PostgreSQL入門
PostgreSQLの設計・構築・パフォーマンスチューニング周りでメモ。
インストール&初期セットアップ
1.yumレポジトリ構築&postgresqlインストール
yum install https://download.postgresql.org/pub/repos/yum/11/redhat/rhel-7-x86_64/pgdg-redhat-repo-latest.noarch.rpm
yum -y install postgresql11-server
## パッケージをインストールすると下記postgresユーザやpostgresグループが作成される。
[root@postgredb ~]# id postgres
uid=26(postgres) gid=26(postgres) groups=26(postgres)
2.データベースクラスタ構築
# データベースクラスタをデフォルトの/var/lib/pgsql/11/dataから変更する
cp -p /usr/lib/systemd/system/postgresql-11.service /etc/systemd/system/
sed -i 's:/var/lib/pgsql/11/data:/postgres/data:g' /etc/systemd/system/postgresql-11.service
systemctl daemon-reload
sed -i 's:/var/lib/pgsql/11/data:/postgres/data:g' /var/lib/pgsql/.bash_profile
echo 'export PATH=/usr/pgsql-11/bin:${PATH}' >> /var/lib/pgsql/.bash_profile
# 初期セットアップ(=データベースクラスタを所定の場所に作る)
PGSETUP_INITDB_OPTIONS="-E UTF8 --locale=C" /usr/pgsql-11/bin/postgresql-11-setup initdb
systemctl enable postgresql-11.service --now
3.デフォルトユーザでの疎通確認&パスワードの再設定
su - postgres
-bash-4.2$ psql -U postgres
psql (11.4)
Type "help" for help.
postgres=# \l
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
-----------+----------+----------+---------+-------+-----------------------
postgres | postgres | UTF8 | C | C |
template0 | postgres | UTF8 | C | C | =c/postgres +
| | | | | postgres=CTc/postgres
template1 | postgres | UTF8 | C | C | =c/postgres +
| | | | | postgres=CTc/postgres
(3 rows)
postgres=# \q
psql -c "alter user postgres with password 'P#ssw0rd'"
4.ユーザ&データベース作成
# DBユーザー [cent] を登録
createuser cent
# テストデータベース作成 (オーナーは上記ユーザー)
createdb testdb -O cent
# データベース接続
psql testdb -U cent
パラメータチューニング(postgresql.conf)
Oracleでは初期化パラメータというが、Postgreにも同様の設定パラメータがある。
postgresql.conf、またはpostgresql.confのinclude句で指定されたファイル内で永続管理するのが基本。
select name,setting,unit,context from pg_settings;
またパラメータによって下記のように設定反映のタイミングを分割して管理することも可能。
| タイミング | pg_settingsシステムビューにcontext値 | 説明 |
|---|---|---|
| SET文実行時 | userまたはsuperuser | 発行したセッション内で即時適用。SET LOCALの場合は発行したトランザクション内のみ。 |
| SIGHUPシグナル発行時 | sighup | PostgreSQLサーバプロセスがSIGHUPシグナルを受け取った時 |
| PostgreSQL起動時 | postmaster | PostgreSQL起動時のみ |
※PostgreSQLのSIGHUPまたは再起動コマンド(systemdではなく製品コマンド)
SIGHUP)
pg_ctl reload -D PD_DATAディレクトリ名
(再起動)
pg_ctl restart -D PD_DATAディレクトリ名
パラメータによっては動的変更可能、再起動しないと変更不可など様々な制約があるが、それをSQLで判別する方法は以下。
# 1.動的変更可能なパラメータ(SET文で同一セッション内での変更も可)
select name,setting,unit,context from pg_settings where context in ('user','superuser');
# 2.SIGHUPシグナル受信時に反映
select name,setting,unit,context from pg_settings where context='sighup';
# 3.Posgre再起動時のみ反映
select name,setting,unit,context from pg_settings where context='postmaster';
加えて、即時反映ではなく次回再起動時の反映となるが、psqlプロンプト上でALTER SYSTEM文による設定変更も可能である。ALTER SYSTEM文を発行すると、postgresql.auto.confに値が追記され、postgresql.confの内容を上書き反映する。この方法については、設定の誤りをALTER SYSTEM文発行時にチェックできる、リモートログインできるスーパーユーザによって
設定のリモートからの変更可能というメリットがある。
# パラメータの動的変更(superuserでないと実施不可能)
postgres=# alter system set shared_buffers="1024MB";
ALTER SYSTEM
-bash-4.2$ cat /postgres/data/postgresql.auto.conf
# Do not edit this file manually!
# It will be overwritten by the ALTER SYSTEM command.
shared_buffers = '1024MB'
# パラメータの詳細情報閲覧
select name,setting,unit from pg_settings;
各パラメータ値の検討/採用方針(postgresql.conf)
listen_addresses
ポートをbindするアドレス。
remote接続許可の場合はまたはアクセスを許可するIPアドレスを記載
例)listen_addresses=''
port
接続を受け待ちするポート番号
例)port=5432
max_connection
max_connectionsは名前そのもの、つまり、許されるクライアント接続の最大数を設定。
この値だが、PostgreSQL自体のバックグラウンドプロセスは値に含めない。
例)max_connection=300
shared_buffers
shared_buffers設定パラメータはPostgreSQLのデータキャッシュに割り当てられるメモリ量を決定する。
1GB以上のRAMを持つシステムであれば、shared_buffersの理想的な開始値はシステムメモリの1/4が推奨値。
またSHMMAXがこの値より少ない場合はPostgreSQL起動時にエラー
例)shared_buffers='1024MB'
effective_cache_size
カーネルや PostgeSQL の共有バッファなど PostgreSQL が使用するバッファ領域、ディスクキャッシュとして利用可能な大きさの推定値。この値はオプティマイザ が利用する。インデックスを使用するコスト推定値の要素となります。より高い値にすれば、よりインデックススキャンが使用されるようになり、より小さく設定すれ ば、シーケンシャルスキャンがより使用されるようになります。よりインデックススキャンを利用できるようにしたければ、OSメモリの50%以上75%以下が推奨。あくまでオプティマイザが、実行計画を判断する上での指標的位置づけなので設定しても特にメモリを占有するわけではない。
work_mem
内部並び替えとハッシュテーブル操作が使用するメモリーサイズを指定します。
ORDER BYによるソートやテーブルの結合、集約といった複雑な問い合わせを行う場合に使用される。
1処理あたりの値のため,1問い合わせの中で複数の該当処理をする場合は、この値×数倍のメモリが利用される。
基本的な考え方としてDB専用のサーバだとすれば、(OSメモリ-shared_buffers)/max_connection=work_memとするのが妥当なのではと考える。
メモリの占有は処理実行時なのでPostgreSQL起動中常時では無い。
例)work_mem='5MB'
maintenance_work_mem
