はじめに
仕事の関係でPostgreSQLでの冗長構成の検討をしていたところ何も考えずにPostgreSQL12を採用して実施した。その後、PG-REXというLinux-HA Japanが提供している冗長構成の補助ツール?を見つけて意気揚々と導入しようとしたところPostgreSQL11までしか対応していないことに途中で気づき絶望を覚えながらもインターネット上でPAF(Postgresql Automatic Failover)というRAが使えるらしいという情報を見つけ、無事自動フェイルオーバー(FO)の実行まで行えたためナレッジの共有をしたいと思っています。
(投稿が遅いですが、検証時期は2020年03月頃です。そこから現在で状況が変わっている可能性があります。ご了承ください。)
概要
PostgreSQL12の自動FOをPacemaker+PAFで実現する。
構成
最終的なサーバ構成です。ちなみにDBは共有ディスクを使用せずにレプリケーション機能を用いるシェアード・ナッシング構成です。
・OS:RHEL 7.7
・ソフトウェア:
PostgreSQL12.1-2、Pacemaker1.1.21-1、PAF2.3.0-1
・使用資材:
| 製品名 | 資材名 |
|---|---|
| PostgreSQL | postgresql12-12.1-2PGDG.el7.x86_64.rpm |
| postgresql12-contrib-12.1-2PGDG.el7.x86_64.rpm | |
| postgresql12-devel-12.1-2PGDG.el7.x86_64.rpm | |
| postgresql12-docs-12.1-2PGDG.el7.x86_64.rpm | |
| postgresql12-libs-12.1-2PGDG.el7.x86_64.rpm | |
| postgresql12-server-12.1-2PGDG.el7.x86_64.rpm | |
| postgresql12-test-12.1-2PGDG.el7.x86_64.rpm | |
| Pacemaker | pacemaker-repo-1.1.21-1.1.el7.x86_64.rpm |
| PAF | resource-agents-paf-2.3.0-1.noarch.rpm |
構築の流れ
構築はPG-REXをもともと使おうとしたこともあり、前提としてPG-REXの構築手順書をベースに作っています。
基本的に手順書に沿って構築・設定を行い、変更したい部分だけ変えています。以下の順序で構築を進めます。
・構築手順書の準備
・環境構築〜その1 手順書に沿って設定〜
・環境構築〜その2 PAFのインストール〜
・環境構築〜その3 リソースの準備〜
・環境構築〜その4 リソースの反映〜
