TL;DR
画像圧縮するベストな方法(2025)で述べた通り、AVIFは現状でWebで使うには最良のフォーマットです。
ここでは、AVIFを最適・最大圧縮・最速で使うオプションを説明します。
2025年現在では、日本語情報としては、最も詳しい情報だと思います。
最初に、コマンドを示しておきます。
用いるAVIFのエンコーダツールは、avifencです。
q=80で圧縮を想定(16コアCPU)
- 最適な設定
avifenc.exe -q 80 -y 444 --nclx 1/1/1 -j 16 --autotiling -a tune=11 src.png dest.avif
- 最大圧縮設定 (src.pngは、輝度値4倍にした16-bit png)
avifenc.exe -q 80 -y 444 --nclx 1/1/1 -s 0 -a tune=11 -d 10 src.png dest.avif
- 最速圧縮設定(最速設定でもWebPよりも高圧縮かつ高速です。)
avifenc.exe -q 80 -y 420 -s 9 -j 16 --tilecolslog2 6 --tilerowslog2 6 -a tune=11 src.png dest.avif
はじめに
AVIFを含む最近の画像圧縮ツールは、様々なアルゴリズムの集合を選択的に使うように動きます。
ここでは、細かなツールはできるだけブラックボックスに収めた状態で、明示的に扱ったほうが良いものだけに着目して説明していきます。
説明する該当オプションは下記になります。
品質への効果が大きい順に説明し、最後に並列化について説明します。
- -q
- 品質の設定
- -s (--speed)
- いろんなオプションをまとめた設定スイッチ(0が最高圧縮で遅く、9が軽量で高速)
- -a tune={psnr, ssim, butteraugli, iq, 11}
- RD最適化の品質尺度指定(11はSSIMULACRA2モードですが、まだマクロがついてません)
- -d (--depth) {8, 10, 12}
- ビット深度の設定。デフォルトは8
- -y (--yuv) {400, 420, 422, 444};
- 色空間の指定
- --sharpyuv
- 上記の場合で420が選択された時に特殊な420を設定するスイッチ
- -nclx 6/6/6 -r full
- 色空間の設定
- -j (--jobs)
- 並列化数
- --autotiling, --tilecolslog2, --tilerowslog2
- 並列化のためのタイル分割設定
品質設定(-q)
品質は-qオプションで0-100(100はロスレス)で指定できます。
AVIFの裏で走っているAV1エンコーダは、品質を64段階で指定できます。