VACUUM, CREATE INDEX, and ALTER TABLE ADD FOREIGN KEYといったメンテナンス系の処理で使われる最大メモリ量を指定。
デフォルト値だと少ないのであげておいた方がよい。経験上256MB程度が目安。
例)maintenance_work_mem='256MB'
wal_buffers
未だディスクに書き込まれていないWALデータに対して使用される共有メモリ容量。
デフォルトはshared_buffersの1/32と自動チューニングされるので数MB以下等にならない場合はデフォルトでよいのでは。
例)wal_buffers = 16MB
synchronous_commit
トランザクションのコミットがクライアントに"success"の表示を返す前に、WALレコードがディスク上に書き込まれるまで待つかどうかの指定をする。デフォルトかつ安全な設定はon。
offの場合、クライアントに成功を報告する時点とトランザクションが本当にサーバクラッシュに対して安全になるまでの間に遅延が発生する。
データベースのクラッシュにより最近コミットされたということになっているトランザクションの一部が失われる可能性があるが、offにすることで性能を加速することは可能なのでデータの一貫性よりも性能が大事な場合はoffにすべき。また、セッション単位でも指定できるので、性能要件がより重要なセッションのみに適用という手もある。
例)synchronous_commit='on'
random_page_cost
シーケンシャルアクセスのにかかる時間を基準1.0としたときの、ランダムアクセスがかかる時間の比率を表現。
ランダムアクセス=インデックススキャンなど。AWSのEBSのようなSSD等の高速なストレージの場合は十分にランダムアクセスも
高速のため1にすると、 index scan が選択されやすくなる効果が高まり性能向上に寄与する。
例) random_page_cost = 1
effective_io_concurrency
PostgreSQLが同時実行可能であると想定する同時ディスクI/O操作の数。
通常は1度に1ブロック(1回あたりのIO=1)ずつ取り出す処理を行うが、1より大きく設定すると、データを先読みして複数ブロックを同時に取得することが可能。
基本的にディスクドライブの数を指定するのが妥当。例えば、EBSを2つ組み合わせてストライピングする場合は2。
例) random_page_cost = 2
参考
https://wiki.postgresql.org/wiki/Tuning_Your_PostgreSQL_Server
データベース管理
データベース作成・削除の基本的なコマンドは下記。Oracleでいうインスタンス(RACではデータベース)が下記Postgresqlにデータベースに相当する。LC_COLLATEとLC_CTYPEはあとで変更不可能。AWSのRDSだと、LC_COLLATEとLC_CTYPEがデフォルトen_US.UTF-8で作成されるため、想定が異なる場合はあとで再作成が必要。
# データベース作成
CREATE DATABASE db01
OWNER = app
TEMPLATE = template0
ENCODING = 'UTF8'
LC_COLLATE = 'C'
LC_CTYPE = 'C';
# データベース削除
DROP DATABASE db01
# データベース覧
postgres=# \l
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
-----------+----------+----------+---------+-------+-----------------------
postgres | postgres | UTF8 | C | C |
template0 | postgres | UTF8 | C | C | =c/postgres +
| | | | | postgres=CTc/postgres
template1 | postgres | UTF8 | C | C | =c/postgres +
| | | | | postgres=CTc/postgres
testdb | pguser01 | UTF8 | C | C |
(4 rows)
ユーザーとロール、スキーマの管理
PostgreSQLに限らないが、一般的なDBMSに下記概念があるのでその説明。
ユーザー
データベースにログインして任意のクエリを発行する主体。また、特定のDBに属さずデータベースクラスタ全体として定義される。
ロール
権限を一括りにまとめた概念。ロールをユーザに付与することで、ユーザはロールにまとめられた権限を行使することができる。(権限をロールに付与せずユーザに直接付与することも可能)また、特定のDBに属さずデータベースクラスタ全体として定義される。
スキーマ
オブジェクトの所属を表す概念。スキーマ名.テーブル名のような形で特定のオブジェクトをさし示す。同一データベースに属するオブジェクトで同一のスキーマ名.オブジェクト名は存在できない。また、特定のDBに属する。
PostgreSQLにおけるイメージ的には以下。
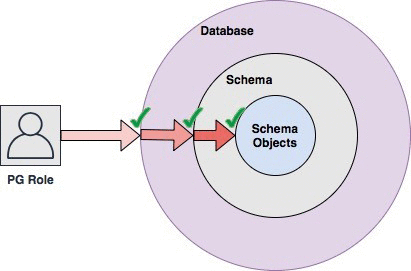
PostgreSQLで注意しておきたいことは、ユーザとロールがほぼ=と勘違いされやすいこと。Oracleでは明確に分かれていて、ロールでデータベースにログインすることはできないが、PostgreSQLではロールにLOGIN権限が付与されていればロールでログインすることが可能。そのため、自分も初めはロール=ユーザ?と思ったが明確には下記と考えた方が良さそう。

個人的には、ロールとユーザは明確に分けたいので、ロールにLOGIN権限を付与することはせずあくまで権限をロールで取りまとめ、それをユーザに付与するという設計をしたい。
# Postgresではロール=ユーザの概念?
--ユーザ作成(ROLEと出てくるのでミスリードしやすい)
testdb=> create user pguser01 with login password 'P#ssw0rd';
CREATE ROLE
--ロール作成
CREATE ROLE pguser01;
--ロール作成(パスワードも付与するとロールでログイン化の仕組み)
CREATE ROLE pguser01 with login password 'P#ssw0rd';
--ユーザへ権限付与
ALTER USER pguser01 SUPERUSER;
--ロールへ権限付与
ALTER ROLE pguser01 SUPERUSER;
--ユーザ削除
testdb=> drop user pguser01;
DROP ROLE
--ロール削除
drop role pguser01;
--現在のログインユーザ(ロール)確認
select current_user;
--ユーザ一覧(ロールも一緒に各レコードとして出てくるので混在)
postgres=# \du
List of roles
Role name | Attributes | Member of
-----------+------------------------------------------------------------+-----------
pguser01 | Superuser | {}
postgres | Superuser, Create role, Create DB, Replication, Bypass RLS | {}
※システム権限一覧(これらはロール経由で付与できない)
| 付与 | 剥奪 | 備考 |
|---|---|---|
| SUPERUSER | NOSUPERUER | スーパーユーザーの権限 |
| CREATEDB | NOCREATEDB | データベース作成の権限 |
| CREATEROLE | NOCREATEROLE | ロール作成の権限。CREATEROLE権限を持つロールは、スーパーユーザ以外のロールに対してその名前を変更できます |
| CREATEUSER | NOCREATEUSER | ユーザー作成の権限 |
| LOGIN | NOLOGIN | ログイン権限 |
| REPLICATION | NOREPLICATION | レプリケーションの作成権限 |
--スキーマ作成
postgres=# create schema XXX;
CREATE SCHEMA
--!!!スキーマを作成するにはコマンドを実行するロールがスーパーユーザーか、スキーマを作成するデータベースで CREATE 権限を持っている必要がある。
# スキーマ削除
postgres=# drop schema XXX;
DROP SCHEMA
# 現在のスキーマ確認
select current_schema;
# カレントスキーマ変更
SET search_path = XXX;
# スキーマ一覧
postgres=# \dn
List of schemas
Name | Owner
-------+----------
xwork | postgres
(1 row)
権限管理
基本的な権限関連コマンドとしては以下。付与と削除と確認。
大きく分けて、ロールの付与とオブジェクトへの権限の付与が存在する。
またロールの継承もできる。ロールの継承とは継承元のロールが持つ権限をそのまま継承先のロールに引き継ぐことである。
この継承によって与えた権限は上記の権限確認[¥z]場では表示されない。
--pguser01ロールの権限をpguser03ロールへと付与
grant pguser01 to pguser03;
--特定オブジェクトへの権限付与