なお、構築時のIPアドレスやNIC名、LAN名称についても構築手順書の呼称、設定を使用します。
構築環境と手順書との違い
今回の構築で作成した構成と構築手順書に記載の構築との違いについて説明します。
- インターコネクトLAN2はDB-LANを使用しています。
- Slaveの冗長(vip-slave)の設定は行いません。
構築手順書の準備
まず、構築手順書を入手するためLinux-HA Japanの公式サイトからPG-REXのパッケージをダウンロードします。(https://ja.osdn.net/projects/pg-rex/releases/)
環境によっても違うかと思いますが私の場合は「pg-rex11-2.0-NoSTONITH-1.tar.gz」をダウンロード。STONITHは主系と副系の二重起動(スプリットブレイン)を防ぐためにFOする際に管理ポート経由で旧Masterのサーバーを停止する機能です。私の場合は仮想環境で管理ポートを用意できなかったため使用しないNoSTONITHで構築を進めました。
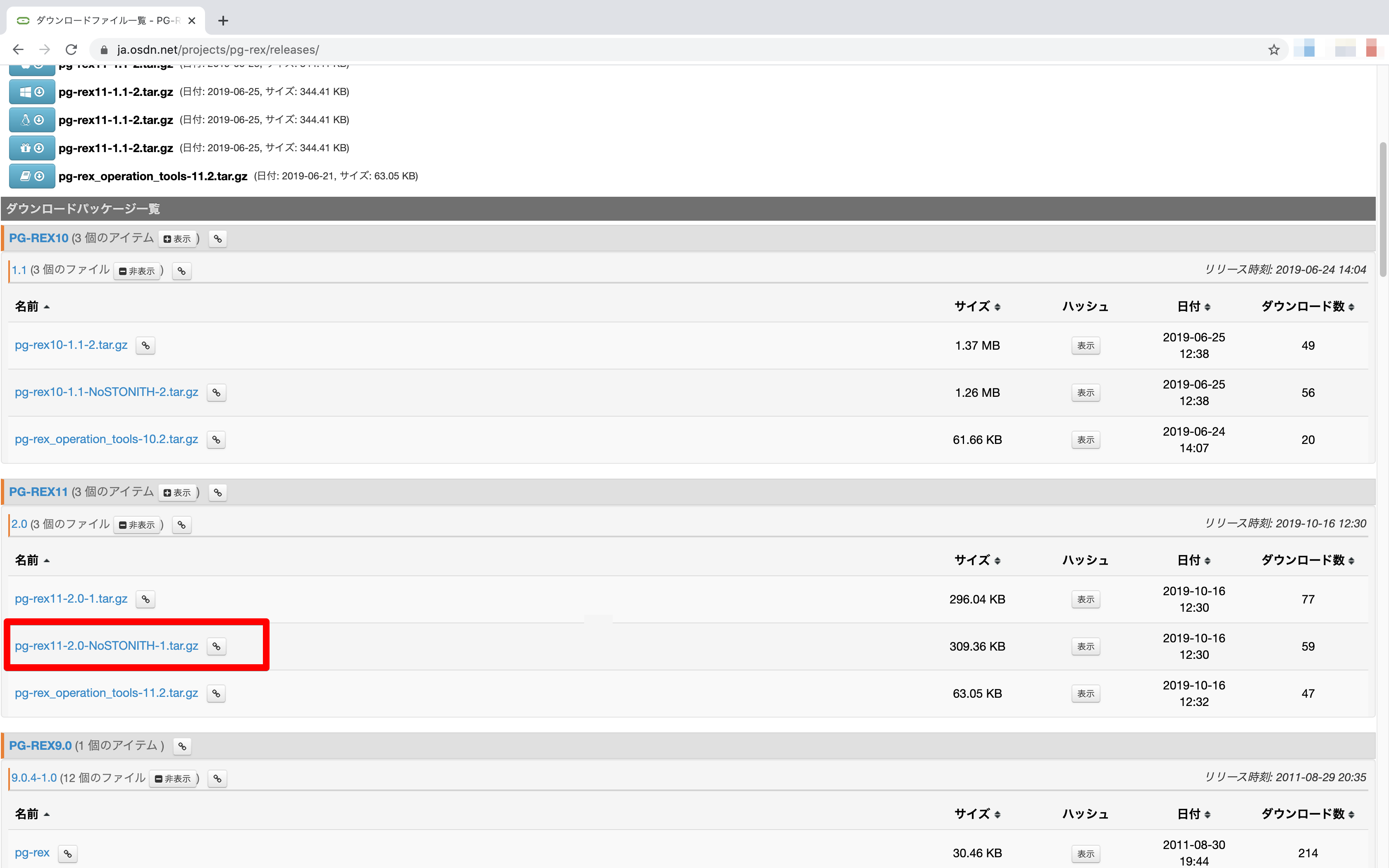
ダウンロードしてファイルを解答するとPG-REX10-1.1_NoSTONITH_docs.zip内に「PG-REX10利用マニュアル_STONITHなし__第1.0.1版(公開用利用者マニュアル).docx」というファイルがあります。これが構築手順書になります。
環境構築〜その1 手順書に沿って設定〜
構築手順書の3.1. ネットワーク〜3.4. PostgreSQLを参考にインストールや設定を進めます。
私の場合はDBディレクトリなど一部読み替えをしましたがほぼ手順書の通りに進めました。
この時点でクラスタリングの構成は完了します。Pacemakerを起動して以下のような状態になればOKです。
Stack: corosync
Current DC: tdbs01.localdomain (version 1.1.21-1.el7-f14e36f) - partition with quorum
Last updated: Wed Jun 24 11:21:32 2020
Last change: Wed Jun 24 11:21:27 2020 by hacluster via crmd on pgrex01
2 nodes configured
0 resources configured
Online: [ pgrex01 pgrex02 ]
No resources
Node Attributes:
* Node pgrex01:
+ ringnumber_0: 192.168.1.1 is UP
+ ringnumber_1: 192.168.3.1 is UP
* Node pgrex02:
+ ringnumber_0: 192.168.1.2 is UP
+ ringnumber_1: 192.168.3.2 is UP
Migration Summary:
* Node pgrex01:
* Node pgrex02:
手順書と設定を変えている箇所
-
「3.4. PostgreSQL」でのDBクラスタのディレクトリはデフォルト(/var/lib/pgsql/12/data)で構築しています。
-
「3.4.5. postgresql.confの編集」でのpostgresql.confについて以下の箇所を変更しています。
| パラメータ名 | 設定値 | 変更理由 |
|---|---|---|
| hba_file | '/var/lib/pgsql/12/pg_hba.conf' | レプリケーション時にMasterからSlaveへ上書きされないように一つ上の階層を格納先に指定する。 |
| include | '/var/lib/pgsql/12/standby.conf' | Pacemaker経由での起動時に必須の設定。スタンバイサーバがプライマリサーバへ接続するための設定(primary_conninfo)を記載するファイル。サーバ毎に自身のサーバ名を記載する必要があるため、レプリケーション時にMasterからSlaveへ上書きされないように一つ上の階層を格納先に指定する。 |
- 上記変更理由からstandby.confを新規作成する
pgrex01でpostgresユーザにスイッチし、standby.confの作成する
host:運用LANの仮想IP、application_name:自サーバ名を記載する
$ vi ~/12/standby.conf
primary_conninfo = 'host=192.168.0.10 port=5432 user=sysrep application_name=pgrex01'
$ chmod 600 ~/12/standby.conf
同様にpgrex02でpostgresユーザにスイッチし、standby.confの作成する
$ vi ~/12/standby.conf
primary_conninfo = 'host=192.168.0.10 port=5432 user=sysrep application_name=pgres02'
$ chmod 600 ~/12/standby.conf
- 「1.6.7. pg_hba.conf.confの編集」での設定値と格納先を変更します
まずファイルをデフォルトの$PGDATA配下から一つ上の階層にコピーします。
$ cp -p $PGDATA/pg_hba.conf ~/12/.
続いて対向のD-LANについてはMETHODを[md5]に自身のD-LANについてはMETHODを[reject]となるように設定します。(RAの誤動作で自身にレプリケーションを行わないようにrejectする。)
