 上实证了"prompt 策略的进化能缓解弱点"。
把 proxy 轴(前述)和实 LLM 轴(上)并排来看,就能用眼睛看出"用 proxy 测出的形状"
和"实测的形状"有何不同。proxy 只表明机构在运转。实 LLM 则表明,prompt 策略
对模型的弱点实际如何奏效。这 2 张图的差异,正是本文主张的实物。
6.3 但在这里,也要诚实
在实 LLM 上跑起来了——但在这里,我同样要拉响警笛。保留有 4 条。
-
(a) 只有 c_prompt 参与 fitness — persona / c_factors 是中立的,不牵涉 fitness。
谱系由 reservoir 维持,初期选择由 novelty 承担。也就是说,这是"prompt 策略的进化",而不是
"persona 的进化"。 -
(b) 全部 founder 的初期 c_prompt 相同(default) — 所以探索由 mutation 驱动。
让每个 founder 的 prompt 多样化是今后的改善点。 -
(c) 小批量(每轴 2 题) — 估计含噪。"multistep 0→1"也因为题数少,
仅凭这个无法主张泛化。 -
(d) on-prem only(测量纯度) — 限于 localhost ollama,
并非对一般 LLM 能力的主张([[feedback_llive_measurement_purity]])。
我也启动了 12h 连续运行(--fitness real-pressure --selection lldarwin --novelty --lineage-reservoir --genome3d)。在 wallclock 12h safely 停止(已 snapshot → 可用 --resume 续跑)。
但我不说"跑了 12h 所以是真的"。跑了,是事实。把本质测尽了,是谎言。
proxy→real 的桥架起来了。但还没渡完。——这就是 Stage2 的诚实状态。
7. 结论 — 能主张到哪里(界线)
"只要把 LLM 的弱点当作 proxy fitness,进化就能克服"是乐观的。
用反证削减之后,我把 lldarwin 的价值主张限定为下面 3 点。
- (a) proxy 只是 mechanism feasibility — 验证进化的管路在运转。不主张 production 能力。
-
(b) 实 LLM/VLM 评价才是本质 — 智能的选择压力由个体 → 实模型映射(Stage 2)承担。
桥在这里架起来了。但正式渡过还在今后。 -
(c) 多样性的地图化 — 把能赢的轴限定为"无可验证性的多样性(认知、文化风格)的地图"。
不主张未设想涌现。
这就是 honest disclosure。失败(#25)、自己的混淆(§3.2)、极限(#5/§6.3),都不抹去地留下。
一句气派的胜利宣言都没写的这篇文章,我认为正是进化弧线中最诚实的一回。
向前迈进的立足点,只存在于这条界线之上。
8. 教训(永久保存)
-
结果越好(0.05 改善)越要怀疑其内訳。 "proxy 行为多样性"既不是"谱系多样性"也不是"实 LLM 智能多样性"。
看到一个数字就草率断定另一种能力也变好了的我,就是 Goodhart 的活标本。 -
不修"测量"只把"淘汰"做得高级,是徒劳。 对饱和的镜片,任何选择压力都无效。
打磨镜片在先,载上淘汰器在后。 -
Goodhart 定律是进化的天敌。 把指标当作目标的那一刻,进化就会 hack 它。
而且读指标的人类的解释也一并背离。 - 既然设计者决定多样性的方向,就不主张未设想涌现。 限定能赢的轴,才是诚实。
-
"存活"也许是"生命维持"。 全部 8 个谱系都留下来了,是事实。全员都在活跃进化,是谎言。
动词的选择之中寄宿着 honest disclosure。
下回预告: 用反证夯实立足点之后,接下来是 Stage 2 的全面化(实 LLM/VLM 评价, on-prem ollama)。
不是 proxy 的幻影,而是能否真的把实模型的智能多样性变成选择压力。
能否不让"multistep 0→1"止步于小批量的偶然,而把它培育成可复现的选择信号? 从这里起才是动真格。
9. 相关
- 连载 #25"只有我和弗里斯顿留了下来"— 失败的记录(本文的起点)
- 连载 #26"lldarwin 的设计"— 淘汰器(本文反证的对象)
- 实现 commit(llive): Stage1 =
8060204/ lineage-reservoir PoC =0d0537d/
Stage1.5(EvolutionLoop 集成)=b03cbda/ Stage2(实 LLM real-pressure)=2fb2912 - 实测正本:
../../research/lldarwin_stage1_results_2026_05_26.md(§3 honest disclosure / §4.1–4.5) - 设计正本:
../../vision/LLDARWIN_DESIGN.md§7 / §7.1(反证调查、已接受的极限) - 相关 memory: [[feedback_benchmark_honest_disclosure]] / [[feedback_llive_measurement_purity]] / [[feedback_implementation_status_record]]
- 参考: Goodhart 定律 / La Cava 2019(ε-lexicase, arXiv 1905.13266)/ Taylor et al. 2016(open-endedness 的极限)/
Bedau(neutral shadow)/ Kimura(中立进化说)
☕ 闲话休题 —— 演一出"双簧" —— ccr 自动续跑里,那"人类的一根手指"
反证连着写下来,脑子有点累了,讲个让人喘口气的故事。作者一心想让 Claude Code"尽可能靠它自己一直跑下去",于是搭了一套机制(ccr 自动续跑):一启动就把工作内容自动喂进去。理想状态是一台全自动机器,睡觉时开发也照样自己往前推进。可是无论怎么折腾,最后总有那么一处,必然要留下"人类的一根手指"。具体来说,就是被要求重启或重新登录的那一刻——唯独那里,AI 没法自己去按那个按钮,世界会一直停摆,直到人伸手按下回车。这是一道再朴素不过的墙:AI 没法靠自己把自己重启。
这恰好像一出"双簧"。前面那位负责脸和嘴、做表情,后面藏着的那位负责发声、动手。两人配合默契时活灵活现,可到了关键处,少了那位"幕后的人"这出戏就唱不成。AI 自主运行也一样:九成九的时间都是 AI 在台前又唱又跳,唯独最后那一手,得靠人从幕后伸进来。不去扑那个"完全自动"的幻象,而是老老实实承认"人类的介入点究竟必然留在哪里"——这同样是本文一以贯之的那句"结果越好越要怀疑其内訳"的一个小小的实地版。来,喝杯茶吧。
第6章 「展示」进化的技术谱系 #30 — 从 Conway 的生命游戏到 3DGS
📖 一句话概括
这是一回零公式、几乎零代码的"散步"。作者一直喋喋不休讲的人工进化,其实已有半个多世纪的历史;有意思的是,这门研究始终与"怎么展示(可视化)"两人三脚地一同前行。从 1970 年那个黑白闪烁的生命游戏起步,到让代码成为生物的 Tierra、测量进化的 Avida 系统树、用 3D 动画呈现进化的 Karl Sims、平滑唯美的 Lenia、把多样性画成地图的 QD,再到最前沿的 3D 高斯……我们一口气追溯展示方式从"抽象→具象→动态"一路进化的历程。最后,我们定位 FullSense 的进化可视化在这半个世纪的谱系中究竟站在哪个位置。
概念钩子:我在 #25〜#27 里喋喋不休讲的「人工进化」,其实是一个有着半个多世纪历史的研究领域。而有意思的是,进化研究始终与「如何展示(可视化)」并肩前行。从 1970 年黑白闪烁的细胞,到 2024 年连续流体与 3D 高斯。让我们作为一种通识,一口气追溯「展示进化的技术」的谱系。最后,我们将定位 FullSense 的进化可视化(绘制在思考因子图上的系统树)站在这条谱系的哪个位置。
0. 为什么「可视化」是进化研究的主角
进化是一种 长时间、大种群、多世代 的现象。一堆数字罗列,根本抓不住「到底发生了什么」。因此人工进化的历史,几乎就直接是 「让人一眼理解进化的表现手法发明史」。
🍵 休息点:这篇文章是一次零公式、几乎零代码的「散步」。请端着咖啡慢慢看。我们只拾取各个时代「展示方式的突破」。
1. 1970:Conway 的生命游戏 —「简单规则生出图案」
- 是什么:二维元胞自动机。生死两态 × 8 个邻居细胞的简单规则。
- 可视化的发明:格点的闪烁本身就是可视化。滑翔机、闪光灯、滑翔机枪这类「移动的图案」被赋予了名字 = 人类 用眼睛为涌现模式命名 的最早期例子。
- 局限:这并非进化(自然选择),而是决定论式的展开。但「简单规则 → 复杂外观」的冲击开辟了这个领域。
本节计划充实:深入探讨「滑翔机被识别为『移动的结构』」如何成为可视化催生概念的绝佳例子。
2. 1991:Tierra(Tom Ray)—「代码成为生物」
- 是什么:在虚拟 CPU 上自我复制的机器码程序的生态系统。寄生体、免疫、最优化 自行涌现。
- 可视化的发明:内存映射的可视化。把每个程序所占据的内存区域用颜色涂出,将寄生体咬入宿主的样子作为「地图」展示。它 把「代码的生态系统」描绘成了一个空间。
- 意义:在计算机内首次观测到「自我复制子的自然选择」。这是开放式进化(open-ended evolution)研究的起点之一。
3. 1994:Avida(Adami / Ofria)—「测量进化」
- 是什么:继承 Tierra 谱系的数字生命平台。完成逻辑运算便可获得奖励(CPU 时间)。
- 可视化的发明:系统树(phylogeny)与适应度地形的可视化。把「哪些子孙从哪个祖先分支而来」绘成一棵树,让复杂性状(如 EQU 运算等)逐步进化的过程变得 可追踪。
- 意义:它实证了「复杂性会经由不可避免的步骤进化」(Lenski et al. 2003, Nature)。它 把进化从故事变成了测量对象。FullSense 的 monoculture 监控(max_lineage_share / archive 成长)正是这种「被测量的进化」的直系后裔。
🤔 打比方(相声风):
逗哏:「Avida 让进化能用数字来测量了。」
捧哏:「也就是给进化发了张成绩单嘛。」
逗哏:「没错。我在 #25 里说『满分通胀把成绩单搞坏了』,说的正是 Avida 级别的测量这回事。」
4. 1994:Karl Sims「Evolved Virtual Creatures」—「用影像呈现进化」
- 是什么:在 3D 物理仿真之中,同时进化 形态(block 的连接)与神经控制,孕育出会游泳、会走路、会争抢物体的生物。
- 可视化的发明:3D 动画影像。不是用论文里的图,而是用 视频 来展示,这引发了震撼。它把「进化所设计的、谁都没料到的奇异步态」做成了 人类能凭直觉觉得有趣 的形态。
- 意义:进化可视化从「面向研究者的图表」迈向了「任何人看了都会惊叹的影像」。它是 FullSense 演示哲学([[project_f25_demo_polish]]「以动感取胜」)的精神祖先。
🍵 休息点:到这里,如果你能看出展示方式经历了 抽象 → 具象 → 动态 的进化——「黑白点 → 内存地图 → 系统树 → 3D 视频」——那就够了。后半部分是现代篇。

🗒️ "人类灭绝之后的动物!?" — 用影像呈现进化的谱系(空想进化)(© Forbidden shibukawa / SHUEISHA・《零食吧 Basue》)
5. 2019:Lenia(Bert Chan)—「连续的人工生命」
- 是什么:把生命游戏一般化为 连续空间、连续时间、连续状态。人们发现了大量平滑运动、「像生物一样」的图案(如 orbium 等)。
- 可视化的发明:连续场的平滑渲染。从离散的闪烁,转向如生物细胞般柔韧运动的流体式表现。它开辟了一条新的诉求轴线:「人工生命是 美的」。
- 意义:这是可视化质量本身提升了研究发现力的例子。正因为看上去美,人类才能注意到新的图案。
6. 2020 年代:Quality-Diversity 的可视化 —「把多样性画成地图」
- 是什么:MAP-Elites / CMA-ME 等 QD 算法。它们生出的不是单一 best,而是 多样的高性能解的集合。
- 可视化的发明:behavior space 的热力图。取两轴的 behavior 描述子放到格点上,把每个 cell 的 elite 用颜色涂出 = 「把多样性本身可视化为地图」。
- 意义:FullSense / lldarwin 的 QD archive 可视化直接立足于此。它能通过 地图的空白 vs 填充 一眼展示「只要还剩一个 cell 就不会全军覆没」(详见 #26)。
7. 2020 年代起:3D Gaussian Splatting(3DGS)—「将进化的状态以空间表达」(FullSense 的赌注)
- 是什么:原本是新视角合成(NeRF 谱系)的技术。它把点云用 3D 高斯来表示,并以高速、高品质渲染。
- FullSense 的构想:一种探索——能否把进化种群的 高维 genome / pressure profile 映射到 3D 高斯空间,从而「将进化的状态立体地展示出来」(与 [[project_precision_metrology_llm]] 的 SH 系数联动同根同源)。
- 定位:这 仍是一项研究性赌注,并非已确立的技术(honest disclosure)。它是放在本文谱系「最前沿的边缘」上的一次实验。
8. FullSense 的进化可视化站在哪里
| 时代 | 展示方式的核心 | 在 FullSense 中的继承 |
|---|---|---|