--test01テーブルに対するselect,insert権限をpguser03ロールに付与
grant select,insert on test01 to pguser03;
--特定オブジェクトからの権限削除
### test01テーブルに対するdelete権限をpguser03ロールから削除
revoke delete on test01 from pguser03;
---権限確認
### test01テーブルに対するselect,insert権限がpguser03ロールに付与されている
¥z
アクセス権
スキーマ | 名前 | 型 | アクセス権 | 列のアクセス権限
----------+----------+----------+---------------------------+------------------
public | test1 | テーブル | pguser01=arwdDxt/pguser01+|
| | | pguser03=ar/pguser01 |
--特定オブジェクトへの全権限付与
### test01テーブルに対する全権限をpguser03ロールに付与
grant all on test01 to pguser03;
権限の見方
| 文字 | 説明 |
|---|---|
| a | INSERT可能(apend) |
| r | SELECT可能(read) |
| w | UPDATE可能(write) |
| d | DELETE可能(delete) |
| D | TRUNCATE |
| x | REFERENCES |
| t | TRIGGER |
| /yyyy | この権限を付与したロール |
また、特定スキーマやデータベースのオブジェクトを問答無用で全て操作したいこともあると思う。そんな時はこちらを実施
https://www.postgresql.jp/document/10/html/sql-grant.html
--xxxworkの全テーブルへの権限付与
GRANT ALL ON ALL TABLES IN SCHEMA xxxwork TO user02;
--xxxworkの全テーブルからの権限剥奪
REVOKE ALL ON ALL TABLES IN SCHEMA xxxwork TO user02;
--xxxworkスキーマへの全権限付与
GRANT ALL ON SCHEMA xxxwork TO user02;
--xxxworkスキーマからの全権限剥奪
REVOKE ALL ON SCHEMA xxxwork FROM user02;
--db01データベースへの全権限付与
GRANT ALL ON DATABSE db01 TO user02;
--db01データベースからの全権限剥奪
REVOKE ALL ON DATABSE db01 FROM user02;
ログ管理
PostgreSQL でも発生したエラーや警告などの問題を記録するサーバログを出力することが可能である。基本的にはsyslog出力形式と個別のテキストファイルの2種類から方式が選べるが、テキストファイルの方がOS系の情報と混在しないので妥当と考える。
サーバログ設計
基本的なサーバログ出力のためのパラメータ候補。postgresql.confで設定。
log_destination,log_collector
log_destinationはログをどこに出力するか決めるパラメータでsyslog,stderr(標準エラーログ),csvlogが設定可能。syslogにすると、OSのsyslogに出力される。stderr,csvlogの場合は同時にlog_collectorをonにした場合は、テキストファイルまたはcsvに出力される。
log_destination='stderr'
log_collector='on'
log_directory,log_filename
og_destinationを 'stderr' や 'csv' とし、logging_collectorを有効にしてPostgreSQL 独自にロギングする場合に、どのディレクトリにどのような名前でログファイルを出力するかを設定。
log_directory='/var/log/pgsql'
log_filename='postgresql-%Y-%m-%d-%H-%M-%S.log'
log_line_prefix
出力するログメッセージに付与するプレフィックスを指定。デフォルトではメッセージのみ出力されるようになっているため、%t (時間)、%u (ユーザ名)、%d (データベース名)、%p (プロセスID) あたりを指定しておくと良い。
log_prefix='[%t][%p][%u][%d] '
log_rotation_age,log_rotation_size
ログのlotateタイミングを指定。log_rotation_ageは時間指定(分)、log_rotation_size(キロバイト)はサイズ契機でログの切り替えを実施可能。log_rotarion_ageの切り替え時間は、PostgreSQLの起動した日の0時0分0秒を起点として計算される。
log_rotation_age=1d
log_rotation_size=102400
log_min_error_statement
エラー条件の原因となったSQL文をサーバログに記録するかを制御。設定したレベル以上のエラーを発生させた全てのSQL文がログに記録される。errorくらいが妥当か。
log_min_error_statement='error'
log_hostname
通常だとDBに接続する元のアクセス元IPアドレスを記録するが、接続ホストのホスト名も逆引きによりホスト名もログに表示されるようになる。しかし、IPアドレスの逆引きがボトルネックになるので、offが妥当。
log_hostname=off
長時間化処理検知やその他処理をログに残すかの設計
log_autovacuum_min_duration
指定ミリ秒実行した場合、autovacuumで実行される各活動がログに残るようになる。autovacuum活動のトレースには便利
例)5秒以上は検知
log_autovacuum_min_duration=5000
log_min_duration_statement
処理の遅いクエリを出力するための閾値をミリ秒単位で指定。
-1 を指定すると出力しない。
例)1分以上は検知
log_min_duration_statement=60000
log_checkpoints
チェックポイントおよびリスタートポイントをサーバログに記録。 書き出されたバッファ数や書き出しに要した時間など、いくつかの統計情報がこのログメッセージに含まれる。
log_checkpoints=on
監査ログ設計
セキュリティ要件で監査ログをDBで取得することは昨今では一般的。監査ログ取得方式をまとめたい。
ログイン監査
log_connections
onにすることでクライアント認証の成功終了などのサーバへの接続試行がログに残すことが可能。
log_connections=on
log_disconnections
onにすることでクライアント接続の終了をログに残すことが可能。
log_disconnections=on
SQL監査
log_statement_all
ログに出力する対象の SQL 文を指定。
「none」を指定すると出力無し。
「ddl」を指定すると CREATE、ALTER、DROP などの DDL を出力
「mod」を指定すると DDLの 出 力 に INSERT 、 UPDATE 、DELETE なども出力。
「all」を指定すると全ての SQL 文を出力。
※ただし、明らかに構文的に誤っている SQL 文が実行された場合はログに出力されない。
こういったエラーも出力させたい場合は、log_min_error_statementをerrorと定義することで情報が出力
上記でPostgresSQLのSQL監査ログを制御するが、システム単位、データベース単位、ユーザ単位でそれぞれ制御することができる。
1)システム単位
log_statement_allをpostgresql.confに設定
2)データベース単位
# 追加
ALTER DATABASE <DB名> SET log_statement = '<none|ddl|mod|all>';
# 削除
ALTER DATABASE <DB名> RESET log_statement
# 確認
SELECT * FROM pg_db_role_setting;
3)ユーザ単位
# 追加
ALTER ROLE <ユーザ名> SET log_statement = '<none|ddl|mod|all>';
# 削除
ALTER ROLE <ユーザ名> RESET log_statement ;
# 確認
SELECT * FROM pg_db_role_setting;
補足:
「pg_db_role_setting」は、データベースとロールに対して設定されているパラメーターの情報を保持しているシステムカタログ
✔︎CSVデータを投入する方法
純朴にinsertを実行してもよいのだが、PostgreSQL には COPY FROM という大量データ取り込み専用のコマンドがある。 COPY コマンドは外部からタブ区切り (.tsv) やカンマ区切り (.csv) のファイルを読み込める上に、INSERT よりもずっと高速。
※初期ロードの際には、インデックスを張ってからロードするよりも、張らずにロードして後から CREATE INDEX したほうが速い場合が多い
1.CREATE TABLE (テーブル定義 + CHECK制約のみ)
2.COPY FROM によるデータロード
3.インデックスやインデックスを含む制約、外部キー制約の追加
