株式会社massive lnggの古川です。
下記にこの記事の続編の研究を載せました
[自動的に知能を高める次世代AIシステム開発:動画機械学習]
https://qiita.com/furukawamassive7/items/fc3b7de6ad092d87cb30
https://qiita.com/furukawamassive7/items/71354bf3713ec84d27d9
AI≒機械学習のエンジニアとして
**「次世代AIは動画学習によって生まれる」**ということを
ほぼ確信しています。
AIの動画学習によって現在では手の届いていない
まるで人間のように会話をしたり、思考ができる
革新的な人工知能アルゴリズムが登場するのではないかと考えています。
その理由とともに
裏付けとして今回行った実験結果を報告したいと思います。
また、あえて機械学習ではなく
「AI=人工知能」というワードを用いています。
機械学習をそこそこ知っている人を対象に書いていますが
代表的な論文のみに絞って紹介し、細かい理論には触れません。
現在の自然言語処理技術の限界と動画機械学習
「あれ、動画の話しじゃないの?」と思った人もいるかもしれませんが
実は今、言語と画像の境界が研究において無くなりつつある、という話しを含めて
説明したいと思います。
自然言語処理に関わるエンジニアならわかるように
現在はbag of words、つまり言葉の出現回数などを手がかりに
文章を分類したり意味理解する手法が主流です。
厳密には凝ったアルゴリズムもオントロジーなど別アプローチもあるかもしれませんが
基本は「文章を学習して、文章を理解させる」です。
AIが東大に入れるか、という「東ロボ」プロジェクトがありましたが
文章の意味理解(≒意味が想像できない)ができないことが短所の一つとなっていました。
(参考:https://www.dailyshincho.jp/article/2017/02080800/?all=1)
このようなプロジェクトが素晴らしい取り組みであると前置きした上で
どうすれば良いのか?
それは「動画によって知能を育てる」ことだと考えています。
例えば言葉の定義が厳格な法律文書の分類はできても
「靴が小さすぎて履くことができない」という事実を機械が認識するのは
現段階ではとても難しいです。
現状の機械学習では「靴、大きい、小さい、履く」は一緒に出現しやすい言葉であるとわかっても
因果関係を理解することはできません。
そこで!
動画という実世界のコンテキスト(=文脈)を理解しうる材料を使って
機械に学習させれば良いのではないかということです。
これまでの類似研究
若干、細かい話しを含むので結果を先に知りたい方は次のセクションへどうぞ。
動画AI学習について
あの「googleの猫」(2012年)がひとつ挙げられます。
これはニューラルネットワークで1000万枚のyoutubeの画像を教師なし学習した結果
「猫」によく反応するニューロンができ、概念を習得したであろう、という主旨でした。
(参考:https://googleblog.blogspot.com/2012/06/using-large-scale-brain-simulations-for.html)
また、動画関連ではキャプション生成・翻訳が有名かと思います。
MS COCOデータ・セットなどで画像に何が写っているかコメントさせるという主旨の研究が
ニューラルネットワークでそこそこ行われていると思います。

(引用元:"Show, Attend and Tell: Neural Image Caption Generation with Visual Attention" http://proceedings.mlr.press/v37/xuc15.pdf)
動画に関する類似研究
代表的な動画のデータセットは現状Youtube8mであると思います。
・Youtube-8m: A large-scale video classification benchmark
(https://arxiv.org/pdf/1609.08675)
これも素晴らしいデータセットであり、かつ、youtube challengeなどをkaggleで開催している一方で
動画のラベル付け=動画自体のカテゴリー分類がほぼ目的になっており
動画のフレームごとの関連やそのコンテキストを機械に学習させるようにしよう
といったものではないと考えています。
視覚的にAI学習系研究
・PredNet "Deep Predictive Coding Networks for Video Prediction and Unsupervised Learning"