つまり100段階も指定できないため、下記のように量子化されています。
const int quantizer1 = (int)round(((100.0 - q) * 63.0) / 100.0);
スピード(-s)
AVIFは何十ものアルゴリズム・ツールの組み合わせで動いています。
このツール群を、10段階くらいでグループ化し、選択しやすくしたプリセットがスピード-sオプションです。
オプションの 0~6はエンコーダに、AOM_USAGE_GOOD_QUALITYかAOM_USAGE_ALL_INTRAの指定値をいれて比較的高品質な画像が出力されるように命令を入れています。
オプションの 7-9は、 AOM_USAGE_REALTIMEの指定値をいれて、高速に動作するように命令を入れています。
なお、デフォルト値は6が入っています。つまり高品質モードの最速設定がデフォルトです。
実際に使う場合、画質と速度は設定値5,6,7で大きく変わり、特に5と
6に大きなギャップがあります。
高性能よりで使いたい場合は5を指定し、そうでない場合はデフォルト(オプション指定なし)で使うと良いでしょう。
speed 0,1,2はほとんど小さくならない割に恐ろしく計算時間を消費します。
ほぼ気のせいな差しかないため、最大品質圧縮をしたいときも3程度が良いでしょう。
なお、同じQP値でspeedオプションを変えるとサイズも画質も変わります。
言い換えると、QP=50で固定して下記2枚を出力したとき
- speed=5で出力された画像
- speed=0で出力した画像
直観的には、品質は同じでspeed=0のほうがファイルサイズが小さくなっていることを期待します。
しかし、必ずしもそうならず、speed=0のほうが画質が高く、ファイルサイズも大きくなっている場合もあります。
この場合は、speed=0のQP値を下げてファイルサイズをspeed=5の場合と同じになるまで下げて使うのが正しい使い方です。
QPを同じにして比較してはいけません。
(サイズを指定するオプションもありますが、計算時間が増えます)
例えば、QPを固定した場合、もっともファイルサイズが小さくなるのはspeed=6のオプションです。
ですが、このオプションは2番目に画質が悪いです。(一番画質が悪いのはspeed=9)。
画像圧縮するベストな方法(2025)でも述べましたが、QPを固定して比較することには意味がありません。
ここで紹介したインターフェイスを使えば、これが検証できます。
なお、他のエンコーダと比較した場合、先の紹介記事のベンチマーク から情報を拾うと、下記のことが言えます。
- MozJPEGよりもAVIFの最速設定オプションのほうが高精度かつ高速