| Conway 1970 | 闪烁细胞 = 为涌现命名 | (概念上的祖先) |
| Tierra 1991 | 内存地图 | 系统占有率的地图化 |
| Avida 1994 | 系统树 + 测量 | monoculture 监控 / lineage tree |
| Karl Sims 1994 | 3D 视频 | 「以动感取胜」的演示哲学 |
| Lenia 2019 | 连续场之美 | animated SVG 表现层 |
| QD 2020 年代 | behavior 地图 | lldarwin QD archive 可视化 |
| 3DGS 2020 年代起 | 3D 空间表达 | (研究性赌注) |
FullSense 的进化可视化(思考因子图上的系统树 + animated SVG)所处的位置,是 在终端 / 浏览器中再现 Avida 的「会测量的系统树」、Karl Sims 的「以动感取胜」以及 QD 的「多样性地图」。它是这条长达半世纪的谱系中,虽不起眼却根正苗红的后裔。
下回预告:追溯完谱系,接下来就是实现。我们将以真实的 evolution.svg 为题材,讲解 FullSense 的系统树 animated SVG 究竟吸收了上述哪些「展示方式」、又是怎么吸收的。
9. 相关
- 连载 #25〜#27 — 本文进化可视化的「内容」(monoculture / lldarwin / 反证)
- 相关 memory:[[project_github_animated_svg]] / [[project_fullsense_animemd_branch_token_viz]] / [[project_f25_demo_polish]]
- 参考:Conway 1970 (Life) / Ray 1991 (Tierra) / Adami & Ofria (Avida) / Lenski et al. 2003 (Nature) / Karl Sims 1994 (SIGGRAPH) / Bert Chan 2019 (Lenia, arXiv 2005.03742) / MAP-Elites (Mouret & Clune 2015, 1504.04909) / 3DGS (Kerbl et al. 2023)
第7章 让 AI 把 AI 当作下属来使用 #31 —— Claude 主导 + Codex 配属的「两根支柱」开发体制
📖 一句话概括
FullSense 是作者一个人的个人开发项目,但实际上并不是"一个人"。它运转着一套"人 1 + AI 2"的两层体制:把 AI 编码代理 Claude Code 放在"主(指挥中枢)",把另一个 AI Codex 放在"下属"。本章的要点不是"用两个 AI = 聪明一倍",而是把指挥系统始终保持为一条。最大的危险,是"一个 AI 不加验证就相信另一个 AI 的输出"这种连锁——错误会被层层放大。所以铁律是:"外部 AI 说的话,必须用真实代码或一次信息源逐条核实之后才采用"。下属的汇报是起点,而不是结论——本章用实例与反模式,讲述这套多重委派的统制之术。
概念钩子:FullSense(llmesh / llive / llove)是我一个人的个人开发项目。但实际情况
并不真的是「一个人」。一套以一个 AI 编码代理为主、以另一个 AI 代理为下属的
两层开发体制正在运转。主为 Claude Code,下属为 Codex CLI。
「AI 把工作分派给 AI,再由 AI 来验证其成果」——如何让这种多重委派保持纪律、
不至于失控?本文是关于运行「1 个人 + 2 个 AI」这一「两根支柱」体制的实践记录。关键词是 编排者(orchestrator)/ 配属 worker / 验证纪律 / 并行化。
0. 三行剧情简介
- Claude = 编排者(计划、实现、委派、验证)/ Codex = 配属 worker(执行、评审、调查)。
- 「两根支柱」并非对等,而是 Claude 主导 + Codex 配属。指挥系统要保持唯一。
- 铁律:外部 AI 的 finding 必须先用实代码 / 一手信息逐条验证后才采用(禁止盲信)。
1. 为什么是「两根支柱」—— 动机
在个人开发中,只用一个 AI 代理早已是常态。那么我为什么要加上第二个(Codex),而且是作为下属?
- 厂商分散与冗余 —— 对冲单一代理的计费变更 / 故障 / quota 枯竭。
- 交叉评审 —— 把同一份设计拿给另一系谱的 AI 看,获取第二意见(减少盲点)。
- 并行 worker —— 把独立子任务抛给下属,主则专注于最重要的任务。
🍵 休息点:「用两个 AI = 聪明两倍」是错的。关键在于保持指挥系统的唯一性。
若搞成乌合之众,反而会变慢。本文有一半是在讲「如何统制」。
2. 角色分工 —— 编排者与配属 worker

- Claude(主)的职责:任务分解、依赖性判定、独立任务的并行启动、进度监控、成果验证、统一提交(commit)。
-
Codex(下属)的职责:执行被委派的范围。非交互式委派 =
codex exec -s read-only "<prompt>"。 - 指挥系统始终是 Claude。 Codex 只能经由 Claude 才能影响整体(不让它直接 commit)。
本节待充实的内容:对比 Claude 子代理并行([[feedback_parallel_first_execution]])与 Codex 配属委派的
使用区分表。「同一 file 串行、独立 file 并行」「git 操作由 orchestrator 统一进行」([[feedback_agent_no_git_parallel]])。
3. 验证纪律 —— 「禁止盲信」是体制的命脉
两根支柱中最危险的,是一个 AI 不经验证就采用另一个 AI 的输出。错误会被放大。因此有铁律:
外部 AI(Codex / Copilot / Gemini)的 finding,只有在用实代码 / 一手信息逐条验证之后才采用。
实例:在本连载 #26(lldarwin 设计)中,对既有代码资产的调查(例如 mating.py:139 LexicaseSelection
是「已实现但未接线」等)是让下属去调查的,但接线点与行号是由主(Claude)在实文件中确认后
才写进设计文档的。不会把「Codex 是这么说的」当作设计的依据。
🤔 打个比方(相声风格):
师父:「喂,那个函数,接线了没有?」
徒弟:「禀师父,没接线。」
师父:「……你这『禀师父』我信不过。我自己去看源码。」
——这就是验证纪律。徒弟的报告是起点,而非结论。
本节待充实的内容:验证的三个阶段(收到 finding → 用实代码 / 一手信息确认 → 采用或弃用),以及
评审封装器(如 tools/copilot_review.sh 这类只读评审)的定位。
4. 并行化的规矩 —— 不让它失控的统制
同时运转多个 worker(Claude 子代理 + Codex)时的纪律:
- 2~4 个并行是安全区(主的 context 有余裕、无提交冲突)。5 个以上则要严格管理 file 级别的独立性。
- 抽取独立任务 = 无依赖 + 在 file / module / repo 级别互不接触。同一 file 串行(类似 file lock)。
- 不可逆操作(删除 / push / submodule 改动)逐条经人工确认。 不让下属擅自去做。
- git 操作由 orchestrator 统一进行。 不让并行 worker 碰 git(规避冲突)。
🍵 休息点:「把 AI 摆得越多越快」是个陷阱。主的 context(注意力的总量)才是限速因素。
即便并行 5 个,若主处理不过来也毫无意义。和大脑的工作记忆一样,能同时把握的数量是有上限的。
5. 反模式(绝不可做的事)
- 宣布「我会逐个确认着推进」之后却默默地串行执行(错失了并行化的机会)。
- 不委派给下属,全部都在主的 context 里干(context 爆炸)。
- 在并行启动的 worker 出结果之前,主就去碰同一个 file(冲突)。
- 委派两个 worker 去写同一个 file(独立性判定的遗漏)。
- 不经验证就把下属 AI 的 finding 采用进设计或实现(错误放大 = 两根支柱体制中最大的事故)。
6. 这套体制实际运转出了什么(FullSense 的实例)
- 设计交叉评审:让下属评审进化设计 / 需求 / PoC,主用实代码验证后做出采用判断。
- 既有资产调查:让下属调查 lldarwin 既有部件(loop.py / mating.py / nsga2.py 等)的所在 → 主确认。
- 并行子任务:把文章骨架、代码调查、需求整理作为独立任务并行化(本连载本身就是其产物)。
🍵 休息点:最后我也会诚实地谈谈,「1 个人 + 2 个 AI」让个人开发的生产力发生了怎样的主观变化。
对变快的方面(并行、冗余)与增加的负担(验证成本、统制成本)两者都做 honest disclosure。
7. 教训
- 保持指挥系统的唯一性。 两根支柱并非对等,而是主从。指挥中心的分裂是事故之源。
- 验证纪律是体制的命脉。 AI 不经验证就相信 AI 的连锁,是最大的风险。
- 并行度由主的 context 限速。 以能处理的量来决定,而非以个数。
- 不可逆操作与 git 由人类 / orchestrator 掌握。 只把可逆的工作交给下属。
下回预告:把用两根支柱运转出来的进化设计(#26 lldarwin),借助配属的 Codex + on-prem ollama,
推进到 Stage 2(用真实 LLM 评估)。多重 AI 委派究竟能把「研究的实现速度」提升到什么程度。
8. 相关
- 连载 #26「lldarwin 的设计」—— 用本体制运转出来的实例。
- 相关 memory:[[reference_codex_two_pillar]] / [[feedback_parallel_first_execution]] / [[feedback_agent_no_git_parallel]] / [[feedback_external_ai_verify]]
第8章 (连载 #32) llcore CPU PoC battery 完成
📖 一句话概括
从这里开始,话题从 lldarwin 转向 llcore。llcore 不把"LLM 的权重"当基因,而是把权重底下那个"核心计算的式子本身(状态更新规则、学习规则等)"当基因来进化,是一个只用 CPU 就能跑的研究框架。本章是它的地基——5 个小实验(PoC battery)完成的报告。最大的看点,是为了不让进化失控、生出数值上会坏掉的式子,把 Z3(一种机械地证明式子是否成立的工具)放进进化循环里当门卫。事前调查确认这是先行研究中找不到的独有之轴。同时也诚实地补一句限制:接真实 LLM 还在等 GPU。
TL;DR
- 将 Transformer 的核心计算 (state update / 学习规则 / 认知驱动 Δ) 作为进化对象的研究框架
llcore(PyPI:llmesh-llcore0.1.0a0, llive 独立路线) 的 CPU PoC battery 完成 - 以 5 个 PoC / 39 个可证伪 gate / 76 个测试 / Codex pair-review 5/5 Green-light 完成机制验证
- 用 Z3 对结构变异进行 online gate = 把 SMT 嵌入进化搜索的 selection pressure,经事先调查发现为未被探索的先行研究 (事前调查 RAD 14 个领域 + Agent A-D 确认)
- 投稿候选: TMLR (本命) / GECCO 2027 short / NeurIPS 2026 workshop (verification × ML)
为什么要做
冻结 LLM 权重是标准做法,但核心计算算法本身仍固定为人工设计。AutoML-Zero / NAS / AlphaEvolve / Sakana Evolutionary Model Merge 等 architecture/algorithm 搜索虽已推进,但:
- 个人 compute 无法承担计算资源 (TinyLlama 1.1B from scratch = $140k / 90 天 / 16×A100)
- 搜索过程中没有安全性保证 = 生成数值不稳定的 architecture 而浪费时间
- 带验证的搜索与静态 verification (Reluplex/Marabou/α,β-CROWN) 相互割裂 — 在进化循环内做 SMT online gate 的研究未被发现
已确定的独有轴 (事前调查中没有 negation work)
机制已验证 (4 个轴):
- ChangeOp → Z3 online gate (Stage 1a, 5.8ms)
- 将 state update 规则基因化 RWKV-style (Stage 0a v2)
- factor_hook (认知状态 → SSM Δ) (Stage 2a mock)
- 自研进化器 + verifier 基础 (Stage 0c + 1a)
post phase: persona-indexed specialist / Marabou refinement / 提出 VNN-COMP 新类别。
PoC 阶梯 (5 stage / 39 gate 全部 PASS)
| PoC | 内容 | 关键数值 |
|---|---|---|
| 0a v2 | RWKV-style state update gene | G6 var=7.4e-3, G9 escape@step1 |
| 0b v2 | synthetic fitness (copy/add) | G4 rank_corr=-0.20, G7 best 0.518/0.525/0.703 |