COPY <tbl名> FROM 'CSVファイルパス' with DELIMITER ',' csv header;
※delimiter '区切り文字' 区切り文字を表現
※csv header ヘッダーがあることを表現
### RDSでは管理者権限(superuser)が使えないため通常のcopyは利用できない。下記で代替。
\copy source-table from 'test.csv' with DELIMITER ',' csv header;
✔︎テストデータの大量作成 Tips
PostgreSQLで大量のテストデータを作成する方法を備忘として記録する。何かと検証するきわにデータが欲しいため。
- generate_series関数を利用
---10000000件のテストデータ作成。凡そ600M程度の大きさのテーブルになる
create table tbl1 (col1 integer,col2 char(20));
insert into tbl1 select generate_series(1,10000000),'XXXXXXXXXXXXXXXXXXXX';
CPUを張り付かせるSQL Tips
PostgreSQLでテスト等でCPUを張り付かせるためのSQL
- generate_series関数を利用
- 交差結合を利用
同一テーブルの各行を同一テーブルの全行と結合する処理が実施されるため、行数が多ければ多いほどかなりの結合処理を行う形になる。
結合後の行数は、単純に元のテーブルの2乗になる。複数のコアを張り付かせたい場合は、更に同様のSQLを放てばよい。
--10000000件のテストデータを自テーブルと交差結合させる。
create table tbl1 (col1 integer,col2 char(20));
insert into tbl1 select generate_series(1,10000000),'XXXXXXXXXXXXXXXXXXXX';
select count(*) from tbl1 x,tbl1 y;
容量調査
データベースを運用している以上、テーブルのサイズや件数は統計として取りたいことがよくある。またデータベース自体のサイズも。
PostgreSQLに関して、調査する方法としては以下。
--データブロックのサイズを確認
show block_size;
--データベースオブジェクトのサイズ降順
SELECT relowner,relname,reltuples as rows,(relpages::int8 * 8192) as bytes FROM pg_class order by bytes desc ;
--各テーブルのサイズ(byte)と件数を出力。上記結果をrelpagesの乗数として入れる。
SELECT relowner,relname,reltuples as rows,(relpages::int8 * 8192) as bytes FROM pg_class WHERE relname = 'テーブル名'
SELECT datname, pg_size_pretty(pg_database_size(datname)) FROM pg_database;
参考:
https://www.postgresql.jp/document/10/html/catalog-pg-class.html
シーケンス制御
PostgreSQLの場合の簡易的なシーケンスの利用方法。例えばテーブルのID列の番号採番に利用できる。
MySQLと異なり、列定義としてauto_incrementという構文は無い。
/* PostgreSQLの場合 */
DROP SEQUENCE t_id_seq;
CREATE SEQUENCE t_id_seq
START WITH 1
INCREMENT BY 1
NO MAXVALUE
NO MINVALUE
CACHE 1;
DROP TABLE product;
CREATE TABLE product (
id int DEFAULT nextval('t_id_seq') PRIMARY KEY NOT NULL,
name text not null,
price int not null
);
## セッション内での直近のシーケンス値を確認
select currval('t_id_seq');
## 次に発行されるシーケンス値を確認(実際のシーケンス値も更新される)
select nextval('t_id_seq');
## シーケンス値をリセット(現在のテーブルのID列のMAX値にcurrvalをセットする
SELECT setval('t_id_seq', (SELECT MAX(id) FROM product));
SSL接続
Postgresqlに対して接続を暗号化するための設定。
暗号化されていないと、DBとやりとりするデータが平文で流れてしまうのでセキュリティ対策で行うことが推奨される。あくまでネットワーク通信の暗号化。
- まずはSSL証明書をサーバ側(DB側)で作成することが必要
- SSL秘密鍵、CRS、証明書を作成
- SSL秘密鍵のパスワードは削除。これを実施しないと、起動時に毎回パスワードを聞かれる
# サーバ秘密鍵の作成
-RSA形式、256bitのAES形式、かつ2048bitの鍵長で作成
openssl genrsa -aes256 2048 > server.key
# CSRの作成
req CSRファイル作成
-new 新規にCSR作成
-key 秘密鍵ファイル指定
openssl req -new -key server.key > server.csr
# サーバ証明書作成
x509 X.509形式証明書
-in CSRファイル CSRファイル指定
-days 証明書有効期限
-req 入力ファイルがCSRであること明示
-signkey秘密鍵 秘密鍵ファイル指定
openssl x509 -in server.csr -days 3650 -req -signkey server.key > server.crt
Tips:サーバ秘密鍵からパスフレーズ削除
cp -p server.key server.key_org
openssl rsa -in server.key_org > server.key
その後、作成した秘密鍵、証明書をconfへ登録する。fileのパスはデータディレクトリからの相対パスでも指定できる
ssl = 'on'
ssl_cert_file = 'ssl/server.crt'
ssl_key_file = 'ssl/server.key'
ssl_ciphers = 'ECDHE-ECDSA-AES256-GCM-SHA384:ECDHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-CHACHA20-POLY1305:ECDHE-RSA-CHACHA20-POLY1305:DHE-RSA-AES128-GCM-SHA256:DHE-RSA-AES256-GCM-SHA384'
※SSL暗号プロトコルはこちらの推奨も参考に設定すべきか?
https://wiki.mozilla.org/Security/Server_Side_TLS#Recommended_configurations
※PostgresqlのpsqlはデフォルトでSSL有効。サーバ側がSSLに対応していなかったら、非SSL接続になる。強制的に無効にする必要がある場合は、PGSSLMODE=disableを環境変数として設定する。
※SSL接続時は下記のようにSSL接続に関わる情報がでる
[root@vm1 ~]# psql -U pguser01 -h db1 db01
psql (11.5)
SSL 接続 (プロトコル: TLSv1.2、暗号化方式: ECDHE-RSA-AES256-GCM-SHA384、ビット長: 256、圧縮: オフ)
"help" でヘルプを表示します。
db01=>
トランザクション分離レベル(Transaction Isolation Level)
端的に言うと、データ不整合の問題をどの程度許容するかがトランザクション分離レベル
RDBMSの信頼性を保つ性質(ACID)として以下分離性の概念がある。
分離性 (Isolation)
トランザクション中に行われる操作は他のトランザクションに影響を与えない性質。つまり、それぞれのトランザクションは分離された状態で操作を行わなければならない
これが守られない場合、下記のようなデータ不整合事象が起きる可能性がある。冒頭に書いた通り、こちらの問題をどの程度許容するかを定義したものがトランザクション分離レベルである。
-ダーティリード (Dirty Read)
トランザクションBでコミットされていないデータをトランザクションAで読み取ってしまう問題が発生する。
- 反復不能読み取り/ファジーリード/ノンリピータブルリード (Fuzzy Read / Non-Repeatable Read)
トランザクションAでデータを複数回読み取っている途中で、トランザクションBでデータを更新(update)してコミットした場合、トランザクションAでトランザクション内の前回と違う結果のデータを読み取ってしまう問題が発生
- ファントムリード (Phantom Read)
トランザクションAで一定の範囲のレコードに対して処理を行っている途中で、トランザクションBでデータを追加(insert)・削除(delete)してコミットした場合、トランザクションAで幻影のようにデータが反映されるため、処理の結果が変わってしまう問題が発生。
一見、反復不能読み取りとファントムリードの違いがわかりづらいが、前者はレコードの値に関しての同一トランザクション内の非一貫性を問題にしているのに対して、後者はそれに加えてレコードの数の一貫性が無いことを問題にしている。