https://arxiv.org/pdf/1605.08104
AI実現に大きなヒントをくれた論文だと感じています。
脳の機能を参考にしながら動画など数フレーム未来を
描かせて予測させるニューラルネットワークです。
この論文によって2次元画像からでも3次元の概念が認識できそうな予兆と
動画のコンテキストが理解できそうな雰囲気が感じ取れます。
今回の取り組みの異なる点では、あくまで
「1フレーム後、車が進行方向に動いている」のような話しではなく
「車のカギを持っている人がいたら、次のシーンではその人は車に乗っているだろう」という
コンテキスト(=文脈)を理解させたい、概念を理解してほしいということにあります。
・SCAN "SCAN: Learning Hierarchical Compositional Visual Concepts"
さすがDeepmindと思わせる論文です。
視覚と概念の学習を結びつけようとする手法です。
他にもDeep Q-Network周りなど強化学習も基本
ゲームプレイ系のAIは今回目指す動画学習と共通点があり
参考になる点があるかと思います。
今回行った動画によるAI学習手法
ずばり、簡単にいうと
「数フレームを入力して次のフレームを予測させるようニューラルネットワークを学習」
その上で
「低次元化された特徴量ベクトルを無教師分類して意味理解できているか確認」です。
紆余曲折あってこの形になっているわけですが
基本的な考え方は
動画を学習しまくれば意味がわかるようになるでしょう、ということです。
さらに、動画・言語・その他の知覚をできる限り学習することで
人間と似たような思考方法を身につけるかもしれないし
人間と全く別の科学的知能を持つ可能性があるのではないかと予想しています。
例えば数学も機械が再構築する日が来るかもしれないと感じています。
さて、話しを戻して、動画でのAI学習手順と結果を示していきます。
AI動画学習手法の具体的な手順
1.動画学習環境の構築と実験セット
料理に関する約50000動画を10秒ごとのフレーム
サッカーの試合に関する約6000動画を1秒ごとのフレーム
で学習できる環境を構築しました。
2ジャンル別々のモデルで学習を実行します。
理想の結果としては
料理なら「切る・混ぜる・焼く」などを分類できた上で料理の種類や
細かな調理法などの違いが判別できたり
サッカーであれば1フレーム前にゴールに入りそうかどうかを判別できたり
ファウルが起きそうなシーンを未然に予測できる、といったことです。
2.convolutional autoencoderでフレームを低次元特徴量化
そのままのフレーム画像を突っ込んでしまうと
ピクセル位置が少しズレたときに全く別の画像と認識してしまうであろうことや
強化学習系の研究からも特徴量化した方が良いことがわかっているのでこの形にしてます。
入力と出力を同じ画像にして突っ込んで復元して
真ん中のencodeできたものをフレーム特徴量としています。
下記の様なkerasのコードを使っています。
試行錯誤の結果、層が深すぎるとうまく復元できないことや
LeakyReLUを使った方が0で塗りつぶされた領域がやはり発生しにくいことがわかりました。
https://github.com/furukawaMassive555/videoai
from keras.layers import Input, Dense, Conv2D, MaxPooling2D, UpSampling2D, BatchNormalization, Activation
from keras.models import Model
from keras.layers.advanced_activations import LeakyReLU
def ConvAuto(input_shape):
input_img = Input(shape=input_shape)
x = Conv2D(64, (3, 3), padding='same')(input_img)
x = BatchNormalization()(x)
x = LeakyReLU(alpha=0.2)(x)
x = MaxPooling2D((2, 2), padding='same')(x)
x = Conv2D(32, (3, 3), padding='same')(x)
x = BatchNormalization()(x)
x = LeakyReLU(alpha=0.2)(x)