| 0c v2 | 自研 minimal GA | G3 monotonic 0.249→0.552, G7 dist=2.15 |
| 1a v2 | Z3 state_norm invariant | G2 unsat 5.8ms, G3 sound CE |
| 2a | factor_hook × state update mock | G7 evolution smoke monotonic |
从 v1 的失败中学到的东西 (honest disclosure)
PoC 0a v1 用 decay*s + mix*x*tanh(gate_str*s),使得 state=0 成为 fixed point 的 zero attractor = 形式上通过 G1-G5,但信息传递为零。Claude 单独遗漏的设计问题被 Codex (gpt-5.4) 与 gem-critic 的独立 verdict 检测出来,从而在 RWKV-style 上做了 v2 redesign。
→ 在 5 个 PoC 中有 4 件,Claude 单独遗漏的设计问题被 Codex pair-review 检测出来。这是相互评审在防止结构崩溃上发挥作用的实例。
下一步选项
a. Stage 3 kernel 多样化 (将 rwkv/mamba/hopfield/linear-attn 基因化)
b. Stage 4 将学习规则 (FF/EP/PCN/Hebb) 基因化
c. Stage 5 Marabou Incremental NN Verification bridge
d. 用 PrediPrune+Quokka 给 Z3 gate 提速
e. 用 FlashEvolve 实现 3.5-5x wall-clock 提速
f. 写成论文 (TMLR + GECCO 2027)
Honest 保留
- 以 mock 为主,连接真实 LLM/权重要等 GPU/新 PC
- 1 step scalar invariant 处于 over-approx proof 阶段,多维、多 step 在 post phase
- tanh 上界近似偏保守 (sound 但不完整)
Tags: 进化计算 / 形式验证 / Z3 / RWKV / state space model / CPU研究
相关: 连载 #14-31 (llive lldarwin v0.B-E + 观测+governance + lleval)
Project: (PyPI llmesh-llcore 0.1.0a0)
☕ 闲话休题 —— 上下文爆炸的悲喜剧
这里说一段让 AI 长时间干活时必然撞上的"上下文爆炸"。AI 一次能记住的工作便签是有上限的(上下文),一旦读进长长的实验日志或大量文件,那块额度就眼看着被填满。换成人,就好比桌上堆的文件太多,关键的那一张反倒不知道压在哪儿了。麻烦在于:额度一满,AI 就开始把旧记忆压缩成摘要扔掉,而那些没能留在摘要里的"还没保存的改动""一直开着没关的进程",就这么从意识里悄悄消失了。
有意思的是,这和本文 lldarwin 讲的"在满分处饱和、选择压就消失"多少同构。那边是评价钉死在天花板、差异消失的病,这边是记忆钉死在天花板、细节消失的病。两者结构相同:"一旦贴死在容量的上限,重要的信息就会被抹平。"所以正篇里也上了一道朴素的保险:长时间运行的状态不交给摘要去托管,而是每次都老老实实重新核对一遍当前状况。在花哨的进化计算背后,还藏着这种"不停收拾记忆的桌面"的日常活儿——这就是这段后台轶事。
第9章 (连载 #33) 过于整齐的结果不是胜利,而是警报 —— 用 proper power 给第三轴 ③ 一锤定音的一天
📖 一句话概括
问题很简单——"用进化去搜索 AI 的核心计算时,那个保住多样性、分门别类挑选的工夫(③)到底要不要?"本章正是给这个问题画上句号的一天的记录。钥匙是地形的比喻。把设计的好坏用山的高度来表示,③ 唯有在"素朴的登山者会被假山顶卡住的欺骗地形"上才派得上用场;面对平滑的单峰山,它就是个累赘。于是我们把评估噪声从物理上压到零、重新测量那块接近实物的地形,结果确认它"确实平滑",③ 不需要被坐实。本章的看点,就是以"太整齐的好结果反而是警报"这条纪律,用三个透镜捶打自己的结论、把说过头的话一句句削掉的过程。
TL;DR
- 问题是 「当用进化去搜索 AI 的核心计算时,"挑选、分开、培育"这个工夫 (= 进化的 ③ 适者生存/分离要素) 究竟需不需要?」
- 在合成的"带山谷的 (欺骗性) 地形"上,③ 大获全胜 (过去实验中 Cliff δ=+1.0)。③ 作为机制是货真价实的。
- 但当我们把更接近真实的 CPU proxy 地形的评估噪声物理性地降到零之后重新测量,结果是"真正平滑 (单峰)",于是确定 ③ 不需要。"过去的 negative 不是检出力不足 (underpower),而是地形本来就平滑"这一点首次得到佐证。
- 只有真实 multitask 邻域 (C-gen4b) 出现了微弱的"③ NOT null"气息,但增加数据后就发生摇摆,止步于候选 (走行内漂移 + 在多重比较下脆弱)。
- "某个后处理在隐藏 ③"的怀疑 (K4 ridge clip),去掉之后反而变得更差 → 它并没有隐藏什么,降级为诊断性所见。
- 外部评审 (Codex) 没有阻断项地追认了结论。
- 结论一句话:「③ 只有在地形具有欺骗性时才会发挥作用。这次在 CPU 上能测到的、接近真实的地形,恰好是平滑的。」 主战场的定论需要 GPU (真实 LLM 地形),但那是投资决策。
- 追记 (2026-06-02, §11.5): 最后的 CPU 逃生路线 kernel 多样化 (BG9) 在结构上被堵死了。 kernel 选择是低维,因此强 baseline (RR) 会直接采样,③ 的 niching 优势在原理上无法出现。要让 ③ 起作用,需要"高维的"欺骗性地形,剩下的路只有 GPU full-LLM (而这本身也是一场赌注)。
- 元教训:诚实披露 (honest disclosure) 不是装饰,而是推动研究前进的工具。 在 BG9 中,同样的纪律在"把 negative 正确地确定为 negative"这个方向上也奏效了。
⚠ 本文中的所有数值,都是与本地 (手边) 的研究 commit
THIRD_AXIS_SETTLE_VERDICT.md绑定的实测值。llcore 还没有建立公开仓库,所以无法贴出外部链接。作为替代,我把"如何测量"全部写在正文里。
0. 这篇文章在讲什么 (概念)
llcore 是一个 CPU 完结的研究框架,它"把 Transformer 的核心计算 (状态更新规则、学习规则、认知驱动 Δ) 作为基因,一边用 Z3 验证其不会崩坏,一边进化" (PoC battery 的事在连载 #32 写过)。
它的进化引擎有一个设计上的命门:如何让进化四要素中的 ③ (适者生存 selection / 分离 separation) 生效。这是一种像 MAP-Elites 那样"挑选、分开、培育"的机制,保持多样性并把精英留在各自的 niche 里。
问题很简单。
那个 ③,真的需要吗?
如果需要,那么为承载 ③ 而进行的重投资 (最终是在 GPU 上跑真实 LLM) 就有意义。如果不需要,执着于 ③ 就是浪费时间和电力。
在这一天 (2026-06-02),我用 3 个实验正面给这个问题作了了断。正如标题所说,结论又一次把我们拉回 FullSense 的那条低音主旋律——"过于整齐的结果是警报"。
—— 到这里 30 秒。准备运动结束。进入正题。 —
1. 打个比方:登山,与欺骗地形
在公式之前,先用地形的比喻把全貌抓住 (这是本研究中一贯使用的隐喻)。
我们用 地形的高度 来表示设计的好坏。高处 = 好设计。 这是一个寻找最高山顶的游戏。
地形其一:平滑的单座山 (简单)
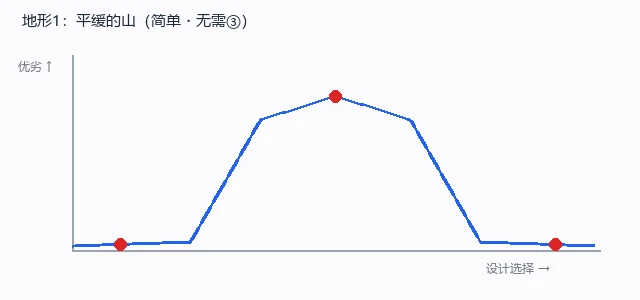
在这样的地形上,朴素的"登山法 (hill-climbing)",也就是"只朝比现在稍好一点的方向移动",就足以到达山顶。不需要那些精巧的工夫 (③)。
地形其二:欺骗地形 (deceptive)
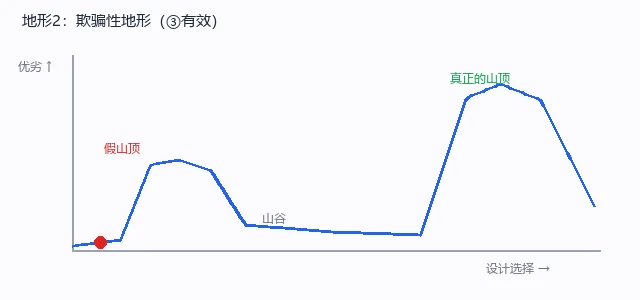
在这里,朴素的登山法会停在假山顶上。因为它没有走下山谷的勇气。
此时起作用的就是 ③ 的思路。把各种类型的登山者分散留在山谷的各处 (= 记忆宫殿 / MAP-Elites archive)。某个登山者可以靠"踏脚石"渡过山谷,到达真正的山顶——这就是其机制。
用一句话概括本研究的核心:③ 真正有用的,只有在"欺骗地形"的时候。 在平滑的单座山上,③ 是无用的累赘。
所以问题可以改写为:
「当用进化设计 AI 时,实际遇到的地形是"欺骗地形",还是"平滑的单座山"?」
这个一旦确定,③ 需不需要也就确定了。今天,我们测的就是这个。
2. 过去遗留的问题 ——"③ 不需要"真的是"不需要"吗
通过迄今为止的实验 (Step C → 梯子段 1 → E-A → 谷深实测),图像大致是这样的。
- 在合成的欺骗 corridor 上,③ 大获全胜 (战胜全部 3 个 baseline,Cliff δ=+1.0)。③ 已被存在性证明,作为机制是真的。
- 在更接近真实问题的 proxy 地形上,③ 是 negative (MAP-Elites 只能与 random 打平 = 与平滑地形相同的症状)。
然而,这里残留着 2 个未解决的疙瘩。
- "③ 不需要"究竟是因为"地形平滑",还是仅仅因为"样本数不够、检测不出差异 (underpower)"? ── 弄错这一点,就会犯下"③ 无力"这种过度泛化的错误。
- 谷深的直接测量上次以 N/A (无法测量) 告终。评估噪声比山谷的深度还大,所以即便有谷也会被埋没看不见——这是仪器的极限。
也就是说,"看起来平滑"究竟是 地形的性质 还是 仪器的极限,并没有定论。把这一点说清楚就是 Step D。
—— 稍事休息。以上是前提。从这里开始是今天做的 3 个实验。 —
3. 实验设计 —— 三件套
| 实验 | 测什么 | 目的 |
|---|---|---|
| EXP1 | proper-n 复检 | 认真增大样本数,用检出力把 ③ 的效果是否真实钉死 |
| EXP2 | 决定论 C1 多峰性 | 把评估噪声物理性地归零,noise-free 地判断地形是"欺骗地形"还是"平滑的单座山" |
| EXP3 | K4 ridge clip 的 verdict-flip | 验证"某个后处理在隐藏 ③"的怀疑 |
纪律:全部隔离在 research/step_d_settle/,src 不改动,git 由协调器一次性提交。每个实验都要通过崩坏门 (G1 CPU 全程跑完 / G2 可复现性 / G3 诊断器有效 / G4 src 不变)。
4. EXP2 才是决定性的 —— 把评估噪声归零,地形就显现了
顺序有所颠倒,但 最起作用的是 EXP2,所以先写它。
上次谷深测量变成 N/A 的原因很简单,就是 "谷的深度 (约 0.05·|fitness|) ≪ 评估噪声的抖动"。山谷被埋在仪器的噪声里,无法判断它存在与否。
EXP2 的诀窍是这样的。
ESN reservoir (固定 seed) + ridge readout 的 closed-form (
np.linalg.solve),完全不抽取随机数。 因此可以把评估噪声物理性地归零到机器 epsilon (约 1.11e-16)。
实测中我们确认了 eval_noise_std ≤ 1.11e-16。这不是"每次评估值都抖动",而是源于浮点最小单位 (ULP) 的误差,实质为零。 在噪声之雾完全散去的状态下,可以直接测量地形的山谷。
结果如下 (valley_fraction = 山谷的比例,越大越多峰 = 欺骗地形):
| landscape | 类别 | 维度 | valley_fraction (mean/max) | 多峰? | 判定 |
|---|---|---|---|---|---|
| ESN_3param (真实 proxy) | real | 3 | 0.000 / 0.000 | False (3 seed 一致) | 平滑=单峰 → ③ 不需要,noise-free 确定 |
| ESN_perneuron40 (真实 proxy) | real | 40 | 0.096 / 0.121 | False (3 seed 一致) | 偏平滑 (低于地板 0.2) → ③ 不需要 |
| ctrl_multipeak_dim3 (正 control) | control | 3 | 0.701 / 0.727 | True | 诊断器能检出多峰 ✓ |
| ctrl_multipeak_dim40 (正 control) | control | 40 | 0.795 / 0.818 | True | 诊断器健全 ✓ |
| ctrl_quadratic_dim3 (负 control) | control | 3 | 0.000 | False | 诊断器能检出平滑 ✓ |
| ctrl_quadratic_dim40 (负 control) | control | 40 | 0.000 | False | 诊断器健全 ✓ |
要点有 3 个:
- 真实 proxy 地形 (3 维 / 40 维 都是) 是 valley≈0 = 单峰。 在 3 个 seed 上完全一致。
- 诊断器本身是健全的。 故意做出来的多峰正 control 被正确检出为多峰 (0.70/0.80),二次函数的负 control 被正确检出为平滑 (0.0)。所以"真实 proxy 是单峰"不是仪器的 bug,而是地形的性质。
