株式会社massive lnggの古川です
私が考える人類のテクノロジーの最終解は
「自動的に際限なく知能・知識量を高め続けるマシン」を作ること
(AIがAIを作るなど含めて)だと思いますが
そこから逆算して現在、次の一歩は何なのか?ということを考えた結果
「動画の機械学習によって少し抽象的、高次元の概念を自動獲得すること」
だと考えました。
そこで動画の分類技術を中心に先行研究を調べ
抽象的な概念の獲得のための
準抽象概念動画データセット(semi Abstract Concept Video Dataset:sACVD)
というものを作成しました。
成果は論文にもまとめる予定です。
コードは以下のgithubリポジトリにあります
https://github.com/furukawaMassiveReborn777/abstract-concept-video-learning
動画機械学習技術の最前線
現状ではvideo classificationが主流ですが
本当の動画理解につなげるには
video question answering, video generation
などのジャンルの盛り上がりが必要だと思いました
3DCNNなど動画分類の基本な歴史は下記の原氏のスライドがわかりやすいです
"3D CNNによる人物行動認識の動向"
https://www.slideshare.net/kenshohara11/3d-cnn
動画機械学習に関する最前線の研究のうち今回の目的に近いものは以下の通りです
論文の主旨というより関連する部分について主に述べます
"Temporal relational reasoning in videos"[1]
something-somethingというデータセットを使って
move (object) to rightのような
簡易的な動作であれば異なるオブジェクトの物体でも同じ行動として認識できる様子であることについて
定性的な結果が載っています
"Long-Term Feature Banks for Detailed Video Understanding"[2]
いきなり一つの画像をみても、前後の情報がないと何しているかわからないことは多いです
そこで前後の文脈、それも数秒ではなくもっと長い時間の動画の文脈を捉えて
画像の正確な意味を予測しようというような内容でした
"Imagine This! Scripts to Compositions to Videos"[3]
文章からアニメ動画生成する技術です
失敗例もあるものの予想以上の正確さを感じました
http://www.youtube.com/watch?v=688Vv86n0z8
"Adversarial Inference for Multi-Sentence Video Description"[4]
動画のdescriptionに関してSOTAかそれに近い論文です
こちらも現在の動画理解精度とモデルアーキテクチャを把握するために確認しました
"Can spatiotemporal 3d cnns retrace the history of 2d cnns and imagenet?"[5]
3DCNNに関して豊富な実験結果と考察があり
結果が出ない場合や新しいアーキテクチャを検討する際に
どう改善すればいいのかの貴重なヒントとなる論文です
動画関連データセット
kinetics
something-something
AVA
UCF 101
これら代表的なデータセットの長所・短所を把握した上で
今回の目的を達成するためのデータセットを作成しました
動画で抽象的な概念を自動獲得する方法
人間のように思考する、会話するようなマシンを作るために
機械学習的に次のように獲得すべき概念を分けられるのではないかと考えました。
非時間的視覚概念(non-temporal visual concept)
画像から学習できる「色」や「形」などの概念です
時間的視覚概念(temporal visual concept)
「時間的」な概念は動画から学習できるはずです
(例)休む、急ぐ、昼夜
時間的非視覚概念(temporal non-visual concept)
視覚に現れない高次抽象概念の獲得がひとつの壁になると考えています
(例)法律、数式など
機械的に「見たままの具体的な状態を表している概念の獲得」
「もっと抽象的な状態を表している概念の獲得」に大きな差があると考えています
どうすれば「目に見えない抽象的な概念を獲得できるか?」
その答えとして 十分な数の具体的な概念の学習から抽象的な概念が獲得できる と仮説を立てました。
さらにそれを自動的に抽象概念のラベル無しで抽象概念が獲得できるとすれば
自動的に高次抽象概念を学習できる ようになるのではないかと考えました。
準抽象概念動画データセット(semi Abstract Concept Video Dataset:sACVD)
actionの対極ペア(例:goとcomeなど)が存在するように
動画をタグ付たデータセットによって