pgrex01でpostgresユーザにスイッチし、pg_hba.confを修正する
$ vi ~/12/pg_hba.conf
host replication sysrep 192.168.2.2/32 md5
host replication sysrep 192.168.2.1/32 reject
同様にpgrex02でpostgresユーザにスイッチし、pg_hba.confを修正する
$ vi ~/12/pg_hba.conf
host replication sysrep 192.168.2.1/32 md5
host replication sysrep 192.168.2.2/32 reject
環境構築〜その2 PAFのインストール〜
PAFをインストールするため、パッケージをダウンロードしてきます。ファイルはGitにアップロードされています。
(https://github.com/ClusterLabs/PAF/releases)
ダウンロードするファイルは「resource-agents-paf-2.3.0-1.noarch.rpm」です。リリースノートを見るとわかるのですがPostgreSQL12をサポートという記述があります。これのおかげでPacemakerでのPostgreSQL自動フェイルオーバーが実現できます。
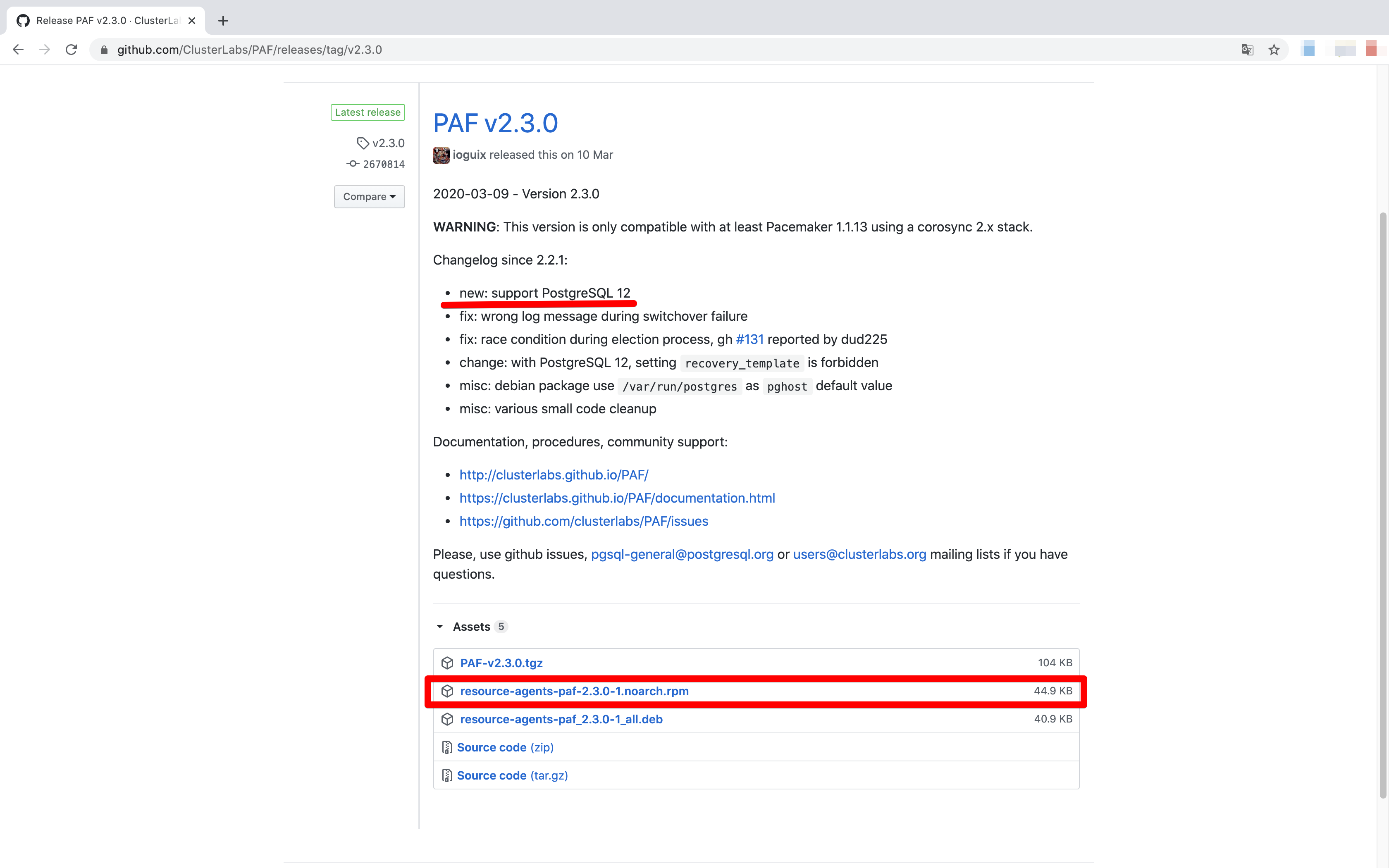
ここのDocumentationページをみるとリソースの設定方法など英語ですが色々と記載があります。今回のリソースはここを参考に設定をしています。
PAFをダウンロードしたらyumでダウンロードしていきます。(以下ではrpmファイルを/tmp配下に配置した状態で実施しています。)
各サーバでrootユーザにスイッチし、PAFのRAをインストールする
# yum install -y resource-agents-paf-2.3.0-1.noarch.rpm
読み込んだプラグイン: product-id, search-disabled-repos, subscription-manager
Repository rhel-7-server-rpms is listed more than once in the configuration
resource-agents-paf-2.3.0-1.noarch.rpm を調べています: resource-agents-paf-2.3.0-1.noarch
resource-agents-paf-2.3.0-1.noarch.rpm をインストール済みとして設定しています
依存性の解決をしています
--> トランザクションの確認を実行しています。
(略)
完了しました!