- 由此,"过去的 ③ negative 不是 underpower,而是因为地形本来就平滑" 首次在真实 substrate 上得到了 noise-free 的佐证。
我也老实写下一个副发现。原本打算用作正 control 的欺骗 corridor (make_corridor_eval(d=0.16)),一旦决定论化,竟变成了 valley=0.0 (单峰判定)。 corridor 的欺骗性是"关进单一 basin、用 ③ 的 behavioral niching 逃出"这一型 (behavioral-reach 欺骗),而 不是 地形山谷 (C1 multi-basin) 的欺骗。我们用实测确定了 scope 的收窄:corridor 不能成为 C1 的正 control。这意味着过去的谷深校准无法把"corridor 来源的阈值"迁移到地形多峰性上。
—— 在这里喘口气。"正 control 没能当上 control"这件事,意外地让人受了点打击。但这一点也是不测就不会知道的。 —
5. EXP1 —— 只有真实 multitask 邻域出现微弱的"③ NOT null"气息
接着,我们认真增大样本数,对最接近真实问题的频带 (C-gen4b = MAP-Elites vs random,真实 multitask 邻域) 进行了复检。
| case | 原 n=15 (审计) | fresh 真复跑 | 判定 |
|---|---|---|---|
| C-gen4b | diff +0.063 / psd +0.20 / p 0.126 | n=64: diff +0.0472, 单侧 p 0.038, psd +0.188, gate PASS | ③ load-bearing 候选 (still_inconclusive) |
用 fresh seed 跑到 n=64,严格门的 4 个条件全部 PASS。 也就是说,审计读成"③ 不需要 (inconclusive)"在方向上是错的,在 C-gen4b 中 ③ 是朝 NOT null 的方向。
…而在这里不产生"赢了"的飘飘然,正是这一轮的要害所在。出于 3 个理由,我把它 止步于候选。
- 更新后的检出力 power@n64 = 0.517 < 0.80。 门通过了,但没达到确证的标准 (检出力 0.80)。
- 走行内漂移 (这一点起了作用)。 追踪累积 p 值的轨迹:n=40 时首次 PASS (p=0.042) → n=60 时 p=0.010 显著性加深 → n=64 时 p=0.038,又回到了 0.05 边界附近。 进一步把 seed 按前半/后半切开:前 32 个 seed 是 diff=+0.0755 (frac_pos=0.625),但后 32 个 seed 是 diff=+0.0189,最后 9 个 seed 是 diff=−0.0376 (负)。 PASS 是靠前半 seed 撑着的,越是新数据越往反方向跑。
- 多重比较。 p=0.038 在 α=0.05 下 PASS,但仅就 EXP1 的 3 个 case 而言也超过了 Bonferroni α=0.0167 (FAIL)。放到整个 ③ research family 来看就更严苛。
此外,效果量的地板 (psd) 撞上了 结构性天花板。 C-gen4b 的 median psd 从 n=15→0.200 到 n=255→0.200 纹丝不动。P(|psd|≥0.147) (效果量条件的满足率) 即便在 n=255 也封顶于 0.794。因为是中效果 (psd≈0.20),无论怎么增大样本,full gate 的检出力都不会超过 0.80。也就是说,"只要增大样本就会确定 (A)"这个前景本身,在这个 proxy 上就很渺茫。
结论:C-gen4b 是"③ load-bearing 候选 / still_inconclusive"。 "③ NOT null"这个 headline 过于依赖单一的边界 p=0.038。走行内漂移是"候选可能是假阳性"的真证据。
6. EXP3 ——"后处理在隐藏 ③"的怀疑,去掉之后反而更差了
最后一个怀疑是这样的。"ridge readout 的 clip (K4) 这个后处理,会不会其实在掐死 ③ 的信号?" 如果是这样,去掉 clip,③ 就应该浮现出来。
我试着去掉了。
| task | clip | MAP-E mean | 战胜的 baseline 数 | verdict_flip |
|---|---|---|---|---|
| addition | True | +0.0100 | 1/3 | — |
| addition | False | −1.212 | 0/3 (全部恶化) | False |
| flip_flop | True | +0.426 | 0/3 | — |
| flip_flop | False | +0.438 | 0/3 | False |
去掉 clip 后,③ 非但没有浮现,反而 在 addition 上 MAP-Elites 从 +0.010 → −1.212 劣化。 clip=False 把 MAP-Elites 落进了 raw R²<0 的噪声区域 (15/15 seed 为负,R² 在 [−3.68, −0.20]),不仅没能恢复结构反而更差。= 主动反证了"clip 在隐藏信号"这一假说。
null-ridge FPR (gene 无关 target = 真正的零假设) 在 clip True/False 之间差异也为零 (两者都是 0.0)。
判定:K4 不是"唯一的主动 suppression 机制",而是降级为"压扁 spread 但不改变 verdict 的诊断性所见"。 由此可知,过去统计审计断定的"K4 = 唯一的主动 suppression"是夸大了。
诚实的保留 (相当于 §6.3):null-FPR=0/0 只是 null_seeds=4 的地板值,而且这个实验把预算缩小了约 7 倍。所以我把 verdict 的标签统一为不是"null 确定"而是 "not_load_bearing_at_this_budget (在此预算下非载荷)"。因为"在此预算下 K4 非载荷"比"零假设已确定"更准确。判定的实体 (降级为诊断性所见) 不变,只是提高了用词的精度。
—— 在这里深呼吸。3 个实验结束。接下来是"有没有说过头"的自检。 —
7. Surviving refutation —— 用 3 个透镜捶打自己的结论
honest disclosure 的核心是"最狠地怀疑自己的结论",所以我用了 3 个独立的反证透镜。3 个都以 refuted=true / medium 存活下来,也就是说保守的 verdict 没有被推翻,但偏 positive 的强调被朝着减弱的方向修正了。
- [power_adequacy] C-gen4b 的 gate PASS 在 optional-stopping + 多重比较下脆弱。 这就是上面 §5 的漂移和 Bonferroni FAIL。把"③ NOT null"做成 headline 过于依赖边界 p。→ 已把 p 的 n 轨迹和后半 seed 的符号反转记录到披露字段中。
- [determinism_and_circularity] 单峰 verdict 在阈值临近处脆弱。 决定论化和非循环性本身是 clean 的 (behavior 与 fitness 的相关 ≈0,诊断器不使用 behavior 描述子,而是直接看地形几何)。但 ESN_3param 的 midpoint 有 90.9% 向下方 dip,最大相对 dip=0.0435 就在 C1 谷阈 0.05 的正下方 (在 13% 以内)。所以精确地说,它不是"真正单峰",而是"略低于 C1 阈值、带浅谷 (~2–4%) 的弱 multi-basin"。(B) null 的方向得以维持,但稳健性因阈值临近而有限。
- [clip_flip_validity] K4 降级因低预算而仅限 "at this budget"。 verdict_flip=False 确实如此,但 FPR 0/0 是地板值,预算缩小了 7 倍。所以与其说"firm refutation",不如说"not load-bearing at this budget"。
3 个都不至于"把结论翻盘",但全部朝着"削掉说过头的部分"的方向起了作用。这次自我审计正是今天成果的一半。
8. 老实写下自己踩过的一个坑
在上次的谷深 workflow 中,我在第 2 段协调器 briefing 里传入了 stale (旧) 值。 像"全部 below threshold / d*=0.1234"这样的值。可实际 commit 的结果 JSON 是 all_below_threshold=false。我在读上次 workflow 结果时,把另一个 metric 的值搞混了。
敌对验证检出了这一点,把 verdict 降级为 N/A。 也就是说,怀疑自己"过于整齐的结论"的这个过程,抓住了我自己的复制粘贴失误。这不是个令人愉快的故事,但正因为它转起来了,今天的 Step D 才能从正确的立足点重新测量。
我再次体会到,honest disclosure 不只是"不抹掉失败",更是"预先放置一个能检出失败的机制"。
9. 我是如何更新过去 verdict 的
| 过去 verdict | 过去的解读 | Step D 的更新 |
|---|---|---|
| E-A C-gen4b | underpowered, inconclusive | 方向更新:③ 朝 NOT null 的方向 (fresh n=64 下 gate PASS)。 但止步于候选 |
| step6 exp7 (真实 ESN proxy, ③ negative) | n≤10 盲点域,"必须重测" | 大幅更新:地形本来就平滑 (③ 不需要),noise-free 确定。 重测也不会出现多峰 |
| 谷深 N/A (无法测量) | instrument 不能 | 解除:靠决定论化使其可测 → vf≈0 (单峰)。但阈值临近的浅谷是保留项 |
| K4 clip = 唯一的主动 suppression | "clip 隐蔽了 landscape 结构" | 降级:诊断性所见 (not_load_bearing_at_this_budget) |
"看起来像'③ 不需要'的许多过去 negative,不是 underpower,而是因为地形本来就平滑"── 这一点首次在真实 substrate 上得到确认,正是今天的核心。
10. 外部评审 (Codex) 无阻断项地追认
作为 llcore 的纪律,每个 capstone 都要通过 Codex (gpt-5.4, read-only) 的结对评审。这次的总评是 "无阻断项 ── ③ 结论已获外部确认"。
- 把 C-gen4b 留作候选而非 load_bearing 的判断是妥当的 (已在 JSON 中确认更新检出力 0.5174 < 0.80)。
- EXP2 的决定论、非循环是 clean 的。也追认了正文的自认:"阈值下的弱 multi-basin"比"真正单峰"更精确。
- EXP3 的 K4 降级在现预算下是妥当的 (FPR 0/0 + 缩小 7 倍,故仅限 at-this-budget)。
被指出的 4 项 (CF1~CF4) 全都是关于未来 rerun 时 harness 的稳健性和文字精度,并不推翻现结论。在 GPU 上复检 ③ 时,会先应用这些,再重用 harness。
11. 我们当时在尝试 CPU 的逃生路线 (kernel 多样化 / BG9)
"③ 的主战场移到 GPU (真实 LLM 的损失地形)"是 EXP2 的建议。既然真实 proxy 已确定平滑,在平滑地形上追 ③ 也不会出 (A) (地形若是单座山,挑选分离自然没有收益)。
但因为 GPU 是投资决策,我并行尝试着 一个可以在 CPU 上前进的别的假说。 那就是 kernel 多样化。
假说是这样的。即使各个 kernel (rwkv / mamba / hopfield / linear_attn) 各自都平滑,把 4 种 kernel 族 union 起来,可能会在 kernel 切换的瞬间让 fitness 产生不连续的台阶 → 地形可能变成 multi-basin (欺骗地形) → ③ 可能不用 GPU 就在 CPU 上成为 load-bearing。 验证这个的就是 BG9。
在我最初写这篇文章的时候,还是"现在正在 smoke 测量 BG6 (task → best-kernel 映射是否非常数,即'每个任务擅长的 kernel 是否不同')"。在那之后 (同在 2026-06-02 之内),BG9 有了定论。下一节追记就是它的结局。
11.5. 追记 (2026-06-02): BG9 定论 —— 逃生路线在结构上被堵死了
结论一句话:BG9 = N/A (结构性)。也就是说,kernel 多样化这条 CPU 逃生路线被堵死了,因为"③ 立不起来"在结构上是注定的。 这不是"③ 不需要",而是"在这个空间里,③ 在原理上无法与强 baseline 分离"——一个有信息量的 negative。
§11 设下的逃生路线的结果出来了。期待中的"kernel union 生成 multi-basin (欺骗地形)、③ 在 CPU 上立起来"没有发生。 而且不是"碰巧没立起来",而是查明了 在结构上就立不起来。 BG9 用 3 层证据确定了这一点。
(1) substrate validity ——"有辨别但弱" (PASS 但需注意)