上記の問題に対処すべく、アプリケーションの要件に応じて下記の分離レベルを選択することがPostgresqlでは可能。下にいくほどに分離レベルが高くなり、処理の直列化に失敗する可能性が出てくるため、失敗したトランザクションの再実行などのリカバリを考慮しておく必要がある。ほとんどの場合はRead Commitedでアプリケーションの要件は満たすことができる。また分離レベルがトランザクションごとにBEGIN TRANSACTION ISOLATION LEVEL句で指定することも可能のため、データベースのデフォルトは存在しつつも、特定のトランザクションごとに変更して要件に対応するというやり方も可能である。
| 分離レベル | 意味 | 抑止可能な分離レベル |
|---|---|---|
| リードアンコミッティド(Read UNCOMMITED) | 別トランザクションでコミットされていないデータも参照してしまう | - |
| リードコミッティド(Read Commitd) | 問い合わせ(トランザクション内の各SELECT)が実行される直前までにデータベース内でコミットされたデータを参照する(PostgreSQLではデフォルト) | ダーティリード |
| リピータブルリード(Repeatable Read) | トランザクションが開始される直前までにコミットされたデータを参照する。単一されたトランザクション内の連続のSELECTは常に同じ結果を返す | 反復不能読み取り |
| シリアライザブル(Serializable) | もっとも厳しいトランザクション分離レベル。並列実行された複数のトランザクションの実行であっても逐次的に扱われたものと同じ結果を返す。要するに、各トランザクションが1つずつ順番に行われている状態を前提として結果を返す | ファントムリード |
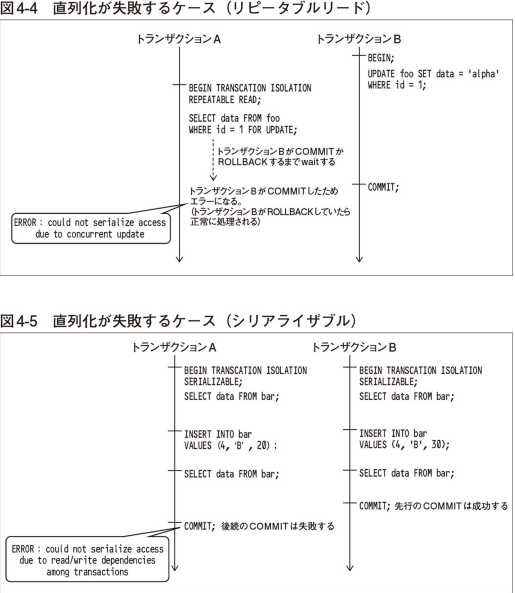
リピータブルリード、シリアライザブルでトランザクションの直列化が失敗し、トランザクションがエラーになる例
✔️バックアップ
PostgreSQLにおけるデータのバックアップ方法について。
ツールとしてはpg_dump,pg_dumpallが存在する。
最大で、データベース単位でバックアップするユーティリティ。
データベースを使用中であっても一貫性のあるバックアップを作成することができる。 pg_dumpは他のユーザによるデータベースへのアクセス(読み書き)をブロックしません。バックアップの範囲は細かくオプションで指定が可能。
https://www.postgresql.jp/document/10/html/app-pgdump.html
https://www.postgresql.jp/document/11/html/app-pgrestore.html
- プレーンテキスト形式
プレーンテキストの SQL 文によるスクリプトを作成します。これがデフォルトの動作。リストアはpsqlコマンドで実施する
例として、以下のように実行可能。
pg_dump -v --format=plain -h kai1 -U pguser01 testdb mydb > mydb_dump.sql
- カスタムアーカイブ形式(推奨)
バイナリ形式のバックアップを作成。
この形式で作成したバックアップをリストアするには、 pg_restore コマンドが必要。
メリットは圧縮されるので容量が少ない。また、リストアの際に必要なテーブルやスキーマ定義だけを分離することができるため
例として、以下のように実行可能。
# バックアップ
pg_dump -v --format=custom -h kai1 -U pguser01 testdb mydb > mydb_dump.custom
# リストア(フルリストア)
pg_restore -C -d postgres < mydb_dump.tar
- TAR形式
カスタムアーカイブ形式と同様に pg_restore でリストアできる形式のバックアップを作成する。
メリットは、tarの中身を閲覧するとOS常に格納されているテーブル構造などがわかることか?
この形式で作成したバックアップをリストアするには、 pg_restore コマンドが必要。
例として、以下のように実行可能。
# バックアップ
pg_dump --format=tar -h kai1 -U pguser01 testdb mydb > mydb_dump.tar
# リストア(フルリストア)
pg_restore -C -d postgres < mydb_dump.tar
✔️ロック
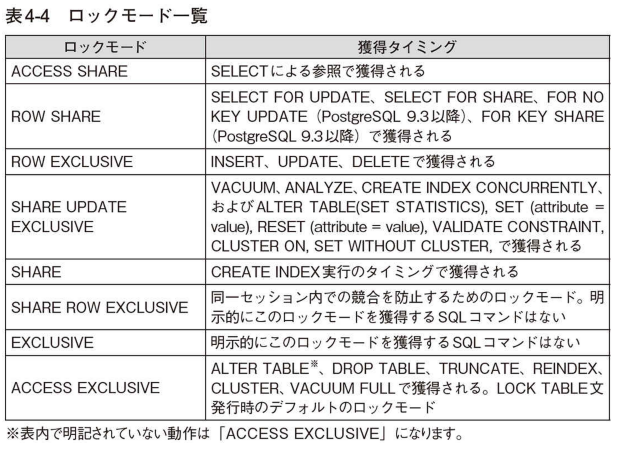
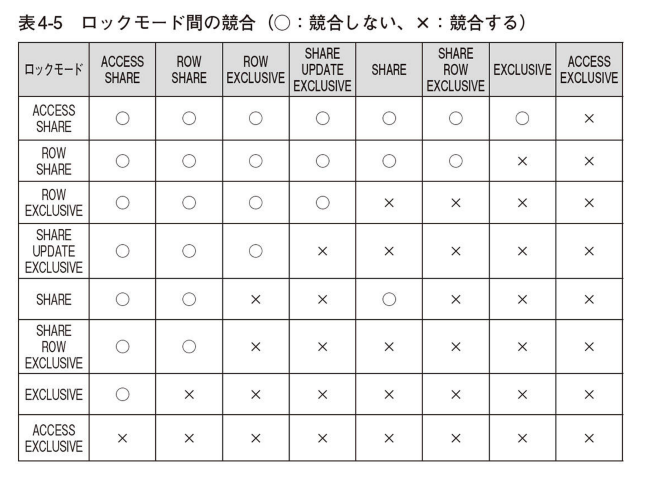
テーブルレベルロック
PostgreSQLはトランザクションの同時実行を確実にするために、テーブル対して明示的なロックを獲得可能。
行レベルロック
行レベルロックは、データの問い合わせには影響を与えない。
行レベルロックは、同じ行に対する書き込みとロックだけをブロックする。例えばupdate文を実行している行にupdateするとロック待ちになる等。
✔︎照合順序
PostgreSQLでは照合順序をLC_COLLATEで制御している。
3種類のDBを作り、照合順序がどう働きかけるか検証する
---C
CREATE DATABASE "pgtestC" WITH OWNER = "pguser01" ENCODING = 'UTF8'
LC_COLLATE = 'C' LC_CTYPE = 'C' TEMPLATE = template0 CONNECTION LIMIT = -1;
---en_US
CREATE DATABASE "pgtestUS" WITH OWNER = "pguser01" ENCODING = 'UTF8'
LC_COLLATE = 'en_US.UTF-8' LC_CTYPE = 'en_US.UTF-8' TEMPLATE = template0 CONNECTION LIMIT = -1;
---ja_JP
CREATE DATABASE "pgtestJP" WITH OWNER = "pguser01" ENCODING = 'UTF8'
LC_COLLATE = 'ja_JP.UTF8' LC_CTYPE = 'ja_JP.UTF-8' TEMPLATE = template0 CONNECTION LIMIT = -1;
testdb=# select * from moji;
col1 | col2 | col3 | col4 | col5 | col6 | col7 | col8 | col9 | col10
------+--------+------------+------------+------+---------------+------------------------+----------------------+----------+------------
1 | 森島 | モリシマ | 1965-05-03 | 54 | 森島 結依 | rKtddmA4d@test.net | http://example.co.jp | 滋賀県 | あいうえお
2 | 江頭 | エトウ | 1987-04-09 | 32 | 江頭 信男 | X7gXd@sample.com | http://sample.com | 福岡県 | かきくけこ
3 | 豊永 | トヨナガ | 1988-02-19 | 31 | 豊永 盛夫 | WsG5TfdE@example.jp | http://example.net | 富山県 | さしすせそ
4 | 山中 | ヤマナカ | 1989-03-20 | 30 | 山中 瑞貴 | MT01FvOa@example.net | http://test.net | 広島県 | たちつてと
5 | 熊谷 | クマタニ | 1972-01-12 | 47 | 熊谷 勝美 | LhUlXDUhCV@example.jp | http://sample.net | 福井県 | なにぬねの
6 | 春名 | ハルナ | 1988-10-08 | 30 | 春名 金治 | etKwM@sample.org | http://test.net | 長崎県 | はひふへほ
7 | 小河 | オガワ | 1954-06-14 | 65 | 小河 勝利 | jzSxIcn0Hq@test.org | http://example.com | 山口県 | まみむめも
8 | 小松崎 | コマツザキ | 1997-09-28 | 21 | 小松崎 日菜子 | hpbo4P@test.net | http://sample.co.jp | 鳥取県 | やゆよ
9 | 米原 | コメハラ | 1995-12-29 | 23 | 米原 将文 | VNKuCm@sample.co.jp | http://example.com | 神奈川県 | らりるれろ
10 | 一瀬 | カズセ | 2006-11-11 | 12 | 一瀬 葉奈 | NMpwQIu_@example.co.jp | http://sample.com | 岐阜県 | わをん
(10 rows)
この状態でpgtestC,pgtestJP,pgtestUSデータベースにそれぞれ同一のSQL文(select * from moji order by colXを実行して出力される結果を比較してみる。結果的には、col1,col4,col5,col8については3データベース共に照合順が同一であったが下記の列については違いが見られた。
col2,col6,col9(漢字)
ja_JPの照合順序のDBのみソート順が異なった。Cとen_USは同じ。
→不明?文字コード順?