環境構築〜その3 リソースの準備〜
リソース設定用のファイル(.crm)を作成するにあたり、Linux-HA Japanのサイト内にある「動かして理解するPacemaker ~CRM設定編~」という記事を参考にしています。(http://linux-ha.osdn.jp/wp/archives/3786)
私はCRMの仕組みを全く理解していない状態で検討を始めたため、基礎を理解するのにとても役にたちました。CRMファイルもここからダウンロードできるものをベースに修正を加えています。
CRMファイルの書き方
「構築手順書の準備」でダウンロードした構築手順書と同ディレクトリにある「PG-REX10_NoSTONITH_pm_crmgen.xls」をベースに変更箇所を説明します。CRMファイルの作成方法は上で話した記事を参考にExcelファイル内に記載されている設定値を作成していく形になります。
ファイル作成の一例です。
例えば、CRMファイルを参考にExcelファイル上の「#表 2-1 クラスタ設定 … クラスタ・プロパティ」を定義すると以下になります。
### Cluster Option ###
property no-quorum-policy="ignore" \
stonith-enabled="false"
同様にExcelファイル上の「#表 4-1 クラスタ設定 … リソース構成」「#表 5-1 クラスタ設定 … リソース・パラメータ」を定義すると以下になります。
### Group Configuration ###
group master-group ¥
vip-master ¥
vip-rep
### Master/Slave Configuration ###
ms msPostgresql \
pgsql \
meta \
master-max="1" \
master-node-max="1" \
clone-max="2" \
clone-node-max="1" \
notify="true"
このような形でファイルを作成していきます。
Excelからの設定変更箇所
Excelに記載の内容をベースにした時、ベースから変更した箇所は以下となります。
※ オレンジ部分は前提として環境に合わせて変更してください。不明な場合は構築手順書を参考にどうぞ。
- #表 7-1-6 クラスタ設定 … Primitiveリソース (id=pgsql)
- #表 8-1 クラスタ設定 … リソース配置制約
表 7-1-6 クラスタ設定 … Primitiveリソース (id=pgsql)
この箇所はPacemakerにデフォルトで入っているPostgreSQLリソース「pgsql」からPAFリソース「pgsqlms」へ変更します。
変更箇所の一つ目は「params」に記載の内容です。前にも記載しましたが設定内容はPAFダウンロードページのDocumentationを参考にしています。
| パラメータ種別 | 項目 | 設定内容 | 概要 |
|---|---|---|---|
| params | system_user | "postgres" | システムユーザを指定 |
| bindir | "/usr/pgsql-12/bin" | PostgreSQLのbinディレクトリを指定 | |
| pgdata | "/var/lib/pgsql/12/data" | PostgreSQLのクラスタDBを指定 | |
| pgport | "5432" | PostgreSQLのポートを指定 |
変更箇所の二つ目は自動フェイルオーバーさせるためにdemoteの設定を変えていきます。今回の構築ではNoSTONITHかつ自動フェイルオーバーを実現したいため、demoteのon_failを「block」から「ignore」に変えています。
デフォルトの「block」だとPostgreSQLのプロセスが死んだ時に死んだプロセスに対してdemoteでプロセスの停止をかけようとするためプロセス停止に失敗してon_failで止まってしまい自動的にフェイルオーバーしてくれません。これはスプリットブレインを防ぐための仕様の動きであると理解しています。おそらく自動フェイルオーバー したいならSTONITHで構築してねってことなんですかね。この辺の説明はあまり自信ありません。
| オペレーション | タイムアウト値 | 監視間隔 | on_fail(障害時の動作) | 役割 | 備考 |
|---|---|---|---|---|---|
| start | 300s | 0s | restart | ||
| monitor | 60s | 10s | restart | ||
| monitor | 60s | 9s | restart | Master | |
| promote | 300s | 0s | restart | ||
| demote | 300s | 0s | restart | ||
| notify | 60s | 0s | restart | ||
| demote | 300s | 0s | ignore |
表 8-1 クラスタ設定 … リソース配置制約
この箇所はPAFを使用することにより設定が変わります。私は以下で設定しました。
location rsc_location-msPostgresql-1 msPostgresql \
rule -INFINITY: not_defined default_ping_set or default_ping_set lt 100 \
rule -INFINITY: not_defined diskcheck_status_internal or diskcheck_status_internal eq ERROR
最終的なCRMファイルのサンプルはGit上にアップロードしています、参考にどうぞ。
<!!!!!!!GitのURLはる!!!!!!>
環境構築〜その4 リソースの反映〜
リソースの反映は以下の順序で実施します。こちらも構築手順書を参考にしています。
① Pacemaker、PostgreSQLがそれぞれ停止していることを確認
② pgrex01でPostgreSQLを起動
③ pgrex02でpgrex01からPostgreSQLのベースバックアップから取得、起動確認
④ pgrex01、pgrex02それぞれでPostgreSQLを停止
⑤ pgrex01、pgrex02それぞれでPacemakerを起動
⑥ pgrex02をonlineからstandbyに変更
⑦ pgrex01でcrmファイルの反映
⑧ pgrex02をstandbyからonlineに変更
① pgrex01、02でPacemaker、PostgreSQLがそれぞれ停止していることを確認します
# systemctl status pacemaker
● pacemaker.service - Pacemaker High Availability Cluster Manager
Loaded: loaded (/etc/systemd/system/pacemaker.service; disabled; vendor preset: disabled)
Active: inactive (dead)
② pgrex01でPostgreSQLを起動します
postgresユーザにスイッチし、PostgreSQLが起動していないことを確認します。
# su - postgres
$ pg_ctl status
pg_ctl: サーバが動作していません
PostgreSQLを起動します。
$ ls -l $PGDATA/standby.signal
ls: standby.signal にアクセスできません: そのようなファイルやディレクトリはありません
※ standby.signalファイルが存在する場合は削除をしてください
$ pg_ctl start
サーバの起動完了を待っています....
