はじめに
Azure Machine Learningにはマイクロソフト社独自のレコメンドの機能(Matchbox recommender)を使ってY!映画のレコメンデーションモデルを作成してみたいと思います。
Y!映画のレコメンデーション
以下はY!映画のレビューの評価点数を使い、協調フィルタリングを行う手順です。
データ
協調フィルタリングで必要なデータは「ユーザ、映画タイトル、評価点数」の3つです。
例)
| user | title | score |
|---|---|---|
| user001 | 君の名は。 | 5 |
| user001 | シン・ゴジラ | 1 |
| user002 | 君の名は。 | 3 |
| user003 | オデッセイ | 4 |
| user003 | アバター | 5 |
※scoreの形式はintegerです。範囲は1から5で大きな数字ほど評価が高くなります。
今回は以下2つのcsvファイルを用意しました。
モデル作成の過程で2つのファイルを結合し、上記の形に整形します。
cinemaid.csv
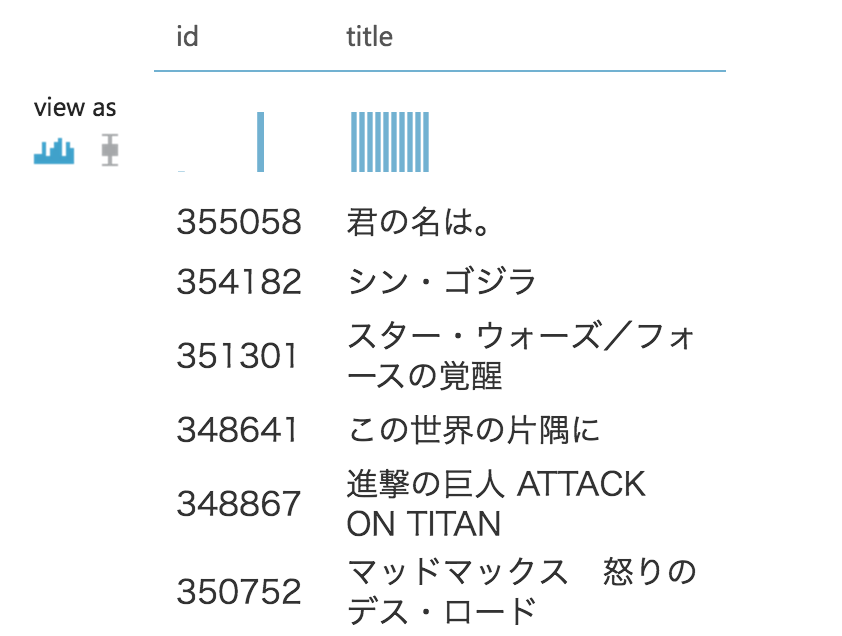
| id | title |
|---|---|
| 355058 | 君の名は |