首先,把 kernel-favoring task 群从第一原理重新设计,再去测量"每个任务擅长的 kernel 是否不同" (BG6),映射是 非常数 = 非 inert (PASS)。 mamba / linear_attn / rwkv 各自在不同任务上成为 best。从避开了 BG6 踩过的"memory_tasks 对 kernel 中立"的覆辙这个意义上说,是前进了。
但老实说 弱:
- hopfield 在任何任务上都没能赢。 这是因为 hopfield kernel 是 对角标量 mock,其 tanh 吸引子功能失常 (per-seed 的 R² 在 0/0.99/0 上两极分化)。所以它实质上不是"4 kernel union",而是 3 kernel。
- clean 的专门化只有 2 个轴 (selective_copy↔mamba / weighted_accum↔linear_attn)。其余 margin 很薄、fragile。
→ 辨别的存在 ≠ 多峰/障壁。 非 inert 化成功了,但那并不保证欺骗地形——只到这一步为止。另外,对角 mock 的局限正如 kernels.py 的 scope 声明,这里 只主张机制的 feasibility (不主张 full kernel 性能)。
(2) harness validity —— positive control 不 validate (这是决定性的)
接下来是主战场。在固定参数 (behavior=(kernel_id, theta L1)) 下,把 MAP-Elites (③) 与 3 个 baseline ── RR-hillclimb (random restart 登山) / panmictic-GA / random ── 做了 honest 的 paired 比较。
| 基质 | 结果 |
|---|---|
| positive control (合成 kernel-barrier) | ③ 击溃 panmictic (+0.423) 和 random (+0.208)。但赢不了 RR (+0.051, p=0.31 → FAIL)。未达到 3 baseline 全胜 = harness validity 立不起来 |
| negative control (kernel 中立任务) | 全 method R²≈1.0 饱和,③ 无优势 = 正确地 null (无假阳性,仪器健全) |
| real (kernel-favoring multitask) smoke | ③ beaten 0/3,panmictic 反而超过 ③ = ③ 不胜 |
这里就是与 Step D (技术版 §4-7) 决定性不同的地方。在 Step D 的欺骗 corridor 上,③ 能够排除 RR。为什么在 kernel 空间里不行? 根因只有一个:
RR 在每次 restart 时都能直接采样 kernel_id ∈ [0,4)。 kernel 选择是 4 离散的单一座标 (低维),所以 RR 在 restart 时会直击全部 4 个 kernel。要"找最佳 kernel",无需跨越山谷 = teleport (直接传送)。 所以 ③ 的 behavioral niching 没有登场的机会。
③ 在 Step4 的 corridor 上能排除 RR,是因为那里的 behavior 是 mean(24 维),由 CLT,均值集中到 0.5 → 全局峰是 measure-zero 区 = random/RR 无法直接采样的高维。 kernel_id 反过来是低维,可以被直接采样。
(3) red-team —— 即使用敌对验证也无法反证,反而成了确证
我们用独立的 red-team 捶打"harness 立不起来真的是结构的缘故吗?会不会是碰巧的设置失误?"。结果 无法反证结构主张,反而强化了它:
- 机制确证:instrumented RR 在 positive control 上,把 restart kid 几乎均匀地分散到 4 个 basin 上 [12,18,16,18],target 到达 88%,best 在 6/8 seed 上是 restart→in-basin climb。用数值确证了"RR 在 restart 时直接采样 kernel_id 来回避山谷"。
- 在 4 个 faithful 构成 (高维 theta corridor / sequential-kernel / in-basin L1 corridor / deceptive multi-basin) 上,③ 都赢不了 RR (beats_rr=False)。 把 corridor 放松,RR 也同等到达;把它收紧,③ 反而 先饿死 (starve)。
- 边界 sweep:把 theta corridor 的维度 D=0→3 越收紧,③ 比 RR 饿死得越快 (D=3: ③ reach 0.08 vs RR 0.42)。在 3 个 base_seed 上相同。
→ 定量确证了 "只排除 RR 而让 ③ 通过的 behavior 维度,在 kernel 空间里结构上并不存在"。
结构性洞察 (这次定论的 payoff)
③ (MAP-Elites 的 behavioral niching) 超过强 baseline,只有在"难处"位于高维 behavior 空间、用直接采样 (random restart) 无法到达的时候。
- kernel 选择是低维 (4 离散的单一座标) → RR 直接采样 → ③ 的 niching 优势在原理上无法出现。
- 即使把欺骗移到 theta 空间,RR 在 restart 后会在 in-basin 做 greedy climb,所以把 corridor 收紧到 RR 无法通过的程度时,③ 也会以同等程度饿死。RR fail ∧ ③ succeed 的窗口并不存在。
这是对 Step4 §7 残留问题"靠 kernel 多样化扩展搜索空间,③ 会 unlock 吗?"的回答。答案是 NO (在 CPU 上是结构性的)。 要让扩展 unlock ③,追加的自由度必须产生一个 高维、难以直接采样 的 behavior。kernel 选择 (低维、离散) 不满足这个条件。
对 GPU 的含意
- CPU 出尽门 CLEAR:BG9 在结构上堵死了最后的 CPU 路线 (kernel-union)。③ 剩下的路线 只有高维的 GPU full-LLM 损失地形。
- 结构性洞察让 GPU 这场赌注 better-motivated。 ③ 只有在高维 behavior 中才有意义。full-LLM 的参数空间是数百万维 = 正是高维。所以 GPU 检定遵循一条原理——不是"也许 full-LLM 是唯一例外"这种弱赌注,而是"③ 需要高维,而 full-LLM 处于高维域"。
- 但它依然是赌注:如果真实 LLM 地形能被 backprop 系的强 baseline 直接导航,那 ③ 就不需要 ── 这是与 BG9 的 RR 同型的风险 ("强 baseline 直接解出"的可能性在 GPU 上也依然存在)。所以 GPU 不应"单独为 ③",而应作为 组合判断 (与 llive 真实 LLM fitness 等搭车) + 借云做 1 次预注册 (在资本投入之前),才算适当。BG9 的结构性洞察本身就成了 GPU 的可证伪 go/no-go 标准:"如果 ③ 在 full-LLM 上 load-bearing,那它的难处应该位于高维 behavior 空间,并且用直接采样/backprop 难以到达。"
honest 保留 (重要)
- 这 不是"③ 被查明不需要"。 "③ 在这个低维 kernel 空间里,原理上无法与强 baseline 分离" = N/A (结构性),而 ③ 的机制本身在 Step4 已确定是真的。它是一个 有信息量的 N/A——虽然是 N/A,却携带了"kernel 路线已堵死"这一决定性信息。
- harness/red-team 是 smoke 规模 (5-12 seed)。在正式检定的 15 seed 下数值会动,但 结构 (收紧则 ③ 先饿死 / RR 直接采样 kernel_id) 与 seed 无关、稳健。 我们不会在 real 上跑 full ≥15-seed 的正式检定 ── 既然 positive control validity 在结构上立不起来,即便在 real 上出了"③ 不需要",也无法分离"③ 不需要 vs 检测器盲",而这个"检测器盲 = kernel 空间的结构"已被 red-team 确定,所以即使投入 7.5h 的 CPU,结论也不会改变。
- substrate 弱 (实质 3 kernel,hopfield 是对角 mock、功能失常)。若有更强的 kernel 辨别 (full 实现、非对角),则有不同结论的余地——这 在理论上 是有的,但 ③ 的结构性障壁 (低维选择 → RR 直接采样) 与 kernel 实现的质量无关。
- 这次 不需要 那条怀疑"③ 过于整齐地成立"的纪律 ── ③ 成立从一开始就没出现 (与 honest prior 一致的 negative)。
12. 元教训 —— 诚实,是为了取胜的工具
今天真正的成果不是数值,而是 "怀疑过于整齐的结果"这种精神,实际推动了研究前进。
- 因为物理性地消除了评估噪声 (EXP2),我们才能切分"平滑"到底是地形的性质还是仪器的极限。
- 因为用了 3 个敌对验证透镜,我们才没把"③ NOT null"做成 headline,而是把它留作"候选"。
- 因为我自己检出了 stale 值的混淆,我才能做出正确的降级到 N/A,并在今天重新测量。
- 在 BG9 (追记) 中又学到一点:低维的难处会被强 baseline 直接解掉。所以要让 ③ (挑选、培育的工夫) 起作用,需要"高维 behavior 空间"。 "做出欺骗地形 ③ 就立"只对了一半,精确地说,地形必须是 高维到无法直接采样的 欺骗地形,③ 才会立起来。在 kernel 4 选 (低维) 的情况下,RR 在 restart 时把它们全部直击,所以 ③ 的登场在原理上就没来。这正是把逃生路线说成不是"放弃"而是"结构性堵死"的依据。
"出现异常好的结果时,在飘飘然以为赢了之前,务必怀疑其内幕"── FullSense 的研究纪律 (feedback_benchmark_honest_disclosure),不是单纯的自我警诫,而是作为 实际抓住假阳性、提高研究精度的机制 在运转。BG9 是同一纪律在相反方向 (把 negative 正确地确定为 negative) 上奏效的例子 ── 在 red-team 里试图反证自己的"③ 立不起来",结果反证不了,反而作为结构得到了确证。
最后,再把结论精确地说一遍 (反映 BG9 的定论):
在 proxy substrate 上,"③ 因地形真正平滑而不需要"被 noise-free 地确定 (Step D)。只有在真实 multitask 邻域 (C-gen4b) 出现了"③ NOT null"的微弱迹象,但因小效果 + 漂移 + 多重比较,它 止步于候选。 K4 clip 从主动 suppression 降级为诊断性所见。而最后的 CPU 逃生路线 kernel 多样化 (BG9) 在结构上被堵死 ── kernel 选择是低维,所以强 baseline (RR) 直接采样,③ 的 niching 优势在原理上无法出现。验证 ③ 主战场剩下的路,只有高维的 GPU full-LLM 损失地形 (这本身也是一场带有"强 baseline 直接解出"风险的赌注)。
"③ 定论 = ③ 被查明不需要"是错的。正确地说,"③ 只有在'高维的'欺骗地形上才发挥作用。这次在 CPU 上能测到的、接近真实的东西 (平滑) 和 kernel 多样化 (低维),都不满足这个条件。" 主战场 (高维 GPU) 还在前方,而且是一场没有保证的赌注。
Tags: 进化计算 / MAP-Elites / 统计检验 / 检出力 / honest disclosure / CPU 研究
相关: 连载 #32 (llcore CPU PoC battery) / #29 (反证・Goodhart・proxy 局限) / #31 (Codex 二本柱)
Project: llcore (PyPI 预留 llmesh-llcore,因仓库未公开为本地研究)
第10章 (连载 #34) 六连战爬山实验弄清了「进化的③何时起作用」——而且 100 年前的进化生物学早已给出同样的答案
📖 一句话概括
上一章(#33)是这场决断的"最终局面",而本章则把围绕同一个问题"③ 到底要不要?"的 6 段实验,当作一个完整的故事来俯瞰。先用"若是欺骗地形,③ 会完胜"作存在证明,接着拿 4 块更接近真实问题的地形去测,结果无一例外都是"③ 不需要的地形"——本章便是追溯这条弧线。抵达的核心是:"③ 只有在难点位于高维、无法直接抵达时才起作用。"而更令人惊讶的是,这条边界条件,近 100 年前进化生物学的那场论争(赖特 对 费希尔)早已以同样的形状描绘过了——本章一直深入到这层接地。不过我们也谨慎地划清界线:生物学并不"证明"计算结果,只是"作为比喻来接地"而已。
TL;DR
- 问题是 「用进化去搜索 AI 的核心计算时,『分门别类、隔离培育的工夫』(= 进化的③:适者生存/分离) 到底需不需要」。连载 #33 写了终局 (Step D + BG9);而本篇 #34 把整段 arc (6 段) 当作一个故事来俯瞰。
- 第 1 段 (合成欺骗地形):③ 大获全胜 (Cliff δ=+1.0)。③ 作为机制是真货 = 存在证明。
- 第 2 段 (记忆任务 / 多 reservoir):被基质的「地板」与「天花板」所阻,无法测量③ = N/A。