具体概念の学習のみで抽象概念を獲得できるか確認することを試みました
データセット本体はgithubのdata/anno/abstract_video_dataset.csvにあります
オブジェクトの影響を排除したデータ集め
先行研究でも指摘があるように
動画の機械学習ではactionそのものではなく
オブジェクトに依存して分類を行っているのではないかという疑念があります。
つまり、「サッカー」なら「ボールを蹴って点を入れる」という行動ではなく
「ユニフォームと大きめのボールが写っている」ことを根拠に
「サッカー」と判断している可能性です。
オブジェクトに依存した分類をさせないために
同じ動画内か同じジャンルの似たオブジェクトが
写った動画で対極ペアのactionを集めました。
例えば、「goal_free_kick」と「miss_free_kick」であれば
同じようにサッカーボールとゴールが写ったシーンで
ゴールが入るか、外すかという行動だけが異なります。
この点ではsomething-somethingデータセットと若干似ていますが
このデータセットの目的はあくまでより抽象的な概念の
可能であれば自動的な獲得にあります。
データセットの各クラスと詳細
main_category=抽象概念、 sub_category=具体概念として
youtubeの(少なくとも検索時には)すべて
クリエイティブコモンズライセンスの動画に対して
タグ付けを行いました
合計約1600シーンあります
概念の定義は以下の通りです
come, go:
カメラからの目線で何かが近づく(come)遠ざかる(go)
build, disassemble:
PCやスマホなどの部品をくっつけたり(build)バラす(disassemble)行動
goal, miss:
サッカーやバスケットでシュートを打ってからゴールに入る(goal)か外す(miss)までの行動
詳しくはデータセットのCSVファイルに再生位置などが記録されているので
中身をご覧ください。
| main_category | narrow_sense | sub_category |
|---|---|---|
| go | go | baseball pitcher |
| come | come | baseball pitcher |
| go | go | run training |
| come | come | run training |
| go | go | free kick keeper come go |
| come | come | free kick keeper come go |
| make | build | lego build |
| break | disassemble | lego disassemble |
| make | build | assemble a pc |
| break | disassemble | disassemble a pc |
| make | build | smartphone assemble |
| break | disassemble | smartphone disassemble |
| make | build | assemble bicycle |
| break | disassemble | disassemble bicycle |
| make | build | assemble engine |
| break | disassemble | disassemble engine |
| succeed | goal | free kick |
| fail | miss | free kick |
| succeed | goal | basketball game |
| fail | miss | basketball game |
| succeed | goal | handball game |
| fail | miss | handball game |
またsemi Abstract Conceptのsemiには
真に抽象的な概念(例:ルール違反・数学など)に対して
視覚的に学習できるレベルの抽象概念という意味が込められています
動画の機械学習による抽象概念獲得実験
行うことはまず自動獲得ではなくでも
抽象概念=main_categoryの動画分類が行えるのかという精度検証と
具体概念=sub_categoryの学習後に特徴量ベクトルを
tsneによる2次元可視化とベクトル差分を比較して抽象概念が獲得されているのかを判断します
動画分類ニューラルネットワーク:ECO
動画分類において軽量で精度もほぼstate of the artである
"ECO: Efficient Convolutional Network for Online Video Understanding"のうち
より軽量なECOliteを参考に実装しました
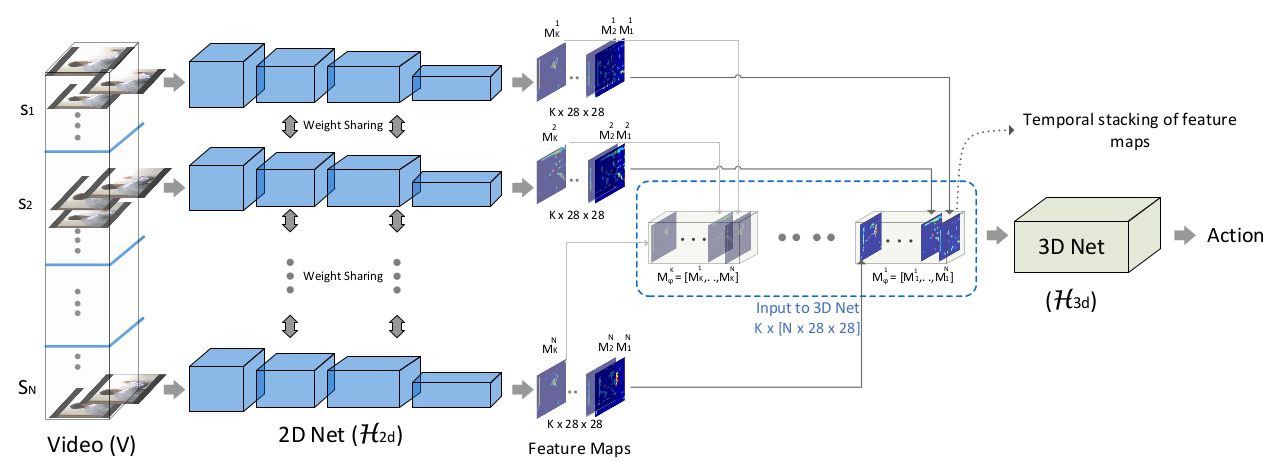
[6]より引用
結果:抽象概念は獲得できているのか?