| 354182 | シン・ゴジラ |
| 351301 | スター・ウォーズ/フォースの覚醒 |
※レビュー投稿数が多い映画タイトル3,000作品をサンプルとして抽出してます。
movie_review.csv
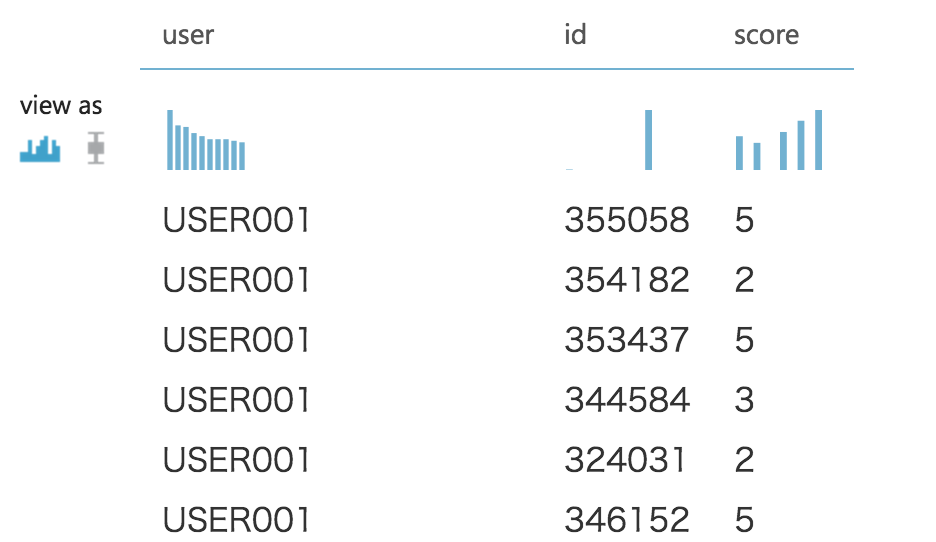
| user | id | score |
|---|---|---|
| user001 | 355058 | 5 |
| user001 | 354182 | 1 |
| user002 | 351301 | 3 |
※上記の映画に書かれたお役立ち度の高いレビューが約28万件でユーザ数は約8万件です。
次のステップへ行く前にローカルにあるcsvファイルをアップロードしておきます。
Azure Machine Learning Studio > DATASET > ページ下の+NEW の順にクリックしファイルをアップロードします。
モデル
Azure Machine Learning Studio > EXPERIMENTS > ページ下の+NEW > Blank Experimentの順にクリックし新規に実験を作成します。
実験名は「Test Movie Recommend」とします。