col3,col10(ひらがな、カタカナ)
en_USの照合順序のDBのみソート順が異なった。Cとja_JPは同じ。
→ja_JP/Cは日本語のあいうえお(アイウエオ)順。en_USはバイト数が少ない順にソートしている模様。
[root@base ~]# psql -h kai1 -U pguser01 -c 'select * from moji order by 3' pgtestJP
col1 | col2 | col3 | col4 | col5 | col6 | col7 | col8 | col9 | col10
------+--------+------------+------------+------+---------------+------------------------+----------------------+----------+------------
2 | 江頭 | エトウ | 1987-04-09 | 32 | 江頭 信男 | X7gXd@sample.com | http://sample.com | 福岡県 | かきくけこ
7 | 小河 | オガワ | 1954-06-14 | 65 | 小河 勝利 | jzSxIcn0Hq@test.org | http://example.com | 山口県 | まみむめも
10 | 一瀬 | カズセ | 2006-11-11 | 12 | 一瀬 葉奈 | NMpwQIu_@example.co.jp | http://sample.com | 岐阜県 | わをん
5 | 熊谷 | クマタニ | 1972-01-12 | 47 | 熊谷 勝美 | LhUlXDUhCV@example.jp | http://sample.net | 福井県 | なにぬねの
8 | 小松崎 | コマツザキ | 1997-09-28 | 21 | 小松崎 日菜子 | hpbo4P@test.net | http://sample.co.jp | 鳥取県 | やゆよ
9 | 米原 | コメハラ | 1995-12-29 | 23 | 米原 将文 | VNKuCm@sample.co.jp | http://example.com | 神奈川県 | らりるれろ
3 | 豊永 | トヨナガ | 1988-02-19 | 31 | 豊永 盛夫 | WsG5TfdE@example.jp | http://example.net | 富山県 | さしすせそ
6 | 春名 | ハルナ | 1988-10-08 | 30 | 春名 金治 | etKwM@sample.org | http://test.net | 長崎県 | はひふへほ
1 | 森島 | モリシマ | 1965-05-03 | 54 | 森島 結依 | rKtddmA4d@test.net | http://example.co.jp | 滋賀県 | あいうえお
4 | 山中 | ヤマナカ | 1989-03-20 | 30 | 山中 瑞貴 | MT01FvOa@example.net | http://test.net | 広島県 | たちつてと
(10 rows)
[root@base ~]# psql -h kai1 -U pguser01 -c 'select * from moji order by 3' pgtestUS
col1 | col2 | col3 | col4 | col5 | col6 | col7 | col8 | col9 | col10
------+--------+------------+------------+------+---------------+------------------------+----------------------+----------+------------
2 | 江頭 | エトウ | 1987-04-09 | 32 | 江頭 信男 | X7gXd@sample.com | http://sample.com | 福岡県 | かきくけこ
7 | 小河 | オガワ | 1954-06-14 | 65 | 小河 勝利 | jzSxIcn0Hq@test.org | http://example.com | 山口県 | まみむめも
10 | 一瀬 | カズセ | 2006-11-11 | 12 | 一瀬 葉奈 | NMpwQIu_@example.co.jp | http://sample.com | 岐阜県 | わをん
6 | 春名 | ハルナ | 1988-10-08 | 30 | 春名 金治 | etKwM@sample.org | http://test.net | 長崎県 | はひふへほ
5 | 熊谷 | クマタニ | 1972-01-12 | 47 | 熊谷 勝美 | LhUlXDUhCV@example.jp | http://sample.net | 福井県 | なにぬねの
9 | 米原 | コメハラ | 1995-12-29 | 23 | 米原 将文 | VNKuCm@sample.co.jp | http://example.com | 神奈川県 | らりるれろ
3 | 豊永 | トヨナガ | 1988-02-19 | 31 | 豊永 盛夫 | WsG5TfdE@example.jp | http://example.net | 富山県 | さしすせそ
1 | 森島 | モリシマ | 1965-05-03 | 54 | 森島 結依 | rKtddmA4d@test.net | http://example.co.jp | 滋賀県 | あいうえお
4 | 山中 | ヤマナカ | 1989-03-20 | 30 | 山中 瑞貴 | MT01FvOa@example.net | http://test.net | 広島県 | たちつてと
8 | 小松崎 | コマツザキ | 1997-09-28 | 21 | 小松崎 日菜子 | hpbo4P@test.net | http://sample.co.jp | 鳥取県 | やゆよ
col7(英語大文字小文字混在)
en_USの照合順序のDBのみソート順が異なった。Cとja_JPは同じ。
→ja_JP/Cは大文字アルファベット→小文字アルファベット順。en_USは小文字アルファベット→大文字アルファベット順。
[root@base ~]# psql -h kai1 -U pguser01 -c 'select * from moji order by 7' pgtestJP
col1 | col2 | col3 | col4 | col5 | col6 | col7 | col8 | col9 | col10
------+--------+------------+------------+------+---------------+------------------------+----------------------+----------+------------
5 | 熊谷 | クマタニ | 1972-01-12 | 47 | 熊谷 勝美 | LhUlXDUhCV@example.jp | http://sample.net | 福井県 | なにぬねの
4 | 山中 | ヤマナカ | 1989-03-20 | 30 | 山中 瑞貴 | MT01FvOa@example.net | http://test.net | 広島県 | たちつてと
10 | 一瀬 | カズセ | 2006-11-11 | 12 | 一瀬 葉奈 | NMpwQIu_@example.co.jp | http://sample.com | 岐阜県 | わをん
9 | 米原 | コメハラ | 1995-12-29 | 23 | 米原 将文 | VNKuCm@sample.co.jp | http://example.com | 神奈川県 | らりるれろ
3 | 豊永 | トヨナガ | 1988-02-19 | 31 | 豊永 盛夫 | WsG5TfdE@example.jp | http://example.net | 富山県 | さしすせそ
2 | 江頭 | エトウ | 1987-04-09 | 32 | 江頭 信男 | X7gXd@sample.com | http://sample.com | 福岡県 | かきくけこ
6 | 春名 | ハルナ | 1988-10-08 | 30 | 春名 金治 | etKwM@sample.org | http://test.net | 長崎県 | はひふへほ
8 | 小松崎 | コマツザキ | 1997-09-28 | 21 | 小松崎 日菜子 | hpbo4P@test.net | http://sample.co.jp | 鳥取県 | やゆよ
7 | 小河 | オガワ | 1954-06-14 | 65 | 小河 勝利 | jzSxIcn0Hq@test.org | http://example.com | 山口県 | まみむめも
1 | 森島 | モリシマ | 1965-05-03 | 54 | 森島 結依 | rKtddmA4d@test.net | http://example.co.jp | 滋賀県 | あいうえお
(10 rows)
[root@base ~]# psql -h kai1 -U pguser01 -c 'select * from moji order by 7' pgtestUS
col1 | col2 | col3 | col4 | col5 | col6 | col7 | col8 | col9 | col10
------+--------+------------+------------+------+---------------+------------------------+----------------------+----------+------------
6 | 春名 | ハルナ | 1988-10-08 | 30 | 春名 金治 | etKwM@sample.org | http://test.net | 長崎県 | はひふへほ