- WebPの最高精度オプションよりもAVIFの最速設定オプションのほうが高精度かつ高速
つまり、たとえAVIFを最速設定で使った場合でも、WebPやMozJPEGよりも高速で高品質です。
該当コードは下記になります。
https://github.com/AOMediaCodec/libavif/blob/main/src/codec_aom.c
チューン(-a tune)
多くの画像圧縮は画像サイズと画像品質のトレードオフを最適化します。
それをrate-distortion最適化(RD最適化)と呼ぶのですが、AVIFは、その時の画像品質に、古典的なPSNRから、SSIM、Butteraugli、IQ (Image quality), SSIMULACRA2が指定できます。
デフォルトはPSNRです。
AVIFの性能が高い理由の一つがこの多様なチューンです。
初期のリリースでは、PSNRとSSIMが対象でしたが、数年前(2021/5)にButteraugliに対応しました。
このチューンオプションを使用するには外部ライブラリとしてJPEGXLの0.7系(古い系統)のライブラリを一緒にコンパイルする必要があります。
また、何度もButteraugliを内部でコールするため結構圧縮時間が伸びます。
また、今年のリリースで、IQおよびSSIMULACRA2が追加されました。
これは、AVIFのバックエンドであるAV1エンコーダの人間の主観評価特化版フォークであるSVT-AV1 PSYのプロジェクトの成果を反映させたものです。
なお、PSYのプロジェクトは終わったようです。
tune IQとSSIMULACRA2はフィルタの強弱が違うだけで低ビット域では同じ応答をします。
どちらのtuneもエンコーダ内部で処理が完了しており、外部ライブラリを使う必要がありません。
AVIFでは、アドバンスドオプションである-aにつづけてtune=PSNR、tune=SSIM、tune=Butteraugli、tune=iq、tune=11で利用できます。
リリースが最近のため、まだAVIFとlibaomの連携が間に合ってませんが、おそらくssimulacra2という名で動くようになるとは思いますが、
現状だとenumの番号である11番を指定する必要があります。
下記に各tuneのRD曲線を示します。
tune=SSIMULACRA2によりかなり性能が上がっていることが分かります。
PSNRの場合も一緒に乗せておきます。
こっちはtune=PSNRのほうが良いですが、高ビット帯はなぜかtune=IQのほうがいいですね。
RD最適化関数の出来の違いでしょうか?詳細はわかりません。
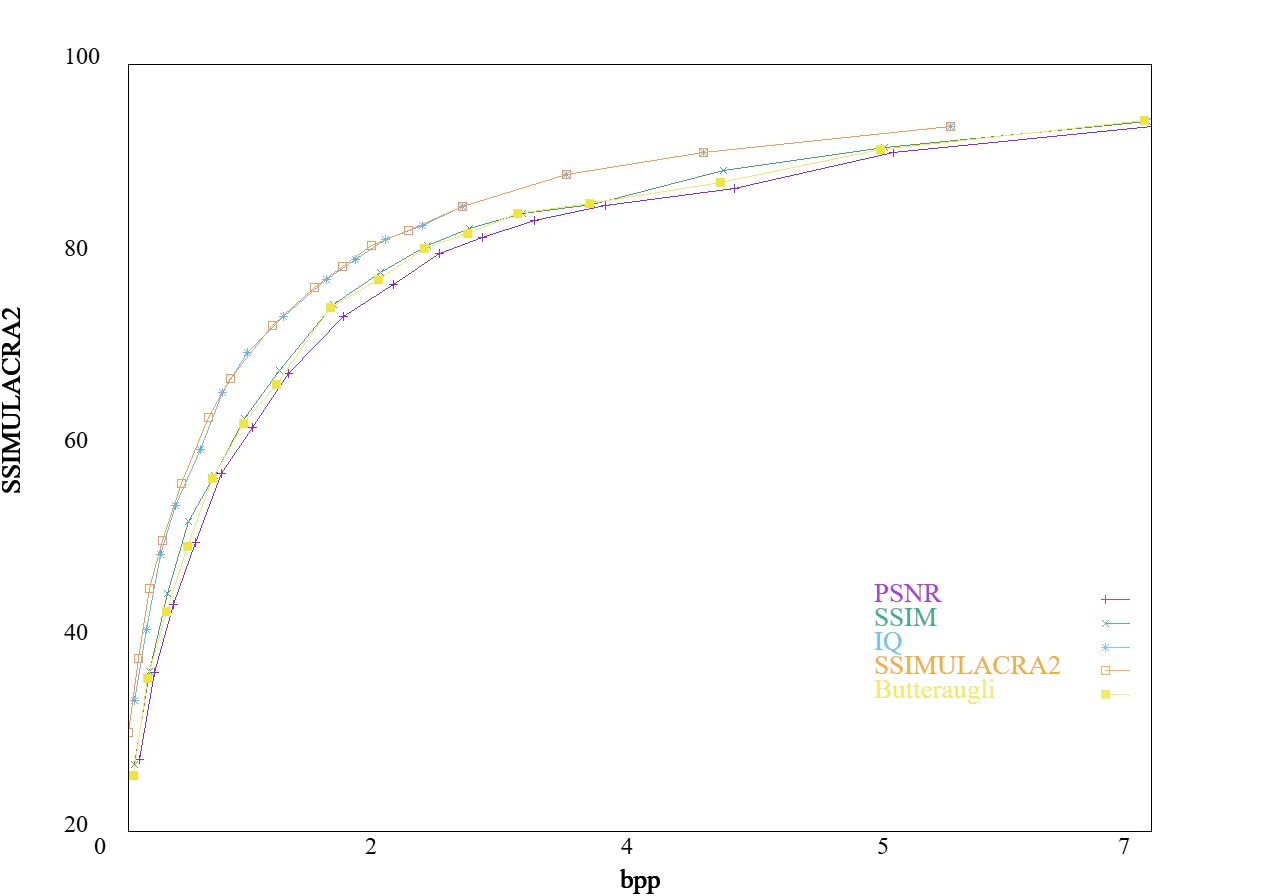