左の実験のメニューから必要なアイテムをドラッグドロップして以下のように配置します。

各モジュールの説明をします。
基本的な配置は分類や回帰など他の機械学習モデルでも同じになります。
データの配置と前処理
先ほどアップロードしたファイルを以下から探し、ドラッグ&ドロップで配置します。
Azure Machine Learning Studio > Saved Datasets > My Datasets
ローカルのファイルではなくAzure StorageやAzure DocumentDBからインポートする手順は場合はこちらを参照してください。
Azure Machine LearningとAzure Storage/DocumentDBを連携させる

下図の部分をクリックしてVisualizeから詳細を確認できます。
movie_review.csv
cinemaid.csv
次に2つのファイルを結合し、user、title、scoreの3つのデータを抜き出します。
またuser、titleがユニークになるようにします。
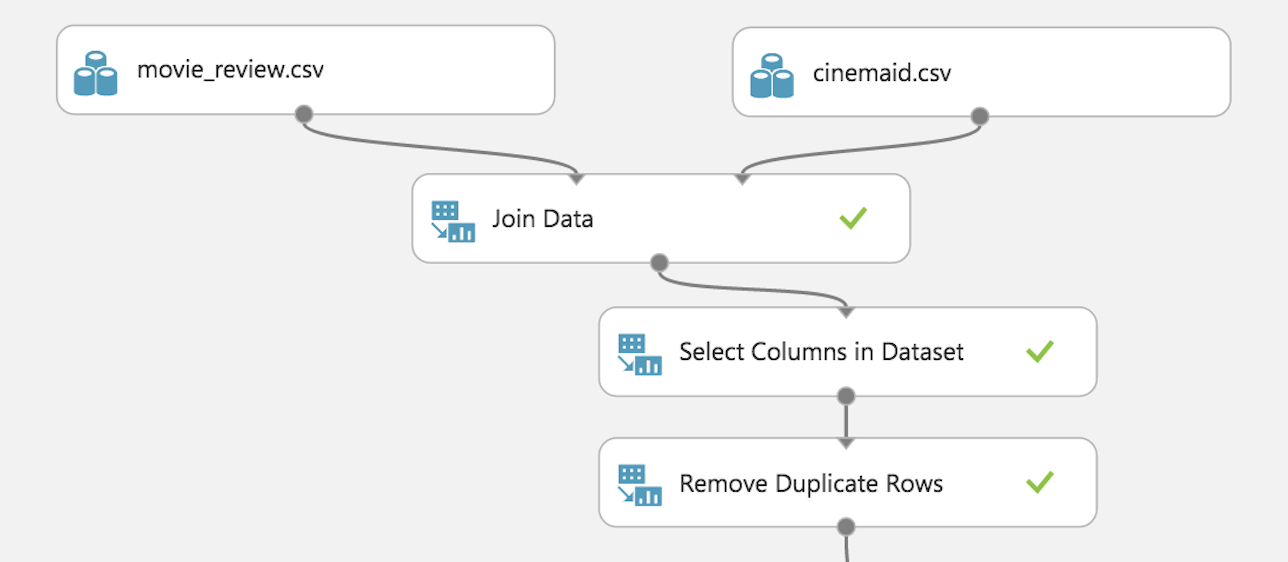
・Join Data
Data Transformation > Manipulation > Join Data