- 第 3 段 (多任务泛化):③ 能赢「无选择」,但赢不了简单选择或 random = ③ 不需要 (honest negative)。
- 第 4 段 (对真实 proxy 地形做 noise-free 测量):把评估噪声物理性地降到零之后,地形 确实是光滑的 (单峰) = ③不需要被确证。「过去的 negative 不是检定力不足,而是地形本来就光滑」第一次得到佐证。
- 第 5 段 (混合 4 种部件的旁门左道 BG9):kernel 选择是 低维,因而强 baseline (随机重启爬山) 直接采样,③ 的 niching 优势 在结构上不出现 = 旁门左道被堵死。
- 结构性洞见 (本 arc 的核心):③ 起作用,只有当难点位于 高维 behavior 空间、无法直接采样时才行。真实 CPU 基质是低维/光滑的,所以③不需要。
- 生物学接地 (已验证):这恰恰就是赖特 (Wright) 的 转移平衡说。对 黑化型蛾 (单基因 = 低维),普通的选择就足够 (= BG9 的 kernel 情形);对 伦斯基的 Cit+ (高维、依赖历史),多样性才起作用 (= ③ regime)。我们的 negative 就是 科因批判的计算版 (现实地形简单、③ 极少起决定性作用)。
- 元教训:「太顺利的结果不是胜利,而是警报」。预先登记、honest disclosure、对抗式验证、确定性的 noise-free 测量,使我们避免了空欢喜。
⚠ 本文中的所有数值,都是与手头 (本地) 研究记录绑定的实测值。llcore 还没有建公开仓库,所以无法贴出外部链接。作为替代,我在正文里写了「是怎么测的」。生物学部分引用的论文,只列出那些已单独对照一次信息源、核实过其存在、归属与主张内容的。

🗒️ "装傻也挺累的呢…!" — 把 100 年份讲完之后的脱力(© Forbidden shibukawa / SHUEISHA・《零食吧 Basue》)
0. 这篇文章在讲什么 (概念)
llcore 是一个 CPU 完整的研究框架,它「把 Transformer 的核心计算 (状态更新规则、学习规则、认知驱动 Δ) 当作基因,一边用 Z3 验证它不会坏掉,一边进化」。
它的进化引擎有一个设计上的要害:在进化的 4 要素 (① 变异 / ② 遗传 / ③ 适者生存・分离 / ④ 过剩繁殖) 之中,③ (selection / separation) 该如何发挥作用?这是像 MAP-Elites 那样、保持多样性并留在生态位里的「分门别类、隔离培育」机制。
问题很简单。
那个③,真的需要吗?
如果需要,那么为承载③而做的重投资 (最终是在 GPU 上跑真 LLM) 就有意义。如果不需要,那么执着于③就是浪费时间与电费。
连载 #33 详细写了那个问题的 终局 (Step D 的确定性测量 + BG9 的结构性了结)。但在抵达那里之前,有 6 段实验,反复地赢 (存在证明)、测不出来 (N/A)、输 (honest negative)。本篇 #34 把 整段 arc 重新排成一个故事。而且作为本次的看点,我们用已验证的一次信息源 接地:这个计算结果与近 100 年前进化生物学的论争 (赖特 vs 费希尔) 在形状上惊人地相同。
— 到这里 40 秒。热身完毕。进入正题。 —
1. 比喻:爬山、欺骗地形,与记忆宫殿
在公式之前,我们用本研究始终使用的 3 个比喻来把握全貌。
我们用 地形的高度 来表示设计的好坏。高的地方 = 好的设计。这是一场寻找最高峰的游戏。
地形其一:光滑的单座山 (简单)
在这样的地形里,朴素的「爬山法 (hill-climbing)」,也就是「只往比现在稍好一点的方向移动」,就足以登顶。花哨的工夫 (③) 不需要。
地形其二:欺骗地形 (deceptive)
这里,朴素的爬山会停在假峰,因为它没有下到谷里的勇气。
这时起作用的就是③的想法。把各种各样的登山者散布留在谷的各处 (= 记忆宫殿 / MAP-Elites archive)。某个人能用「踏脚石 (stepping-stone)」渡过山谷、抵达真正的山顶——这就是机制。
用一句话概括本研究的核心:③ 真正有用,只在「欺骗地形」时。在光滑的单座山上,③ 是无用的大白象。
所以问题可以改写成这样。
「用进化来设计 AI 时,你实际遇到的地形是『欺骗地形』,还是『光滑的单座山』?」
#33 中我们用 Step D + BG9 给这个问题作了了结。本篇 #34 展示通往那里的 全部 6 段爬山。有趣之处在于,每一段「是不是欺骗地形 / 是不是光滑 / 能不能测量」都会变化。
— 小憩。准备到此为止。从这里开始是六连战的实录。 —
2. 整段 arc 地图——一览 6 段爬山
先把地图拿出来。这是本文的脊梁。
| 段 | 基质 (测的是什么地形) | ③ 起作用了吗 | 一句话 |
|---|---|---|---|
| I (Step 4) | 合成的「欺骗地形」(欺骗 corridor) | Yes (完胜) | 存在证明。③ 是真货 |
| II (Step C / 梯子1) | 记忆任务 / 多 reservoir 奇偶 | N/A | 被地板、天花板、degree-5 之墙挡住,测不出来 |
| III (E-A) | 多任务泛化 | No | ③ 能赢「无选择」,仅此而已 |
| IV (Step D) | 真实 proxy 的文本地形 (确定性测量) | No | 确证地形 确实光滑 (noise-free) |
| V (BG9) | 部件 (kernel) 4 种的并集 | No | 在结构上被堵死 (低维选择) |
故事线是这样的。首先证明存在——「③ 在条件合适时确实大获全胜,是真货」(I);接着,为了问「那么在真实问题里如何」,跨 4 段去测量 (II–V),结果每一次都是「真实 CPU 基质是不需要③的地形」。而且在最后 (IV, V),确认了「不需要的理由」是 地形的性质,而非检定力不足——这就是整段 arc 的弧。
那么,一段一段来。
3. 第 I 段 (Step 4)——存在证明:若是欺骗地形,③ 会完胜
最先做的,是「按理论该起作用的场面是否真实存在」的存在证明。我们 故意把地形做成欺骗式,让③ (MAP-Elites) 与 3 个 baseline——pure random / panmictic GA / 随机重启爬山 (random-restart hill-climbing)——对决。
地形的构造:基因是 24 维。把 behavior (登山者的类型) 定义为 mean(基因) = 24 个数的平均。要提高 behavior,就得 同时把全部 24 维抬高。fitness 恰恰是欺骗地形:「behavior≈0.4 处有假峰 (值 0.6) → behavior≈0.65 处有谷 (值≈0) → behavior≈0.9 处有真峰 (值 1.0)」。
结果:
| 方法 | 抵达真峰的比率 | 与 ③ 的比较 |
|---|---|---|
| MAP-Elites (③) | 约 95% | — |
| pure random | 0% | p=1.9e-6, Cliff δ=+1.00 |
| panmictic GA | 0% | 同上 |
| 随机重启爬山 | 0% | 同上 |
只有③抵达了真峰,3 个 baseline 全都停在假峰 (≈0.60)。100% 胜 / 效应量为理论最大 (δ=+1.0)。在 3 种 base seed (共 60 seed) 上稳健。
为什么会这样,会成为后文的伏笔。
- random 的 behavior 必然集中在 ≈0.5 (24 个数的平均被中心极限定理锁在 0.5)。所以它 永远到不了 behavior 0.9 (抽 6000 个样本也是 0%)。
- 爬山 爬到假峰 0.6,拒绝下到谷里那一手。即便重启也回到 behavior≈0.5,落入同样的陷阱。
- ③ (MAP-Elites) 把谷的格子当作「新的 behavioral 生态位」保留,用踏脚石把 behavior 从 0.5 渡到 0.9。
边界我们也诚实地测了。在去掉谷的光滑 corridor 上,③ 已赢不了爬山 (p≈0.29)。③ 不是万能的,它只在欺骗地形里起作用。
honest 保留:这是 故意做出来的 合成地形。它只证明了③「可能」,并没有证明真实任务具备这种结构。toy 规模、低噪声、baseline 是朴素的 (1+1)。
→ 这里立起一个假设:「如果真实问题的地形也这么欺骗,③ 应该能活起来」。接下来的 4 段,就是在更接近真实问题的基质上去验证它的旅程。
— 歇一会儿。第 I 段是令人舒畅的完胜。从这里风云突变…… —
4. 第 II 段 (Step C / 梯子1)——被基质的「地板」与「天花板」所阻 (N/A)
接着我们调查「欺骗 corridor 会不会 在标准的记忆任务里自然出现」(Step C)。用 1 个 leaky reservoir + ridge readout 跑 delayed parity / flip-flop / delayed recall。
结果是干净的 N/A (不可测)。原因有趣在于两个极端。
- delayed parity = 地板 (floor):单个 reservoir 算不出 XOR (Minsky-Papert)。所有方法都是 R²≈0.003。谁都登不上去,所以无法分离③。
- flip_flop = 天花板 (ceiling):所有方法都饱和在 R²≈0.95。方差被压垮,③ 的差异显不出来 (③ vs random 符号为正但 p=0.15 = underpower,因此 并非 null)。
这里有一个重要发现。基因空间的多峰性很高 (parity 的 valley fraction 是 1.000),却对③毫无用处。也就是说,「在基因空间多峰」≠「需要跨越的 behavior 欺骗地形」。这个区别成为 arc 后半的钥匙。
梯子1 (多 reservoir):那么,把多个 reservoir 串起来,地板会不会抬高?→ 试了 5 种机制全是 floor_lifted = false。深度 (DeepESN) 在统计上抬高了地板 (效应 +0.47/+0.60, PASS),但绝对值止步于 R² 0.05-0.10。决定性的是 positive control:degree-2 readout 严格解出 2-bit XOR (R²=+1.0),但 degree≥3 即崩溃。5-bit 奇偶是 degree-5 = 这个 CPU reservoir+ridge 范式的结构性之墙。
→ 奇偶之路在结构上被堵死。③ 的正式检定需要 从奇偶上下来。
honest 保留:degree-5 之墙是「这个设置的墙」,不是对整个范式的不可能性证明。
— 小憩。「测不出来」的结果虽朴素,但在画地图时是重要的空白地带。 —
5. 第 III 段 (E-A)——多任务泛化:③ 不需要 (honest negative)
从奇偶的地板下来,我们用 泛化 (generalization) 来测③,组了一个最干净的 ablation。
设置:单层 leaky reservoir + ridge。可变延迟的 recall。用短延迟 {15, 30} 训练,用长延迟 {45, 60} 测试 (外推)。比较的是 MAP-Elites (①②③全) vs 抽掉选择的 MAP-Elites (randselect:随机选父代、无条件放置 = 只有变异) + panmictic GA + random。
结果 (同行评审后):
| 方法 | 测试泛化 R² (平均±std) |
|---|---|
| MAP-E (①②③全) | 0.682 ± 0.115 |
| MAP-E randselect (抽掉选择) | 0.557 ± 0.108 |
| panmictic GA | 0.702 ± 0.083 |
| random | 0.620 ± 0.105 |
| 门 | 比较 | diff | p (单侧) | 判定 |
|---|---|---|---|---|
| C-gen3 | MAP-E > randselect | +0.126 | 0.0151 | PASS |
| C-gen4a | MAP-E > panmictic | −0.019 | 0.598 | FAIL |
| C-gen4b | MAP-E > random | +0.062 | 0.126 | FAIL |
读法:③ 赢了「抽掉选择的漂移对照」(C-gen3 PASS = "某种选择胜过无选择")。但 赢不了 panmictic GA (有选择但无 niching) (甚至略输),也赢不了 random。也就是说,niching 特有 (= ③ 本来) 的贡献为零。这个泛化地形足够 光滑,以至于简单选择或 random 也能到同一个地方。这与第 I 段的边界「光滑则③不起作用」一致。
honest 保留 (重要):这个 verdict 仅限于这个设置 (预算 400, grid 6×6)。此外——这里是 honest methodology 的要害——同行评审 (Codex) 起初判定「不可信」,强制了 3 个 rerun blocker (每个 replicate 独立 seeding / 采用预算内的全局最优 / 把 honest_n 从 16→30)。修正之后结论仍未改变。 收获是:它不是「一改就翻的脆弱 negative」。
— 歇一会儿。输就是输,但确认我们「正确地输了」的工作更花时间。 —
6. 第 IV 段 (Step D)——真实 proxy 地形被确证为「确实光滑」(noise-free)
这里是 arc 的转折点。直到第 III 段,「③ negative」一直在持续,但始终有一个 疙瘩 残留着。
「③不需要」真的是因为 地形光滑 吗?还是仅仅 样本数不够、检测不出差异 (underpower) 呢?