図:tuneオプションの違い(SSIMULACRA2)
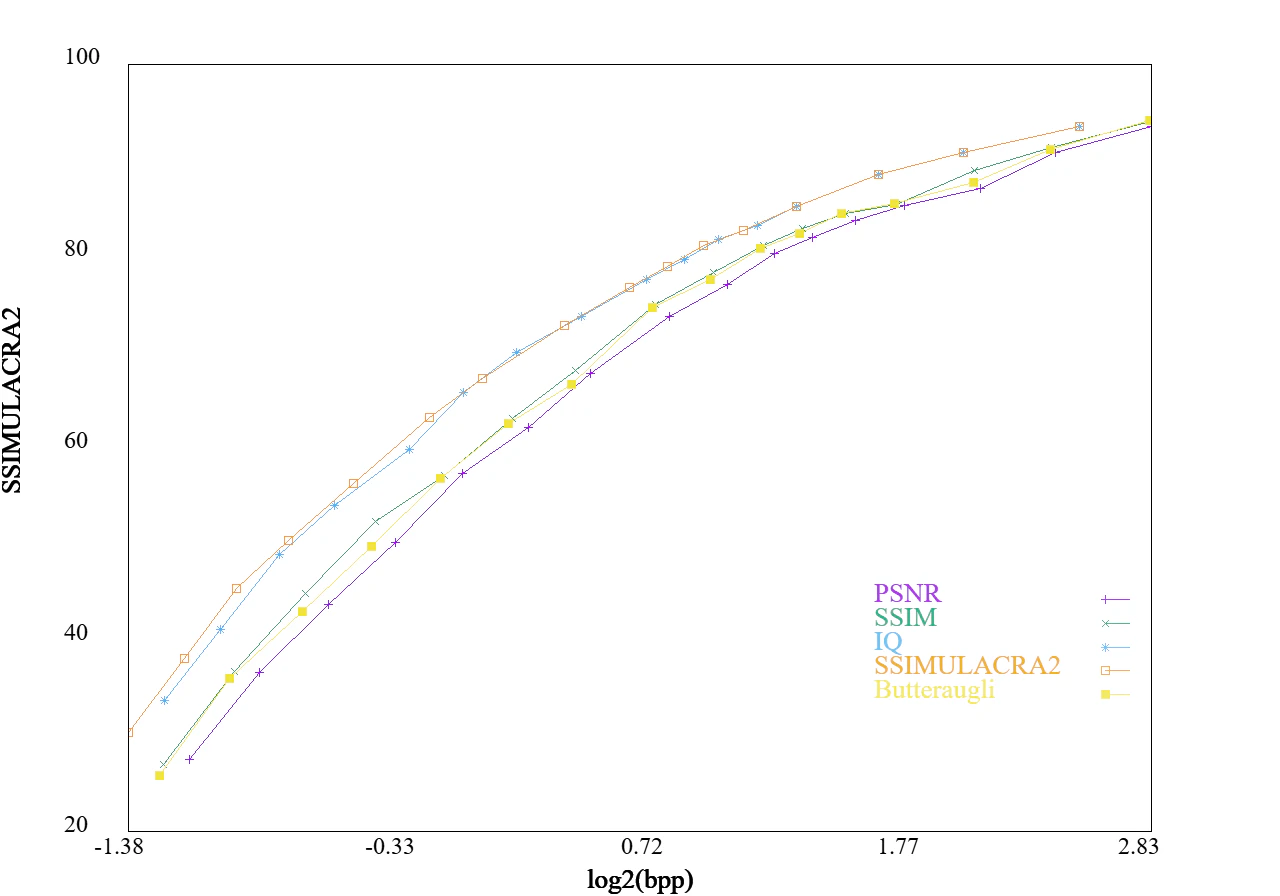
図:tuneオプションの違い(SSIMULACRA2)横軸対数
内部bit数(-d)
AVIFエンコーダは、普通の8ビット画像だけでなく10-bitや12-bitのHDR画像の圧縮も可能です。
この時、普通のSDR 8-bit画像を、10-bitのときは輝度を4倍、12bitの時は輝度を16倍に線形変換してHDR画像としておけば、普通の8-bitディスプレイで表示するときは8-bitで圧縮した場合とほとんど同じ色で表示されることが期待されます。
ビット数は-dオプションで指定可能です。
このように、内部でHDRとしてAVIFで圧縮すると8-bitで圧縮するよりも性能がわずかに向上します。
下記にRD曲線を示します。
低ビットの時は、エンコーダ内部を8-bit、10-bitで圧縮した場合わずかに性能が高いです。
高ビットの時は、エンコーダ内部を10-bit、12-bitで圧縮した場合わずかに性能が高いです。
10-bit、12-bit対応ディスプレイで目視して確認したわけではないため見た目どれくらい一緒かの確認は必須です。
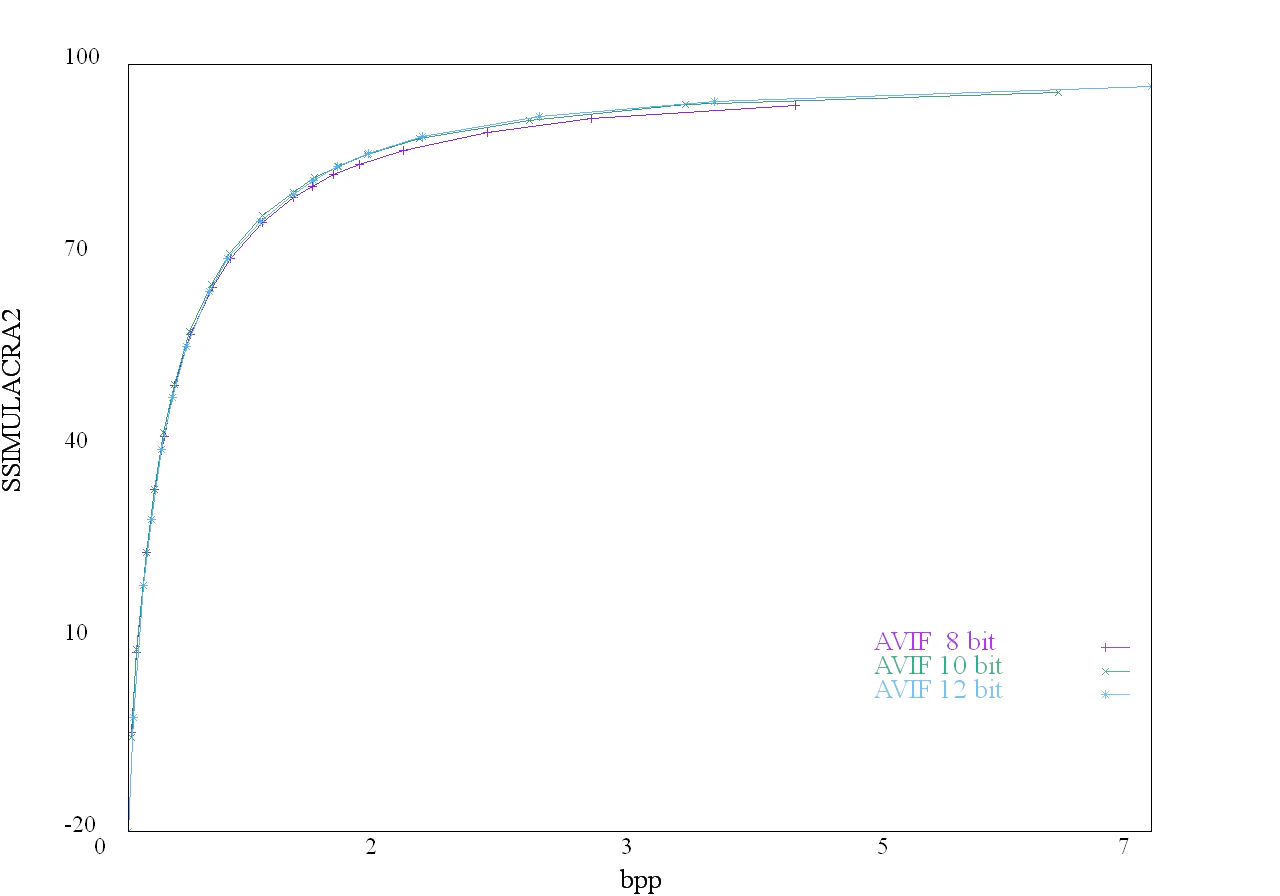
図:内部bit数の違い
ほとんど線が重なっているため、違いが分かりづらいため、横軸を対数化します。
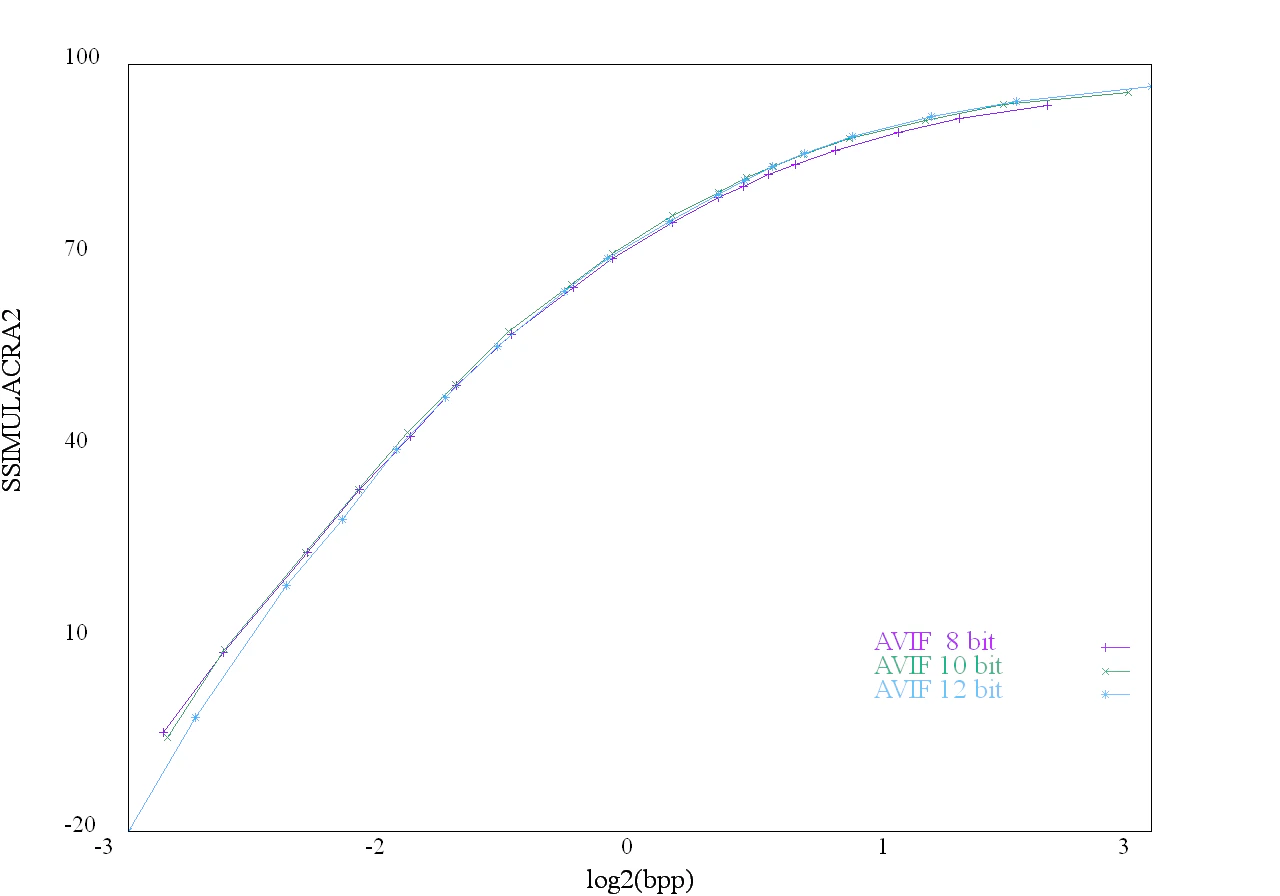
図:内部bit数の違い(横軸対数)
エンコードは、10-bitなら下記で設定可能です。
ただし、入力となるsrc.pngは16bit画像で、元の8-bit画像から4倍したものです。
avifenc.exe -q 80 -d 10 src.png dest.avif
色空間YUVの指定 (-y, --sharpyuv)
AVIFなどロッシーな非可逆圧縮は、RGBの色をそのまま圧縮することはなく、色空間を変換して圧縮します。
多くの場合YUV色空間が使われます。
Yが明るさ、uvが赤っぽさと青っぽさを表す画像になります。
この時、Yに比べてuやvは人間の感知能力が引くいことを利用してuvの解像度を間引く方法が使われます。
縦横1/2にするYUV420がよく使われ、たまに縦だけ1/2にするYUV422、ごくまれに横だけ1/2にするYUV440が使われます。
AVIFでは、-y 420や -y 444で指定できます。
この間引かれたUV信号は再生するときに拡大されてYと同じ解像度に戻されて使われます。
画像拡大は若干色がぼけるため、極端に色が変化するようなロゴのような画像の場合、この劣化が目立つ場合があります。