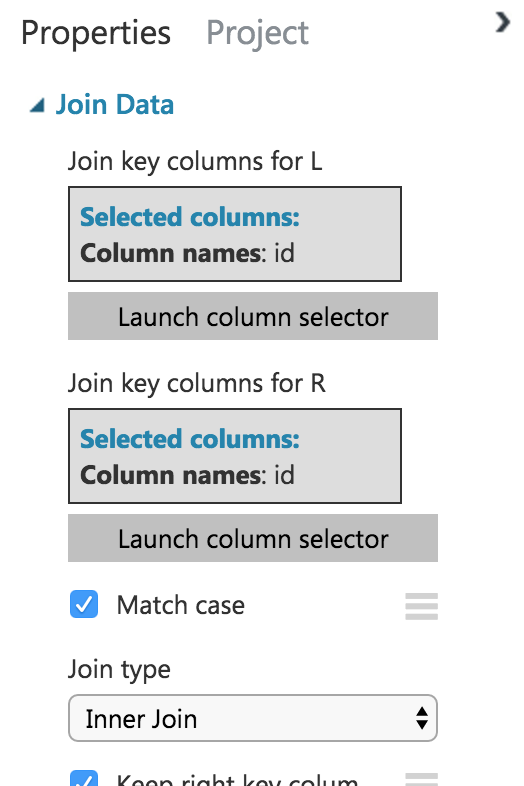
結果は以下のようになります。
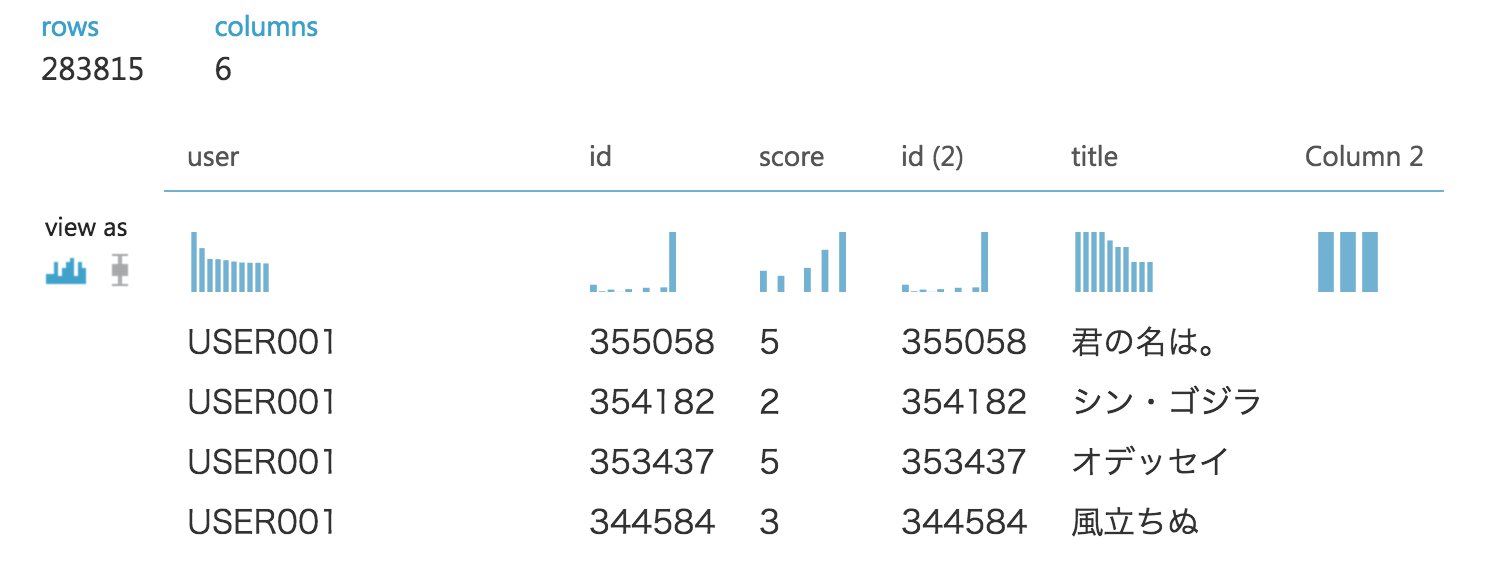
・Select Columns in Dataset
Data Transformation > Manipulation > Select Columns in Datasetから選択し配置しuser、title、score を選択します。
結果は以下のようになりました。
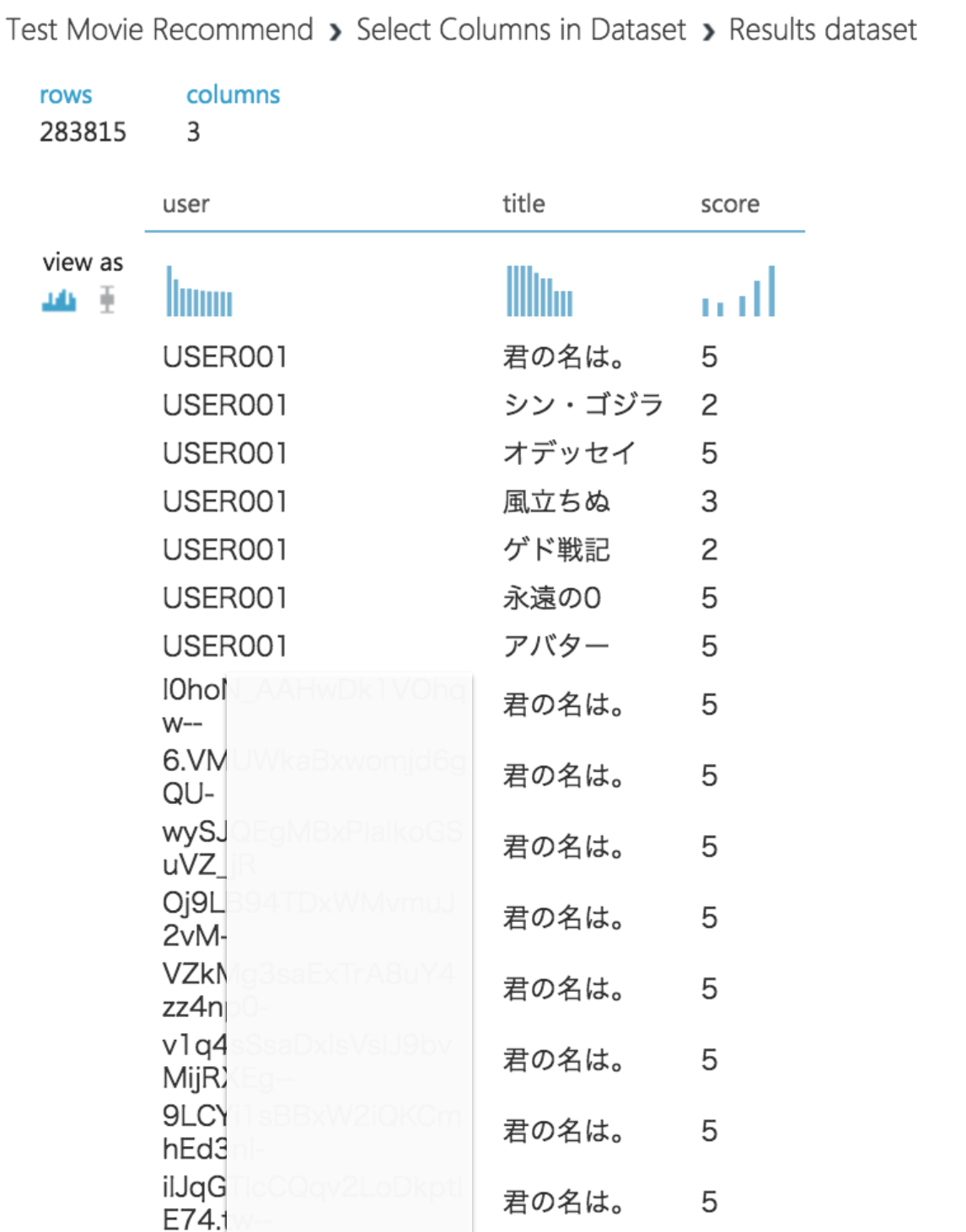
※USER001は確認用のダミーデータですが、それ以外は本物のデータなのでUSER名は伏せてあります。
・Remove Duplicate Rows
userとtitleがユニークになるようにします。
Data Transformation > Manipulation > Remove Duplicate Rows

学習用データとテストデータのセットに分割

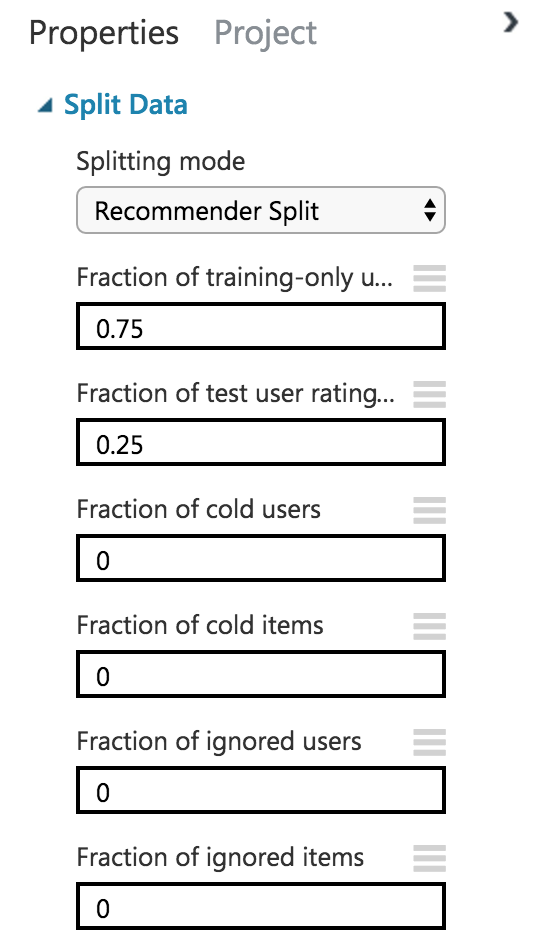
Data Transformation > Sample and Split > Split Data