8 | 小松崎 | コマツザキ | 1997-09-28 | 21 | 小松崎 日菜子 | hpbo4P@test.net | http://sample.co.jp | 鳥取県 | やゆよ
7 | 小河 | オガワ | 1954-06-14 | 65 | 小河 勝利 | jzSxIcn0Hq@test.org | http://example.com | 山口県 | まみむめも
5 | 熊谷 | クマタニ | 1972-01-12 | 47 | 熊谷 勝美 | LhUlXDUhCV@example.jp | http://sample.net | 福井県 | なにぬねの
4 | 山中 | ヤマナカ | 1989-03-20 | 30 | 山中 瑞貴 | MT01FvOa@example.net | http://test.net | 広島県 | たちつてと
10 | 一瀬 | カズセ | 2006-11-11 | 12 | 一瀬 葉奈 | NMpwQIu_@example.co.jp | http://sample.com | 岐阜県 | わをん
1 | 森島 | モリシマ | 1965-05-03 | 54 | 森島 結依 | rKtddmA4d@test.net | http://example.co.jp | 滋賀県 | あいうえお
9 | 米原 | コメハラ | 1995-12-29 | 23 | 米原 将文 | VNKuCm@sample.co.jp | http://example.com | 神奈川県 | らりるれろ
3 | 豊永 | トヨナガ | 1988-02-19 | 31 | 豊永 盛夫 | WsG5TfdE@example.jp | http://example.net | 富山県 | さしすせそ
2 | 江頭 | エトウ | 1987-04-09 | 32 | 江頭 信男 | X7gXd@sample.com | http://sample.com | 福岡県 | かきくけこ
(10 rows)
と色々試してみたがデータ依存の可能性もありそう、かつロケールの仕様的な話の方が正確なので具体的な仕組みは下記参照
https://lets.postgresql.jp/documents/technical/text-processing/2
✔監視項目として取得してい置いた方がよい性能情報系
常駐shellにしろZabbix等の監視用SWにしろだが、PostgreSQLについて定期的に取得をしておいた方がよいと思う情報
### DB全体
SELECT datname,round(blks_hit*100/(blks_hit+blks_read), 2) AS cache_hit_ratio FROM pg_stat_database
WHERE blks_read > 0;
### テーブルごと
SELECT relname,round(heap_blks_hit*100/(heap_blks_hit+heap_blks_read), 2) AS cache_hit_ratio FROM pg_statio_user_tables
WHERE heap_blks_read > 0 ORDER BY cache_hit_ratio;
### インデックスごと
SELECT relname, indexrelname,round(idx_blks_hit*100/(idx_blks_hit+idx_blks_read), 2) AS cache_hit_ratio FROM pg_statio_user_indexes
WHERE idx_blks_read > 0 ORDER BY cache_hit_ratio;
SELECT datname, xact_commit, xact_rollback, (xact_commit + xact_rollback) as sum_transaction FROM pg_stat_database;
### バックグラウンド含む
SELECT count(*) FROM pg_stat_activity ;
### バックグラウンド含まない
SELECT count(*) FROM pg_stat_activity where datname is not null;
select datname, temp_files, pg_size_pretty(temp_bytes) as temp_bytes, pg_size_pretty(round(temp_bytes/temp_files,2)) as temp_file_size
from pg_stat_database where temp_files > 0;
- temp_files: 作成された一時ファイルの数
- pg_size_pretty(temp_bytes): 一時ファイルの合計サイズ
- pg_size_pretty(round(temp_bytes/temp_files,2)): 一時ファイルの平均サイズ
select pg_size_pretty(pg_database_size('testdb')) as database_size;
select lock.locktype, class.relname, lock.pid, lock.mode
from pg_locks lock
left outer join pg_stat_activity act on lock.pid = act.pid left outer
join pg_class class on lock.relation = class.oid where not lock.granted
order by lock.pid;
✔️チェックポイント
PostgreSQL ではcommit完了時に基本的にWALに対して更新内容がflushされるので、データが失われることはないが、定期的にダーティページデータをディスクにflushする。これをしないと、いざOS電源断等で突然サーバが落ちたときに、クラッシュリカバリに非常に時間がかかってしまうが、当該処理をチェックポイントと呼ぶ。チェックポイントが既になされた部分についてはディスク上にあることが保証されるのでクラッシュリカバリする必要がないという事になる。
チェックポイントは以下の2つの意味でコストの高い処理である。
- 現時点の全てのダーティバッファを書き出す必要があるため。
-
full_page_writesが有効化されている場合、各チェックポイント対象の各ページに関しては、その後初回のWAL書き込みの際にページ全体がWALに書き込まれるため、
そのため、チェックポイント用のパラメータを高くし、チェックポイントがあまりにも頻発することがないようにすることが推奨される。チェックポイントに関しては、時間や更新WAL量により発生頻度の制御が可能である。実際にはこれらのパラメータを設定してしばらく様子を見ることで問題ないことを確認する。また、更新量のピーク時に仮にサーバが落ちた際を想定してクラッシュリカバリ時間のテストを実行し、復旧時間が問題ないことを確認するテストを行うことが妥当だろう。
-
checkpoint_timeout- この時間が前回のチェックポイントから経過するとチェックポイント実行。
-
max_wal_size- この更新量が前回のチェックポイントから発生するとチェックポイント実行
その時々のチェックポイントの完了時間(チェックポイント実行〜ディスクへのダーティページのフラッシュ完了)を制御するパラメータとしては、checkpoint_completion_target。デフォルトだと0.5であり、これはチェックポイント実行から次のチェックポイント実行までの半分の時間間隔でチェックポイントが完了するようにする。このパラメータがある理由としてはチェックポイント実行後から一気にダーティページがディスクにflushされると一時的にかなり負荷が高騰するため。
また、頻繁なチェックポイントの発生をログに記録する方法としては、checkpoint_warning。こちらに指定したパラメータ以内の時間でチェックポイント(つまり、max_wal_sizeを超える更新により発生)が発生すると、ログにその旨記録される。基本的にはcheckpoint_timeout未満の値を設定して様子をみてもし頻繁にログに記録されるようであれば、チェックポイント処理頻発による負荷高騰を緩和するために、max_wal_size を増加させることを検討するのが良い。
なお、チェックポイントが実行され、ログが吐き出された後、チェックポイントの位置はpg_controlファイルに保存される。そのため、クラッシュ後のリカバリ開始の際は、PostgreSQLはまずpg_controlを参照し、次にチェックポイントレコードを読みます。 そして、チェックポイントレコード内で示されたログの位置から前方をスキャンすることでクラッシュリカバリ時のREDO処理を行う。
参考
https://www.postgresql.jp/document/11/html/wal-configuration.html
https://www.postgresql.jp/document/11/html/wal-internals.html
✔️ pg_buffercache
shared_buffer 上に乗っているオブジェクトを確認する方法。拡張機能の pg_buffercache を使う。
対象のデータベースにて、まずは、create extension pg_buffercache。
SELECT c.relname, count(*) AS buffers
FROM pg_buffercache b INNER JOIN pg_class c
ON b.relfilenode = pg_relation_filenode(c.oid) AND
b.reldatabase IN (0, (SELECT oid FROM pg_database
WHERE datname = current_database()))
GROUP BY c.relname
ORDER BY 2 DESC
LIMIT 10;