事前学習にkineticsの学習モデルを使用するのが精度が出ると思われますが
今回はあくまで限られたデータソースから概念獲得ができるかどうかの実験であるため
学習はランダム初期値の重みから行います
入力フレームは30fpsで
optimizerはAdadeltaの条件はlr=1.0, rho=0.9, eps=1e-06, weight_decay=0です
カテゴリ分類精度(validデータ)
抽象概念:main_category分類精度結果
| main_category | train accuracy(%) | valid accuracy(%) |
|---|---|---|
| come, go(2 classes) | 80.0 | 96.7 |
| build, disassemble(2 classes) | 74.3 | 71.0 |
| goal, miss(2 classes) | 60.5 | 55.5 |
具体概念:sub_category分類精度結果
| sub_category | train accuracy(%) | valid accuracy(%) |
|---|---|---|
| come, go(6 classes) | 70.7 | 70.0 |
| build, disassemble(10 classes) | 76.8 | 38.0 |
| goal, miss(2 classes) | 57.2 | 36.4 |
(参考:hmdb事前学習モデル使用時の精度)
| sub_category | train accuracy(%) | valid accuracy(%) |
|---|---|---|
| come, go(6 classes) | 95.3 | 70.0 |
| build, disassemble(10 classes) | 95.0 | 31.0 |
| goal, miss(2 classes) | 80.5 | 54.5 |
分類精度からの考察
come, goはmain_category精度から見て抽象概念を獲得できている様子 です
ただしbuild, disassemble、goal, missは
概念の獲得をしたとは言いがたい精度になっています
この原因として現在の動画分類3DCNNのアーキテクチャは
UCFやkineticsといったデータセットをベンチマークとして用いているため
オブジェクト依存で分類を行うことに適していることが考えられます
ただtrainとvalid精度の差があり過学習が見られることから
適切な事前学習を用いれば精度を改善する余地はありそうです
tsneによる動画ベクトルの可視化結果(validデータ)
come goのうち4クラス(残り2クラスはあまりにvalid数が少ないので省略)
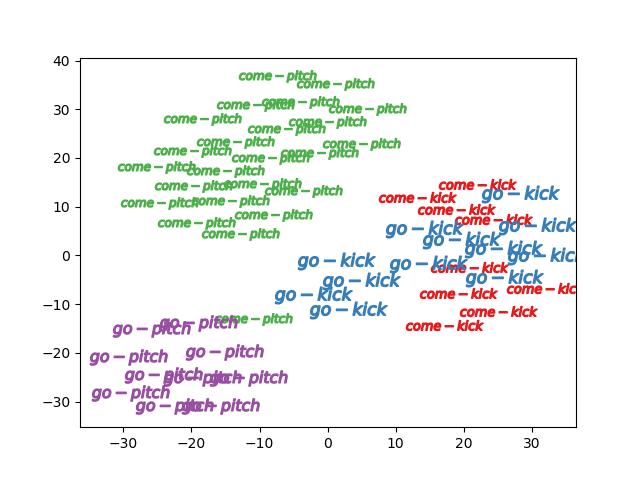
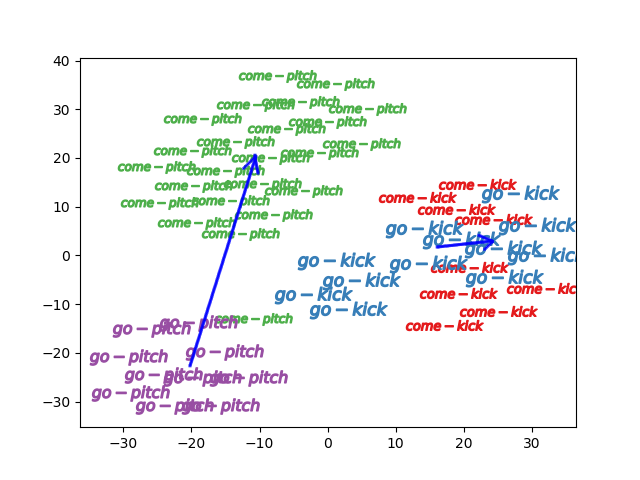
もしcome goの抽象概念が具体概念のみから
学習できているとするなら
特徴量ベクトルの差分は同じベクトルになると考えていますが
下の描画をみる限りは微妙です
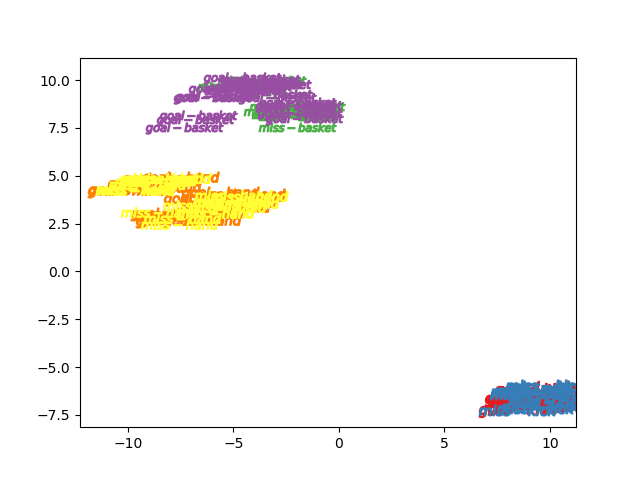
goal missの6クラス
スポーツの種類≒オブジェクト依存で分類されてしまっていて
goal missをそもそも区別できていない様子です
build disassembleの10クラス
こちらはうまくクラスごとに分離できていないようです