「Splitting mode」を「Recommender Split」へ変更し、学習用データの割合を0.75(デフォルトは0.5)、テスト用は0.25に設定します。
モデルのトレーニング

先ほど分割した学習用データを使って学習させます。
Machine Learning > Train > Train Matchbox Recommender
パラメータは特にいじらずデフォルトのままにします。
モデルの評価
Split Dataで分割した25%のテスト用データにスコアをつけて効果を確認します。
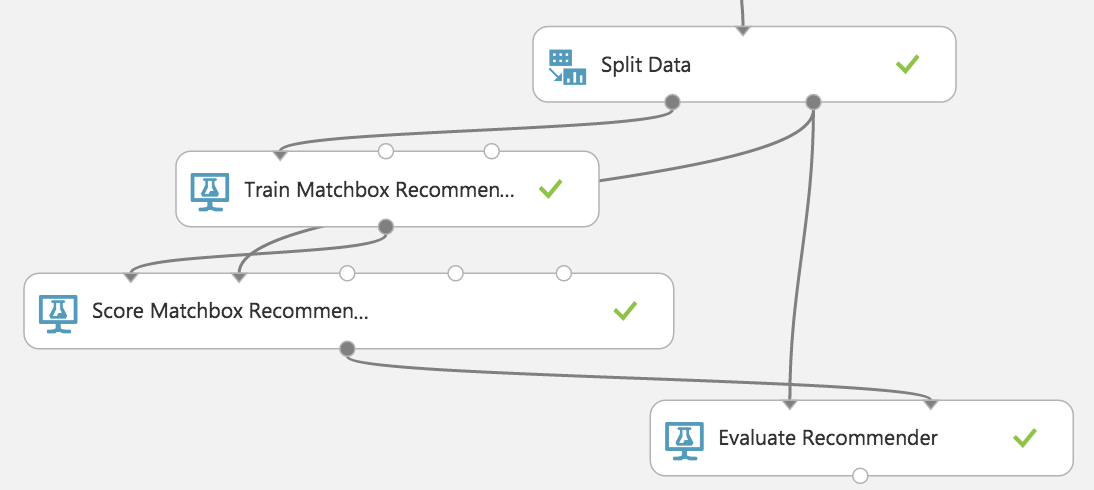
Machine Learning > Score > Score Machbox Recommender
Train Machboxモジュールとテスト用データをつなぎます。
パラメータは特にいじらずデフォルトのままにします。
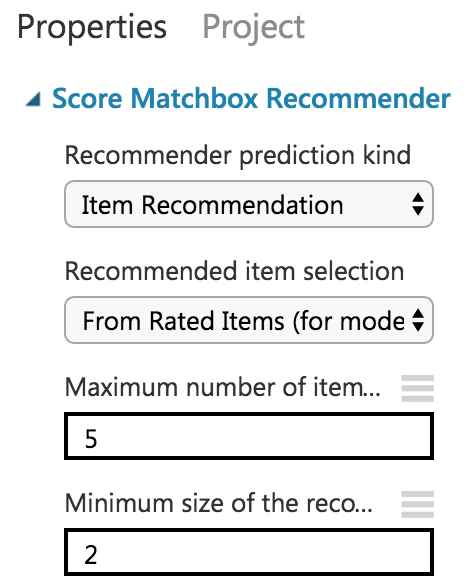
レコメンデーションモデルの精度を評価する場合はRecommended item selectionの選択を「From Rated Items」にします。この場合は自分が評価した作品の中からオススメする作品が選ばれます。全てのアイテムからオススメされるようにするには「From All Items」に変更します。まずはモデルの評価を行いたいので「From Rated Items」のままで進めていきます。