select c.relname,b.relblocknumber,b.isdirty,b.pinning_backends
from pg_buffercache b INNER JOIN pg_class c ON b.relfilenode = pg_relation_filenode(c.oid) AND b.reldatabase IN (0, (SELECT oid FROM pg_database WHERE datname = current_database()))
where c.relname='リレーション名' order by 1,2;
バッファにブロックをピンすることに関してもう少し詳細を。。。
ピン(pin)
リレーション上のブロックは共有メモリバッファ上に読み込まれるが、操作中はこの対応関係をピンしておく必要がある。 PostgreSQL のインスタンス中では別のセッションや背景で動作しているプロセスによって別のブロックが共有メモリバッファに読み込まれ、知らないうちに置換が起きて追い出されてしまうかもしれないからである。 バッファをピンすることによって、勝手な置換が発生しなくなる。
[参考]
http://www.nminoru.jp/~nminoru/postgresql/pg-table-and-block-structure.html
✔️バキューム
バキューム概要
PostgreSQLでは定期的にバキュームという処理を実行する必要がある。
PostgreSQLは追記型アーキテクチャを取っており、update文の実行時に、既存の行を更新する訳ではなく、insert文のようにテーブルの領域の末尾に更新後の行を新たに追記するという形式を取っている。こうすることで、更新時の行ロック確保が既存の参照処理を実施するトランザクションを失敗させないようにする仕組みを取っている。既存の行に関しては、どのトランザクションからも参照されなくなったタイミングで削除フラグが付与されて、以後参照されなくなる。
ただし、参照されなくはなるものの、ディスク領域として物理的に削除されている訳でもなく、また再利用可能な領域でもない。バキュームを実施することにより、これらの不要領域を物理的に削除、または再利用可能な領域にする。
バキュームには大きく分けて2種類の方式が存在する。
- FULL VACUUM
不要タプルを物理的に削除してディスク領域をOSに返却。OSから見たときに物理的にディスク容量が空く。
デメリットしては、実行時対象のテーブルに対してテーブル全体の排他ロックがかかる、かつ長時間かかる。
### データベース全体に対して実行
VACUUM FULL;
### 特定のテーブルに対して実行
VACUUM FULL tbl1;
### 詳細出力モード
VACUUM FULL VERBOSE tbl1;
- 通常VACUUM(Concurrent Vacuum)
不要タプルを物理的には削除しないが、DBMSとして再利用な領域として定義する。実行時特にロック等はかからずFULL VACUUMに比べて短時間で完了する。また基本的に前回のvacuumから更新のあった行に対してのみ実行するので早い。AutoVacuumで実行されるのはこちらの領域。
デメリットとしては、
- ディスク領域をOSに返す訳ではなくOSから見たディスク容量が枯渇の可能性がある点.
- 再利用可能な領域はSELECT時にディスク走査されるため、FULL VACUUMのようにOSにディスク領域として返した時と比べてパフォーマンスが悪くなる点。(例えば、データが1件しか入っていないテーブルのフルスキャンが通常速攻終わるのに、再利用可能な領域が10000000件あるとより時間がかかるなど)
### データベース全体に対して実行
VACUUM;
### 特定のテーブルに対して実行
VACUUM tbl1;
### 詳細出力モード
VACUUM VERBOSE tbl1;
通常時は、通常VACUUMを利用し、ディスク逼迫時といった緊急時、またはデータがそれ以上増えず再利用可能領域の割合が常に多すぎるようなテーブルに対してはテーブルロックが発動してしまう前提でFULL VACUUMを実行すべきと考える。
Auto VACUUM各パラメータ詳細
select schemaname,relname,n_live_tup,n_dead_tup,last_vacuum,last_autovacuum,last_analyze,last_autoanalyze from pg_stat_user_tables;
共有バッファに関して詳細
コード例
JDBCテスト用(Java。truncate⇒csvからinsert⇒結果参照)
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
public class mojia {
public static void main(String[] args) {
String URL = "jdbc:postgresql://kai1:5432/testdb";
String USER = "pguser01";
String PASS = "P#ssw0rd";
String SQL1 = "truncate table MOJI";
String SQL2 = "select * from MOJI";
//TRUNCATE & INSERT
try {
Connection conn = DriverManager.getConnection(URL, USER, PASS);
Statement stmt = conn.createStatement();
try{
stmt.executeUpdate(SQL1);
File file = new File("/root/csv/utf8.csv");
FileInputStream input = new FileInputStream(file);
InputStreamReader stream = new InputStreamReader(input,"UTF8");
BufferedReader br = new BufferedReader(stream);
String s;
while (( s = br.readLine()) != null ) {
String[] data = s.split(",", 0);
stmt.executeUpdate("INSERT INTO MOJI VALUES ('"
+ data[0] + "','"
+ data[1] + "','"
+ data[2] + "','"
+ data[3] + "','"
+ data[4] + "','"
+ data[5] + "','"
+ data[6] + "','"
+ data[7] + "','"
+ data[8] + "','"
+ data[9] + "')"
);
}
br.close();
} catch (IOException e) {
System.out.println(e);
}
stmt.close();
conn.close();
}
catch (Exception e) {
e.printStackTrace();
}
//SELECT
try(Connection conn =
DriverManager.getConnection(URL, USER, PASS);
PreparedStatement ps = conn.prepareStatement(SQL2)){
try(ResultSet rs = ps.executeQuery()){
int i=0;
while (rs.next()) {
System.out.println(
rs.getInt("col1") + "," +
rs.getString("col2") + "," +
rs.getString("col3") + "," +
rs.getDate("col4") + "," +
rs.getString("col5") + "," +
rs.getString("col6") + "," +
rs.getString("col7") + "," +
rs.getString("col8") + "," +
rs.getString("col9") + "," +
rs.getString("col10"));
}
rs.close();
ps.close();
conn.close();
};
} catch (SQLException e) {
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
}
}
}
PHP PDO接続テスト用
<?php
//DB接続定義
$dsn = 'pgsql:host=xxxxx;port=5432;dbname=testdb';
$user='pguser01';
$password='P#ssw0rd';
$dbh = new PDO($dsn, $user, $password);
//SQL実行部分
$sth = $dbh->query('select * from AAA');
foreach($sth as $row){
print($row['col1'].",".$row['col2']."\n");
}
?>
参考リンク
- https://aws.amazon.com/jp/blogs/news/managing-postgresql-users-and-roles/
- https://employment.en-japan.com/engineerhub/entry/2017/09/05/110000
- 内部構造から学ぶPostgreSQL 設計・運用計画の鉄則 4.5
- https://lets.postgresql.jp/documents/technical/statistics/2#db_level_stats
- https://www.percona.com/blog/2018/08/10/tuning-autovacuum-in-postgresql-and-autovacuum-internals/