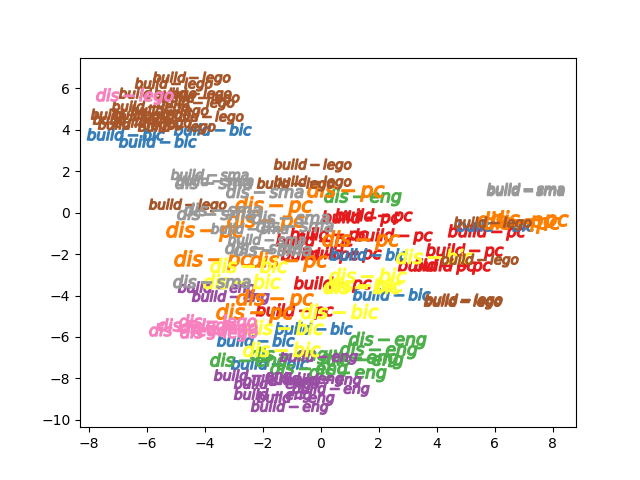
以上から、抽象概念の自動獲得は現状のアーキテクチャでは難しいものの
ラベル付きデータがあれば学習可能であることがわかりました
課題と今後
・コンピュータリソース
やはり動画を3DCNNで学習するにはコンピュータスペックが
かなり必要とされることがネックになりそうです
ECOliteであれば3Dresnetなどよりは何分の一などの計算量で済みますが
それでも普通のコンピュータで大規模データセットを学習するには1回のトライに1日くらいかかってしまいます
・データ量
「欲しい」と検討したジャンルの動画データが存在しないことはよくありました
build tentなども探したのですがdisassemble tentの方が数シーンしか見つからず
現状では人が見て楽しいか実用的だと思う動画でないと十分な量が得ることは難しそうです
(タグ付け対象をクリエイティブコモンズに限定していたこともありますが)
・機械学習アーキテクチャ
やはりオブジェクト依存でない、本当のaction recognitionという意味で理解できるような
タスクを用意すべきであるし(今回のデータセットはそれを叶える要素もありますが)
ニューラルネットでない仕組みも含めてベストな数学的に親和性あるシステムが構築できればなと思いました
感想
動画に関する機械学習が盛り上がってきているものの
やはりまだまだ始まりというイメージです
しかし徐々に動画が正確な知識・概念獲得につながると考える人は増えているようで
これから論文数も増えてきそうな印象でした
徐々に次の壁をデータ的・科学的に超える素養が高まってきていて
何かが起こる予感を感じます、新しい時代の到来の予感を!
参考文献
[1]"Temporal relational reasoning in videos" Debidatta Dwibedi, Pierre Sermanet, Jonathan Tompso.
[2]"Long-Term Feature Banks for Detailed Video Understanding" Chao-Yuan Wu, Kaiming He, Christoph Feichtenhofer, Philipp Krähenbühl, Haoqi Fan, Ross Girshick.
[3]"Imagine This! Scripts to Compositions to Videos", Tanmay Gupta, Dustin Schwenk, Ali Farhadi, Aniruddha Kembhavi.
[4]"Adversarial Inference for Multi-Sentence Video Description" Jae Sung Park, Marcus Rohrbach , Trevor Darrell , Anna Rohrbach.
[5]"Can spatiotemporal 3d cnns retrace the history of 2d cnns and imagenet?" Kensho Hara, Hirokatsu Kataoka, Yutaka Satoh.
[6]"ECO: Efficient Convolutional Network for Online Video Understanding", Mohammadreza Zolfaghari, Kamaljeet Singh and Thomas Brox.