Machine Learning > Evaluate > Evaluate Recommender
レコメンドデータとテスト用データと照らし合わせて誤差を求めるためEvaluate Recommenderを配置し、テストデータとScore Matchboxモジュールをつなぎます。
RUNを実行
すべて配置が完了したのでRUNを実行します。
結果を確認
 この部分をクリックし、Visualizeをクリックして結果を確認します。
この部分をクリックし、Visualizeをクリックして結果を確認します。

NDCGはユーザへオススメされた映画がどれくらい適切かを表すもので1に近いほど精度が高いといえます。
今回はNDCGが0.947という結果でしたのでなかなか良い結果が出たと思います。
すべてのアイテムからレコメンドされるように変更
Evaluate Recommenderを削除して結果をCSVファイルに落として確認するためにConvert to CSVを配置します。
配置が完了したら、Score Machbox Recommenderを以下のように修正します。

RUNを実行し結果を確認します。
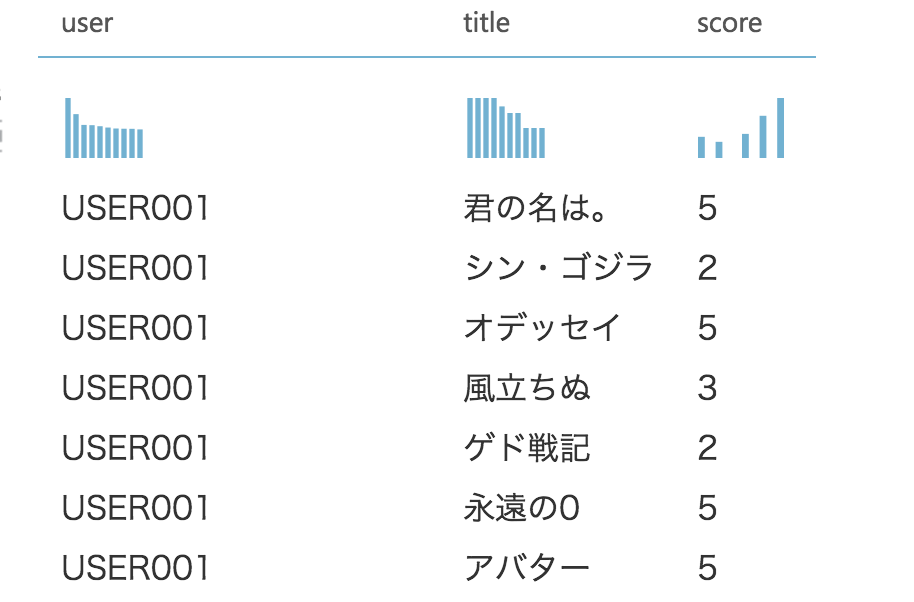
・USER001が点数をつけた映画
・オススメされた5つの映画
「劇場版マクロスF ~サヨナラノツバサ~」,「マイケル・ジャクソン THIS IS IT」,「任侠ヘルパー」,「フラガール」,「ウルトラマンメビウス&ウルトラ兄弟」
※優先度の高い順に並んでいます。
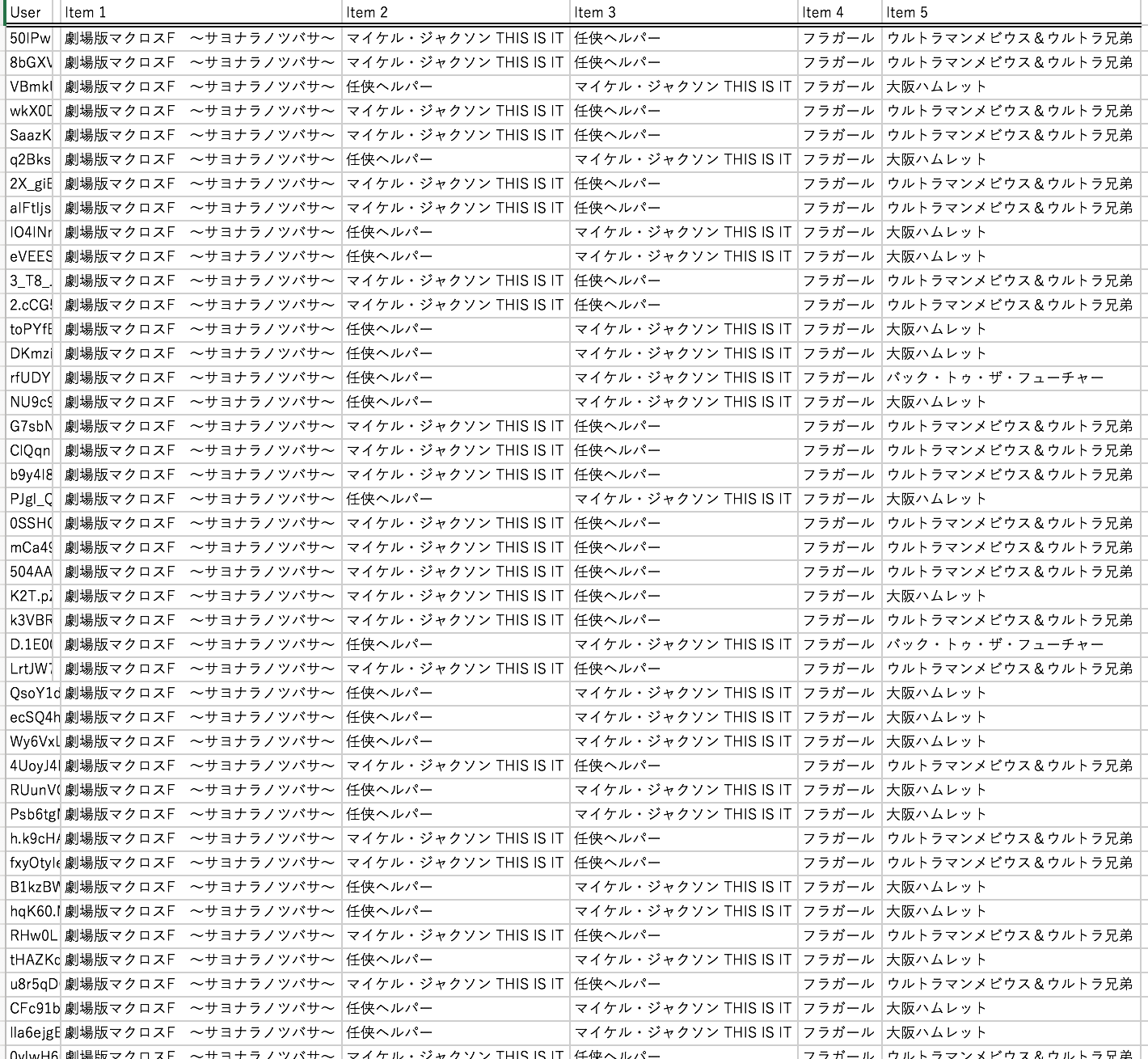
一部ですが、その他のユーザの結果は以下になります。
おわりに
Azure Machine Learningでプログラムを一切することなく簡単にレコメンデーションモデルの作成ができました。
USER001の結果を見てみますと、評価した映画とは違うものがオススメされているのを確認できました。
しかし、ほとんどのユーザに対して上記と同じような映画がオススメされているのでもう少し精度を向上させたいと思います。
今回はTrain Matchbox Recommenderへインプットしたデータはレビューの評価点数だけでしたが、他にもユーザ属性(年齢、性別、好きなジャンルなど)と作品属性(監督、メインキャストなど)をインプットすることができます。
これらを使うことでより精度の高い結果が得られるはずなので今後試してみたいと思います。