:(略)
完了
サーバ起動完了
③ pgrex02でpgrex01からPostgreSQLのベースバックアップから取得、起動確認
pgrex02でpostgresユーザにスイッチし、既存のデータファイルを削除します。
# su - postgres
$ rm -rf /var/lib/pgsql/12/data/*
pgrex02でpgrex01からデータベースバックアップを取得します。
$ pg_basebackup -h 192.168.2.2 -D $PGDATA -X stream --progress -U sysrep
pgrex02でPostgreSQLの起動確認をします。
$ pg_ctl start
サーバの起動完了を待っています....
:(略)
完了
サーバ起動完了
$ pg_ctl status
pg_ctl: サーバが動作中です(PID: xxxxx)
/usr/pgsql-12/bin/postgres "-D" "/var/lib/pgsql/12/data"
④ pgrex01、pgrex02それぞれでPostgreSQLを停止
pgrex01、02でPostgreSQLを停止します。
$ pg_ctl stop
サーバは停止しました
$ exit
⑤ pgrex01、pgrex02それぞれでPacemakerを起動
pgrex01、pgrex02でPacemakerを起動します。rootユーザで実行します。
# rm -rf /var/lib/pacemaker/cib/*
※ CRM定義ファイルを完全削除したい場合に実施する。初回は不要
# systemctl start pacemaker
# systemctl status pacemaker
● pacemaker.service - Pacemaker High Availability Cluster Manager
Loaded: loaded (/etc/systemd/system/pacemaker.service; disabled; vendor preset: disabled)
Active: active (running) since 金 2020-05-01 11:39:54 JST; 5s ago
クラスターの起動を確認します。(pgrex01、pgrex01どちらかで実行)
# crm_mon –fA
Stack: corosync
:(略)
Online: [ pgrex01 pgrex02 ] … ★ 両ノードがOnlineになっていること
:(略)
* Node pgrex01:
+ ringnumber_0: 192.168.1.1 is UP
+ ringnumber_1: 192.168.3.1 is UP
* Node pgrex02:
+ ringnumber_0: 192.168.1.2 is UP
+ ringnumber_1: 192.168.3.2 is UP
:(略)
⑥ pgrex02をonlineからstandbyに変更
pgrex01で待機系(pgrex02)がMasterで起動しないようにcrmファイルのロード前に状態をSTANDBYに変更します。
# crm node standby pgrex02
# crm_mon –fA
Stack: corosync
:(略)
Node pgrex02: standby … ★ pgrex02がstandbyになっていること
Online: [ pgrex01 ]
:(略)
⑦ pgrex01でcrmファイルの反映
pgrex01でcrmファイルのロード・アップデートを行います。(CRM定義ファイルを/tmpに格納していることとします。)
# cd /tmp
# ls -l RHEL7_pm_env.crm
-rw-rw-r-- 1 cloud-user cloud-user 4185 5月 19 15:58 RHEL7_pm_env.crm
# crm configure load update RHEL7_pm_env.crm
# crm_mon -fA
Stack: corosync
:(略)
vipCheckMaster (ocf::heartbeat:VIPcheck): Started pgrex01
Resource Group: master-group
vip-master (ocf::heartbeat:IPaddr2): Started pgrex01 … ★ pgrex01で起動していること
vip-rep (ocf::heartbeat:IPaddr2): Started pgrex01 … ★ pgrex01で起動していること
Master/Slave Set: msPostgresql [pgsql]
Masters: [ pgrex01 ] … ★ pgrex01がMastersとなっていること
Stopped: [ pgrex02 ] … ★ pgrex02がStoppedとなっていること
Clone Set: clnDiskd1 [prmDiskd1]
Started: [ pgrex01 ] … ★ pgrex01がStartedとなっていること
Stopped: [ pgrex02 ] … ★ pgrex02がStoppedとなっていること
Clone Set: clnPing [prmPing]
Started: [ pgrex01 ] … ★ pgrex01がStartedとなっていること
Stopped: [ pgrex02 ] … ★ pgrex02がStoppedとなっていること
:(略)
* Node pgrex02:
+ master-pgsql : -1000 … ★ -1000(停止)となっていること
:(略)
※ [crm configure]コマンド実行時に以下のようなメッセージが表示されることがありますが、Pacemakerの動作に問題はありません。(構築手順書から抜粋)