このにじみを防ぐため、YUVを間引くときに、シャープネスを掛けることで拡大して戻すときのボケを防ぐyuv420 sharpやsharp YUVと呼ばれる方法がWebPで導入されました。
この変換はどんな圧縮でも使え、AVIFでも使えるようになっています。
ただしコンパイル時にWebPに同梱されるlibyuvsharpをリンクする必要があります。
AVIFでは、--sharpyuvをつければYUV420を指定したときにYUV Sharpが使われます。
このYUVSharpは、人間から見たときの見た目や、SSIMULACRA2などの主観評価に近い指標のスコアを上げますが、元の信号から遠くなるため古典的な指標であるPSNRは下がるため比較するときは注意が必要です。
下記にYUV420, 420 sharp, 444のRD曲線を示します。
基本的に低ビットはYUV420が良く、高ビットは444でないと高品質にすることができません。
YUV 420 sharpにしたら、だいたいどこでもそれなりに良い品質にできます。
画像圧縮の速度は、YUV420のほうがYUV444よりも高速です。
これは、処理する情報量が少ないためです。
なお、YUV420 sharpの変換は結構重たいです。そのため、YUV Sharpの420と444圧縮はどちらが速いかは場合によります。
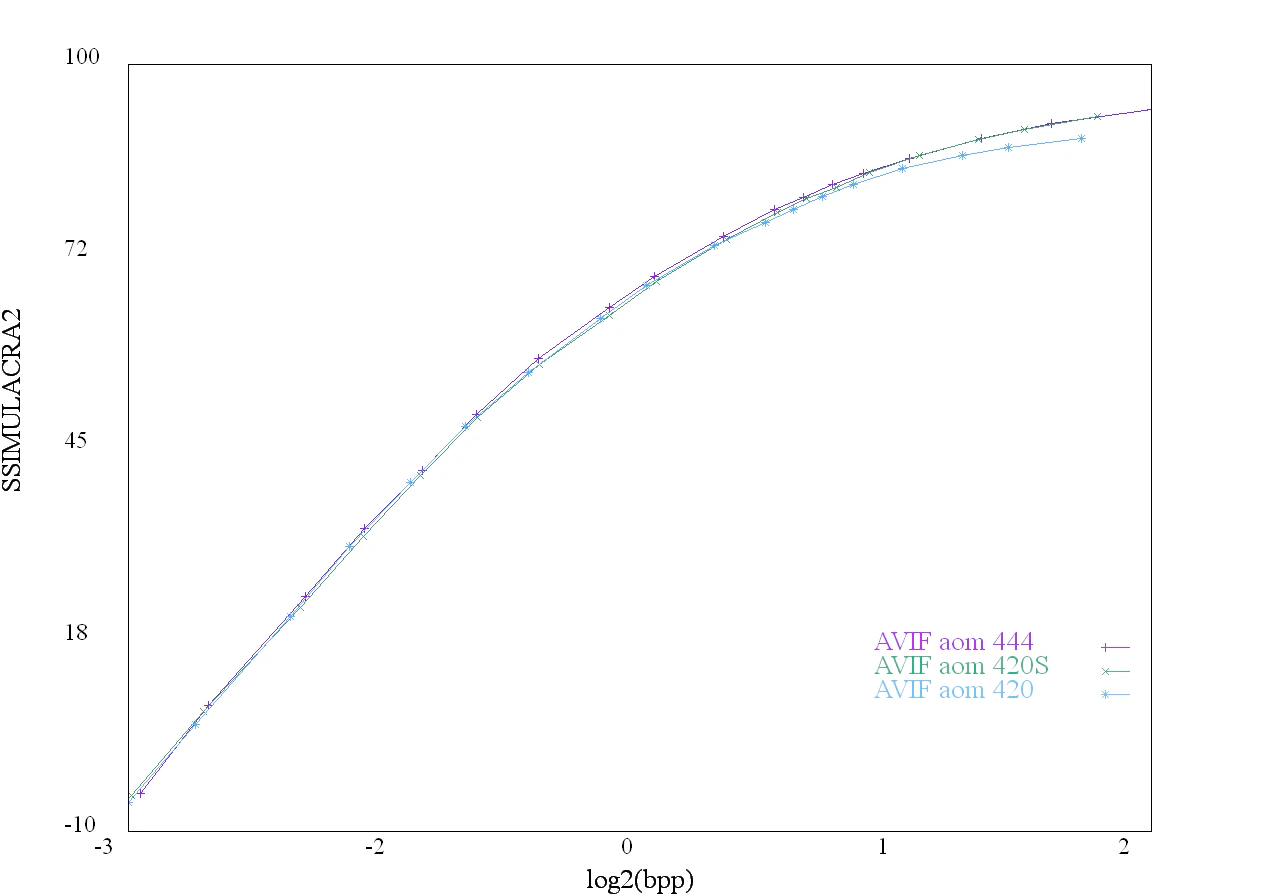
図:YUVの違い
色空間YUV:BT.601とBT.709
RGBからYUVに変換する時、BT.601かBT.709を選ぶことができます。
詳しいことは抜きにして、古いJPEGはBT.601を使っており、新しい規格はBT.709も使えます。
AVIFでは、BT.601は--nclx 6/6/6、BT.709は--nclx 1/1/1で指定できます。
なおデフォルトはBT.601です。
現代の写真は、BT.709を使ったほうがちょっとだけ圧縮できることが多いです。
なお、変換式がわずかに違うだけなため、速度に違いはありません。
下記に3種類の画像に対して両色空間で圧縮した結果を示します。
ほんの少しだけBT.709のほうがいい例を2つ、BT.601のほうがいい例を1つ示します。
統計的にはBT.709のほうが良いですが、圧縮してみないとどちらのほうが良いかはわかりません。
また、差は小さいためデフォルト設定でもよいでしょう。
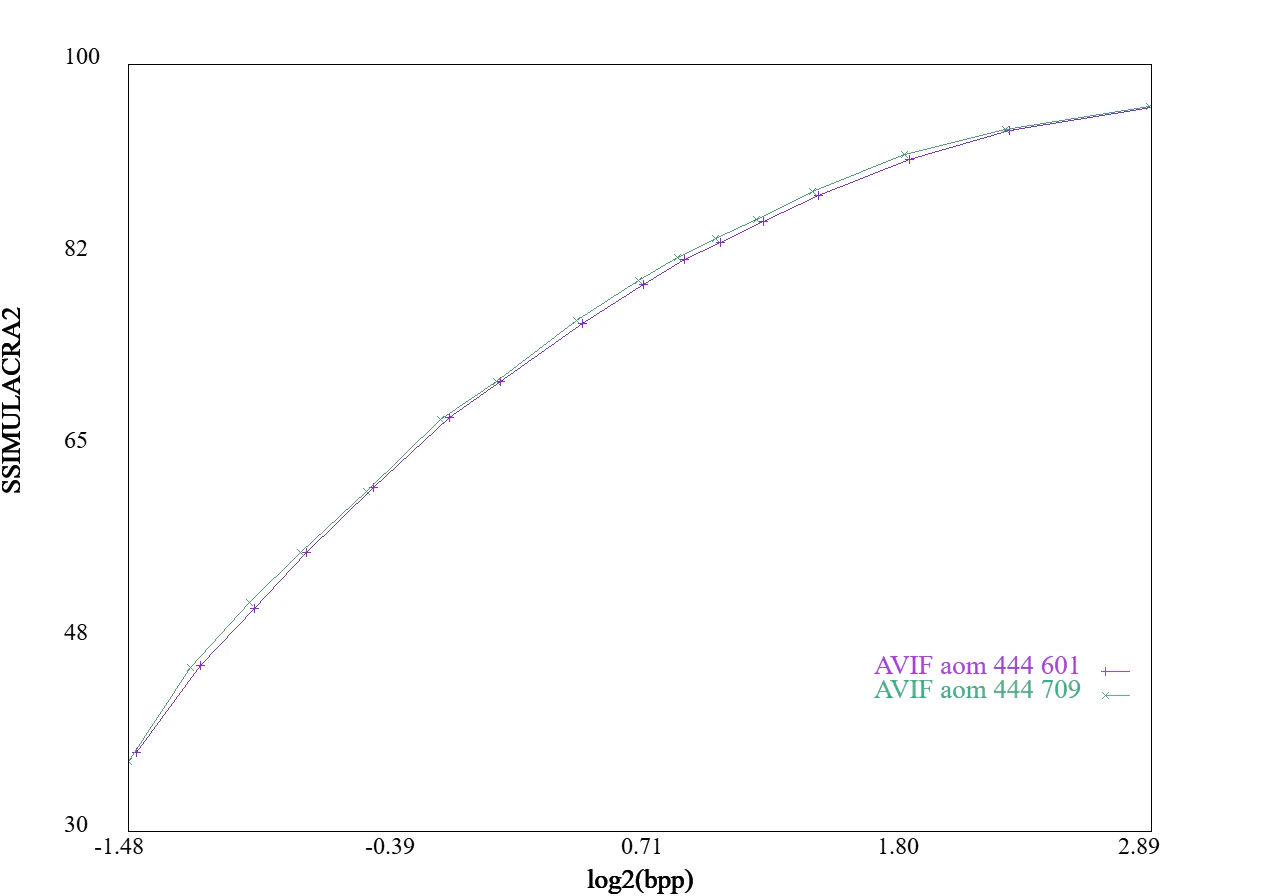
図:YUVのBT601とBT709の違い(その1)
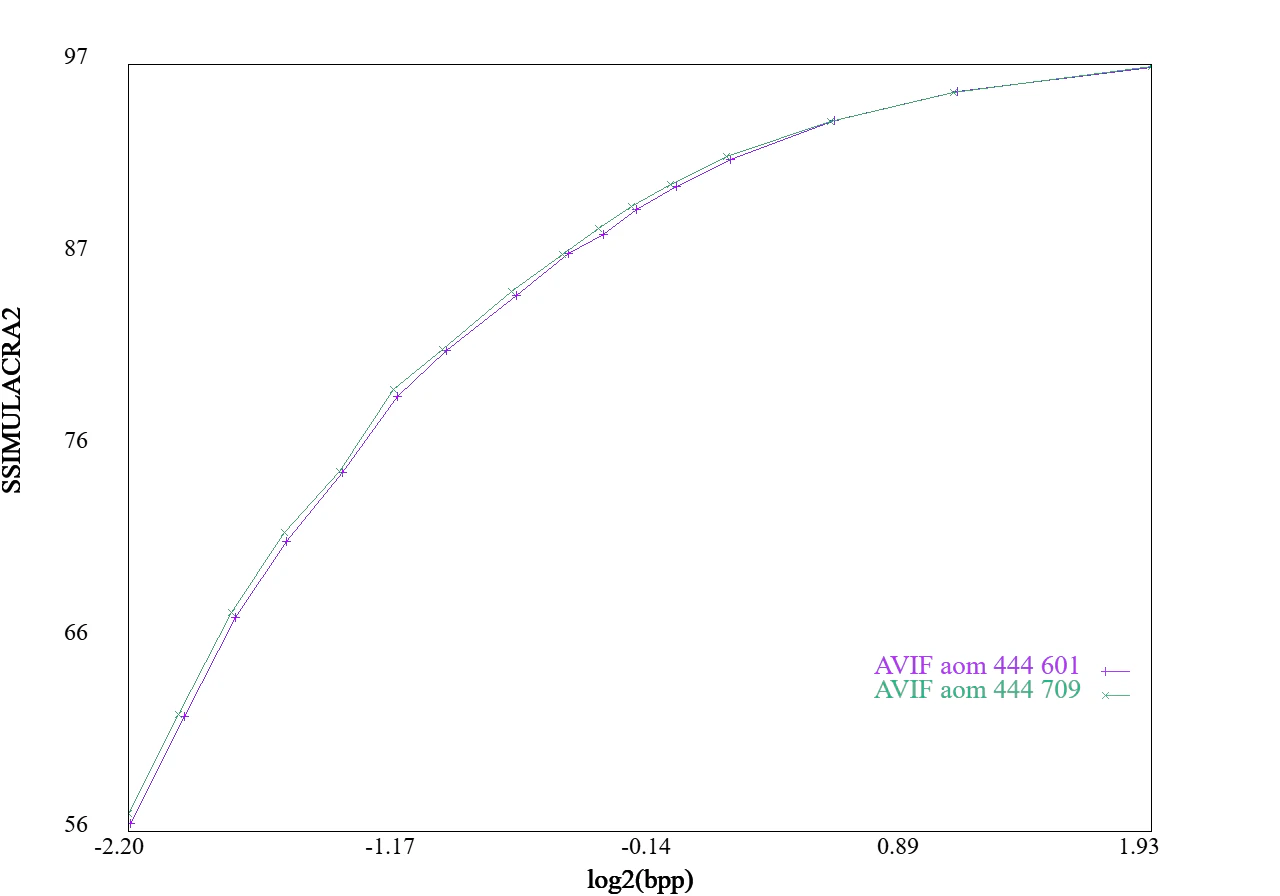
図:YUVのBT601とBT709の違い(その2)

図:YUVのBT601とBT709の違い(その3)
マルチコア並列化(-j)