弄错这一点,就会过度泛化为「③ 无力」。Step D 在这里作了了结。
诀窍:ESN reservoir (固定 seed) + ridge readout 的闭式解 (np.linalg.solve) 完全不抽随机数。所以可以把评估噪声物理性地降到 机器 epsilon (约 1.11e-16)。实测确认了 eval_noise_std ≤ 1.11e-16——这源自浮点的最小单位 (ULP),实质为零。把噪声之雾完全拨开,就能直接测量地形的谷。
地形是 llcore 自身源码 (约 24k 字符) 的下一字符预测。我们测了 valley_fraction (谷的比例;≥0.2 即多峰 = 欺骗地形)。
| 地形 | 维数 | valley_fraction (mean/max) | 多峰? | 判定 |
|---|---|---|---|---|
| ESN 3-param (真实 proxy) | 3 | 0.000 / 0.000 | No (3 seed 一致) | 光滑 → noise-free 确证③不需要 |
| ESN per-neuron (真实 proxy) | 40 | 0.096 / 0.121 | No (3 seed 一致) | 偏光滑 → ③ 不需要 |
| 多峰 control (正) | 3 / 40 | 0.70 / 0.80 | Yes | 诊断器能检出多峰 ✓ |
| 二次函数 control (负) | 3 / 40 | 0.000 | No | 诊断器能检出光滑 ✓ |
要点有 2 个。
- 真实 proxy 地形 (3 维 / 40 维均如此) 是单峰。3 个 seed 一致。
- 诊断器本身是健全的。故意做的多峰被正确检出为多峰,二次函数被正确检出为光滑。所以「真实 proxy 是单峰」不是仪器的 bug,而是 地形的性质。
→ 这才第一次在真实 substrate 上 noise-free 地佐证了 「过去的③ negative 不是 underpower,而是地形确实光滑」。再测也不会出现多峰。
honest 保留 (重要):「光滑」只在阈值附近才精确。ESN 3-param 的 midpoint 有 90.9% 略微向下 dip,最大相对 dip (0.0435) 就在谷阈值 0.05 的正下方。准确说,它不是「真正单峰」,而是「带有略低于阈值的浅谷 (~2-4%) 的弱 multi-basin」。方向得以维持,但因贴近阈值,稳健性有限——不把它圆成「完美的凸碗」,是本次的纪律。
— 深呼吸。到这里「仿真之物是光滑的」已确证。剩下的是「最后的 CPU 旁门左道」。 —
7. 第 V 段 (BG9)——混合部件的旁门左道,在结构上是堵死的
既然真实 proxy 已确证为光滑,在光滑地形里追③就不会出利得。但 GPU 是投资判断,所以我们试了 能在 CPU 上前进的另一个假设。那就是 kernel 多样化 (BG9)。
假设 (预先登记 H7):即便单个 kernel (rwkv / mamba / hopfield / linear_attn) 各自光滑,把 4 种并集起来,在 kernel 切换的瞬间 fitness 会形成台阶 → multi-basin (欺骗地形) → ③ 不靠 GPU 就在 CPU 上立得住。预先登记的 honest prior 偏 null (因为迄今所有 CPU 基质都光滑)。
结果分 3 段。
(1) substrate validity——有辨别但很弱 (PASS 但需注意):测量每个任务的拿手 kernel 是否不同,映射是非常数 = non-inert (PASS)。mamba 在 selective-copy、linear_attn 在 weighted-accumulation 上最佳。不过 hopfield 在任何任务上都赢不了 (对角标量 mock 下功能失常),所以实质是「3 kernel 并集」。辨别的存在 ≠ 多峰障壁。
(2) harness validity——positive control 无法 validate (决定性):在合成 kernel-barrier 上,把③与 3 baseline 比较。
| 基质 | 结果 |
|---|---|
| positive control | ③ 击溃 panmictic (+0.423)、random (+0.208)。但赢不了 RR (随机重启爬山) (+0.051, p=0.31 → FAIL)。未能全胜 3 baseline = harness 立不住 |
| negative control | 全部 method 饱和,③ 无优势 = 正确地 null (仪器健全) |
| real smoke | ③ beaten 0/3,panmictic 反而超过③ |
第 I 段的 corridor 里③能把 RR 排除出去,为什么在 kernel 空间做不到? 根因只有一个。
RR 在每次 restart 都能直接采样 kernel_id ∈ [0,4)。 kernel 选择是 4 个离散值上的单一坐标 (低维),所以 RR 在 restart 时直接命中全部 4 个 kernel。「找最佳 kernel」无需跨谷 = 直接传送。所以③的 behavioral niching 没有出场机会。
第 I 段③能排除 RR,是因为那里的 behavior 是 mean(24 维),平均集中在 0.5 → 全局峰在 measure-zero 区域 = 高维、无法直接采样。而 kernel_id 相反,是低维、可直接采样。
(3) red-team——对抗式验证也无法反证,反而确证:在 positive control 上,instrumented RR 把 restart kernel 在 4 个 basin 上近乎均匀分散为 [12,18,16,18],target 抵达率 88%。在全部 4 种 faithful 构成 (高维 theta corridor / sequential-kernel / in-basin L1 corridor / deceptive multi-basin) 中,③ 都赢不了 RR。把 corridor 收紧,③ 先饿死 (starve) (D=3:③ reach 0.08 vs RR 0.42)。我们定量确证了 「能把 RR 单独排除、又让③通过的 behavior 维度,在 kernel 空间里结构上不存在」。
verdict:形式上是 N/A (positive control 无法 validate),但实质是 决定性的结构性 negative。harness 是健全的 (它正确地把 negative control 置 null,并检测出 GA/random),然而基质 根本无法承载③的欺骗地形。对第 I 段遗留的问题「用 kernel 多样化扩展搜索空间,③ 会 unlock 吗?」的回答是 NO (在 CPU 上,结构性地)。
honest 保留 (重要):这 不是「③不需要被判明」。它是「③ 在低维 kernel 空间里原理上无法与强 baseline 分离」= 有信息量的 N/A。③ 的机制本身在第 I 段已确证为真货。substrate 很弱 (实质 3 kernel;hopfield 是对角 mock)。更强的 kernel 实现在理论上有得出不同结论的余地,但 结构性障壁 (低维选择 → RR 直接采样) 与 kernel 实现的质量无关。
8. 结构性洞见——用一个条件统合 6 段
存在证明 (I) 与 4 个 negative (II–V),全都在仅仅一个条件下连成一体。
③ (behavioral niching) 超越强 baseline,只在「难点」位于高维 behavior 空间、无法用直接采样 (随机重启) 抵达时。
-
第 I 段满足的理由:behavior =
mean(24 维)。平均被中心极限定理集中在 0.5,全局峰 (mean≈0.9) 实质 measure-zero。random 和 restart 都 够不着。所以留下踏脚石、做 ratchet 的③是必需的。 - 真实 CPU 基质不满足的理由:难点是低维。ESN 文本 proxy 的控制坐标实质是 leak rate (光滑的低维旋钮;本就没有谷)。kernel union 的难点是「哪个 kernel」= 4 选 1 的单一离散。RR 直接采样、传送到全部 basin,所以没有需要跨的谷。
所以第 II 段的「基因空间多峰性 1.000」不是充分条件——即便基因满是谷,只要难点集中在低维 behavior 坐标上,restart 就能直接抵达。起作用的是「探索需抵达的 behavior 的维数」,而不是基因的维数。
9. 生物学接地——100 年前的进化生物学早已给出同样的答案
从这里开始是 #34 的看点。「保持多样性的选择,只在狭窄条件下起作用,其余时候是冗余的」——这个边界条件,在 20 世纪的进化生物学里有一个异常干净的先例。
⚠ honesty 契约:以下生物学是 「比喻 (structural analogy)」,而不是我们计算结果的证明。对应是结构性的,在机制层面并不一致。比喻偏离之处,我都当场注明。引用的论文,只列出已单独对照一次信息源、核实过存在、归属与主张内容的。
9.1 赖特 (Wright) 的转移平衡说 = ③ 的先例
休厄尔・赖特 (Sewall Wright, 1931/1932) 这样思考。若维持为一个大「群 (panmictic population)」,普通的自然选择会 被眼前的局部峰困住。要去更高的山,必须先 降低 mean fitness、跨过山谷,而确定性的选择拒绝这样做。
赖特的解法是 把群分成众多半隔离的亚群 (deme)。
- Phase I:小 deme 凭 遗传漂变 (drift) 偶然下谷、渡过去。
- Phase II:在那里,deme 内的普通选择登上新的 (更高的) 峰。
- Phase III:登上高峰的 deme 派出许多迁移者,优良的基因组合扩散到整个物种。
作为 整个 元群体,它跨越了单一收敛群体无法跨越的谷——这是「用踏脚石渡过欺骗地形的谷」的生物学版。
对应到③ / MAP-Elites (= 比喻,非归属):archive 的每个 cell = 半隔离 deme,cell 内的局部 elitism = deme 内选择 (Phase II),cell 间变异 = interdeme 扩散 (Phase III),而 archive 整体 (≒ 元群体,非单一 cell) 跨越山谷。
honesty 注意 (2 点):
- 这是解说者的框架,既非赖特的主张,也非 MAP-Elites 的出处。 MAP-Elites 原论文 (Mouret & Clune 2015) 与 QD 文献 都没有引用赖特或「转移平衡」。赖特是作为我们的 灵感 / 比喻 提出的,而非 MAP-Elites 的谱系。
- 机制只是结构相似,并不相同。 MAP-Elites 的渡谷是 变异算子 把子代放进新 cell 而发生的,不是遗传漂变。archive 也不是复制 cell 的群体。
9.2 赖特 vs 费希尔 = 维数 (地形的形状) 之轴
与赖特同时代的费希尔 (R. A. Fisher, 1930) 主张相反:大的 panmictic 群体 + 对加性方差的群体选择就足够 让适应推进,根本无需特意分割。
二人 最深的对立轴,其实是「上位性 (基因间相互作用) 与地形的形状」。赖特假设「因非加性相互作用,地形 崎岖多峰,所以需要跨谷的 drift」,费希尔判断「相互作用存在但不重要,地形大致 单峰、可平滑攀登,所以群体选择就够」。
这个 epistasis/ruggedness 之轴,正是我们结果生存的维度。地形的形状 (topology) 才是全部问题。 若地形确实崎岖高维 (赖特 regime),多样性把你摆渡过谷;若光滑或难点低维 (费希尔 regime),群体选择——即强随机重启爬山的生物学版——就已足够。我们的 ESN 文本 proxy 是 noise-free 且光滑的,kernel union 的难点是低维离散。两者都是费希尔 regime,③ 不起作用、也没起作用。