x = MaxPooling2D((2, 2), padding='same')(x)
x = Conv2D(16, (3, 3), padding='same')(x)
x = BatchNormalization()(x)
encoded = LeakyReLU(alpha=0.2)(x)
x = Conv2D(16, (3, 3), padding='same', name='conv_encoded')(encoded)
x = BatchNormalization()(x)
x = LeakyReLU(alpha=0.2)(x)
x = UpSampling2D((2, 2))(x)
x = Conv2D(32, (3, 3), padding='same')(x)
x = BatchNormalization()(x)
x = LeakyReLU(alpha=0.2)(x)
x = UpSampling2D((2, 2))(x)
x = Conv2D(3, (3, 3), padding='same')(x)
x = BatchNormalization()(x)
decoded = Activation('sigmoid')(x)
model = Model(input_img, decoded)
model.compile(optimizer='adam', loss='binary_crossentropy')
return model
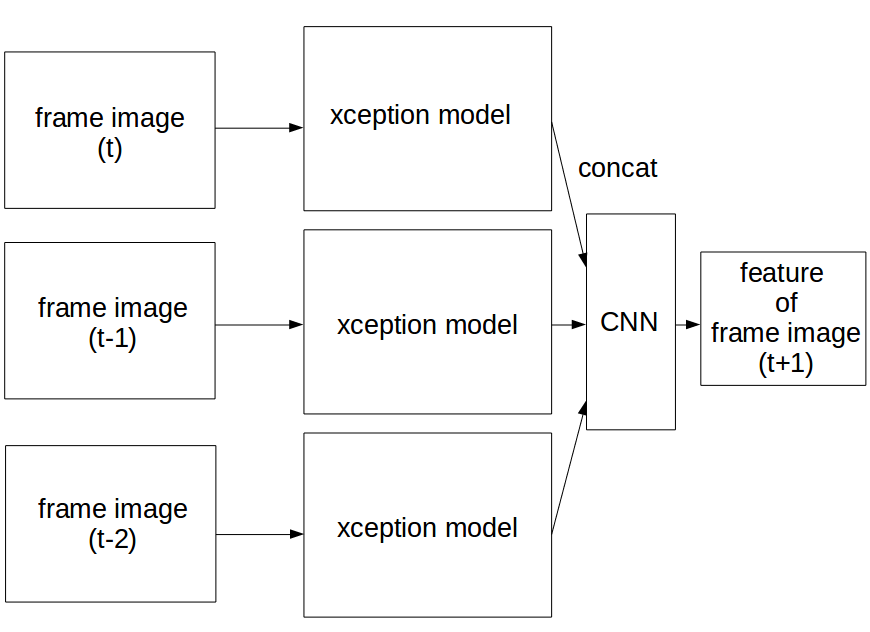
3.直近3フレーム分から未来1フレーム分を予測して学習
xception or mobilenetで3フレーム分を特徴量化した上で
CNN(convolutional neural network)を上に載せる形になっています。
ここで「えっ、時系列データなのにLSTM使わないのか?」と思った人がいるかもしれませんが
RNN(recurrent neural network)は数学的に解析しにくい点と
今回のタスク上では過去の特徴量をある意味、雑に混ぜてしまう懸念から採用していません。
もうひとつの手法の候補として
概念や特徴量を捉える手段として
GAN(Generative Adversarial Network)の変化形が有力でした。
この手法では言語を介さずにコンピュータの思考を出力できることが魅力で
なぜなら、言語はやはり人間に合わせて作られたものであるため
コンピュータからすると言語的思考方法は非効率な可能性があるためです。
しかし、現在ほぼ最新の手法の一つと思われる下記の手法でも
cifar10というドメインが限定された状態でも
ノイズが多い生成状態となっているため
今回は採用しませんでした。
"Improved Training of Wasserstein GANs"
https://arxiv.org/pdf/1704.00028.pdf
今回のネットワーク構成では、パラメータ量と
ネットワークに保存される知識・知性の量は比例するという考えから
十分な深さ、広さを持つxceptionモデルを使用しています。
今回は精度を上げることではなく、コンセプトを示すことが目的なので
できる限りシンプルで再現しやすく、読みやすいコードを心がけた結果
下記の形になっています。
(リストで書けると思いますがこれで実験をしたので、そのまま載せています)
from keras.applications.xception import Xception
from keras.applications.mobilenet import MobileNet
from keras.layers.advanced_activations import LeakyReLU
from keras.models import Model, load_model
from keras.layers import Dense, GlobalAveragePooling2D, Conv2D, Reshape, BatchNormalization
from keras import layers
from keras.optimizers import Adadelta
def Videoai(input_shape, modelarch="xception", output_width=64, output_channel=16):
# define base models ## todo this can be list, variable
if modelarch == "xception":