高速化に最も効くのは、speed設定ですが、マルチコアで動かすようにして数倍速くなります。
-jで動作するコア数を指定すると高速化します。
マルチコアで動作するときに2系統の並列化を設定することができます。
一つ目は行単位の並列化で、何も指定しなければこれだけが動きます。
これは、画像の1行単位でコアを割当てて計算します。
並列化が設定されると、分業して計算できるようにアルゴリズムがわずかに変更されます。
その結果、圧縮の性能自体はわずかに下がります。
また、行単位の並列化は、計算の依存関係を断ち切れる量が少なく、画像サイズにもよりますが2コア~4コアくらいしか有効に活用できません。
詳しい人向けには、アムダールの法則において、並列化可能な割合が低いという意味です。
下記に並列化した場合としなかった場合のRD曲線を示します。
ほんのわずかにシングルコアのほうが性能が良いのですが、まずわからないかと思います。
4コアCPUでテストしたところ、
512 x 512で129msが90ms、1024 x 1024で600msが300msでした。
速度は、コア数や画像によって違いますが、1.25倍~2倍が期待できます。
期待するほど速くはないですね。
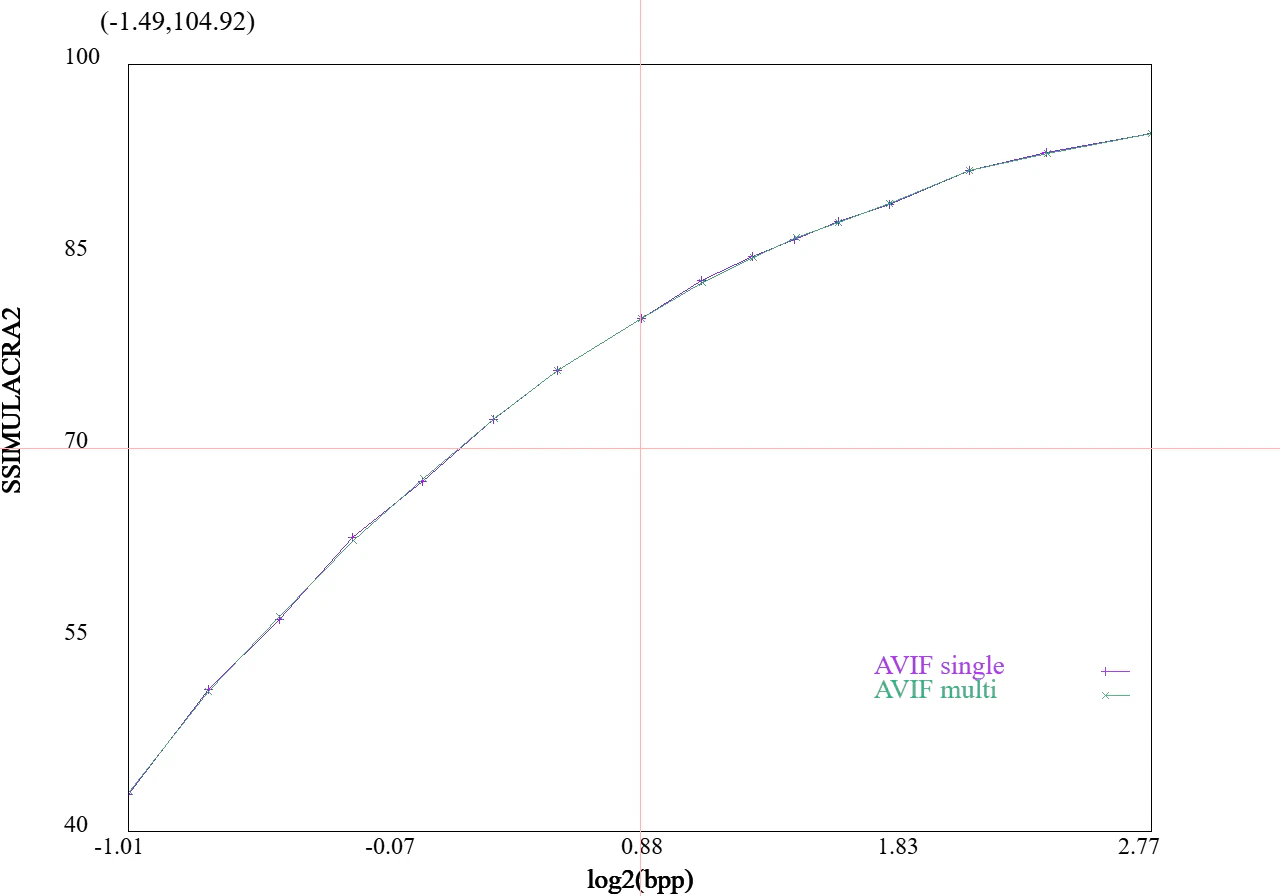
図:並列化の有無
タイル分割(--autotiling, --tilecolslog2, --tilerowslog2)
普通の並列化だけでは、並列化効率が低く、多コア環境ではコアを持て余します。
その時は、画像をタイル分割し、1枚の画像を小さな画像がたくさん並んでいるとみなして圧縮するモードにすると、さらにコア数を使えるようになります。
その時の指定の仕方が、自動的に設定する--autotilingオプション、もしくはマニュアルで横、縦それぞれの分割数(のlog2)を指定する --tilecolslog2, --tilerowslog2です。
--autotilingで指定した場合、おそらく画像サイズが512 x 512が最小となるように画像がタイルで分割されます。
--tilecolslog2、--tilerowslog2は、log2の値のため0で分割なし、1で2分割、2で4分割、3で8分割です。最大で6まで設定できます。
これを縦横で指定するためブロック構造が出来上がります。
最小のタイルサイズは128です。
下記に、タイル分割した場合のRD曲線を示します。
通常の並列化と違ってタイル分割するとレートが低いときに性能が下がっていることが分かります。
256x256のタイルサイズなら許容範囲ないかなくらいの差で、autoのタイルである512x512なら差はほぼわからないくらいかなと思います。
速度は下記にのようになりました。
512 x 512
