ふくだ学習録とは?
ふくだが学習したことの備忘録。
目に見える形で残すことによってやる気を出す個人的な作戦です。
他人に見せるように書いているわけではないので、すごく読みにくいです。
読了した本
データベースエンジニア養成読本 [DBを自由自在に活用するための知識とノウハウ満載!]
ゼロから作るDeepLearning
PHPフレームワーク CakePHP 3入門
SQLアンチパターン
Docker入門
今読んでいる本
なし
アプリ制作
進捗
私用が多かったので、あまり作成進んでいない。
一旦、下記赤枠部分のスクレイピング部分は完成した。(dockerコンテナでの環境構築と、scrapy,seleniumでの情報取得)
ここからは、scrapyからmysqlへの取得情報のカキコミを実装する。
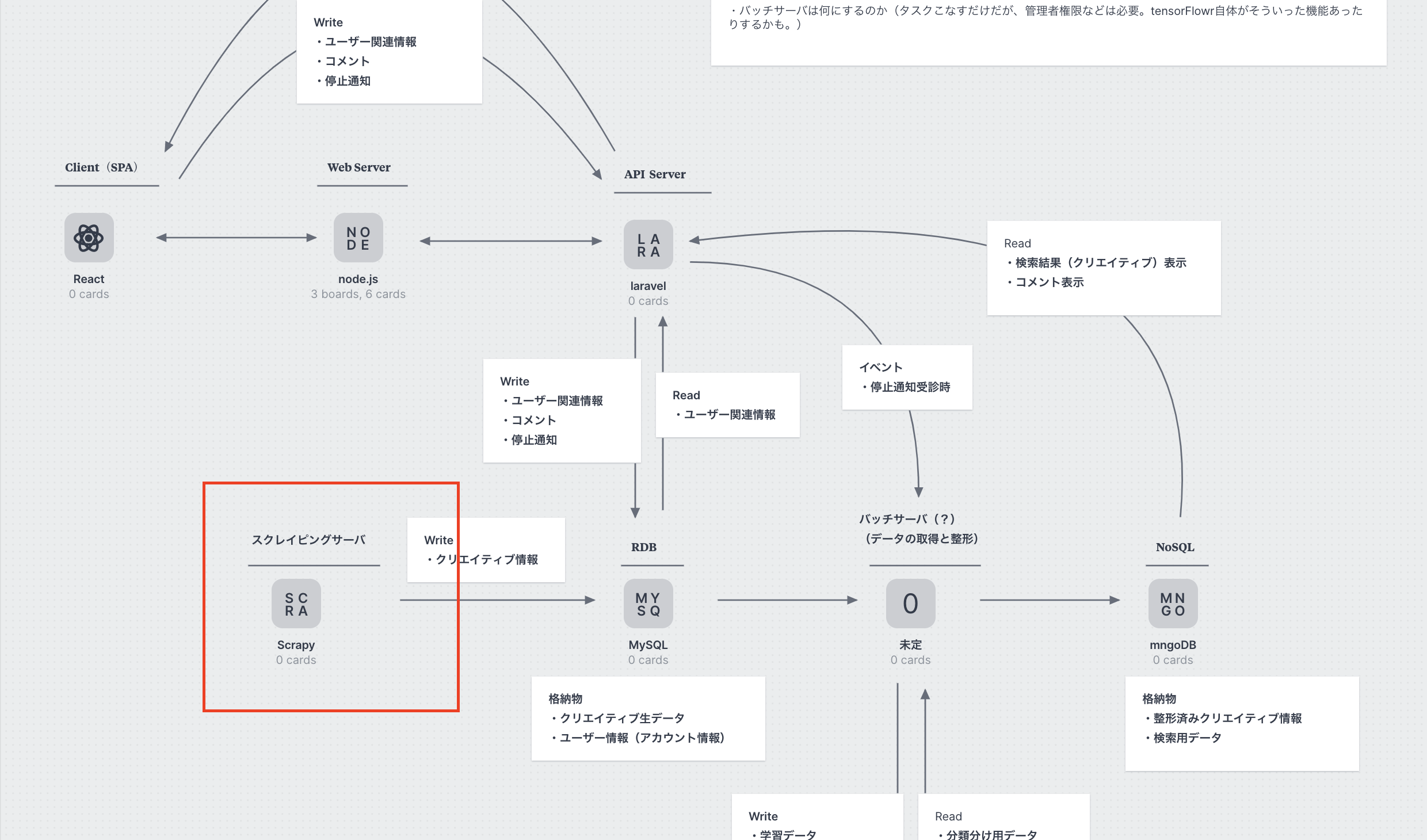
scrapyでスクレイピングする対象サイトの追加が、現在CUIコマンドで行なっているけど、できればGUI(というかブラウザ上の管理画面的なところ)で行えるようにしたいなぁ。。
ってなってきたら、
①scrapyは、Django内で動かす
②Djangoでscrapyタスク作成画面を作成する
(具体的には「新規spiderを作成」と「クローリングの実行タイミングの制御」を管理できるようにする)
③scrapyで集めた情報をMySQLへカキコミする。
上記の流れが良さそう(だと思ってる)
悩んでいる部分
悩んでいる(というか経験少なくて何がベストプラクティスかわからない)ところは下記の部分。
1個目
scrapyとDjangoは別コンテナで作成しなくてはならないって認識で合っているのか?
というかそもそも「Django側からscrapyを操作する」って対応が正しいのか?
2個目
scrapyで取得した情報をRDBへ書き込む方法は
①scrapy内部にcsvとして一旦保存。その後、csvファイルを一旦Django側に渡し、その情報あを元に一気にMySQLへ入力する」
②scrapyでクローリングを実行する度に、RDBへカキコミしていく。
上記2点のどっちの方が良さそうか?
(個人的な見解としては①のが効率良さそうやしベターな気がしてる。同じ情報を取得してるかどうかは、スクレイピング実行後に判明するから、都度RDBへ情報保存したところで効率変わらなさそうなので)
上記ちょっと社内の先輩に相談してみる。
seleniumのエラー
spider実行すると、下記のエラーが出てspider止まってしまう事象が発生していた。
selenium.common.exceptions.WebDriverException: Message: unknown error: session deleted because of page crash
しかも、同じコマンド打ってもエラーが発生するとき,しないときがあるという困った状況。
調べてみると、どうやらメモリ不足が原因(っぽい)。
Capybara の e2e テストで Chrome が Selenium::WebDriver::Error でたまにクラッシュする
とりあえずdockerへ割り当てるリソース増やした。これで解決されることを祈る。
今日の一言
エンジニアやのに最後の方祈って終わってしまってる。ダメダメエンジニアや。。。
精進していこ。。