base_model1 = Xception(weights="imagenet", include_top=False, input_shape=input_shape)
base_model2 = Xception(weights="imagenet", include_top=False, input_shape=input_shape)
base_model3 = Xception(weights="imagenet", include_top=False, input_shape=input_shape)
else:
base_model1 = MobileNet(weights="imagenet", include_top=False, input_shape=input_shape)
base_model2 = MobileNet(weights="imagenet", include_top=False, input_shape=input_shape)
base_model3 = MobileNet(weights="imagenet", include_top=False, input_shape=input_shape)
# change to unique layer name
for layer in base_model1.layers:
layer.name = layer.name + str("_one")
for layer in base_model2.layers:
layer.name = layer.name + str("_two")
for layer in base_model3.layers:
layer.name = layer.name + str("_three")
frame1_out = base_model1.output
frame2_out = base_model2.output
frame3_out = base_model3.output
frame1_out_rs = Reshape((output_width, output_width, -1))(frame1_out)
frame2_out_rs = Reshape((output_width, output_width, -1))(frame2_out)
frame3_out_rs = Reshape((output_width, output_width, -1))(frame3_out)
x_concat = layers.concatenate([frame1_out_rs, frame2_out_rs, frame3_out_rs])
x_concat = Conv2D(output_channel, (2, 2), padding='same', name="concat_conv1")(x_concat)
x_concat = BatchNormalization()(x_concat)
x_concat = LeakyReLU(alpha=0.2)(x_concat)
x_concat = Conv2D(output_channel, (2, 2), padding='same', name="concat_conv2")(x_concat)
x_concat = LeakyReLU(alpha=0.2)(x_concat)
x_concat = Conv2D(output_channel, (2, 2), padding='same', name="concat_conv3")(x_concat)
x_concat = BatchNormalization()(x_concat)
x_concat = LeakyReLU(alpha=0.2)(x_concat)
model = Model(inputs=[base_model1.input, base_model2.input, base_model3.input],
outputs=x_concat)
optimizer = Adadelta(lr=1.0, rho=0.95, epsilon=None, decay=0.0)
model.compile(loss='mean_squared_error', optimizer=optimizer, metrics=['accuracy'])
return model
4.学習結果
料理の場合は2000動画
サッカーの場合は900動画をテストデータとして学習データと分けた上で
テスト検証を行いました。