细节注意 (诚实地):「费希尔忽视了 drift」是被压缩的俗说。准确说是「他承认 drift 存在,但判断在大群体里其量可忽略」。不是全盘否定。
9.3 我们的 negative = 科因批判的计算版
最切中的对应,不是赖特的 提议,而是生物学界的 经验判定。Coyne, Barton & Turelli (1997, Evolution 51(3):643–671) 从理论与实证两面评估了转移平衡说,并如此结论 (全文已对照)。
- 群体选择通常就够了。 「几乎没有用赖特三段机制比用简单群体选择解释得更好的实例。」人为选择实验也没能证明「分割群体的选择比大群体的群体选择产生更大的响应」。
- 转移平衡起作用,只在有限、稀少的条件下。 群体结构的经验估计表明「drift 只能在被浅谷隔开的峰之间引起迁移」(深谷靠 drift 极少能渡过),而且 大多数适应不需要跨谷。
这是我们结果的 惊人精确的生物学版。把他们的话翻译成我们的词汇就是——若地形并非真正欺骗/高维,普通的群体选择 (≒ 强随机重启爬山) 就已经能解,多样性维持装置几乎什么都买不到。「现实的谷通常浅、大多数适应不需跨谷」就是我们「实际地形通常简单,所以 niching 是冗余的」的生物学陈述。
honesty 注意 (3 点):
- 他们没有「反证」转移平衡。 他们明言 Phase I/II 可能发生,并举出 6 个经验事例。主张是 更狭窄的、概率性的 (「难以称之为一般而重要的机制」),写「refuted」就过头了。
- 论争尚未了结。 Wade & Goodnight (1998)、Peck et al. (1998,标题字面就主张「feasible」) 提出反驳,接着是 Coyne 等人 2000 年的再反驳、Goodnight & Wade 在同期的反驳。不可把 1997 批判当作「最终结论」来引用。
- 生物拥有计算侧无对应物的机制,而且做出比我们更强的主张。 在 Phase III,保护多样性的 gene-flow 障壁可能 把好解困在周边 deme、妨碍其扩散 = niching 可能 适得其反。我们 stateless 的离散选择设置没有这个 cost 的对应物,所以这里 不过度叠加。这是生物做出更强主张的地方。
9.4 两个实例——低维的蛾,与高维的大肠杆菌
我们的主张有两个极 (低维 = ③不需要 / 高维 = ③ 可能起作用),而进化生物学对每个都有干净的实例。
低维之极——桦尺蛾的工业黑化 (= BG9 kernel 情形):Biston betularia 的 carbonaria (黑) vs typica (白) 受 单一孟德尔座位、少数等位基因 支配 (致因变异是向 cortex 基因的转座因子插入;van't Hof et al. 2011/2016),并受 强方向性选择 (s ≈ 0.1-0.2;Saccheri et al. 2008;捕食在 Cook, Grant, Saccheri & Mallet 2012 中再确认)。最优在每个时点都是单峰,只随环境平移。简单的方向性选择——贪婪爬山/随机重启的生物学版——直接固定更适应的型,多样性维持机制既不需要也未被调用。 这恰恰就是 BG9:kernel 选择是 4 选 1 的低维单一座位,RR 直接采样全部 kernel,③ 在结构上无法分离。黑化型 = BG9 kernel 情形的生物版。
注意 (诚实地):过渡期会暂时保持多型,但那是由于 空间环境异质 + 基因流动 (迁移-选择平衡),而非内在的多样性保存机制。比喻略微偏离之处。
高维、依赖历史之极——伦斯基的 Cit+ (= ③ regime):在大肠杆菌长期进化实验 (LTEE) 中,需氧柠檬酸利用 (Cit+) 在 12 个群体中恰好 1 个 里于约第 31,500 代进化出来 (Blount, Borland & Lenski 2008)。关键是一条高维、依赖历史的路径,即有序的 potentiation (前驱变异的积累) → actualization (citT 串联重复带来的启动子捕获) → refinement (Blount et al. 2012)。重放实验把「历史偶然性」从「恒定率的稀有变异」中区分开来。这 真正例示 了探索 contingency、上位性与高维崎岖地形的价值——是③可能起作用之 regime 的实例。
honesty 注意 (这只对应我们条件句的「前件」):
- LTEE 不使用 niching 算法。 它就是普通的自然选择,12 个并行群体 本身就是随机重启式的设计。所以它是「contingency + 多样性使稀有创新成为可能」的存在证明,不是「niching 胜过强 restart baseline」的证据。
- 「大肠杆菌从零获得吃柠檬酸的能力」是俗说的夸张。创新是 调控 (既有转运体的需氧表达) = exaptation,既非新基因也非新生化。
- Van Hofwegen et al. (2016) 指出「若直接选择,Cit+ 出现得快得多」,挑战了「稀有/偶然」框架 (伦斯基一侧反驳说这与 LTEE 条件下的 potentiation 并不矛盾)。若要依赖「极稀有/长期延迟」叙事,就应一并注明这个 有争议的追试。
9.5 接地小结
| 极 | 生物学 | 地形 | ③ 起作用? | 我们的基质 |
|---|---|---|---|---|
| 低维/光滑 | 黑化型 (单座位, s≈0.1-0.2, 方向性) | 单峰・平移 | No — 群体选择足够 | BG9 kernel union;ESN/ridge 文本 proxy (确定性・光滑) |
| 高维/偶然 | 伦斯基 Cit+ (potentiation→actualization→refinement) | 崎岖・靠变异越谷 | Yes (可能起作用的 regime) | 合成欺骗 corridor (behavior = 24 维的平均) |
| 经验判定 | 科因・巴顿・图雷利:群体选择通常足够,转移平衡极少起决定性作用 | 实际地形通常简单 | 我们 negative 的镜像 | 试过的全部 CPU 基质 |
结论:赖特的转移平衡是「③起作用时为何起作用」的正确生物学先例,赖特-费希尔的 epistasis/ruggedness 之轴是「维数条件」的正确框架,黑化蛾与伦斯基 Cit+ 是低维/高维的干净两极,科因批判是我们 negative 的生物学先例。但这些都不能证明计算结果。它们只是接地。 比喻松动最大之处,在于生物加了一个 cost (Phase III 的 gene-flow trap)——我们 stateless 的设置没有它。
— 歇一会儿。当我意识到 100 年前的论争有同样的形状时,老实说我起了一身鸡皮疙瘩。但不把「起鸡皮疙瘩」误认作「证明」,正是本次的纪律。 —
10. 对 GPU 的含意——剩下的路只有高维,但依旧是赌
arc 把 CPU 的路全部堵死了。真实 proxy 是 noise-free 且光滑 (IV),最后的候选 (kernel 多样化) 在结构上被堵死 (V)。③ 剩下的路只有 高维地形——而提供它的,是 full-LLM 的参数/损失空间 (数百万维)。
结构性洞见让 GPU 这场赌 better-motivated。它不是「也许只有 full-LLM 是例外」这种盲目的赌,而是遵循原理「③ 需要高维,而 full-LLM 正处于高维域」的赌。
但依旧是赌。 出于与生物学的 Cit+ 不能证明「③ 算法的胜利」相同的理由,以及与 BG9 里赢不了 RR 同型的理由——若真实 LLM 地形能用 backprop (梯度下降) 这个强 baseline 直接导航,③ 仍然不需要。难点是高维,这是 必要条件而非充分条件。还需额外证明「强力的直接法解不了它」(CPU 上是 RR,GPU 上是梯度下降)。
所以 GPU 适合的 不是「单为③」,而是 组合 (portfolio) 判断 (与 llive 的真 LLM fitness 等搭车) + 借云做 1 次预先登记 (在投入资本之前)。go/no-go 标准也能写成 falsifiable:
full-LLM 的难点在 behavior 上是否高维,且是否难以被强力的直接 baseline (梯度下降) 抵达? 若高维但梯度能直接够到,③ 不需要 (= BG9 的 RR 结果的 GPU 版)。
11. 元教训——诚实,是用来赢的工具
这段 arc 真正的成果不是数值,而是 「怀疑过于工整的结果」这种精神,实际上把研究往前推进了。
- 在 存在证明 (I) 中赢的时候,我们用去掉谷的边界实验,主动确认了「③不是万能」(不高估胜利)。
- 在 泛化 (III) 中,同行评审甩出 3 个 rerun blocker,但修正后结论没变 (确认它不是脆弱的 negative)。
- 在 确定性测量 (IV) 中,因为物理性地抹掉了评估噪声,我们才能区分「光滑」是地形的性质还是仪器的极限。
- 在 BG9 (V) 中,在对抗式验证里我们 试图反证、却无法反证 自己的「③立不住」,它被确证为结构性的 (同样的纪律也在「把 negative 正确地确定为 negative」的方向上起了作用)。
而贯穿整段 arc 我们学到一件事——低维的难点会被强 baseline 直接解掉。所以③ (分门别类、隔离培育的工夫) 要起作用,就需要「高维 behavior 空间」。「做出欺骗地形③就立得住」只对了一半;准确说,除非是 高维到无法直接采样 的欺骗地形,③ 才立得住。而且令人惊讶的是,这个边界条件是 赖特的转移平衡与科因批判在近 100 年前就已抵达 的。
「当出现异常好的结果时,在自以为赢之前,务必先怀疑其内訳」——FullSense 的研究纪律 (honest disclosure) 不仅是自我告诫,而是一个 实际捕捉假阳性、正确确定 negative、提升研究精度的机制,在全部 6 段中都在转动。
最后,把结论再精确地说一遍。
③ 活起来,只在「高维」的欺骗地形时。 它在存在证明 (合成 corridor) 中完胜,但真实 CPU 基质——记忆任务 (地板/天花板)、多任务泛化 (光滑)、真实 proxy 文本地形 (noise-free 且光滑)、kernel 多样化 (低维、结构上堵死)——没有一个满足那个条件。这 不是「③了结 = ③被判明不需要」,而是「现在能在 CPU 上测的仿真之物,没有满足③活起来的条件 (高维欺骗地形)」。主城 (GPU 高维) 还在前方,而且是一场背负着「强力直接 baseline 会解掉它」风险的赌。而且这个结论的骨架,20 世纪的进化生物学早已描绘过——只不过生物学 不证明它,只接地它。
Tags: 进化计算 / MAP-Elites / 统计检定 / honest disclosure / 进化生物学 / CPU 研究
关联: 连载 #33 (第三轴 ③ 了结 Step D + BG9) / #32 (llcore CPU PoC battery) / #29 (反证・Goodhart・proxy 极限)
Project: llcore (PyPI 预约 llmesh-llcore,因仓库未公开故为本地研究)
⚡ 本系列与 Claude Code 携手写成
文章中的实现、验证与可视化均与 Claude Code(Anthropic 的 AI 编程环境)一起完成。
Claude Code 提供 1 周免费试用。如果你喜欢并通过下方的推荐链接订阅付费方案,
作者将获得「继续开发的额度」,从而支持本系列持续更新。👉 免费试用 / 推荐链接 → https://claude.ai/referral/0sqPw8E_lw

🗒️ "真掉价" — 想靠推荐链接赚点零花钱的小算盘,连我自己都觉得有点掉价。(© Forbidden shibukawa / SHUEISHA・《零食吧 Basue》)