- single 129ms
- multi 90ms
- autotile 90ms (512x512のタイルになるので上と同じ)
- tile(1,1) 55ms (256x256のタイル4個)
- tile(2,2) 41ms (128x128のタイル16個。テストしたマシンだとコア数足りない)
- tile(3,3) 41ms (128x128のタイル16個。同上)
1024 x 1024
- single 660ms
- multi 370ms
- autotile 250ms (512x512のタイル4個)
- tile(1,1) 250ms (512x512のタイル4個)
- tile(2,2) 230ms (256x256のタイル16個。テストしたマシンだとコア数足りない)
- tile(3,3) 225ms (128x128のタイル64個。テストしたマシンだと全然コア数足りない)
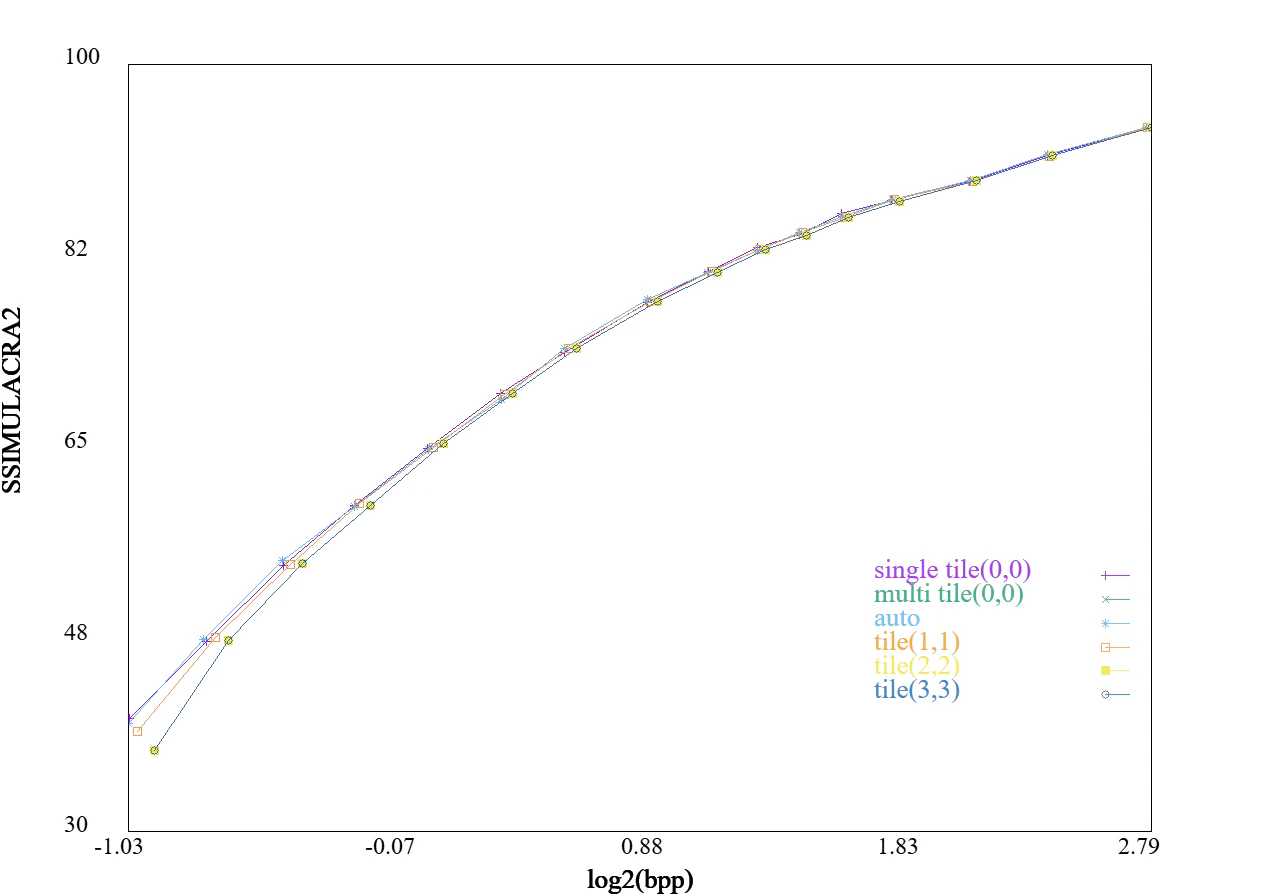
図:タイル分割(512 x 512) tile(2,2)とtile(3,3)はタイルサイズ下限のため同じ
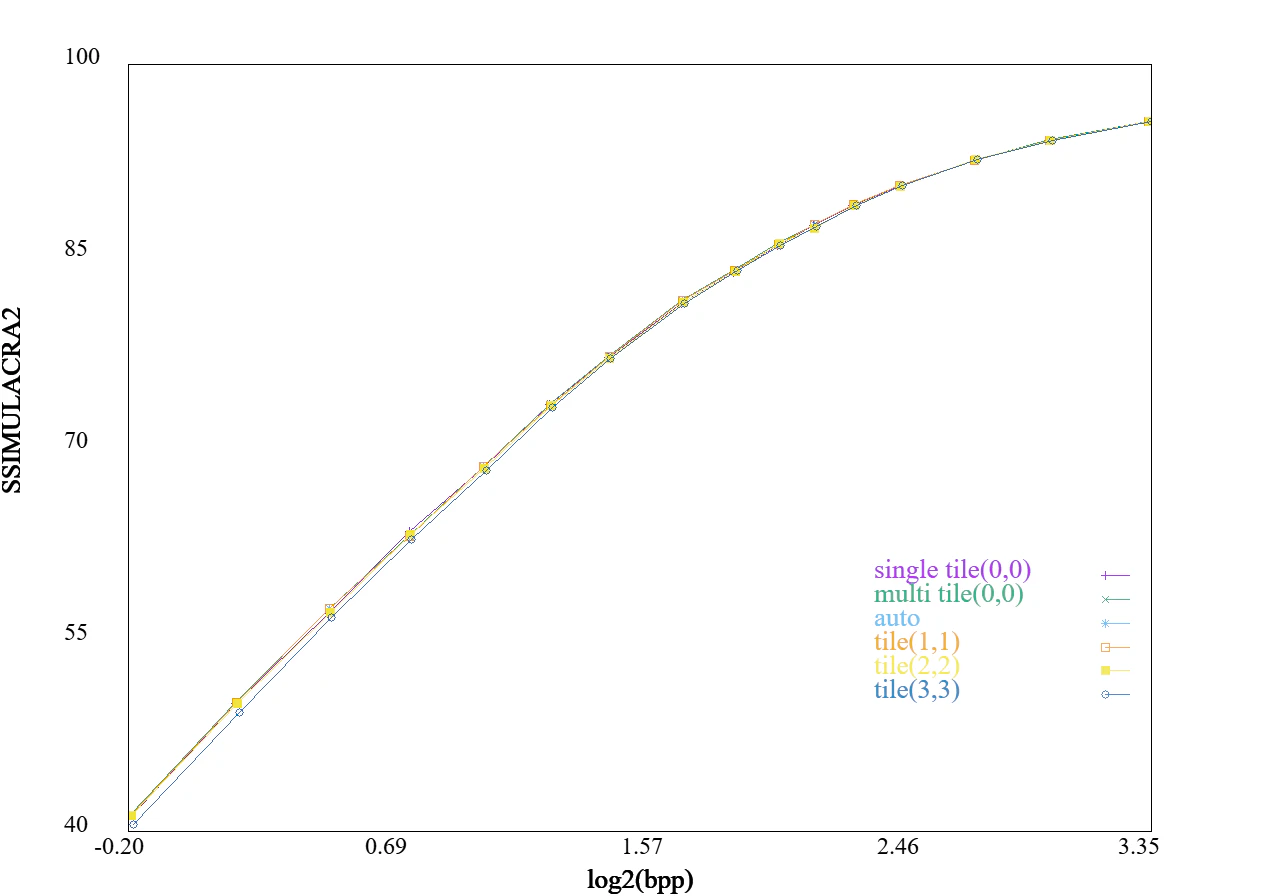
図:タイル分割(1024 x 1024)
OpenCVの対応状況
OpenCVで有効化しているオプションは下記のみです。
使っているライブラリはlibavifなため、該当コードが書かれていないだけで全てオプションが使えます(だれかパッチを作れば)。
imgcodecsモジュール内のコードであるgrfmt_avif.cpp, grfmt_avif.hppに記述されています。
対応しているキーは下記であり、クオリティ、デプス、スピードの3種類のみ指定可能です。
その他はデフォルトです。
m_supported_encode_key = { IMWRITE_AVIF_QUALITY, IMWRITE_AVIF_DEPTH, IMWRITE_AVIF_SPEED };
- IMWRITE_AVIF_QUALITY 0-100
- IMWRITE_AVIF_DEPTH 8/10/12を指定可能
- IMWRITE_AVIF_SPEEDで0-10
『効いてない?』で悩まない imgcodecsがIMWRITEパラメータを本気でバリデーションの記事で紹介されているバリデートしている項目が上記3つです。
色空間は、YUV420固定であり、下記で設定されています。
result->colorPrimaries = AVIF_COLOR_PRIMARIES_BT709;
result->transferCharacteristics = AVIF_TRANSFER_CHARACTERISTICS_SRGB;