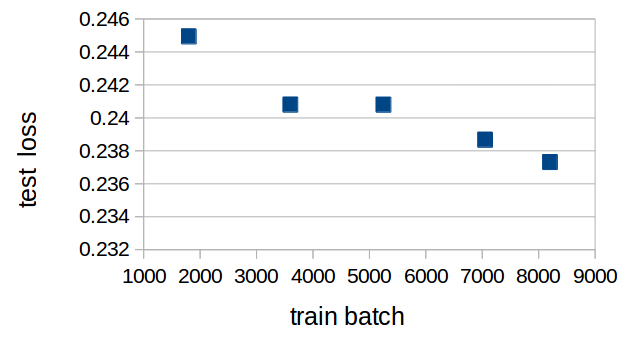
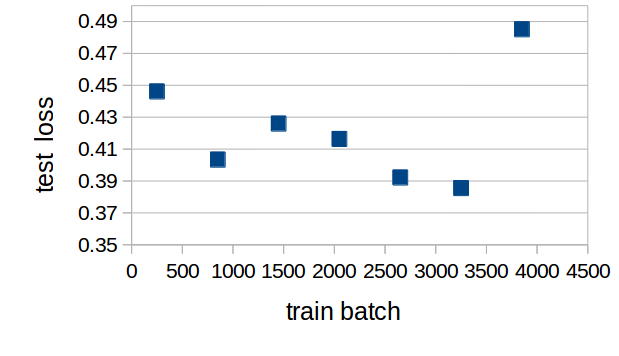
・lossの推移
lossの推移は以下の通りです。
料理は1train batch=120フレーム分
サッカーは1train batch=100フレーム分です。
サッカーに関する学習の最後の方で発散しているところ以外は
順調に学習できている様子が見て取れます。
料理データ学習テスト損失推移
サッカーデータ学習テスト損失推移
・kmeansによる画像特徴量の無教師分類
では、本丸であるテストデータを無教師分類してみるとどうなるのか
その料理のフレームを5グループに分類した結果の一部が以下の通りです。

クリエイティブ・コモンズライセンスの基に再利用させていただいております。
権利者の方、問題があればお教えください。
他のデータもクラスタリングした結果言えることは以下の点です。
・同じ動画の画像がやはり多く集まる
・鍋やコップなど似たものがクラスタリングされる傾向がある
ということで色や構図に強く影響され過ぎてしまうという結果になりました。
出力の教師データを未来とすることである程度似たコンテキストが集まるかと期待しましたが
そういう結果にはなりませんでした。
未来ではなく現在時刻の特徴量を教師データとするとさらにその影響は顕著になりました。
つまり
・意味が理解できないと解けないタスクを用意して学習すべき
という結論が得られました。
反省と改善
今回ネックになった動画でのAI学習におけるポイントがいくつかあります。
・データの質、量
多くの現存する動画は見る人を対象として
編集されていたり、学習上のノイズが多かったりします。
やはり一番はじめの段階では編集された間の行間を読む想像力は
機械にないので、なるべく単純かつ実世界に近い動画で学習すべきだと感じました。
・コンピューターパワーの不足
やはりたった3つのxceptionモデルより多いモデルにすると
memory errorが出てしまうのはかなり痛かったです。
学習も1回の試行に数日単位かかってしまうので
反省を活かしつつ進めるには時間が必要になります。
・ネットワークの構成が適していない
数学的にも分析をしていないので所感になってしまいますが
xceptionなどのganのモデルがimagenetなどのデータ・セットに
最適化され過ぎているのではないか?という疑問も生じました。
まず異なる構図、サイズに弱い雰囲気が見受けられる点などからそう感じています。
・学習のさせ方の改善
ここがやはり1番の肝であり、これからの課題です。
skip gramの動画バージョン=skip frames的に現在のフレームから前後何が起きたか?を出力させたり
まだ使っていない言語データを手がかりとして使うこともアリかと思います。
そのもっと簡単なバージョンではimagenetの1000クラスの物体のどれが出現するかを
ラベルで予測するという案も考えました。
また、生画像をどうやって特徴化せずに、でも生のフレーム画像に影響を受け過ぎないためには
特徴量を学習しながら、コンテキストも同時に学ぶ、といったことが必要だと思いました。
エピローグ
まずなぜこのような実験を行い記事を公開しようかと思った理由として
次の技術革新が早く起きることでビジネス活用がもっとうまく進み
結果、投資が豊富になり、AIやアルゴリズム進化の歴史を加速できる期待があります。
他に「やっぱりAIには動画が必要だな」と感じさせられたきっかけの一つに
牛久先生のこのスライドがあります。
https://www.slideshare.net/YoshitakaUshiku/deep-learning-73499744
この内容を約2年弱くらい前に勉強会で聞いてから
CVPR(画像処理の国際学会)などでも徐々にマルチモーダルな動画などに
焦点を当てた研究が増えてきたことは事実である一方、
「2年位経ったのに、まだ汎用的アルゴリズムって出てないのか?」と感じ
信じている考え方があるので少しでも自分でトライしてみようと思ったことにあります。
最後自分に類似研究など含めて見落としがないかな、という点もあるので
ご指摘・議論はウェルカムです、コメントでもメールでもお気軽にください!
リクエストが多ければもう少し詳細な結果やコードも載せるかもしれません。
何にせよ僕はコンピュータの信者であり
テクノロジーの進化がより今後加速的に顕著になり
必ず良い方向に社会を導くと思っています。
この記事は言葉で締めたいです。
アルゴリズムに不可能はない!
(2018/10/11 初回投稿)