WARNING: pgsql: specified timeout 60s for notify is smaller than the advised 90
⑧ pgrex02をstandbyからonlineに変更
pgrex01で待機系(pgrex02)の状態をOnlineに変更します。
# crm node online pgrex02
# crm_mon -fA
Stack: corosync
:(略)
Master/Slave Set: msPostgresql [pgsql]
Masters: [ pgrex01 ]
Slaves: [ pgrex02 ] … ★ pgrex02がSlavesとなっていること
Clone Set: clnDiskd1 [prmDiskd1]
Started: [ pgrex01 pgrex02 ] … ★ 両ノードがStartedとなっていること
Clone Set: clnPing [prmPing]
Started: [ pgrex01 pgrex02 ] … ★ 両ノードがStartedとなっていること
:(略)
* Node pgrex02:
+ default_ping_set : 100
+ diskcheck_status_internal : normal
+ master-pgsql : 1000 … ★ 1000 or 1001(起動)となっていること
:(略)
試しにフェイルオーバー
PostgreSQLのプロセスをkillで落として、擬似的なアプリケーション障害を発生させます。
まずはpgrex01でプロセス番号の確認をします。
# su - postgres
-bash-4.2$ pg_ctl status
pg_ctl: サーバが動作中です(PID: 4258)
/usr/pgsql-12/bin/postgres "-D" "/var/lib/pgsql/12/data"
-bash-4.2$ exit
次にpgrex01でプロセスをkillします。
# kill -9 4258
状態を確認します。
# crm_mon -rfA
Waiting until cluster is available on this node ...
Stack: corosync
Current DC: pgrex02 (version 1.1.21-1.el7-f14e36f) - partition with quorum
Last updated: Wed May 20 18:05:21 2020
Last change: Wed May 20 18:04:49 2020 by root via crm_attribute on pgrex02
2 nodes configured
9 resources configured
Online: [ pgrex01 pgrex02 ]
Full list of resources:
vipCheckMaster (ocf::heartbeat:VIPcheck): Started pgrex02
Resource Group: master-group
vip-master (ocf::heartbeat:IPaddr2): Started pgrex02
vip-rep (ocf::heartbeat:IPaddr2): Started pgrex02
Master/Slave Set: msPostgresql [pgsql]
Masters: [ pgrex02 ]
Stopped: [ pgrex01 ]
Clone Set: clnDiskd1 [prmDiskd1]
Started: [ pgrex01 pgrex02 ]
Clone Set: clnPing [prmPing]
Started: [ pgrex01 pgrex02 ]
Node Attributes:
* Node pgrex01:
+ default_ping_set: 100
+ diskcheck_status_internal: normal
+ master-pgsql: -1000
+ ringnumber_0: 192.168.1.1 is UP
+ ringnumber_1: 192.168.3.1 is UP
* Node pgrex02:
+ default_ping_set: 100
+ diskcheck_status_internal: normal
+ master-pgsql: 1001
+ ringnumber_0: 192.168.1.2 is UP
+ ringnumber_1: 192.168.3.2 is UP
Migration Summary:
* Node pgrex01:
pgsql: migration-threshold=1 fail-count=2 last-failure='Wed May 20 18:04:03 2020'
* Node pgrex02:
Failed Resource Actions:
* pgsql_stop_0 on mdbs01 'unknown error' (1): call=85, status=complete, exitreason='Unexpected state for instance "pgsql" (returned 9)',
last-rc-change='Wed May 20 18:04:37 2020', queued=0ms, exec=226ms
Connection to the cluster-daemons terminated
各RAがpgrex02で起動していることを確認できました。
戻す場合は一度、pgrex01でpgrex02からデータバックアップを取得して、Pacemakerの障害情報をクリアした後にPostgreSQLを起動してあげます。