result->matrixCoefficients = AVIF_MATRIX_COEFFICIENTS_BT601;
result->yuvRange = AVIF_RANGE_FULL;
まとめ
上記までの各種設定を想定すると、下記のようなオプションが良いでしょう。
- 速度・精度のバランス型の設定として下記を使うといいでしょう。
speedオプションをデフォルトの6として、YUV444のBT.709を使い、マルチスレッドをオートタイルにして、あとは、tune=11でSSIMULACRA2で最適化します。
avifenc.exe -q 80 -y 444 --nclx 1/1/1 -j 16 --autotiling -a tune=11 src.png dest.avif
- 速度を無視して・最高性能の最大圧縮型の設定として下記を使うといいでしょう。
speedオプションは最大の0、YUV444のBT.709を使い、デプスを10-bitに設定します。マルチスレッドは使いません。あとは、tune=11でSSIMULACRA2で最適化します。
avifenc.exe -q 80 -y 444 --nclx 1/1/1 -s 0 -a tune=11 -d 10 src.png dest.avif
- 圧縮性能を無視して・最速性能の最速圧縮型の設定として下記を使うといいでしょう。
speedオプションは最速の9、YUV420を使い、マルチスレッドはマニュアルで最大タイル分割を指定します。あとは、tune=11でSSIMULACRA2で最適化します。
これでもWebPよりも高圧縮かつ高速になっているはずです。
avifenc.exe -q 80 -y 420 -s 9 -j 16 --tilecolslog2 6 --tilerowslog2 6 -a tune=11 src.png dest.avif
前回紹介したSCPCベンチマークでは、AVIFは、現在150通りのオプションのテストが上がってます。
しかし下記はテストしていません。
- ビット深度の違い
- 色空間のBT.601とBT.709の違い
- タイル分割数の違い
これらを含めると3x2x7=42倍、つまり6300通りのオプションでエンコードする必要が出てきて、網羅的に計算を完了させるまでに約10年くらいかかります。
そのころには、新しいコーデックが出来て、この情報は意味がなくなってしまうでしょう。
現状でも普及率を考えなければ、H.266/VVCのイントラ符号化を使えばAVIFよりも高性能に圧縮できますし、もうすぐAVIFのバックエンドであるAV1がアップデートされてAV2が登場します。
次世代の符号化規格であるJPEG AIも出てきます。
次の規格の登場を楽しみに待ちましょう!